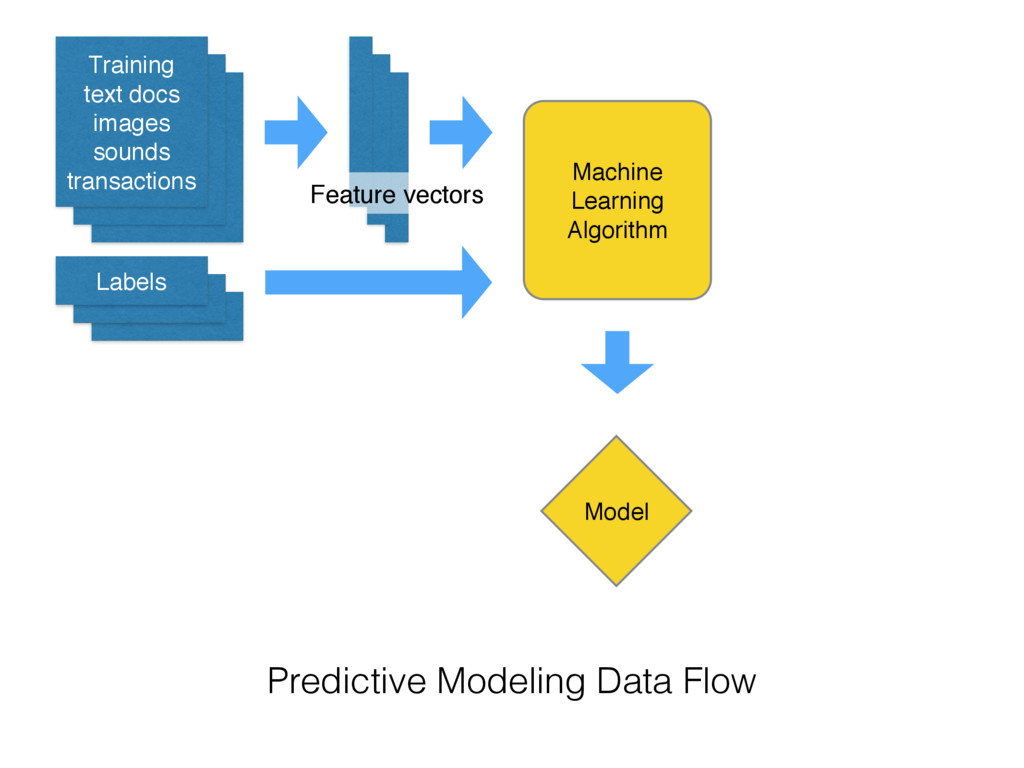
on new data • Extract the structure of historical data • Statistical tools to summarize the training data into a executable predictive model • Alternative to hard-coded rules written by experts
the criterion when searching for the best split value • Speed up between 1.1x and 2x depending on data and CPU architecture • Still not as fast as XGBoost but getting closer
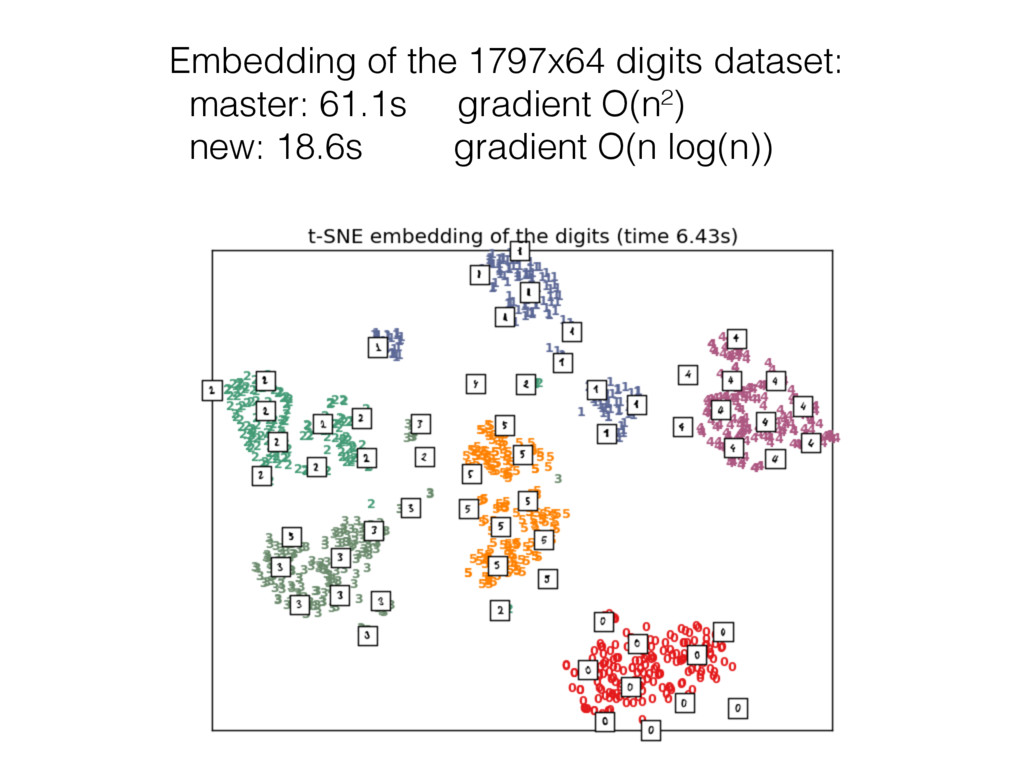
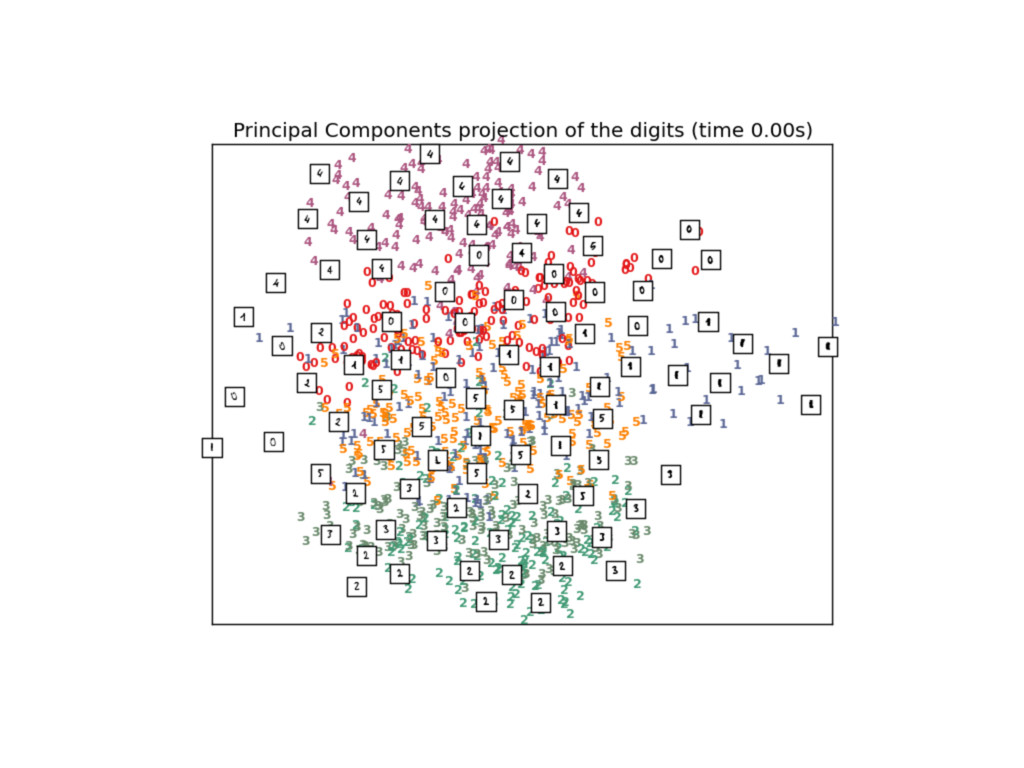
distances • Very useful for visualization of high dim data when PCA does not work • BH-T-SNE: Approximate methods to skip useless pairwise distance computation • Still work to do to cut memory usage
document based on topics • Online solver: incremental fitting on data that does not fit in RAM • Based on an implementation by Matt Hoffman adapted for the scikit-learn common API
keys clipper use security public technology bit Topic #11: memory use video bus monitor board ground pc ram need Topic #14: game team games play season hockey league players bike win Topic #19: drive scsi disk mac problem hard card apple drives controller
Projected Gradient solver • CD less sensitive to initialization scheme than PG • Change in hyper-parameters to make them more consistent with other scikit-learn models
vga bus cards drivers color driver ram Topic #16: team games players year season hockey play teams nhl league Topic #18: jesus christ christian bible christians faith law sin church christianity Topic #19: encryption chip clipper government privacy law escrow algorithm enforcement secure
SGD / L-BFGS solvers (pure numpy, no GPU) • Gaussian Processes big refactoring • Anomaly detection with Isolation Forests • More flexible API for Cross-Validation splitters
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}