Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Intro to scikit-learn
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
Olivier Grisel
August 27, 2017
Technology
750
5
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Intro to scikit-learn
EuroScipy 2017
Olivier Grisel
August 27, 2017
More Decks by Olivier Grisel
See All by Olivier Grisel
An Intro to Deep Learning
ogrisel
1
340
Predictive Modeling and Deep Learning
ogrisel
2
400
Intro to scikit-learn and what's new in 0.17
ogrisel
1
420
Big Data, Predictive Modeling and tools
ogrisel
2
350
Recent Developments in Deep Learning
ogrisel
3
730
Documentation
ogrisel
2
280
How to use scikit-learn to solve machine learning problems
ogrisel
0
1.1k
Build and test wheel packages on Linux, OSX and Windows
ogrisel
2
370
Big Data and Predictive Modeling
ogrisel
3
260
Other Decks in Technology
See All in Technology
伝票作成AIエージェントを支える、LLMOpsとインフラの選択肢 / AICon2026_takeda
rakus_dev
0
270
10年目を迎えた「ABEMA」がどのように AI 活用を推進して、AI 駆動開発にシフトしているのか / How ABEMA, entering its 10th year, is promoting the use of AI and shifting toward AI-driven development
miyukki
0
380
インシデント事例と パッケージの全量解析に学ぶ ソフトウェアサプライチェーンの守り方 / supply-chain-attack-defense
flatt_security
0
1k
なぜ、あなたのAPIは使われないのか? AX時代の設計原則、ガードレール、運用体制
yokawasa
1
220
アップデートで何が変わった?デモで学んで使いこなすIBM Bob2.0
muehara
0
250
Aurora MySQL 8.4リリース! Rubyistが備えること / what-rubyist-should-prepare-for-aurora-mysql-8-4
fkmy
0
1.1k
Multicaで30個のミニプロジェクトをAIエージェント運用して見えてきたこと
eiei114
1
650
AI時代の開発生産性は、個人技からチーム設計へ
moongift
PRO
4
2.6k
AI時代のYAGNI:「爆速で無駄になった機能」からの学び / 20260720 Naoki Takahashi
shift_evolve
PRO
3
540
ここは地獄!つらい朝会を体験することで、チームとしてのより良い振る舞いに気づくワークショップ / The stand-up meeting from hell in the game industry
scrummasudar
0
300
ダッシュボード"開発"について 〜使われるダッシュボードのつくりかた〜
kimichan
0
210
PHPで作って学ぶリアルタイム音声対話AIとWebSocket入門 by ムナカタ
munakata
0
150
Featured
See All Featured
Primal Persuasion: How to Engage the Brain for Learning That Lasts
tmiket
0
390
A better future with KSS
kneath
240
18k
How to train your dragon (web standard)
notwaldorf
97
6.7k
Prompt Engineering for Job Search
mfonobong
0
380
Mobile First: as difficult as doing things right
swwweet
225
10k
The Myth of the Modular Monolith - Day 2 Keynote - Rails World 2024
eileencodes
28
3.6k
The Language of Interfaces
destraynor
162
27k
Groundhog Day: Seeking Process in Gaming for Health
codingconduct
0
250
A Guide to Academic Writing Using Generative AI - A Workshop
ks91
PRO
1
360
First, design no harm
axbom
PRO
2
1.2k
Un-Boring Meetings
codingconduct
0
350
Unsuck your backbone
ammeep
672
58k
Transcript
Intro to scikit-learn EuroScipy 2017 - Olivier Grisel - Tim
Head
Outline • Machine Learning refresher • scikit-learn • Hands on:
interactive predictive modeling on Census Data with Jupyter notebook / pandas / scikit-learn • Hands on: parameter tuning with scikit-optimize
Predictive modeling ~= machine learning • Make predictions of outcome
on new data • Extract the structure of historical data • Statistical tools to summarize the training data into a executable predictive model • Alternative to hard-coded rules written by experts
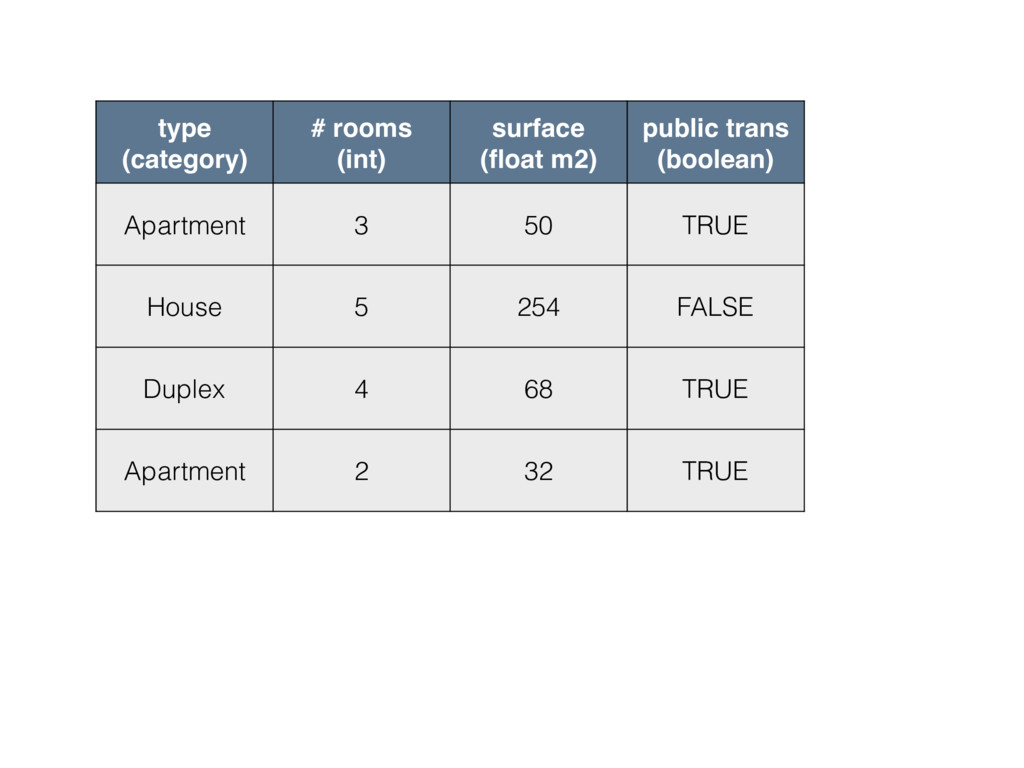
type (category) # rooms (int) surface (float m2) public trans
(boolean) Apartment 3 50 TRUE House 5 254 FALSE Duplex 4 68 TRUE Apartment 2 32 TRUE
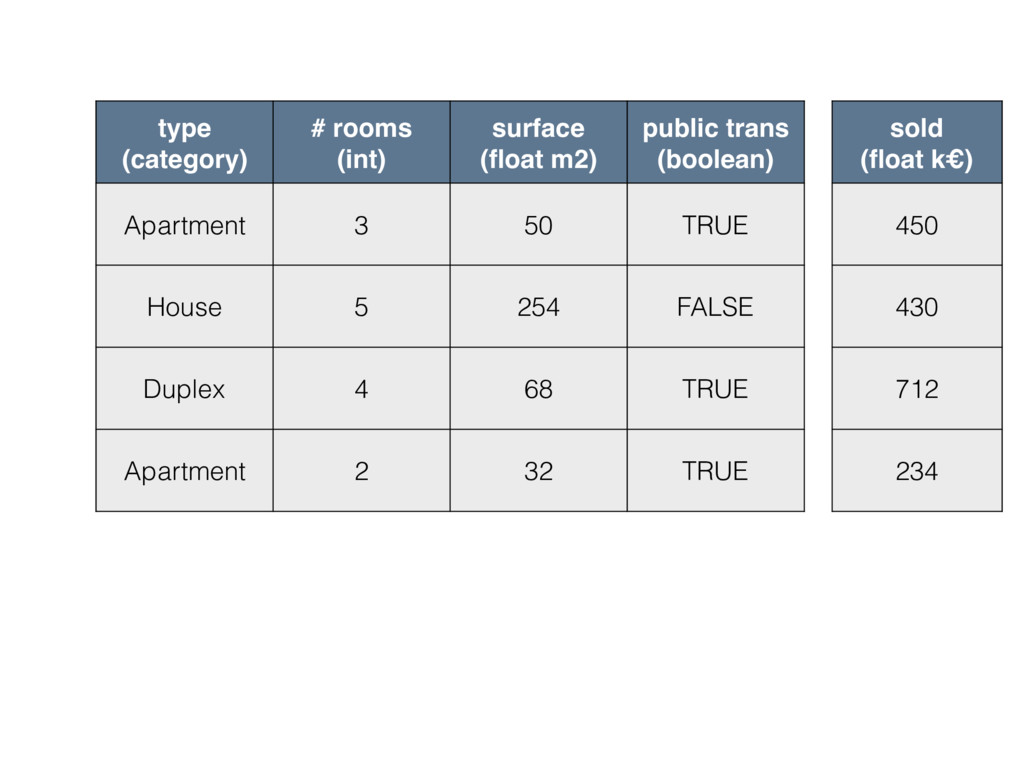
type (category) # rooms (int) surface (float m2) public trans
(boolean) Apartment 3 50 TRUE House 5 254 FALSE Duplex 4 68 TRUE Apartment 2 32 TRUE sold (float k€) 450 430 712 234
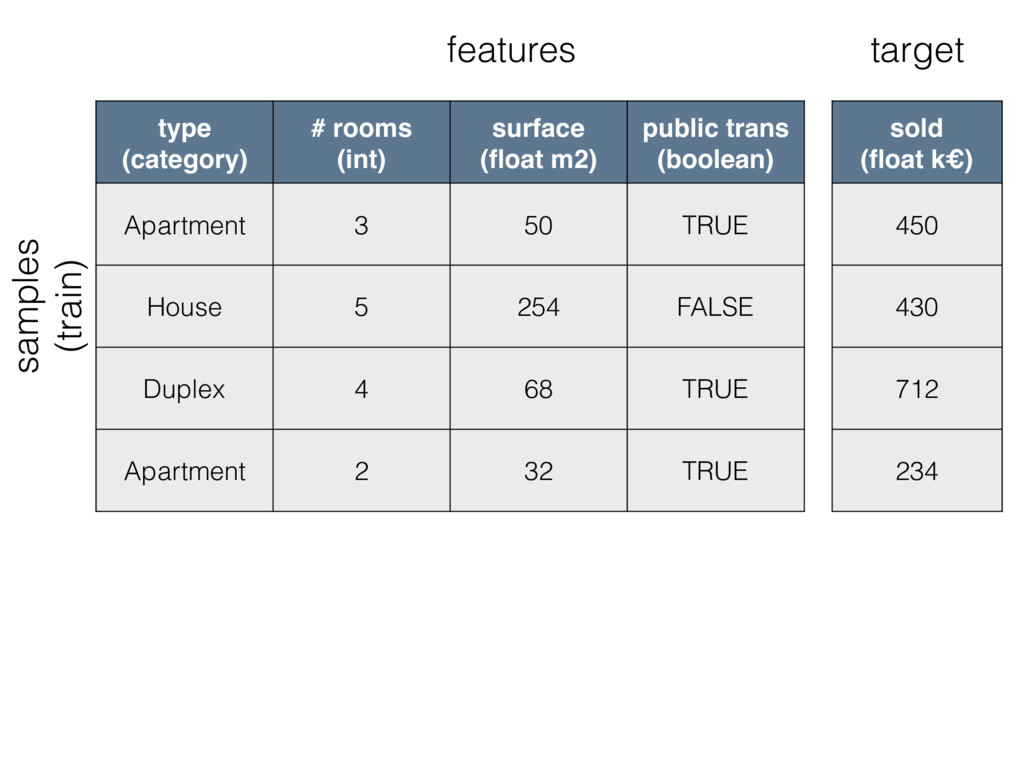
type (category) # rooms (int) surface (float m2) public trans
(boolean) Apartment 3 50 TRUE House 5 254 FALSE Duplex 4 68 TRUE Apartment 2 32 TRUE sold (float k€) 450 430 712 234 features target samples (train)
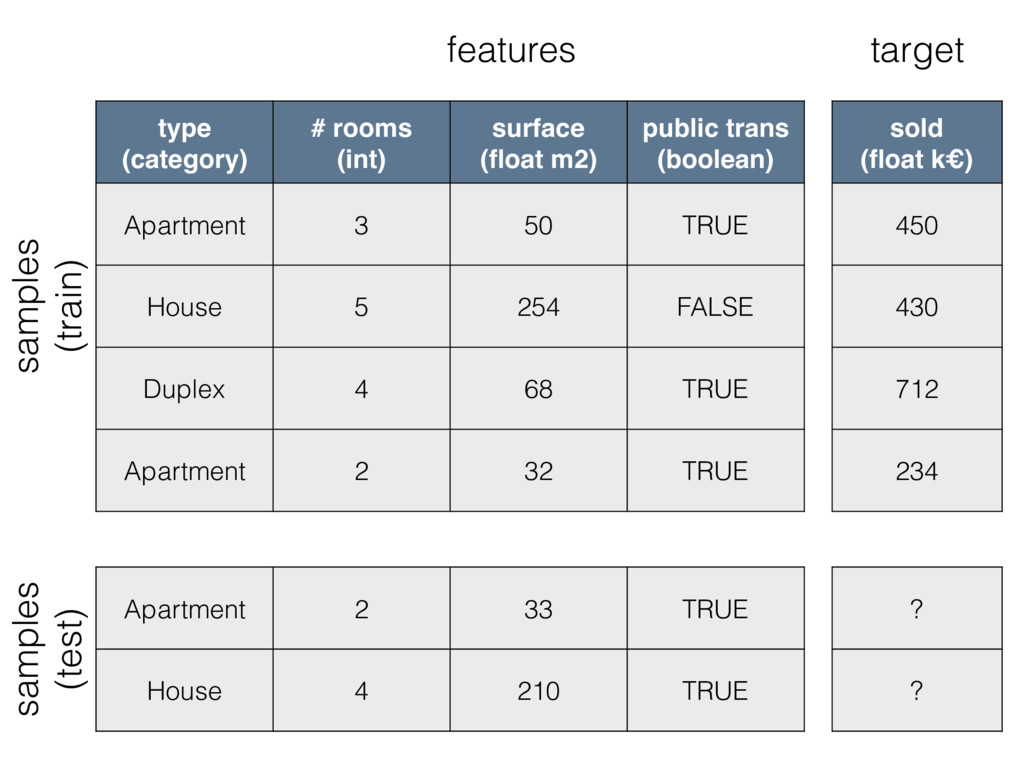
type (category) # rooms (int) surface (float m2) public trans
(boolean) Apartment 3 50 TRUE House 5 254 FALSE Duplex 4 68 TRUE Apartment 2 32 TRUE sold (float k€) 450 430 712 234 features target samples (train) Apartment 2 33 TRUE House 4 210 TRUE samples (test) ? ?
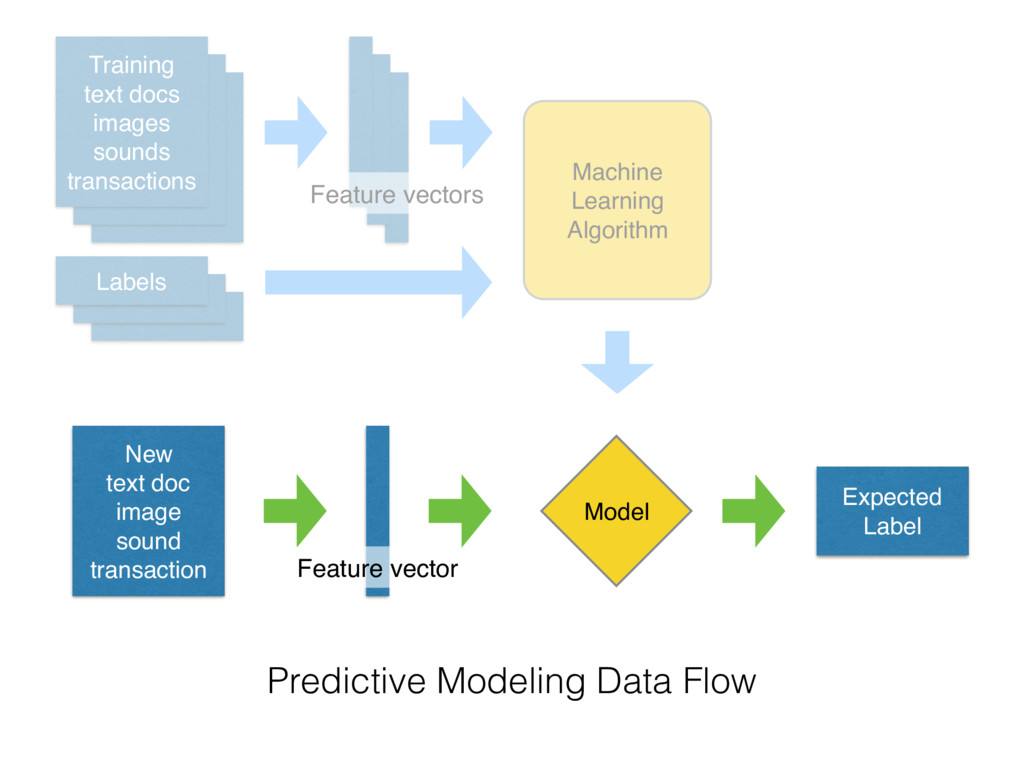
Training text docs images sounds transactions Labels Machine Learning Algorithm
Model Predictive Modeling Data Flow Feature vectors
New text doc image sound transaction Model Expected Label Predictive
Modeling Data Flow Feature vector Training text docs images sounds transactions Labels Machine Learning Algorithm Feature vectors
Inventory forecasting & trends detection Predictive modeling in the wild
Personalized radios Fraud detection Virality and readers engagement Predictive maintenance Personality matching
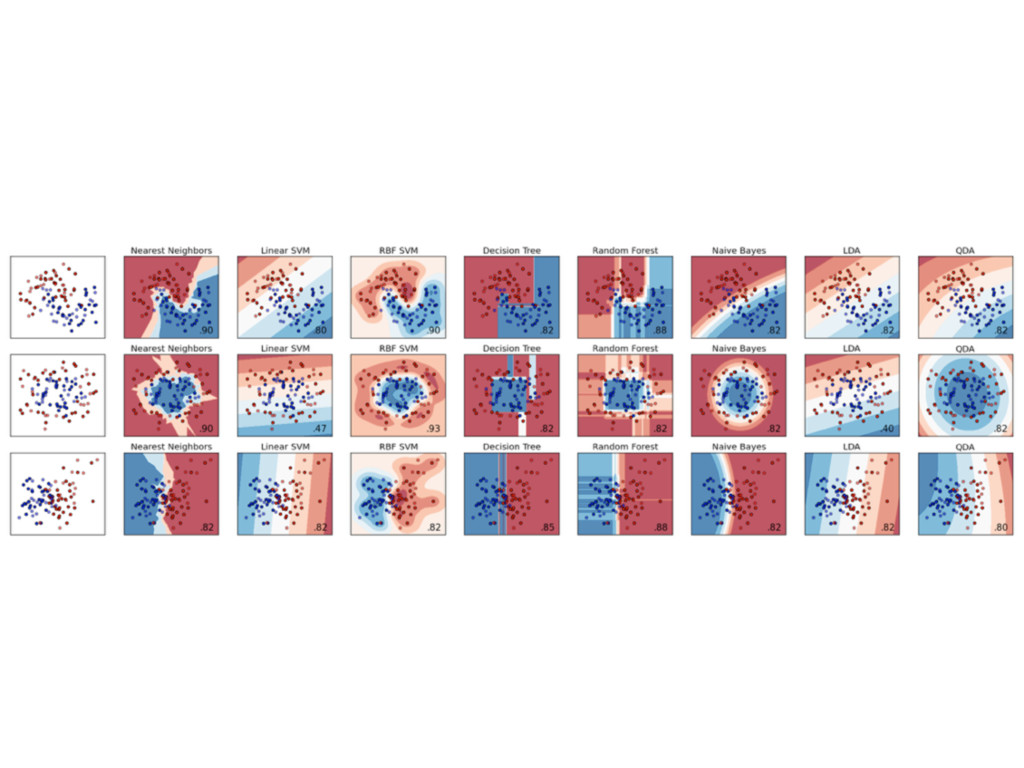
• Library of Machine Learning algorithms • Focus on established
methods (e.g. ESL-II) • Open Source (BSD) • Simple fit / predict / transform API • Python / NumPy / SciPy / Cython • Model Assessment, Selection & Ensembles
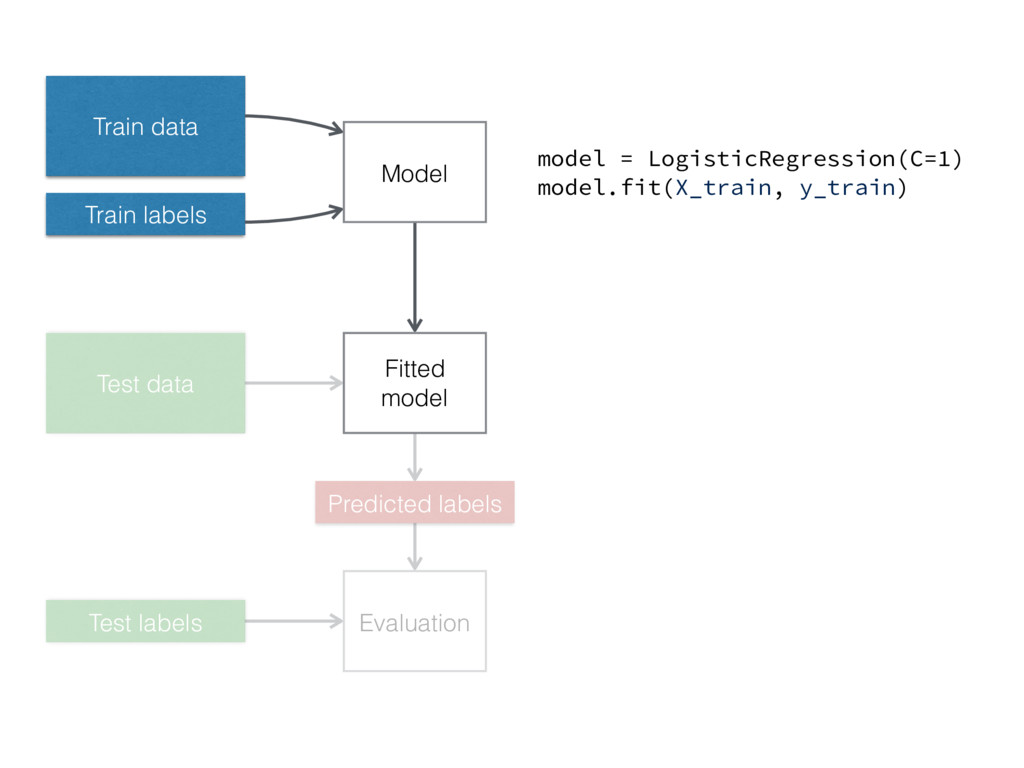
Train data Train labels Model Fitted model Test data Predicted
labels Test labels Evaluation model = LogisticRegression(C=1) model.fit(X_train, y_train)
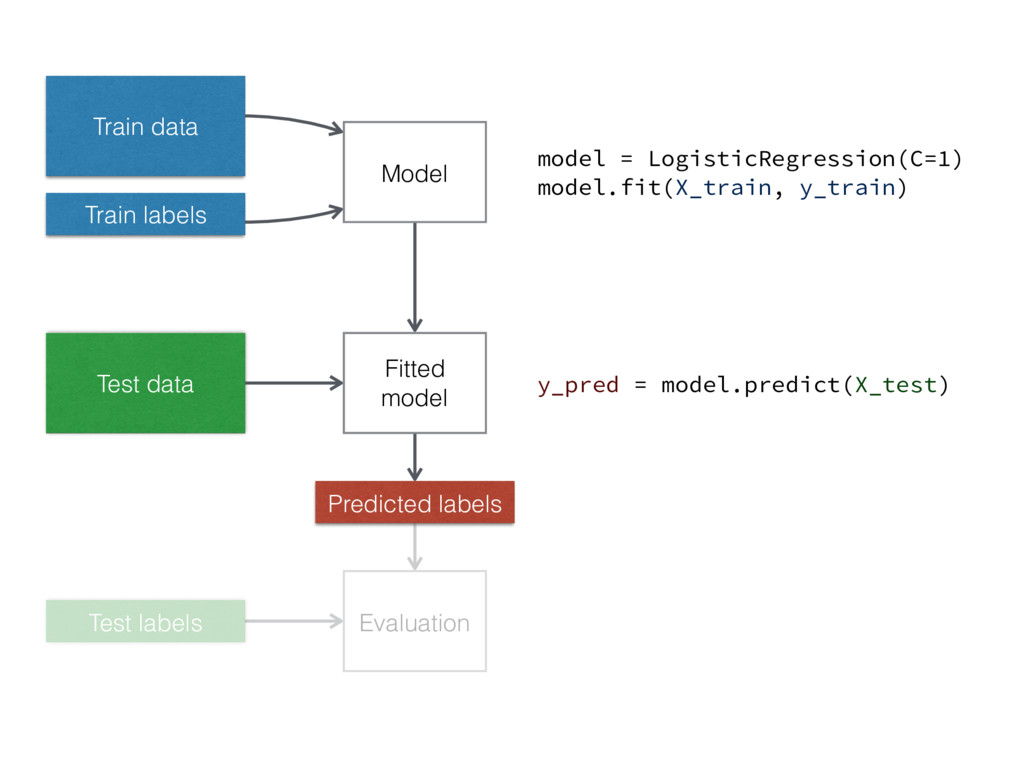
Train data Train labels Model Fitted model Test data Predicted
labels Test labels Evaluation model = LogisticRegression(C=1) model.fit(X_train, y_train) y_pred = model.predict(X_test)
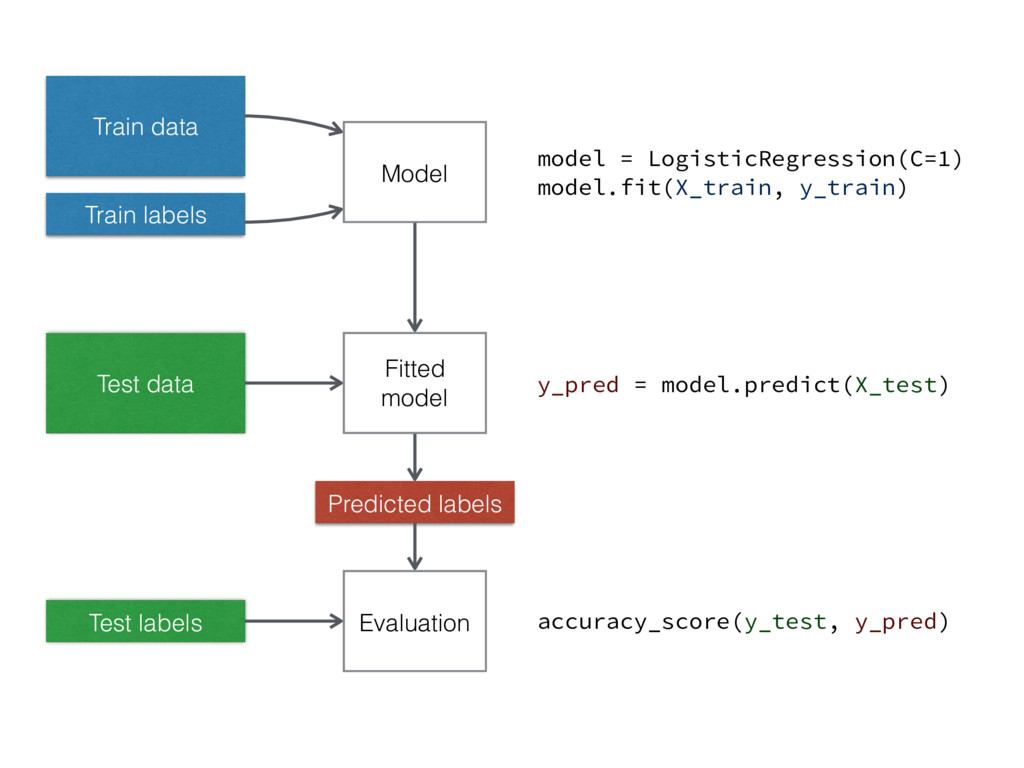
Train data Train labels Model Fitted model Test data Predicted
labels Test labels Evaluation model = LogisticRegression(C=1) model.fit(X_train, y_train) y_pred = model.predict(X_test) accuracy_score(y_test, y_pred)
Support Vector Machine from sklearn.svm import SVC model = SVC(kernel="rbf",
C=1.0, gamma=1e-4) model.fit(X_train, y_train) y_predicted = model.predict(X_test) from sklearn.metrics import f1_score f1_score(y_test, y_predicted)
Linear Classifier from sklearn.linear_model import SGDClassifier model = SGDClassifier(alpha=1e-4, penalty="elasticnet")
model.fit(X_train, y_train) y_predicted = model.predict(X_test) from sklearn.metrics import f1_score f1_score(y_test, y_predicted)
Random Forests from sklearn.ensemble import RandomForestClassifier model = RandomForestClassifier(n_estimators=200) model.fit(X_train,
y_train) y_predicted = model.predict(X_test) from sklearn.metrics import f1_score f1_score(y_test, y_predicted)
None
None
Workshop time! https://github.com/ogrisel/euroscipy_2017_sklearn
Combining Models from sklearn.preprocessing import StandardScaler from sklearn.decomposition import RandomizedPCA
from sklearn.svm import SVC scaler = StandardScaler() X_train_scaled = scaler.fit_transform(X_train) pca = RandomizedPCA(n_components=10) X_train_pca = pca.fit_transform(X_train_scaled) svm = SVC(C=0.1, gamma=1e-3) svm.fit(X_train_pca, y_train)
Pipeline from sklearn.preprocessing import StandardScaler from sklearn.decomposition import RandomizedPCA from
sklearn.svm import SVC from sklearn.pipeline import make_pipeline pipeline = make_pipeline( StandardScaler(), RandomizedPCA(n_components=10), SVC(C=0.1, gamma=1e-3), ) pipeline.fit(X_train, y_train)
Scoring manually stacked models scaler = StandardScaler() X_train_scaled = scaler.fit_transform(X_train)
pca = RandomizedPCA(n_components=10) X_train_pca = pca.fit_transform(X_train_scaled) svm = SVC(C=0.1, gamma=1e-3) svm.fit(X_train_pca, y_train) X_test_scaled = scaler.transform(X_test) X_test_pca = pca.transform(X_test_scaled) y_pred = svm.predict(X_test_pca) accuracy_score(y_test, y_pred)
Scoring a pipeline pipeline = make_pipeline( RandomizedPCA(n_components=10), SVC(C=0.1, gamma=1e-3), )
pipeline.fit(X_train, y_train) y_pred = pipeline.predict(X_test) accuracy_score(y_test, y_pred)
Parameter search import numpy as np from sklearn.grid_search import RandomizedSearchCV
params = { 'randomizedpca__n_components': [5, 10, 20], 'svc__C': np.logspace(-3, 3, 7), 'svc__gamma': np.logspace(-6, 0, 7), } search = RandomizedSearchCV(pipeline, params, n_iter=30, cv=5) search.fit(X_train, y_train) # search.best_params_, search.grid_scores_
Thank you! • http://scikit-learn.org • https://github.com/scikit-learn/scikit-learn @ogrisel
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}