Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
How to use scikit-learn to solve machine learni...
Search
Olivier Grisel
April 22, 2015
Technology
1.1k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
How to use scikit-learn to solve machine learning problems
AutoML Hackathon - Paris - April 2015
Olivier Grisel
April 22, 2015
More Decks by Olivier Grisel
See All by Olivier Grisel
Intro to scikit-learn
ogrisel
5
750
An Intro to Deep Learning
ogrisel
1
340
Predictive Modeling and Deep Learning
ogrisel
2
400
Intro to scikit-learn and what's new in 0.17
ogrisel
1
420
Big Data, Predictive Modeling and tools
ogrisel
2
350
Recent Developments in Deep Learning
ogrisel
3
730
Documentation
ogrisel
2
280
Build and test wheel packages on Linux, OSX and Windows
ogrisel
2
370
Big Data and Predictive Modeling
ogrisel
3
260
Other Decks in Technology
See All in Technology
AI驚き屋発見器
yama3133
1
380
AI駆動開発は個人技からチーム戦へ:組織でAIを使いこなすための実践設計
moongift
PRO
0
290
ここは地獄!つらい朝会を体験することで、チームとしてのより良い振る舞いに気づくワークショップ / The stand-up meeting from hell in the game industry
scrummasudar
0
440
AI研修(Day2)【MIXI 26新卒技術研修】
mixi_engineers
PRO
2
1.5k
システム監視入門
grimoh
5
760
plamo-3-translateの開発
pfn
PRO
0
180
最新IoT事例11選に学ぶ!現場の成功パターンと実践のコツ【SORACOM Discovery 2026】
soracom
PRO
0
120
システム監視を 「システムを監視するだけ」で 終わらせないために
seiud
0
150
データエンジニアこそ組織のオントロジーに向き合うべき — 問いに答えるAIから、事業を動かすAIへ
gappy50
4
2.3k
害獣害虫を自動判別! ペストコントロール支援ビジネス成功のヒント【SORACOM Discovery 2026】
soracom
PRO
0
130
現場をAIで動かす「フィジカル AI」の組み込み設計の考え方【SORACOM Discovery 2026】
soracom
PRO
0
150
歴史から理解するクラウドインフラのしくみ
kizawa2020
0
190
Featured
See All Featured
Ruling the World: When Life Gets Gamed
codingconduct
0
290
My Coaching Mixtape
mlcsv
0
180
Optimizing for Happiness
mojombo
378
71k
Fashionably flexible responsive web design (full day workshop)
malarkey
408
67k
Introduction to Domain-Driven Design and Collaborative software design
baasie
1
920
We Have a Design System, Now What?
morganepeng
55
8.2k
Distributed Sagas: A Protocol for Coordinating Microservices
caitiem20
333
23k
HDC tutorial
michielstock
2
760
How to Talk to Developers About Accessibility
jct
2
450
Amusing Abliteration
ianozsvald
1
240
Easily Structure & Communicate Ideas using Wireframe
afnizarnur
194
17k
The Pragmatic Product Professional
lauravandoore
37
7.4k
Transcript
How to use scikit-learn to solve machine learning problems AutoML
Hackathon April 2015
Outline • Machine Learning refresher • scikit-learn • Demo: interactive
predictive modeling on Census Data with IPython notebook / pandas / scikit-learn • Combining models with Pipeline and parameter search
Predictive modeling ~= machine learning • Make predictions of outcome
on new data • Extract the structure of historical data • Statistical tools to summarize the training data into a executable predictive model • Alternative to hard-coded rules written by experts
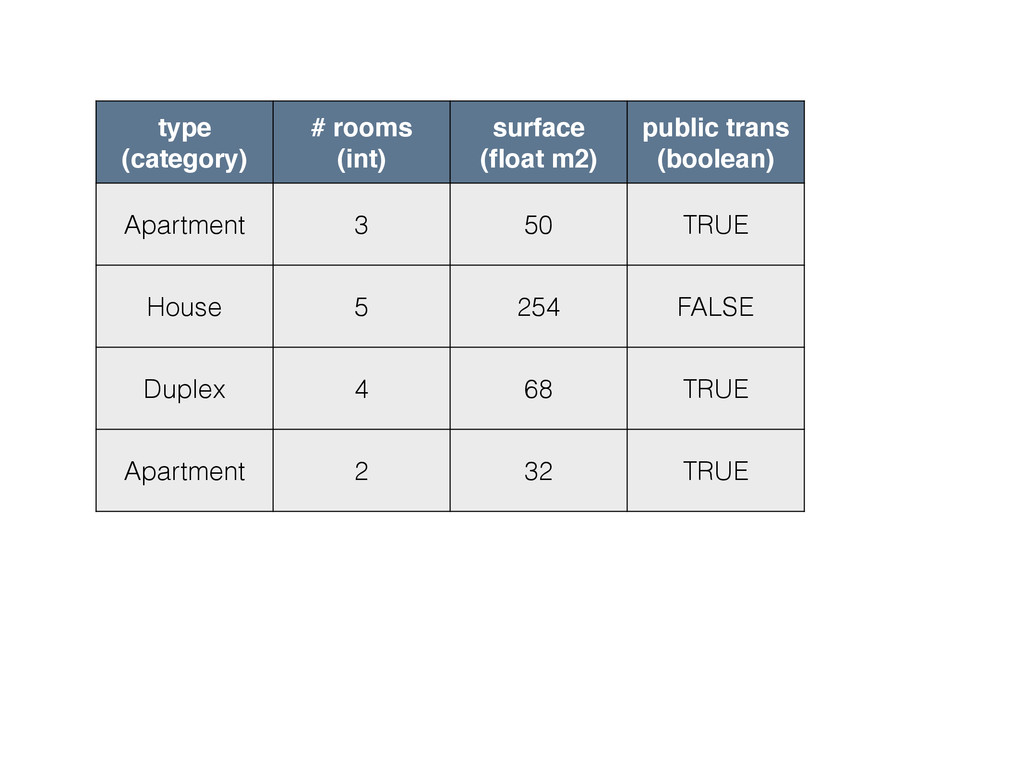
type (category) # rooms (int) surface (float m2) public trans
(boolean) Apartment 3 50 TRUE House 5 254 FALSE Duplex 4 68 TRUE Apartment 2 32 TRUE
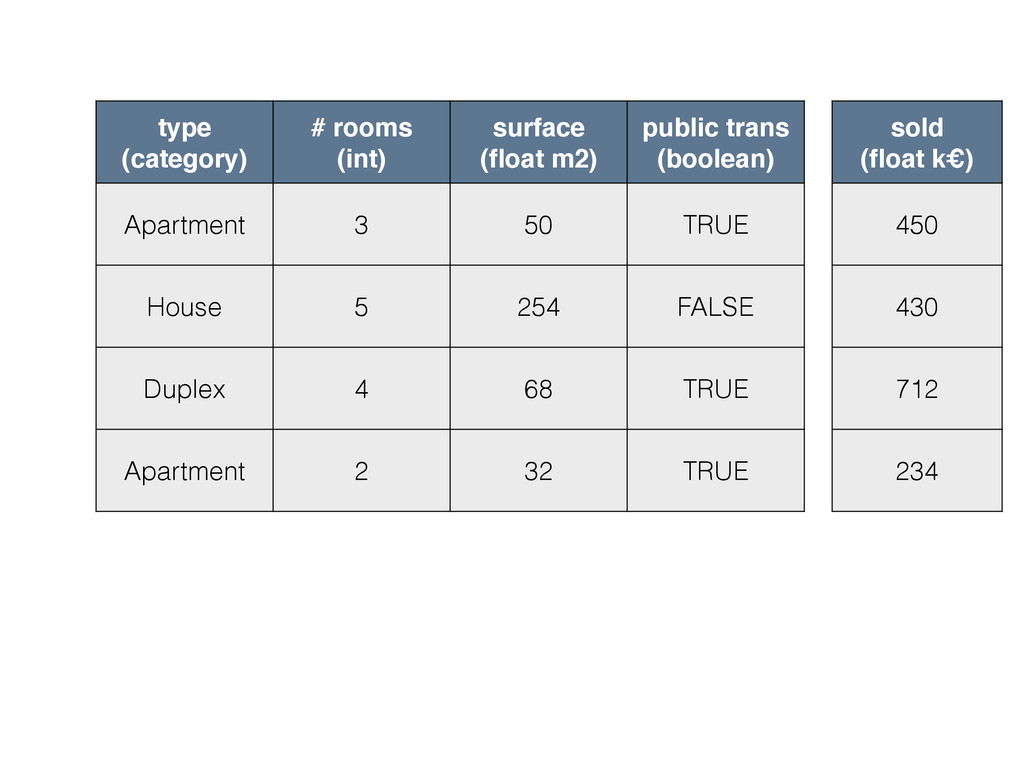
type (category) # rooms (int) surface (float m2) public trans
(boolean) Apartment 3 50 TRUE House 5 254 FALSE Duplex 4 68 TRUE Apartment 2 32 TRUE sold (float k€) 450 430 712 234
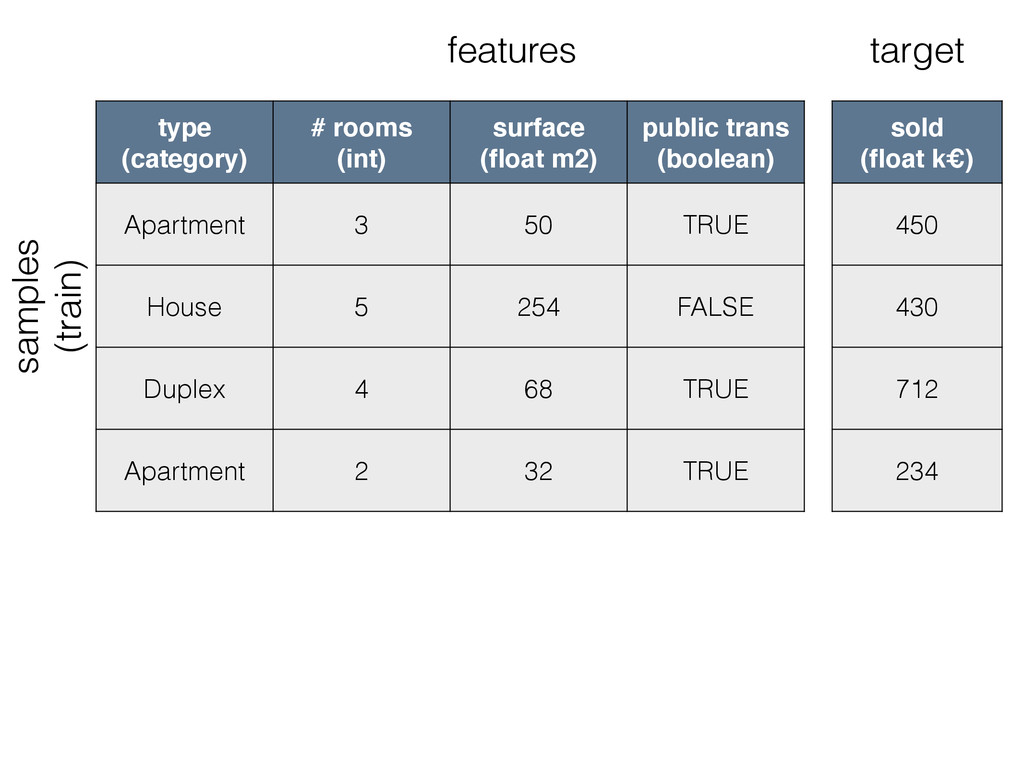
type (category) # rooms (int) surface (float m2) public trans
(boolean) Apartment 3 50 TRUE House 5 254 FALSE Duplex 4 68 TRUE Apartment 2 32 TRUE sold (float k€) 450 430 712 234 features target samples (train)
type (category) # rooms (int) surface (float m2) public trans
(boolean) Apartment 3 50 TRUE House 5 254 FALSE Duplex 4 68 TRUE Apartment 2 32 TRUE sold (float k€) 450 430 712 234 features target samples (train) Apartment 2 33 TRUE House 4 210 TRUE samples (test) ? ?
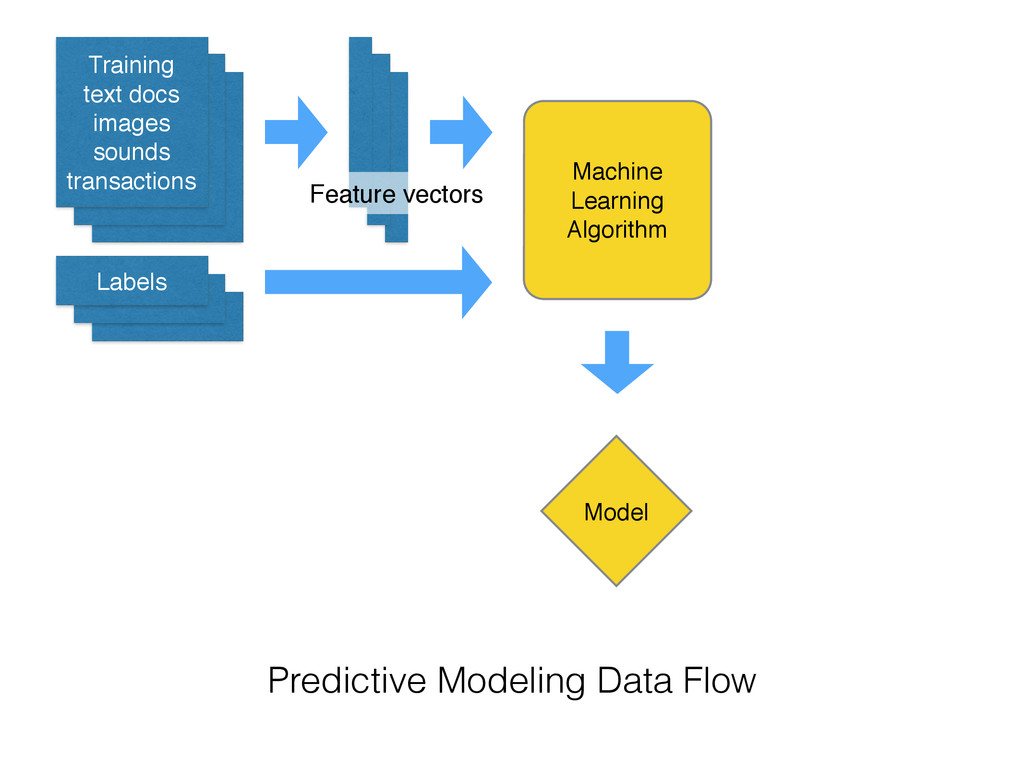
Training text docs images sounds transactions Labels Machine Learning Algorithm
Model Predictive Modeling Data Flow Feature vectors
New text doc image sound transaction Model Expected Label Predictive
Modeling Data Flow Feature vector Training text docs images sounds transactions Labels Machine Learning Algorithm Feature vectors
Inventory forecasting & trends detection Predictive modeling in the wild
Personalized radios Fraud detection Virality and readers engagement Predictive maintenance Personality matching
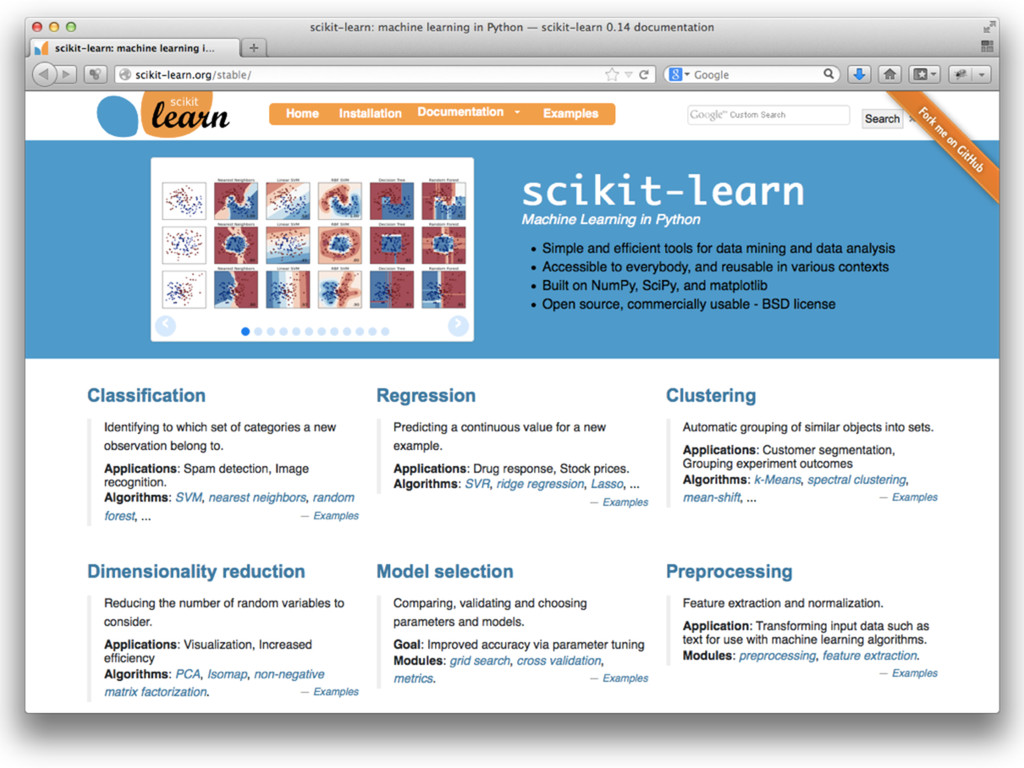
• Library of Machine Learning algorithms • Focus on established
methods (e.g. ESL-II) • Open Source (BSD) • Simple fit / predict / transform API • Python / NumPy / SciPy / Cython • Model Assessment, Selection & Ensembles
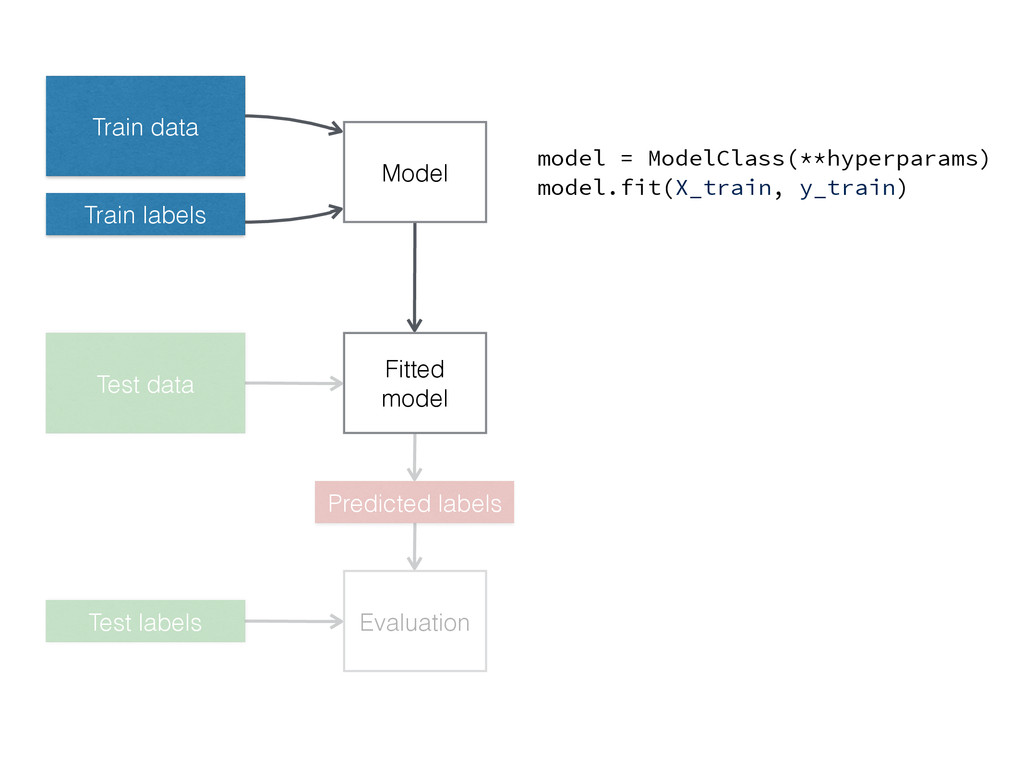
Train data Train labels Model Fitted model Test data Predicted
labels Test labels Evaluation model = ModelClass(**hyperparams) model.fit(X_train, y_train)
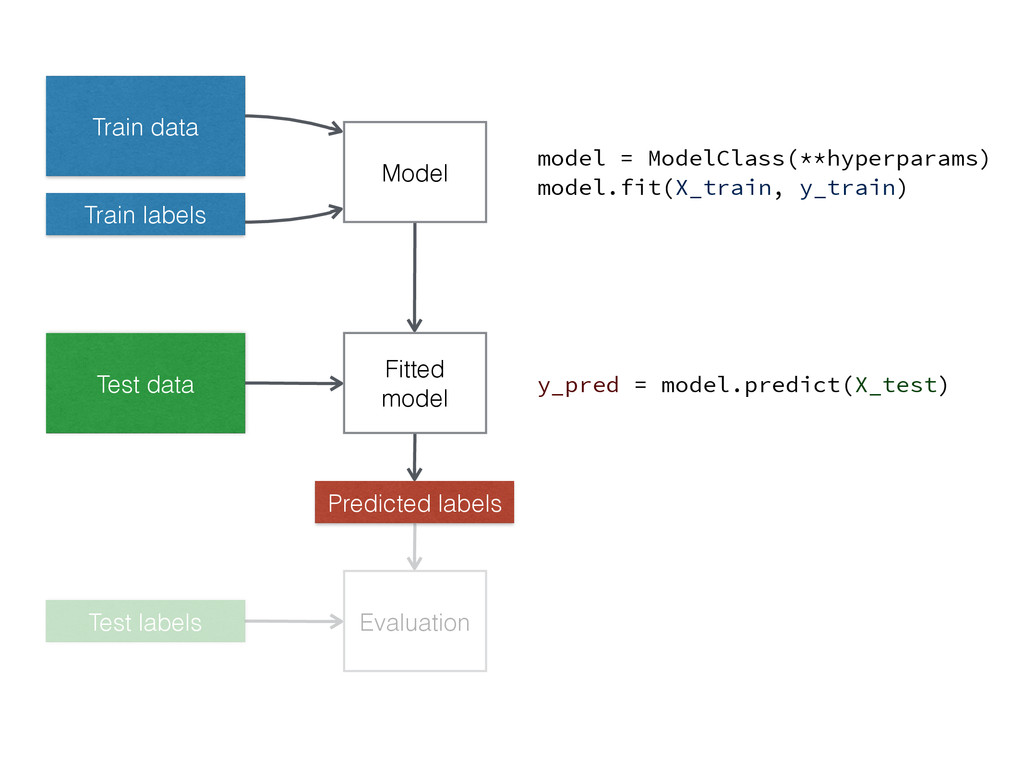
Train data Train labels Model Fitted model Test data Predicted
labels Test labels Evaluation model = ModelClass(**hyperparams) model.fit(X_train, y_train) y_pred = model.predict(X_test)
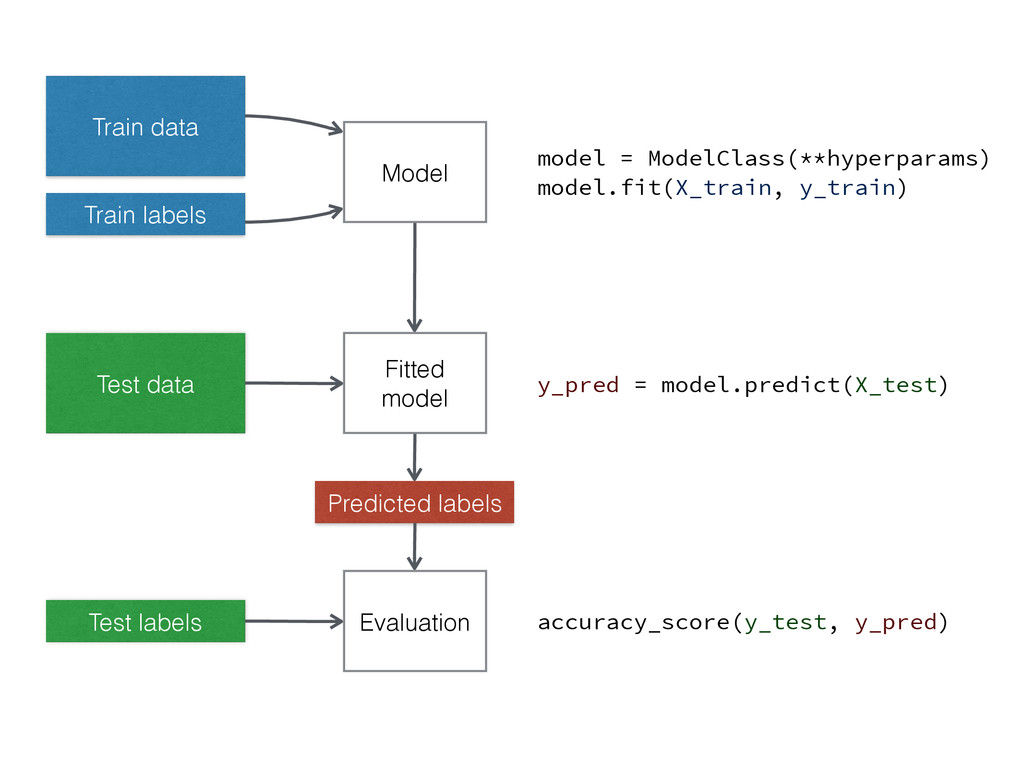
Train data Train labels Model Fitted model Test data Predicted
labels Test labels Evaluation model = ModelClass(**hyperparams) model.fit(X_train, y_train) y_pred = model.predict(X_test) accuracy_score(y_test, y_pred)
Support Vector Machine from sklearn.svm import SVC model = SVC(kernel="rbf",
C=1.0, gamma=1e-4) model.fit(X_train, y_train) y_predicted = model.predict(X_test) from sklearn.metrics import f1_score f1_score(y_test, y_predicted)
Linear Classifier from sklearn.linear_model import SGDClassifier model = SGDClassifier(alpha=1e-4, penalty="elasticnet")
model.fit(X_train, y_train) y_predicted = model.predict(X_test) from sklearn.metrics import f1_score f1_score(y_test, y_predicted)
Random Forests from sklearn.ensemble import RandomForestClassifier model = RandomForestClassifier(n_estimators=200) model.fit(X_train,
y_train) y_predicted = model.predict(X_test) from sklearn.metrics import f1_score f1_score(y_test, y_predicted)
None
None
Demo time! http://nbviewer.ipython.org/github/ogrisel/notebooks/blob/ master/sklearn_demos/Income%20classification.ipynb https://github.com/ogrisel/notebooks
Combining Models from sklearn.preprocessing import StandardScaler from sklearn.decomposition import RandomizedPCA
from sklearn.svm import SVC scaler = StandardScaler() X_train_scaled = scaler.fit_transform(X_train) pca = RandomizedPCA(n_components=10) X_train_pca = pca.fit_transform(X_train_scaled) svm = SVC(C=0.1, gamma=1e-3) svm.fit(X_train_pca, y_train)
Pipeline from sklearn.preprocessing import StandardScaler from sklearn.decomposition import RandomizedPCA from
sklearn.svm import SVC from sklearn.pipeline import make_pipeline pipeline = make_pipeline( StandardScaler(), RandomizedPCA(n_components=10), SVC(C=0.1, gamma=1e-3), ) pipeline.fit(X_train, y_train)
Scoring manually stacked models scaler = StandardScaler() X_train_scaled = scaler.fit_transform(X_train)
pca = RandomizedPCA(n_components=10) X_train_pca = pca.fit_transform(X_train_scaled) svm = SVC(C=0.1, gamma=1e-3) svm.fit(X_train_pca, y_train) X_test_scaled = scaler.transform(X_test) X_test_pca = pca.transform(X_test_scaled) y_pred = svm.predict(X_test_pca) accuracy_score(y_test, y_pred)
Scoring a pipeline pipeline = make_pipeline( RandomizedPCA(n_components=10), SVC(C=0.1, gamma=1e-3), )
pipeline.fit(X_train, y_train) y_pred = pipeline.predict(X_test) accuracy_score(y_test, y_pred)
Parameter search import numpy as np from sklearn.grid_search import RandomizedSearchCV
params = { 'randomizedpca__n_components': [5, 10, 20], 'svc__C': np.logspace(-3, 3, 7), 'svc__gamma': np.logspace(-6, 0, 7), } search = RandomizedSearchCV(pipeline, params, n_iter=30, cv=5) search.fit(X_train, y_train) # search.best_params_, search.grid_scores_
Thank you! • http://scikit-learn.org • https://github.com/scikit-learn/scikit-learn @ogrisel
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}