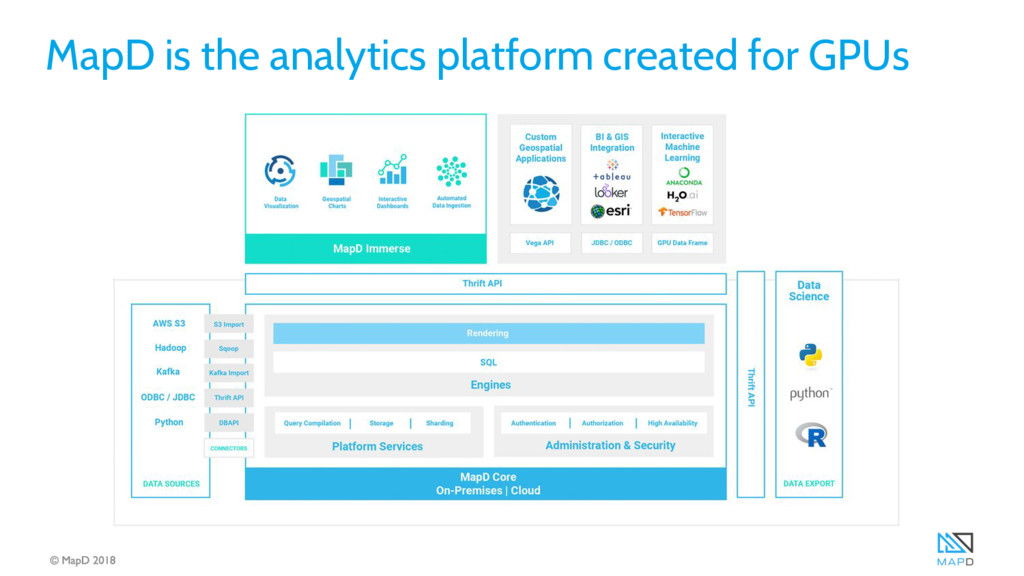
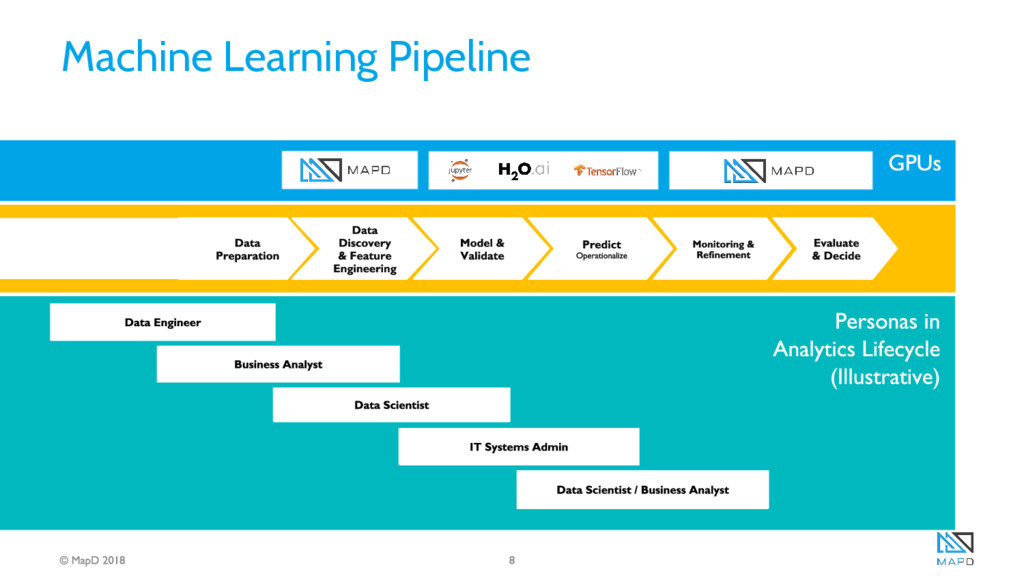
Use of the humble GPU has spiked over the past couple years as machine learning and data analytics workloads have been optimized to take advantage of the GPU’s parallelism and memory bandwidth. Even though these operations (the steps of the Machine Learning Pipeline) could all be run on the same GPUs, they were typically isolated, and much slower than they needed to be, because data was serialized and deserialized between the steps over PCIe.
That inefficiency was recently addressed by the formation of the GPU Open Analytics Initiative (GOAI http://gpuopenanalytics.com/), an industry standard founded by MapD, H2O.ai and Anaconda. This group created the GPU data frame (GDF), based on Apache Arrow, for passing data between processes and keeping it all in the GPU.
In this talk, Aaron will explain how the GDF technology works, show how it is enabling a diverse set of GPU workloads, and demonstrate how to use a Jupyter Notebook to take advantage of it. We’ll demonstrate on a very large dataset how to manage a full Machine Learning Pipeline with minimal data exchange overhead between MapD’s SQL engine and H2O’s generalized linear model library (GLM).
https://www.eventbrite.com/e/jupyter-pop-up-tickets-42550005211
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}