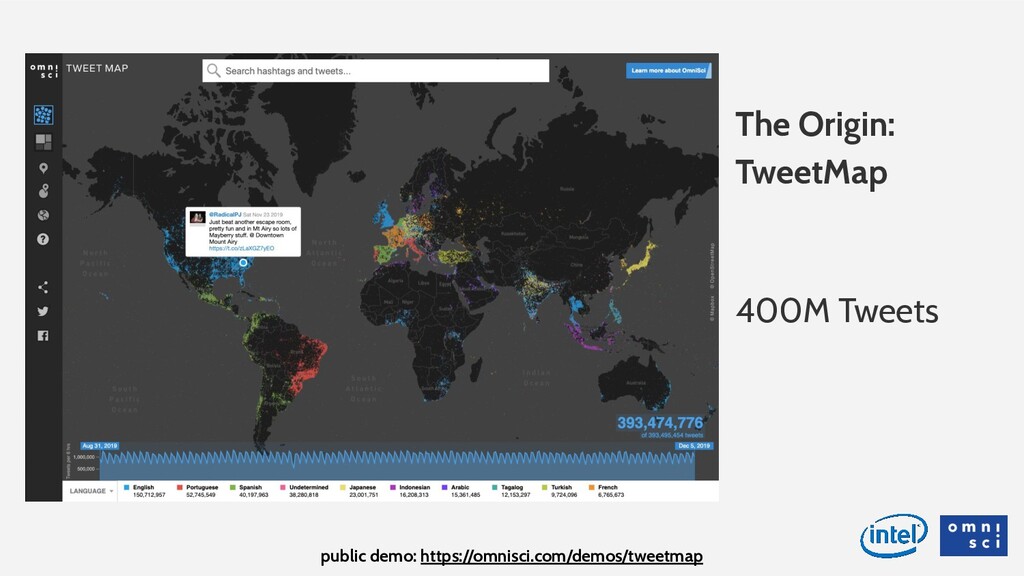
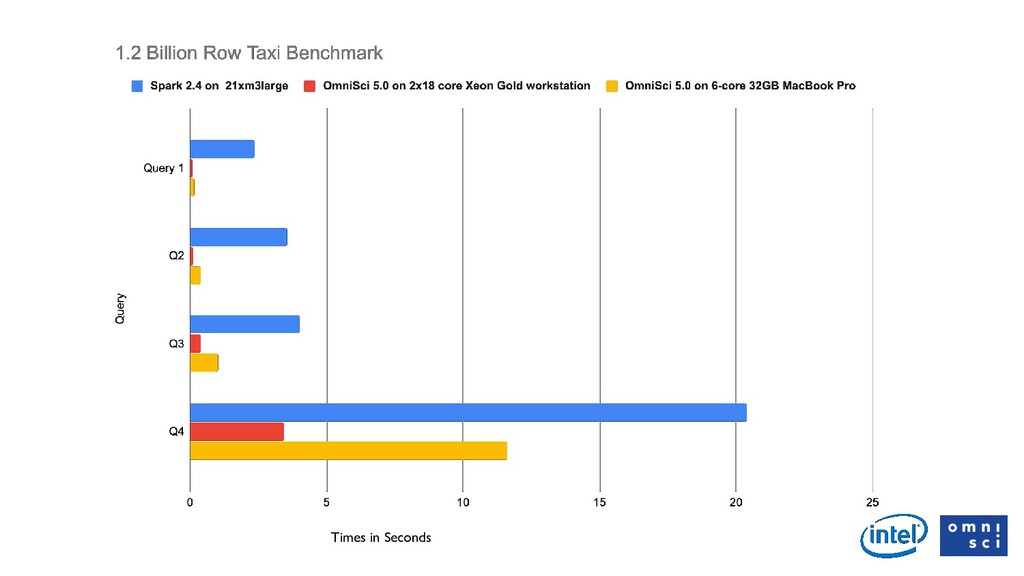
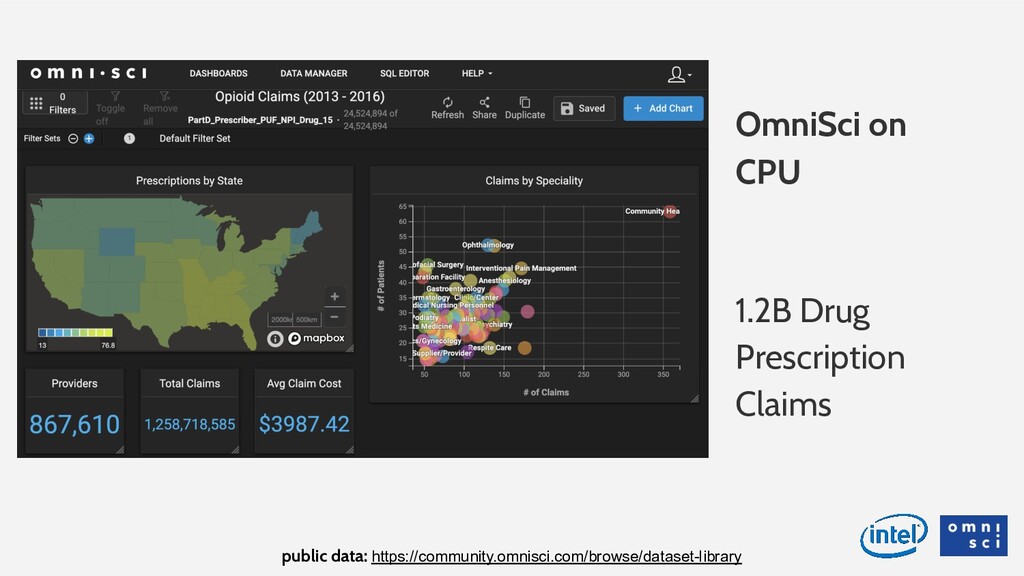
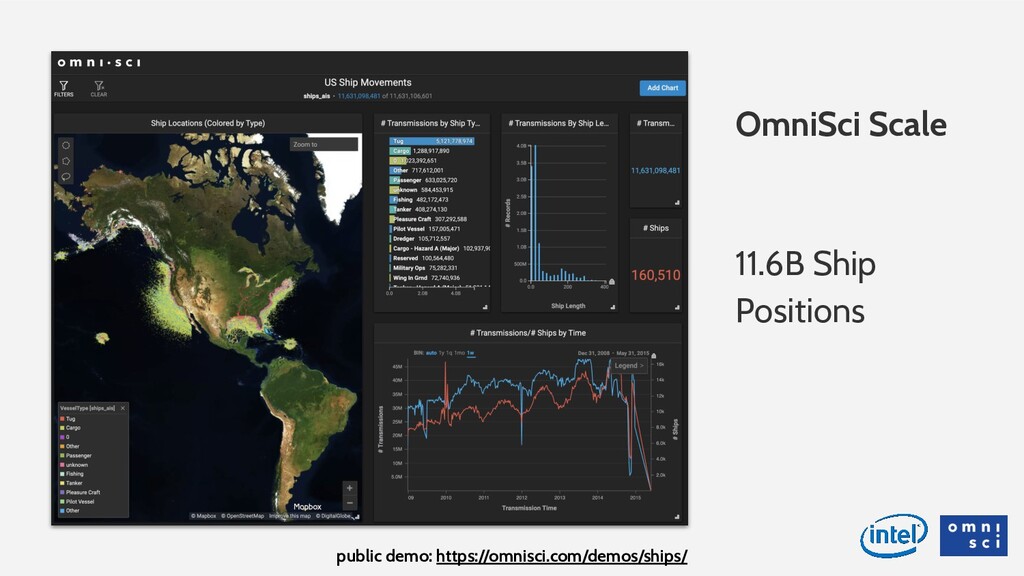
Data analytics is fundamentally changing: millions of rows are becoming billions of rows (either through more fine-grained collection, or through mash-ups with relevant, third-party data), and geospatial and time series data types are becoming more commonplace. On top of these technical challenges, analysts are also being pushed to make more effective, data-driven decisions in real time, with their data. The shift last decade from legacy databases to in-memory databases helped, but the speed and scale of traditional solutions has not kept pace with these challenges, and the lagging user experience costs time and money for companies that are increasingly data rich but insight poor. In this talk we’ll look at a way to classify this new category of big, visual, interactive data, and look at how OmniSci leverages the fastest hardware (fast memory, fast parallel processing) to run SQL queries hundreds of times faster than traditional tools. We will demonstrate a 10B row dataset, that can be queried in less than 300 milliseconds without any indexing or aggregation of the data.
{kind=link}
![@_arw_ [email protected] /in/aaronwilliams/ /williamsaaron slides: https://speakerdeck.com/omnisci Aaron Williams VP, Global](https://files.speakerdeck.com/presentations/ad997e7e241e45c4b99349b4102f8939/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
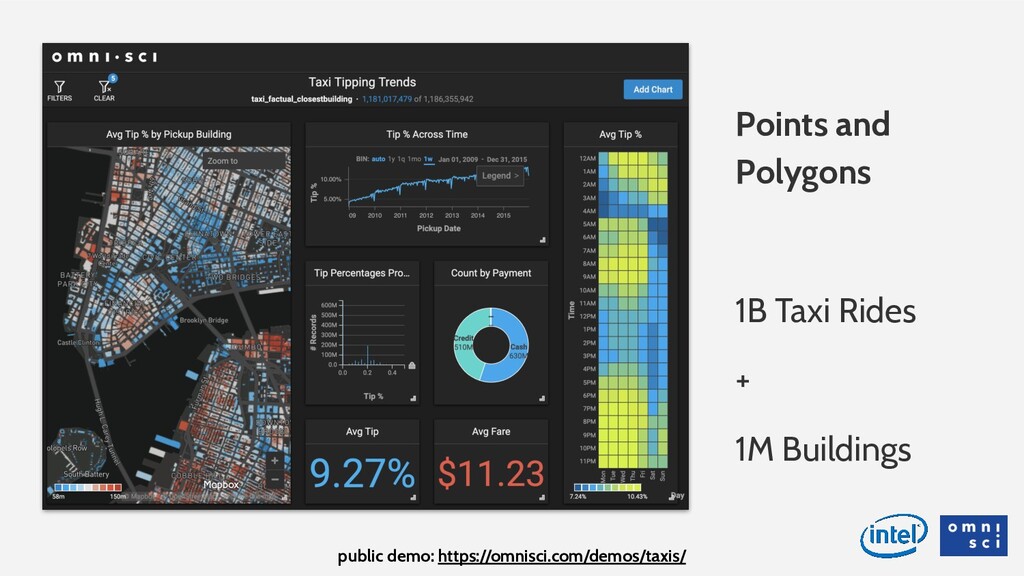{kind=link}
{kind=link}
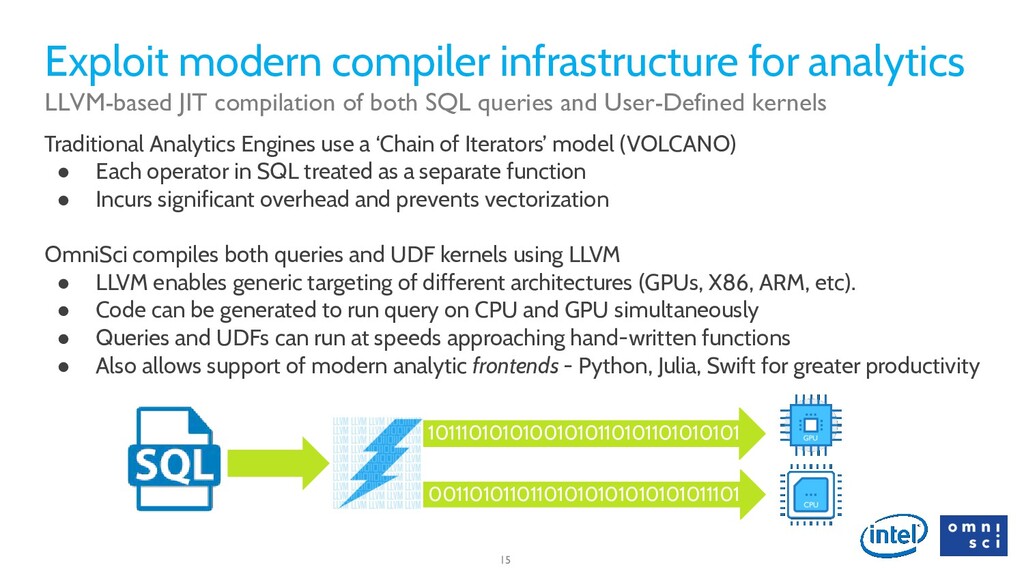{kind=link}
{kind=link}
{kind=link}
![© OmniSci 2018 @_arw_ [email protected] /in/aaronwilliams/ /williamsaaron slides: https://speakerdeck.com/omnisci Aaron](https://files.speakerdeck.com/presentations/ad997e7e241e45c4b99349b4102f8939/slide_17.jpg){kind=link}