Community Day Keynote & Hackathon Kickoff
Speaker: Aaron Williams, VP of Global Community, OmniSci
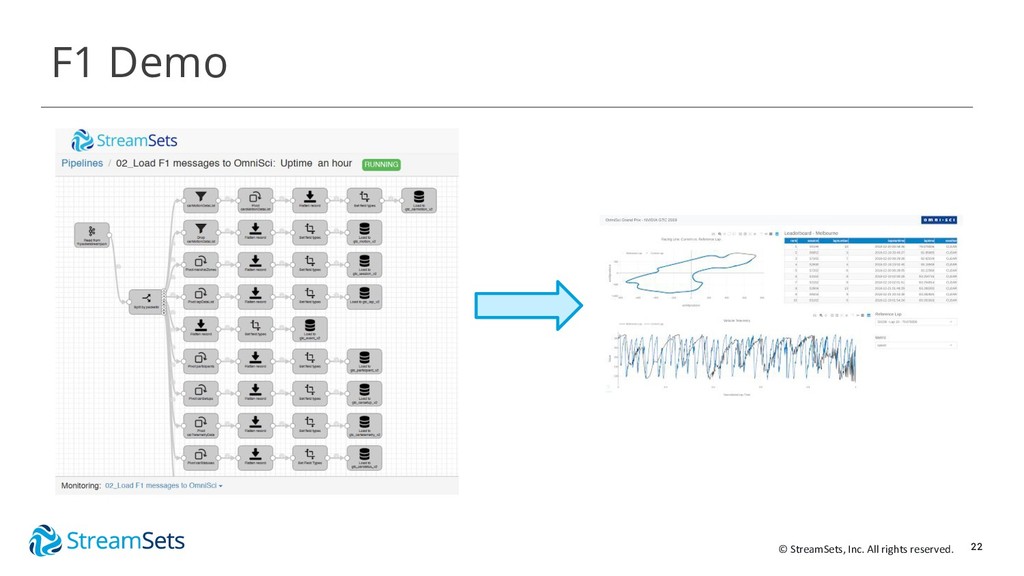
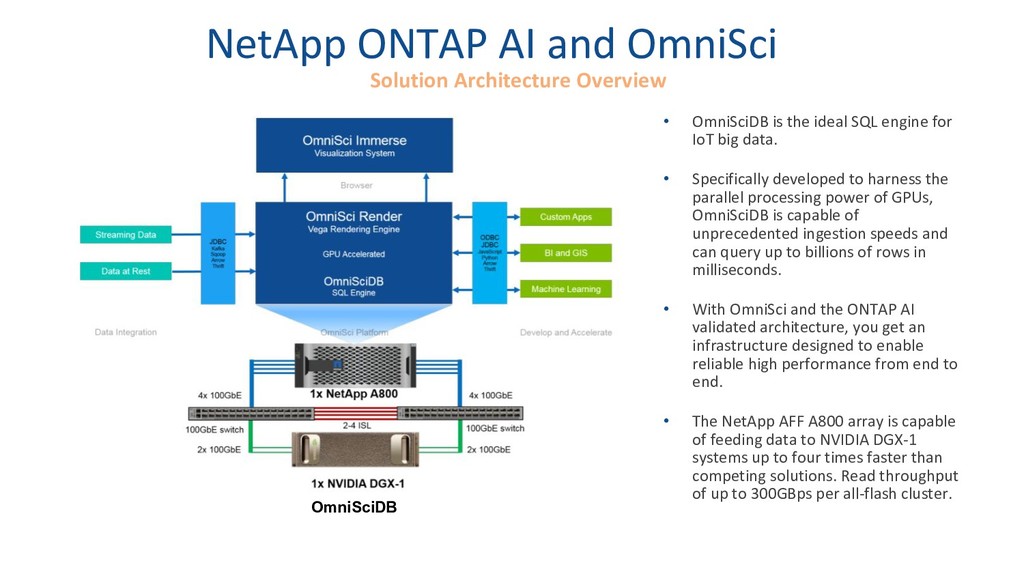
Lightning Talk: IoT Data Integration with StreamSets for Analytics in OmniSci
Speaker: Pat Patterson, Director of Evangelism, StreamSets
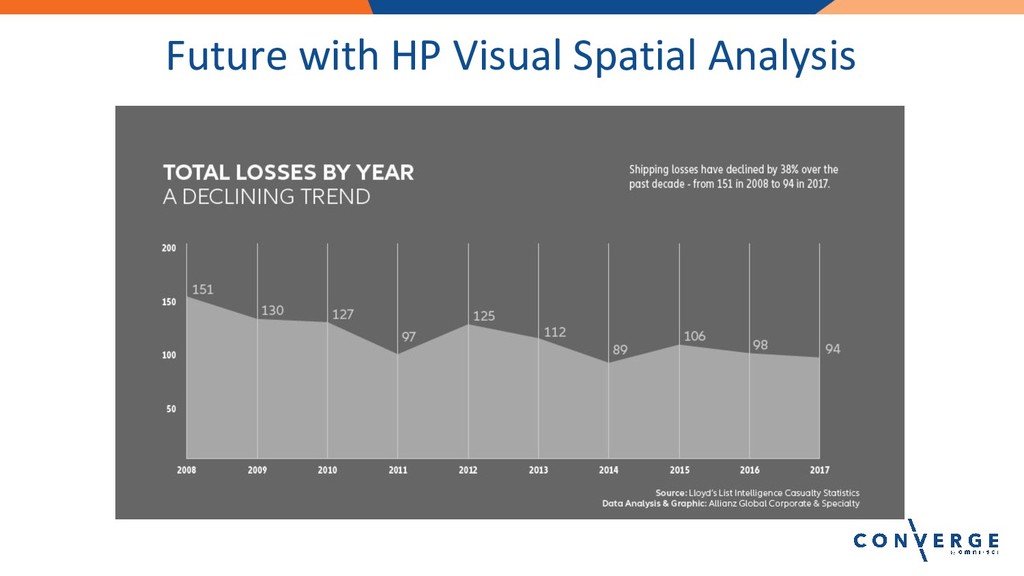
Lightning Talk: Real-time Automatic Identification System (AIS) Data Analytics
Speaker: Umesh Gupta, PhD Student, NC State University
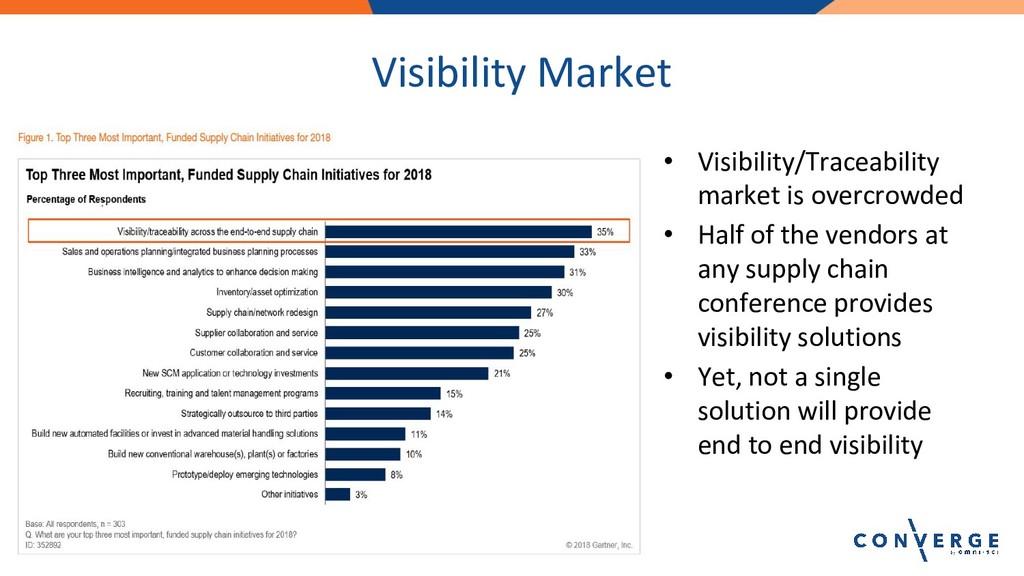
Lightning Talk: Leveraging Data and Analytics to Custom Fit Retail Logistics
Speaker: Madhav Sadhu, Senior IT Director, Tailored Brands
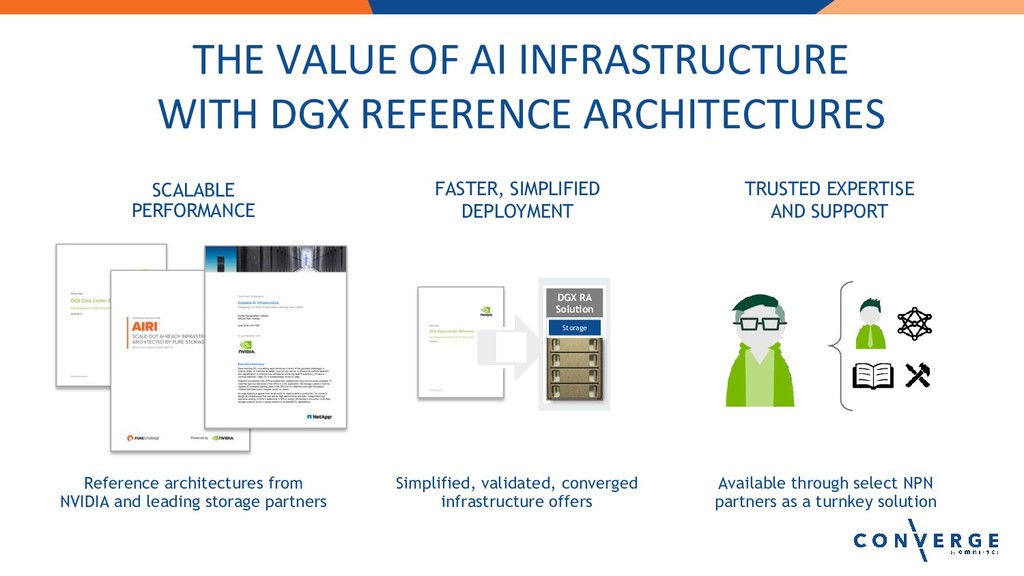
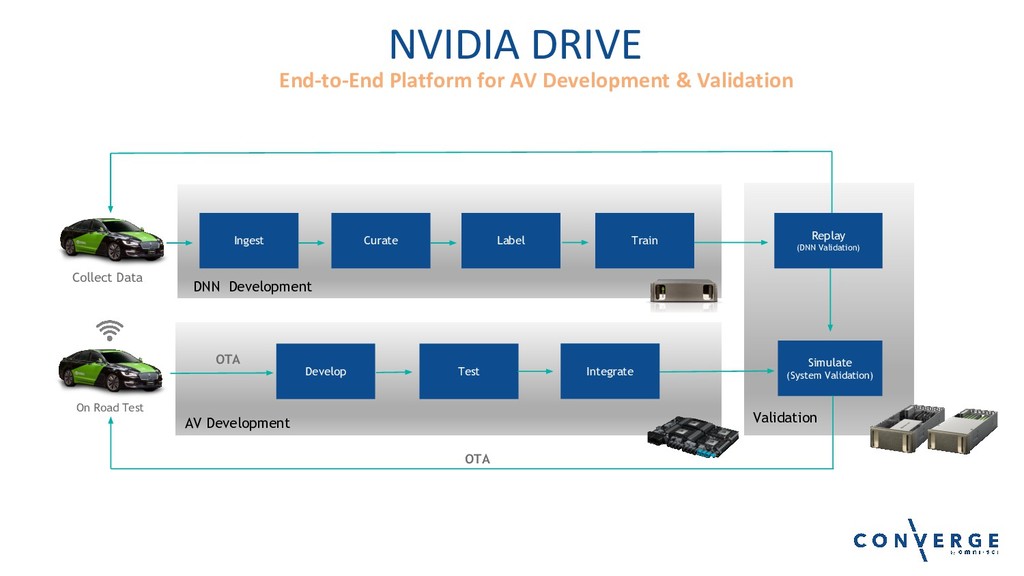
Lightning Talk: AI-Ready Building Blocks for Deep-learning Based Accelerated Workflow and Data Curation
Speaker: Jacci Cenci, Sr. Technical Marketing Engineer, NVIDIA
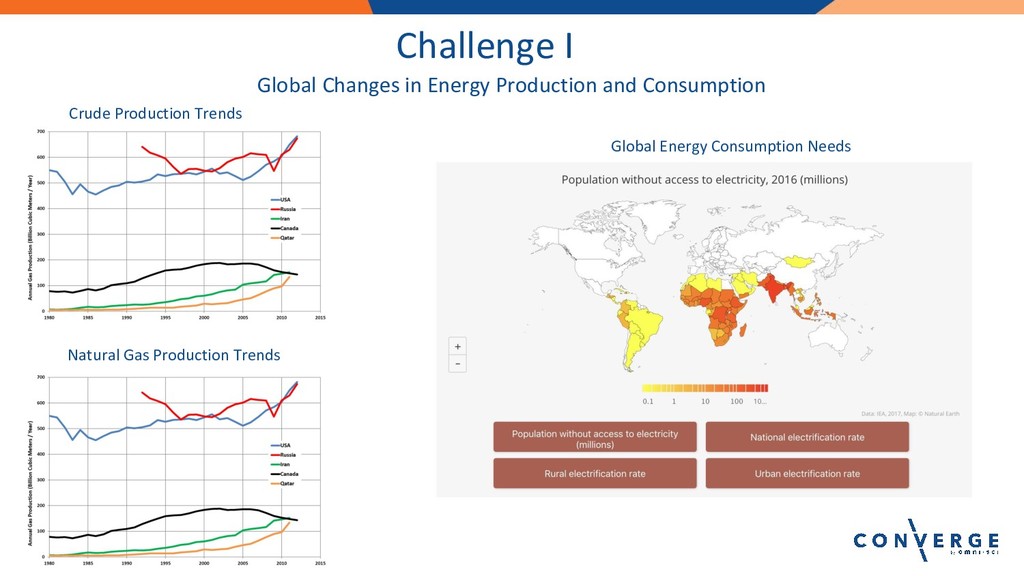
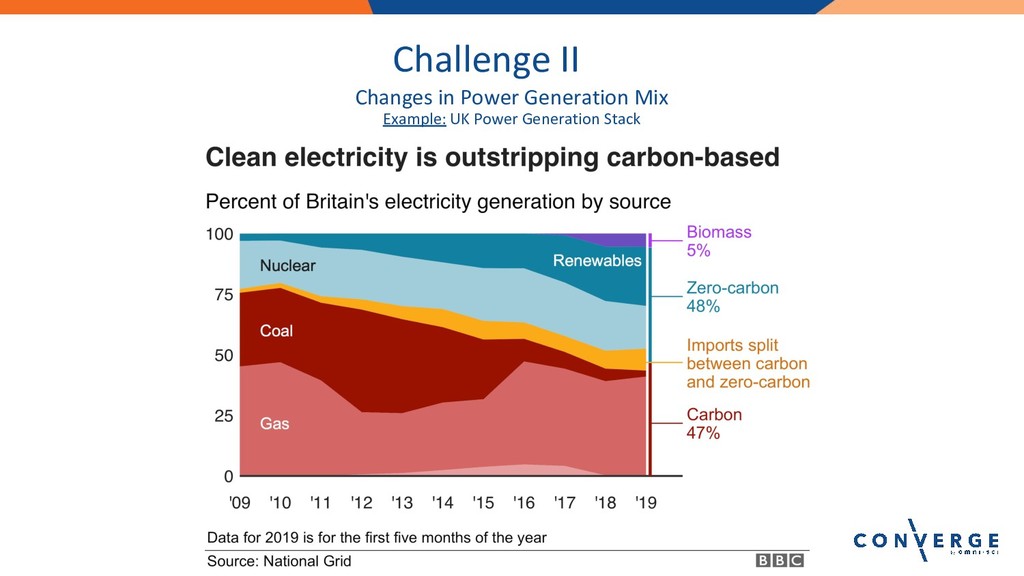
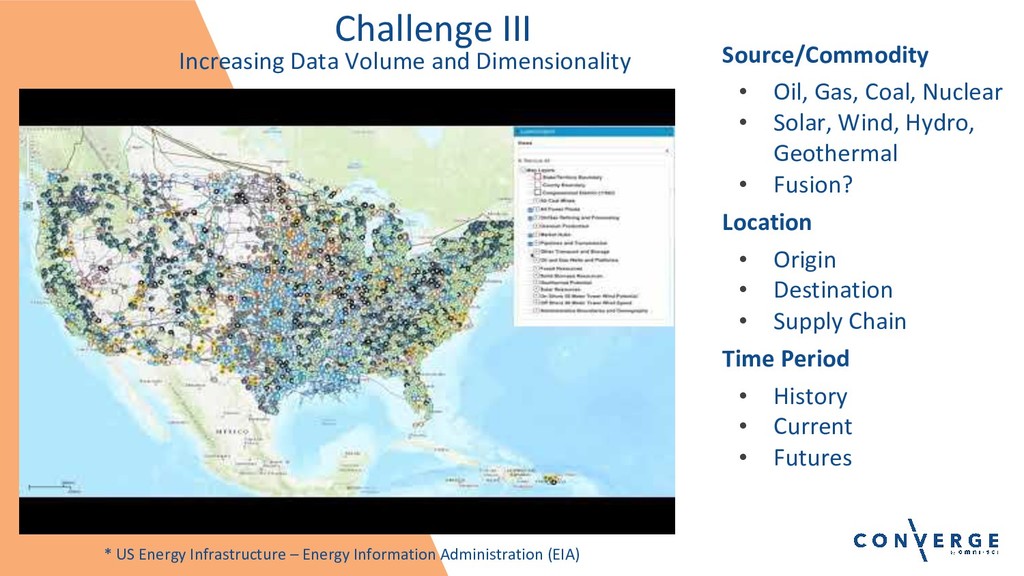
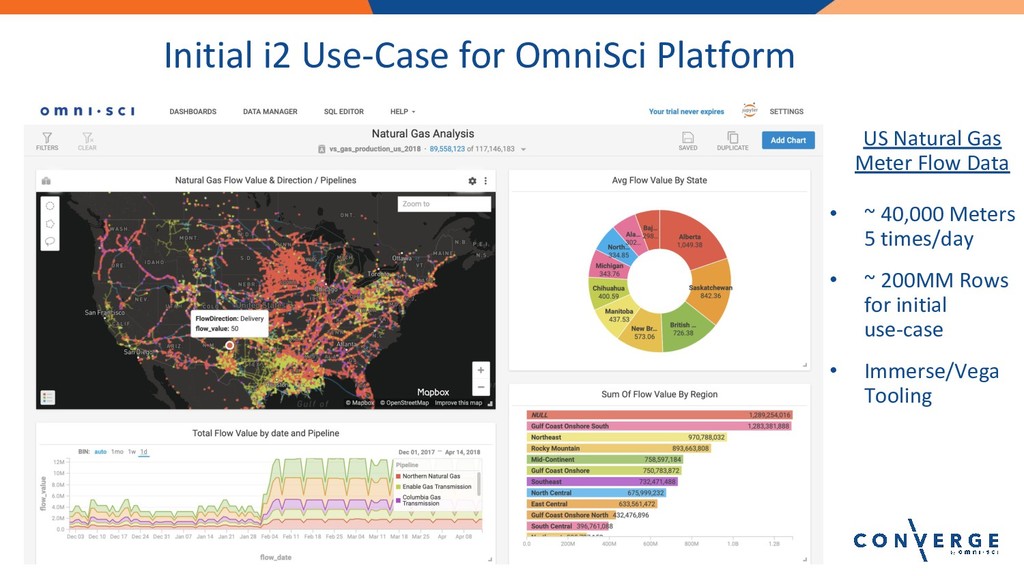
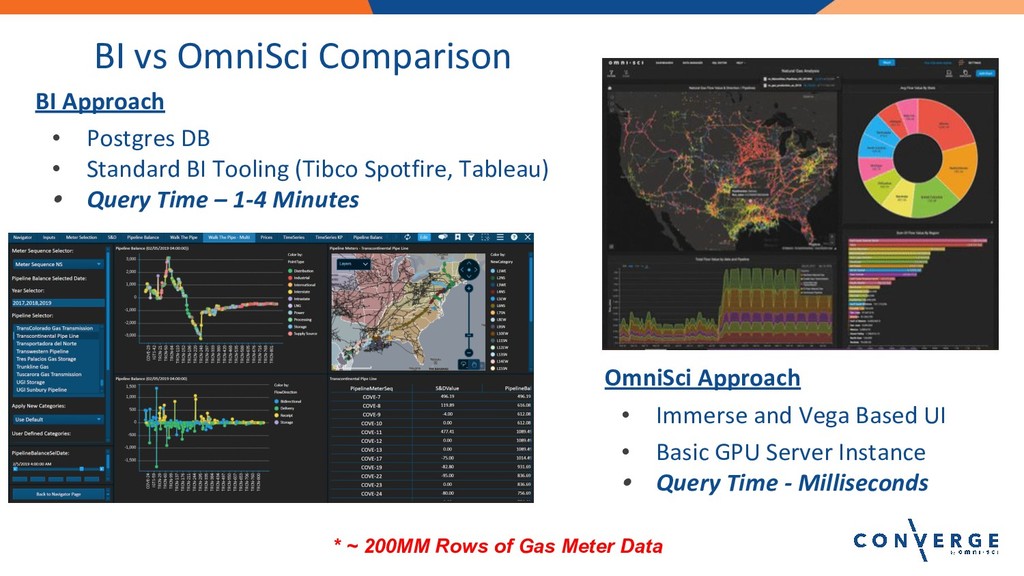
Lightning Talk: The Future of Energy Market Analytics with OmniSci
Speaker: Alan Lipe, Principal, i2enabled, Inc.
{kind=link}
![Aaron Williams VP, Global Community @_arw_ #OmniSciConverge [email protected] /in/aaronwilliams/ /williamsaaron](https://files.speakerdeck.com/presentations/805f407ad71c416aba89b6e8eeaee257/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Pat Patterson Director of Evangelism [email protected] @metadaddy IoT Data Integration](https://files.speakerdeck.com/presentations/805f407ad71c416aba89b6e8eeaee257/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
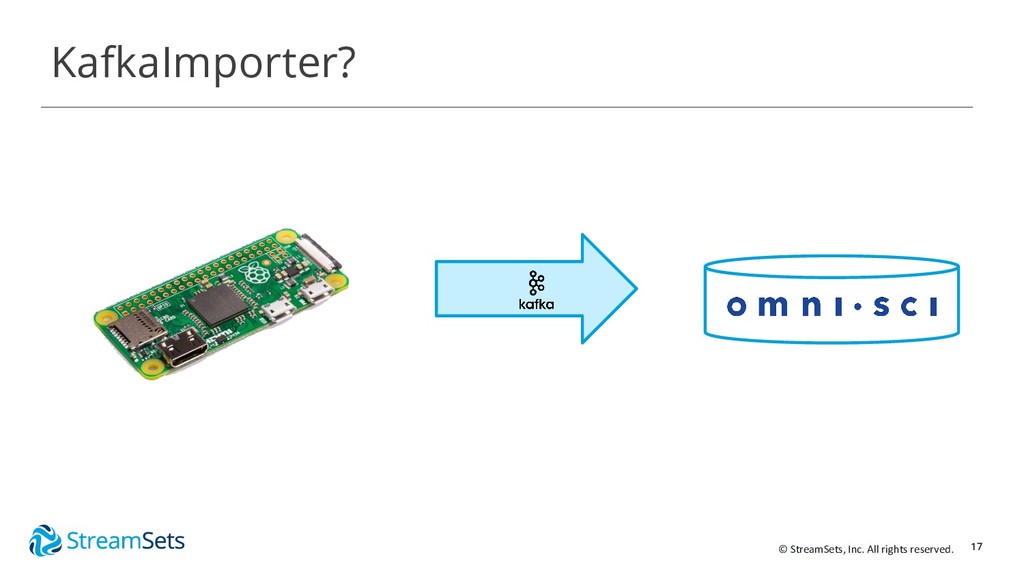{kind=link}
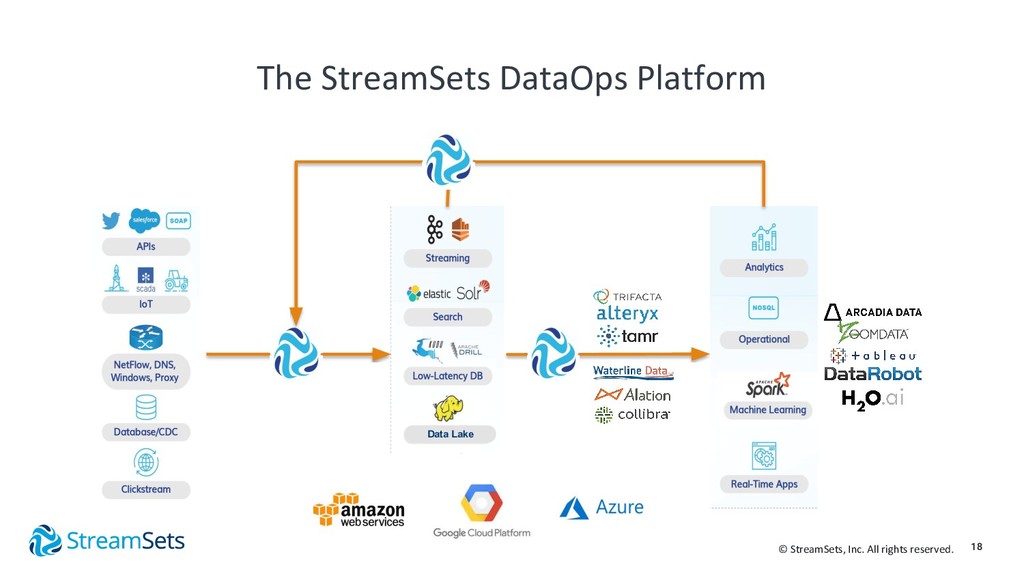{kind=link}
{kind=link}
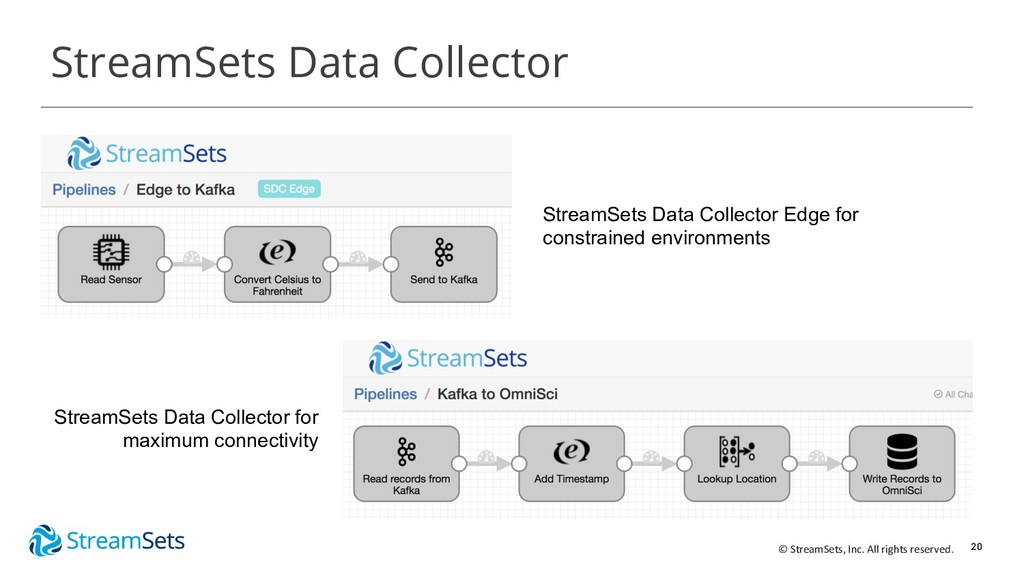{kind=link}
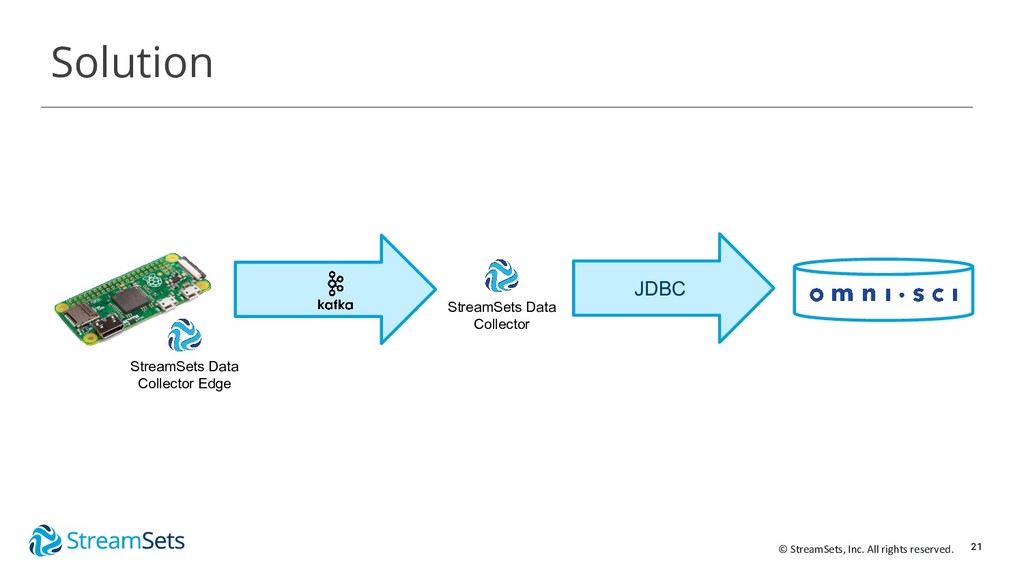{kind=link}
{kind=link}
{kind=link}
![thank you Pat Patterson Director of Evangelism [email protected] @metadaddy](https://files.speakerdeck.com/presentations/805f407ad71c416aba89b6e8eeaee257/slide_23.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}