Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Hyperloglog 简析
Search
onlyice
January 25, 2021
Programming
190
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Hyperloglog 简析
描述了在面对海量数据时,如何利用 HyperLogLog 做去重和统计,以及它背后的概率原理。
onlyice
January 25, 2021
Other Decks in Programming
See All in Programming
改善しないと、タスクが回らない。 “てんこ盛りポジション” を引き継いだ情シスの、入社3ヶ月の業務改善録
krm963
0
180
Embedded SREと共に達成した会員管理システムのAWS移行 - SRE NEXT 2026 ランチスポンサーセッション
niftycorp
PRO
1
3k
AI がコードを書く時代における新卒エンジニアの仕事風景 (2026) / New Graduate Engineers in the Era of AI Coding (2026)
sushichan044
0
240
AI時代のPHPer生存戦略 ~「言語、もうなんでもよくない?」に本気で向き合う~
vivion
0
160
Hatena Engineer Seminar #37「言語モデルの活用に関する研究」
slashnephy
0
550
作るコストが小さくなった時代 幸せに働くために改めて考えたいこと 〜エンジニアとして価値を出し続けるために注視している二分野〜
yuppeeng
0
120
Apache Hive: Toward a Cloud Native Lakehouse
okumin
0
160
FDEが実現するAI駆動経営の現在地
gonta
2
220
AI駆動開発を妨げる技術的負債の解消アプローチ / ai-refactoring-approach
minodriven
17
9.3k
What's New in Android 2026
veronikapj
0
190
壊れたパーサから始める関数型設計と構成的なパーサ #fp_matsuri
raiga0310
2
400
GDG Korea Android: 2026 I/O Extended ~ What's new in Android development tools
pluu
0
150
Featured
See All Featured
Making Projects Easy
brettharned
120
6.7k
The Language of Interfaces
destraynor
162
27k
Exploring the Power of Turbo Streams & Action Cable | RailsConf2023
kevinliebholz
37
6.5k
How to audit for AI Accessibility on your Front & Back End
davetheseo
0
470
Data-driven link building: lessons from a $708K investment (BrightonSEO talk)
szymonslowik
1
1.2k
Prompt Engineering for Job Search
mfonobong
0
380
Building a A Zero-Code AI SEO Workflow
portentint
PRO
0
640
Into the Great Unknown - MozCon
thekraken
41
2.6k
How GitHub (no longer) Works
holman
316
150k
The Organizational Zoo: Understanding Human Behavior Agility Through Metaphoric Constructive Conversations (based on the works of Arthur Shelley, Ph.D)
kimpetersen
PRO
0
390
Discover your Explorer Soul
emna__ayadi
2
1.2k
Agile Leadership in an Agile Organization
kimpetersen
PRO
0
190
Transcript
HyperLogLog 简析 林志衡 blog.zhiheng.io 2021/01/23
问题 大数据量去重统计,比如页面 UV。 2
传统方法 把全部数据加入 Set。 优点:精确 缺点:内存消耗巨大 概率方法 HyperLogLog 算法。 优点:内在消耗很少 缺点:不精确,但误差可以控
制在 1% 以内 3
什么是概率方法? 4
一个简单例子 将原始数据通过哈希算法随机生成一批均匀 分布在 [0, 1) 的数字。 只要随机过程足够均匀,比如图中的 hash(x)。 那么: 估算的元素个数
= 1 / 最小的 hash 值 缺点: 如果最小的哈希值碰巧很小,那么估算误差 巨大。 5
另外一种方法 计算末尾连续 0 个数。 前提: 1. 哈希算法计算出来的值是均匀分布的整数 2. 均匀分布的整数中,末位是连续 n
个 0 的 概率为 2^n 结论: 计算一批哈希值中,末位连续 0 最多的数字, 比如是连续 R 位。那么: 估算的元素个数 = 2^R 6
连续末尾 0 计数法 缺点: 1. 估算出来的元素个数 只能是 2 的次方 2.
估算结果可能 不精确(当碰巧出现末尾连 续 0 比较多时) 7
优化精确度 使用多个 hash 函数,生成多批哈希值并估算 出多个元素个数值,再做平均值。 优点: 避免单个 hash 函数带来可能的大误差。 缺点:
计算量成倍增加。 8 LogLog 算法, 1. 取哈希值的前几位作为桶(bucket,也称 register) 2. 按前几位的不同,把数字分入不同的桶中 3. 各个桶分别计算出元素个数,再估算出总 数 优点: 1. 通过分桶实现与多个 hash 函数一样的效果 2. 计算量不会大量增加
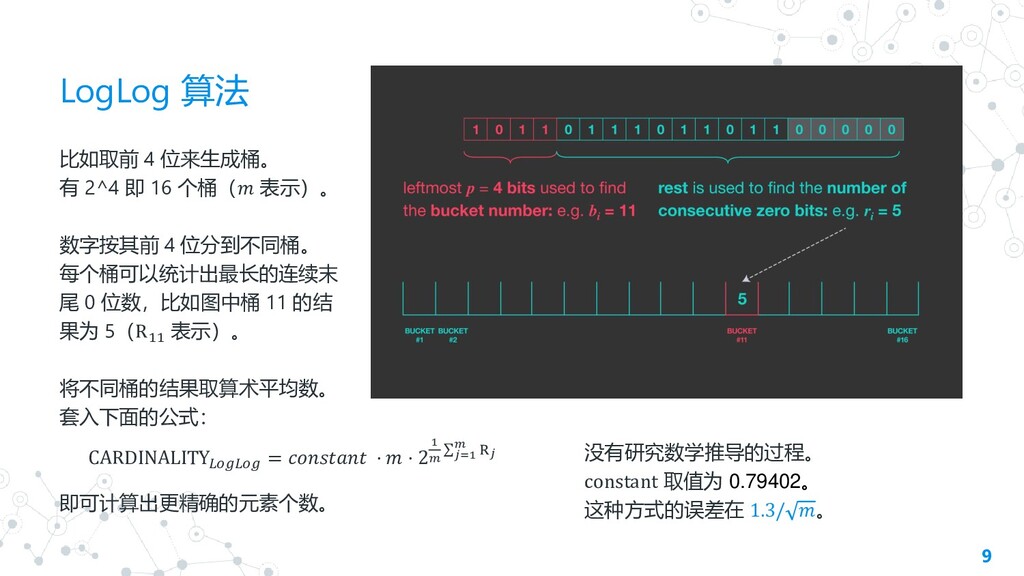
LogLog 算法 9 比如取前 4 位来生成桶。 有 2^4 即 16
个桶( 表示)。 数字按其前 4 位分到不同桶。 每个桶可以统计出最长的连续末 尾 0 位数,比如图中桶 11 的结 果为 5(R11 表示)。 将不同桶的结果取算术平均数。 套入下面的公式: 即可计算出更精确的元素个数。 CARDINALITY = ⋅ ⋅ 2 1 σ=1 R 没有研究数学推导的过程。 constant 取值为 0.79402。 这种方式的误差在 1.3/ 。
进一步提升精确度 10 SuperLogLog: 去掉异常值、使用几何平均数。 精确度提升到 1.05 。 HyperLogLog: 使用调和平均数。 精确度提升到
1.04 。
Redis 的 HyperLogLog 实现 11 • Hash 值为 64 位整数
• 使用前 14 位作为桶(register),一共 16K 个桶(16384 ) • 误差在 0.81%
参考 12 1. HyperLogLog in Presto: A significantly faster way
to handle cardinality estimation https://engineering.fb.com/2018/12/13/data-infrastructure/hyperloglog/ 2. Redis new data structure: the HyperLogLog http://antirez.com/news/75
Thanks! 林志衡 blog.zhiheng.io 13
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}