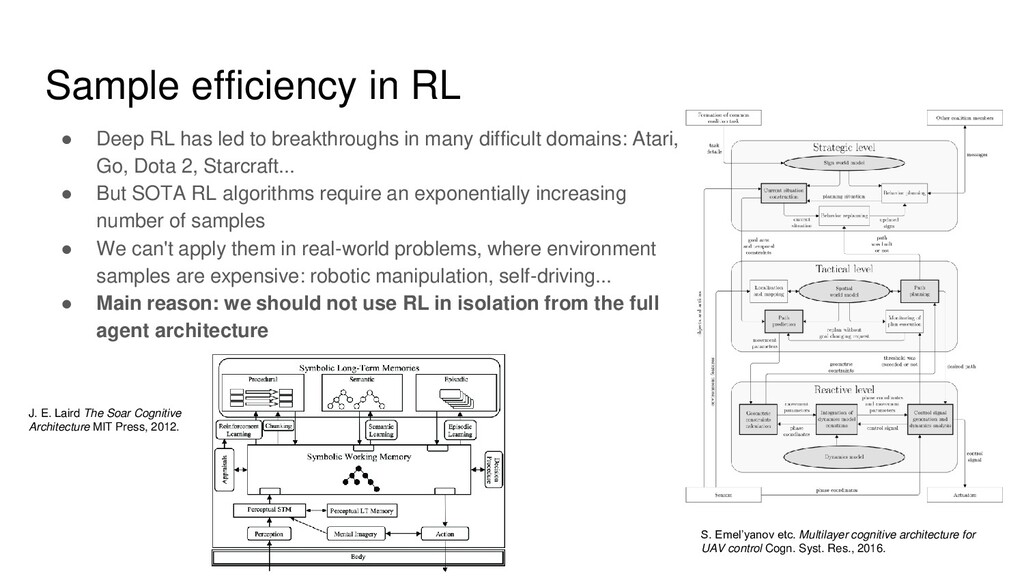
breakthroughs in many difficult domains: Atari, Go, Dota 2, Starcraft... • But SOTA RL algorithms require an exponentially increasing number of samples • We can't apply them in real-world problems, where environment samples are expensive: robotic manipulation, self-driving... • Main reason: we should not use RL in isolation from the full agent architecture J. E. Laird The Soar Cognitive Architecture MIT Press, 2012. S. Emel’yanov etc. Multilayer cognitive architecture for UAV control Cogn. Syst. Res., 2016.
Isaac • Hierarchical Reinforcement Learning: ◦ S. Levine et al. Data-Efficient Hierarchical Reinforcement Learning NIPS 2018 ◦ A. Skrynnik and A. I. Panov Hierarchical Reinforcement Learning with Clustering Abstract Machines RCAI 2019 • Imitation Learning and Learning from Demonstrations: ◦ Y. Gao et al. Reinforcement Learning from Imperfect Demonstrations 2018. ◦ W. H. Guss et al. The MineRL Competition on Sample Efficient Reinforcement Learning using Human Priors NIPS 2019. • Memory-based Reinforcement Learning: ◦ S. Levine et al. Deep Reinforcement Learning in a Handful of Trials using Probabilistic Dynamics Models NIPS 2018 ◦ A. Younes and A. I. Panov Toward Faster Reinforcement Learning for Robotics : Using Gaussian Processes RAAI Summer School 2019 • Lifelong learning and Transfer Learning
applied to ATARI 2600 games and require from 44 to over 200 million frames (200 to over 900 hours) to achieve human-level performance • OpenAI Five utilizes 11,000+ years of Dota 2 gameplay • AlphaZero uses 4.9 million games of self-play in Go • AlphaStar uses 200 years of Starcraft II gameplay MineRL Sample-efficient reinforcement learning in Minecraft
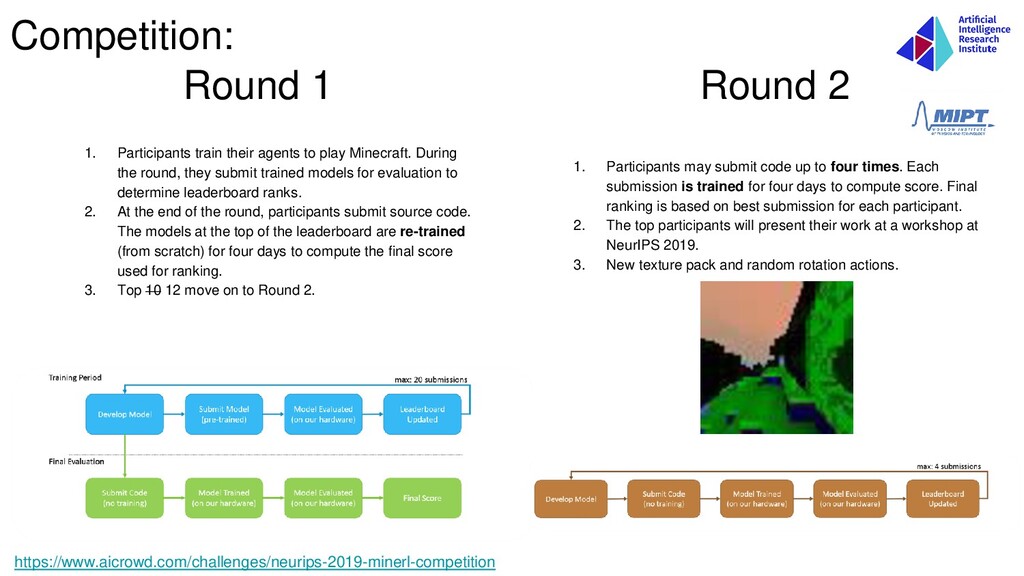
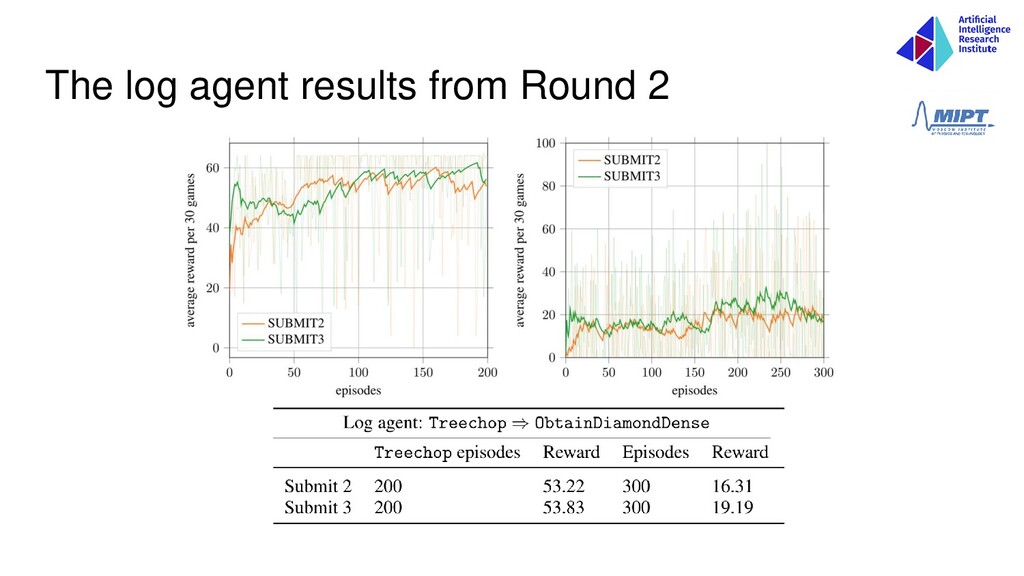
round, they submit trained models for evaluation to determine leaderboard ranks. 2. At the end of the round, participants submit source code. The models at the top of the leaderboard are re-trained (from scratch) for four days to compute the final score used for ranking. 3. Top 10 12 move on to Round 2. https://www.aicrowd.com/challenges/neurips-2019-minerl-competition 1. Participants may submit code up to four times. Each submission is trained for four days to compute score. Final ranking is based on best submission for each participant. 2. The top participants will present their work at a workshop at NeurIPS 2019. 3. New texture pack and random rotation actions. Round 2 Competition: Round 1
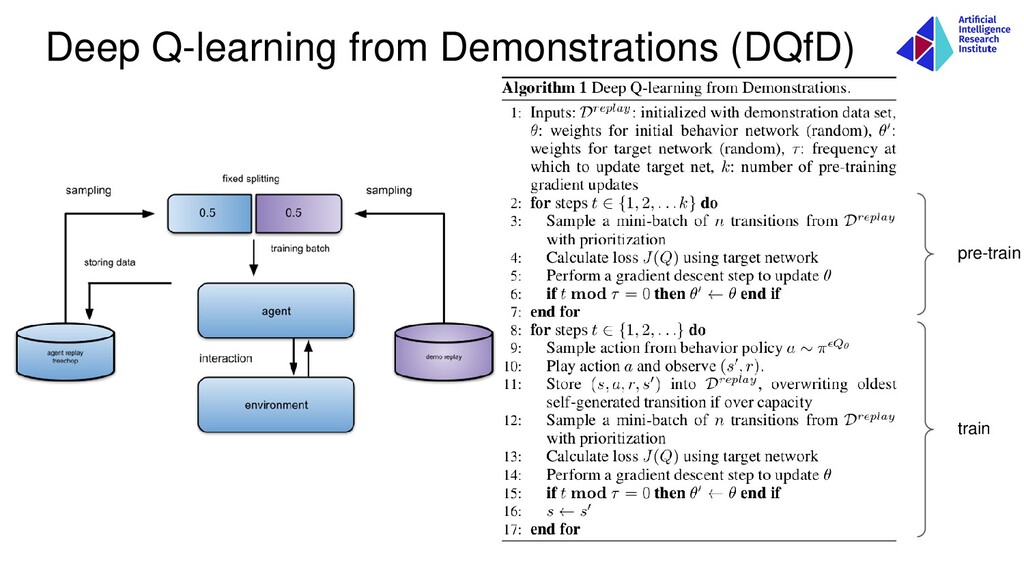
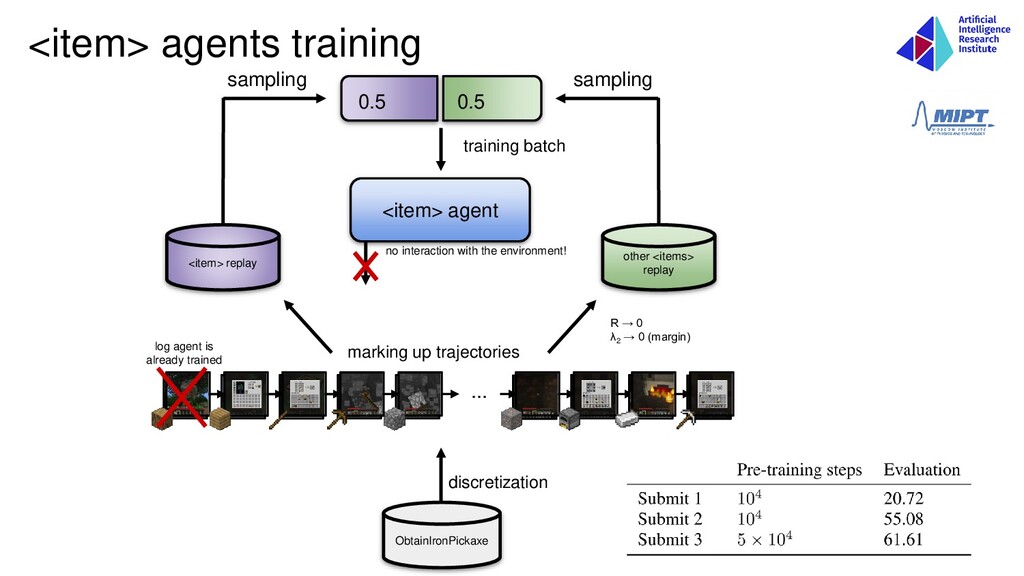
training batch 0.5 0.5 discretization log agent is already trained ... marking up trajectories no interaction with the environment! R → 0 λ2 → 0 (margin) <item> agents training
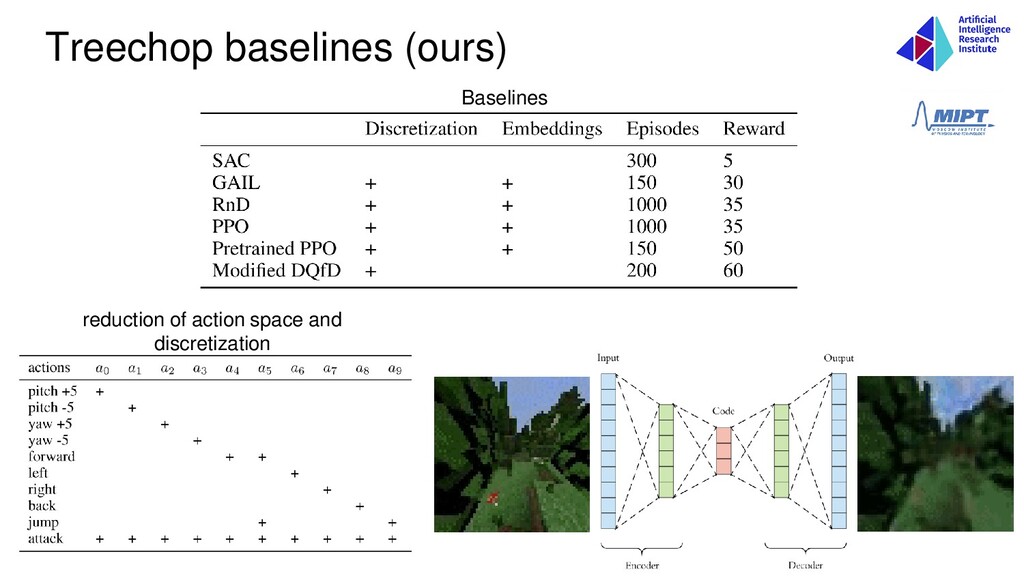
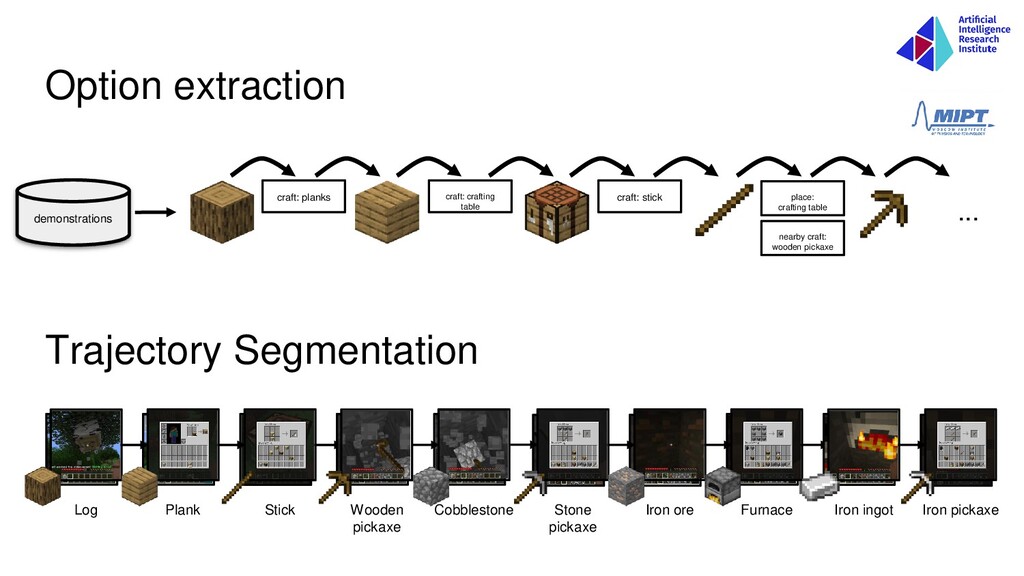
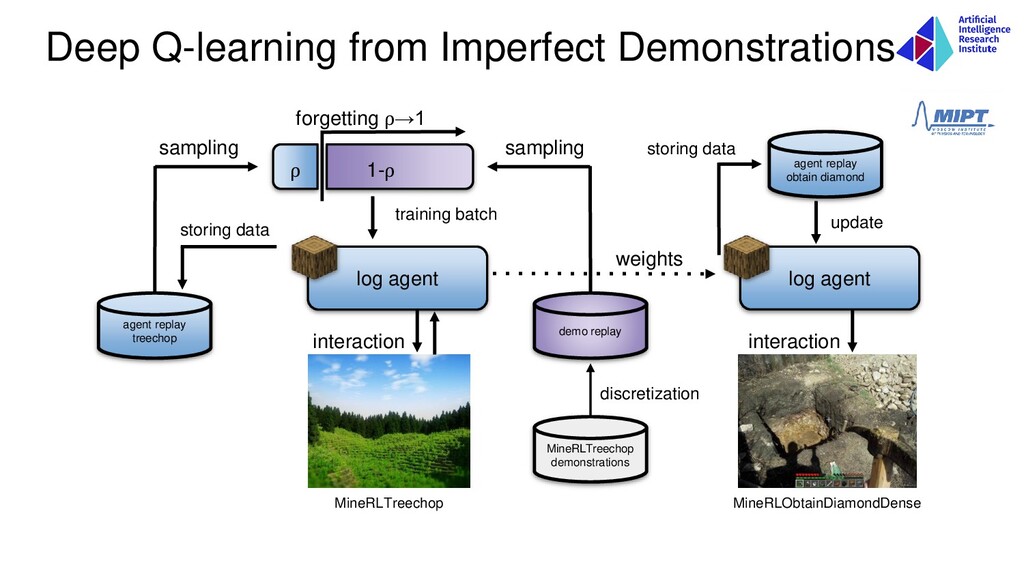
agent’s actions and reduction of action space • Reduction of state space via extracting subtasks • Structured replay buffer for <item> agents • Semantic network of meta-actions • DQfD with forgetting
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you for your attention [email protected]](https://files.speakerdeck.com/presentations/053abcda1b254781b8a818622948698f/slide_15.jpg){kind=link}