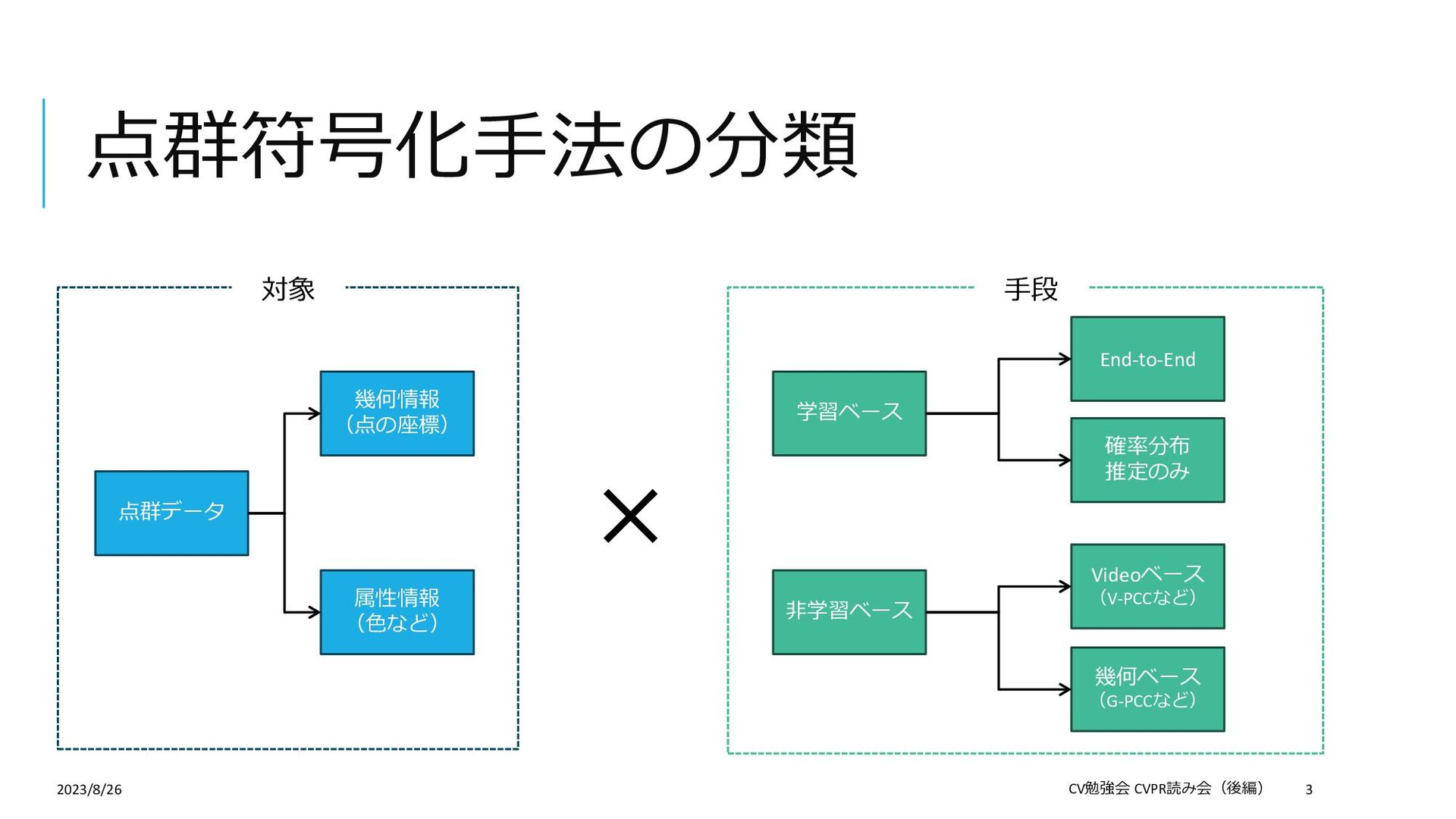
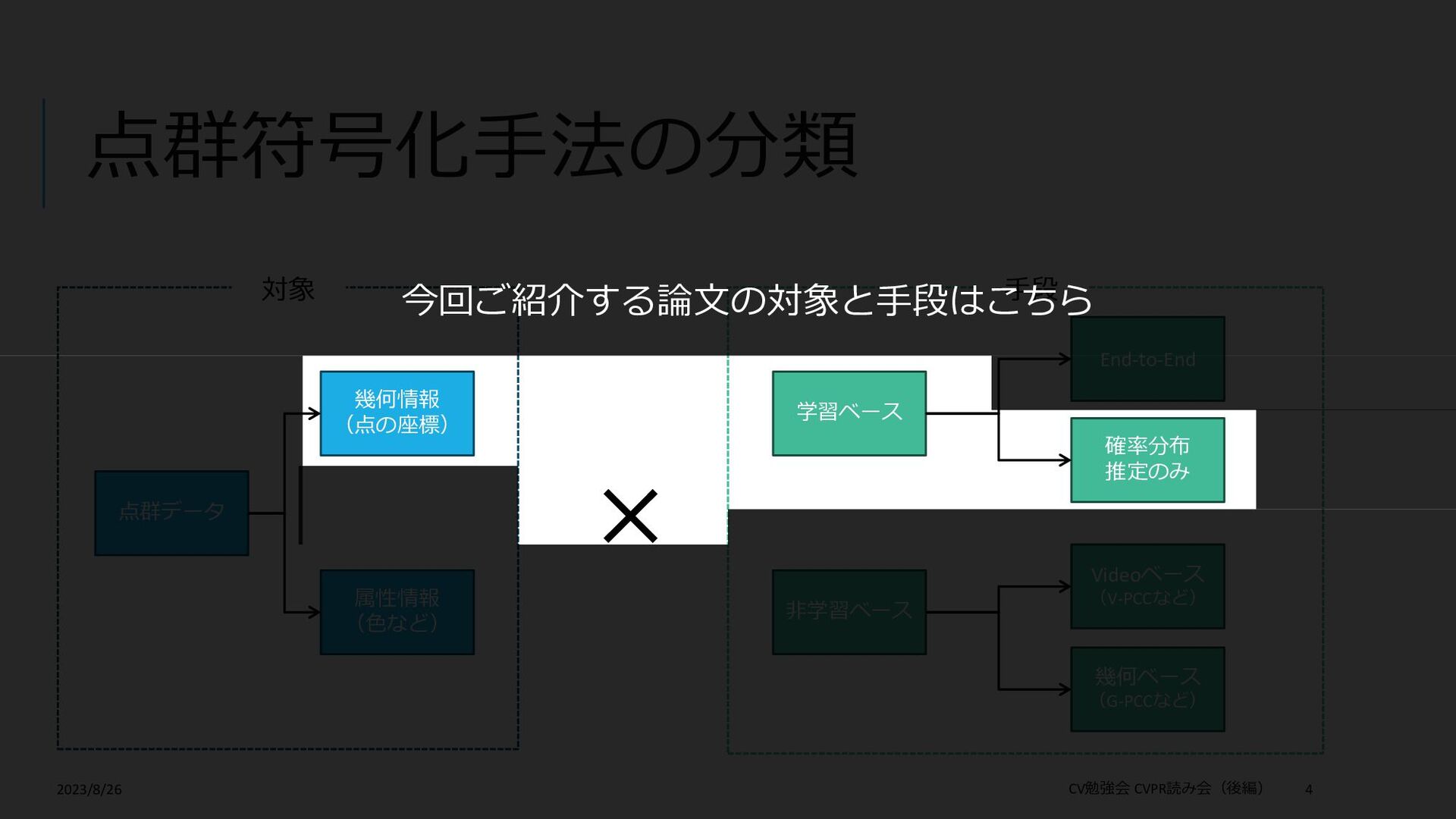
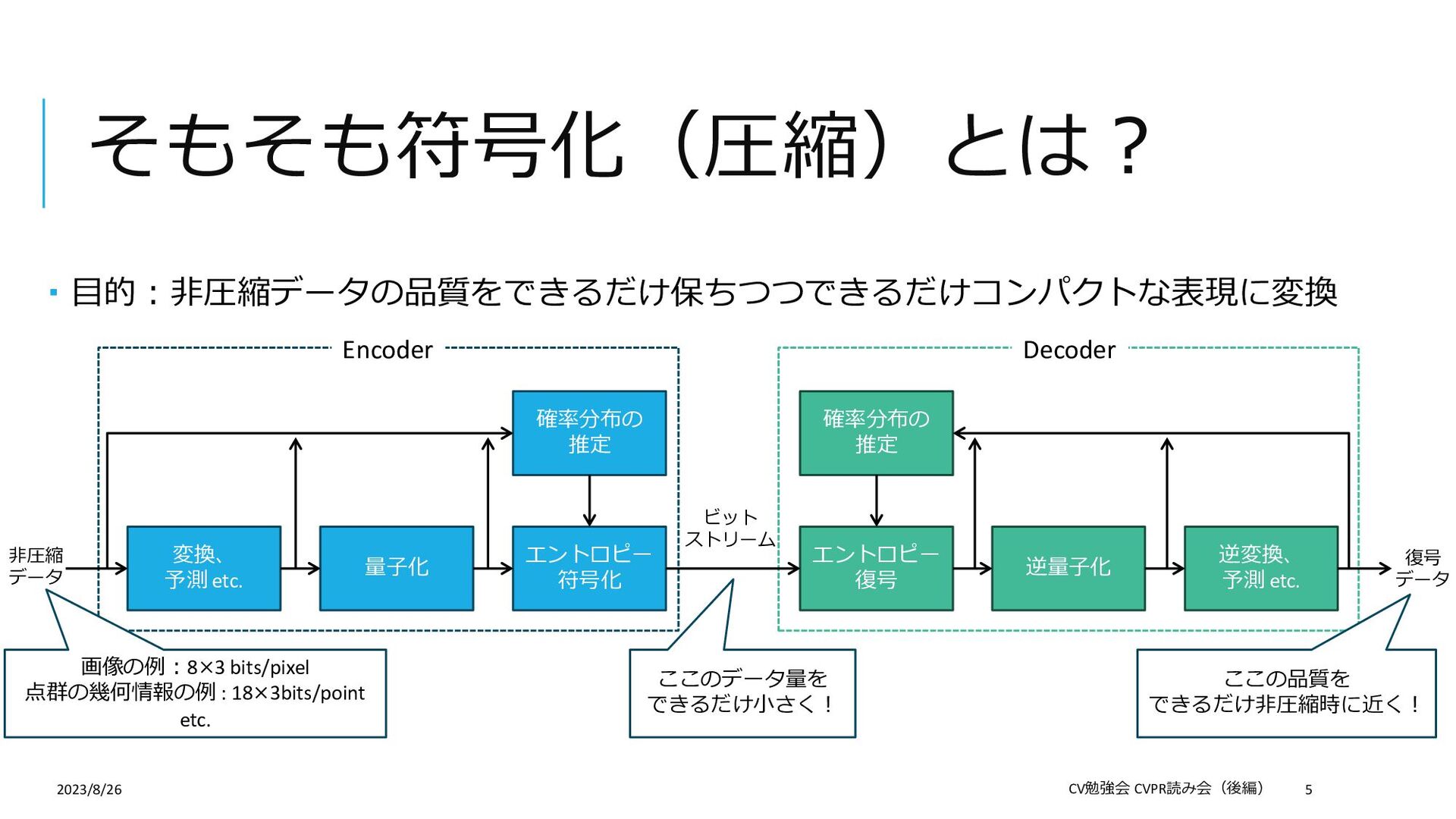
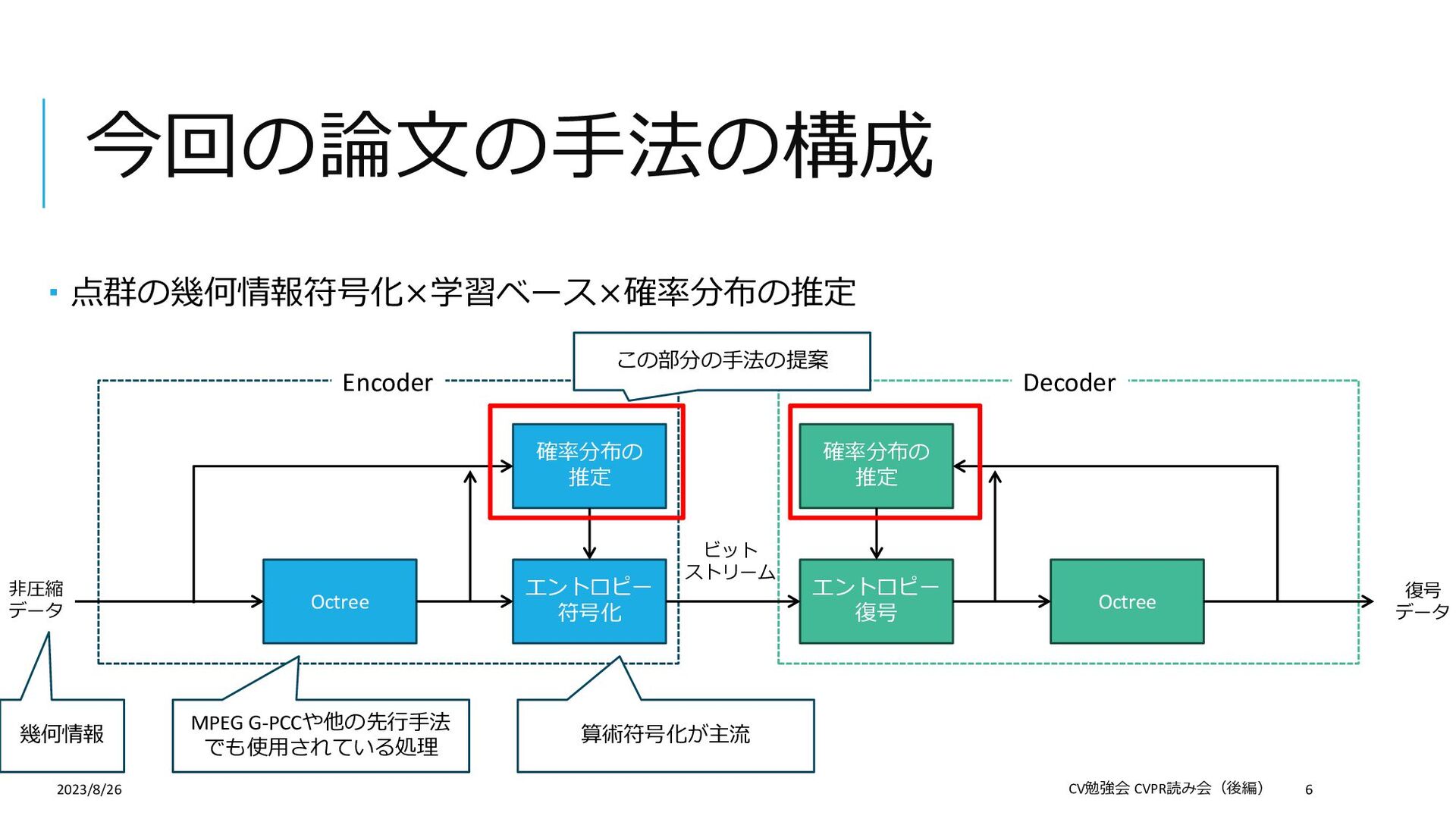
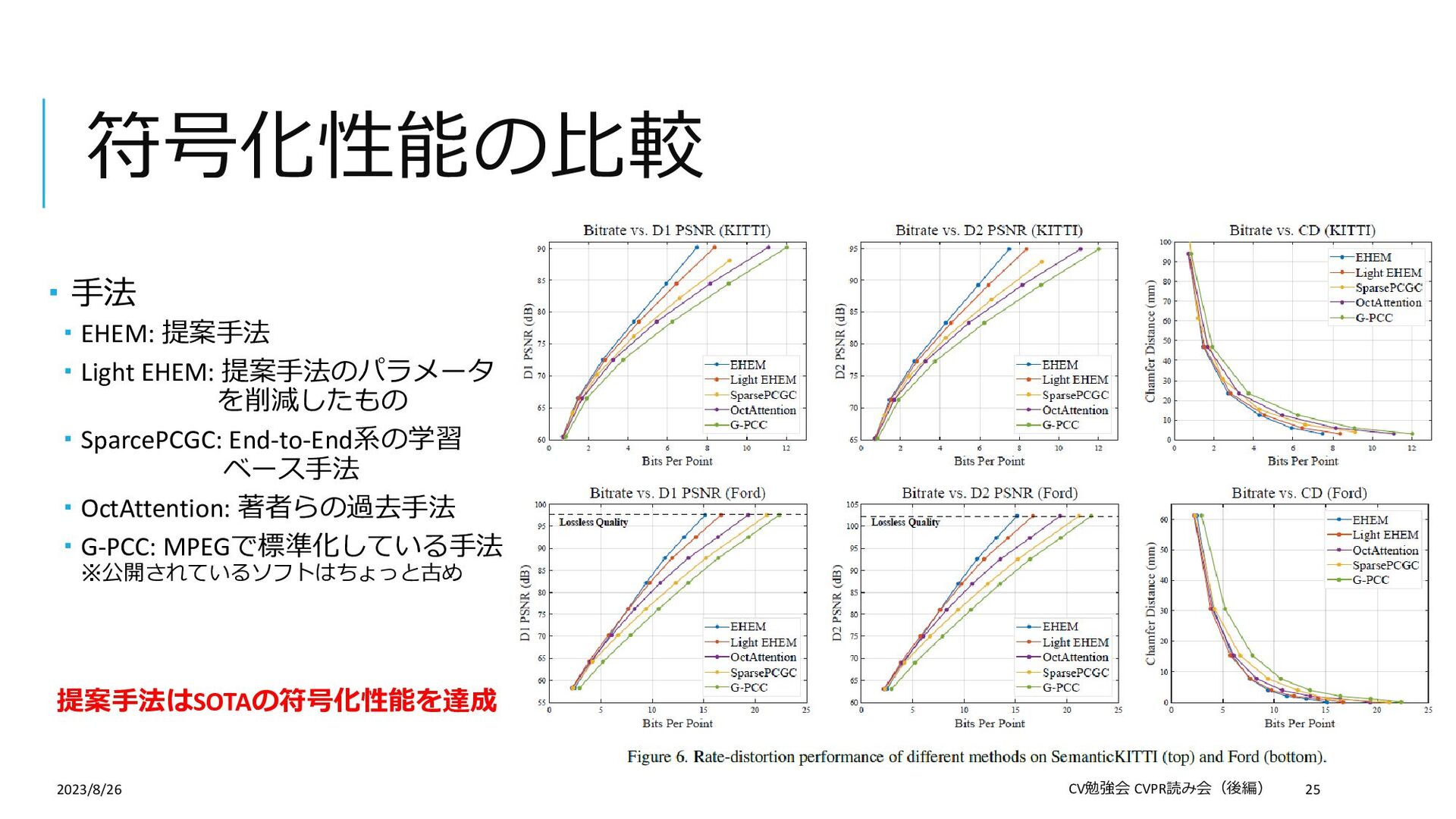
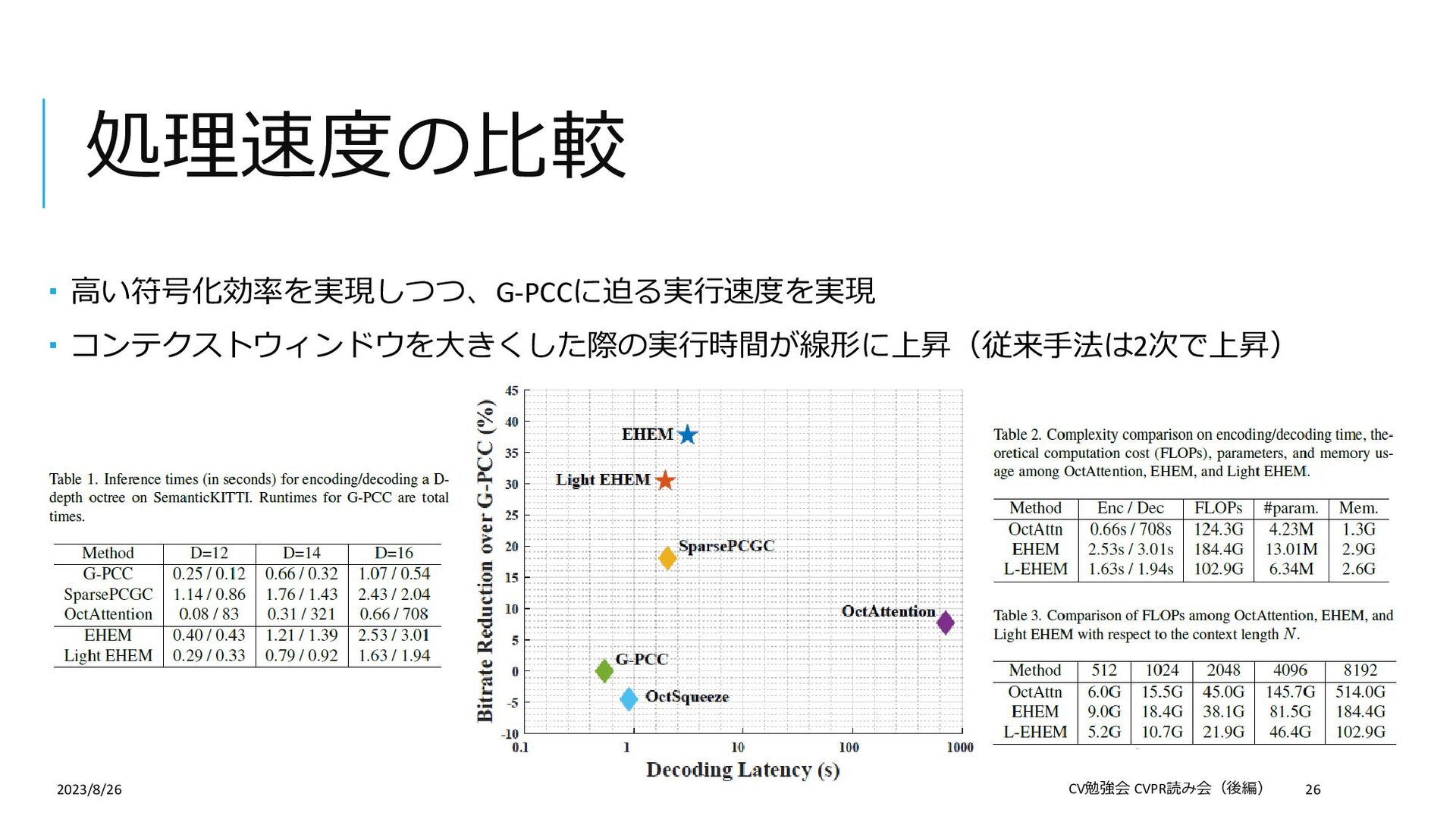
Compression 論文: https://openaccess.thecvf.com/content/CVPR2023/papers/Song_Efficient_Hierarchical_Entropy_Model_for_Learned_P oint_Cloud_Compression_CVPR_2023_paper.pdf Supplemental: https://openaccess.thecvf.com/content/CVPR2023/supplemental/Song_Efficient_Hierarchical_Entropy_CVPR_2023_su pplemental.pdf 概要:学習ベースの点群の幾何情報符号化(圧縮) この論文を選んだ理由: 学習ベースの符号化手法について勉強したかった(普段の仕事は非学習ベース) 「符号化」というタスクを紹介したかった 「点群」×「符号化」の論文がCVPR2023ではこれしかなかった 2023/8/26 CV勉強会 CVPR読み会(後編) 2
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
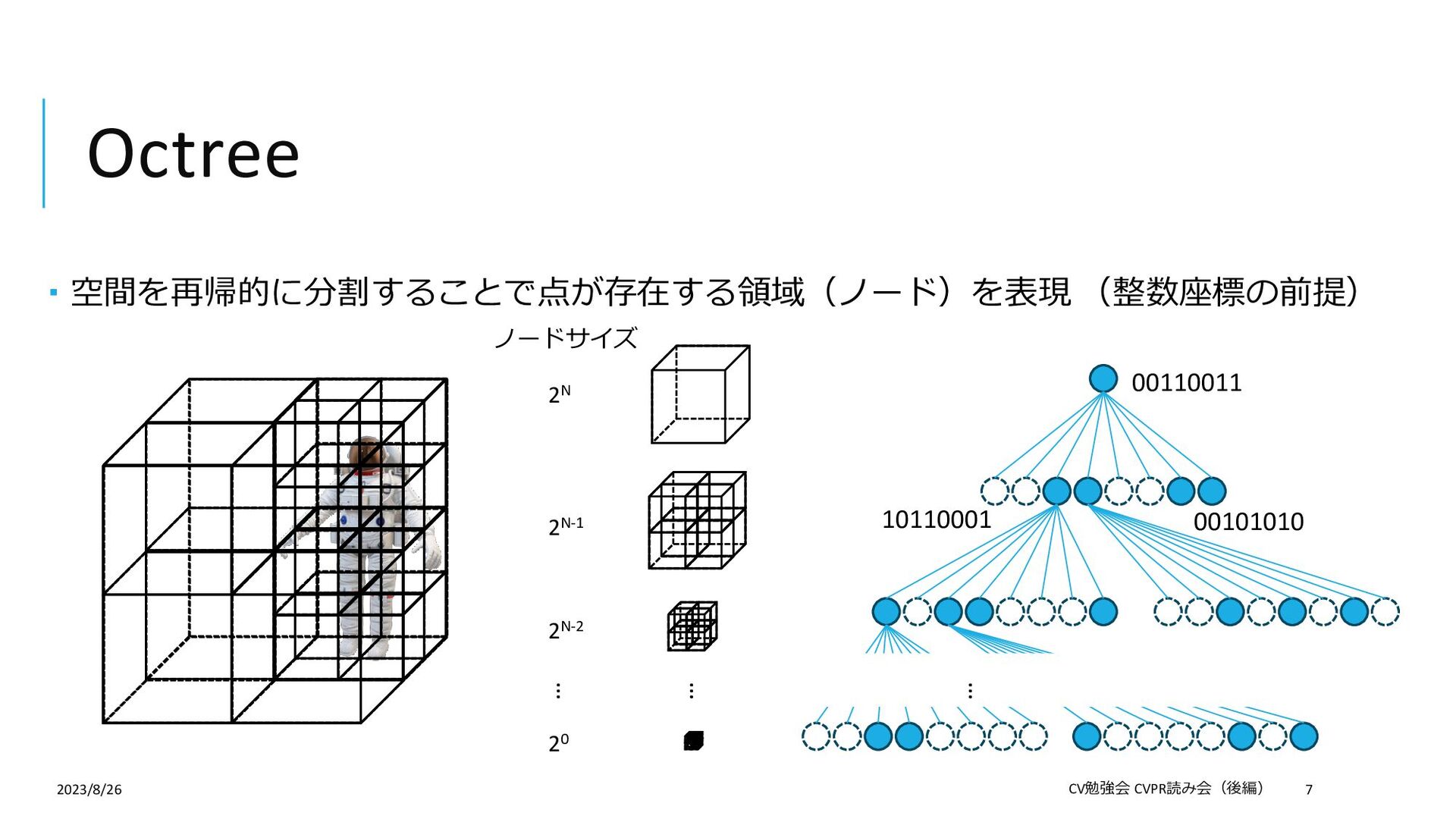{kind=link}
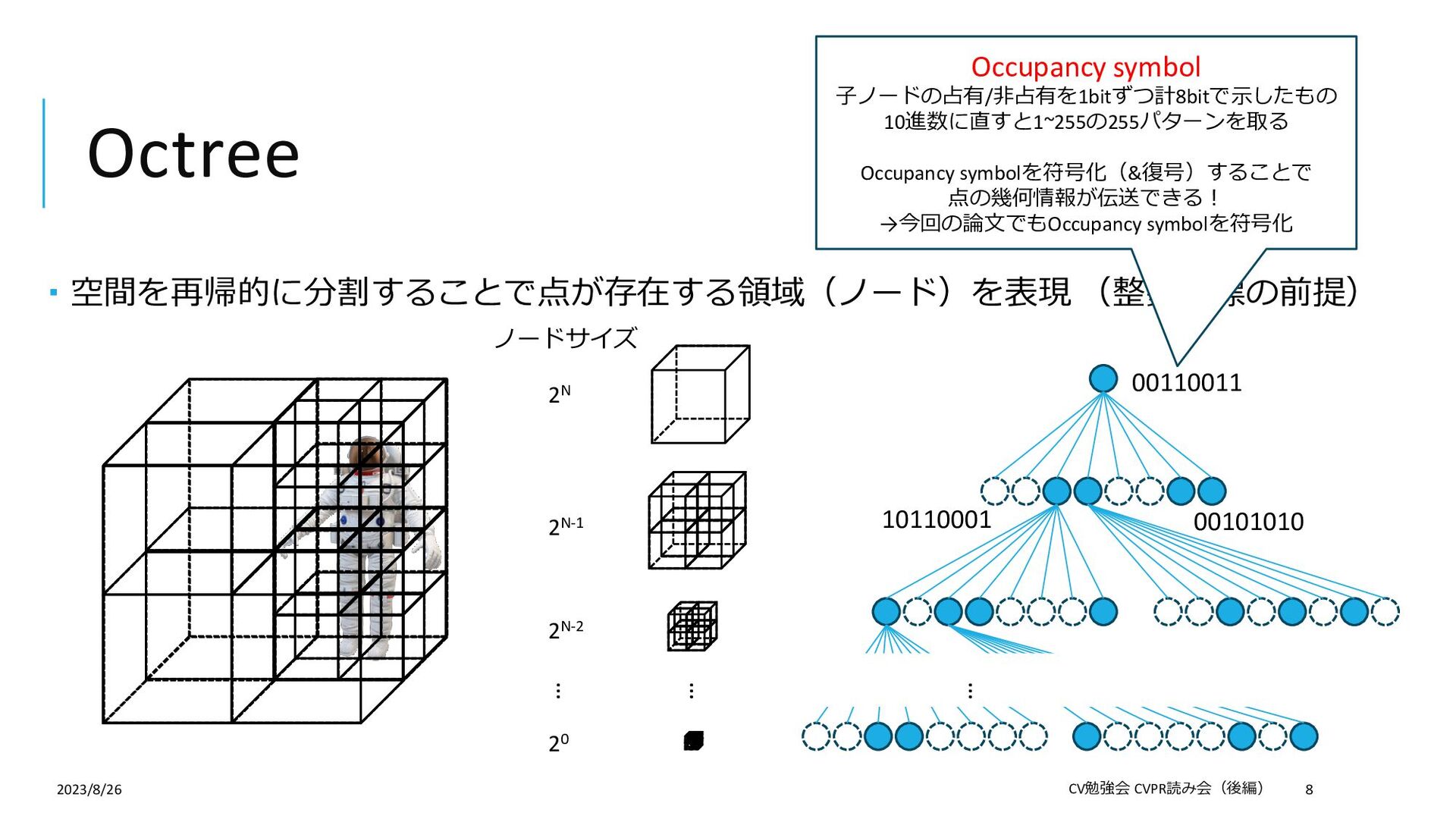{kind=link}
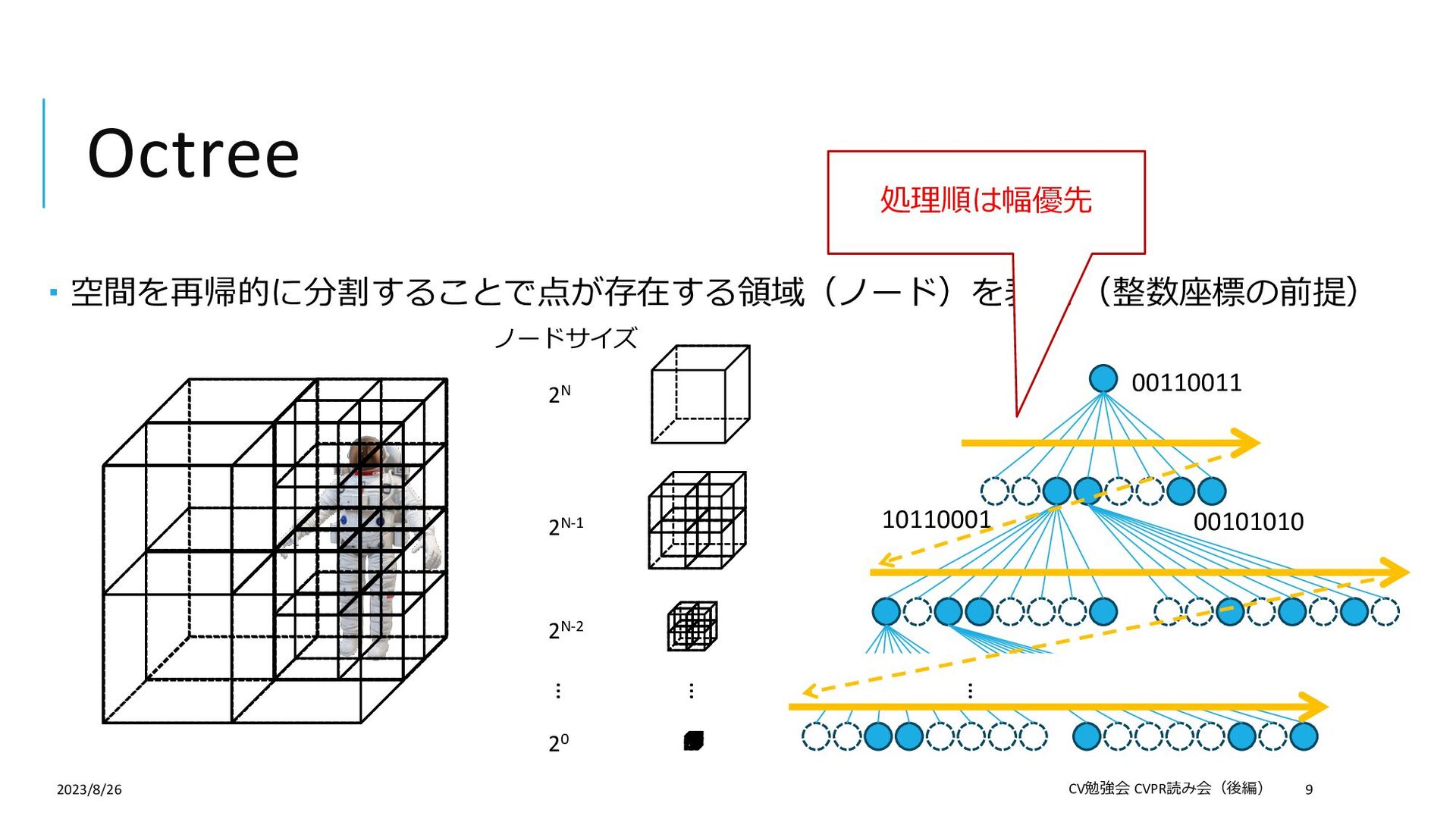{kind=link}
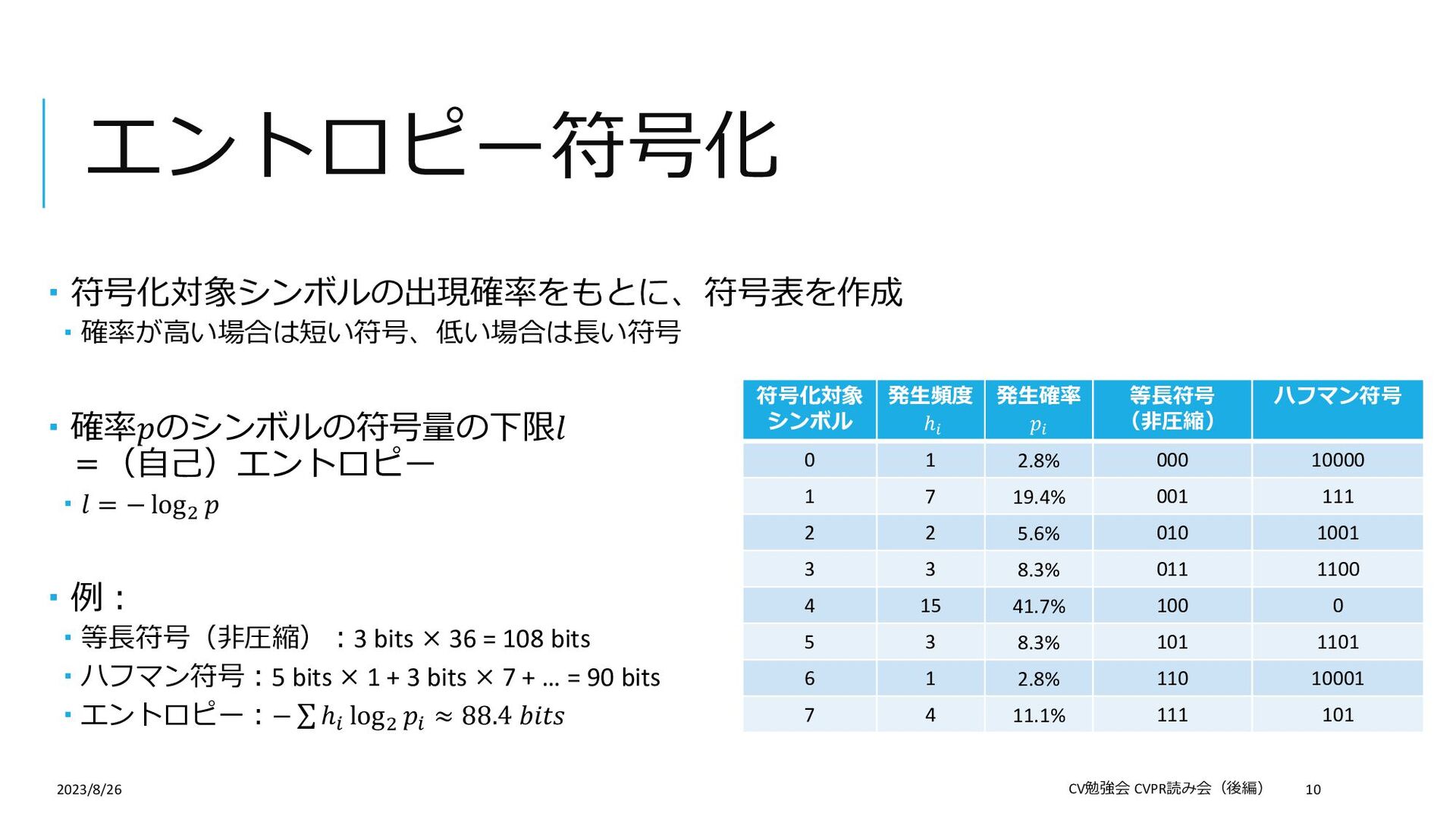{kind=link}
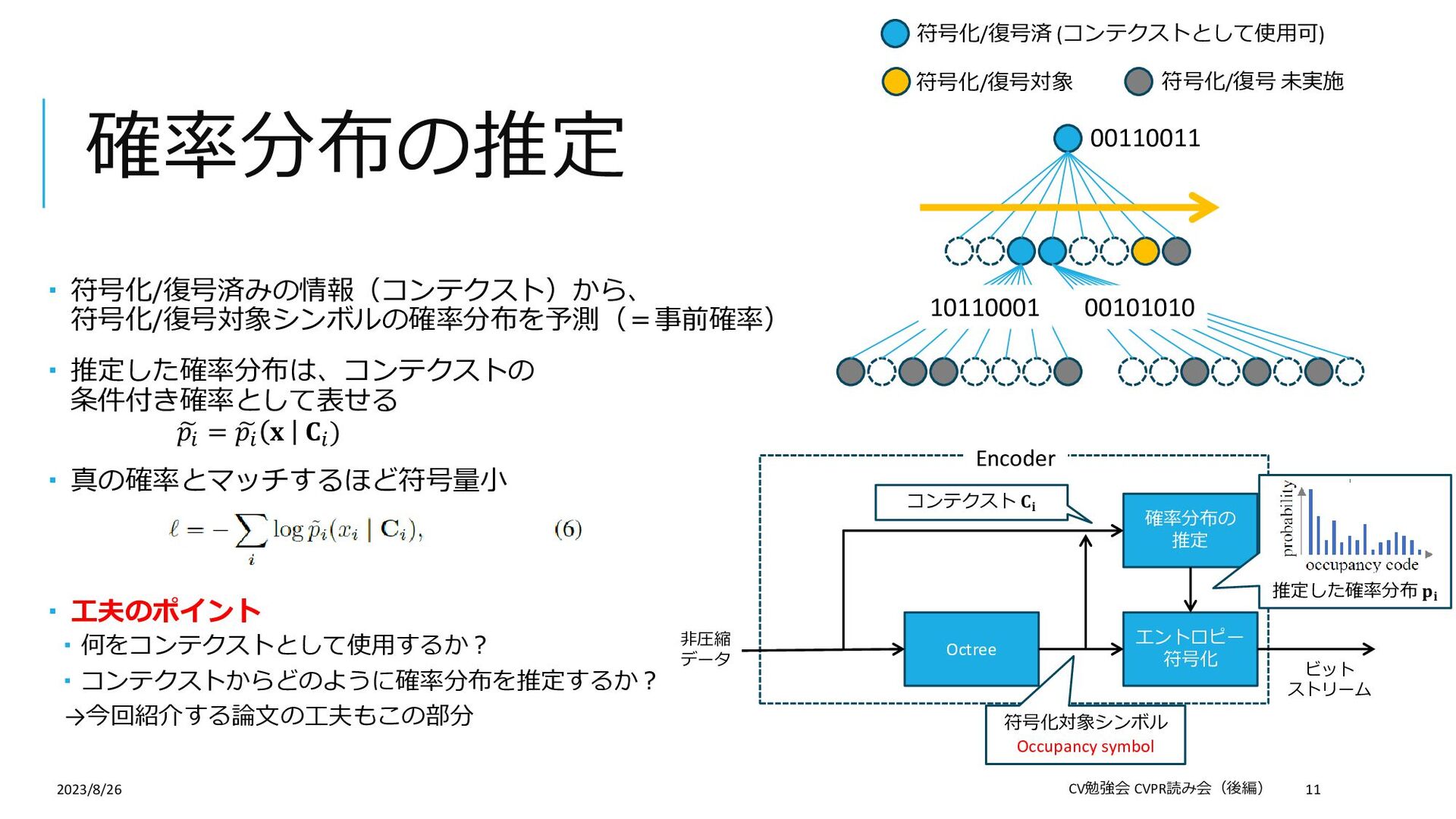{kind=link}
![従来手法と課題 OctAttention [10]:著者らの過去の手法 自己回帰モデル 1ノードずつ幅優先探索で符号化/復号 直前に符号化/復号したノードの情報を使用](https://files.speakerdeck.com/presentations/6b4bf7a234474199a3176cd97238ca66/slide_11.jpg){kind=link}
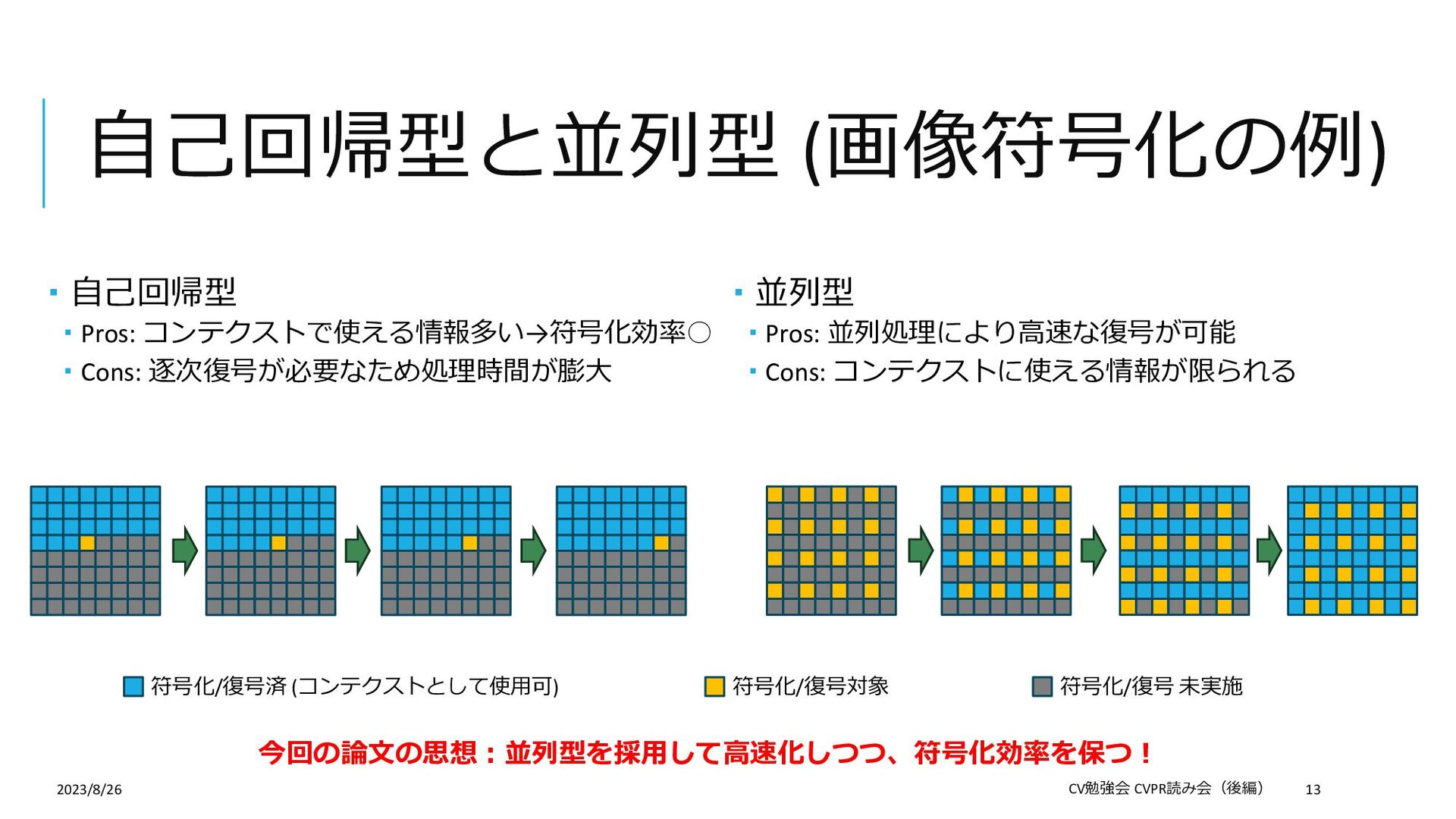{kind=link}
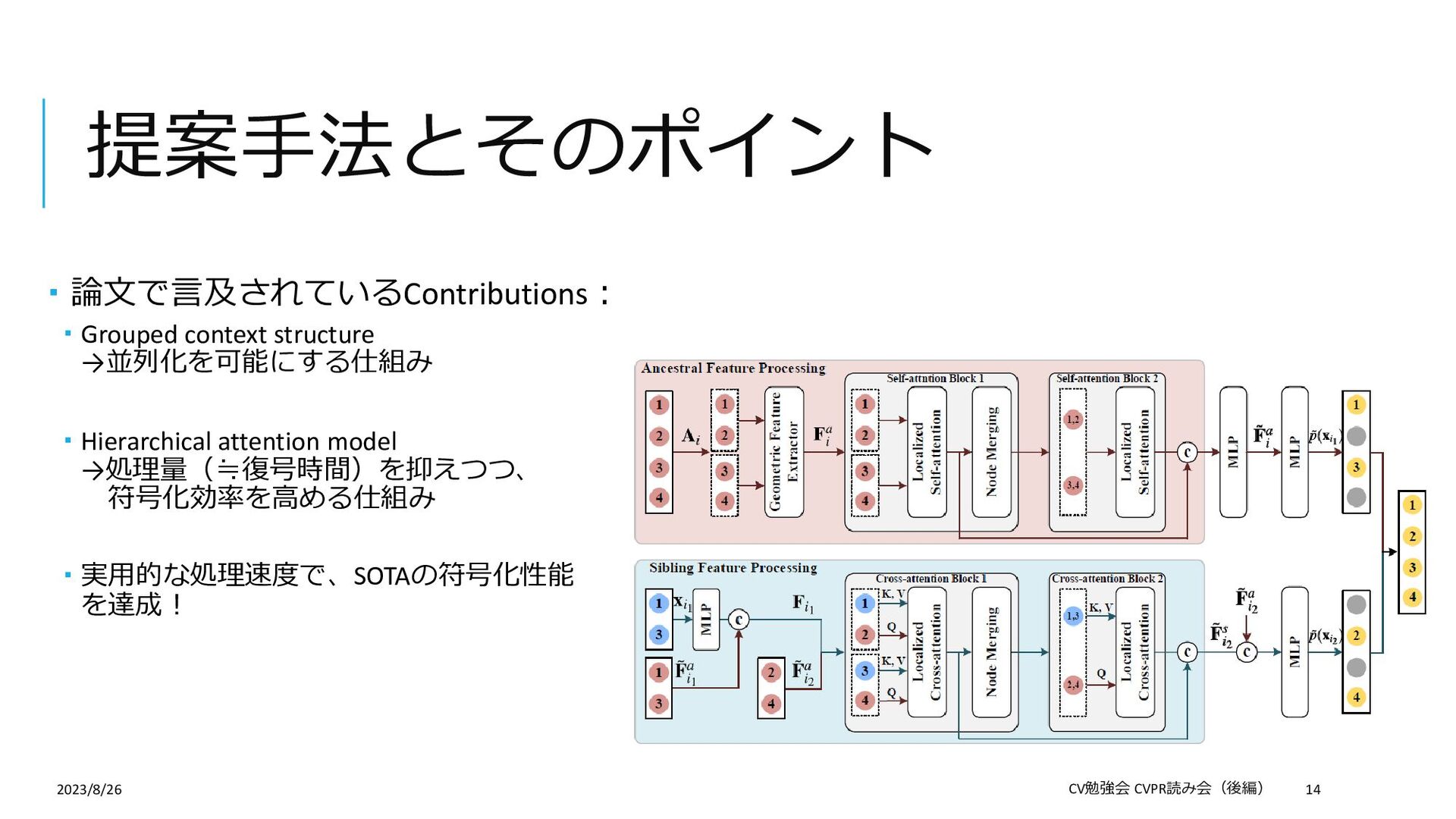{kind=link}
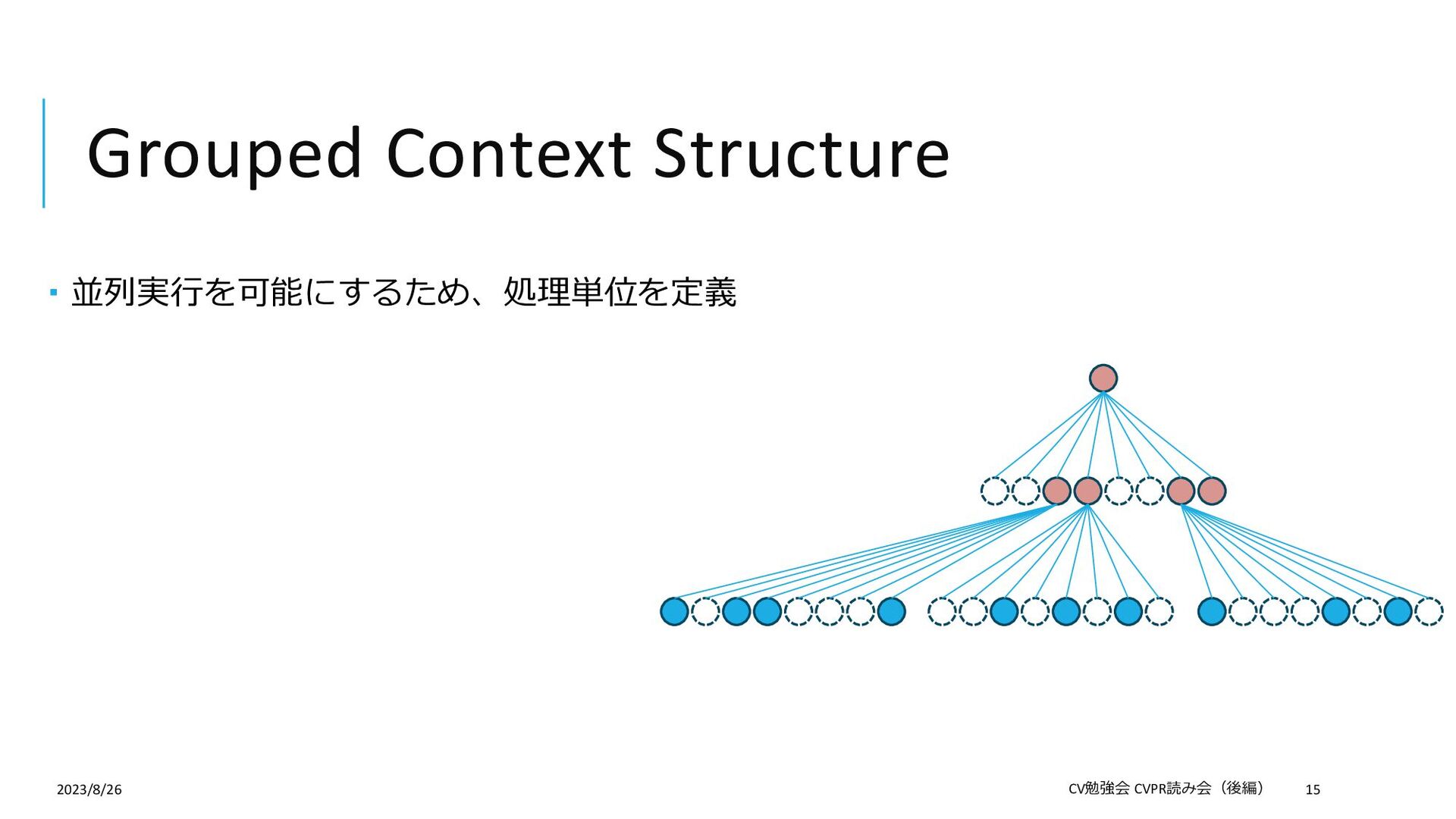{kind=link}
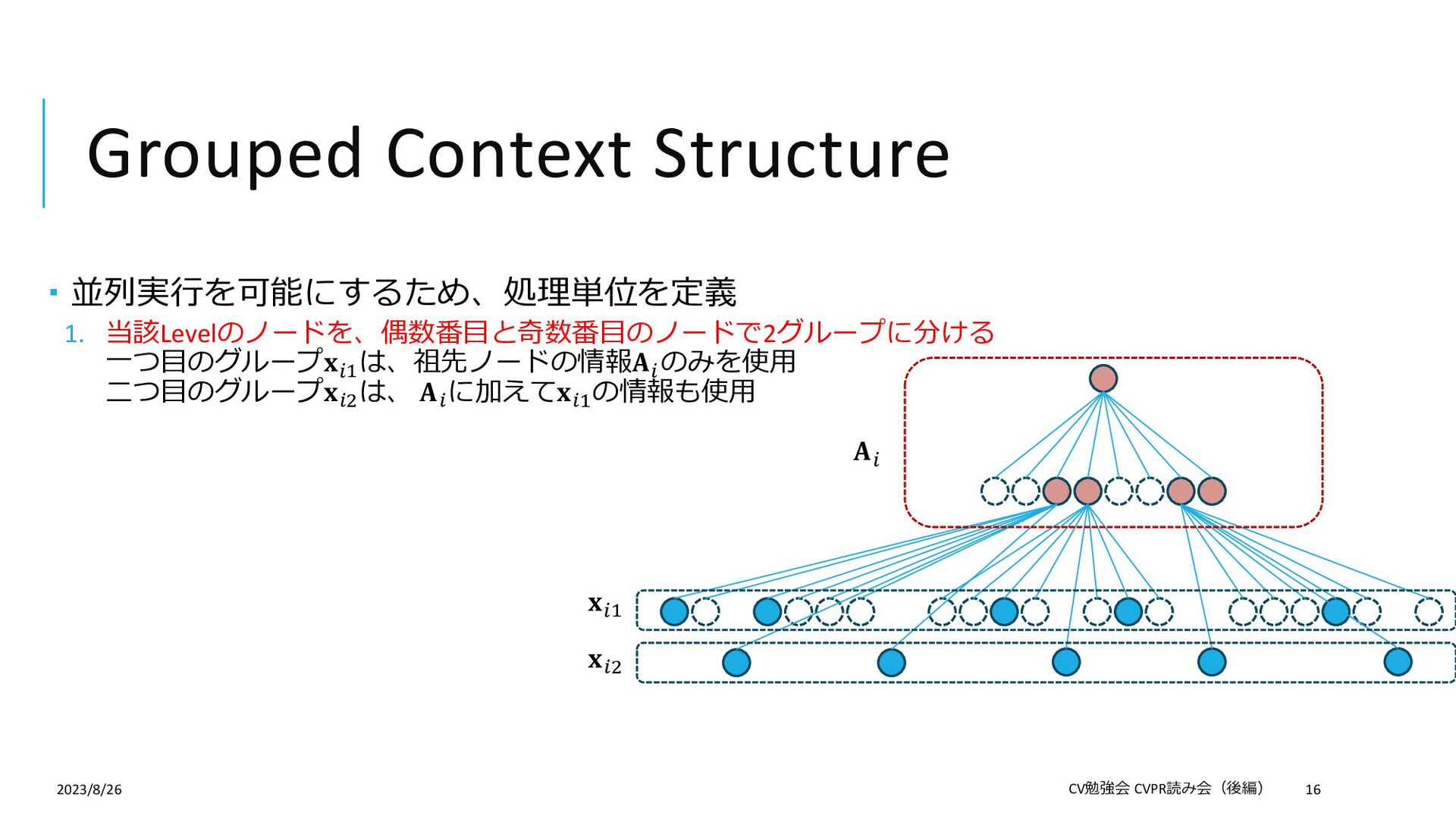{kind=link}
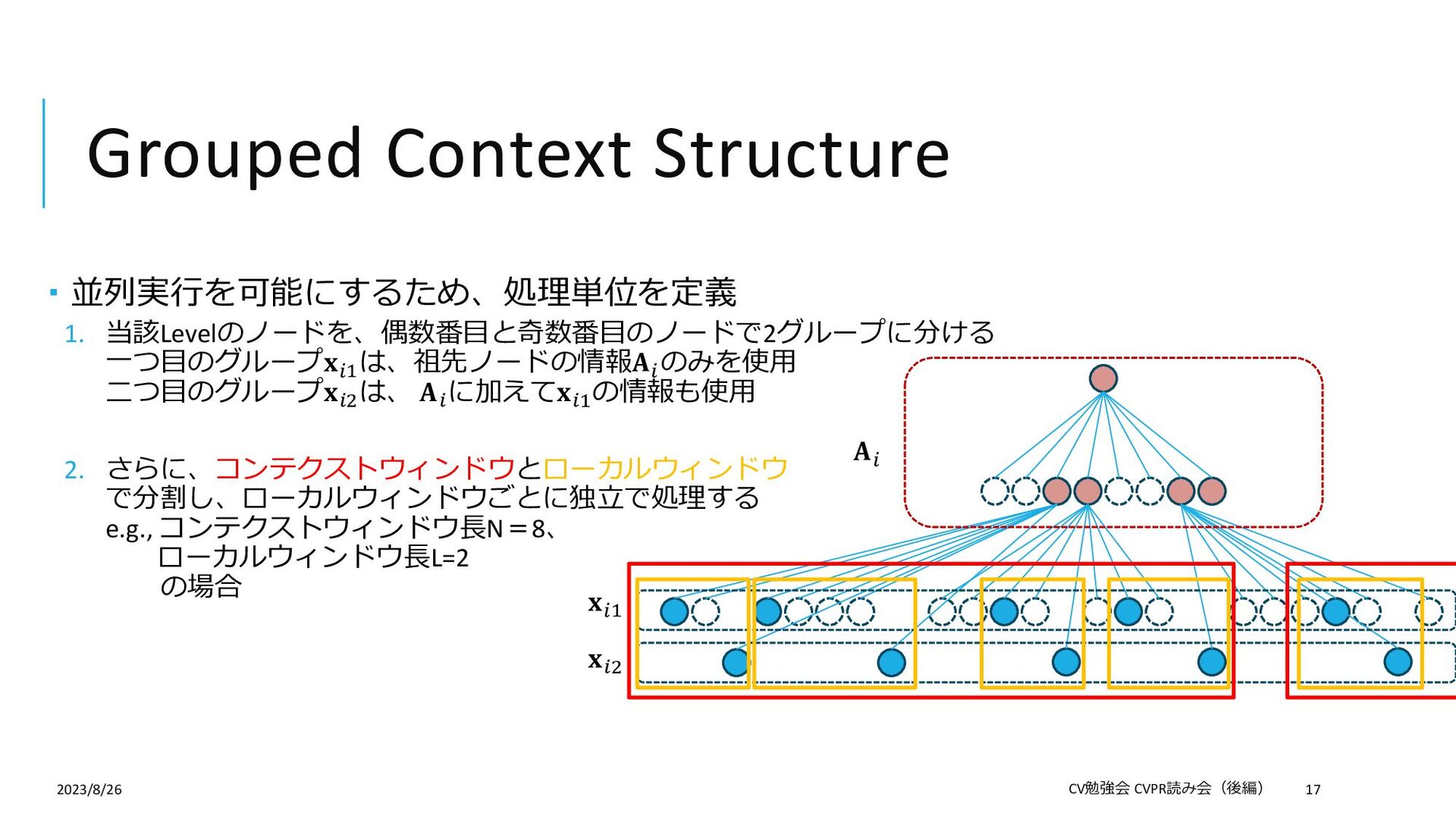{kind=link}
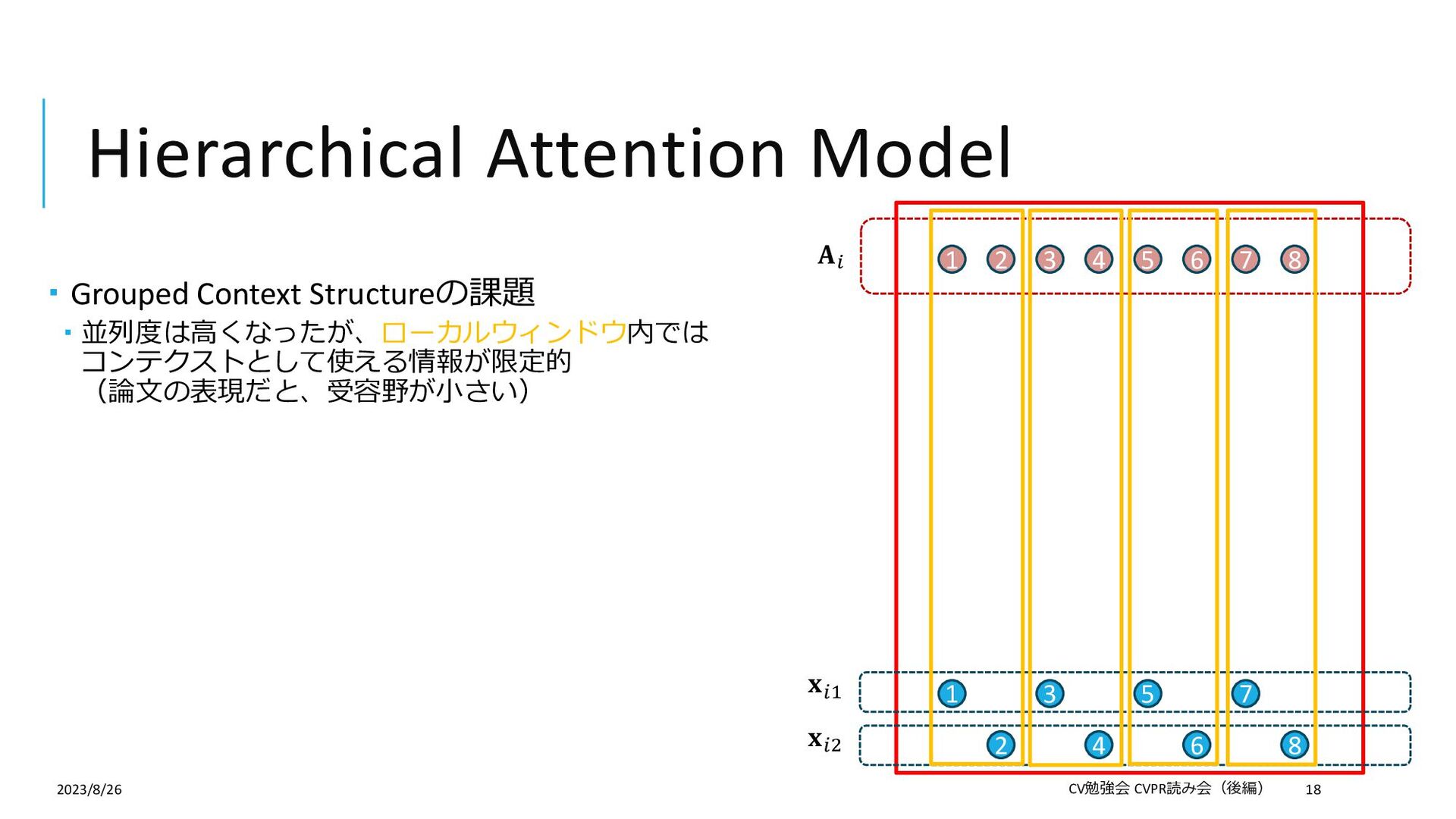{kind=link}
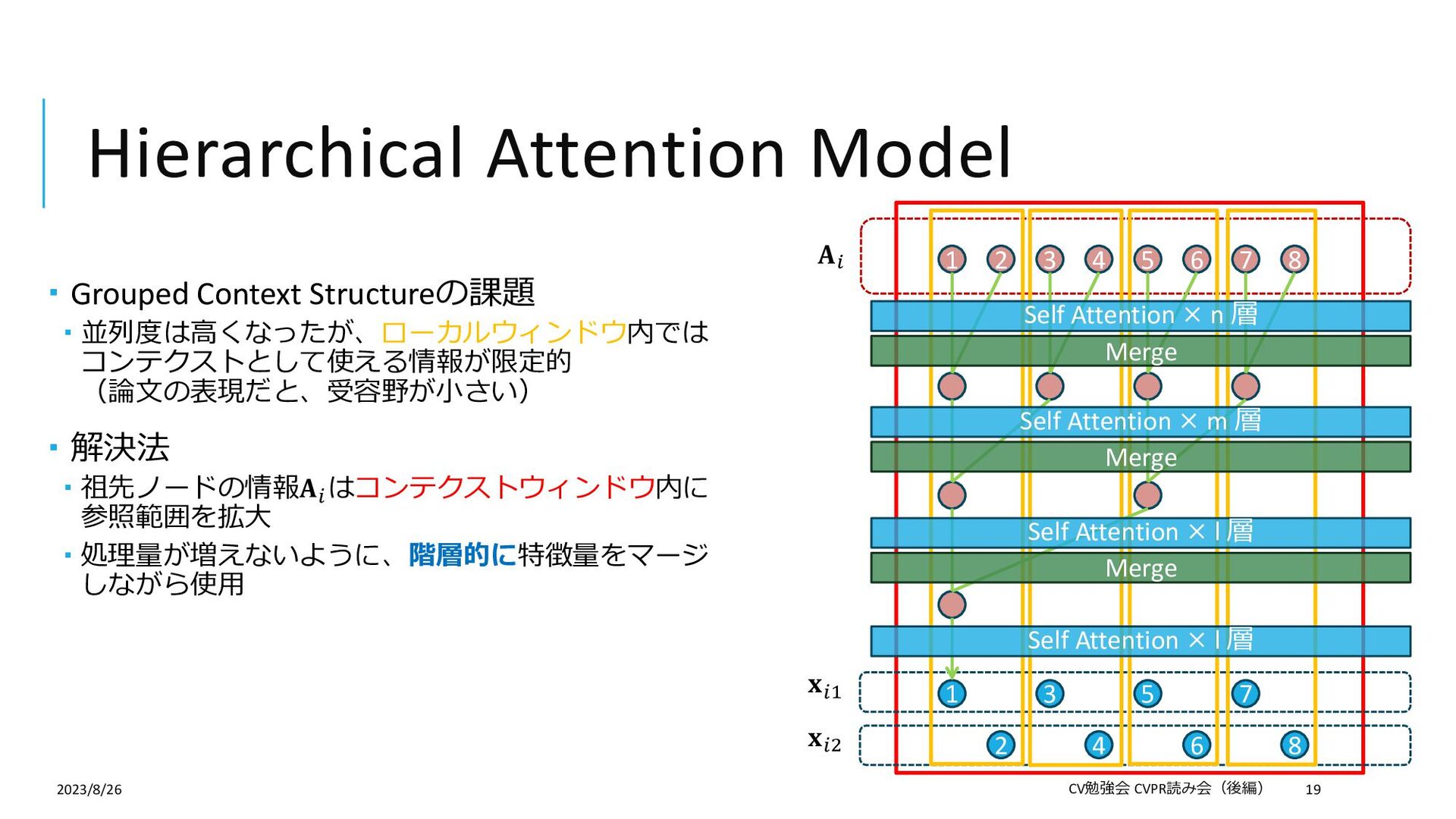{kind=link}
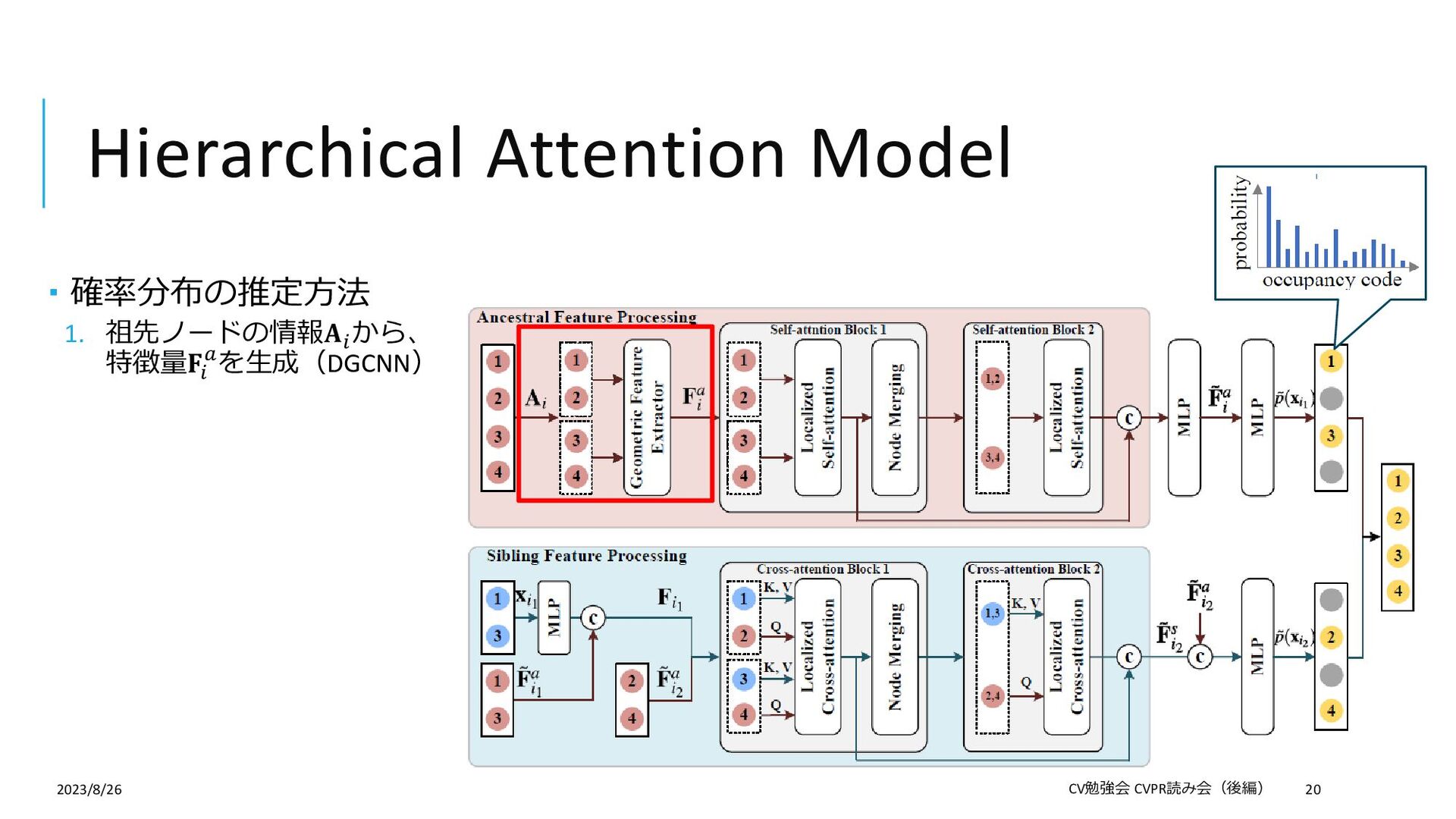{kind=link}
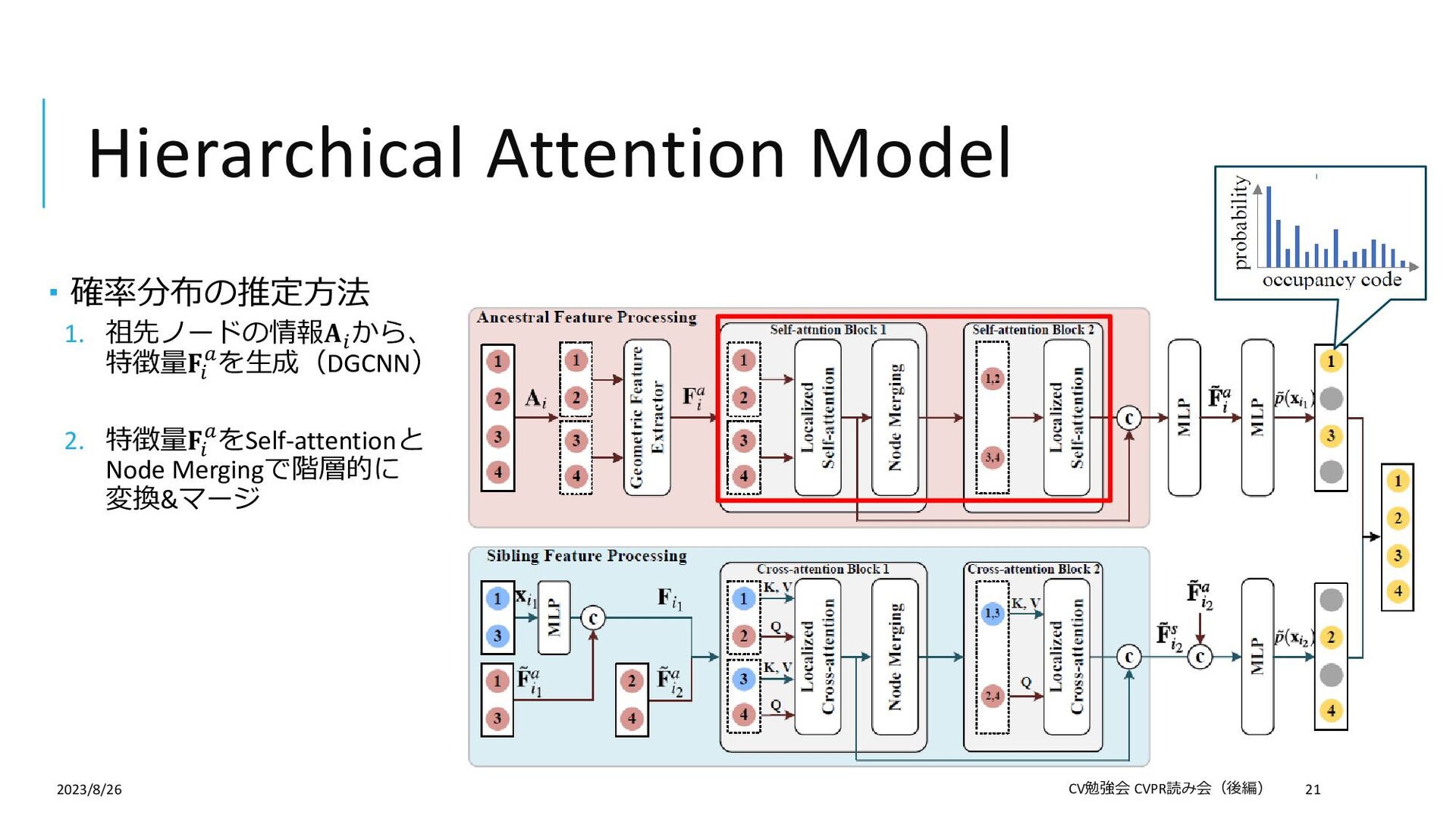{kind=link}
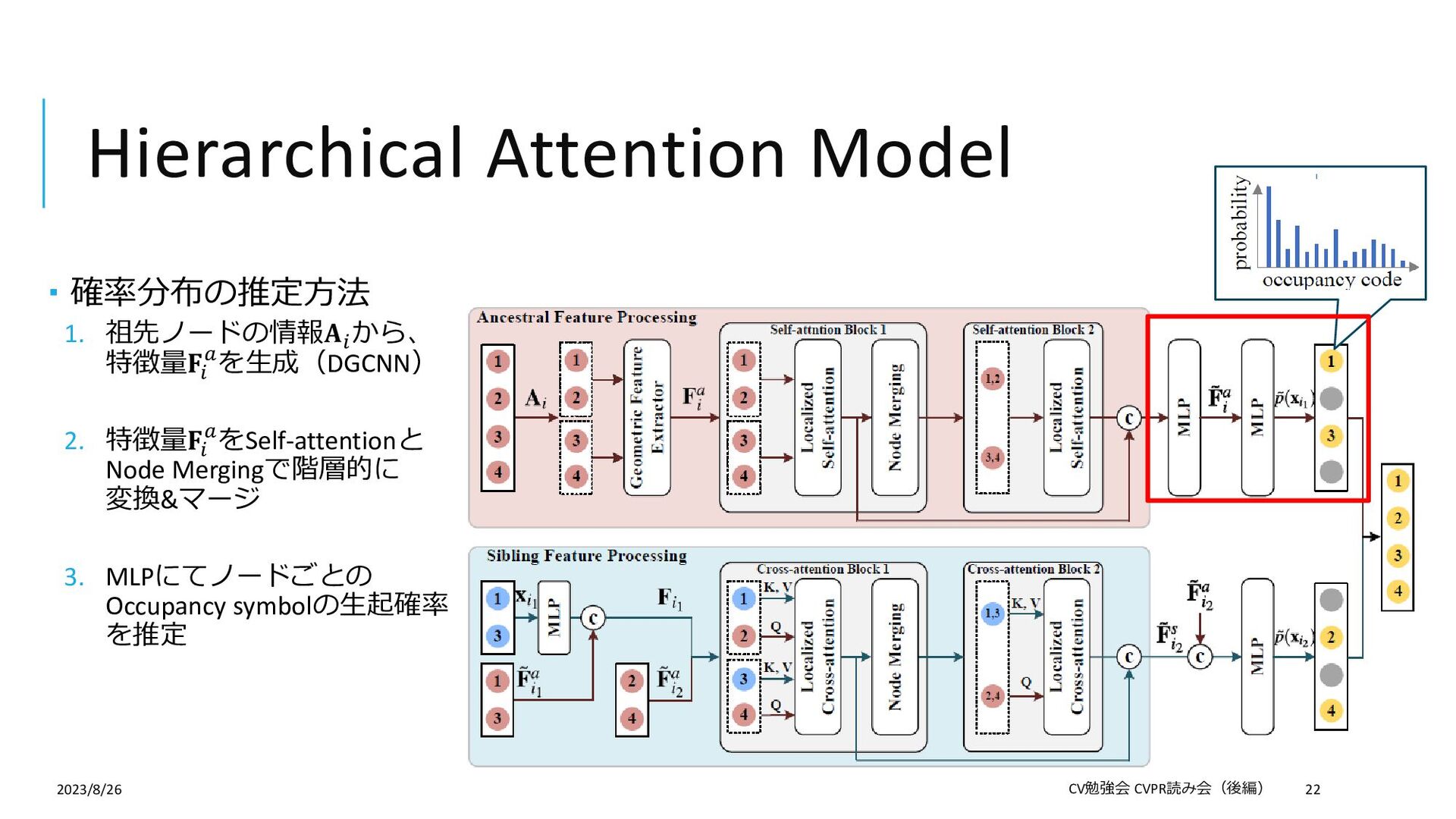{kind=link}
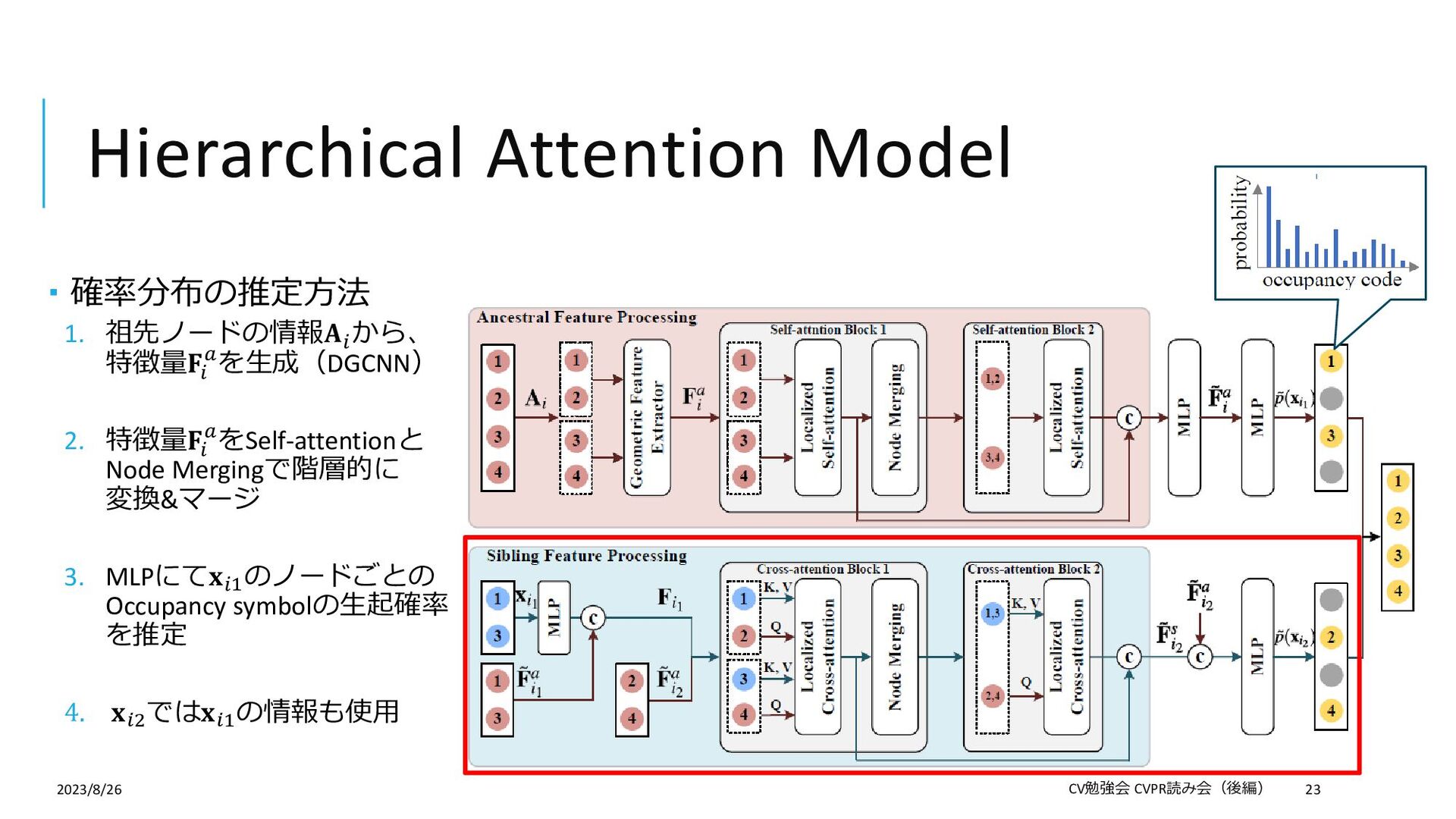{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}