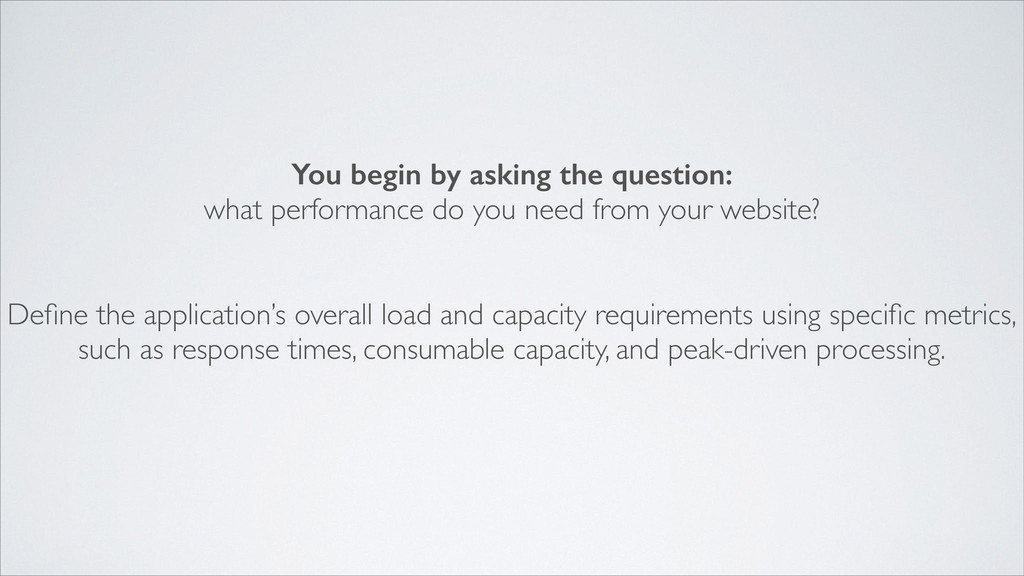
need from your website? Define the application’s overall load and capacity requirements using specific metrics, such as response times, consumable capacity, and peak-driven processing.
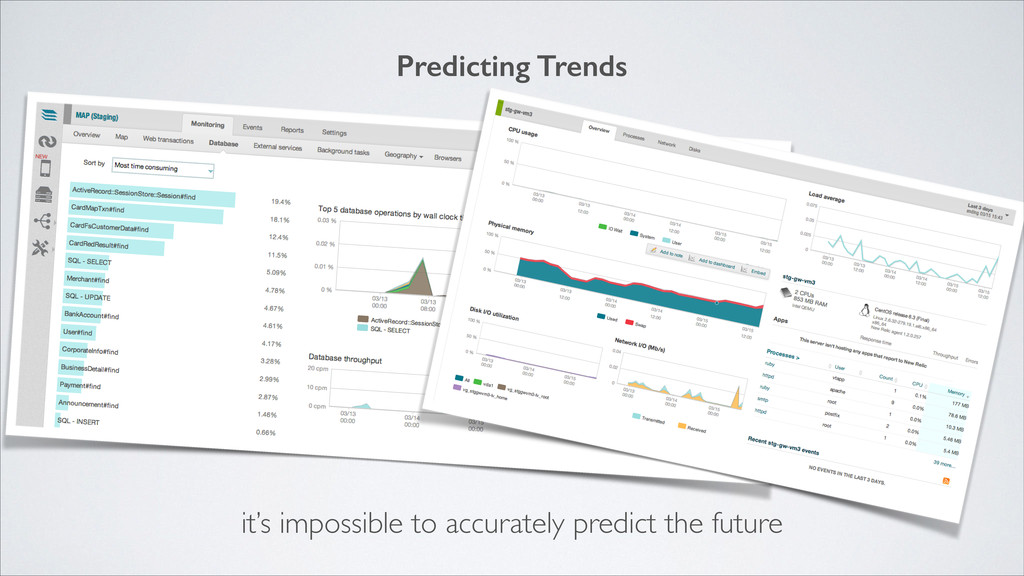
and predictions on a quickly changing landscape, approximations will be necessary, and it’s important to realize what that means in terms of limitations in the process.
we have a database server that responds to queries from your frontend web servers. Planning for capacity means knowing the answers to questions such as these: • Taking into account the specific hardware configuration, how many queries per second (QPS) can the database server manage? • How many QPS can it serve before performance degradation affects end user experience?
which will allow you to set alert thresholds accordingly. • What to expect from adding (or removing) similar database servers to the backend. • When to start sizing another order of new database capacity. Once you find that “red line” metric, you’ll know:
web servers are processing X requests per second is handy, but it’s also good to know what those X requests per second actually mean in terms of your users. ! Maybe X requests per second represents Y number of users employing the site simultaneously. ! It would be even better to know that of those Y simultaneous users, A percent are uploading photos, B percent are making comments on a heated forum topic, and C percent are poking randomly around the site while waiting for the pizza guy to arrive.
your measurements, made snap judgments about usage, and sketched out future predictions, you’ll need to actually buy things: bandwidth, storage appliances, servers, maybe even instances of virtual servers.
is fun, and it’s addictive. But after you spend some time tweaking values, testing, and tweaking some more, it can become a endless hole, sucking away time and energy for little or no gain. Capacity planning must happen without regard to what you might optimize. The first real step in the process is to accept the system’s current performance, in order to estimate what you’ll need in the future. ! If at some point down the road you discover some tweak that brings about more resources, that’s a bonus.
your application’s data will be accessed by yet more applications, each with their own usage and growth patterns. It also means users have a convenient way to abuse the system, which puts more uncertainty into the capacity equation. The Effects of Open APIs
that you should be serving your pages in less than three seconds, you’re going to have a tough time determining how many servers you’ll need to satisfy that requirement. ! More important, it will be even tougher to determine how many servers you’ll need to add as your traffic grows. ! Common sense, right? Yes, but it’s amazing how many organizations don’t take the time to assemble a rudimentary list of operational requirements. Waiting until users complain about slow responses or time-outs isn’t a good strategy.
caching objects like a normal web browser would? Why or why not? Can you determine how much time is spent due to network transfer versus server time, both in the aggregate, and for each object? Can you determine whether a failure or unexpected wait time is due to geographic networkissues or measurement failures?
is, 99.9% uptime stretched over a month isn’t as great a number as one might think: ! 30 days = 720 hours = 43,200 minutes 99.9% of 43,200 minutes = 43,156.8 minutes 43,200 minutes – 43,156.8 minutes = 43.2 minutes
smooth and speedy experience for your users ! For example, when serving static web content, you may reach an intolerable amount of latency at high volumes before any system-level metrics (CPU, disk, memory) raise a red flag ! This can have more to do with the construction of the web page than the capacity of the servers sending the content. !
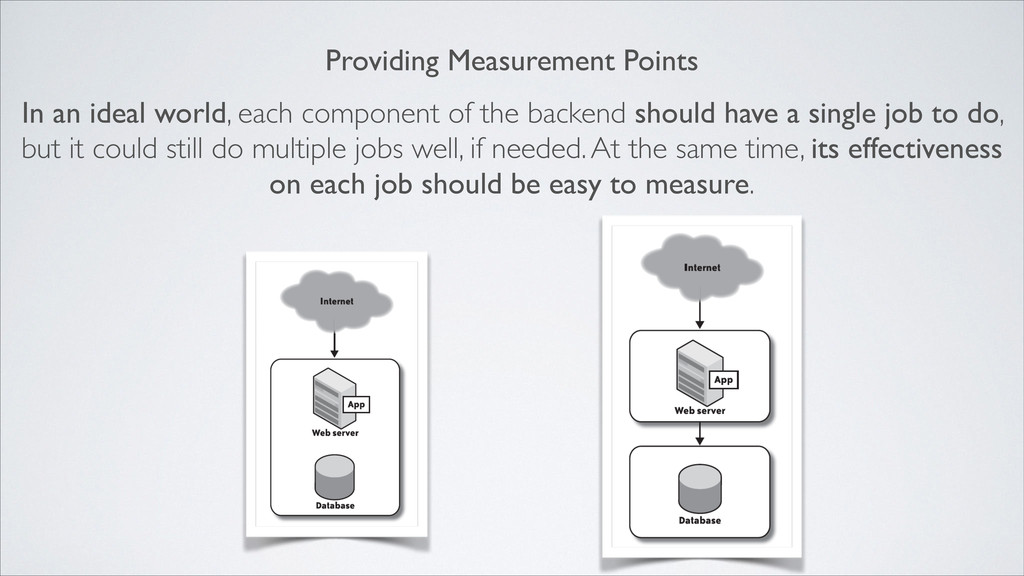
the backend should have a single job to do, but it could still do multiple jobs well, if needed. At the same time, its effectiveness on each job should be easy to measure.
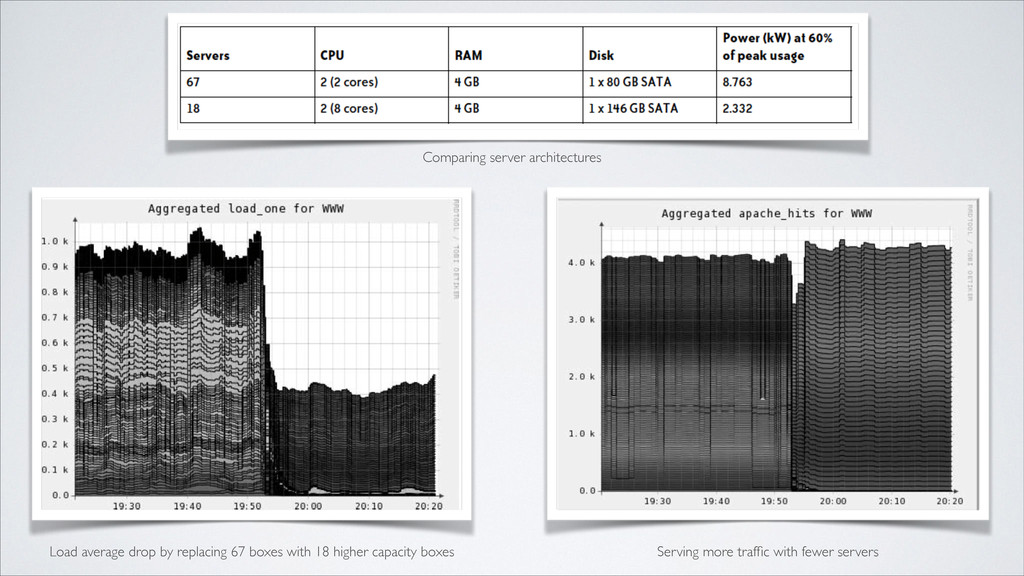
to be disk-bound, so there’s no compelling reason to buy two quad-core CPUs for each database box. Instead, they spend money on more disk spindles and memory to help with filesystem performance and caching. Providing Scaling Points
allows for adding capacity by simply adding similarly functioning nodes to the existing infrastructure. ! Being able to scale vertically is the capability of adding capacity by increasing the resources internal to a server, such as CPU, memory, disk, and network. ! Diagonal scaling is the process of vertically scaling the horizontally scaled nodes you already have in your infrastructure. Hardware Decisions
human-induced catastrophe. ! Examples of such disasters include data center power or cooling outages, as well as physical disasters, such as earthquakes. ! Regardless of the cause, the effect is the same: you can’t serve your website. Disaster Recovery
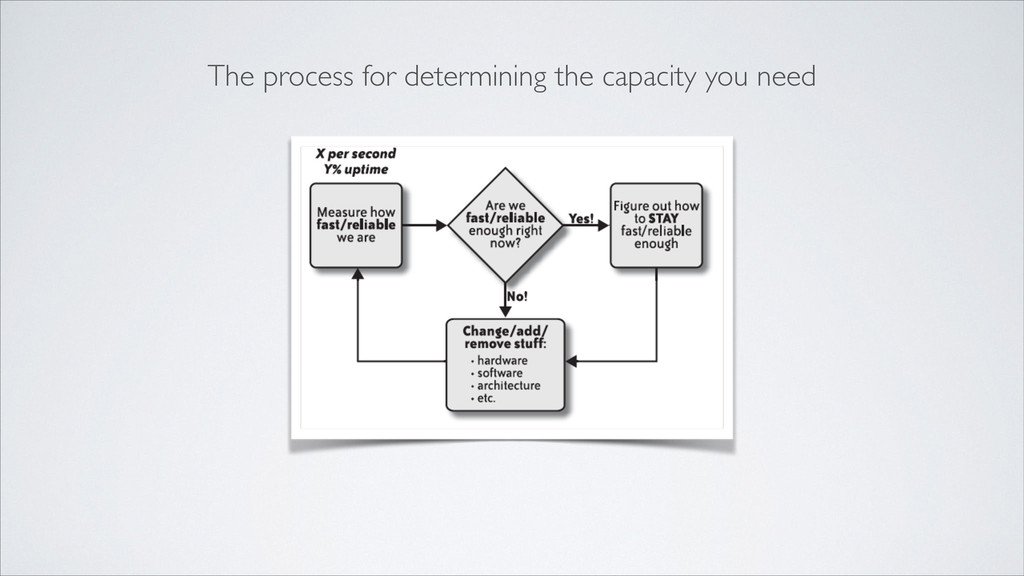
should provide, at minimum, an easy way to: ! • Record and store data over time • Build custom metrics • Compare metrics from various sources • Import and export metrics IF YOU DON’T HAVE A WAY TO MEASURE YOUR CURRENT CAPACITY, YOU CAN’T CONDUCT CAPACITY PLANNING—you’ll only be guessing.
viewed as the eyes and ears of your infrastructure. It can inform all parts of your organization: finance, customer care, engineering, and product management. ! Capacity planning can’t exist without the measurement and history of your system and application-level metrics. ! Planning is also ineffective without knowing your system’s upper performance boundaries so you can avoid approaching them.
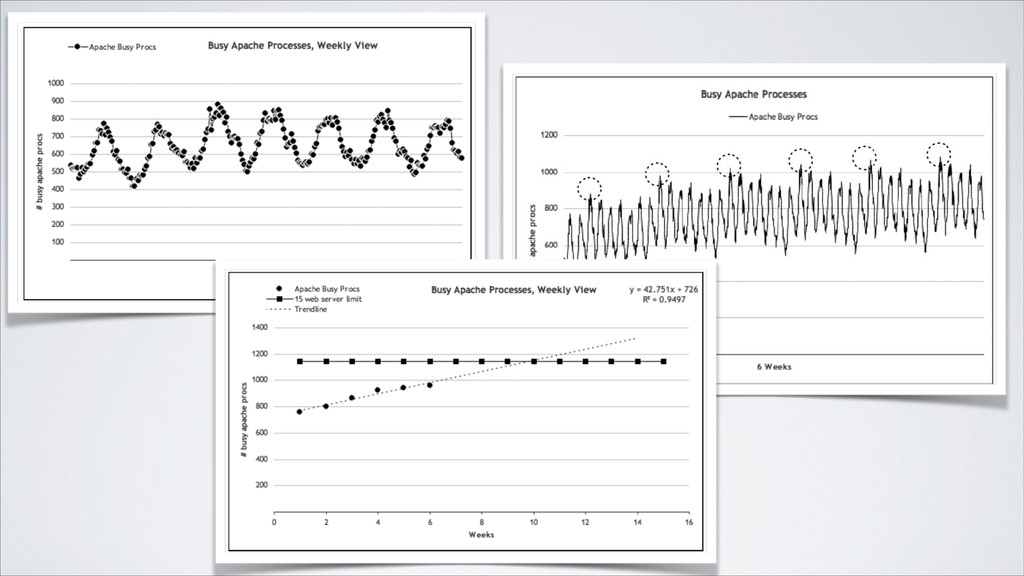
same process: ! 1. Measure and record the server’s primary function. Examples: Apache hits, database queries ! 2. Measure and record the server’s fundamental hardware resources. Examples: CPU, memory, disk, network usage ! 3. Determine how the server’s primary function relates to its hardware resources. Examples: n database queries result in m percent CPU usage ! 4. Find the maximum acceptable resource usage (or ceiling) based on both the server’s primary function and hardware resources by one of the following: • Artificially (and carefully) increasing real production load on the server through manipulated load balancing or application techniques. • Simulating as close as possible a real-world production load.
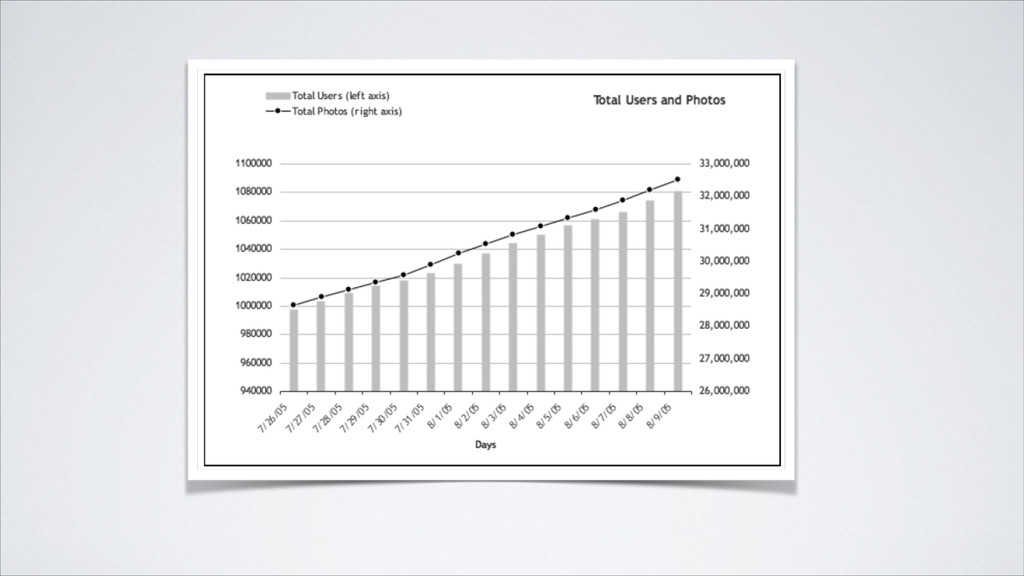
starts in the fall, so there might be increased usage as students browse your site for materials related to their studies (or just to avoid going to class). ! As another example, the holiday season in November and December almost always witness a bump in traffic, especially for sites involving retail sales.
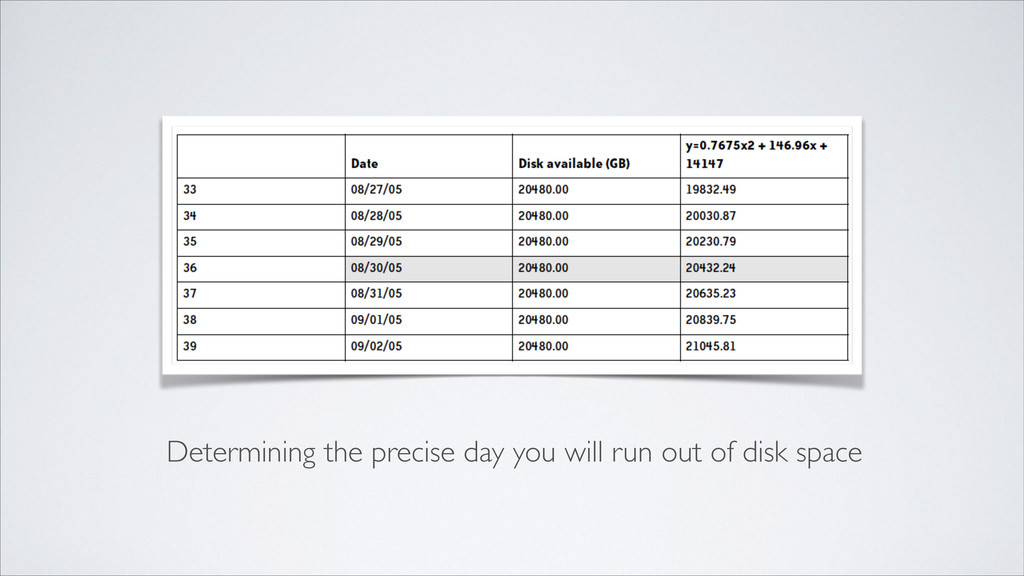
! 1. Determine, measure, and graph your defining metric for each of your resources. Example: disk consumption ! 2. Apply the constraints you have for those resources. Example: total available disk space ! 3. Use trending analysis (curve fitting) to illustrate when your usage will exceed your constraint. Example: find the day you’ll run out of disk space
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}