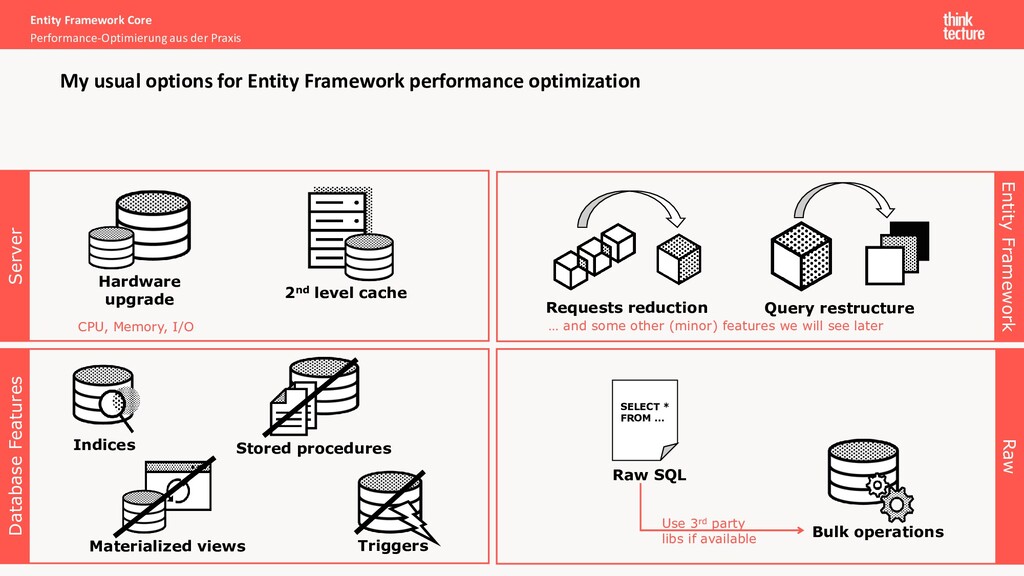
for Entity Framework performance optimization 2nd level cache Hardware upgrade Materialized views Stored procedures Triggers Database Features Server Raw SELECT * FROM … Raw SQL Bulk operations Indices Entity Framework Requests reduction Query restructure … and some other (minor) features we will see later Use 3rd party libs if available CPU, Memory, I/O
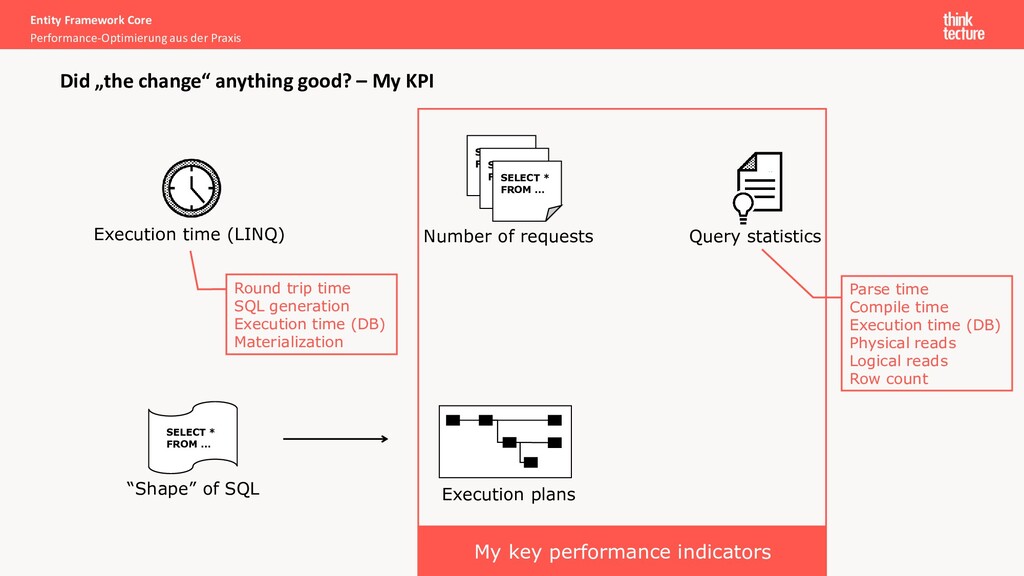
anything good? – My KPI Execution time (LINQ) SELECT * FROM … SELECT * FROM … SELECT * FROM … Number of requests Query statistics SELECT * FROM … “Shape” of SQL Execution plans Parse time Compile time Execution time (DB) Physical reads Logical reads Row count Round trip time SQL generation Execution time (DB) Materialization My key performance indicators
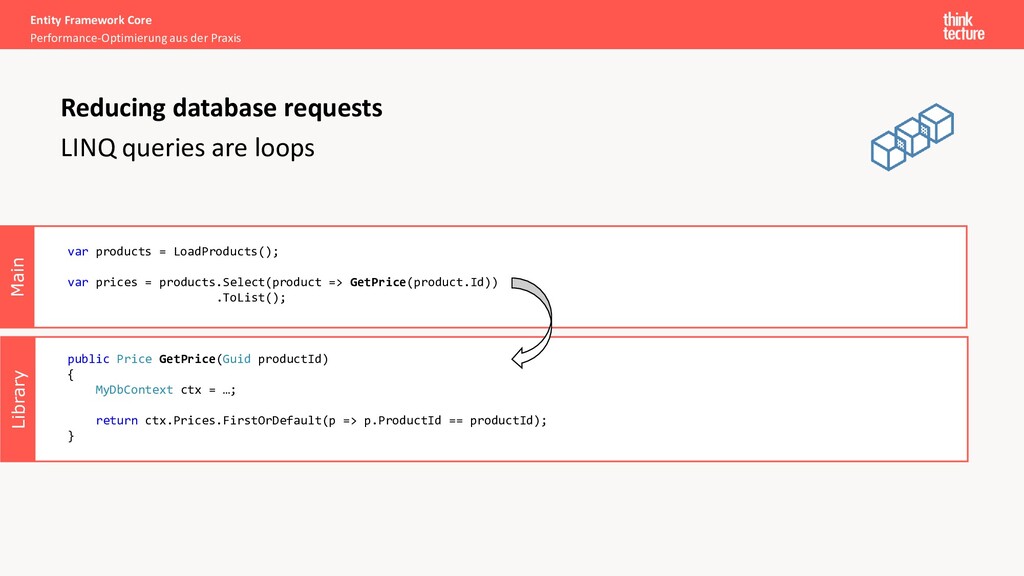
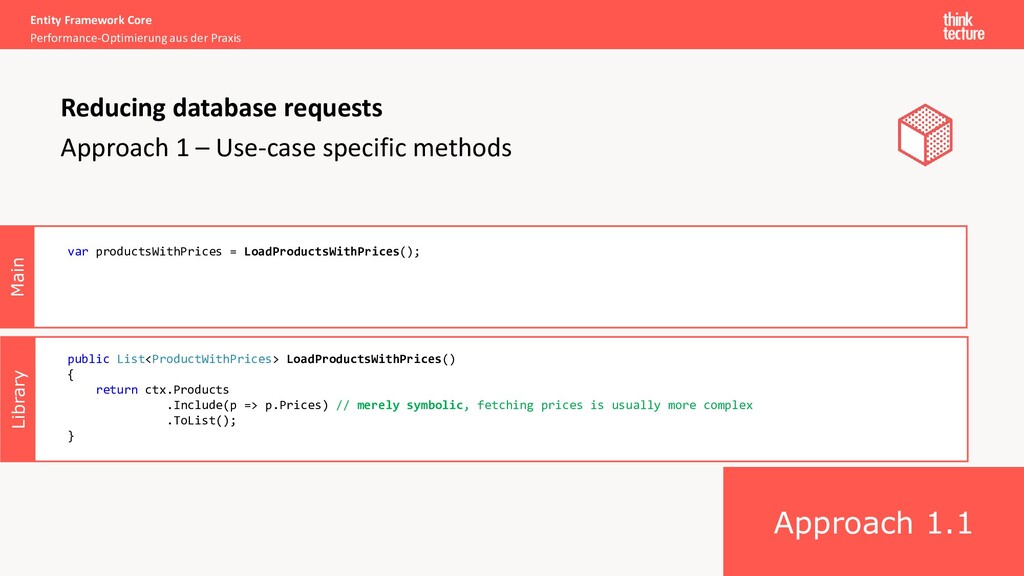
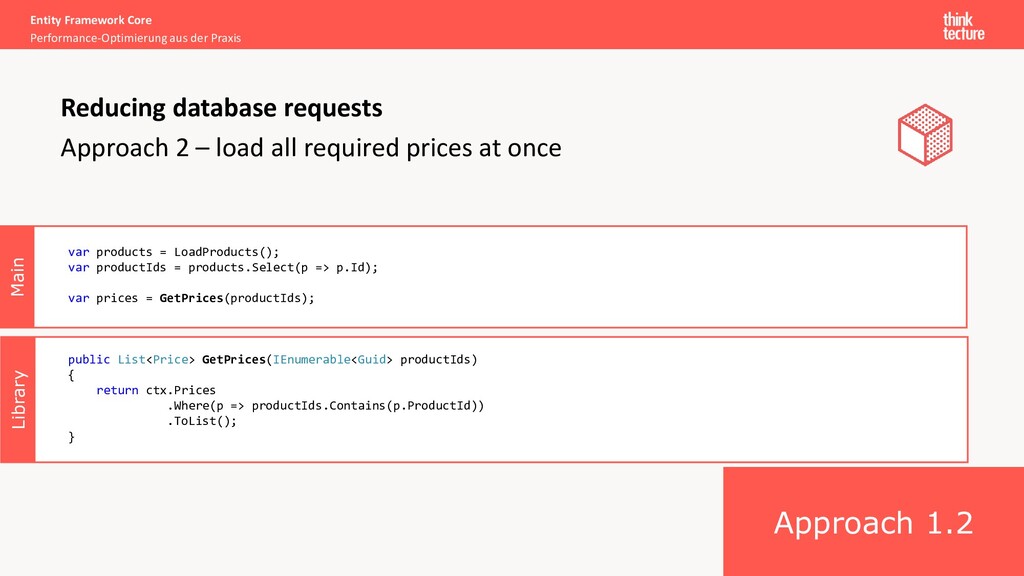
Execution of hundreds of requests for one use case Caused by: unintentional execution of queries in loops Possible solutions: • Better code structure (software architecture) • Avoid overgeneralization (shared/core projects) • Help each other to improve (review/feedback) • Know the insights of Entity Framework • Lazy loading • Limitations Reducing database requests Demos 1.1 + 1.2
loop Library Main Entity Framework Core Performance-Optimierung aus der Praxis Multiple requests in loops Reducing database requests var products = LoadProducts(); var prices = new List<Price>(); foreach (var product in products) { var price = GetPrice(product.Id); prices.Add(price); } public Price GetPrice(Guid productId) { MyDbContext ctx = …; return ctx.Prices.FirstOrDefault(p => p.ProductId == productId); } Executed N times
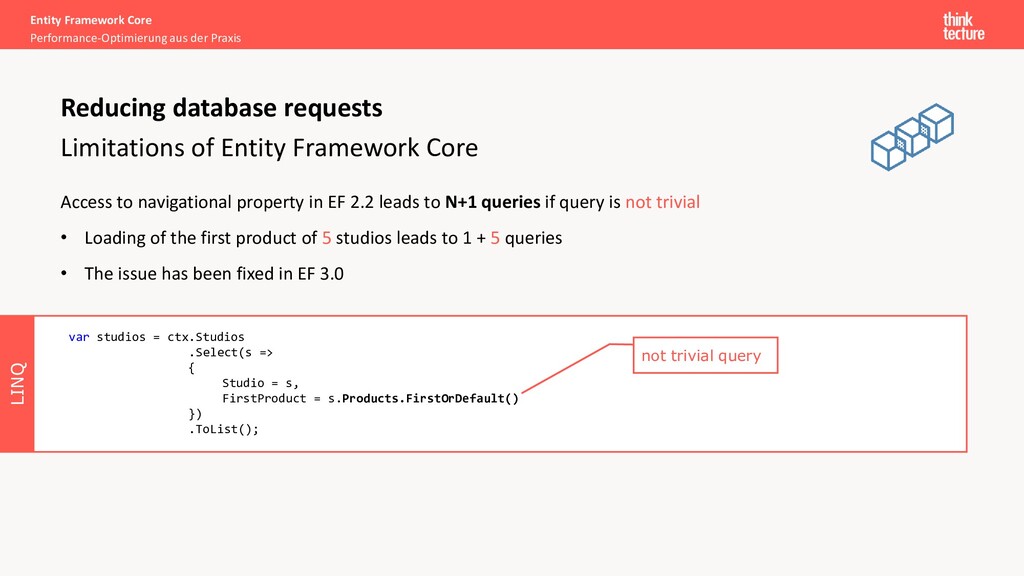
Entity Framework Core Access to navigational property in EF 2.2 leads to N+1 queries if query is not trivial • Loading of the first product of 5 studios leads to 1 + 5 queries • The issue has been fixed in EF 3.0 Reducing database requests var studios = ctx.Studios .Select(s => { Studio = s, FirstProduct = s.Products.FirstOrDefault() }) .ToList(); not trivial query
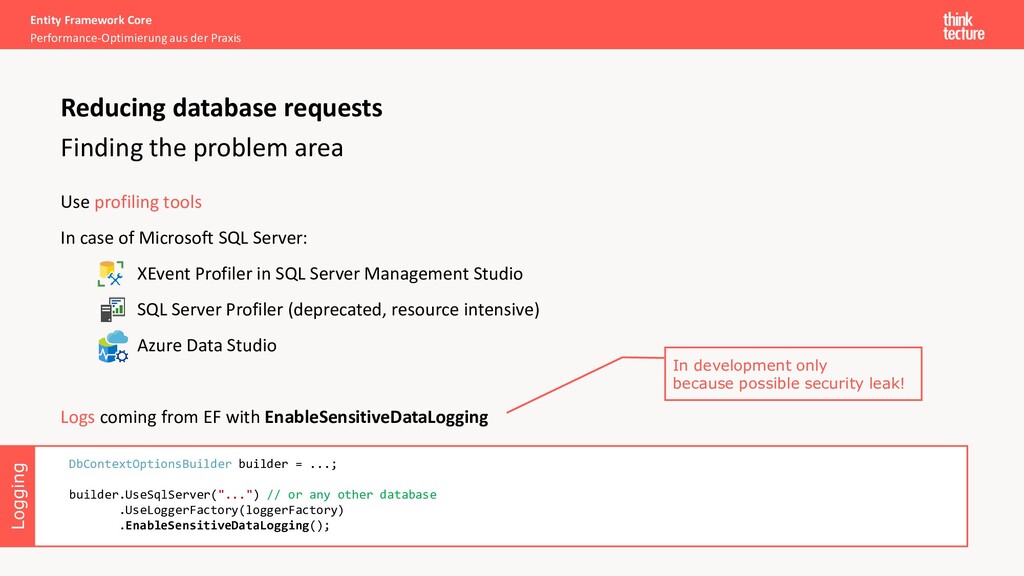
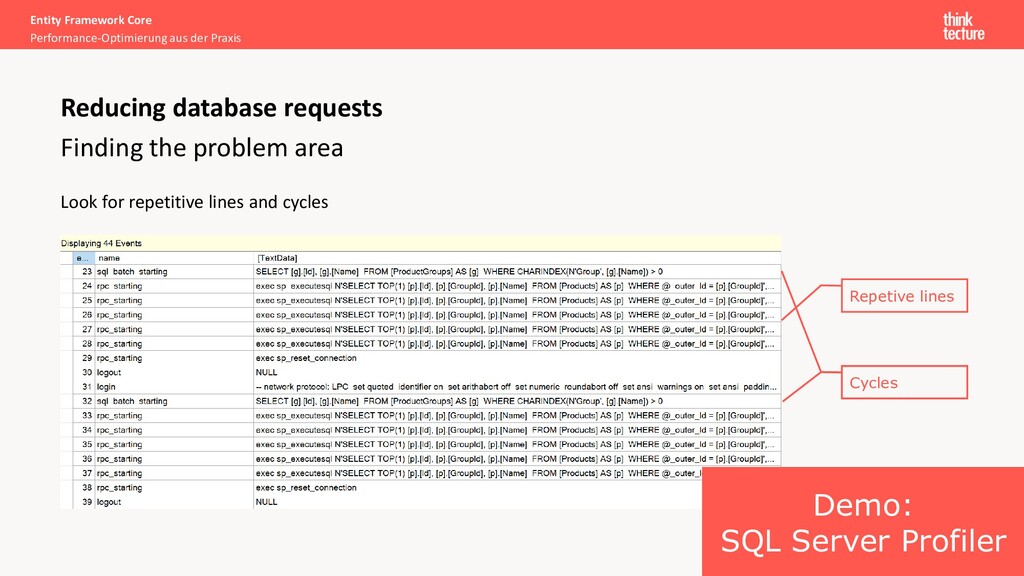
area Use profiling tools In case of Microsoft SQL Server: XEvent Profiler in SQL Server Management Studio SQL Server Profiler (deprecated, resource intensive) Azure Data Studio Logs coming from EF with EnableSensitiveDataLogging Reducing database requests Logging DbContextOptionsBuilder builder = ...; builder.UseSqlServer("...") // or any other database .UseLoggerFactory(loggerFactory) .EnableSensitiveDataLogging(); In development only because possible security leak!
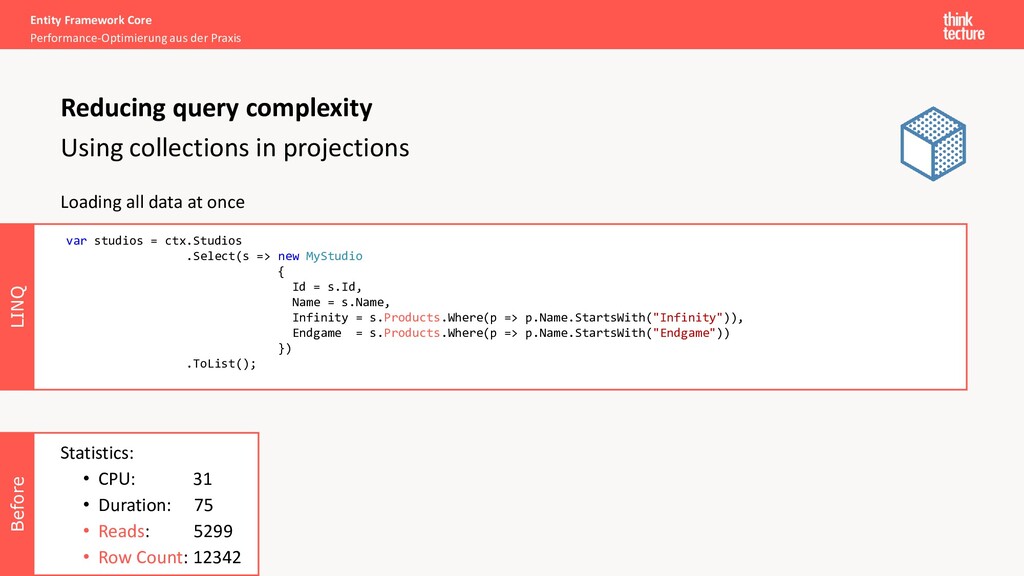
Fetching a lot of data from multiple tables at once • Increased memory consumption and execution time • High I/O load Caused by: loading of multiple navigational collection-properties Possible solutions: • Reduce Includes (eager loading) • Reduce access to navigational properties in projections (i.e. Select) Reducing query complexity Query splitting Demo 2.1
Include EF 2.2 is loading collections separately EF 3.0 loads all data using 1 SQL statement • Bigger result sets: 100 products with 10 prices each and 2 sellers (100 * 10 * 2) rows > (100 + 1000 + 2) records • EF-forced ORDER BY clause produces considerable load Reducing query complexity Product Id Price Id Seller Id 1 1 1 1 1 2 1 1 3 1 2 1 1 2 2 1 2 3 SQL LINQ var products = ctx.Products .Include(p => p.Studio) .Include(p => p.Prices) .Include(p => p.Sellers) .ToList(); SELECT * FROM Products INNER JOIN Studios ... LEFT JOIN Prices ON ... LEFT JOIN Sellers ON ... ... ORDER BY Products.Id, Prices.Id, Sellers.Id Cartesian explosion
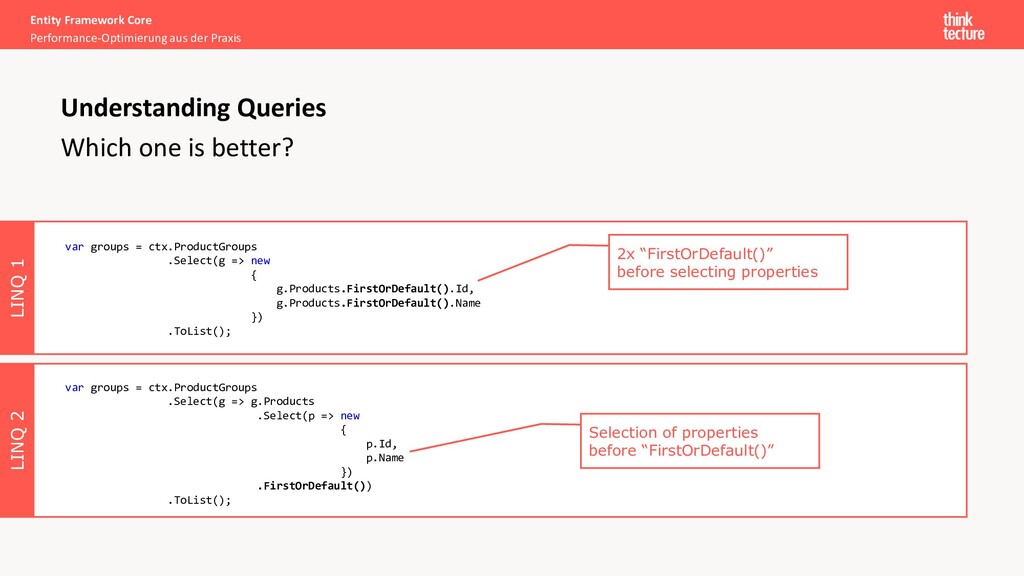
Praxis Which one is better? Understanding Queries var groups = ctx.ProductGroups .Select(g => new { g.Products.FirstOrDefault().Id, g.Products.FirstOrDefault().Name }) .ToList(); var groups = ctx.ProductGroups .Select(g => g.Products .Select(p => new { p.Id, p.Name }) .FirstOrDefault()) .ToList(); 2x “FirstOrDefault()” before selecting properties Selection of properties before “FirstOrDefault()”
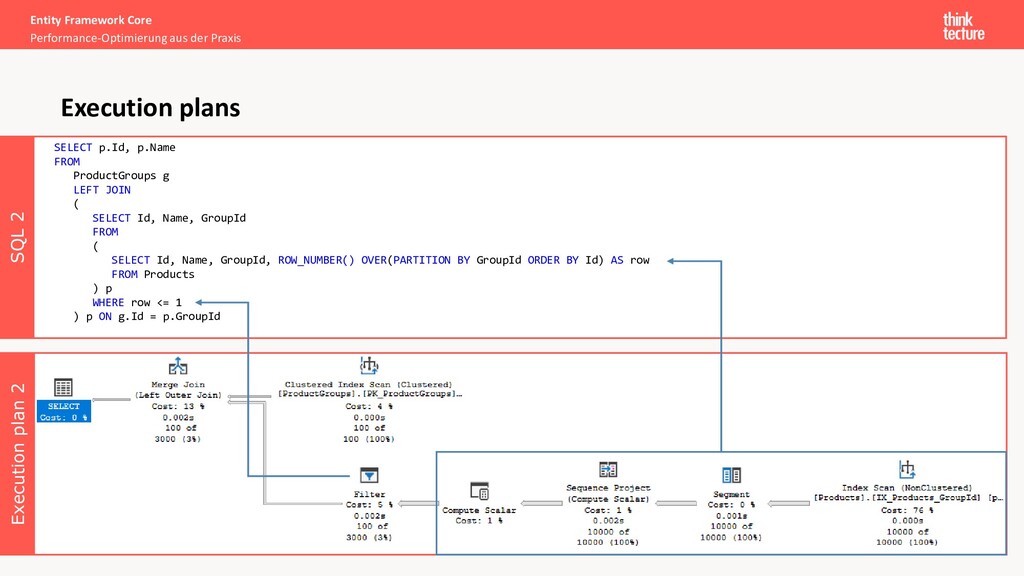
Praxis Lets try with SQL … Understanding Queries SELECT ( SELECT TOP(1) p.Id FROM Products p WHERE g.Id = p.ProductGroupId ) AS FirstProductId, ( SELECT TOP(1) p.Name FROM Products p WHERE g.Id = p.ProductGroupId ) AS FirstProductName FROM ProductGroups g SELECT p.Id, p.Name FROM ProductGroups g LEFT JOIN ( SELECT Id, Name, ProductGroupId FROM ( SELECT Id, Name, ProductGroupId, ROW_NUMBER() OVER(PARTITION BY ProductGroupId ORDER BY Id) AS row FROM Products ) p WHERE row <= 1 ) p ON g.Id = p. ProductGroupId 2 sub-selects Window function “ROW_NUMBER”
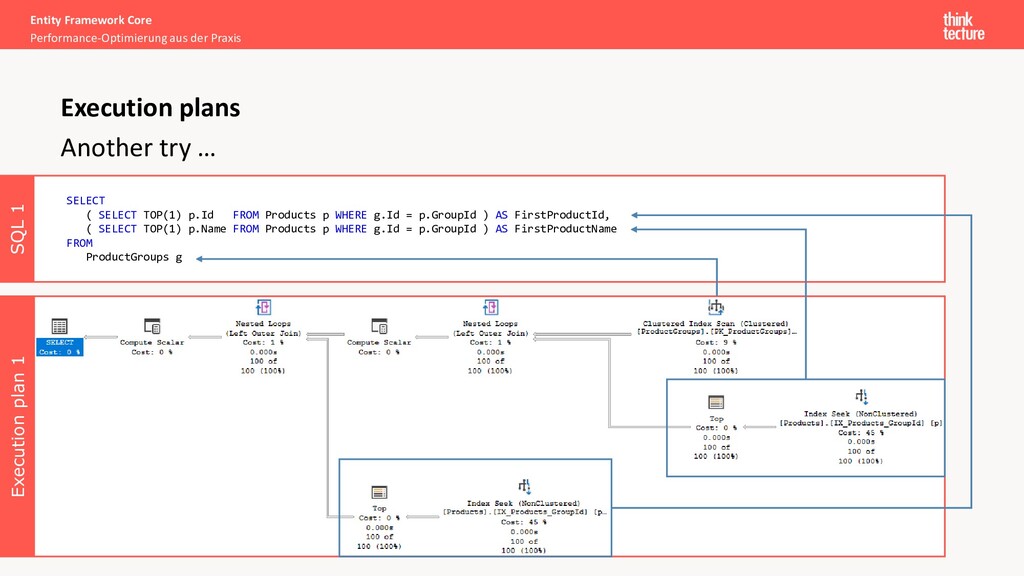
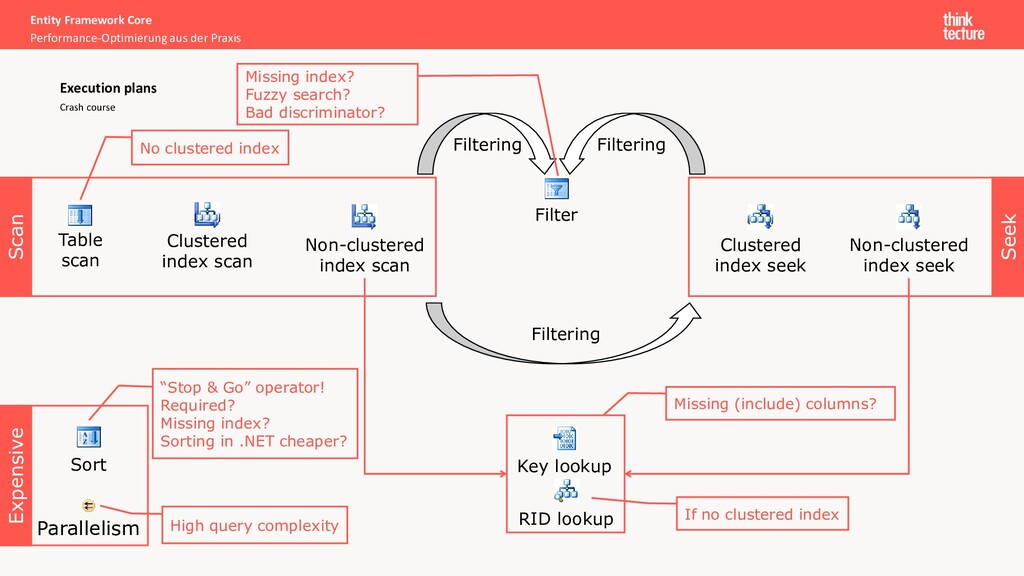
all database operations • Type and the order of operations (JOIN, filter, projection, ...) • Indexes being used • Amount of data flowing between two operations • Costs of an operation and a subtree Some tools have built-in support for displaying execution plans as a graph Execution plans
Execution plans Execution plan 1 SQL 1 SELECT ( SELECT TOP(1) p.Id FROM Products p WHERE g.Id = p.GroupId ) AS FirstProductId, ( SELECT TOP(1) p.Name FROM Products p WHERE g.Id = p.GroupId ) AS FirstProductName FROM ProductGroups g
plan 2 SQL 2 SELECT p.Id, p.Name FROM ProductGroups g LEFT JOIN ( SELECT Id, Name, GroupId FROM ( SELECT Id, Name, GroupId, ROW_NUMBER() OVER(PARTITION BY GroupId ORDER BY Id) AS row FROM Products ) p WHERE row <= 1 ) p ON g.Id = p.GroupId
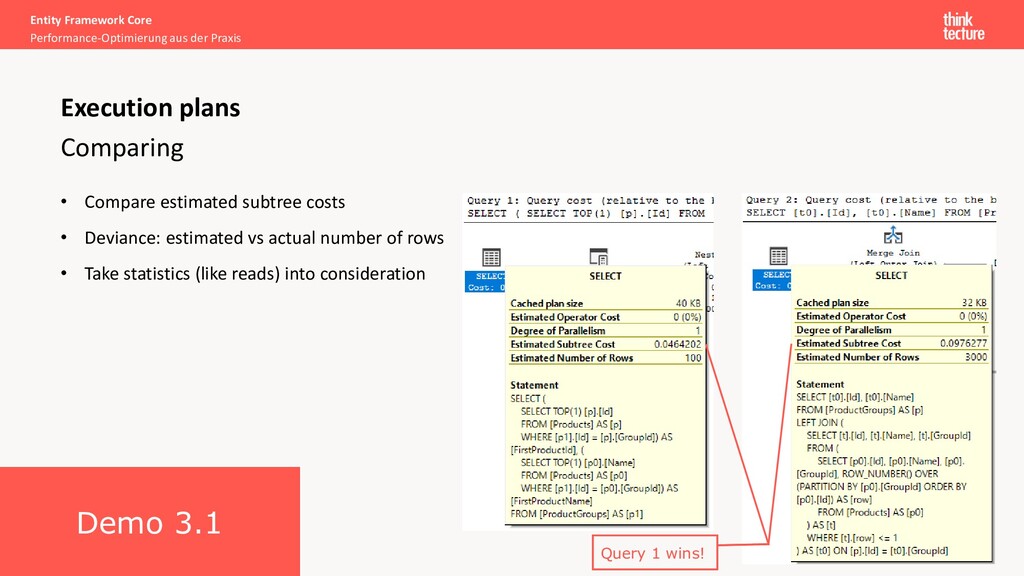
estimated subtree costs • Deviance: estimated vs actual number of rows • Take statistics (like reads) into consideration Execution plans Query 1 wins! Demo 3.1
course Table scan Clustered index scan Non-clustered index scan Clustered index seek Non-clustered index seek Scan No clustered index Seek Filter Filtering Filtering Filtering Key lookup Missing (include) columns? RID lookup If no clustered index Sort “Stop & Go” operator! Required? Missing index? Sorting in .NET cheaper? Parallelism Expensive High query complexity Missing index? Fuzzy search? Bad discriminator?
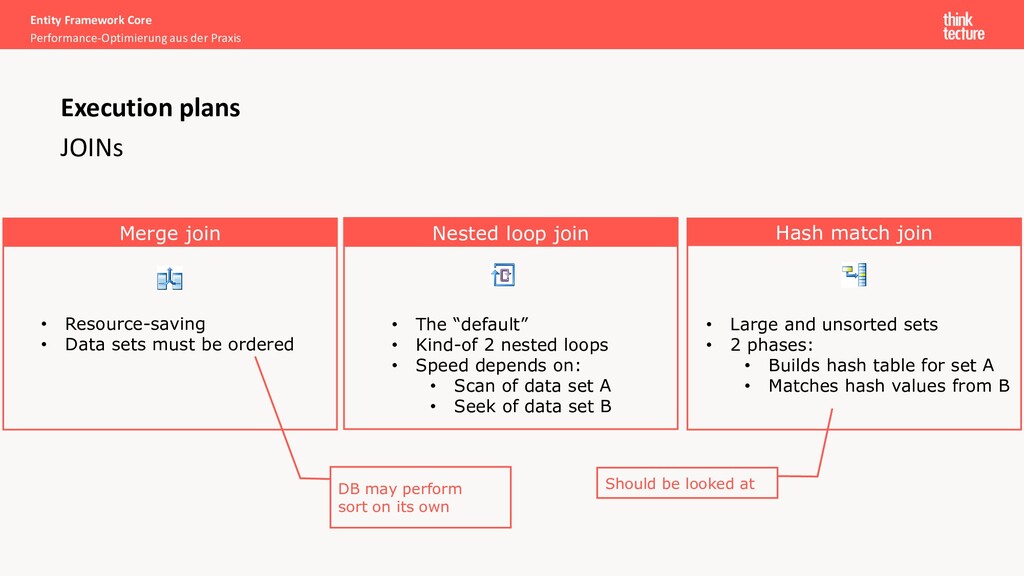
DB may perform sort on its own • Resource-saving • Data sets must be ordered • The “default” • Kind-of 2 nested loops • Speed depends on: • Scan of data set A • Seek of data set B • Large and unsorted sets • 2 phases: • Builds hash table for set A • Matches hash values from B Should be looked at Merge join Nested loop join Hash match join
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}