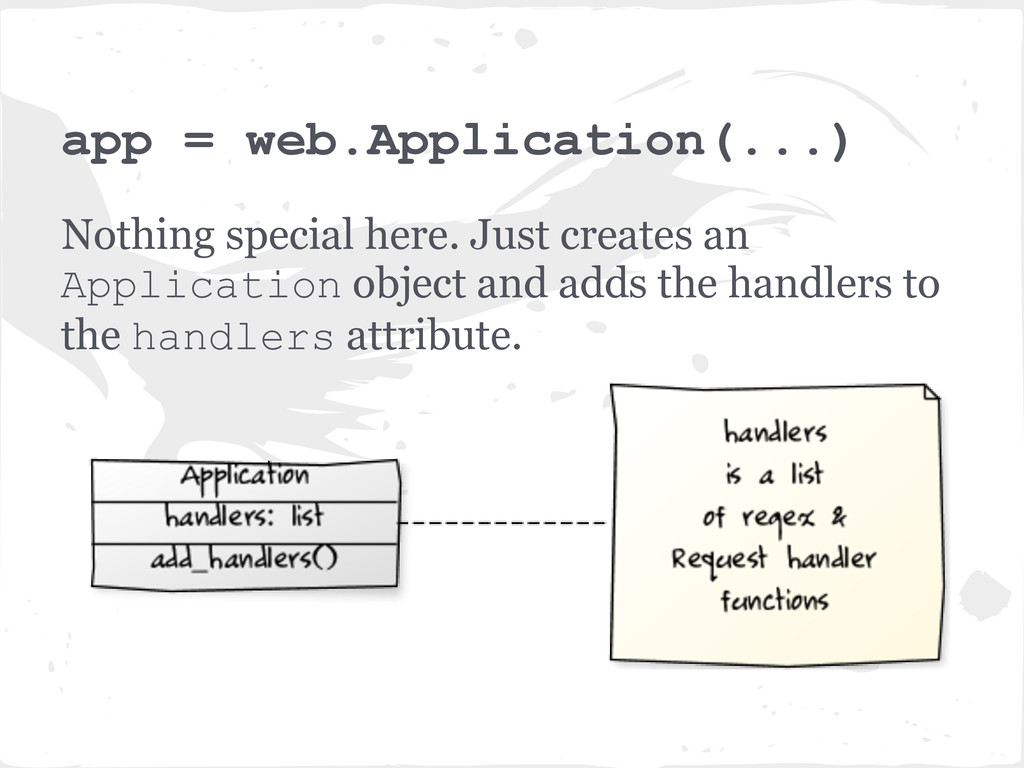
Also a minimal Web Application Framework. Written in Python. Open source - Apache V2.0 license. • Originally built by FriendFeed (acquired by Facebook). "The framework is distinct from most mainstream web server frameworks (and certainly most Python frameworks) because it is non- blocking and reasonably fast. Because it is non-blocking and uses epoll or kqueue, it can handle thousands of simultaneous standing connections, which means it is ideal for real-time web services." - Tornado Web Server Home page blurb.
what happens at every step of the way. All the way from how the server is setup to how the entire request-response cycle works under the hood. • But first a little bit of background about sockets and poll.
known as sockets. Socket is an object similar to a file that allows a program to accept incoming connection, make outgoing connections, and send and receive data. Before two machines can communicate, both must create a socket object. The Python implementation just calls the system sockets API. • For more info $ man socket
of IP address and port • Address family - controls the OSI network layer protocol, for example AF_INET for IPv4 Internet sockets using IPv4. • Socket type - controls the transport layer protocol, SOCK_STREAM for TCP.
INET, STREAMing socket s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) #now connect to the web server on port 8080 s.connect(("www.mcmillan-inc.com", 8080))
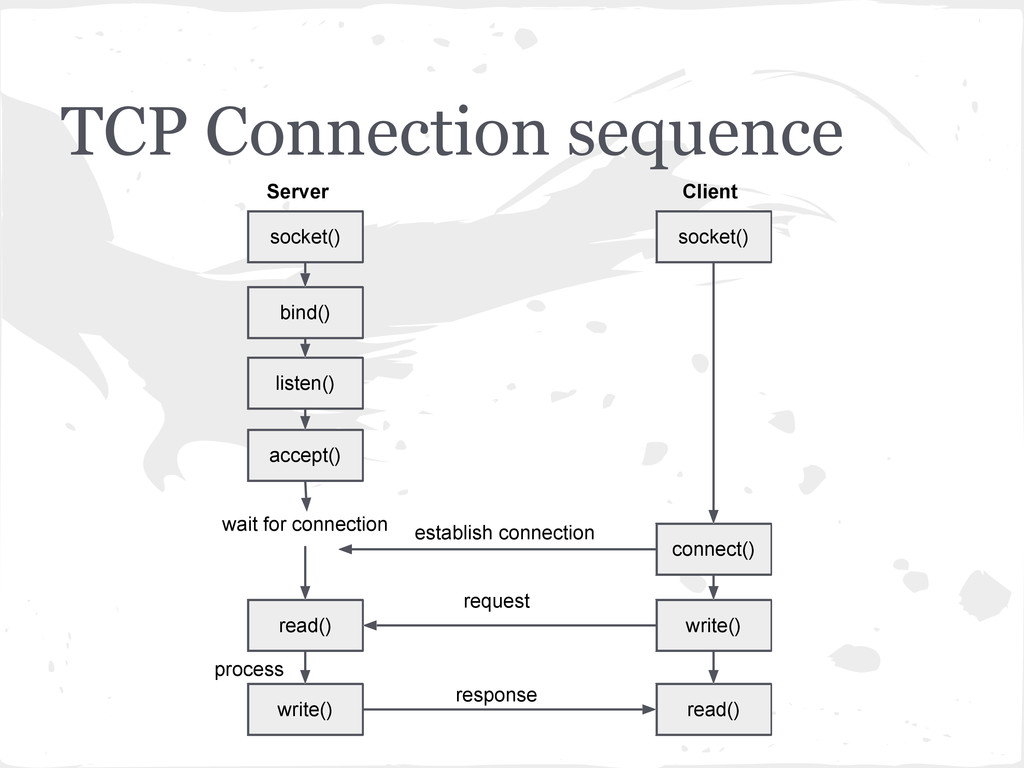
INET, STREAMing socket serversocket = socket.socket(socket.AF_INET, socket.SOCK_STREAM) #bind the socket to a public host,and a well-known port serversocket.bind('localhost', 8080)) #become a server socket serversocket.listen(5) while True: #accept connections from outside (clientsocket, address) = serversocket.accept() #do something. In this case assume in a different thread ct = client_thread(clientsocket) ct.run()
It doesn’t receive any data. It just produces client sockets. Each client socket is created in response to some other client socket doing a connect() to the host and port we’re bound to. As soon as we’ve created that client socket, we go back to listening for more connections. The two clients are free to chat it up - they are using some dynamically allocated port which will be recycled when the conversation ends.” - Gordon McMillan in Socket Programming HOWTO
to handle client socket • create a new process to handle client socket • Use non-blocking sockets, and mulitplex between our server socket and any active client sockets using select.
socket API calls will block indefinitely until the requested action (send, recv, connect or accept) has been performed. • Non-blocking sockets - send, recv, connect and accept can return immediately without having done anything. • In Python, you can use socket. setblocking(0) to make a socket non- blocking.
choices. You can check return code and error codes and generally drive yourself crazy. If you don’t believe me, try it sometime. Your app will grow large, buggy and suck CPU. So let’ s skip the brain-dead solutions and do it right. … Use select.” Gordon McMillan - Author of Socket Programming HOWTO & creator of PyInstaller
monitor multiple file descriptors, waiting until one or more of the file descriptors become "ready" for some class of I/O operation • More info $ man select • Python’s select() function is a direct interface to the underlying operating system implementation.
only requires listing the file descriptors of interest, while select() builds a bitmap, turns on bits for the fds of interest, and then afterward the whole bitmap has to be linearly scanned again. • select() is O(highest file descriptor), while poll() is O(number of file descriptors).
• Register a fd and the events of interest to be notified about p.register(fd, events) • Start monitoring. You will be notified if there is an event of interest on any of the registered fd's. p.poll([timeout])
So epoll is O(active fd's), poll is O (registered fd's) • So epoll faster than poll (there is debate about exactly how much faster, but let's not get into that ... because I have no idea). • Provides exactly same API as poll. • Tornado tries to use epoll or kqueue and falls back to select if it cannot find them.
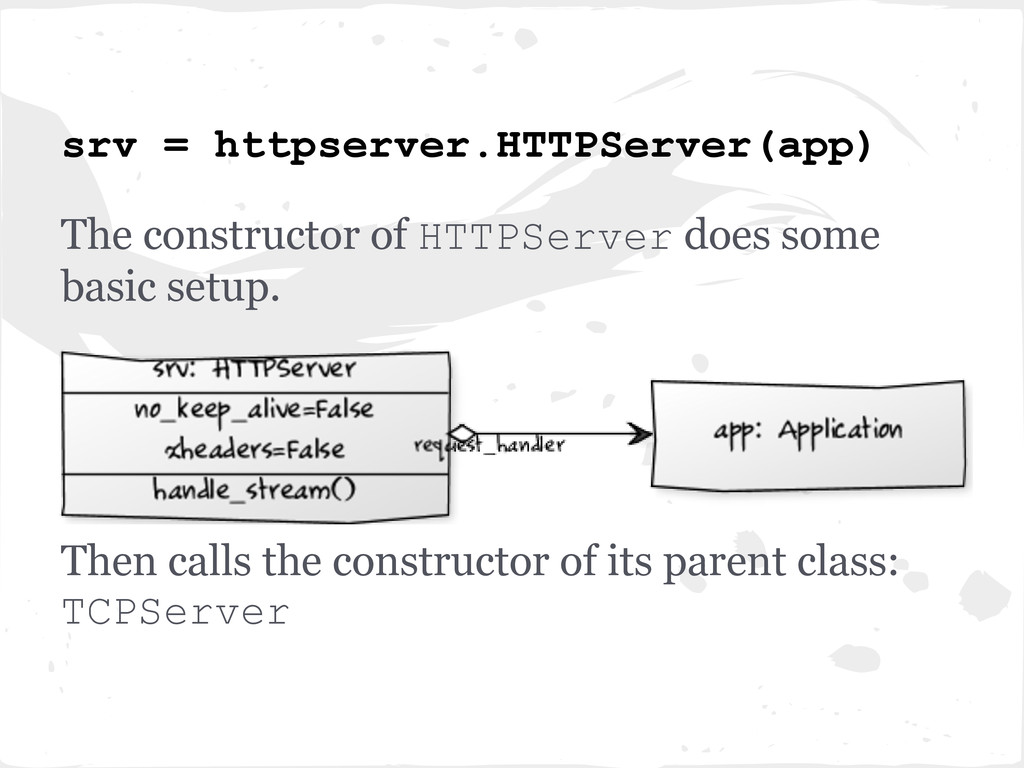
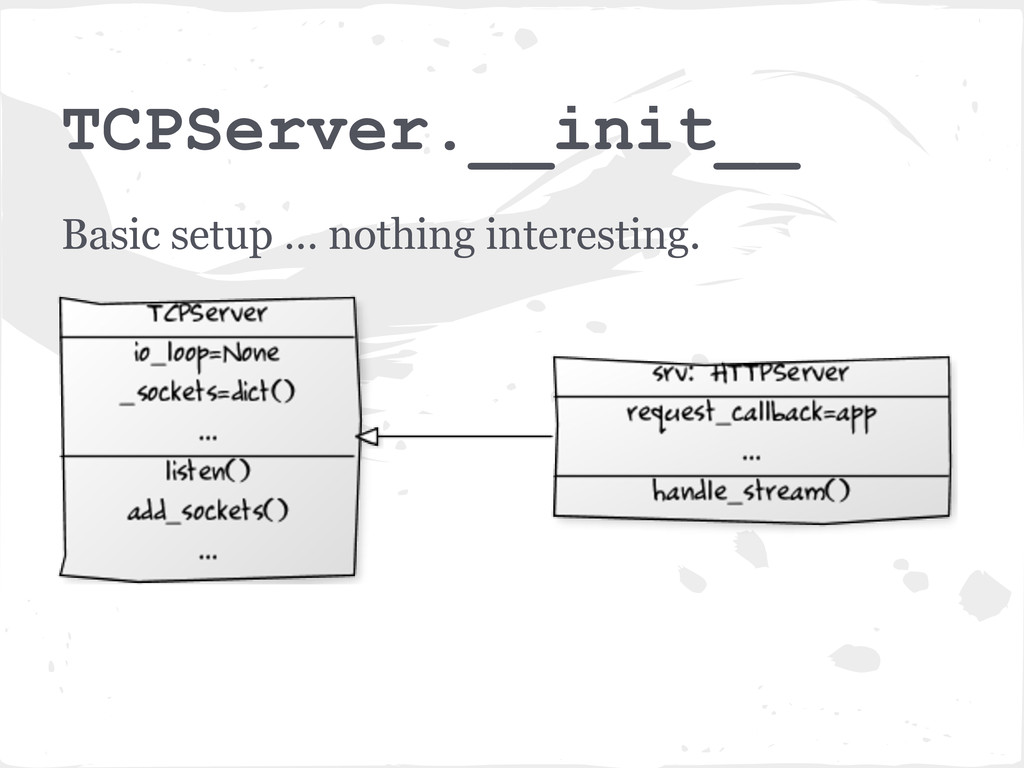
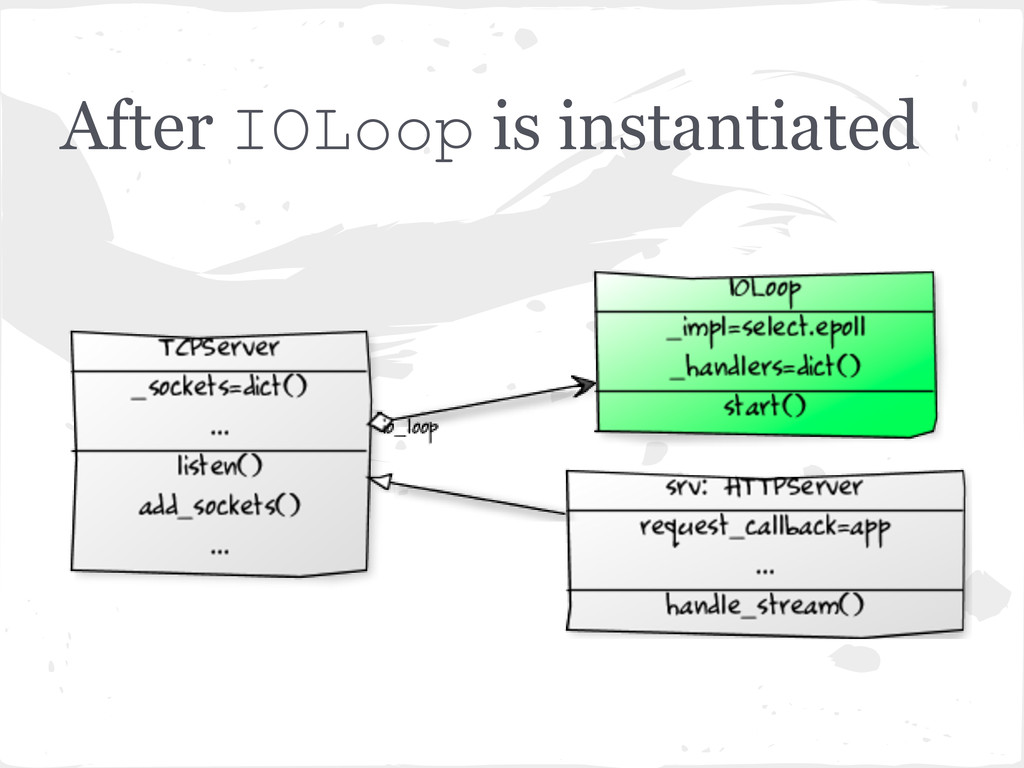
listening server socket (or sockets) bound to the given address and port (in this case localhost:8080). • Then creates an instance of the IOLoop object self.io_loop = IOLoop.instance()
• We will register the file descriptors of the server sockets with this epoll object to monitor for events on the sockets. (will be explained shortly).
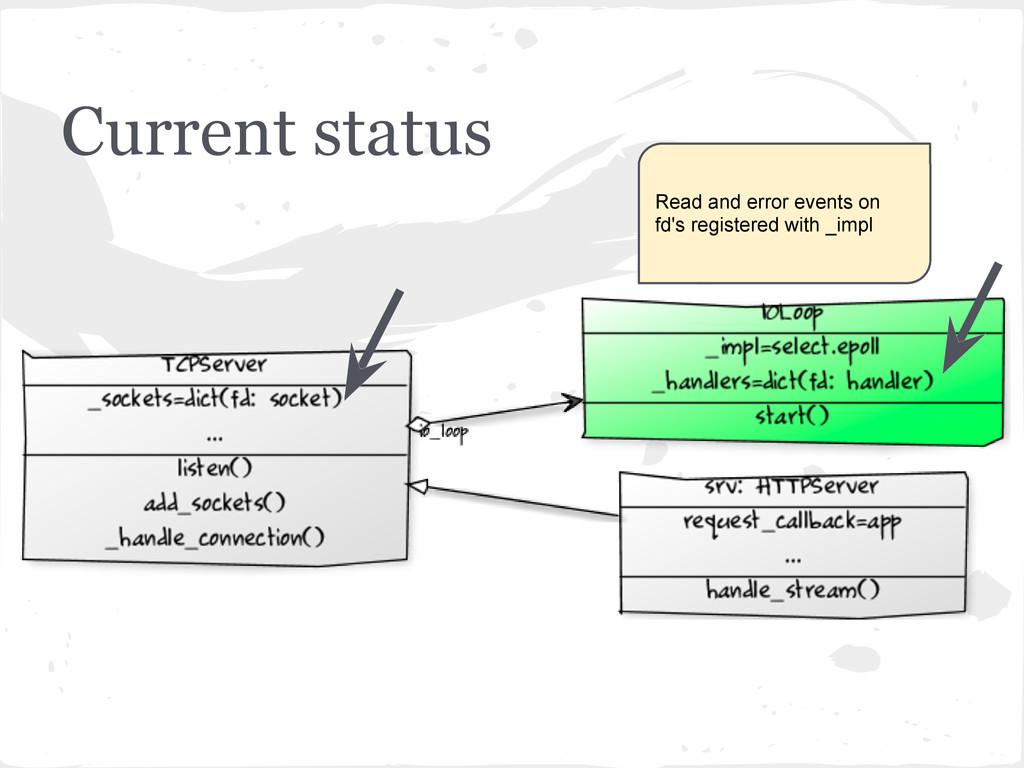
in the _sockets dict - {fd: socket} • An accept_handler function is created for each socket and passed to the IOLoop.add_handlers() method. • accept_handler is a thin wrapper around a callback function which just accepts the socket (socket. accept()) and then runs the callback function. • In this case the callback function is the _handle_connection method of the TCPServer. More on this later.
to keeps track of which handler function needs to be called when a client tries to establish a connection. • Registers the fd (file descriptor) and data input and error events for the corresponding socket with IOLoop._impl (the epoll object).
the heartbeat and the nerve center of everything. • Continually runs any callback functions, callbacks related to any timeouts, and then runs poll() method on self._impl the epoll object for any new data input events on the socket. • Note: A connect() request from a client is considered as an input event on a server socket. • There is logic in here to send signals to wake up the I/O loop from idle state, ways to run periodic tasks using timeouts etc. which we won't get into.
connect() is captured by the poll() method in the IOLoop's start() method. • The server runs the accept_handler which accept()'s the connection, then immediately runs the associated callback function. • Remember that accept_handler is a closure that wraps the callback with logic to accept() the connection, so accept_handler knows which callback function to run. • The callback function in this case is _handle_connection method of TCPServer
wrapper around non- blocking sockets which provides utilities to read from and write to those sockets. • Then calls HTTPServer.handle_stream (...)and passes it the IOStream object and the client socket address.
app as a request_callback. • HTTPConnection handles a connection to an HTTP client and executes HTTP requests. Has methods to parse HTTP headers, bodies, execute callback tasks etc.
the IOStream object. self.stream.read_until(b("\r\n\r\n"), self._header_callback) • _header_callback is _on_headers method of HTTPConnection. (We'll get to that in a moment).
methods. Finally once the headers are read and parsed, invokes _run_callback method. Invokes the socket. recv() methods. • Call back is not executed right away, but added to the IOLoop instance to be called in the next cycle of the IO loop. self.io_loop.add_callback(wrapper) • wrapper is just a wrapper around the callback with some exception handling. Remember, our callback is _on_headers method of HTTPConnection object
have parsed the headers). • Then calls the request_callback and passes the HTTPRequest. Remember this? May be you don't after all this ... request_callback is the original app we created. • Whew! Light at the end of the tunnel. Only a couple more steps.
method. So you can just call an application. • The __call__ method looks at the url in the HTTPRequest and invokes the _execute method of appropriate RequestHandler - the MainHandler in our example.
• In our case get method calls write() and writes the "Hello World" string. • Then calls finish() method which prepares response headers and calls flush() to write the output to the socket and close it.
to the request, which in turn delegates it to the HTTPConnection which in turn delegates it to the IOStream. • IOStream adds this write method to the IOLoop. _callbacks list and the write is executed in turn during the next iteration of IOLoop. • Once everything is done, the socket is closed (unless of course you specify that it stay open).
a process. • We did not spawn a thread. • Everything happens in just one thread and is multiplexed using epoll.poll() • Callback handlers are run one at a time, in turn, on a single thread. • If a callback task (in the RequestHandler) is long running, for example a database query that takes too long, the other requests which are queued behind will suffer.
handler asynchronous, and keep the connection open so that other requests do not suffer. • But you have to close the connection yourself. • See the chat example in the source code.
in 2.x and only option in 1.3. • The main Apache process will at startup create multiple child processes. When a request is received by the parent process, it will be processed by whichever of the child processes is ready.
a number of worker threads. • The request may be processed by a worker thread within a child process which already has other worker threads handling other requests at the same time.
maintaining the other processes which are essentially idle when the request load is low. Tornado does not have this overhead. • Tornado natively allows you to use websockets. Experimental support in apache with apache-websocket module. • Scalability - There are arguments for both sides. Personally I haven't built anything that cannot be scaled by Apache. So no idea if one is better than the other.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}