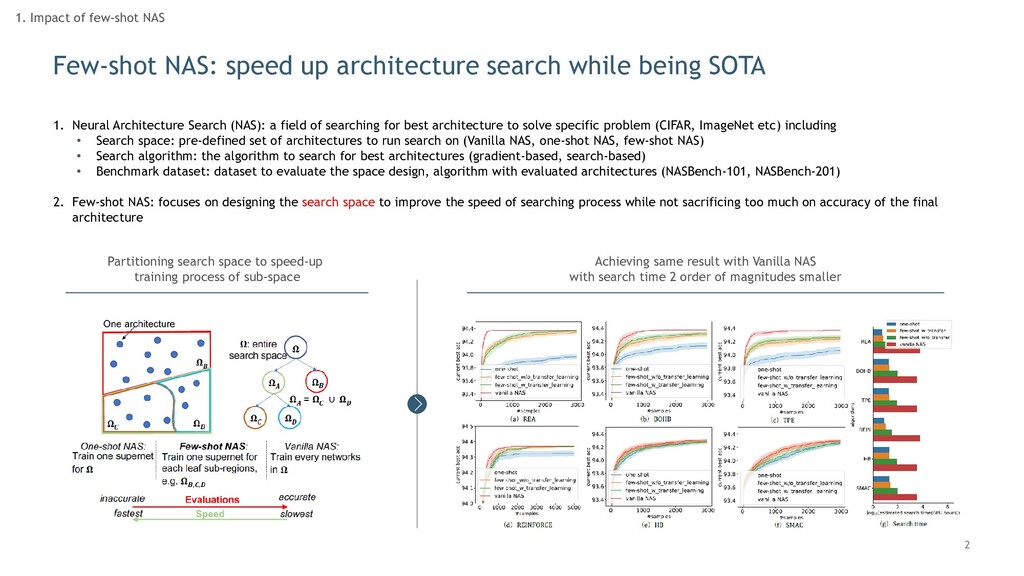
1. Neural Architecture Search (NAS): a field of searching for best architecture to solve specific problem (CIFAR, ImageNet etc) including • Search space: pre-defined set of architectures to run search on (Vanilla NAS, one-shot NAS, few-shot NAS) • Search algorithm: the algorithm to search for best architectures (gradient-based, search-based) • Benchmark dataset: dataset to evaluate the space design, algorithm with evaluated architectures (NASBench-101, NASBench-201) 2. Few-shot NAS: focuses on designing the search space to improve the speed of searching process while not sacrificing too much on accuracy of the final architecture Achieving same result with Vanilla NAS with search time 2 order of magnitudes smaller Partitioning search space to speed-up training process of sub-space 1. Impact of few-shot NAS
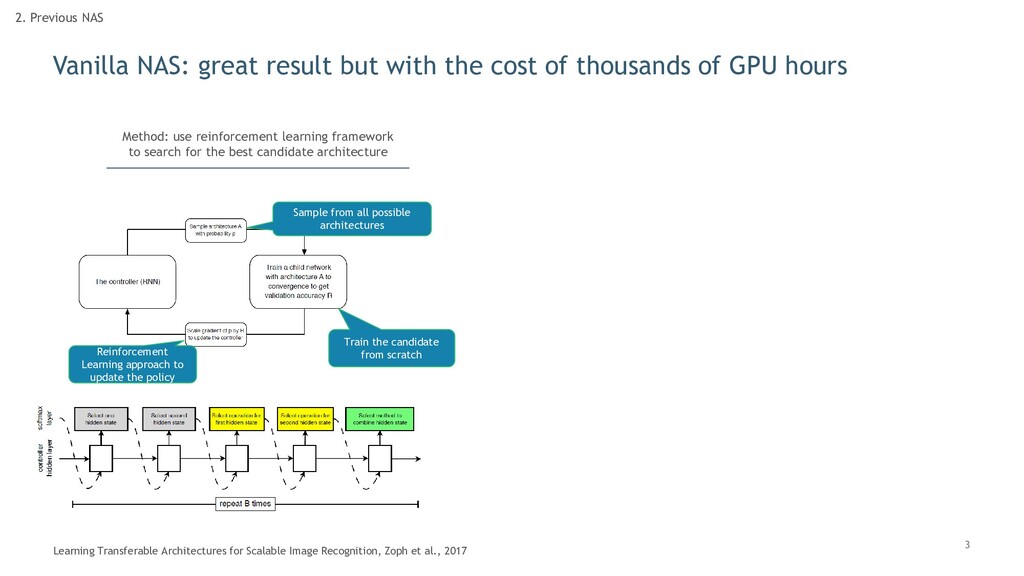
thousands of GPU hours 2. Previous NAS Learning Transferable Architectures for Scalable Image Recognition, Zoph et al., 2017 Sample from all possible architectures Train the candidate from scratch Reinforcement Learning approach to update the policy Method: use reinforcement learning framework to search for the best candidate architecture
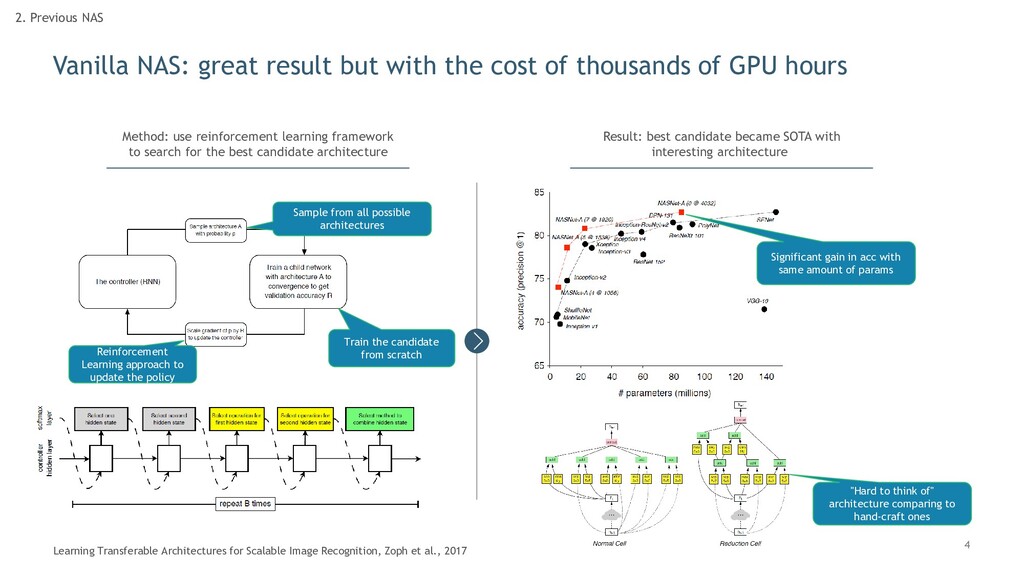
thousands of GPU hours 2. Previous NAS Learning Transferable Architectures for Scalable Image Recognition, Zoph et al., 2017 Sample from all possible architectures Train the candidate from scratch Reinforcement Learning approach to update the policy Method: use reinforcement learning framework to search for the best candidate architecture Result: best candidate became SOTA with interesting architecture Significant gain in acc with same amount of params "Hard to think of" architecture comparing to hand-craft ones
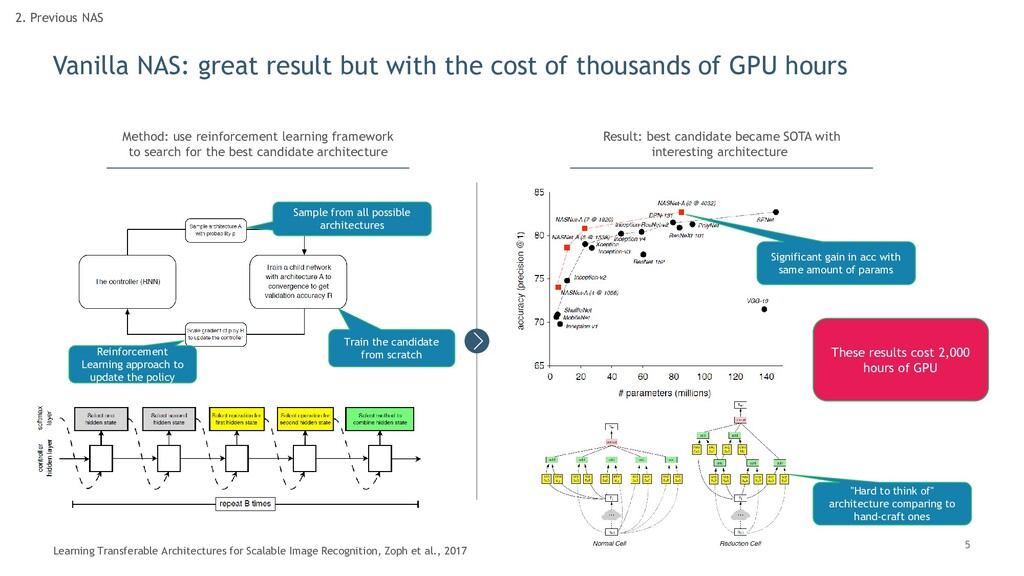
thousands of GPU hours 2. Previous NAS Learning Transferable Architectures for Scalable Image Recognition, Zoph et al., 2017 Sample from all possible architectures Train the candidate from scratch Reinforcement Learning approach to update the policy Method: use reinforcement learning framework to search for the best candidate architecture Result: best candidate became SOTA with interesting architecture Significant gain in acc with same amount of params "Hard to think of" architecture comparing to hand-craft ones These results cost 2,000 hours of GPU
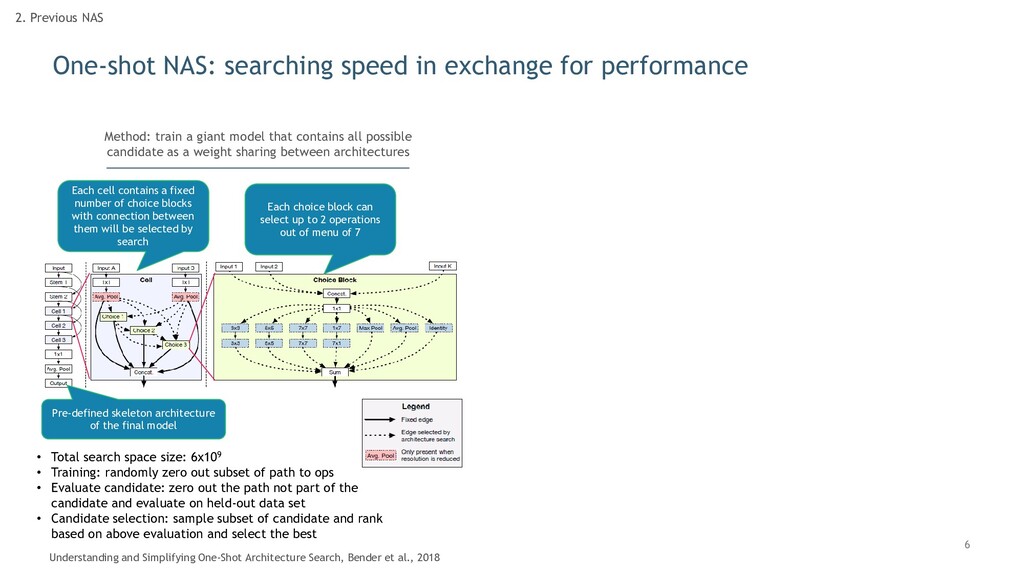
Previous NAS Understanding and Simplifying One-Shot Architecture Search, Bender et al., 2018 Method: train a giant model that contains all possible candidate as a weight sharing between architectures Pre-defined skeleton architecture of the final model Each cell contains a fixed number of choice blocks with connection between them will be selected by search Each choice block can select up to 2 operations out of menu of 7 • Total search space size: 6x109 • Training: randomly zero out subset of path to ops • Evaluate candidate: zero out the path not part of the candidate and evaluate on held-out data set • Candidate selection: sample subset of candidate and rank based on above evaluation and select the best
Previous NAS Understanding and Simplifying One-Shot Architecture Search, Bender et al., 2018 Method: train a giant model that contains all possible candidate as a weight sharing between architectures Result: significantly better than hand-crafted architecture with cost of 80 GPU hours Pre-defined skeleton architecture of the final model Each cell contains a fixed number of choice blocks with connection between them will be selected by search Each choice block can select up to 2 operations out of menu of 7 • Total search space size: 6x109 • Training: randomly zero out subset of path to ops • Evaluate candidate: zero out the path not part of the candidate and evaluate on held-out data set • Candidate selection: sample subset of candidate and rank based on above evaluation and select the best Out-performed Mobile-Net for the same number of params
Previous NAS Understanding and Simplifying One-Shot Architecture Search, Bender et al., 2018 Method: train a giant model that contains all possible candidate as a weight sharing between architectures Result: significantly better than hand-crafted architecture with cost of 80 GPU hours Pre-defined skeleton architecture of the final model Each cell contains a fixed number of choice blocks with connection between them will be selected by search Each choice block can select up to 2 operations out of menu of 7 • Total search space size: 6x109 • Training: randomly zero out subset of path to ops • Evaluate candidate: zero out the path not part of the candidate and evaluate on held-out data set • Candidate selection: sample subset of candidate and rank based on above evaluation and select the best Out-performed Mobile-Net for the same number of params Losing to VanillaNAS with non-trivial gap in terms of acc Reason: performance predicted by the supernet is in low correlation with true performance of candidates
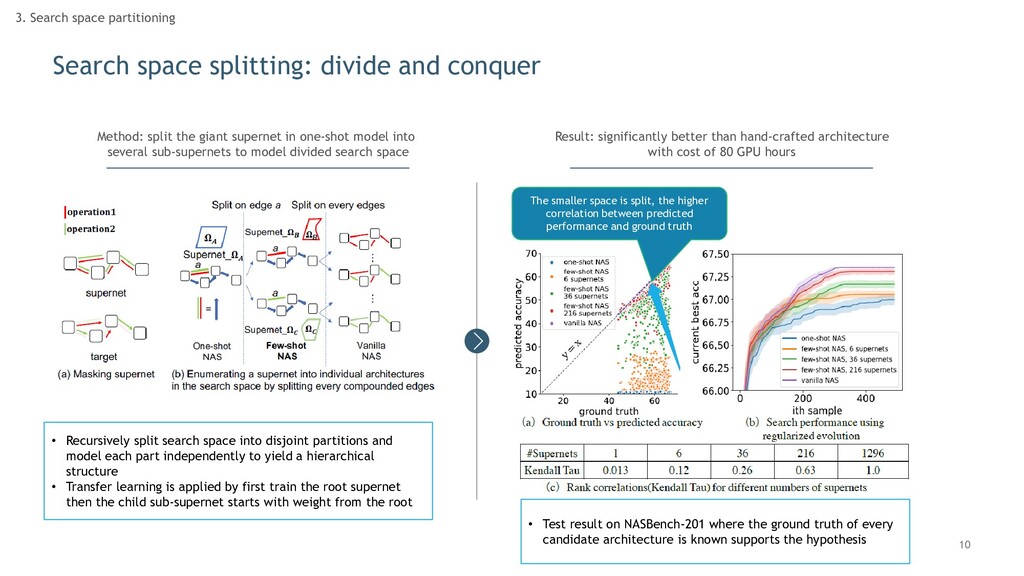
partitioning Method: split the giant supernet in one-shot model into several sub-supernets to model divided search space • Recursively split search space into disjoint partitions and model each part independently to yield a hierarchical structure • Transfer learning is applied by first train the root supernet then the child sub-supernet starts with weight from the root
partitioning Method: split the giant supernet in one-shot model into several sub-supernets to model divided search space Result: significantly better than hand-crafted architecture with cost of 80 GPU hours • Recursively split search space into disjoint partitions and model each part independently to yield a hierarchical structure • Transfer learning is applied by first train the root supernet then the child sub-supernet starts with weight from the root The smaller space is split, the higher correlation between predicted performance and ground truth • Test result on NASBench-201 where the ground truth of every candidate architecture is known supports the hypothesis
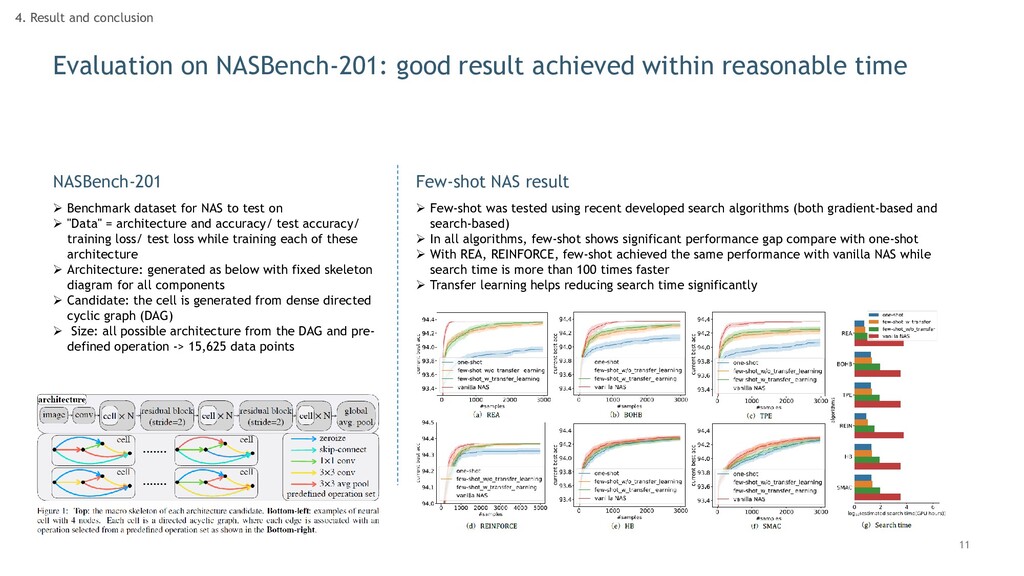
4. Result and conclusion Benchmark dataset for NAS to test on "Data" = architecture and accuracy/ test accuracy/ training loss/ test loss while training each of these architecture Architecture: generated as below with fixed skeleton diagram for all components Candidate: the cell is generated from dense directed cyclic graph (DAG) Size: all possible architecture from the DAG and pre- defined operation -> 15,625 data points Few-shot was tested using recent developed search algorithms (both gradient-based and search-based) In all algorithms, few-shot shows significant performance gap compare with one-shot With REA, REINFORCE, few-shot achieved the same performance with vanilla NAS while search time is more than 100 times faster Transfer learning helps reducing search time significantly NASBench-201 Few-shot NAS result
the same search space with EfficientNet Apply few-shot approach in dividing search space Few-shot OFA large achieved new SOTA for 9M params and 600M Flops with 68 GPU hours 4. Result and conclusion Conclusion: proposed a novel approach of divide and conquering the search space, which can be integrated with transfer learning while using up-to-date search algorithm for efficient architecture search
and Simplifying One-Shot Architecture Search, Bender et al., 3.Learning Transferable Architectures for Scalable Image Recognition, Zoph et al., 4.NAS-Bench-201: Extending the Scope of Reproducible Neural Architecture Search, Dong et al.,
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}