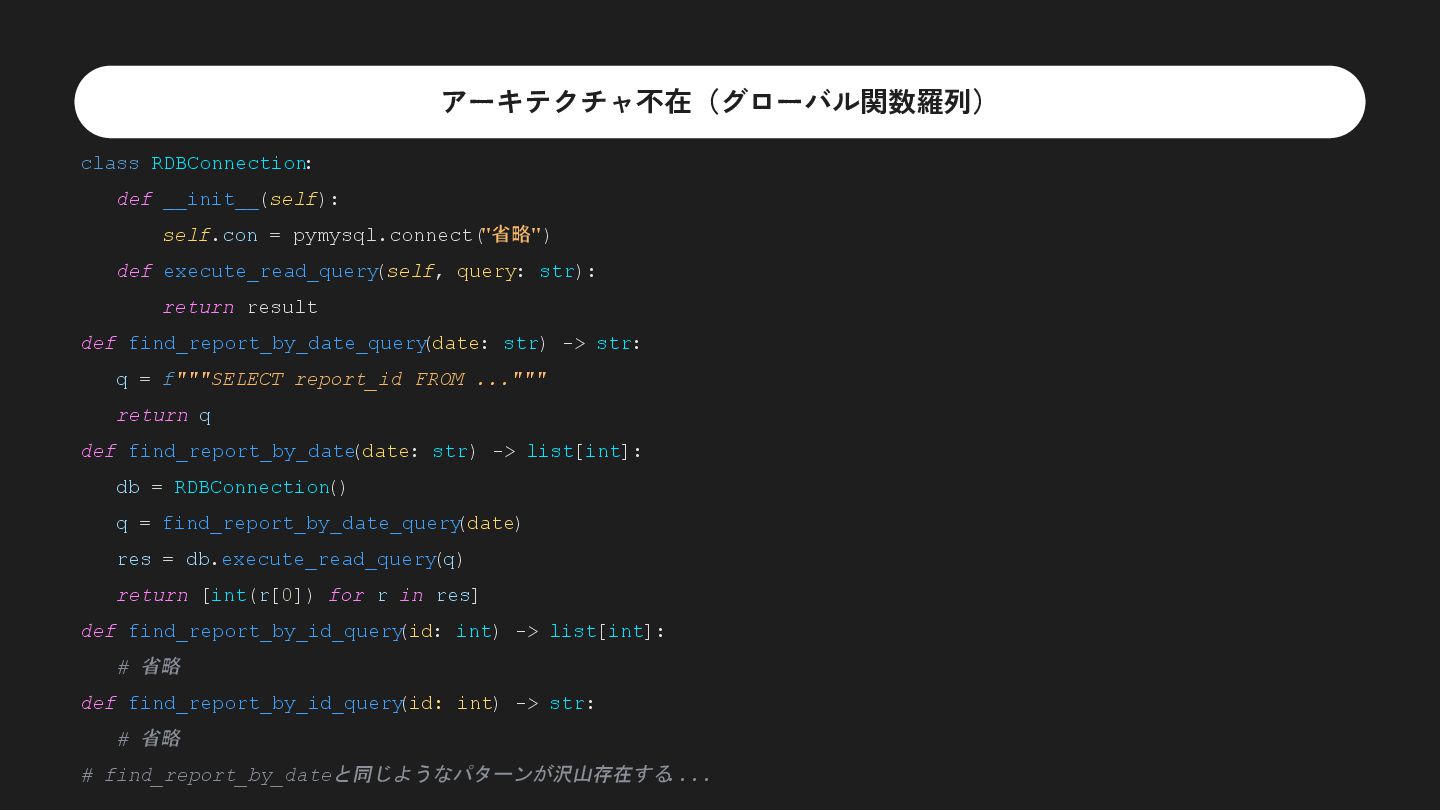
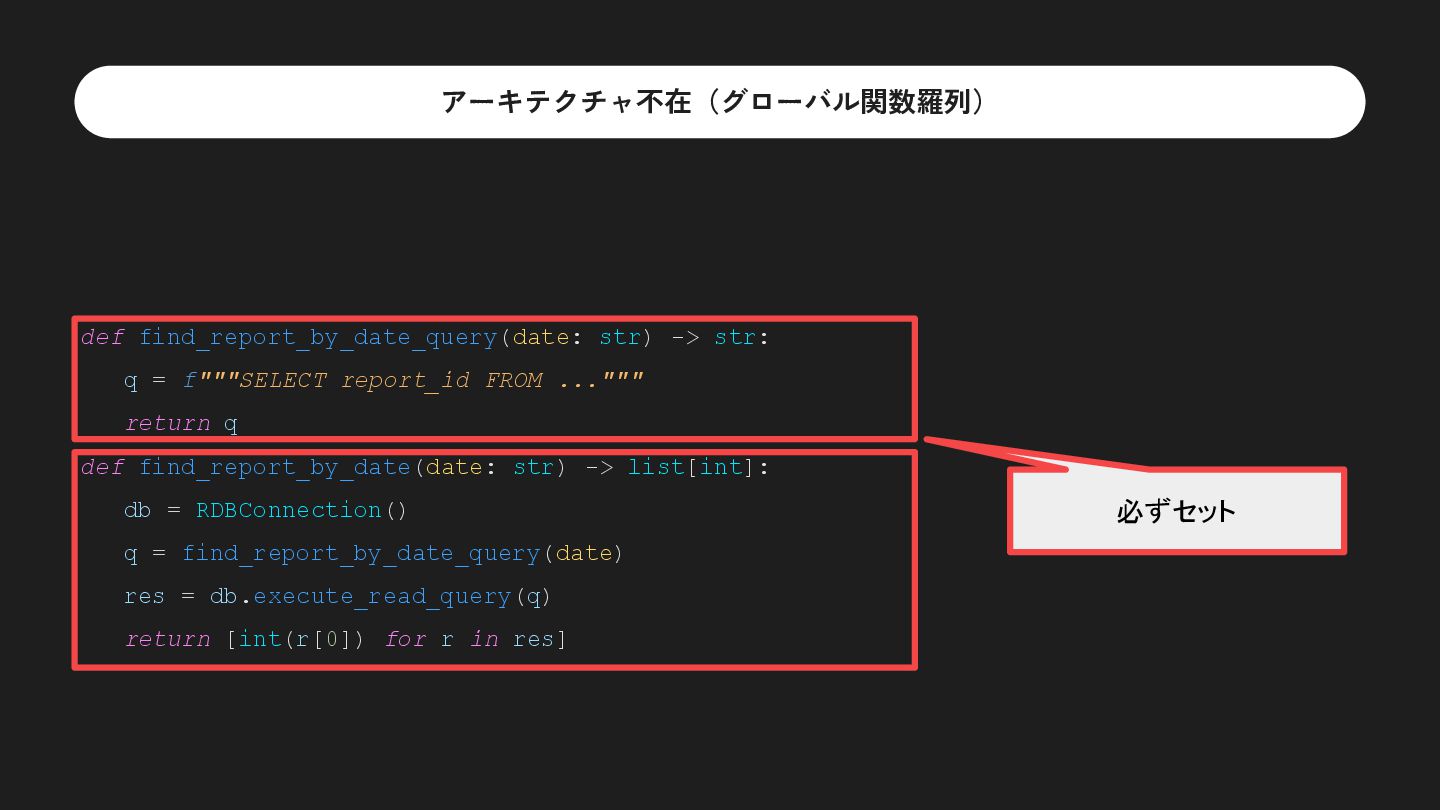
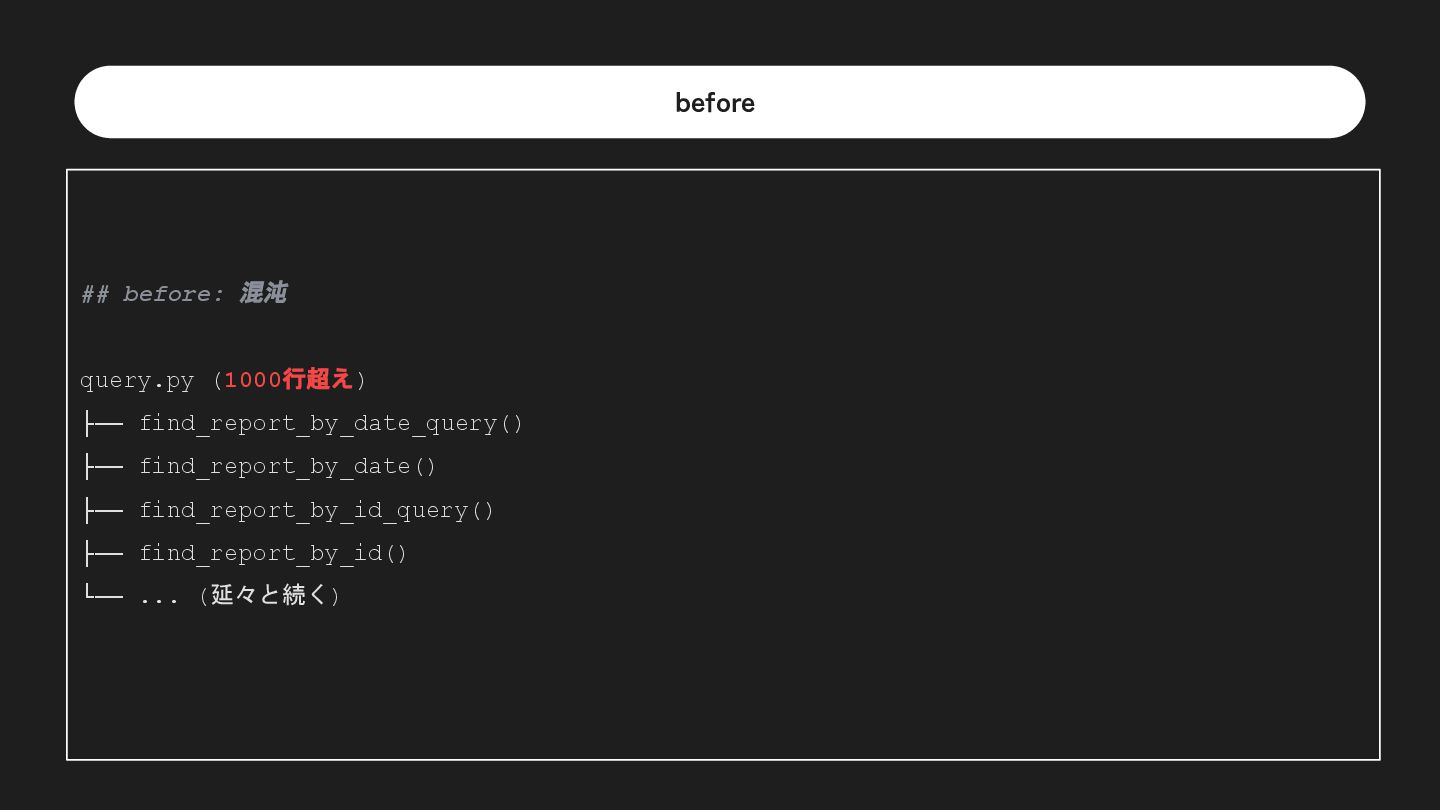
FROM ...""" return q def find_report_by_date(date: str) -> list[int]: db = RDBConnection() q = find_report_by_date_query(date) res = db.execute_read_query(q) return [int(r[0]) for r in res] 必ずセット
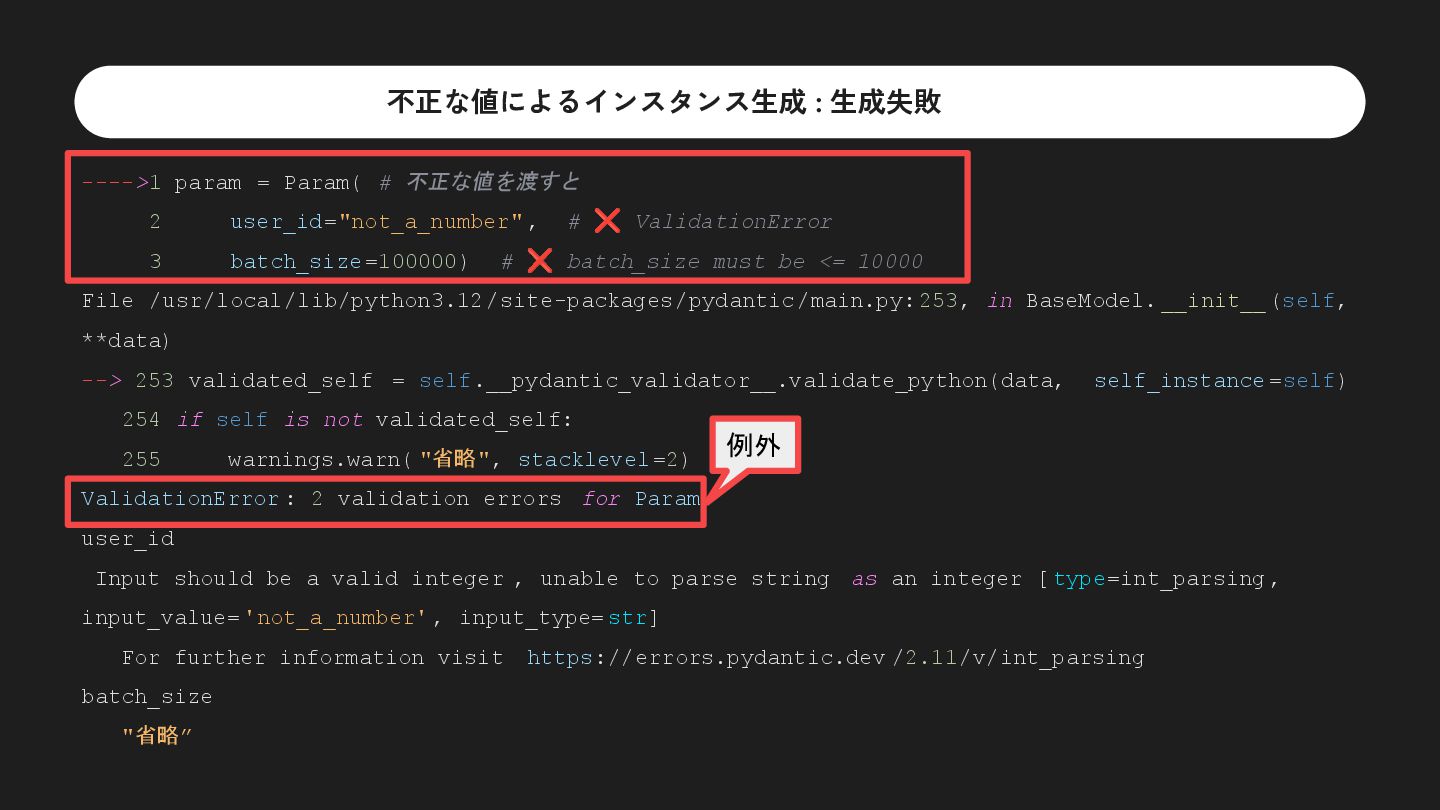
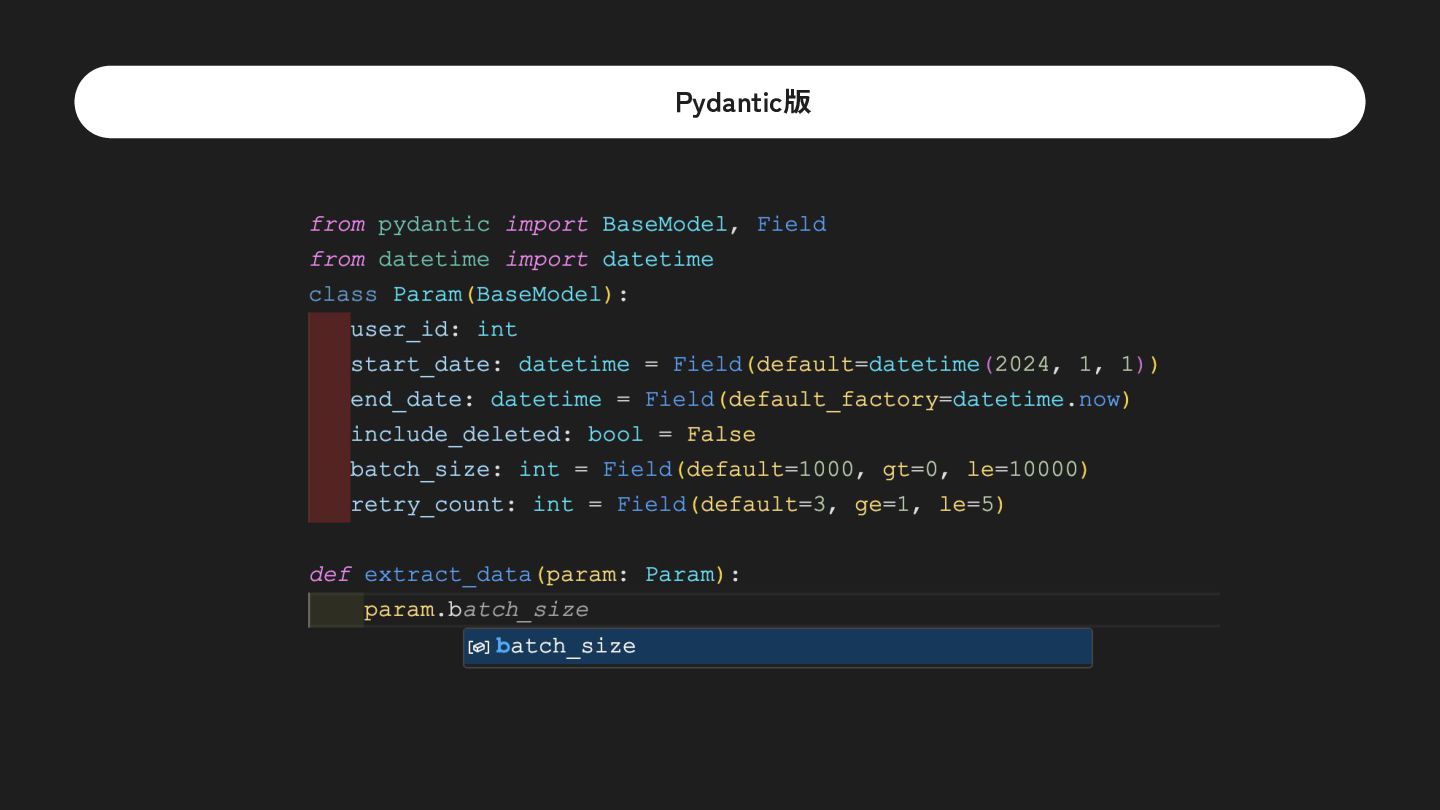
user_id="not_a_number" , # ❌ ValidationError 3 batch_size=100000) # ❌ batch_size must be <= 10000 File /usr/local/lib/python3.12/site-packages/pydantic/main.py:253, in BaseModel. __init__(self, **data) --> 253 validated_self = self.__pydantic_validator__.validate_python(data, self_instance =self) 254 if self is not validated_self: 255 warnings.warn( "省略", stacklevel=2) ValidationError : 2 validation errors for Param user_id Input should be a valid integer , unable to parse string as an integer [ type=int_parsing , input_value= 'not_a_number' , input_type= str] For further information visit https://errors.pydantic.dev /2.11/v/int_parsing batch_size "省略” 例外
[2]: class User(BaseModel): ...: id: int ...: name: str In [3]: u = User(id=123, name="PyCon2025") In [4]: u.name="hoge" In [5]: u Out[5]: User(id=123, name='hoge') 項目値変更可能 インスタンス生成成功
class Param: ...: name: str ...: age: int ...: In [2]: p = Param(name="PyCon2025", age="15歳") In [3]: p Out[3]: Param(name='PyCon2025', age='15歳') ”15歳”という文字列がそのまま格納 🤔
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![def process(data_df): jp_indices = data_df[data_df['region'] == 'JP'].index data_df.drop(data_df.index.difference(jp_indices), inplace=True) data_df['ctr']](https://files.speakerdeck.com/presentations/51c5b3feba4a4827ac313ac72b0b198a/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
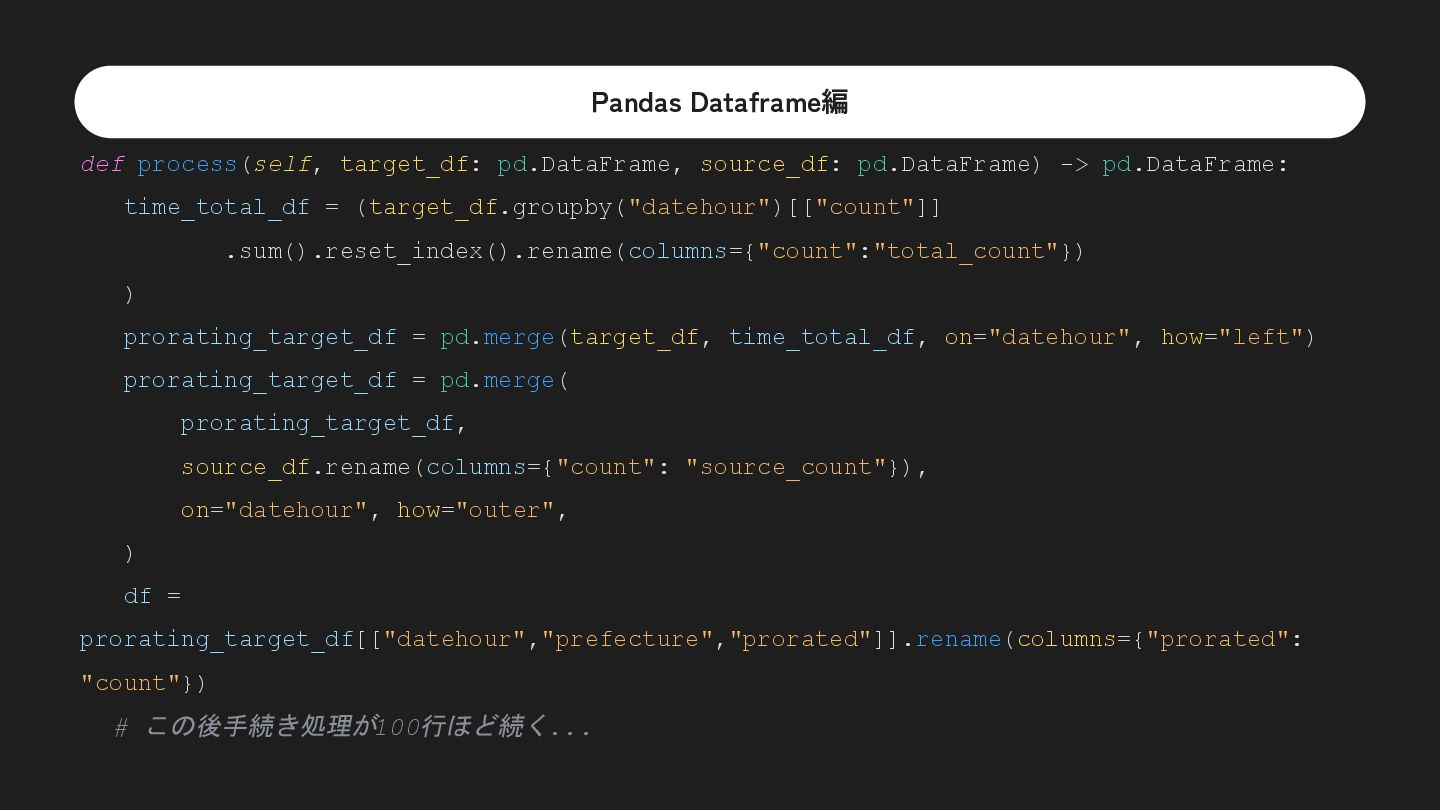
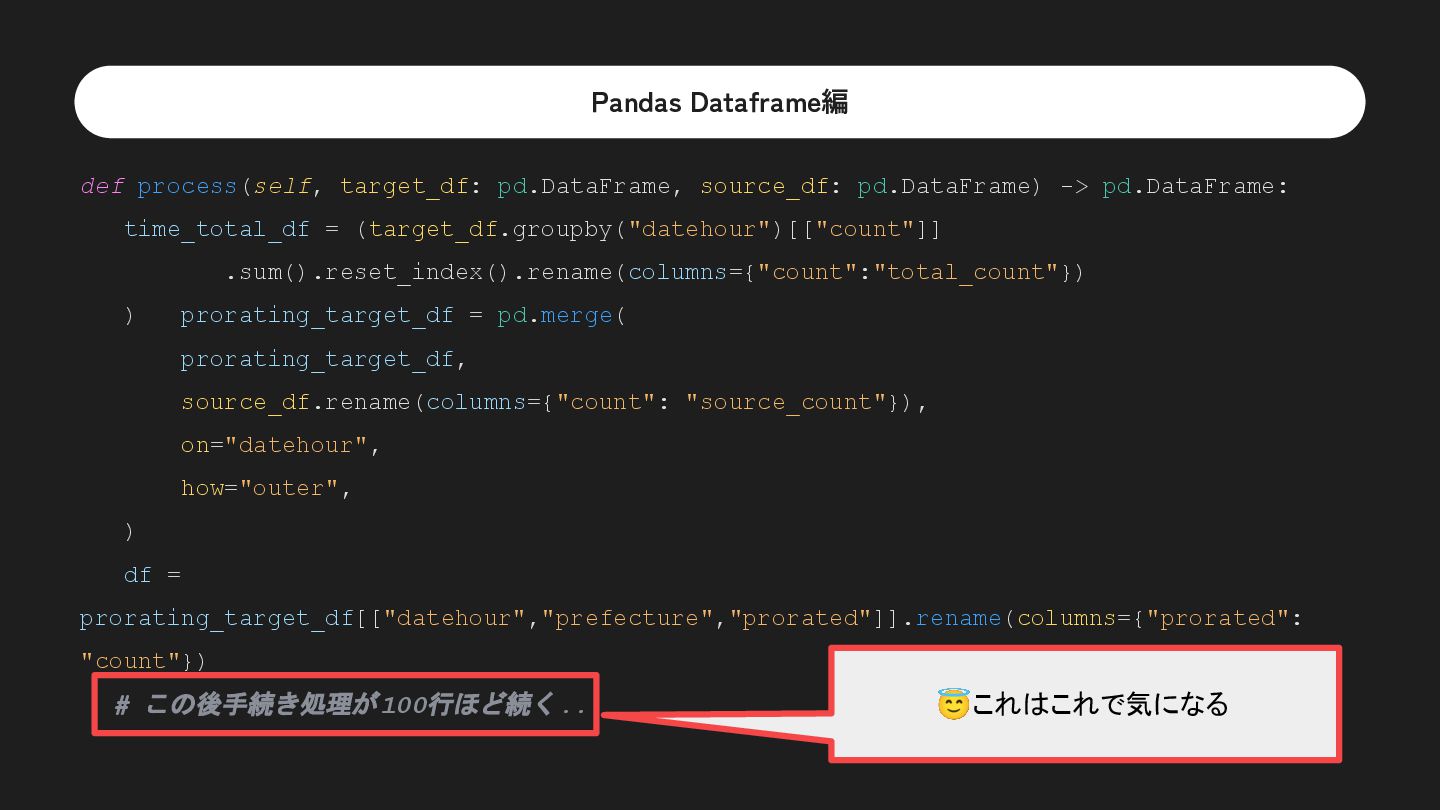
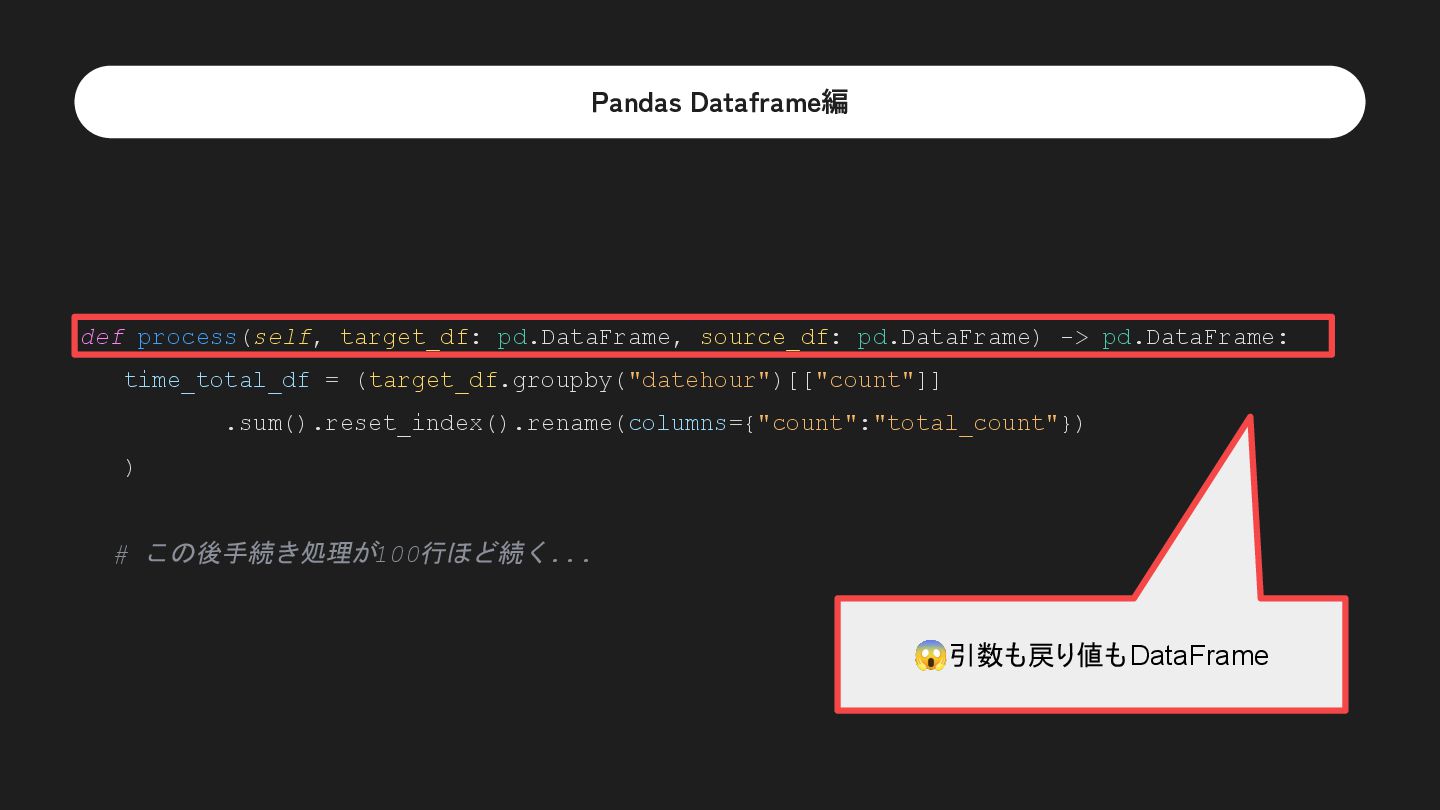
![Pandas Dataframe編 time_total_df = (target_df.groupby("datehour")[["count"]] .sum().reset_index().rename(columns={"count":"total_count"}) ) prorating_target_df = pd.merge(target_df,](https://files.speakerdeck.com/presentations/51c5b3feba4a4827ac313ac72b0b198a/slide_45.jpg){kind=link}
{kind=link}
{kind=link}
![アーキテクチャ不在(グローバル関数羅列) def find_report_by_date (date: str) -> list[int]: db = RDBConnection()](https://files.speakerdeck.com/presentations/51c5b3feba4a4827ac313ac72b0b198a/slide_48.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![正常想定の値によるインスタンス生成 : 生成成功 In [1]: from pydantic import BaseModel, Field](https://files.speakerdeck.com/presentations/51c5b3feba4a4827ac313ac72b0b198a/slide_59.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Pydantic デフォルト設定 In [1]: from pydantic import BaseModel, ConfigDict In](https://files.speakerdeck.com/presentations/51c5b3feba4a4827ac313ac72b0b198a/slide_65.jpg){kind=link}
![Pydantic イミュータブル設定 In [1]: from pydantic import BaseModel, ConfigDict ...:](https://files.speakerdeck.com/presentations/51c5b3feba4a4827ac313ac72b0b198a/slide_66.jpg){kind=link}
{kind=link}
![型ヒントのみ In [1]: from dataclasses import dataclass ...: @dataclass ...:](https://files.speakerdeck.com/presentations/51c5b3feba4a4827ac313ac72b0b198a/slide_68.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}