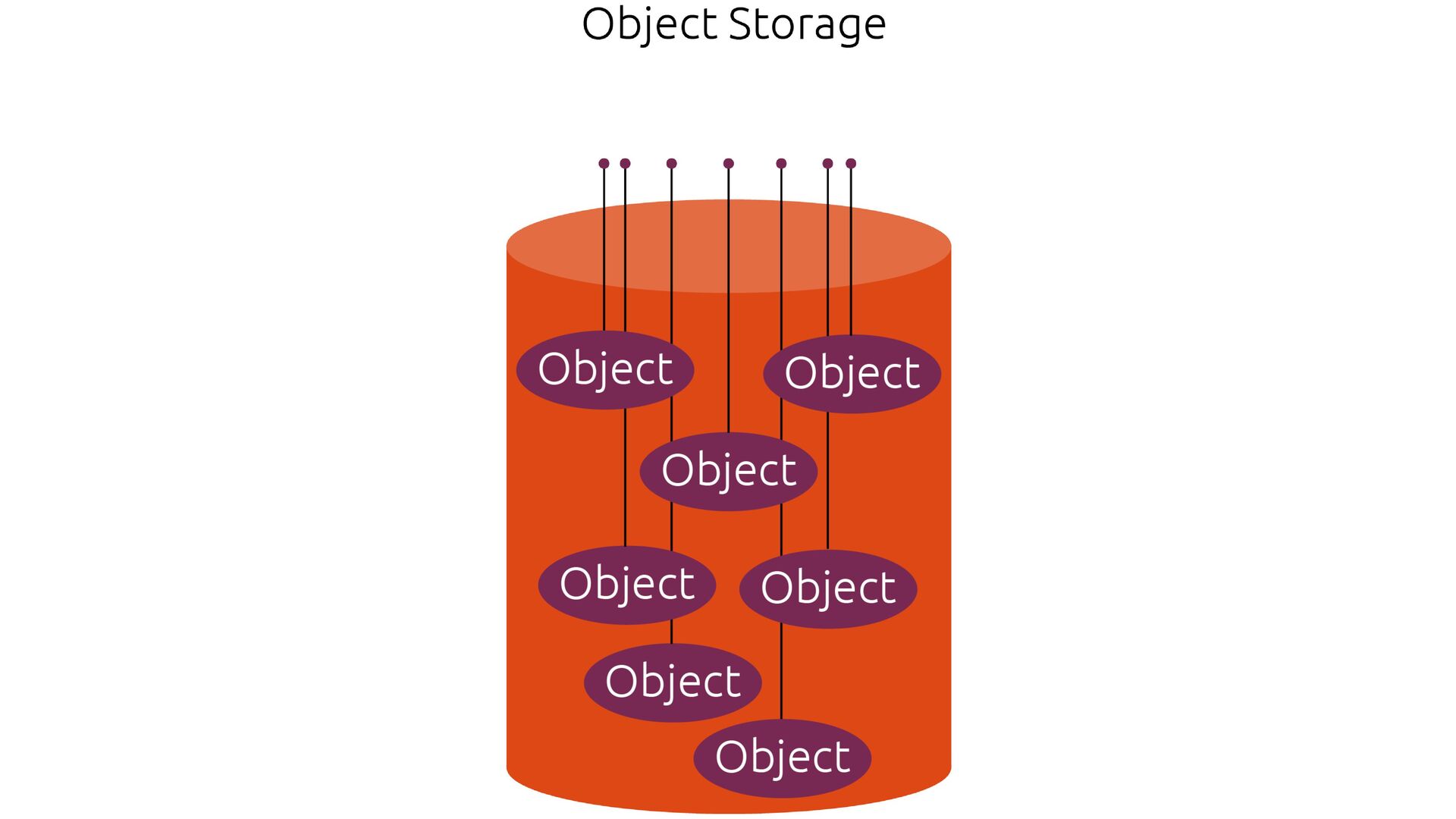
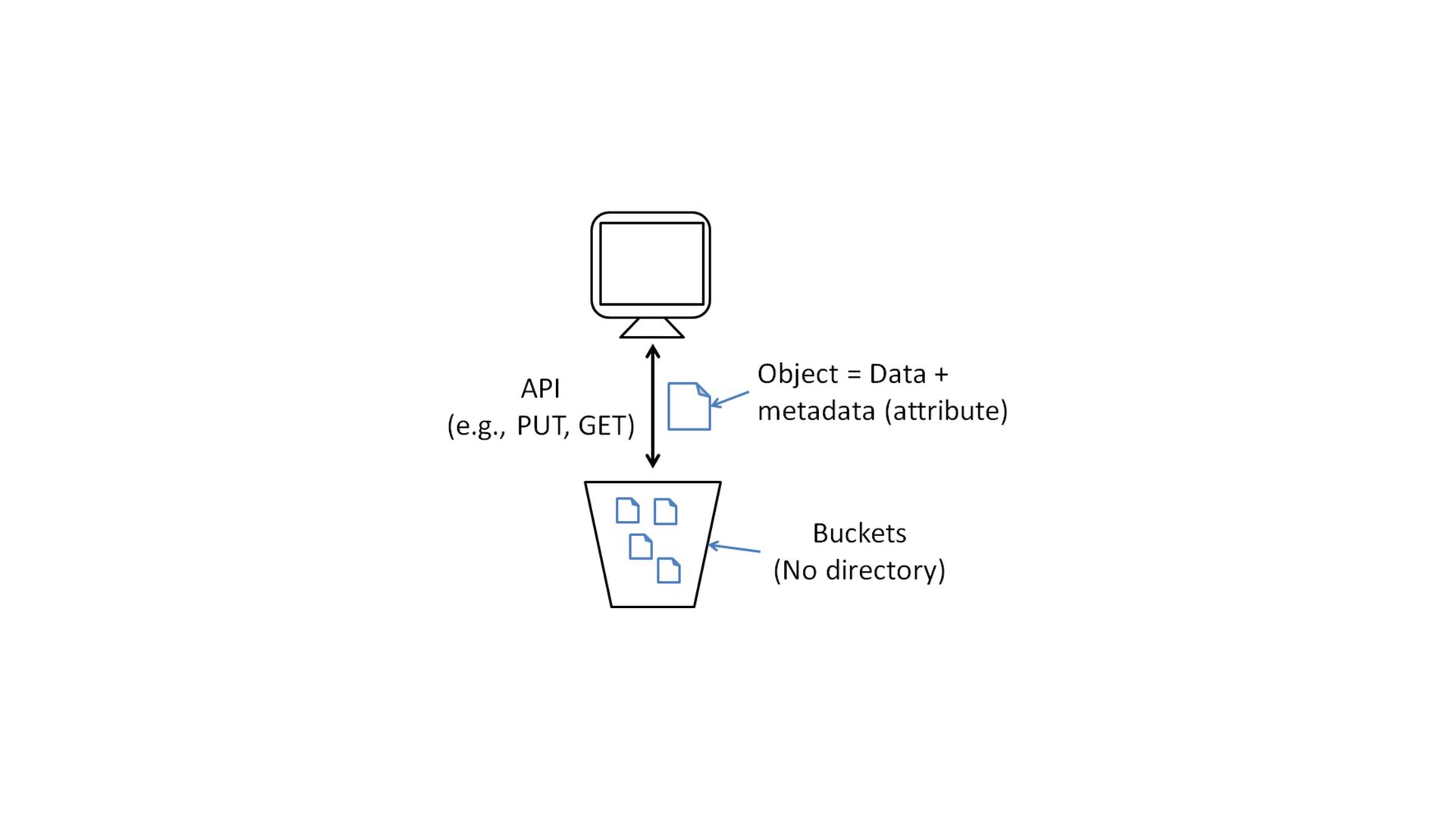
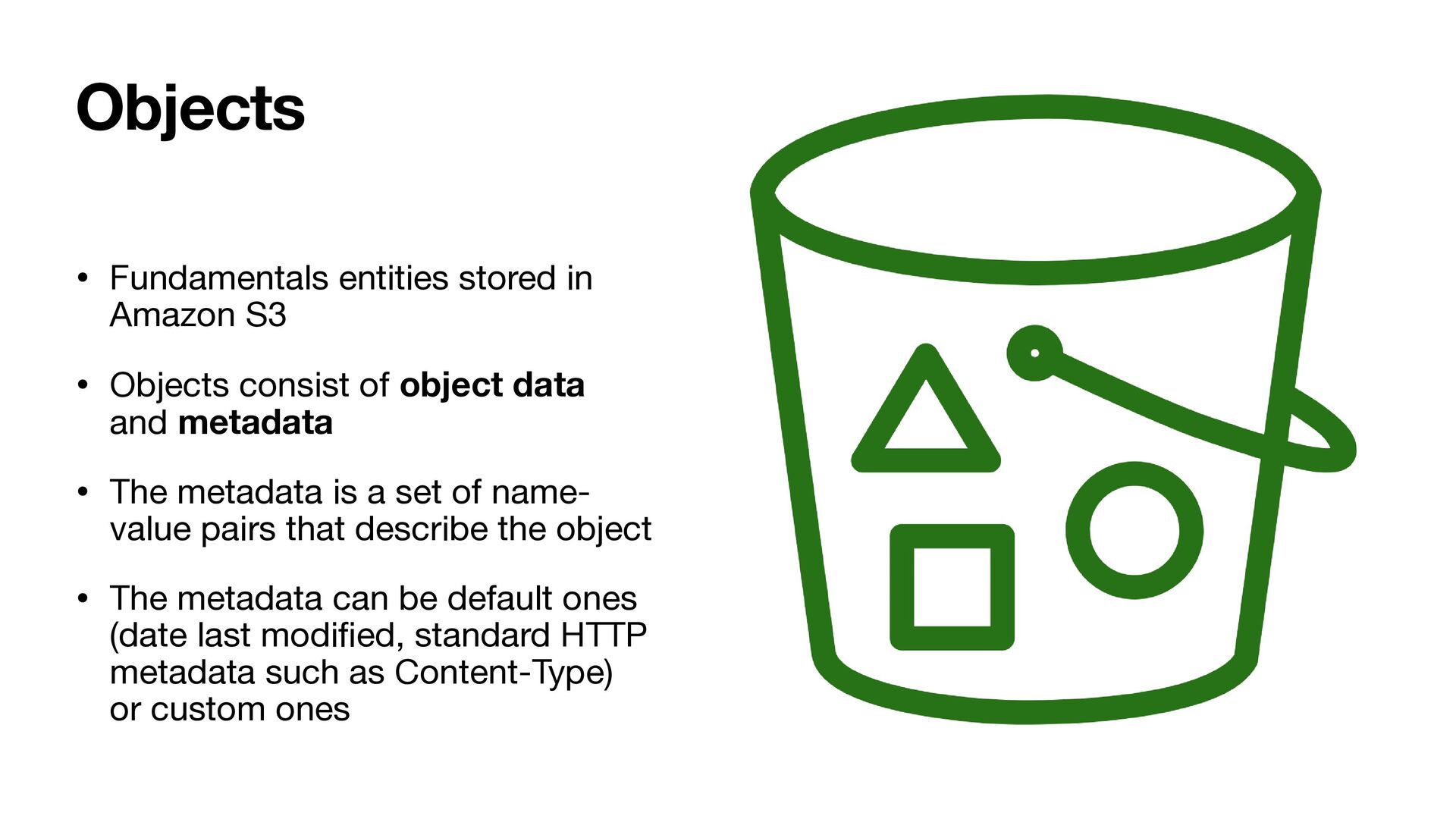
of object data and metadata • The metadata is a set of name- value pairs that describe the object • The metadata can be default ones (date last modi fi ed, standard HTTP metadata such as Content-Type) or custom ones Objects
key • The combination of a bucket, key, and version ID uniquely identi fi es each object • Eg. in https://doc.s3.amazonaws.com/2006-03-01/AmazonS3.wsdl, doc is the name of the bucket and 2006-03-01/AmazonS3.wsdl is the key
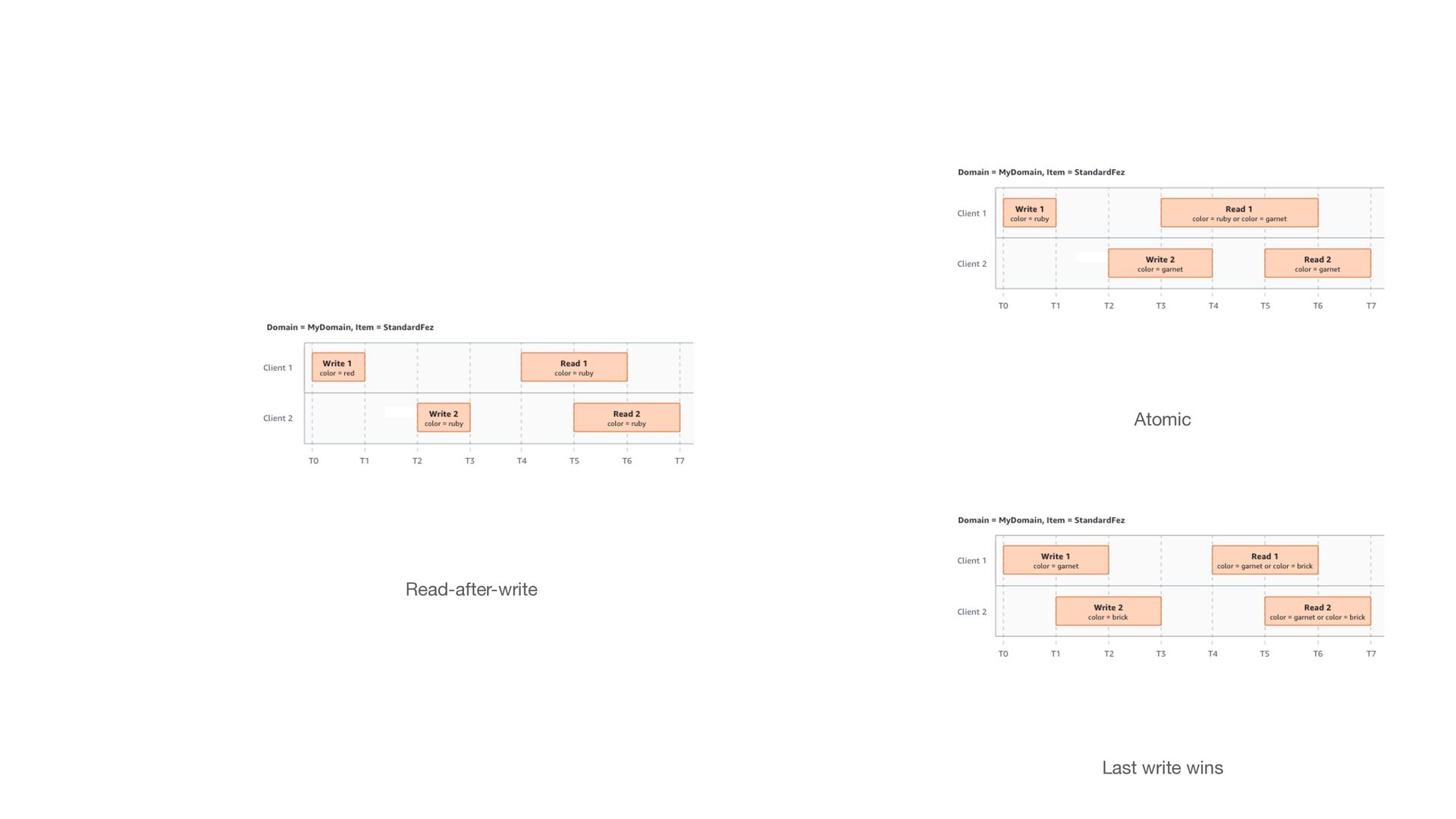
DELETEs • Strongly consistent read operations on Amazon S3 Select, Amazon S3 Access Control Lists, Amazon S3 Object Tags, and object metadata • Updates to a single key are atomic
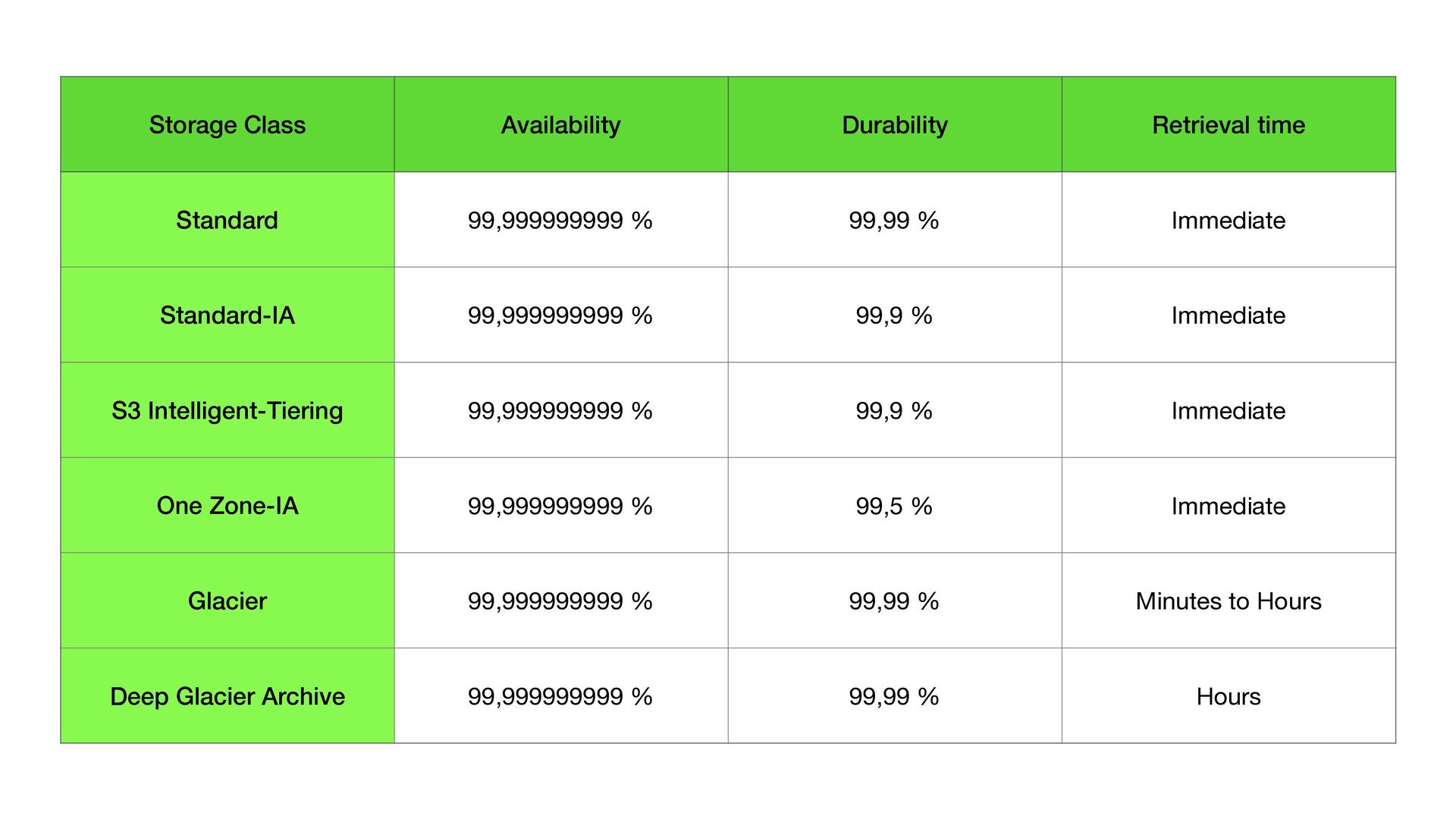
i.e. the storage system is operational and can deliver data upon request • Durability, on the other hand, refers to long-term data protection, i.e. the stored data does not su ff er from bit rot, degradation or other corruption
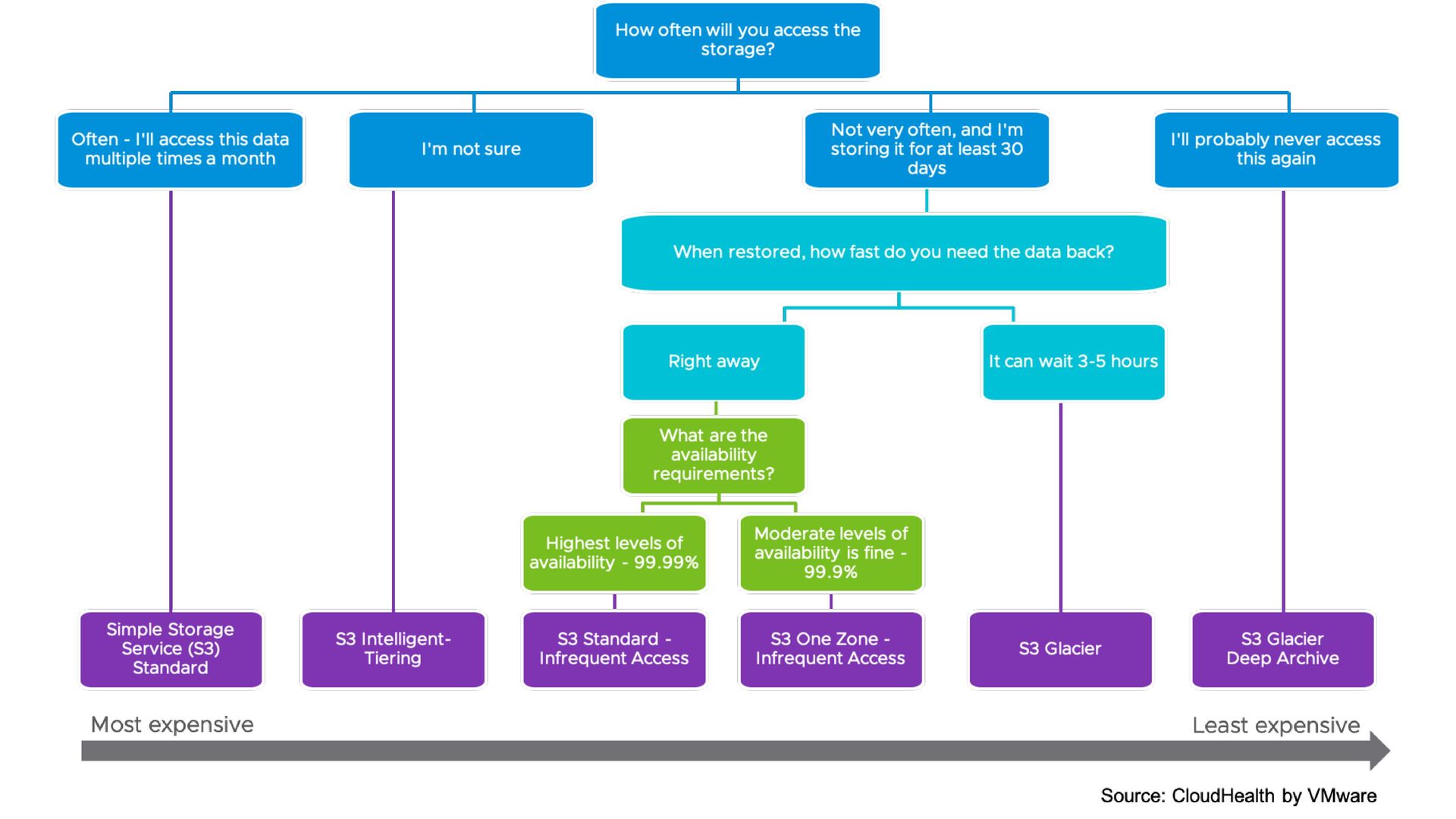
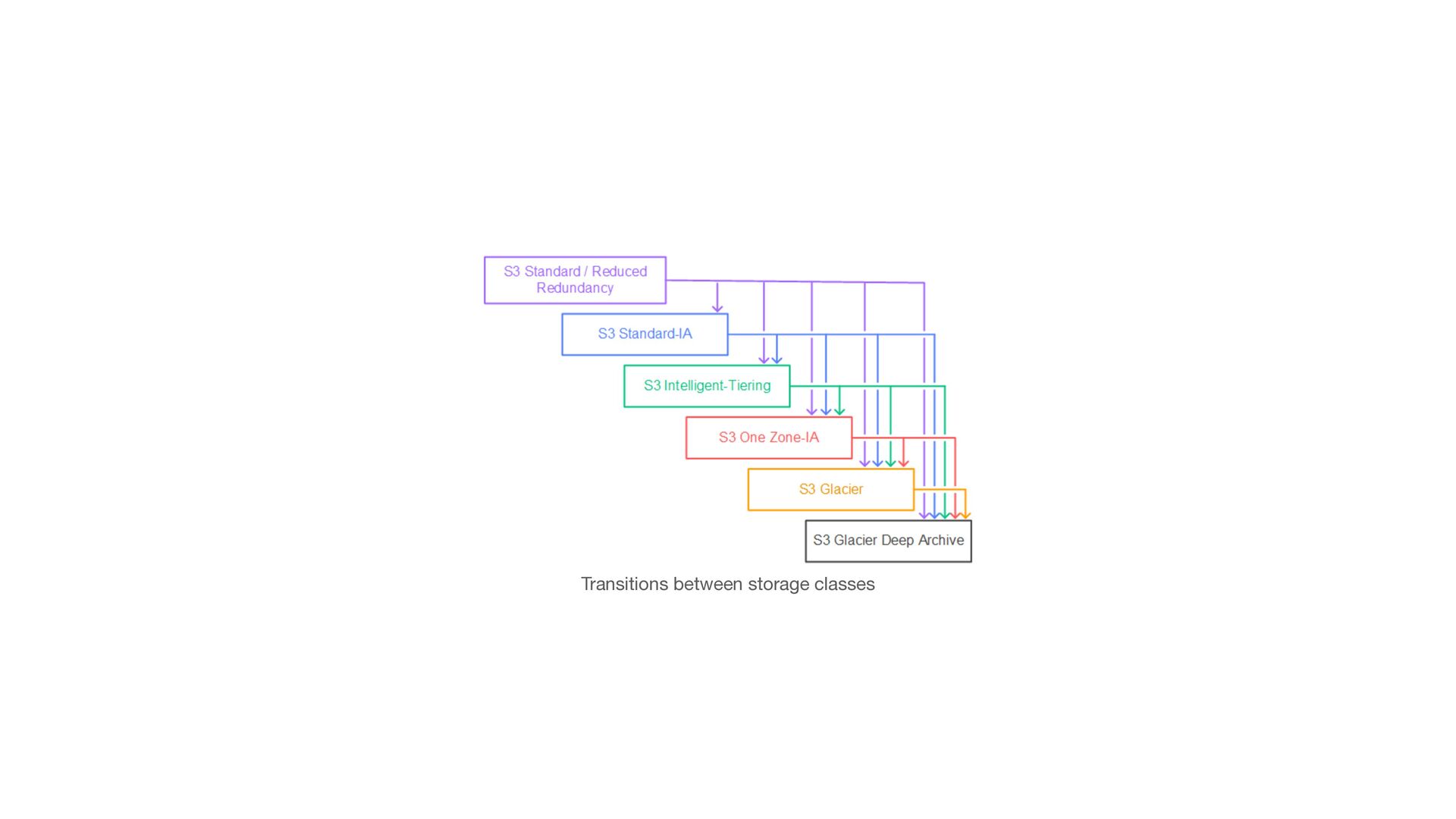
• 99.99% (Four 9s) Availability • Reduced Redundancy: Storage class designed for non-critical, reproducible data. • 99.99% Durability • 99.99% (Four 9s) Availability • Not Recommended as less cost e ff ective than S3 Standard
accessed less frequently, but requires rapid access when needed. • Same low latency and high throughput performance of S3 Standard • 99.9% (Three 9s) availability • S3 One Zone-IA: Amazon S3 stores the object data in only one Availability Zone, which makes it less expensive than S3 Standard-IA • Same low latency and high throughput performance of S3 Standard • 99.5% (Two and half 9s) availability
S3 One Zone-IA are suitable for objects larger than 128KB that you plan to store for at least 30 days • S3 Standard-IA — Use for your primary or only copy of data that can't be re- created. • S3 One Zone-IA — Use if you can re-create the data if the Availability Zone fails, and for object replicas
of the data might need to be retrieved in minutes • Low cost • Con fi gurable retrieval times, from minutes to hours • S3 Glacier Deep Archive: Use for archiving data that rarely needs to be accessed • Lowest cost • Retrieval times from 12 hours to 48 hours
90 days for S3 glacier • 180 days for S3 Glacier Deep Archive • Retrieval times ranked by fastest/expensive: • Bulk • Standard • Expedite • You can directly upload data in glacier as archives inside vaults using the Glacier API
moving data to the most cost e ff ective access tier • It works by monitoring access patterns • The objects are moved rolling the pattern: • After 30 days of non access : move to infrequent access tier • After 90 days of non access: move to archive access tier • After 180 days of non access: move to deep archive access tier
of rules that de fi ne actions S3 applies to a group of objects • There are two types of actions: • Transition actions: De fi ne when objects transition from a storage class to another • Expiration actions: De fi ne when objects expire and should be deleted by S3 • Lifecycle con fi guration fi les are XML documents
<Transition> <Days>365</Days> <StorageClass>S3 Glacier</StorageClass> </Transition> <Expiration> <Days>3650</Days> </Expiration> </Rule> </LifecycleConfiguration> Example of lifecycle con fi guration
multiple versions of the same object in the same bucket • If S3 receives multiple write requests for the same object, it stores all of those objects • When versioning is activated: • A simple GET request retrieves the current version of the object. To retrieve a speci fi c version, you have to specify the version ID • A simple DELETE request cannot delete an object. To delete version object de fi nitely, you have to also specify the version ID
to prevent objects for being deleted or overwritten • Works only in versioned buckets and applies to individual object versions • There is two types of object locking: • Retention period: Speci fi es a fi xed amount of time during which the object remains locked • Legal hold: Provides the same protection as retention period but has no expiration date. Legal holds remain in place until explicitly removed.
in-transit • Amazon S3 allows the following options for protection data at rest: • Server-side encryption: Requesting S3 to encrypt your objects before saving them on disks in the data centres • Client-side encryption: Encrypt data client-side and upload the encrypted data to Amazon S3.
Keys (SSE-S3): AES-256 keys is used to encrypt object and the master key is managed and rotated by S3 • Server-Side Encryption with Customer Master Keys (CMKs) Stored in AWS Key Management Service (SSE-KMS): Uses a customer managed master key with AWS KMS. It allows audit trail (who and when the key was used) • Server-Side Encryption with Customer-Provided Keys (SSE-C): Uses AES-256 encryption keys provided by the customer when uploading to encrypt the object. When retrieving the object, the same key must be provided in order to allow Amazon S3 to decrypt and return the object data
before sending them to S3 • It can be done by: • Using a customer master key (CMK) stored in KMS • Using a master key that you store in your application • When uploading an object, a symmetric key is generated using the CMK ID via KMS or the owned master key via AWS Encryption SDK. The plainkey is used to encrypt the data and the encrypted one is stored in object metadata • When downloading an object, the encrypted key is retrieved from the object metadata, decrypted with the master key and used to decrypt the object data
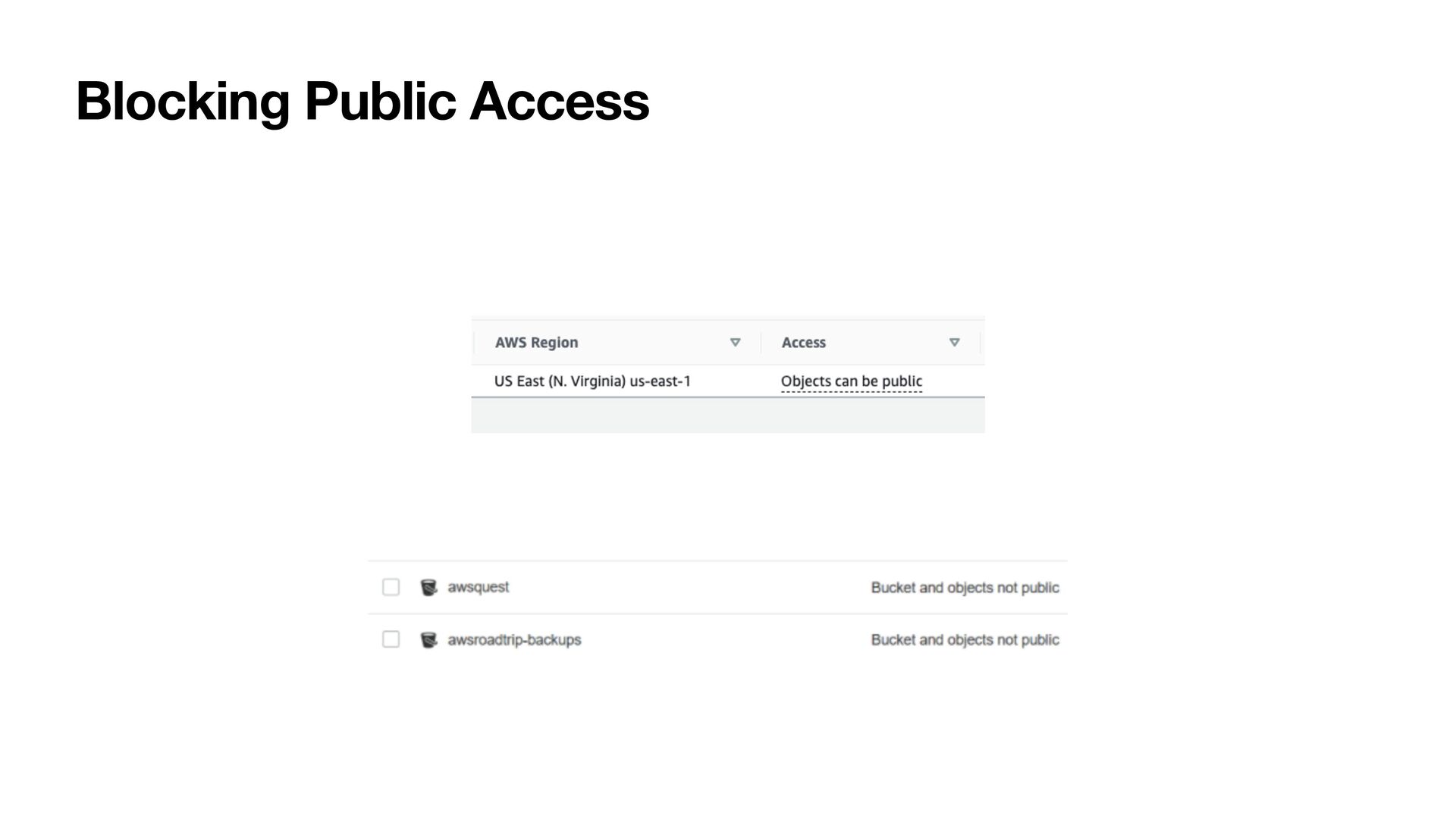
resources are private. Only the resource owner can access the resource • You can create and con fi gure bucket policies to grant permission to your Amazon S3 resources. Bucket policies use JSON-based access policy language • You can use ACLs to grant basic read/write permissions to other AWS account
Amazon S3 buckets. • Object may be replicated to a single destination bucket or multiple destination buckets • Original metadata are replicated across buckets • Note: Object created with SSE-C encryption keys are not replicated
use SQL statements to fi lter the contents of an Amazon S3 object (on S3 or Glacier) and retrieve just the subset of data that you need • Works on objects stored in CSV, JSON or Apache Parquet. It also works on objects compressed with GZIP or BZIP2 and server-side encrypted objects. • The following standard clauses are supported: • SELECT list • FROM clause • WHERE clause • LIMIT clause (Amazon S3 Select only)
operation on lists of Amazon S3 objects that you specify • Can be used to copy objects, set tags, access control lists or invoke lambda to perform custom actions using your objects • S3 Batch terminology • Job: A basic unit of work for S3 batch operations • Operation: The type of API action (copying objects, call Lambda) that you want the batch operation to run • Task: The unit of execution for the job. A task represents a single call to an Amazon S3 or AWS Lambda API
host a static website (static HTML, SPA web app) • Only http available, to provide https you can use Cloudfront • For your customers to access content at the website endpoint, you must make all your content publicly readable • You can optionally enable Amazon S3 server access logging
and secure transfer of fi le over long distance • S3 Transfer Acceleration uses CloudFront distributed edge location and routes data to S3 using an optimised network • Works both with IPv4 (bucketname.s3-accelerate.amazonaws.com) and IPv6 (bucketname.s3-accelerate.dualstack.amazonaws.com) • S3 Transfer Acceleration Speed Comparison tool can be used to benchmark accelerated vs non-accelerated S3 upload across AWS Regions
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}