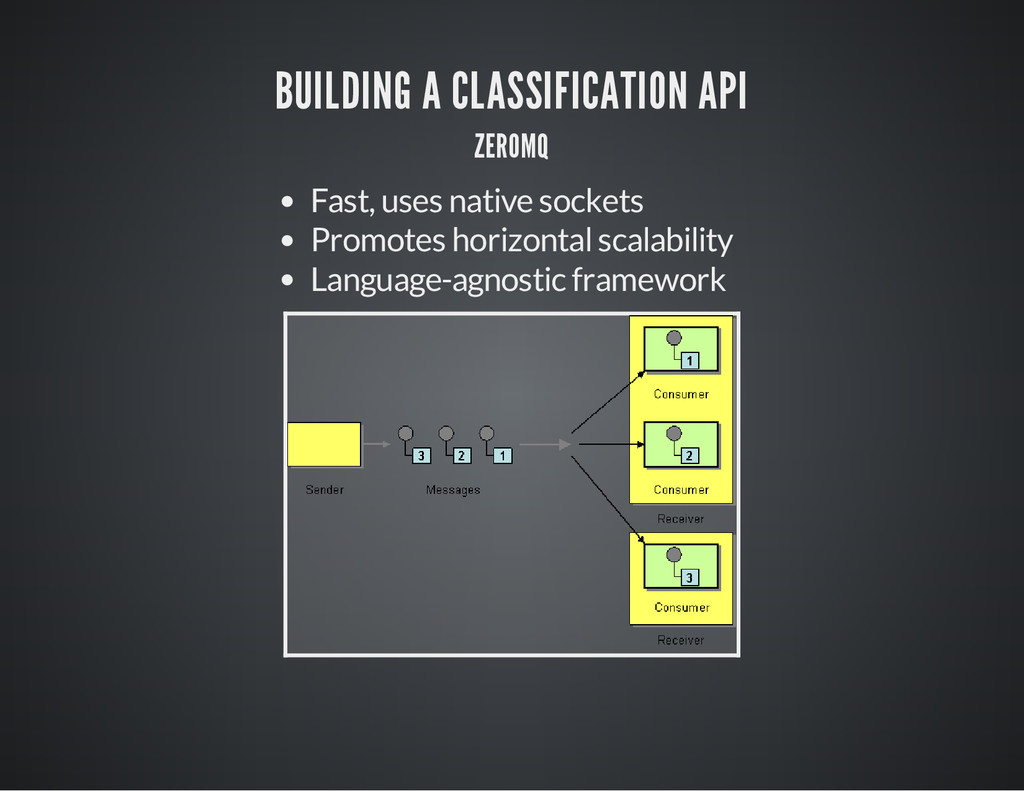
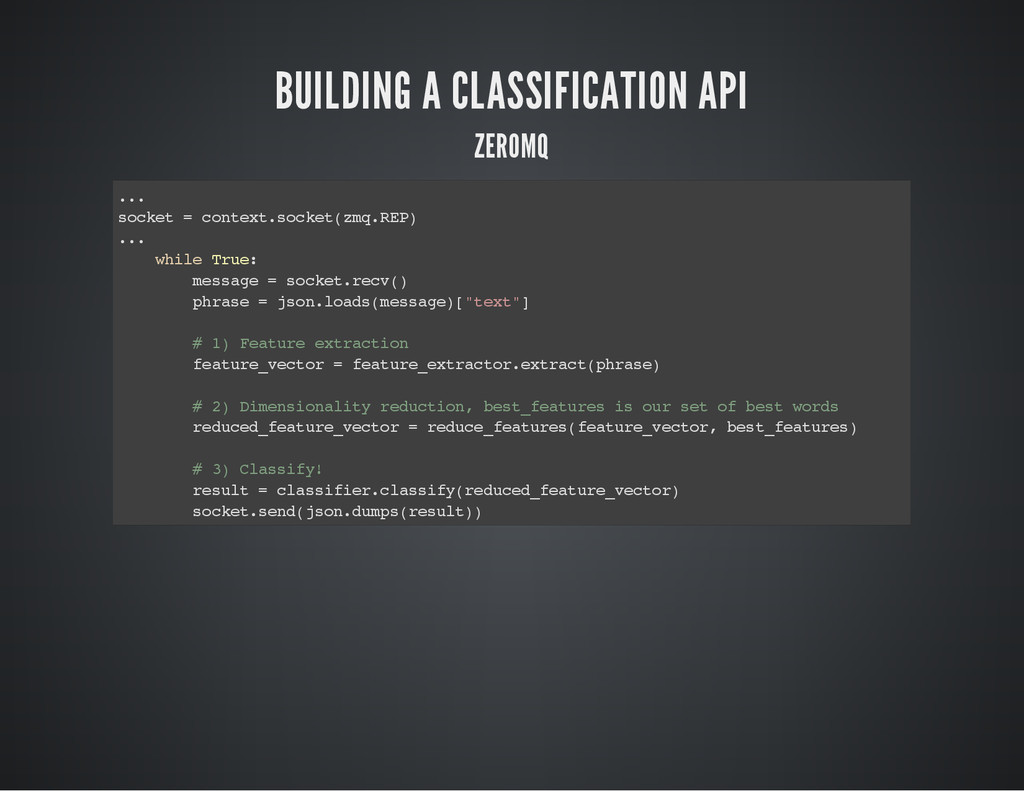
I am a Machine Learning (ML) and Natural Language Processing enthusiast. For my university dissertation I created a realtime sentiment analysis classifier for Twitter. My talk will be about the experience and the lessons learned. I will explain how to build a scalable machine learning software as a service, consumable with a REST API. The purpose of this talk is not to dig into the mathematics behind machine learning (as I do not have this experience), but it’s more about showing how easy it can be to build a ML SaaS by using some of the amazing libraries such as NLTK, ZMQ and MrJob that have helped me make throughout the development. This talk will give several benefits: users with no ML background will have a great introduction to the subject, they will also be able to replicate my project at home. More experienced users will gain new ideas to put in practice and (most) probably build a better system than mine! Finally, I will attach a GitHub project with the slides and a finished product.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
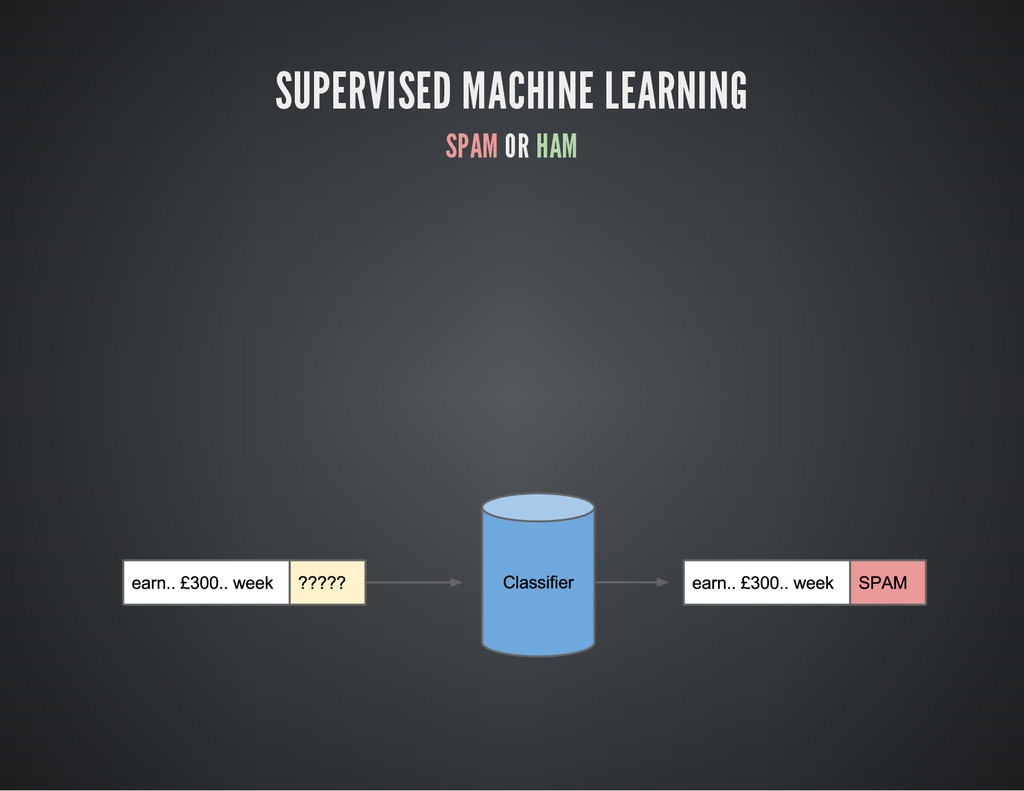{kind=link}
{kind=link}
{kind=link}
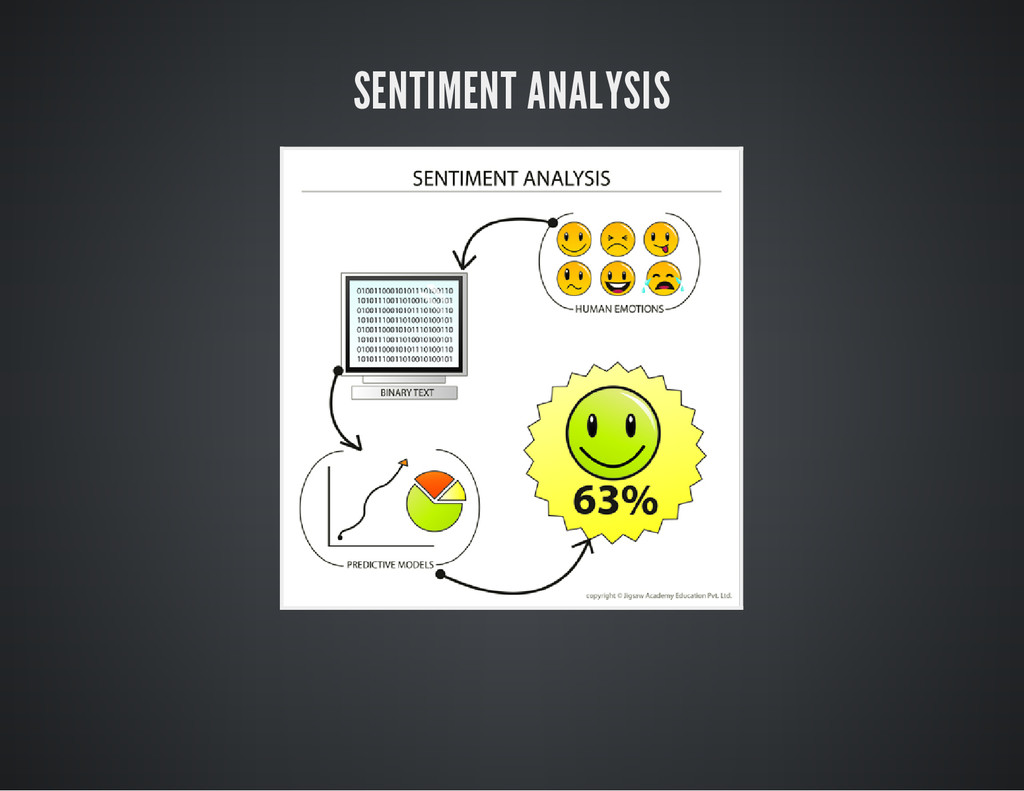{kind=link}
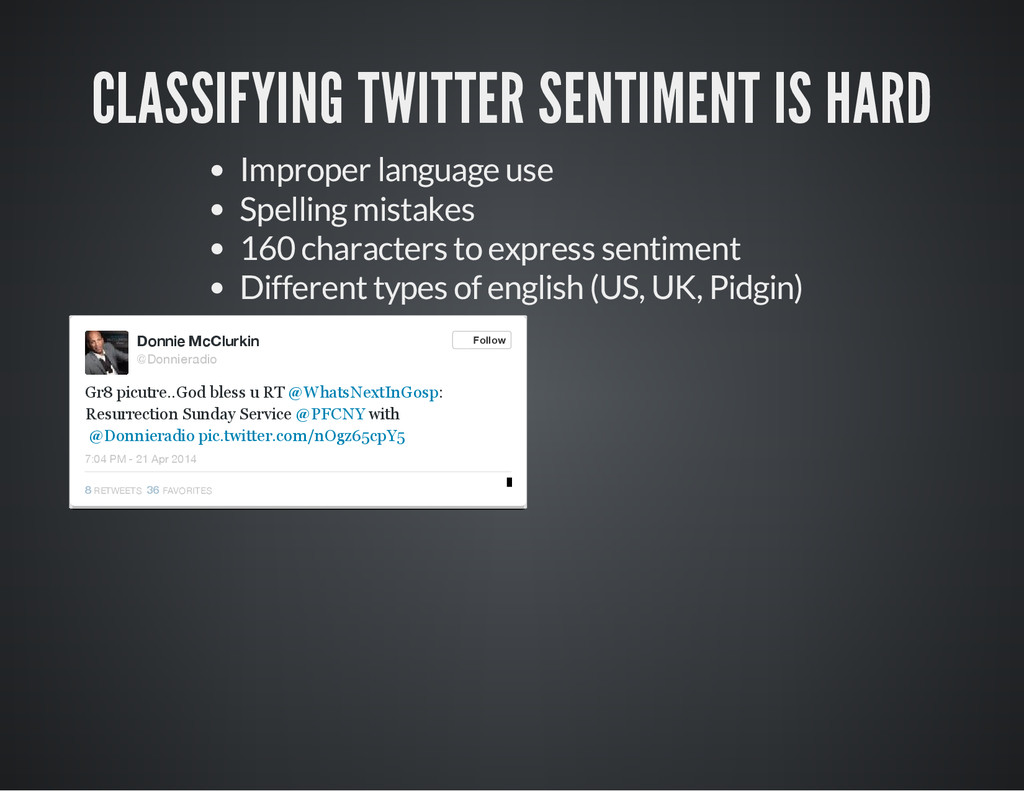{kind=link}
{kind=link}
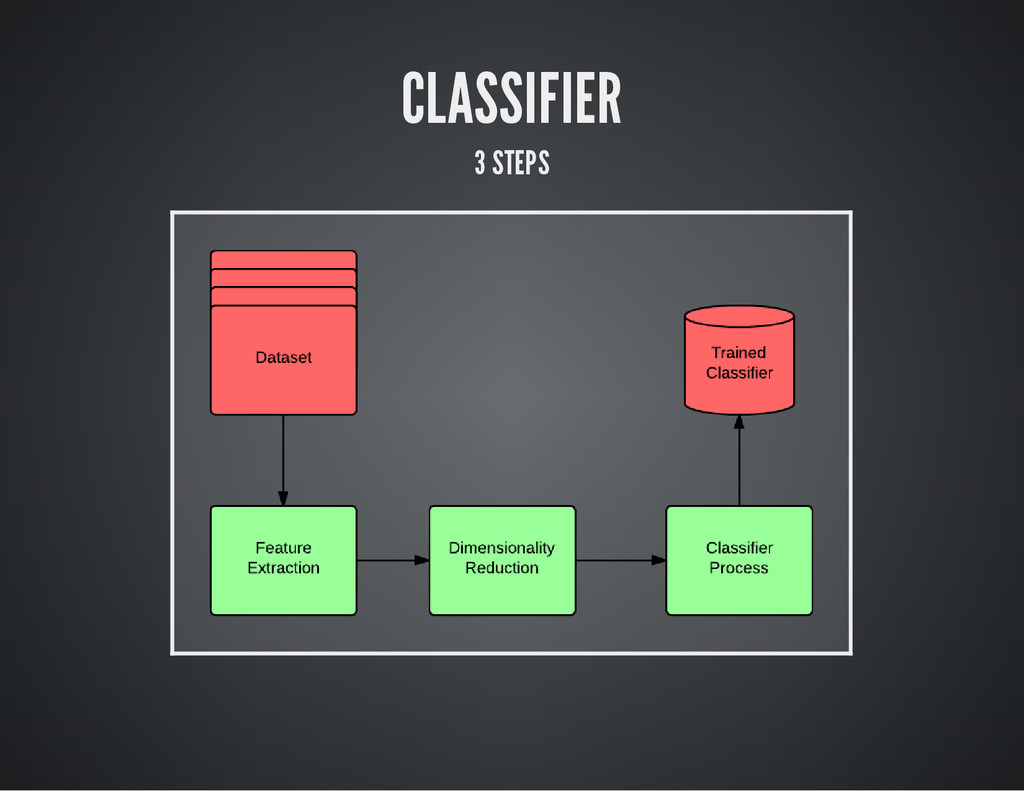{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}