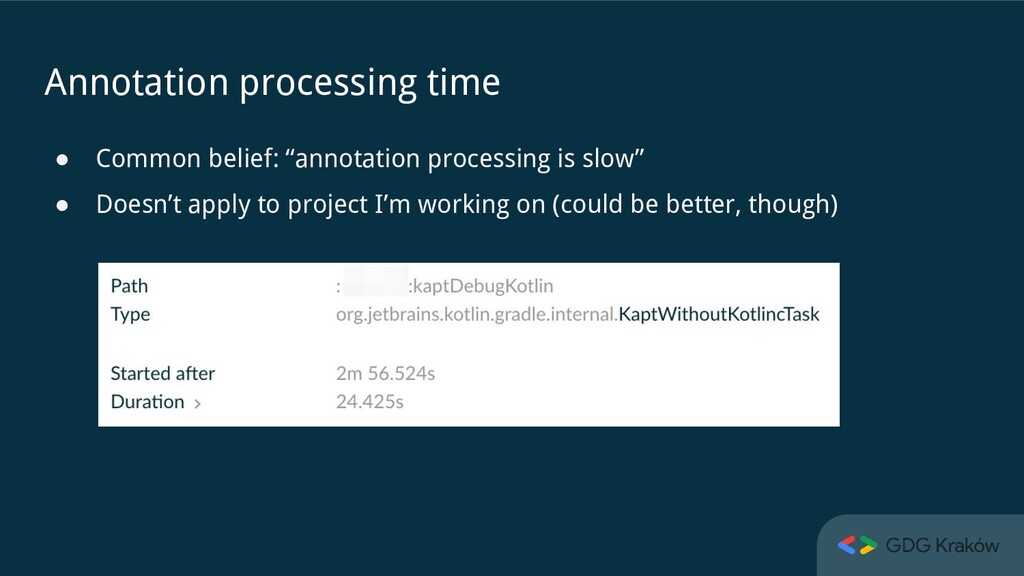
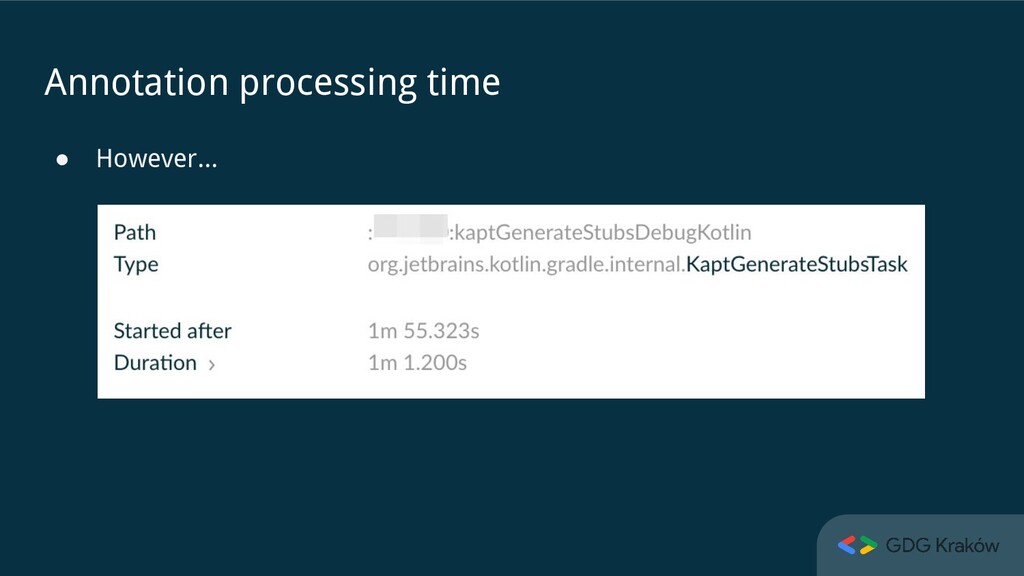
do about it” • “Better focus on the app architecture, modularization, product, ...” • “Don’t use Dagger, switch to Koin” • “No need to care about it if my app builds in less than X minutes” • “I have worse problems than this one” Why care?
tools you use in your project • You should be aware of what happens under the hood in your project ◦ You should understand your project in the technical terms ◦ You should not ignore any of the project technical areas and aspects ◦ You should not assume that something “just works” • If you notice that something is wrong, it’s too late ◦ You need to dedicate some extra time to investigate the issue ◦ Investigation can be harder, you may run into multiple problems ◦ During the investigation, the issue persists
multiplied by # of builds and devs can make a difference! • Modularization won’t solve all of your build time problems ◦ You keep tasks small, run them in parallel, but the build time is still there
your project (in technical terms) ◦ No one will give you time to do this • Jump into different areas (build/tools, static code analysis, architecture) • Try changing things, look for improvements, adopt new practices • Keep a technical backlog, pick things from it • Do it on a regular basis ◦ It’s ok to leave it for a while in hard times, but this should be an exception • Do it also when “nothing wrong happens”
◦ kapt { useBuildCache = true } • Running kapt tasks in parallel: since Kotlin 1.2.60 ◦ kapt.use.worker.api=true • Compile avoidance for kapt: since Kotlin 1.3.20 ◦ Annotation processing is skipped when source files are unchanged or changes in dependencies are ABI compatible ◦ kapt.include.compile.classpath=false
• Supported since: ◦ Gradle 4.7 (April 2018) ◦ Android Gradle Plugin 3.3 (January 2019) ◦ Kotlin (kapt) 1.3.30 (April 2019), enabled by default since Kotlin 1.3.50 • Annotation processors authors need to make them incremental • To make incremental annotation processing work, all annotation processors in the module must be incremental
for information about non-incremental processors ◦ [WARN] Incremental annotation processing requested, but support is disabled because the following processors are not incremental: com.airbnb.epoxy.EpoxyProcessor (NOT_INCREMENTAL). • Keep a list of non-incremental annotation processors • Check from time to time if there are any updates to the libraries ◦ Always check release notes for e.g. new feature toggles! • Subscribe to related GitHub issues/pull requests notifications • Move code related to particular annotation processor to other module
◦ must generate their files using Filer API ◦ must not depend on compiler-specific APIs like com.sun.source.util.Trees • “Isolating” and “aggregating” annotation processors • “Isolating” processors look at each annotated element in isolation • “Aggregating” processors can aggregate several source files into one or more output files
processing by itself ◦ it generates Java stubs and feeds them to Java annotation processing • kapt steps: ◦ Parse Kotlin sources; generate Java stubs ◦ Run Java annotation processing ◦ Compile Java sources; compile Kotlin sources • Stubs are generated even for classes without any annotations source: Vladimir Tagakov (Lyft), Droidcon San Francisco https://www.droidcon.com/media-detail?video=380953207
- “Working around kapt” lightning talk (https://www.droidcon.com/media-detail?video=380953207) • NAPT plugin ◦ annotation processing for Kotlin without kapt ◦ not open sourced yet ◦ can’t reference generated code from Kotlin (can be workarounded), can’t reference generated types from Kotlin
disable annotation processing in following scenarios: ◦ dev builds ◦ PR checks (static code analysis, unit tests) • Generated code could be replaced with reflection • Risk: can lead to runtime errors in debug builds, or compilation errors when preparing release builds • Gain: can greatly speed up most of the builds
or IDE build, e.g. properties.containsKey(“android.injected.invoked.from.ide”)>) { implementation "com.somedep:somedep-reflect:x.x.x" } else { kapt "com.somedep:somedep-processor:x.x.x" } debugImplementation "com.somedep:somedep-reflect:x.x.x" kaptRelease "com.somedep:somedep-processor:x.x.x" } • First way seems to be less readable • Second way cannot be applied for non-Android modules!
full reflection • Partial reflection still uses (in a minimal way) an annotation processor • Full reflection avoids using annotation processors • Some limitations, but didn’t run into these • Some code adjustments may be needed ◦ Lint checks for wrong annotation retention are available
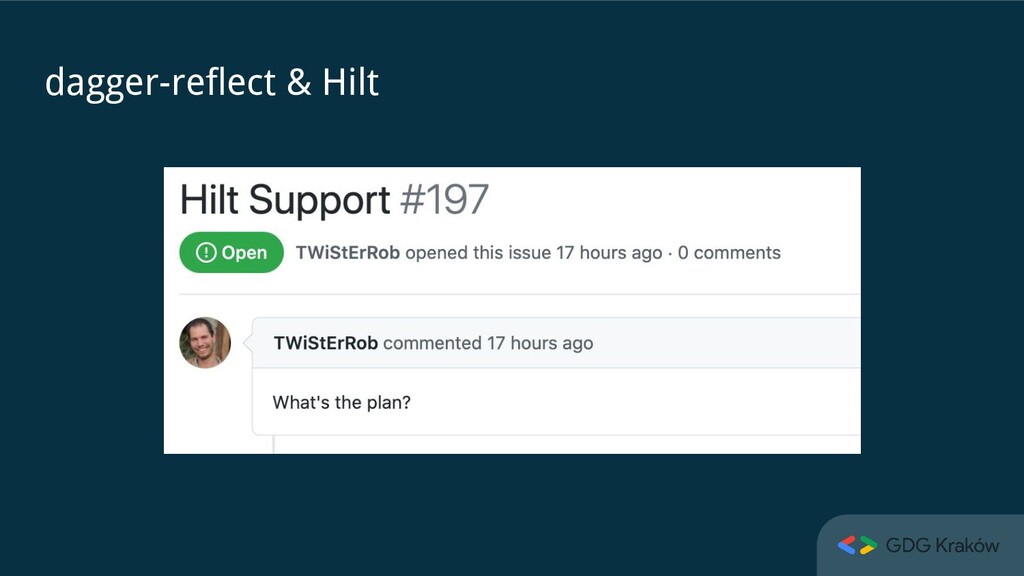
R8 issues: ◦ rules not included in the artifact ◦ suggested ones do not work when included manually ◦ https://github.com/JakeWharton/dagger-reflect/pull/143 • Some limitations, but didn’t run into these ◦ https://github.com/JakeWharton/dagger-reflect#unsupported-features-and-limitations
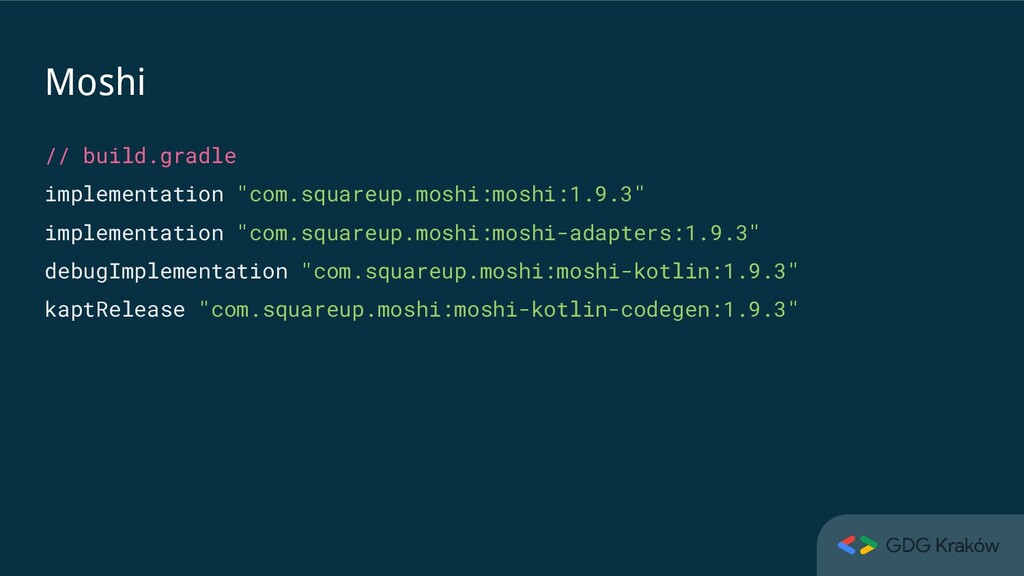
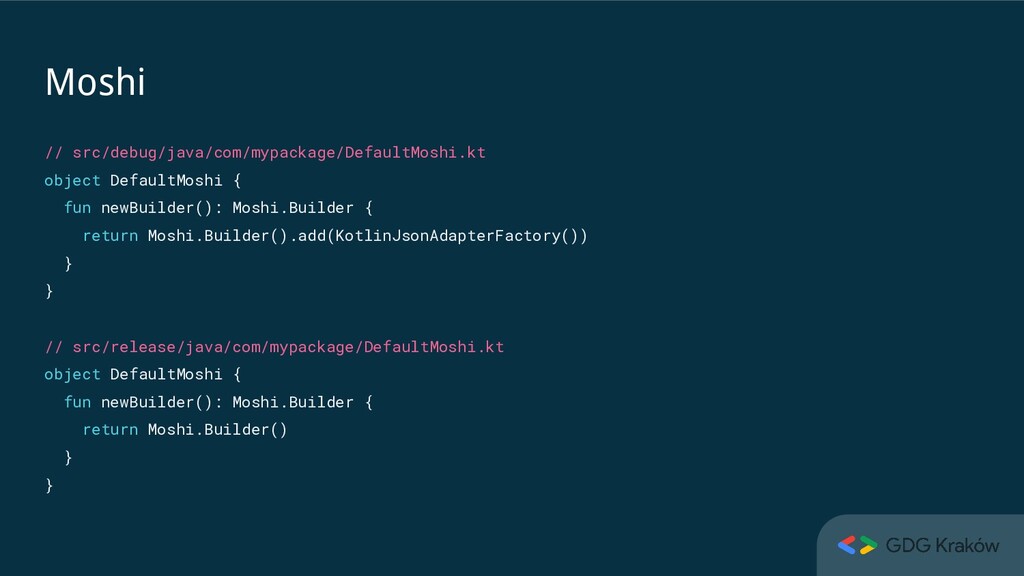
annotation processor generates adapter • A need for annotation processing can be skipped by using reflection-based adapter: val moshi = Moshi.Builder() .add(KotlinJsonAdapterFactory()) .build()
"error_logs": { "log1": "value1", "log2": "value2" } } data class Message( val type: Type, // enum val value: String?, val error_logs: Map<String, Any>? )
lightweight plugins for Kotlin compiler • Developed by Google, available in Kotlin 1.4-M1 • “For some processors (...) KSP reduces full compilation times by up to 25% when compared to KAPT” • Incremental processing planned, but not implemented yet
you’re running latest versions of Gradle, Android Gradle Plugin and Kotlin and all the optimization flags are correctly switched 2. Make sure you’re using incremental annotation processors. Don’t mix in one module incremental processors with non-incremental ones. 3. Use reflection-based artifacts for dev/debug/PR check builds. 4. If possible, drop kapt for that builds. 5. Look for Kotlin with stable KSP version and libraries that will use it.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}