pour passer d'un état à un autre état Test de succès (pour déterminer si un état correspond au but désiré) Fonction de coût (pour évaluer le coût du passage d'un état à un autre)
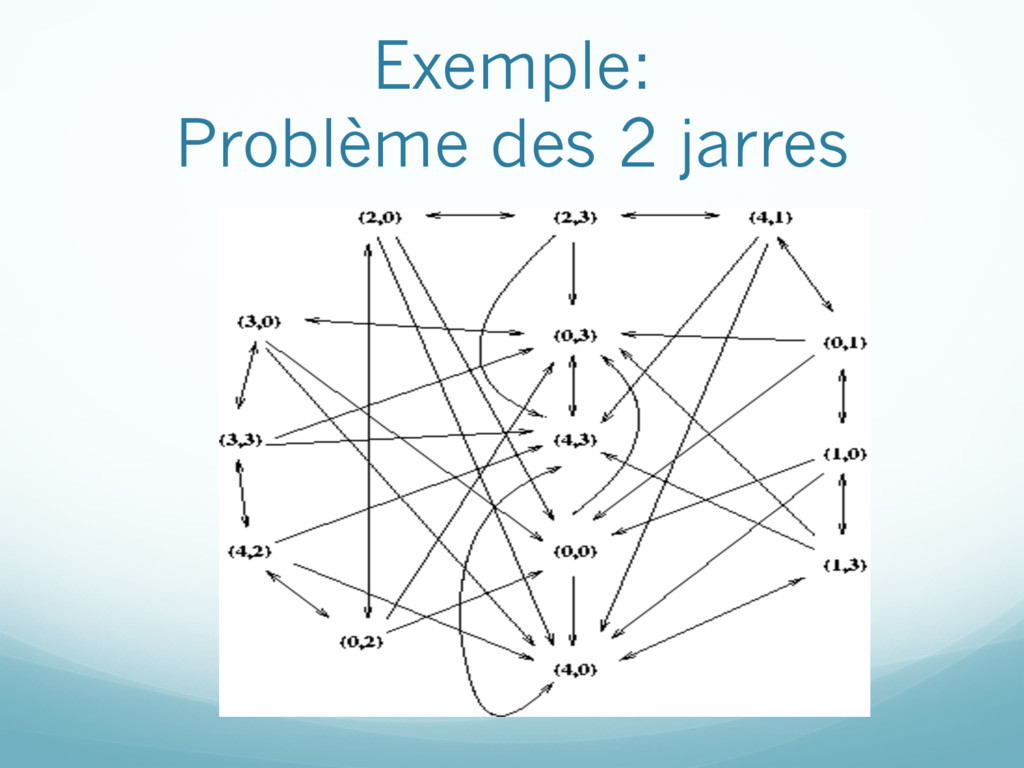
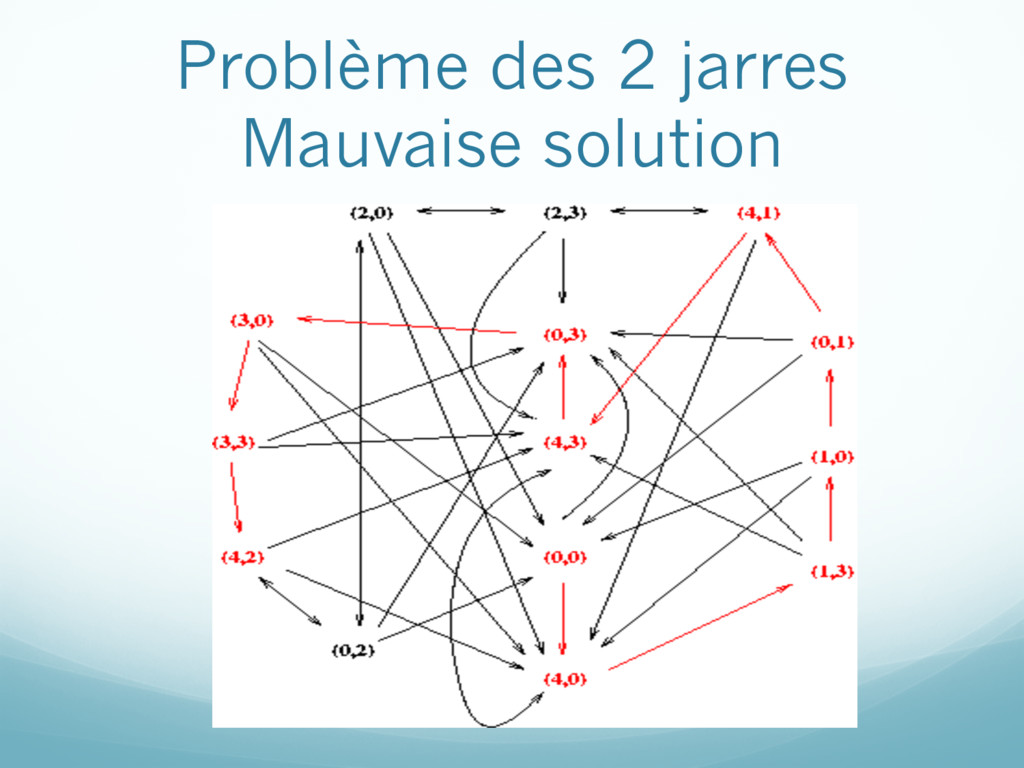
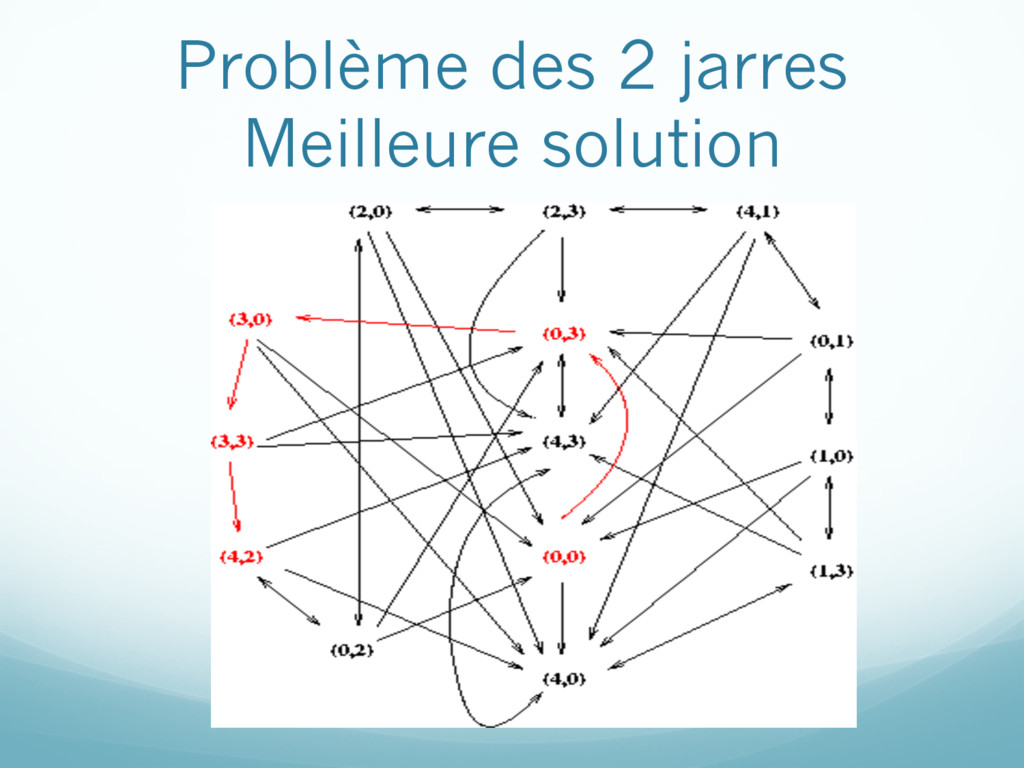
représente le contenu des deux jarres État initial: (0,0) État final: une des deux jarres contient exactement deux litres Opérateurs (coût toujours égal à 1): Remplir une jarre Vider une jarre Transvider une jarre dans l’autre
évalué selon une fonction f(n) = g(n) + h(n) où g(n) est le coût de l'état initial au noeud n h(n) est un estimé du coût du noeud n à l'état final (heuristique) L’heuristique doit être admissible: elle ne surestime jamais le coût pour atteindre le but À chaque itération, on choisit de faire l’expansion du nœud n dont f(n) est le plus bas
final nous intéresse On ne conserve qu'un seul état en mémoire, soit le noeud courant On considère tous les noeuds successeurs du noeud courant, qui constituent le voisinage On choisit un de ces noeuds, qui deviendra le noeud courant On répète le processus jusqu'à l'obtention de l'état désiré
h(n) qu'il faut minimiser On génère une solution initiale On calcule h(n') pour tous les noeuds n' successeurs du noeud courant n On choisit le noeud n' qui minimise h(n') et tel que h(n') < h(n)
états sont représentés par une collection de termes prédicatifs Formalisme PDDL (Planning Domain Definition Language) qui est dérivé du langage STRIPS
contenant aucune variable et aucune fonction at(plane23,dorval) on, off On appelle fluent chacun de ces termes Un état peut être vu comme un ensemble de fluents qui doivent tous être vrais Si un fluent n’apparaît pas dans un état, il est supposé faux On définit les actions en spécifiant leurs préconditions et leurs effets
ses variables, ainsi que les préconditions et l’effet Exemple: (:action fly :parameters (?p ?orig ?dest) :precondition (and (plane ?p) (at ?p ?orig) ) (airport ?orig) (airport ?dest)) :effect (and (not (at ?p ?orig) (at ?p ?dest)))) Une action peut être exécutée quand un état respecte toutes ses préconditions Si une action est exécutée: on retire de l’état tout terme x tel que –x est dans EFFET on ajoute dans l’état tout terme x tel que +x est dans EFFET
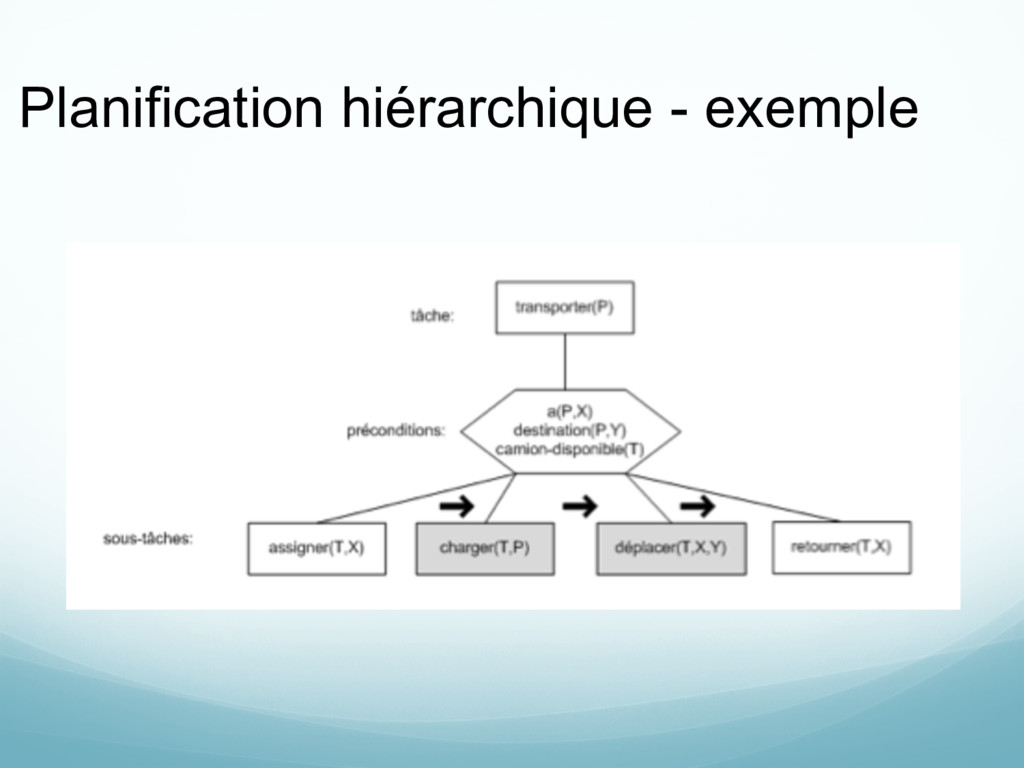
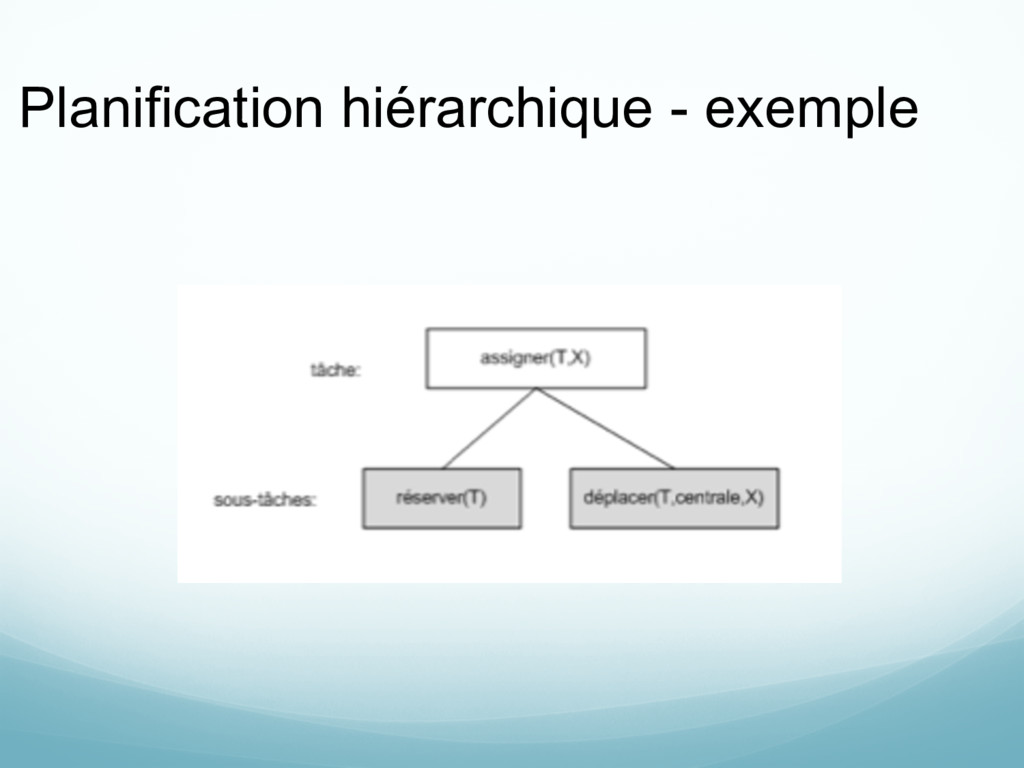
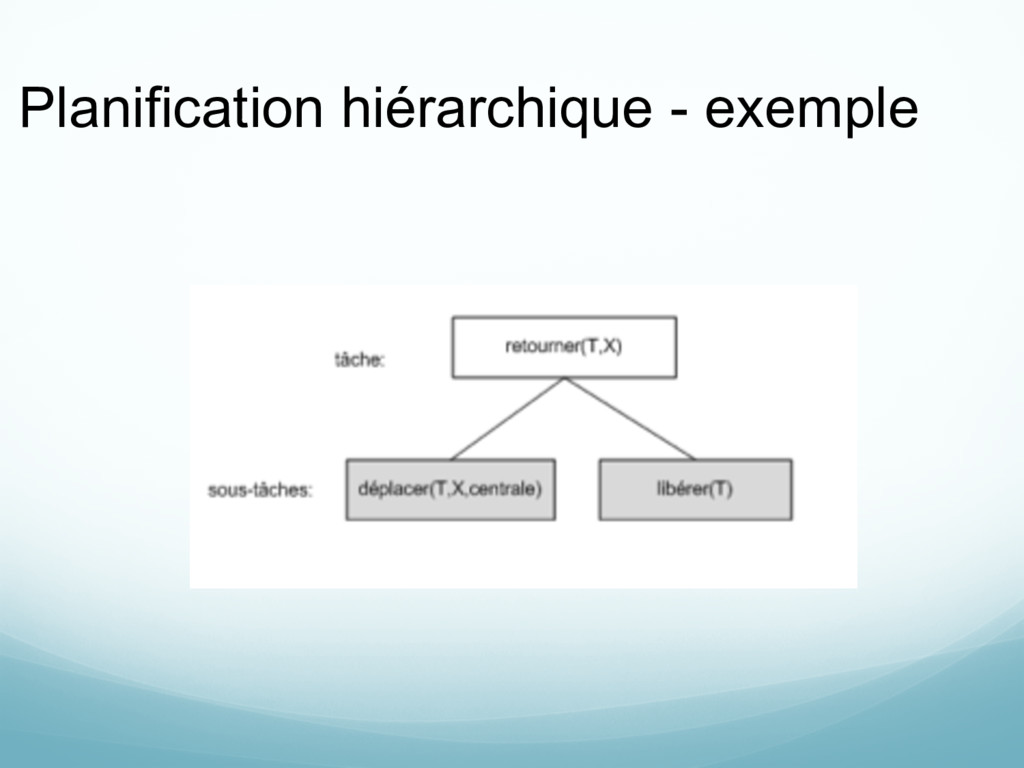
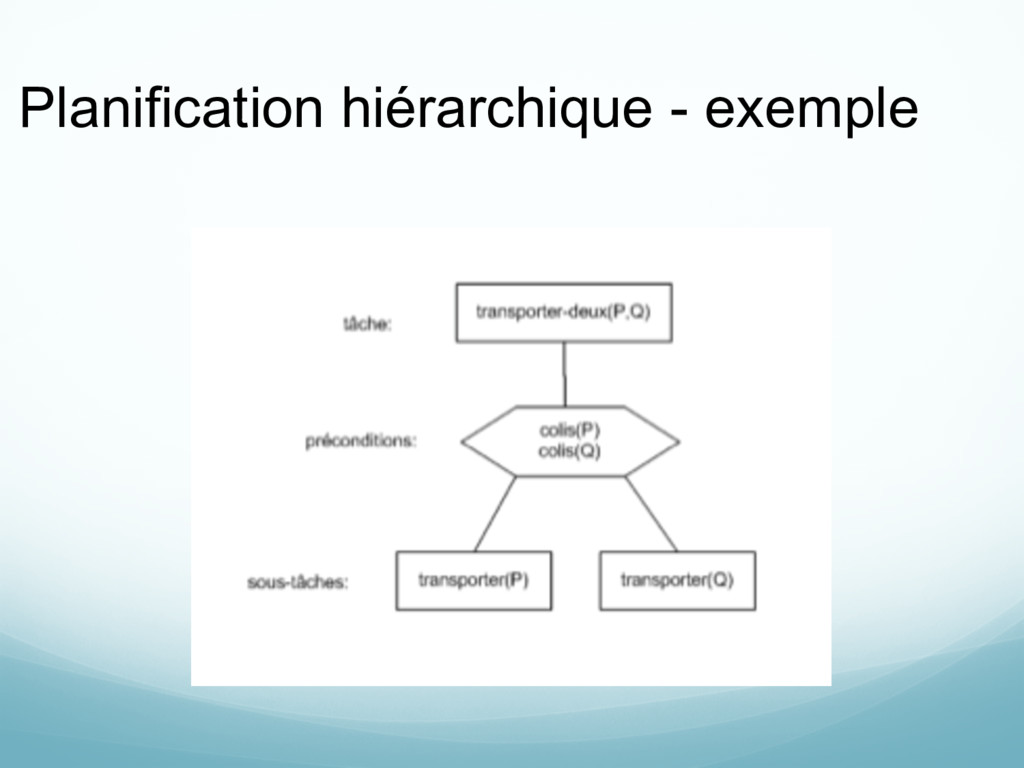
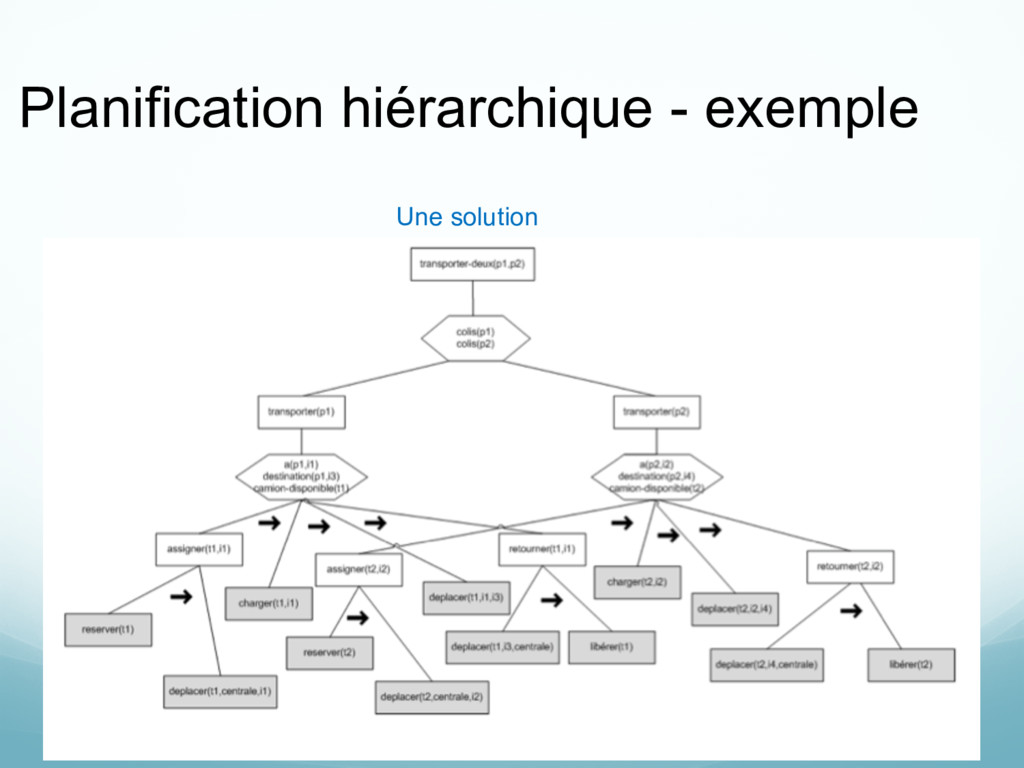
actions de haut niveau Règles de raffinement: définit comment une action de haut niveau se décompose en une séquence d’actions (primitives ou de haut niveau)
markovien Modèle de transition: T(s,a,s') représente la probabilité d'obtenir l'état s' si on exécute l'action a à l'état s Fonction de récompense: R(s) La solution est une politique (s), qui spécifie l'action recommandée pour chaque état s Meilleure politique :
passe à un nouvel état sont utilisées pour définir une politique optimale Principe: mélange d'exploration et d'exploitation Une implémentation simple: à intervalles réguliers, on choisit une action aléatoirement Une meilleure approche: favoriser les actions qui ont été peu essayées en leur attribuant arbitrairement une récompense très élevée Méthode très utilisée: Q-learning
de Russell et Norvig Notes on Artificial Intelligence de Francis Tseng Mes vidéos sur Youtube Recherche dans un espace d’état: AI - Popular Search Algorithms Stochastic Local Search – Foundations and Applications Stochastic Local Search Algorithms: An Overview Planification: PDDL FF SHOP (Simple Hierarchical Ordered Planner) Reinforcement learning: Simple Beginner’s guide An Introduction (draft)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}