Share
プログラムを高速化するためのテクニックをまとめました。GPU編はこちら https://speakerdeck.com/primenumber/puroguramuwogao-su-hua-suruhua-ii-gpgpubian
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
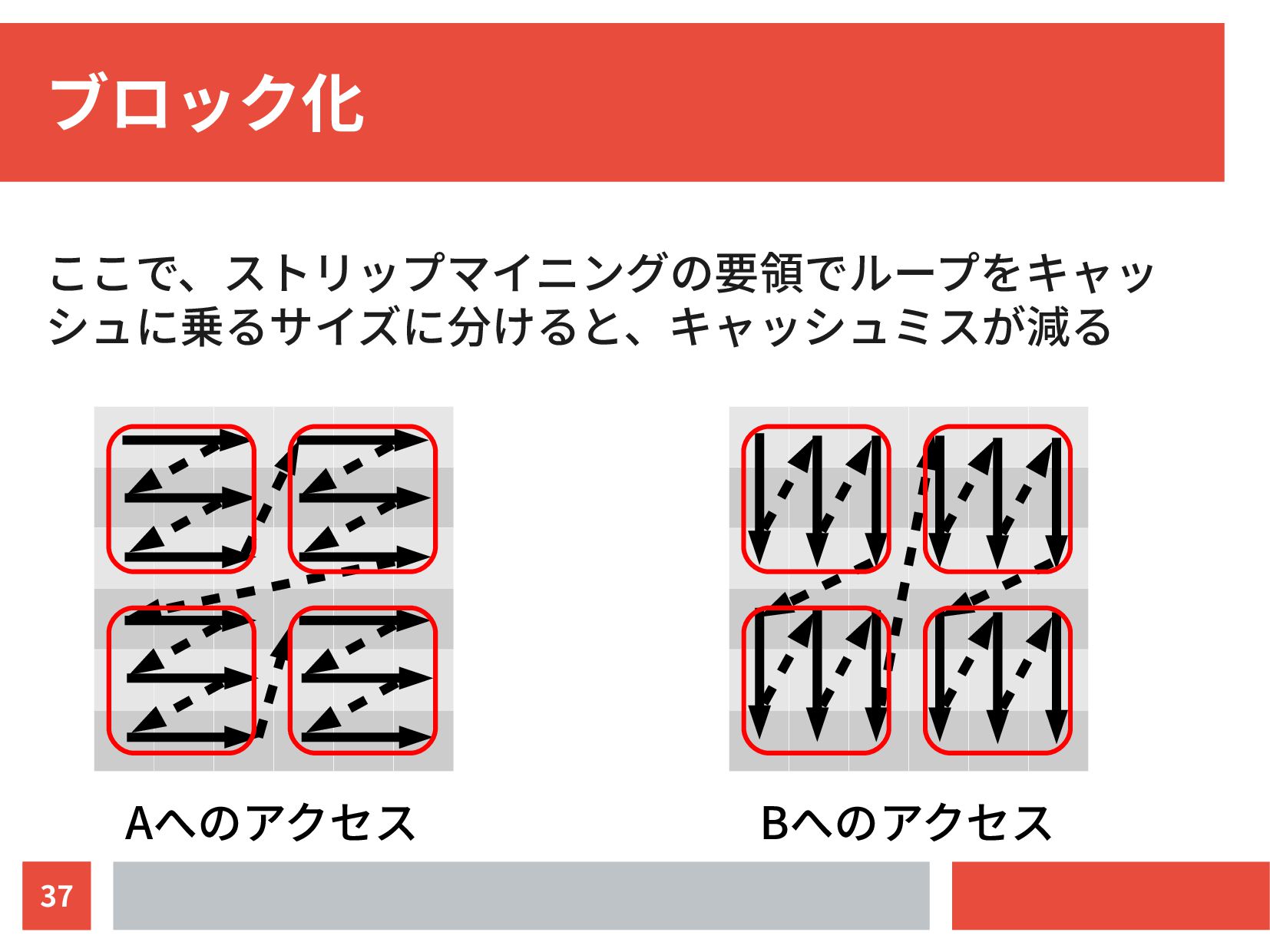{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
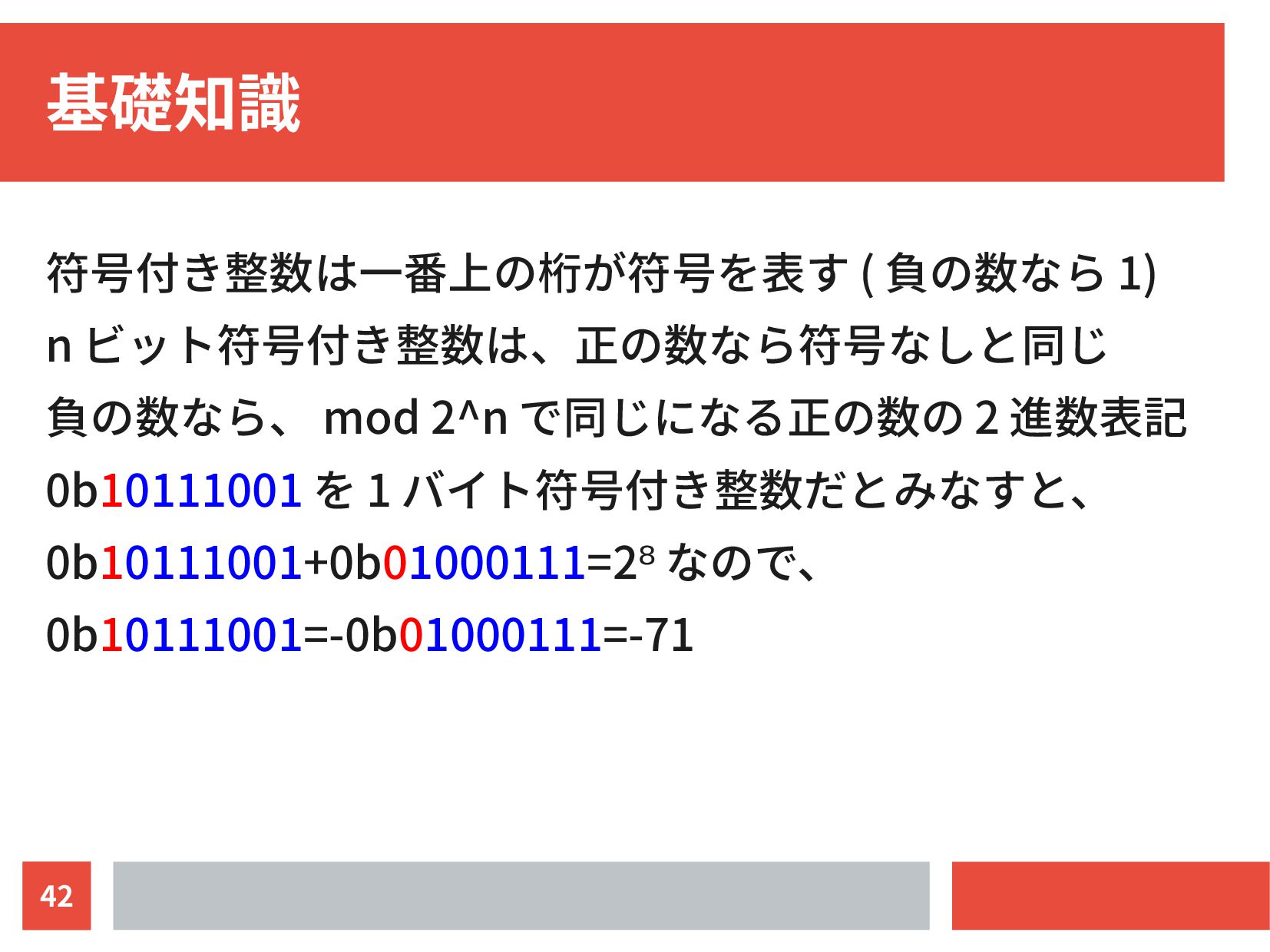{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
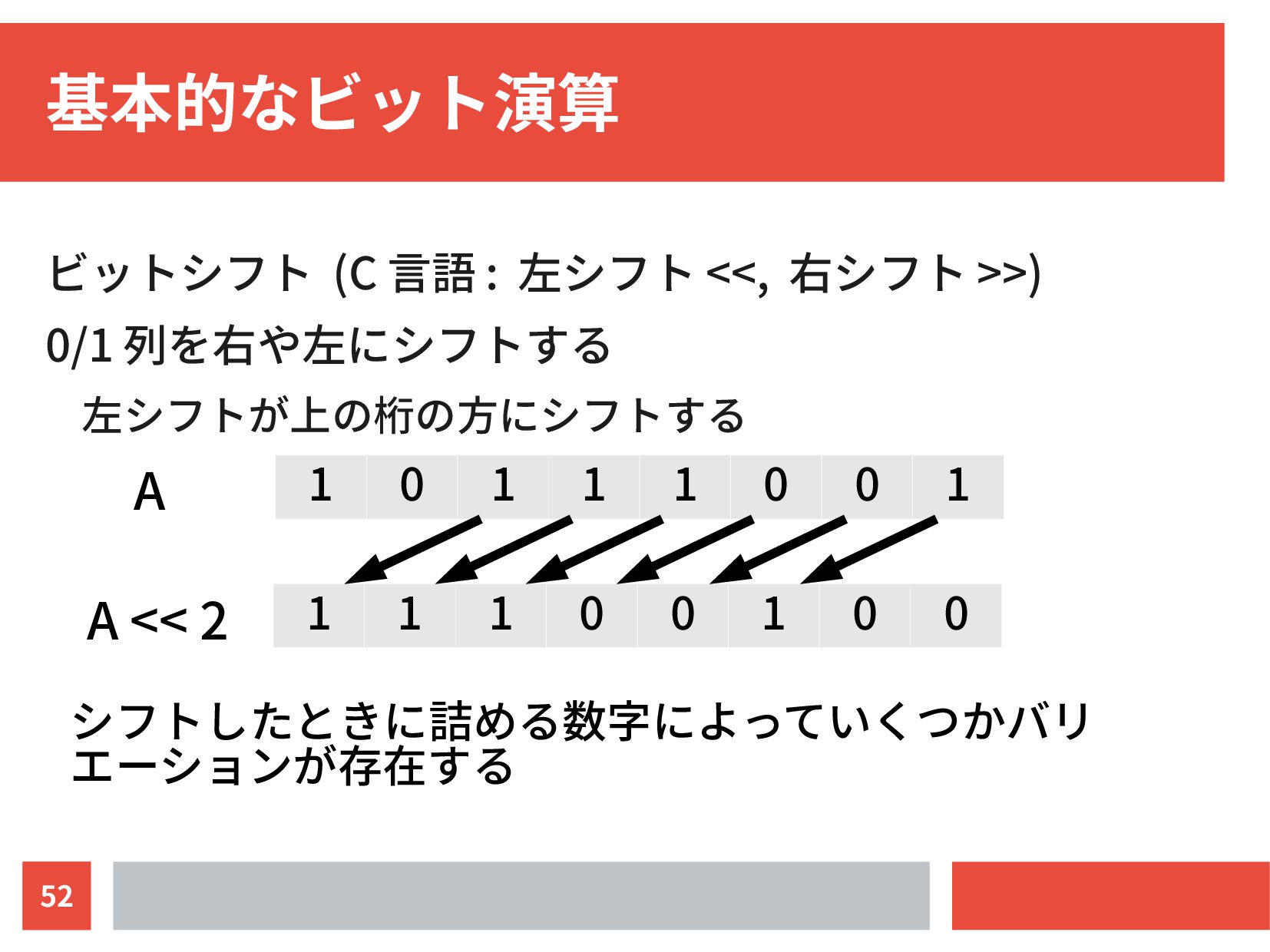{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
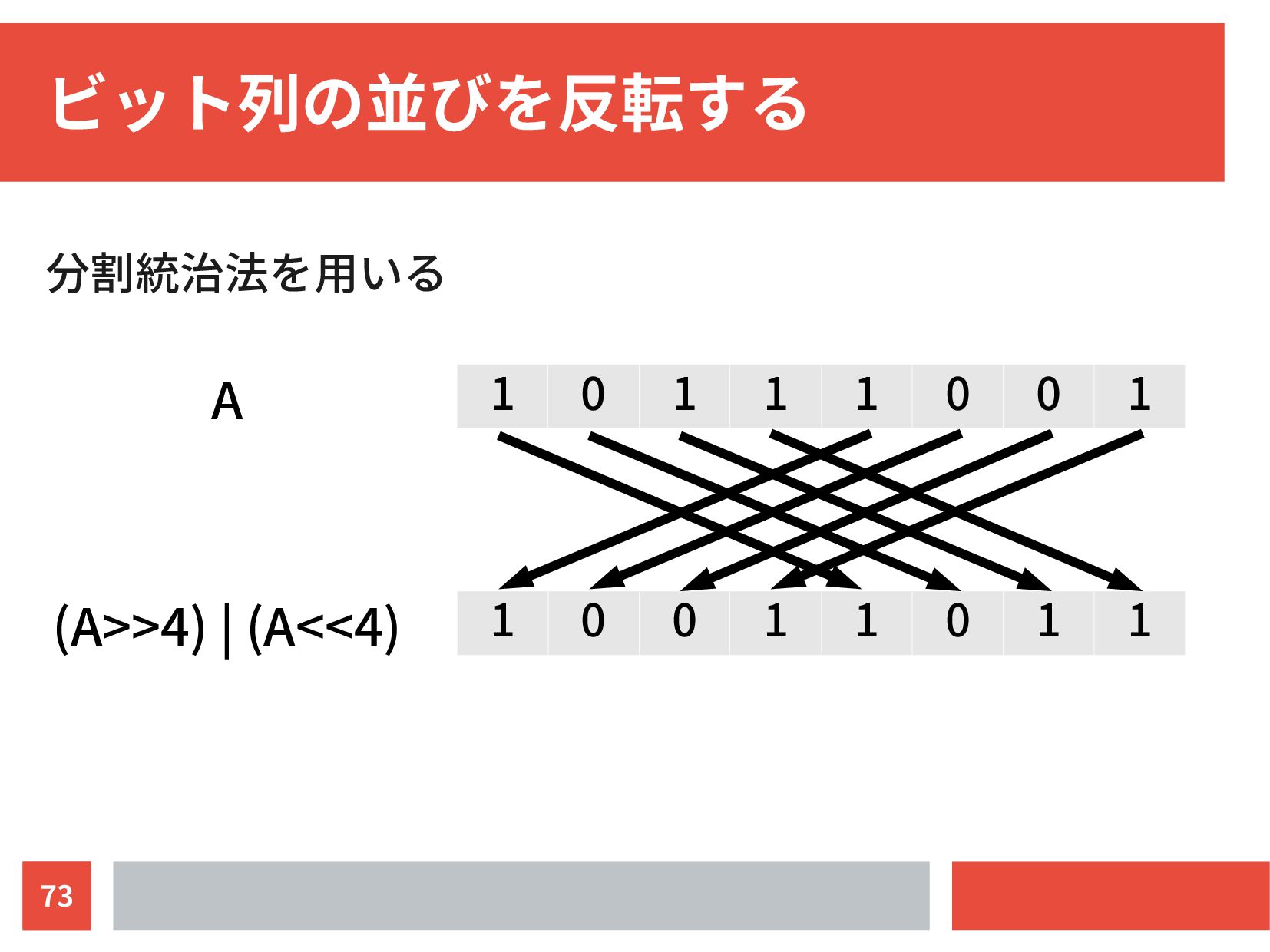
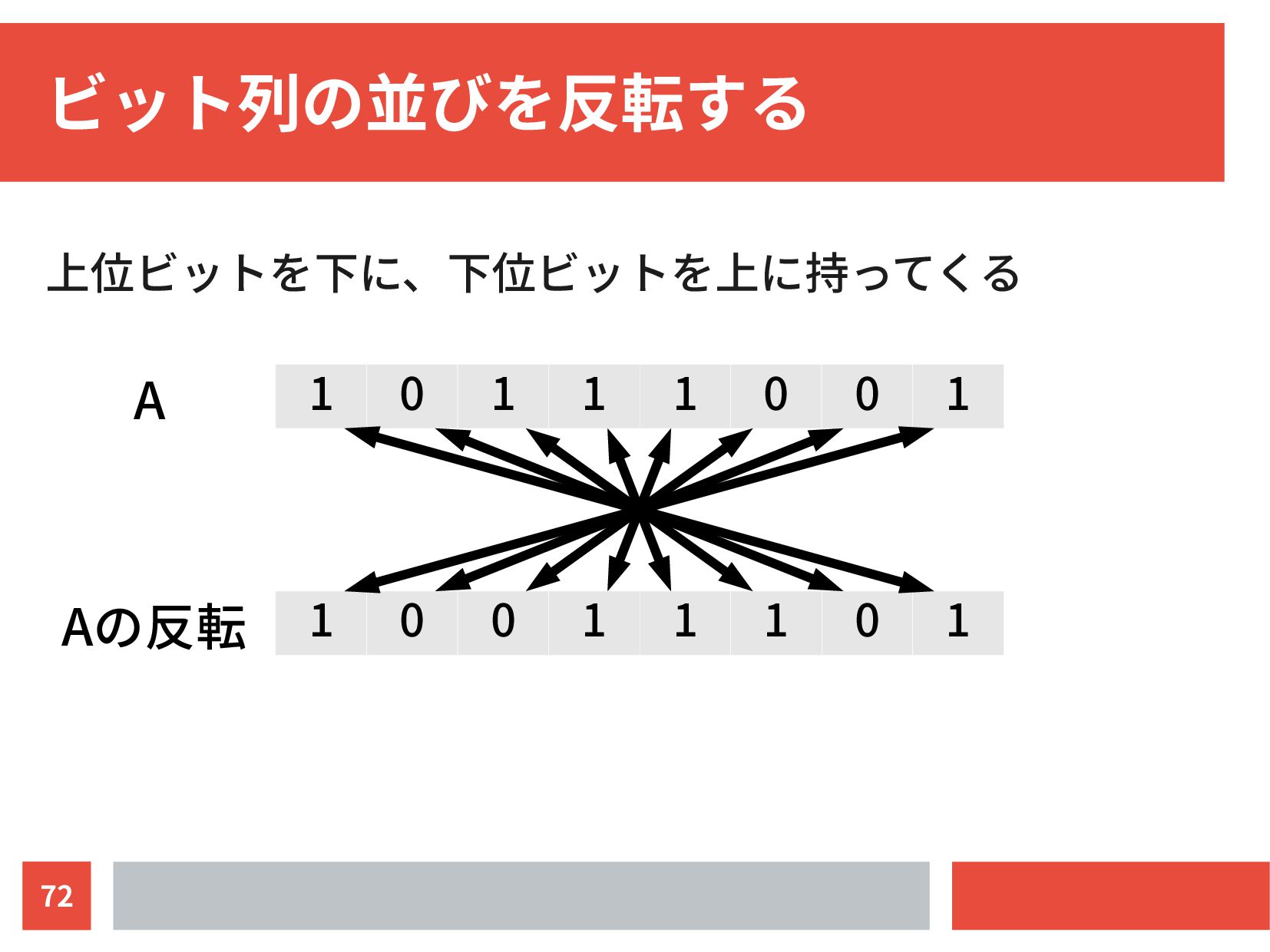{kind=link}
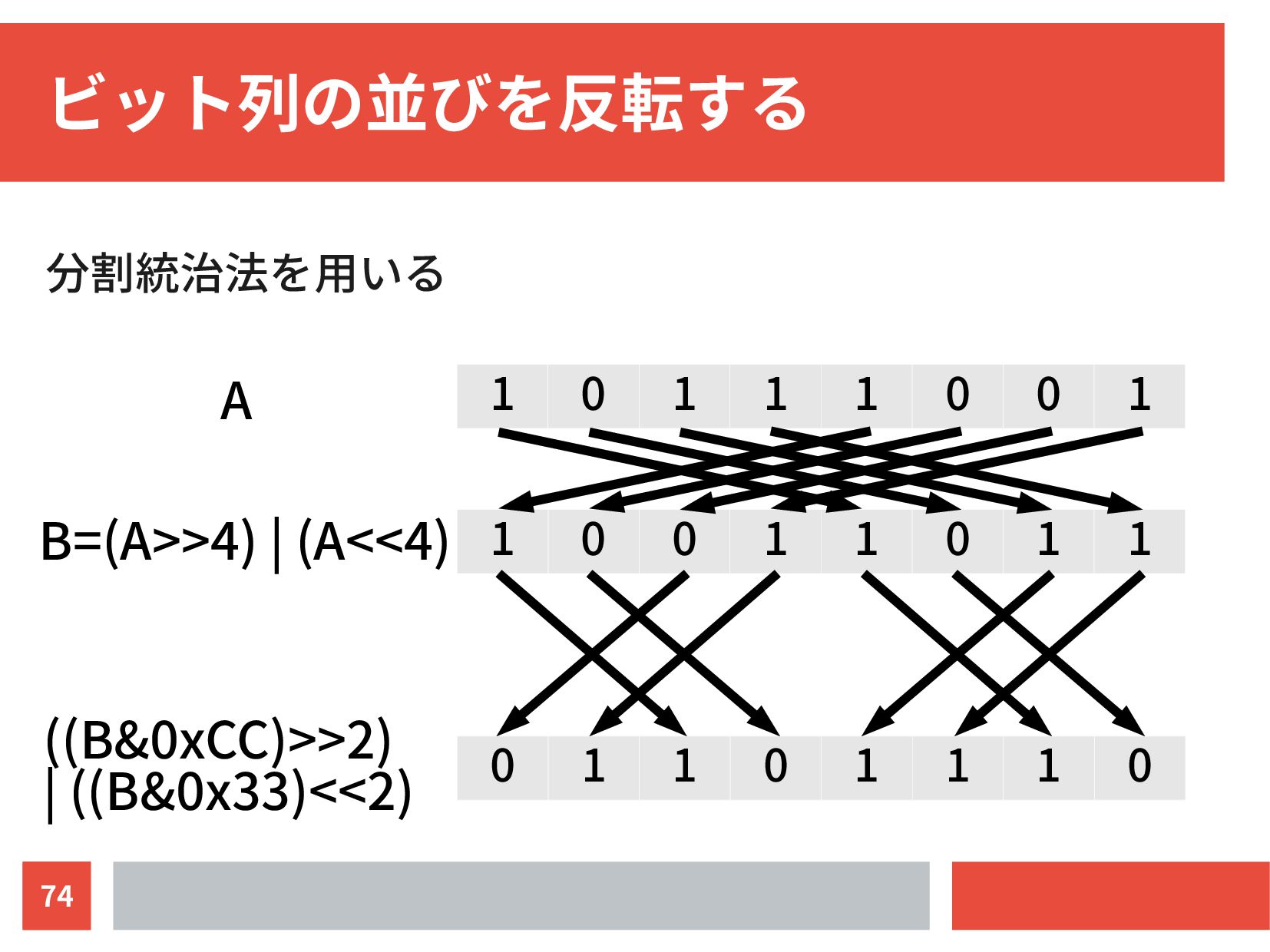
{kind=link}
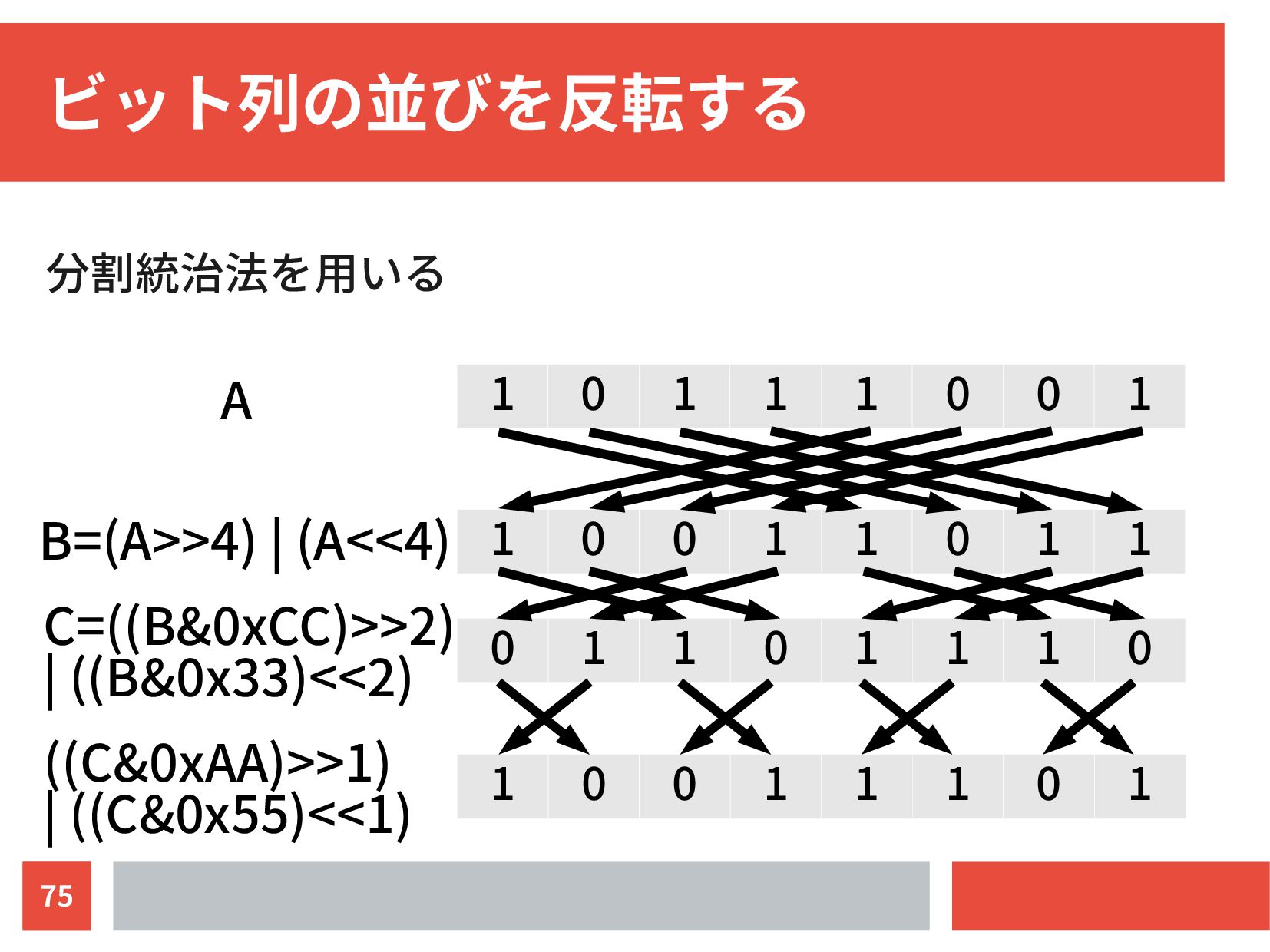
{kind=link}
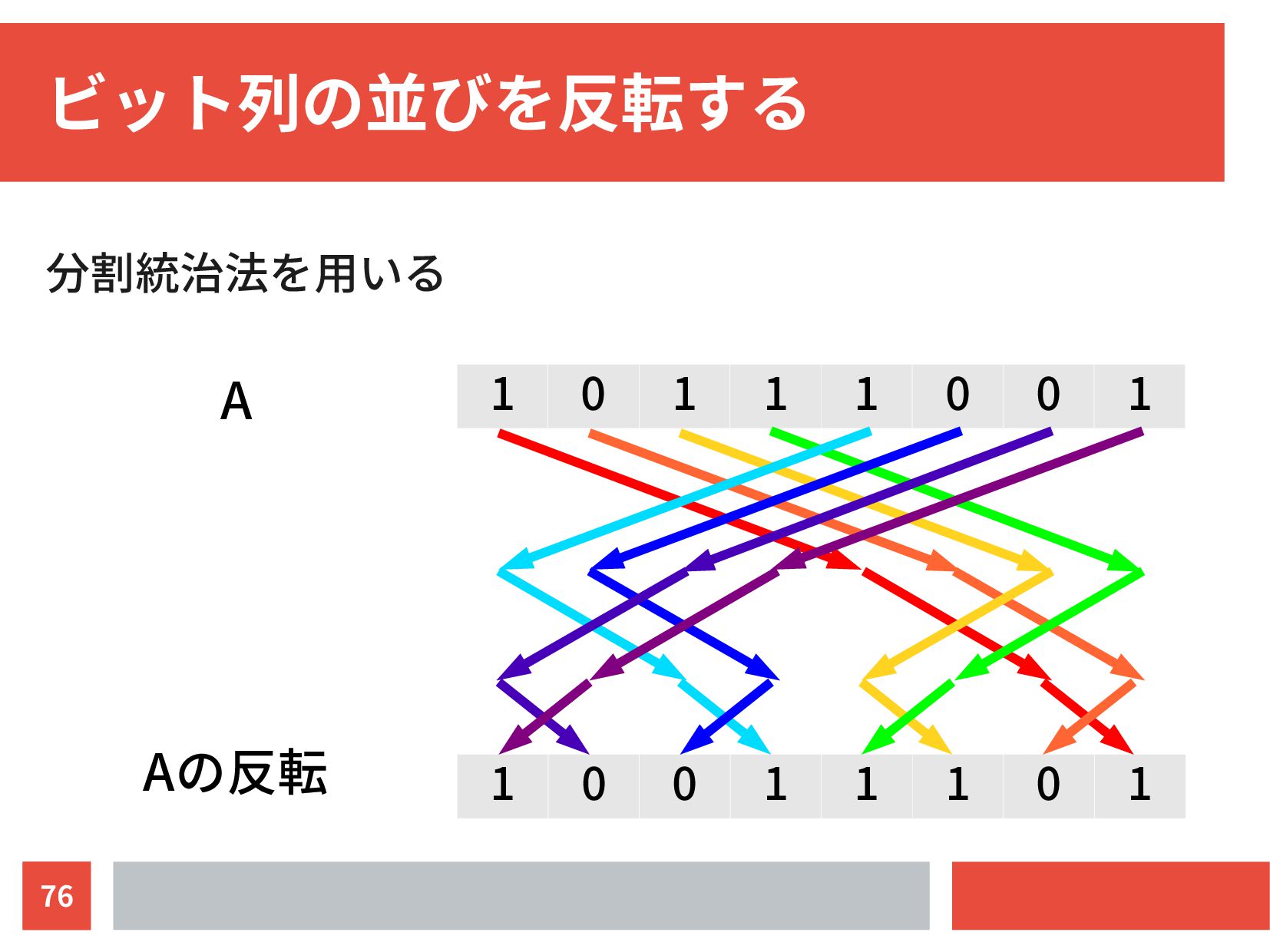
{kind=link}
{kind=link}
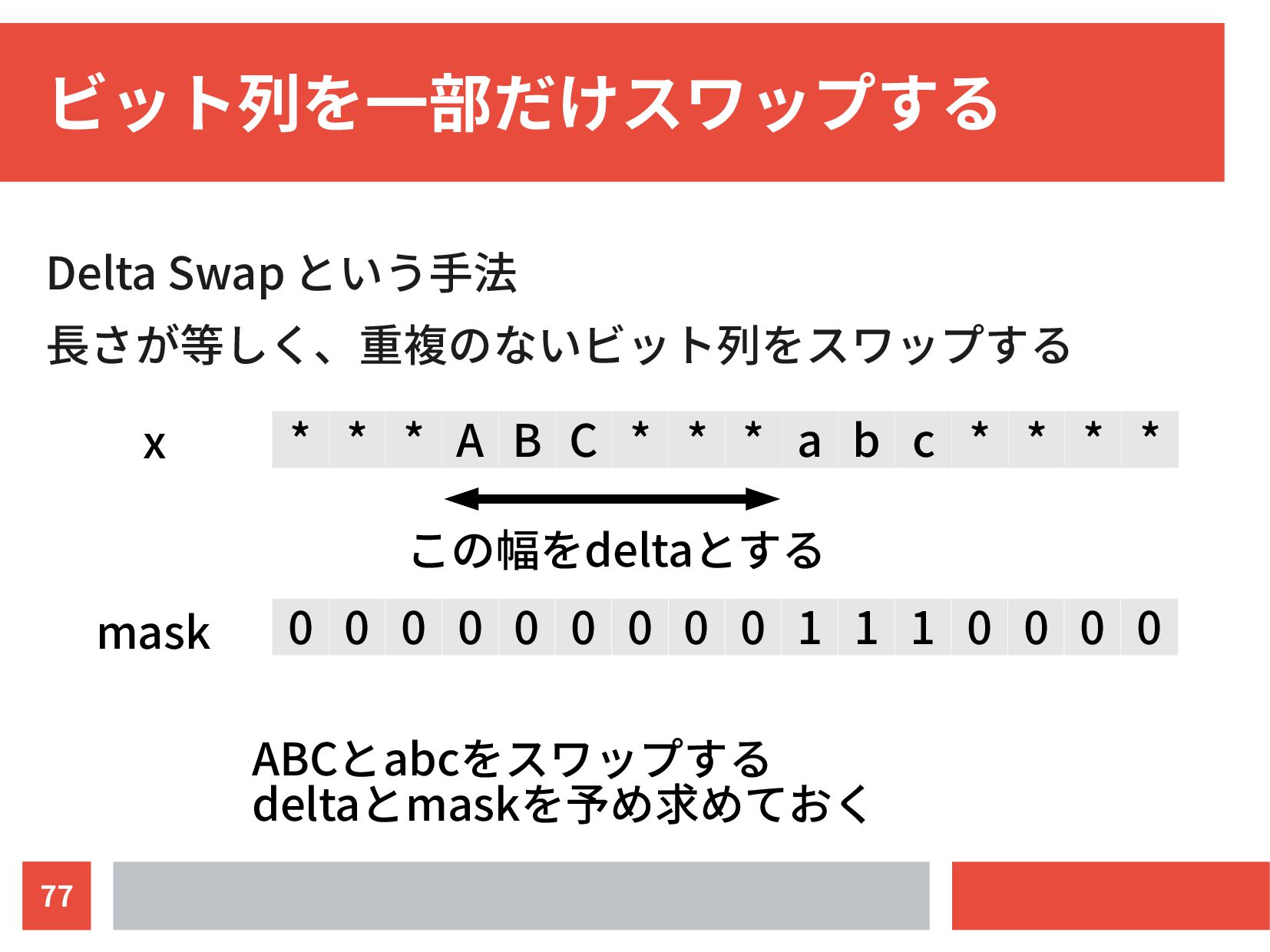{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
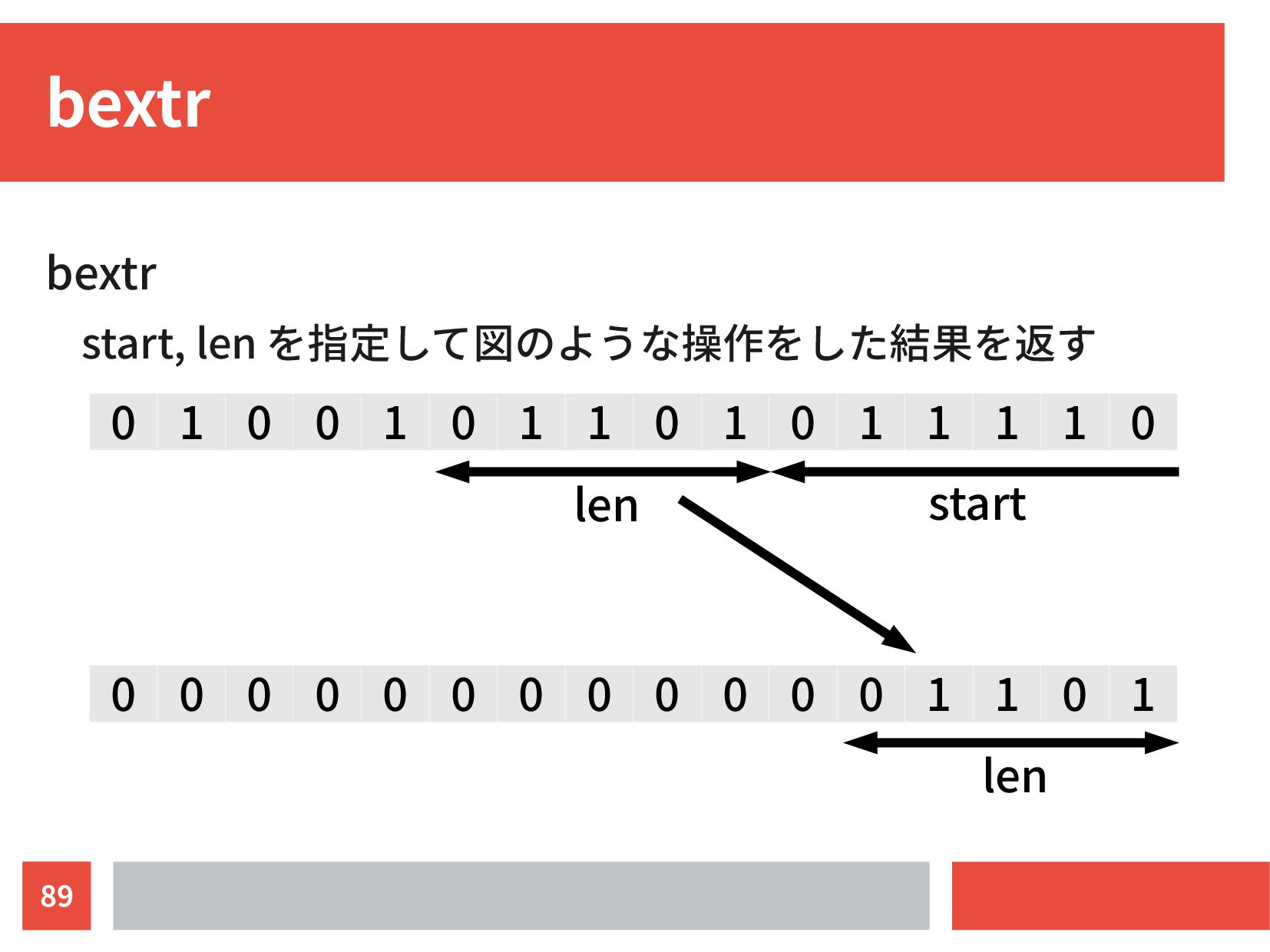{kind=link}
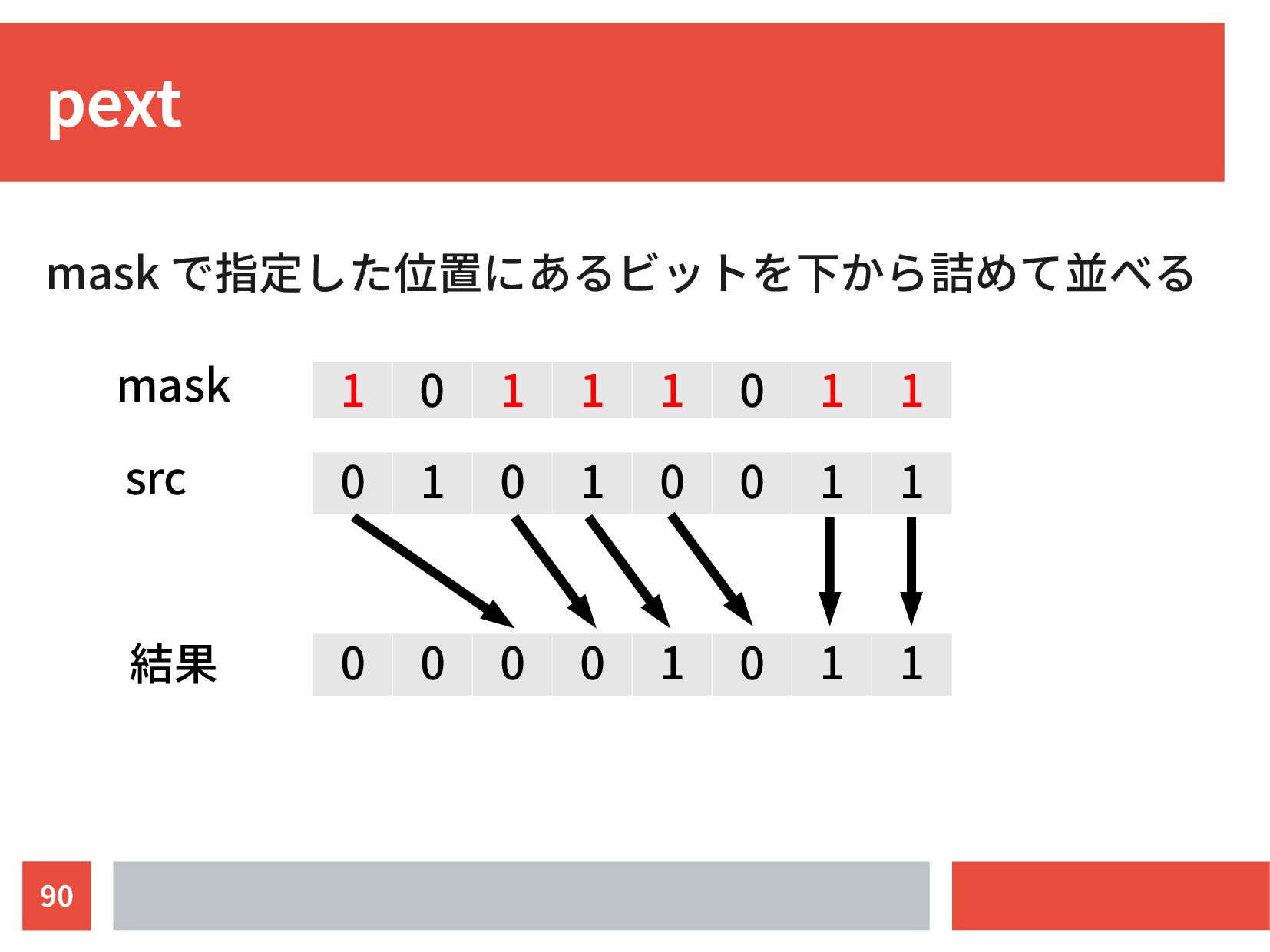{kind=link}
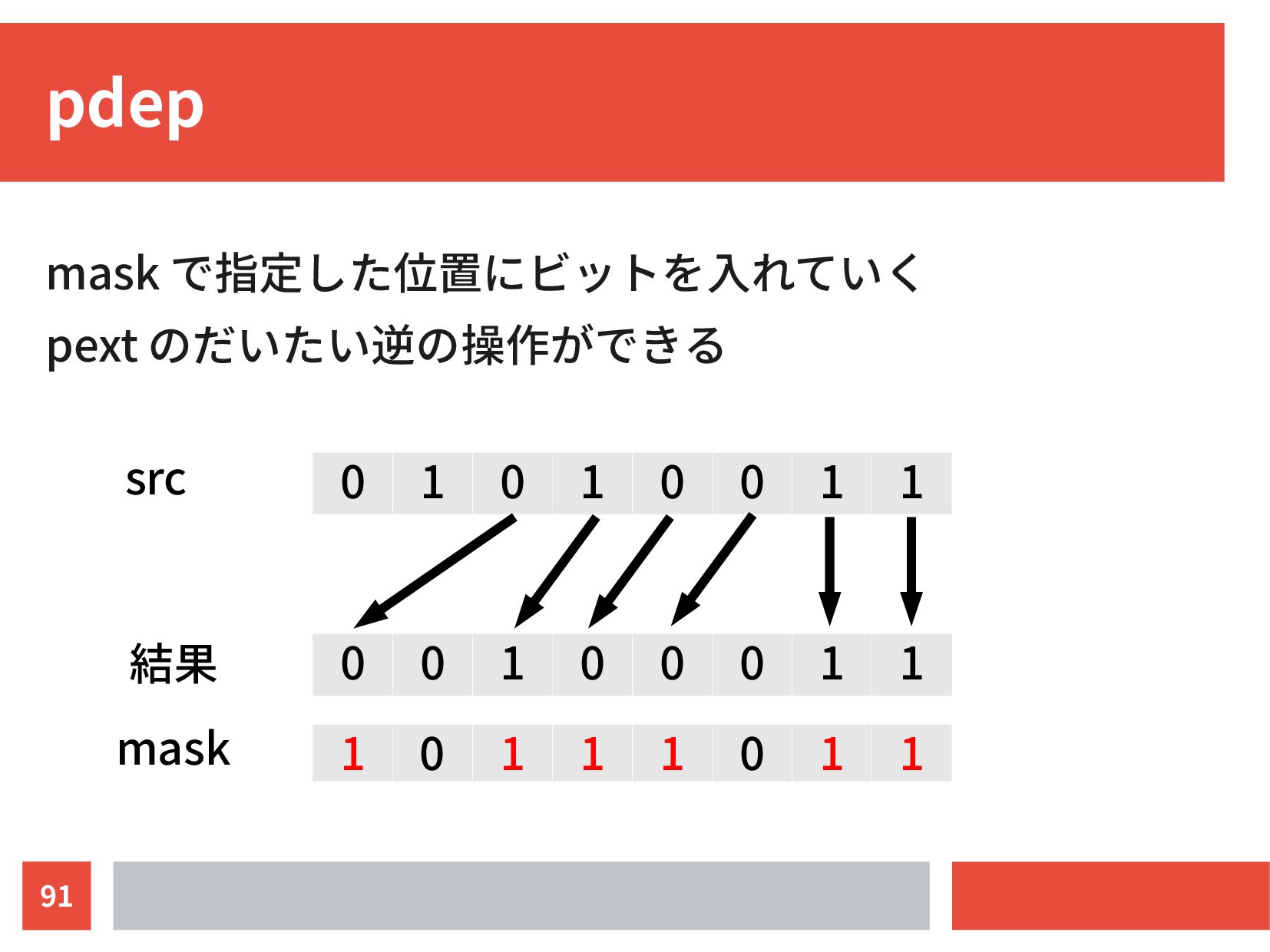{kind=link}
{kind=link}
{kind=link}
![94 SIMD 命令とは A[0] A[1] A[2] A[3] B[0] B[1] B[2]](https://files.speakerdeck.com/presentations/7e5323f76f3c48cba64f6d2566496e4f/slide_93.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![105 メモリアラインメント 静的確保 alignas(32) uint64_t ary[SIZE]; ary の先頭は 32 バイト境界に合わせられる](https://files.speakerdeck.com/presentations/7e5323f76f3c48cba64f6d2566496e4f/slide_104.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![120 参考文献等 [0] インテル ® 64 アーキテクチャーおよび IA-32 アーキテク チャー最適化リファレンス・マニュアル](https://files.speakerdeck.com/presentations/7e5323f76f3c48cba64f6d2566496e4f/slide_119.jpg){kind=link}
![121 参考文献等 [3] Intel® Architecture Instruction Set Extensions Programming Reference](https://files.speakerdeck.com/presentations/7e5323f76f3c48cba64f6d2566496e4f/slide_120.jpg){kind=link}
![122 参考文献等 [6] Chess Programming Wiki https://chessprogramming.wikispaces.com/](https://files.speakerdeck.com/presentations/7e5323f76f3c48cba64f6d2566496e4f/slide_121.jpg){kind=link}