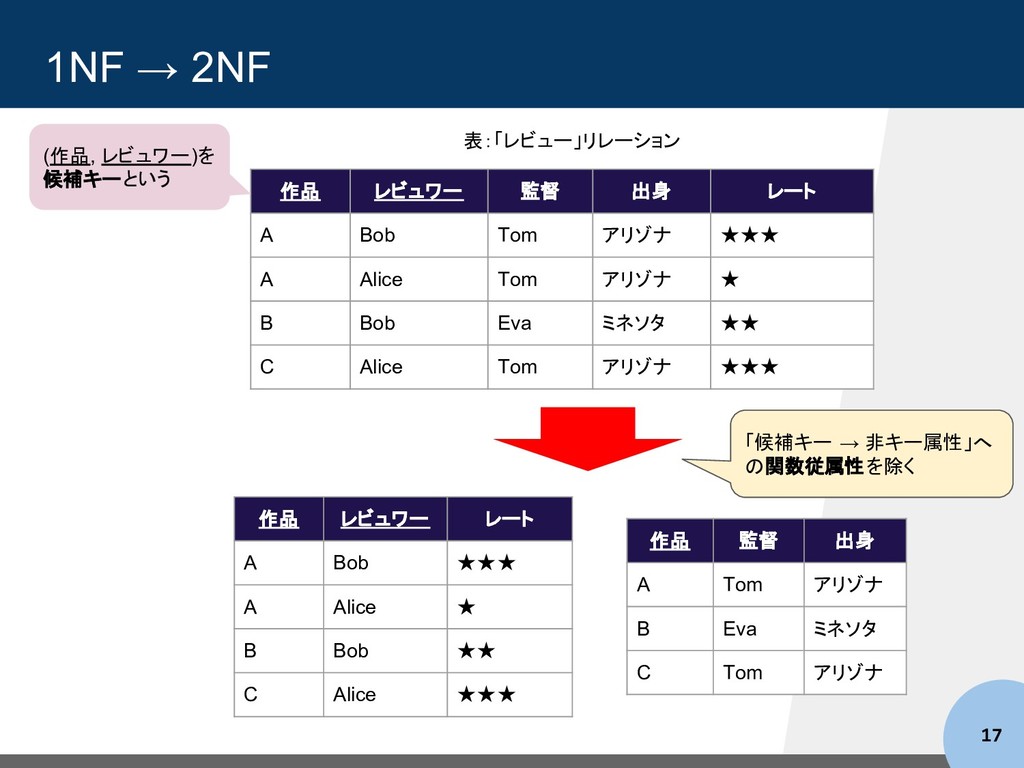
Bob Tom アリゾナ ★★★ A Alice Tom アリゾナ ★ B Bob Eva ミネソタ ★★ C Alice Tom アリゾナ ★★★ 表:「レビュー」リレーション (作品, レビュワー)を 候補キーという 作品 レビュワー レート A Bob ★★★ A Alice ★ B Bob ★★ C Alice ★★★ 作品 監督 出身 A Tom アリゾナ B Eva ミネソタ C Tom アリゾナ 「候補キー → 非キー属性」へ の関数従属性を除く
TABLE city ( city_id integer NOT NULL, city character varying(50) NOT NULL, country_id smallint NOT NULL REFERENCES country, last_update timestamp NOT NULL DEFAULT now(), PRIMARY KEY (city_id) ); 参照テーブル 被参照テーブル
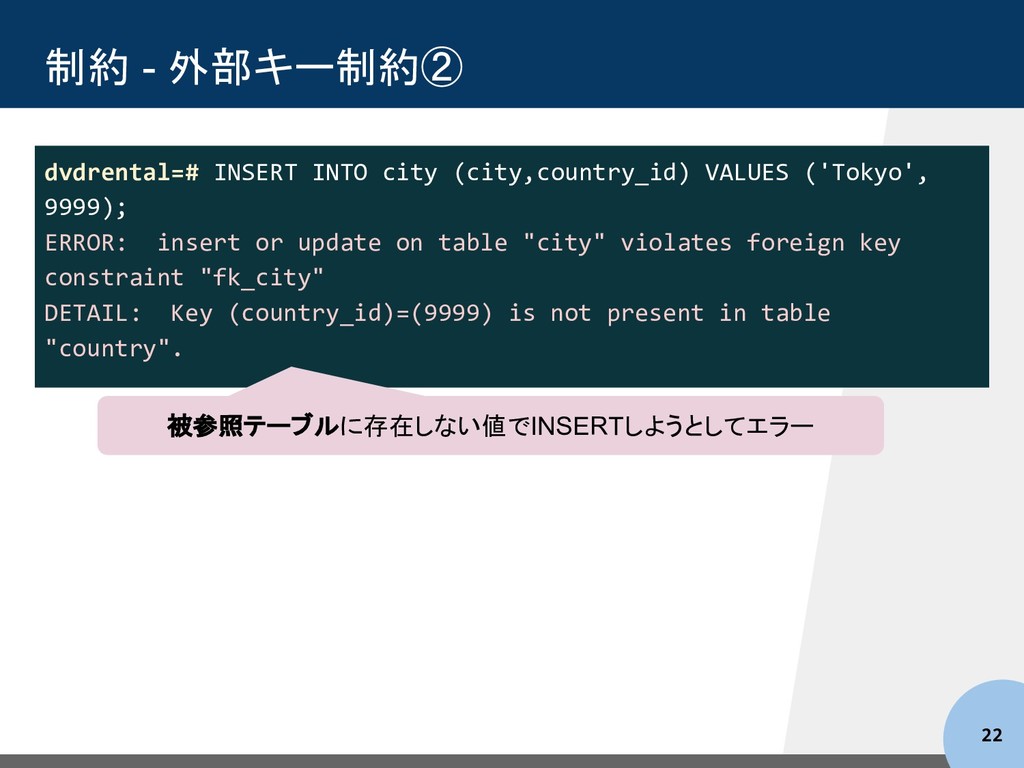
('Tokyo', 9999); ERROR: insert or update on table "city" violates foreign key constraint "fk_city" DETAIL: Key (country_id)=(9999) is not present in table "country". 被参照テーブルに存在しない値でINSERTしようとしてエラー
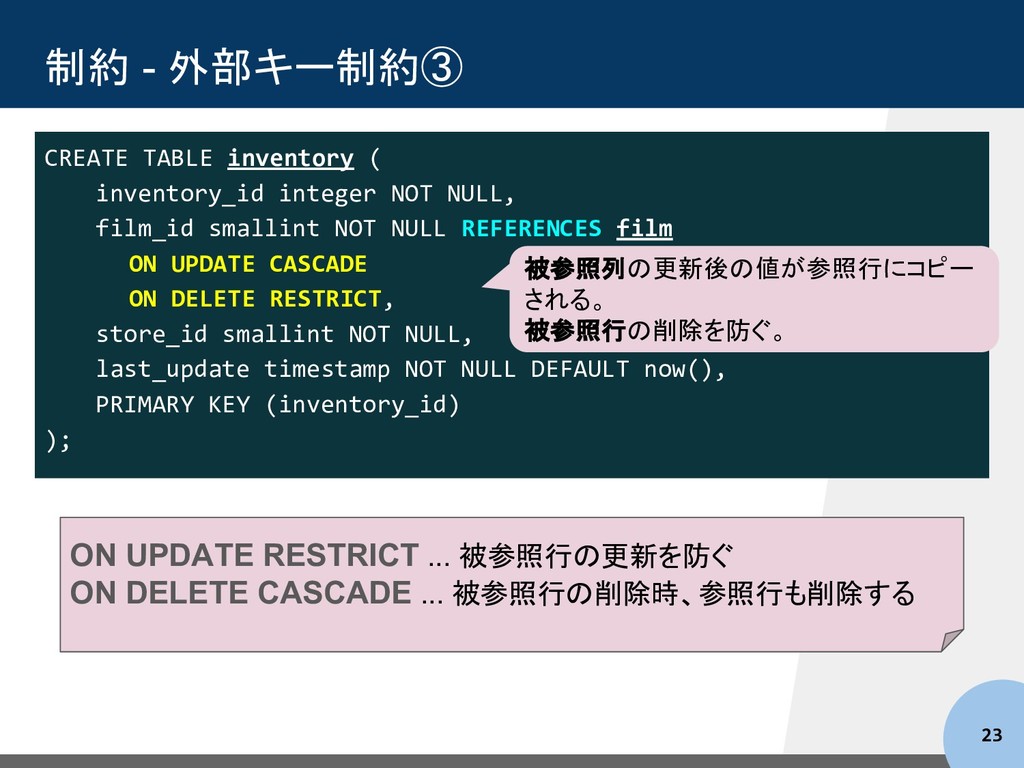
NOT NULL, film_id smallint NOT NULL REFERENCES film ON UPDATE CASCADE ON DELETE RESTRICT, store_id smallint NOT NULL, last_update timestamp NOT NULL DEFAULT now(), PRIMARY KEY (inventory_id) ); 被参照列の更新後の値が参照行にコピー される。 被参照行の削除を防ぐ。 ON UPDATE RESTRICT ... 被参照行の更新を防ぐ ON DELETE CASCADE ... 被参照行の削除時、参照行も削除する
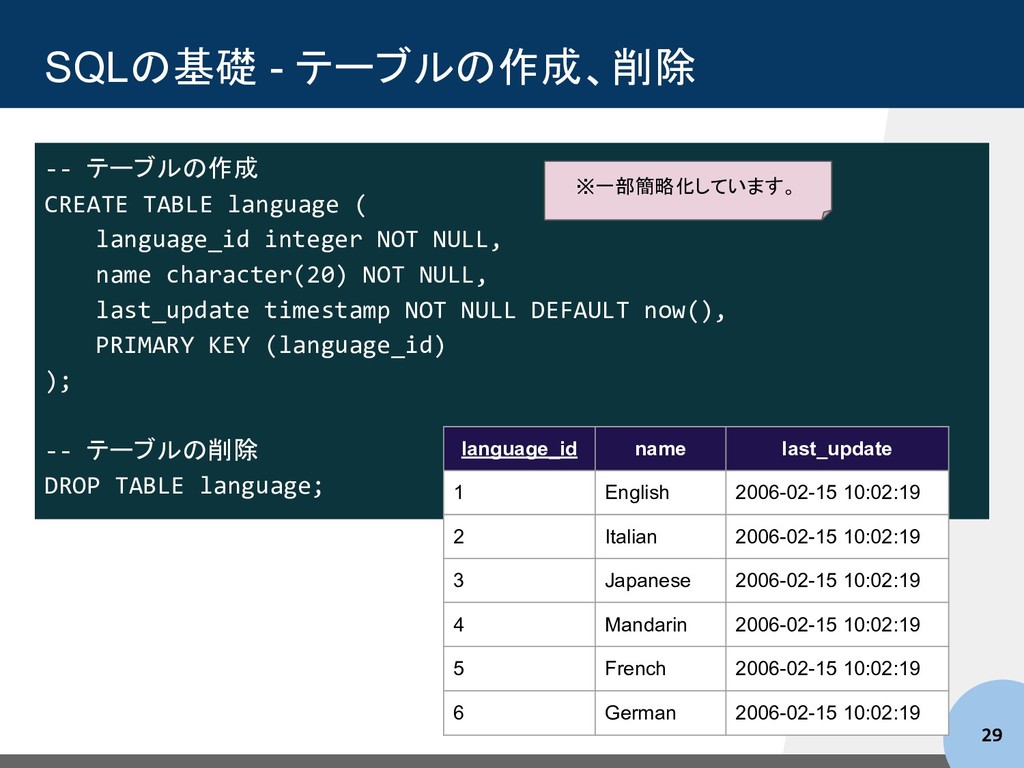
language_id integer NOT NULL, name character(20) NOT NULL, last_update timestamp NOT NULL DEFAULT now(), PRIMARY KEY (language_id) ); -- テーブルの削除 DROP TABLE language; language_id name last_update 1 English 2006-02-15 10:02:19 2 Italian 2006-02-15 10:02:19 3 Japanese 2006-02-15 10:02:19 4 Mandarin 2006-02-15 10:02:19 5 French 2006-02-15 10:02:19 6 German 2006-02-15 10:02:19 ※一部簡略化しています。
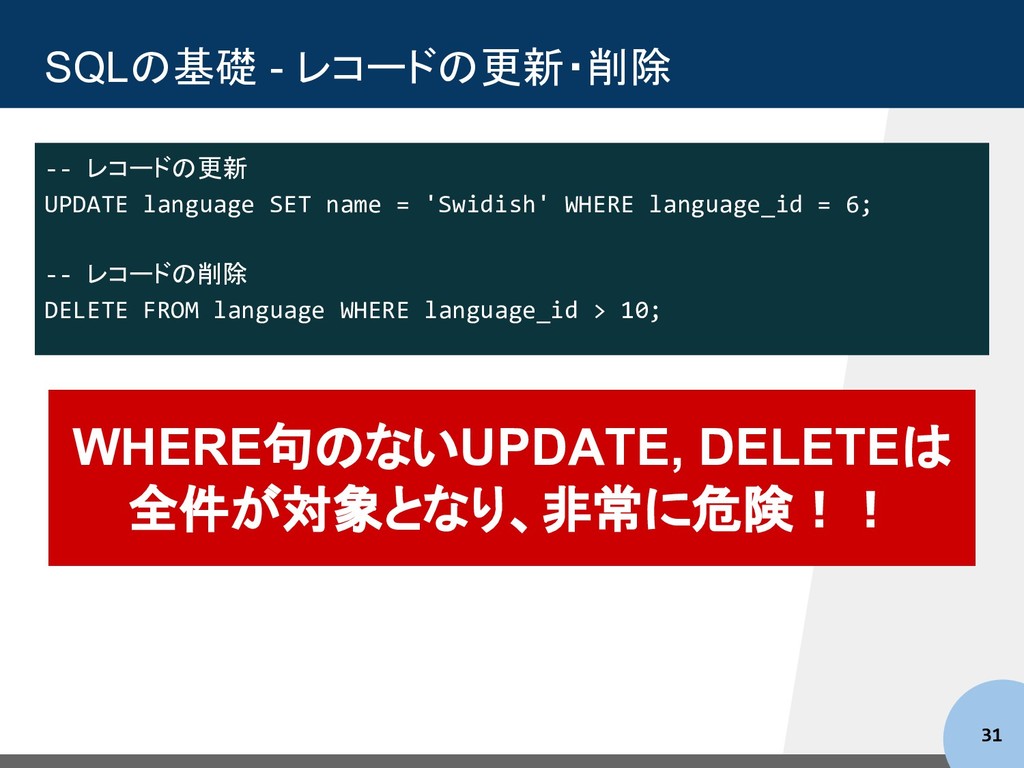
-- 列を指定 SELECT name,last_update FROM language; -- 更に、行の条件を指定 SELECT name,last_update FROM language WHERE language_id IN (1,2); -- ソート SELECT * FROM language ORDER BY last_update DESC; -- ソートして結果の件数を制限 SELECT * FROM language ORDER BY last_update LIMIT 3;
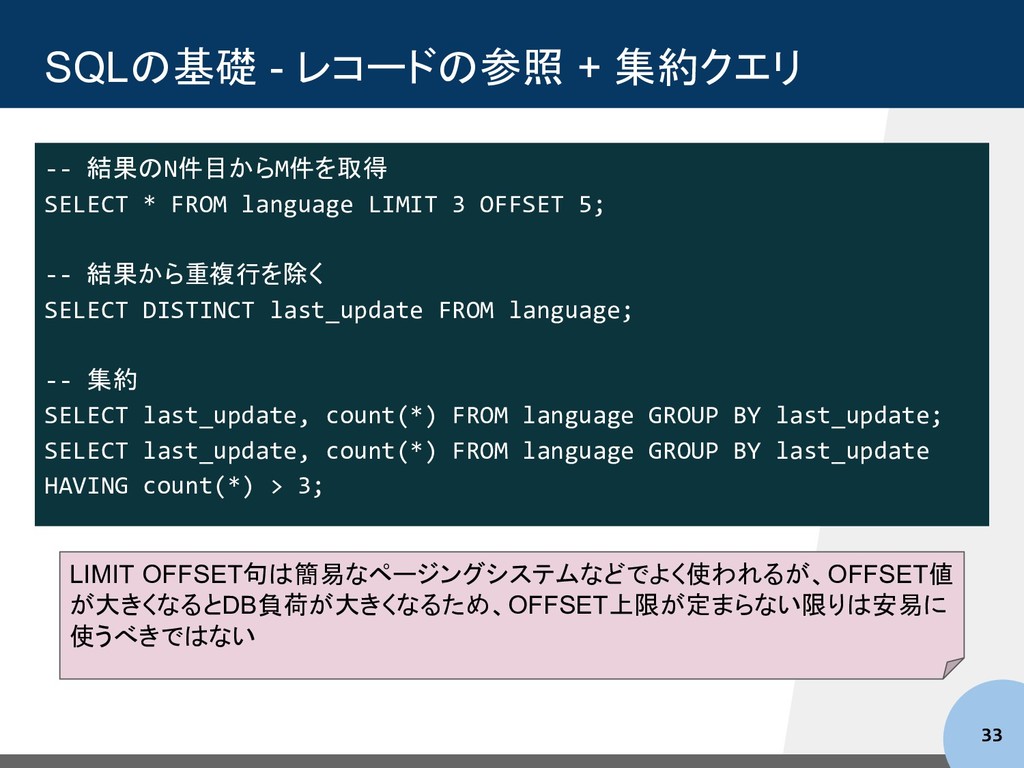
FROM language LIMIT 3 OFFSET 5; -- 結果から重複行を除く SELECT DISTINCT last_update FROM language; -- 集約 SELECT last_update, count(*) FROM language GROUP BY last_update; SELECT last_update, count(*) FROM language GROUP BY last_update HAVING count(*) > 3; LIMIT OFFSET句は簡易なページングシステムなどでよく使われるが、OFFSET値 が大きくなるとDB負荷が大きくなるため、OFFSET上限が定まらない限りは安易に 使うべきではない
結合 ◦ A LEFT OUTER JOIN B ... Aの各行は最低1回は現れ、 Bで値が存在しないものはNULLになる ◦ A RIGHT OUTER JOIN B ... ↑の逆 ◦ A FULL OUTER JOIN B ... A, Bとも最低1回は現れ、他 方に値が存在しないものはNULLになる ➢ クロス結合 ◦ A CROSS JOIN B ... AとBの直積(デカルト積)。すべての 可能な行同士の組み合わせ。結果はn * m行になる。 35
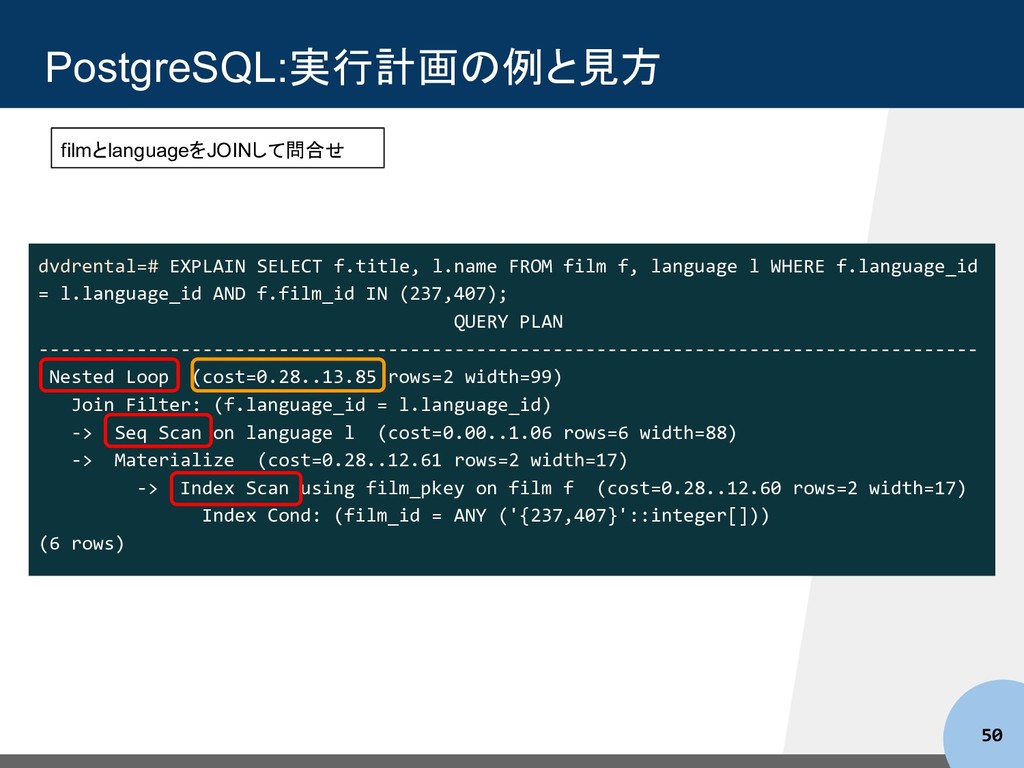
l WHERE f.language_id = l.language_id AND f.film_id IN (237,407); QUERY PLAN -------------------------------------------------------------------------------------- Nested Loop (cost=0.28..13.85 rows=2 width=99) Join Filter: (f.language_id = l.language_id) -> Seq Scan on language l (cost=0.00..1.06 rows=6 width=88) -> Materialize (cost=0.28..12.61 rows=2 width=17) -> Index Scan using film_pkey on film f (cost=0.28..12.60 rows=2 width=17) Index Cond: (film_id = ANY ('{237,407}'::integer[])) (6 rows) 50 filmとlanguageをJOINして問合せ
l WHERE f.language_id = l.language_id AND f.film_id IN (237,407); QUERY PLAN -------------------------------------------------------------------------------------- Nested Loop (cost=0.28..13.85 rows=2 width=99) Join Filter: (f.language_id = l.language_id) -> Seq Scan on language l (cost=0.00..1.06 rows=6 width=88) -> Materialize (cost=0.28..12.61 rows=2 width=17) -> Index Scan using film_pkey on film f (cost=0.28..12.60 rows=2 width=17) Index Cond: (film_id = ANY ('{237,407}'::integer[])) (6 rows) 51 filmとlanguageをJOINして問合せ 入れ子ループ 結合 インデックス が使われる シーケンシャルス キャン。インデック スが使われない 最初の1件を返すまでのコ スト .. 全件を返すまでのコ スト
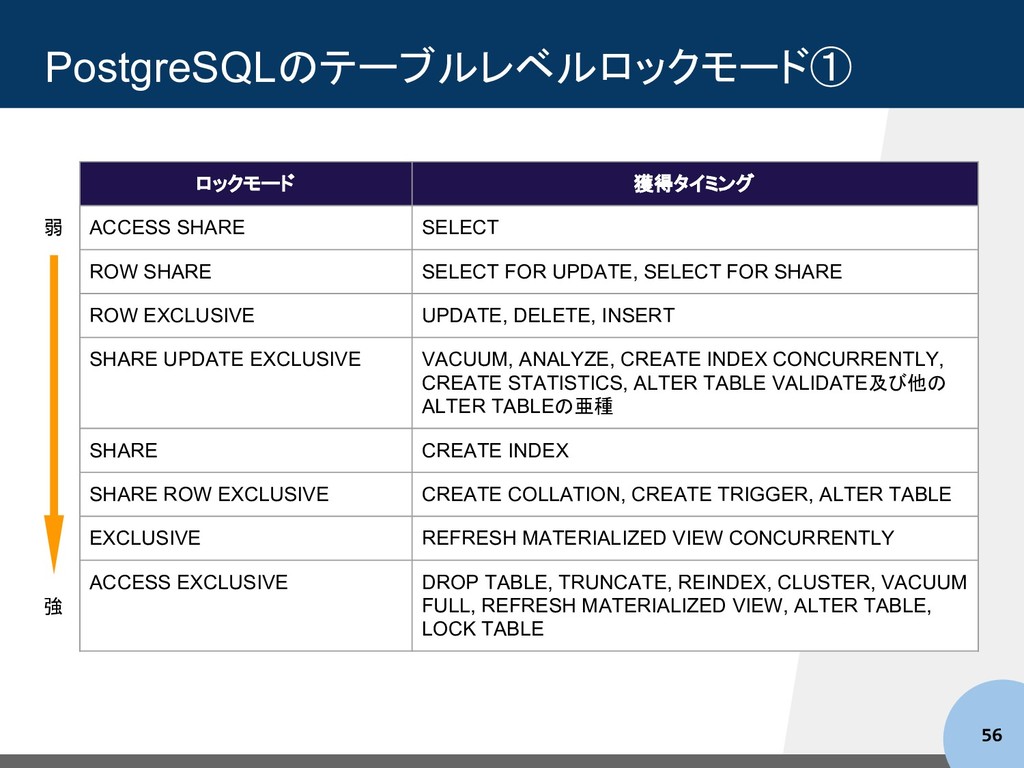
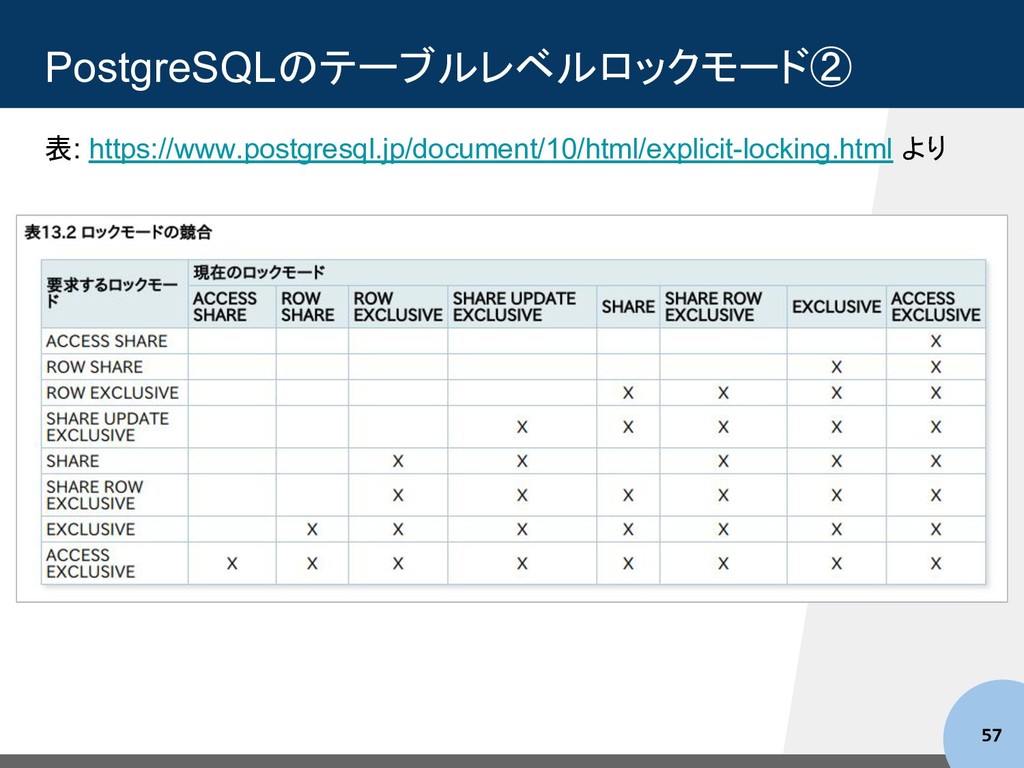
SHARE FOR SHARE SELECT FOR SHARE FOR NO KEY UPDATE ユニークキーを含む列値に対する UPDATE, SELECT FOR NO KEY UPDATE FOR UPDATE UPDATE, DELETE, SELECT FOR UPDATE 弱 強 https://www.postgresql.jp/document/10/html/explicit-locking.html より
OK※ NG NG NG READ COMMITTED OK NG NG NG REPEATABLE READ OK OK OK※ NG SERIALIZABLE OK OK OK OK OK※ ... 標準SQLでは許容されるが、PostgreSQLでは発生しない 表:分離レベルと発生し得る問題 PostgreSQLのデフォルトはREAD COMMITTED. M3でもこれを使って いる。
互いにロック競合するTx処理をしてみよう i. テーブルロック、行ロックそれぞれ試してみる ii. ロック競合しないパターンについても動作確認してみる 3. デッドロックの実験 a. ↑と同じ要領で。 (参考) 複数プロセスが同時に操作しても問題ないことを確認する には、スクリプトを書くなどしてテストする 67
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}