University {gcalikli, ayse.bener}@ryerson.ca An Algorithmic Approach to Missing Data Problem in Modeling Human Aspects in Software Development Gul Calikli and Ayse Bener
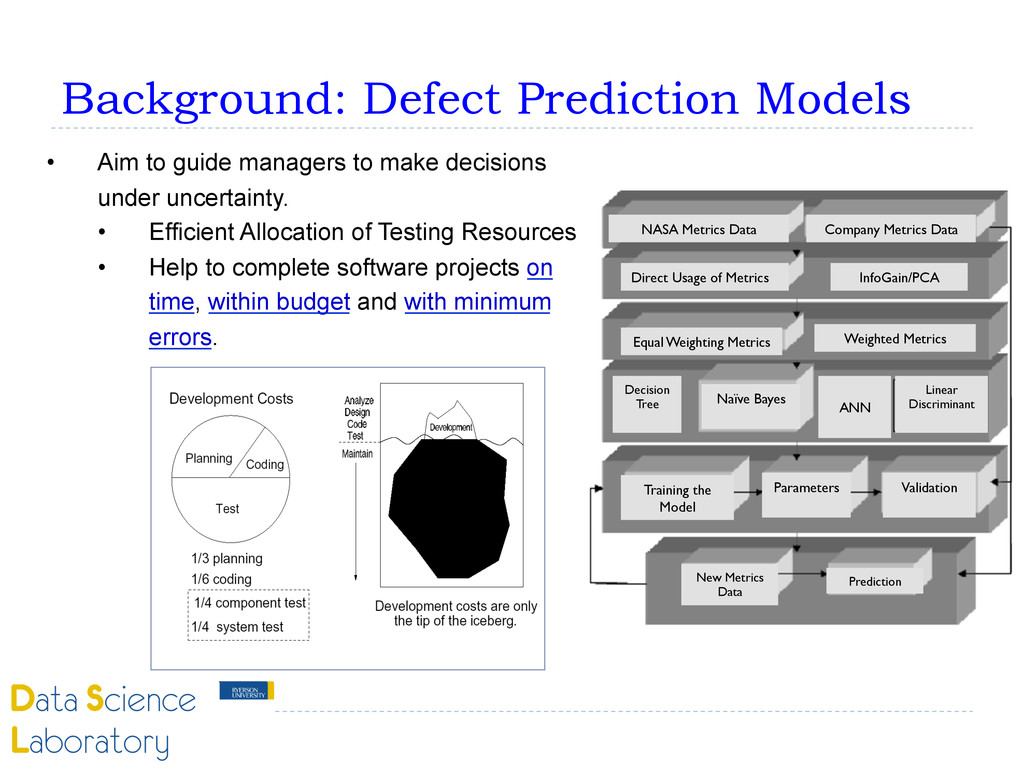
make decisions under uncertainty. • Efficient Allocation of Testing Resources • Help to complete software projects on time, within budget and with minimum errors. NASA Metrics Data Company Metrics Data Direct Usage of Metrics InfoGain/PCA Equal Weighting Metrics Weighted Metrics Decision Tree Naïve Bayes ANN Linear Discriminant Training the Model Parameters Validation New Metrics Data Prediction
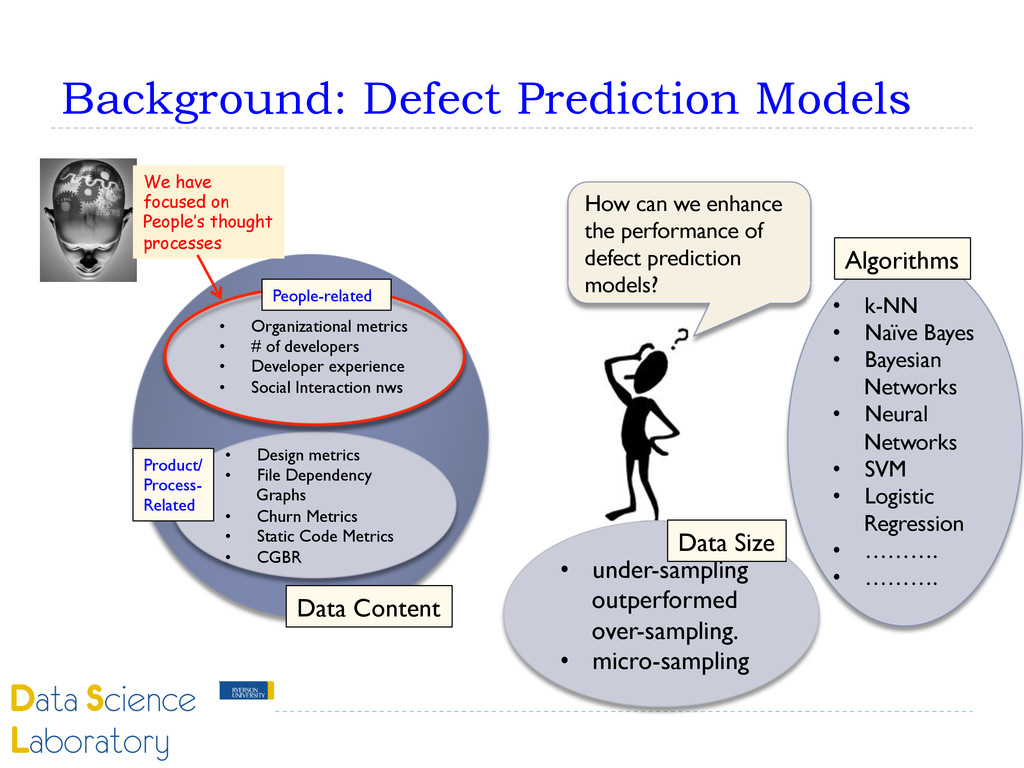
Software Development Quality of the Software Product affect affect } People’s thought processes and cognitive aspects have a significant impact on software quality as software is designed, implemented and tested by people. } In our research, we have focused on a specific human cognitive aspect, namely confirmation bias.
seek evidence to verify a hypothesis rather than seeking evidence to refute that hypothesis. } Due to confirmation bias, developers tend to perform unit tests to make their program work rather than to break their code. } During all levels of software testing, we must employ a testing strategy, which includes adequate attempts to fail the code to reduce software defect density. Background: Confirmation Bias
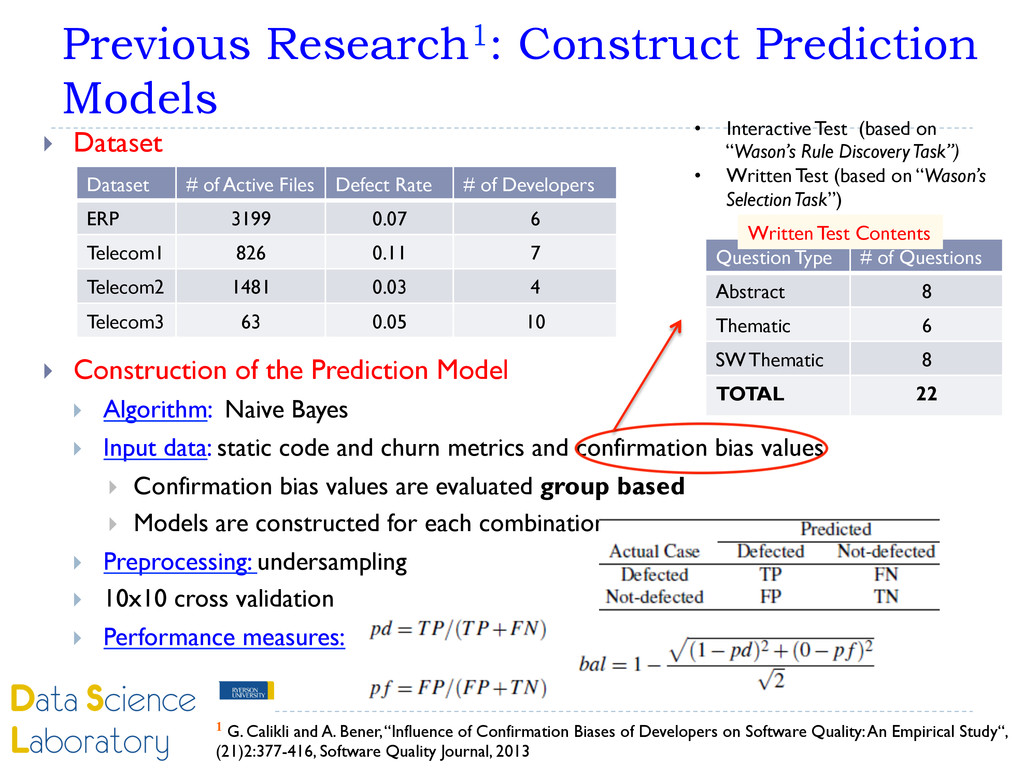
the Prediction Model } Algorithm: Naive Bayes } Input data: static code and churn metrics and confirmation bias values } Confirmation bias values are evaluated group based } Models are constructed for each combination of these metrics } Preprocessing: undersampling } 10x10 cross validation } Performance measures: Dataset # of Active Files Defect Rate # of Developers ERP 3199 0.07 6 Telecom1 826 0.11 7 Telecom2 1481 0.03 4 Telecom3 63 0.05 10 1 G. Calikli and A. Bener, “Influence of Confirmation Biases of Developers on Software Quality: An Empirical Study“, (21)2:377-416, Software Quality Journal, 2013 Question Type # of Questions Abstract 8 Thematic 6 SW Thematic 8 TOTAL 22 • Interactive Test (based on “Wason’s Rule Discovery Task”) • Written Test (based on “Wason’s Selection Task”) Written Test Contents
through interviews/tests might be challenging: } Tight Schedules: In many cases developers have tight schedules to rush the code for the next release. Hence they may see data collection process a waste of time. } Evaluation Apprehension: Many people are anxious about being evaluated (threat to construct validity) } Staff Turn-over: Some of the reused code may have en developed by developers who already left the company. } Lack of Motivation: Developers may see the direct benefit of data collection process. All these result in “missing data problem”
Weighting procedures (used in the case of non-response data) } Imputation based procedures (e.g. hot-deck imputation, mean imputation, regression imputation) } Model-based Procedures (e.g. Expectation-Maximization algorithms) • Suitable for small amount of missing data • Bias is introduced in the imputed data
missing data. } Why EM Algorithm? } Proved to be very powerful leading to high accuracy results. } Conceptually and computationally simple } EM Algorithm in general handles the missing data problem as follows: } (1) Replace missing values by estimated values } (2) Estimate parameters } (3) Estimate missing values assuming that new parameter estimates are correct } (4) Re-estimate parameters and so forth, iterating until it converges.
Step (E-Step): Maximization Step (M-Step): X = wTY Y = CX C = (wT)-1 X = C-1Y =C-1IY = C-1(CT)-1CTY = (CTC)-1CTY X = (CTC)-1CTY C = YXT(X XT)-1 2 Roweis S., “EM Algorithms for PCA and SPCA”, in Advances for Neural Information Processing Systems, pp. 626-632, MIT Press, 1998
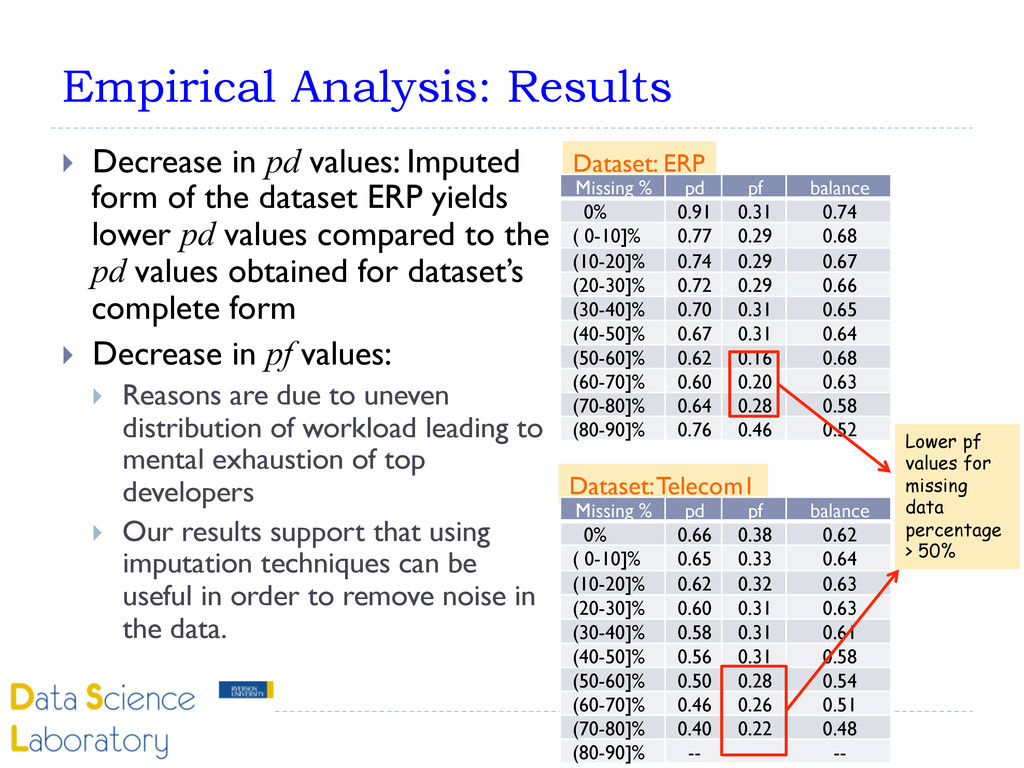
} (N: Total number of developers) } Use EM to handle missing data } Build defect prediction models using imputed data } Compare obtained performance results with the performance of prediction models built using complete data. Missing data percentage Total number of entries with missing confirmation bias metric values Total number of complete entries
construct validity, we used three popular performance measures in software defect prediction research: pd, pf and balance. } Internal Validity: To avoid threats to internal validity10 X 10 cross validation was performed. } External Validity: To avoid external threats to validity } We used 4 datasets from 2 different software companies (1 form an ISV specialized in ERP and 3 from a GSM operator/ telecommunication company) } Our datasets cover two different software development domains (ERP domain and telecommunication domain) } 3 datasets from the GSM operator were collected from 2 different project groups (Dataset Telecom1 come from the project group that developed software for launching GSM tariffs, Telecom2 and Telecom3 come from the billing and charging system.)
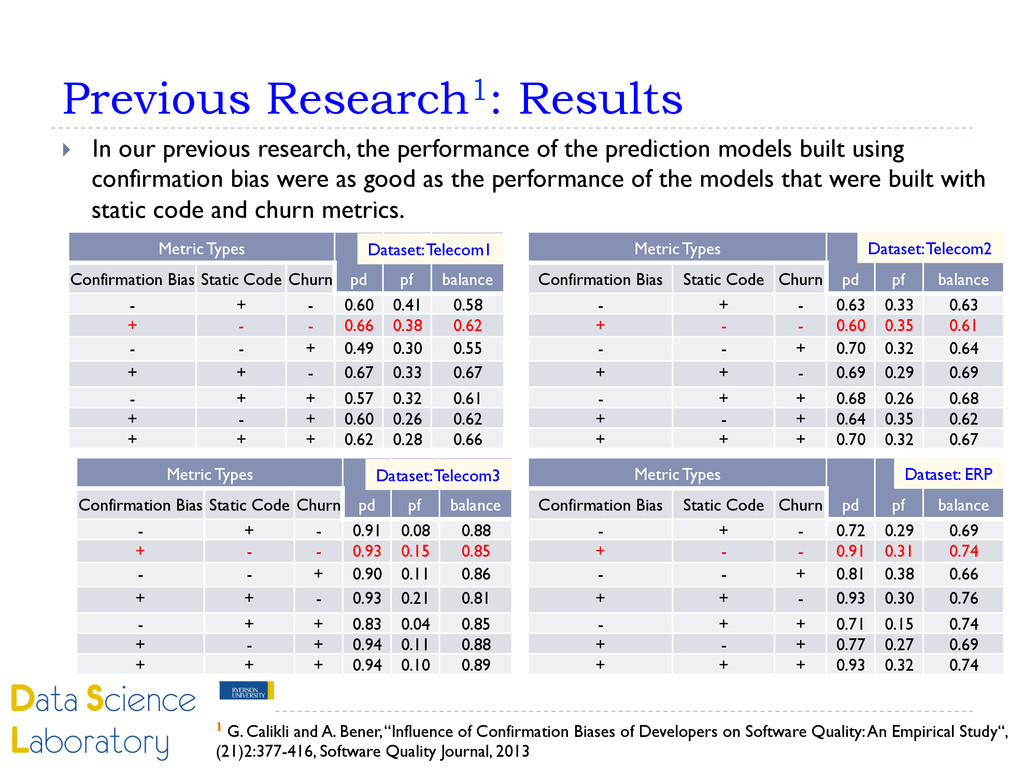
to fill missing confirmation bias metrics values. } Our empirical results showed that by using the imputation algorithm with only confirmation bias metrics we can achieve as good prediction results as the other metrics sets (static code attributes, churn and history metrics). } Our future direction will be to include: } other cognitive bias types, and } to improve the proposed different imputation techniques.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![THANK YOU ANY QUESTIONS? Gül Çalıklı: [email protected] and Ayşe Bener:](https://files.speakerdeck.com/presentations/6b44eab01fa101312c670a36078c81b4/slide_18.jpg){kind=link}