Learning Machines Liyan Song Leandro Minku Xin Yao Department of Computer Science University of Birmingham lxs189 & L.L.Minku & [email protected] PROMISE, 2013 Liyan Song, Leandro Minku, Xin Yao (UoB) Impact of Parameter Tuning in SEE PROMISE, 2013 1 / 37
develop a software system. Early stage of software developing as decision tools in bidding. Over/Under-estimations can be problematic. SEE from Machine Learning Viewpoint Regression Problem Use the completed projects to predict the unknown ones Employing ML approaches, such as k-NN, MLPs, RTs, SVR Liyan Song, Leandro Minku, Xin Yao (UoB) Impact of Parameter Tuning in SEE PROMISE, 2013 4 / 37
can be used; Environment may change. How it works in SEE? At each time step: all completed projects → predicting the next ten. Performance Time step: MAE Overall: average MAE across all time steps. Liyan Song, Leandro Minku, Xin Yao (UoB) Impact of Parameter Tuning in SEE PROMISE, 2013 5 / 37
in SEE. Parameter setting is very important in general ML. In SEE, many studies implicitly assume that PS isn’t going to affect much of the result. 2 Bagging (ensemble) has been shown to improve the performance, will the goodness continue to the sensitivity to PS? [1] L. Minku, and X. Yao. Ensemble and Locality: Insight on Improving Software Effort Estimation. 2013’IST [2] L. Minku, and X. Yao. Can Cross-company Data Improve Performance in Software Effort Estimation? 2012’PROMISE [3] A. Corazza, S. Martino, F. Ferrucci, C. Gravino, F. Sarro, and E. Mendes. How Effective is Tatu Search to Configure Support Vector Regression for Effort Estimation? 2010’PROMISE Liyan Song, Leandro Minku, Xin Yao (UoB) Impact of Parameter Tuning in SEE PROMISE, 2013 7 / 37
set, how sensitive is this approach to different parameter settings in terms of its average performance across time steps? 2 Given an approach and a data set, does the best parameter setting in terms of average performance across time steps perform consistently well at each time step compared with other parameter settings? 3 Could Bagging also help to lessen the base learners’ sensitivity to parameter settings? Liyan Song, Leandro Minku, Xin Yao (UoB) Impact of Parameter Tuning in SEE PROMISE, 2013 9 / 37
parameter values as follows. Among them, the best&worst&default PSs in terms of the average performances across time steps are determined. Liyan Song, Leandro Minku, Xin Yao (UoB) Impact of Parameter Tuning in SEE PROMISE, 2013 13 / 37
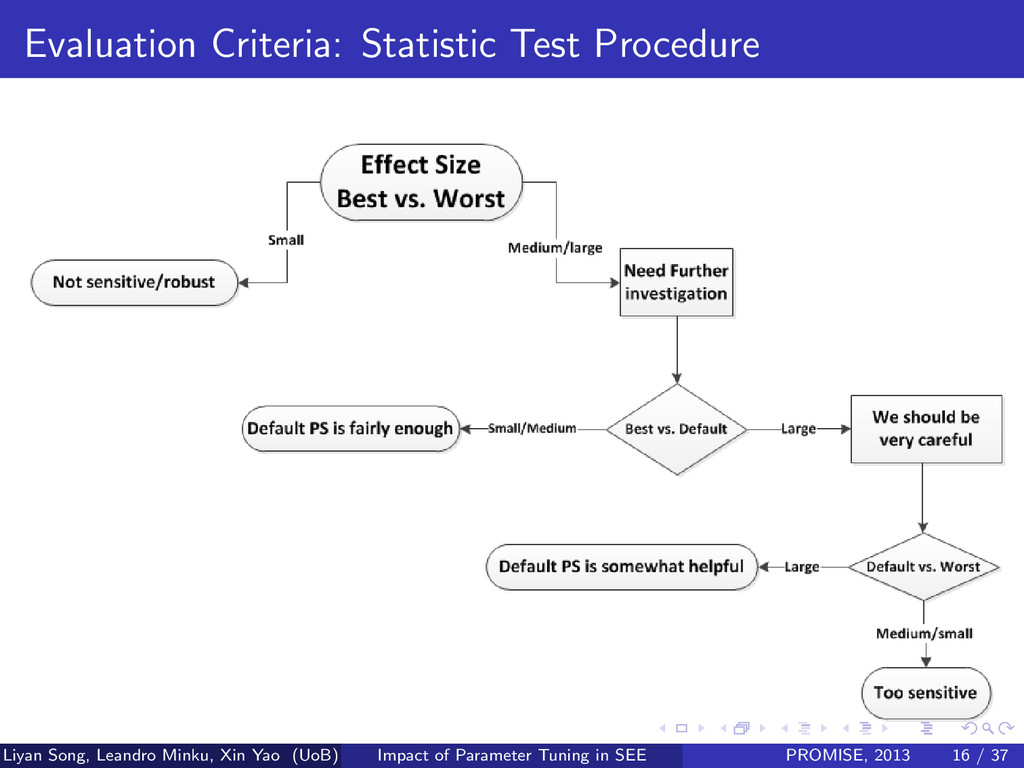
−yi | n ) Symmetric & unbiased Smaller MAE → better performance Statistical Test Wilcoxon sign-rank test with Holm-Bonferroni Correction (0.05) Effect Size → quantify the size of the difference. Liyan Song, Leandro Minku, Xin Yao (UoB) Impact of Parameter Tuning in SEE PROMISE, 2013 15 / 37
and a data set, how sensitive is this approach to different parameter settings in terms of its average performance across time steps? Liyan Song, Leandro Minku, Xin Yao (UoB) Impact of Parameter Tuning in SEE PROMISE, 2013 18 / 37
Usually not sensitive to PS → Blind tuning is allowed Suggestion: If time is not allowed → using default PS Liyan Song, Leandro Minku, Xin Yao (UoB) Impact of Parameter Tuning in SEE PROMISE, 2013 21 / 37
behaves the worst. [¯ 1] k = 3 or 5 always perform the best (see Fig.1∼3 in paper). [2] k-NN is not sensitive to parameter choices in SEE. Liyan Song, Leandro Minku, Xin Yao (UoB) Impact of Parameter Tuning in SEE PROMISE, 2013 22 / 37
and a data set, how sensitive is this approach to different parameter settings in terms of its average performance across time steps? Our Response 1 Different learning machines have different sensitivity to their PSs. MLP & Bagging+MLPs: extremely sensitive RTs & Bagging+RTs: usually not sensitive k-NN: not sensitive Liyan Song, Leandro Minku, Xin Yao (UoB) Impact of Parameter Tuning in SEE PROMISE, 2013 23 / 37
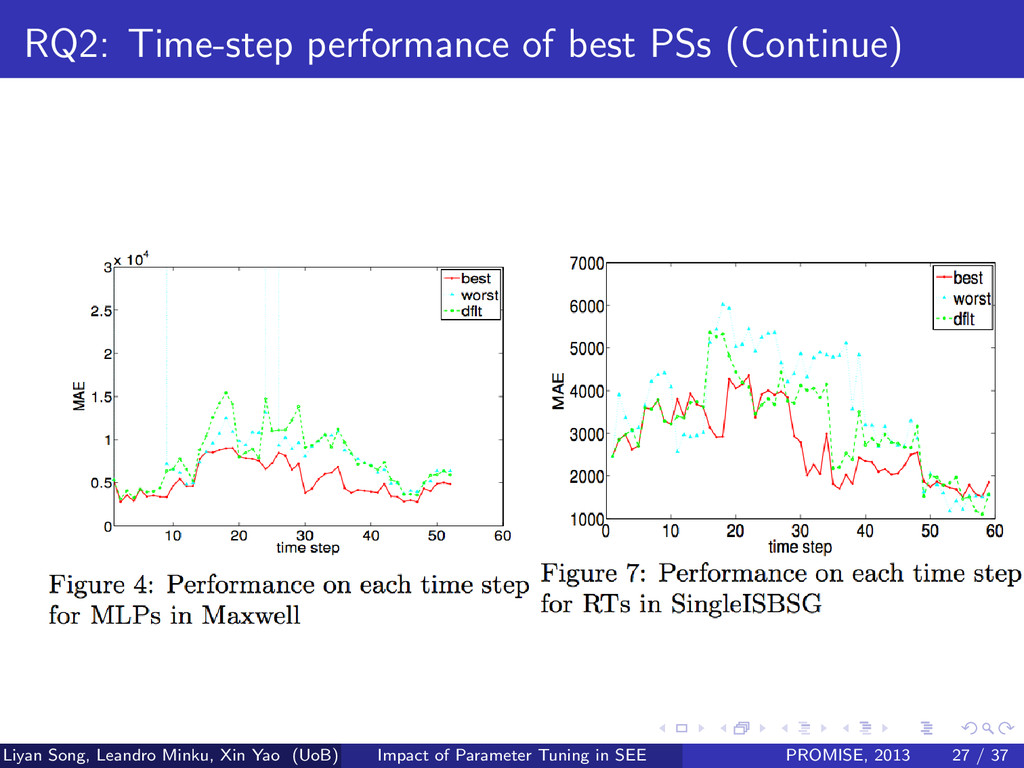
Given an approach and a data set, does the best parameter setting in terms of average performance across time steps perform consistently well at each time step compared with other parameter settings? We only show results in: 1 MLPs + Maxwell 2 RTS + SingleISBSG 3 k-NN + Kitchenham Refer Fig.4 ∼ 10 in our paper. Liyan Song, Leandro Minku, Xin Yao (UoB) Impact of Parameter Tuning in SEE PROMISE, 2013 25 / 37
across most time steps Though a few time steps default/worst outperforms. Liyan Song, Leandro Minku, Xin Yao (UoB) Impact of Parameter Tuning in SEE PROMISE, 2013 26 / 37
Given an approach and a data set, does the best parameter setting in terms of average performance across time steps perform consistently well at each time step compared with other parameter settings? Our Response 2 Best PSs achieve better performance at most time steps. Liyan Song, Leandro Minku, Xin Yao (UoB) Impact of Parameter Tuning in SEE PROMISE, 2013 28 / 37
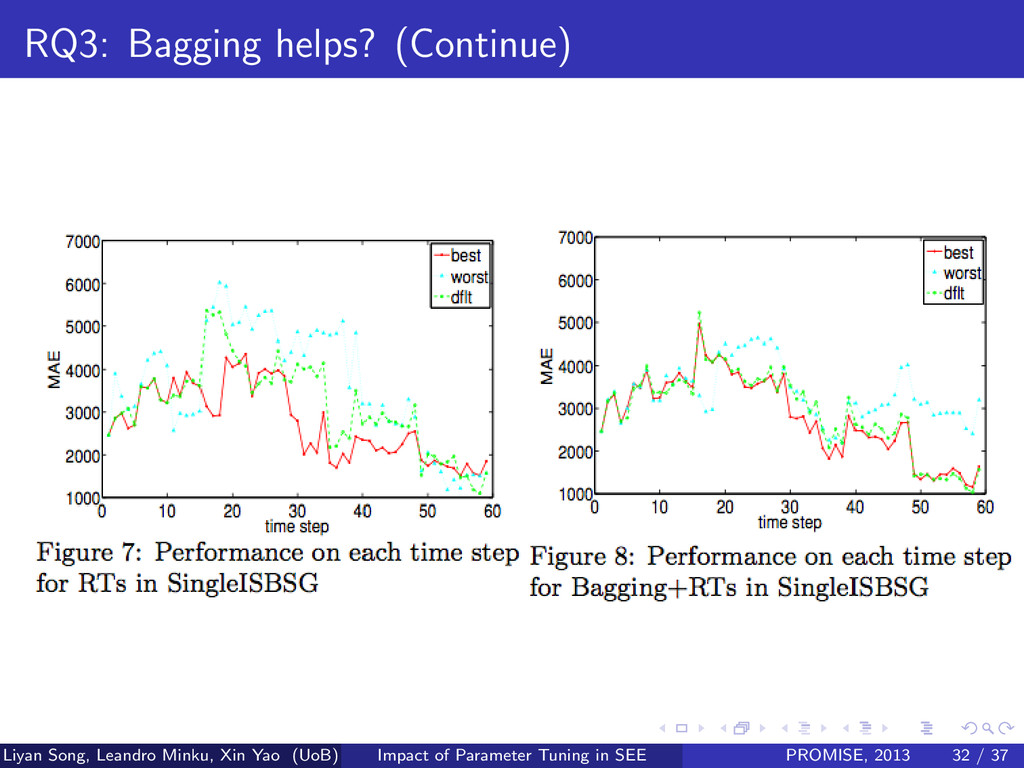
help to lessen the base learners’ sensitivity to parameter settings? Liyan Song, Leandro Minku, Xin Yao (UoB) Impact of Parameter Tuning in SEE PROMISE, 2013 30 / 37
closer to the best ones. [2] In most cases, Bagging helps to improve the overall performance. Liyan Song, Leandro Minku, Xin Yao (UoB) Impact of Parameter Tuning in SEE PROMISE, 2013 31 / 37
help to lessen the base learners’ sensitivity to parameter settings? Our Response 3 Bagging can help the default PSs closer to the best ones. Liyan Song, Leandro Minku, Xin Yao (UoB) Impact of Parameter Tuning in SEE PROMISE, 2013 33 / 37
sets should be investigated. We perform on 5 representative approaches on 3 standard data sets. 2 Unable to exhaust all possible parameter values. Impossible A good range in Table 2. Additional values can be tested in the future. Liyan Song, Leandro Minku, Xin Yao (UoB) Impact of Parameter Tuning in SEE PROMISE, 2013 34 / 37
how sensitive is this approach to different parameter settings in terms of its average performance across time steps? * Different learning machines have different sensitivity to their PSs. 2. Given an approach and a data set, does the best parameter setting in terms of average performance across time steps perform consistently well at each time step compared with other parameter settings? * Best PSs achieve better performance at most time steps. 3. Could Bagging also help to lessen the base learners’ sensitivity to parameter settings? * Bagging can help the default PSs closer to the best ones. Liyan Song, Leandro Minku, Xin Yao (UoB) Impact of Parameter Tuning in SEE PROMISE, 2013 35 / 37
two groups. Formula: d1 = ˆ MAE1− ˆ MAE2 std2 1 +std2 2 2 Pooled Standard Deviation stdpooled = std2 1 +std2 2 +...+std2 n n Liyan Song, Leandro Minku, Xin Yao (UoB) Impact of Parameter Tuning in SEE PROMISE, 2013 37 / 37
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![RQ1 – MLPs & Bagging+MLPs (Table 3 in Paper) [1]](https://files.speakerdeck.com/presentations/589692201f9f013114a40a360350e1fc/slide_18.jpg){kind=link}
![RQ1 – MLPs & Bagging+MLPs (Continue) [2] Default PSs are](https://files.speakerdeck.com/presentations/589692201f9f013114a40a360350e1fc/slide_19.jpg){kind=link}
![RQ1 – RTs & Bagging+RTs (Table 4 in Paper) [1]](https://files.speakerdeck.com/presentations/589692201f9f013114a40a360350e1fc/slide_20.jpg){kind=link}
![RQ1 – k-NN (Table 5 in Paper) [1] 1-NN always](https://files.speakerdeck.com/presentations/589692201f9f013114a40a360350e1fc/slide_21.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![RQ2: Time-step performance of best PSs [1] Best PSs outperform](https://files.speakerdeck.com/presentations/589692201f9f013114a40a360350e1fc/slide_25.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![RQ3: Bagging helps? [1] Bagging helps the default PSs get](https://files.speakerdeck.com/presentations/589692201f9f013114a40a360350e1fc/slide_30.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}