on which files will have bugs discovered a?er release • Few short-‐term ones: – Predic7ons at the change level [Kim/Whitehead/ Zhang] – Maintaining top 10% list of most likely error-‐prone files (most recently created/changed/fixed) [Kim/ Zimmermann/Whitehead/Zeller] PROMISE'13 -‐-‐ Josée Tassé
burst of modifica7ons in one file increases the chances of this file being buggy Short-‐term predic3on • Advantage: can take immediate ac7on instead of wai7ng un7l final tes7ng stages PROMISE'13 -‐-‐ Josée Tassé
[Hassan]: – Increase complexity of project – More difficult to keep track of progress – Reduces understanding of the code Increased chance of bugginess • Our assump7on: changes sca[ered inside single file will have similar effect PROMISE'13 -‐-‐ Josée Tassé
Type of changes made (localized or sca[ered, minor or massive) – Number of changes within a short period of 7me – File size • Idea: Tag a file as error-‐prone if it went through similar changes as another file in the past, which did end up being buggy a?er the changes PROMISE'13 -‐-‐ Josée Tassé
nbBlocks, avgModifs, avgDist (standardized on [0,1] scale) • Use clustering to find types of changes à JEdit: – Type A: small modifica7ons in single block (0.00, 0.17, 0.00) – Type B: average-‐size modifica7ons in few dispersed blocks (0.29, 0.24, 0.47) – Type C: average-‐size modif. in many dispersed blocks (0.61, 0.24, 0.46) – Type D: massive modifica7ons in single block (0.00, 0.72, 0.00) PROMISE'13 -‐-‐ Josée Tassé
file into 7me intervals of consecu7ve changes: changes occurring in consecu7ve weeks, with no more than one week with no changes in between • Metrics for each 7me interval (or “case”): – File size in LOC – Number of changes in the 7me interval – Propor7on of each type of change (Type A to D) during the interval (e.g., [50%, 25%, 0%, 25%] ) PROMISE'13 -‐-‐ Josée Tassé
past cases (all 7me intervals for all files), for which enough 7me has past to tag it “buggy” or “bug-‐free” • When new change burst comes up, measure it and compare it with previous cases • If new case is more like past buggy cases, tag it as “buggy”, otherwise as “bug-‐free” PROMISE'13 -‐-‐ Josée Tassé
nearest cases from the pool (the ones within 0.1 of the minimum distance found) • Calculate the percentage of buggy cases in the subset • Tag new case as buggy if the percentage is significantly higher (e.g. 50% higher) than such percentage on the en7re pool PROMISE'13 -‐-‐ Josée Tassé
and bug-‐free cases from the pool • When a new case comes up, calculate its distance to each cluster (using same distance formula) • Use the tag of the closest cluster as the tag of the new case PROMISE'13 -‐-‐ Josée Tassé
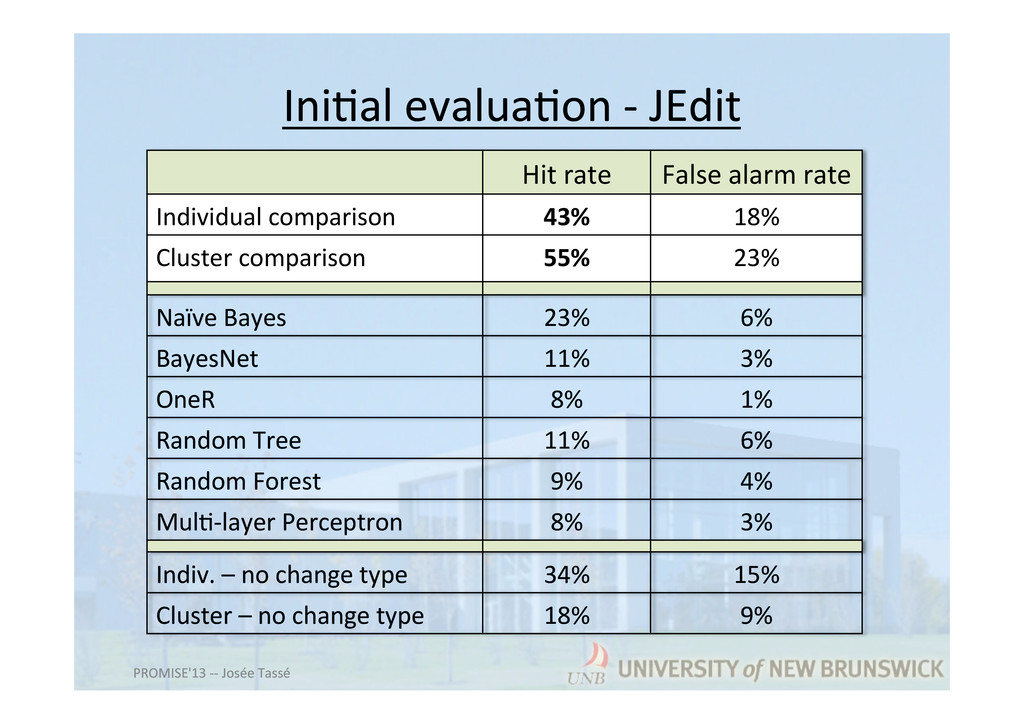
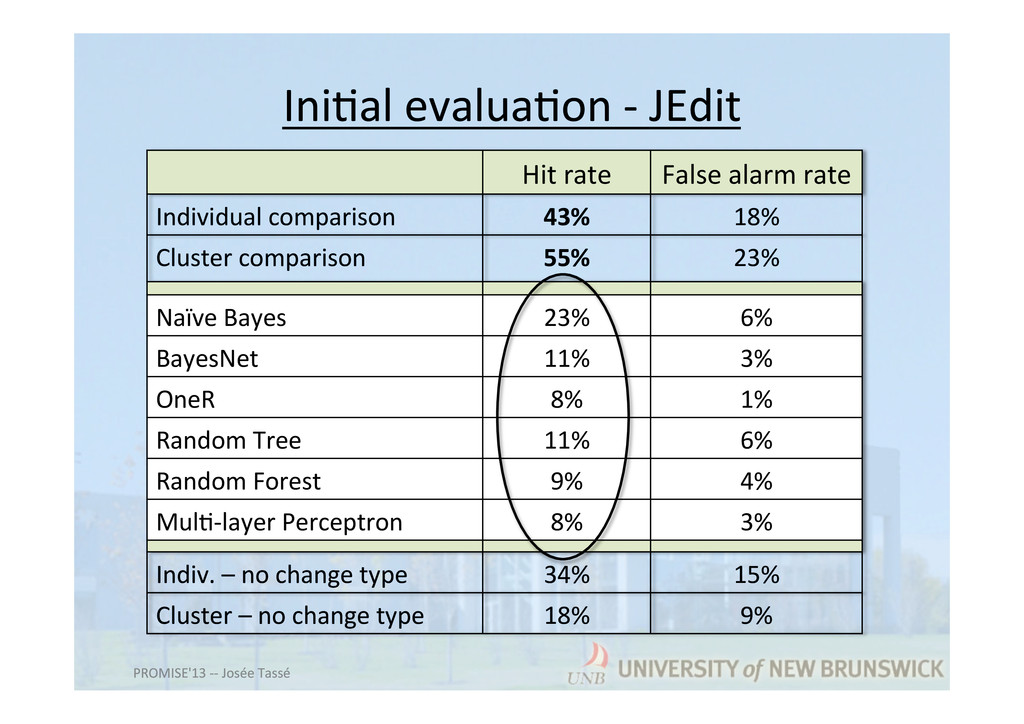
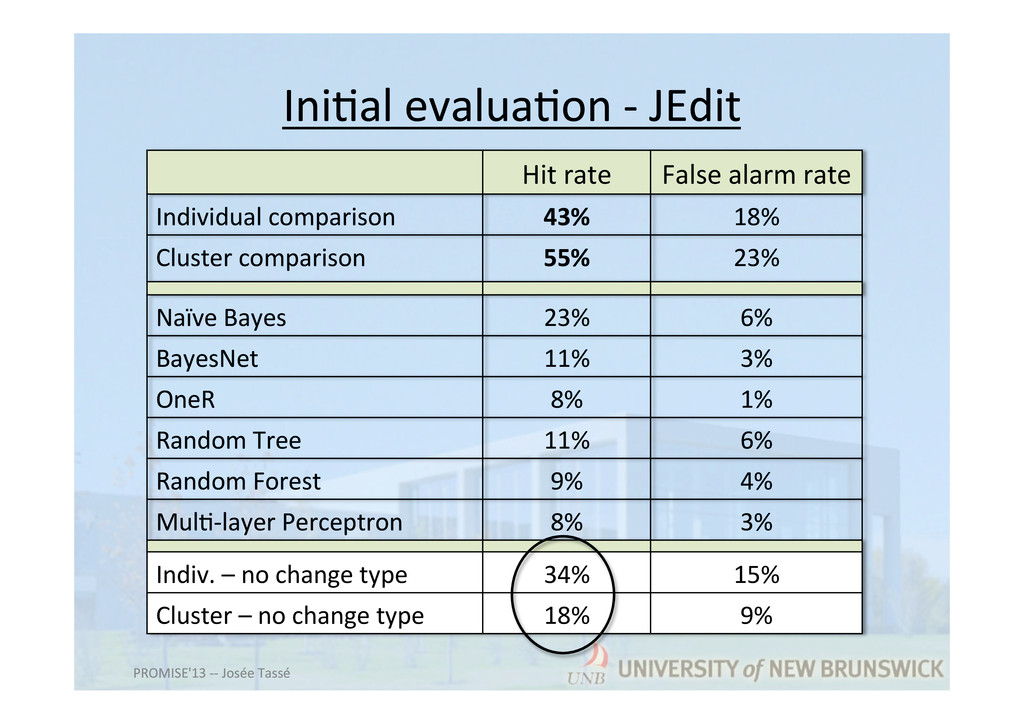
types of changes and past experience • Ini7al evalua7on shows: – Analogy-‐based model beAer than other data mining ones for such case – Change type does help in building a be[er predictor PROMISE'13 -‐-‐ Josée Tassé
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}