main approaches for deploying ProxySQL are either: - Deploy ProxySQL on your application servers - Deploy ProxySQL in a separate layer / standalone server Each approach has its own advantages and disadvantages
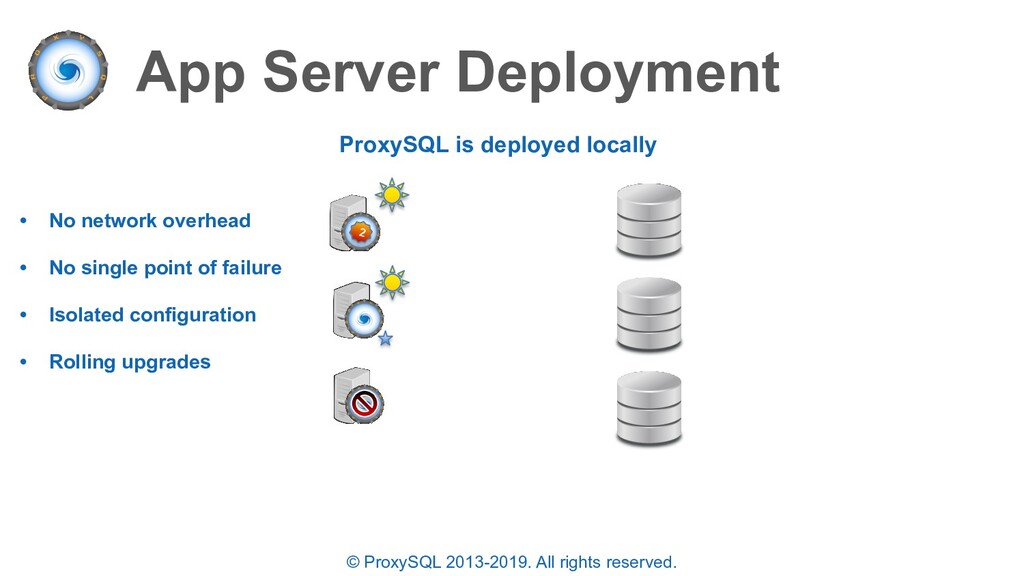
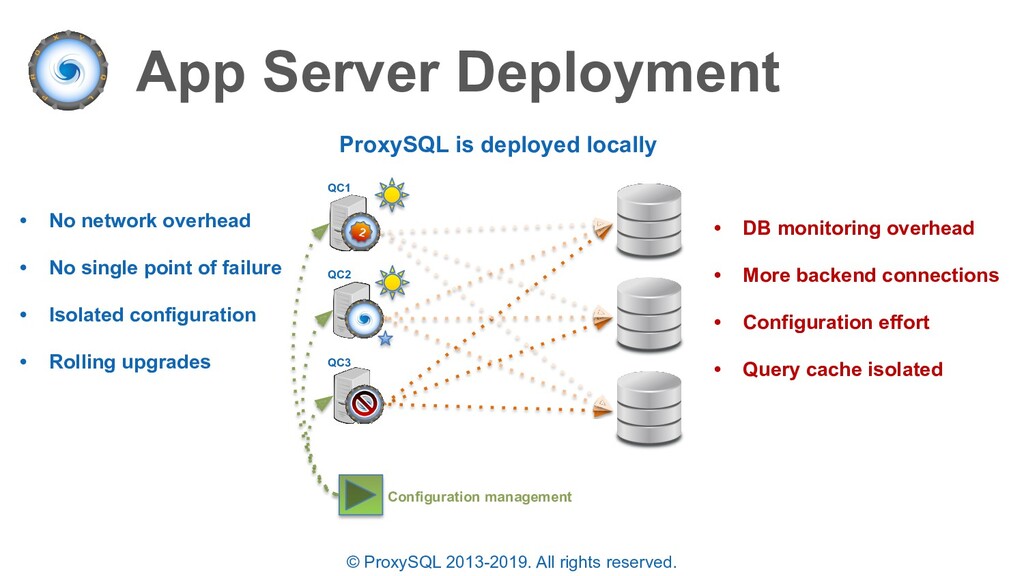
is deployed locally • No network overhead • No single point of failure • Isolated configuration • Rolling upgrades 2 • DB monitoring overhead • More backend connections • Configuration effort • Query cache isolated Configuration management QC1 QC2 QC3
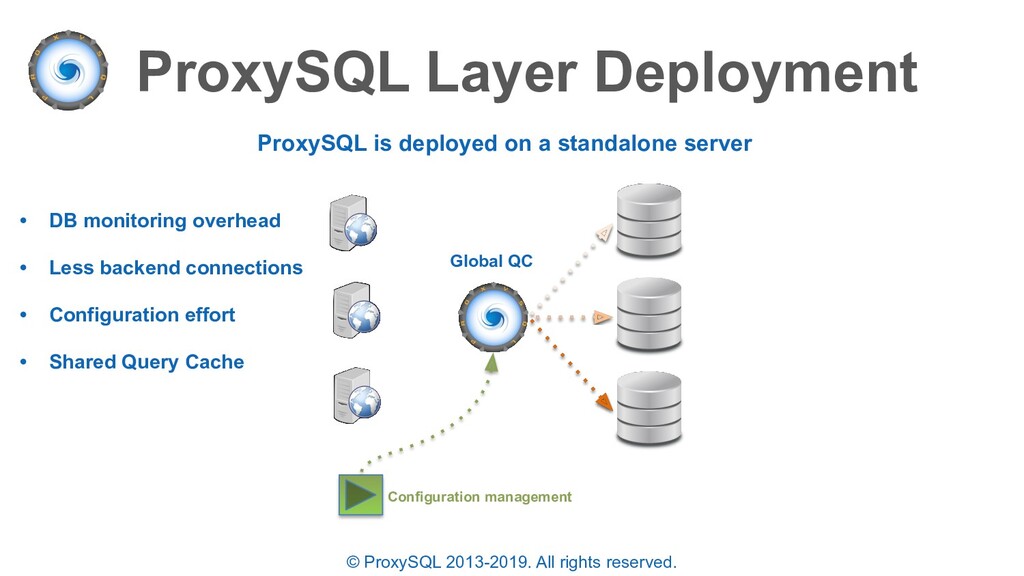
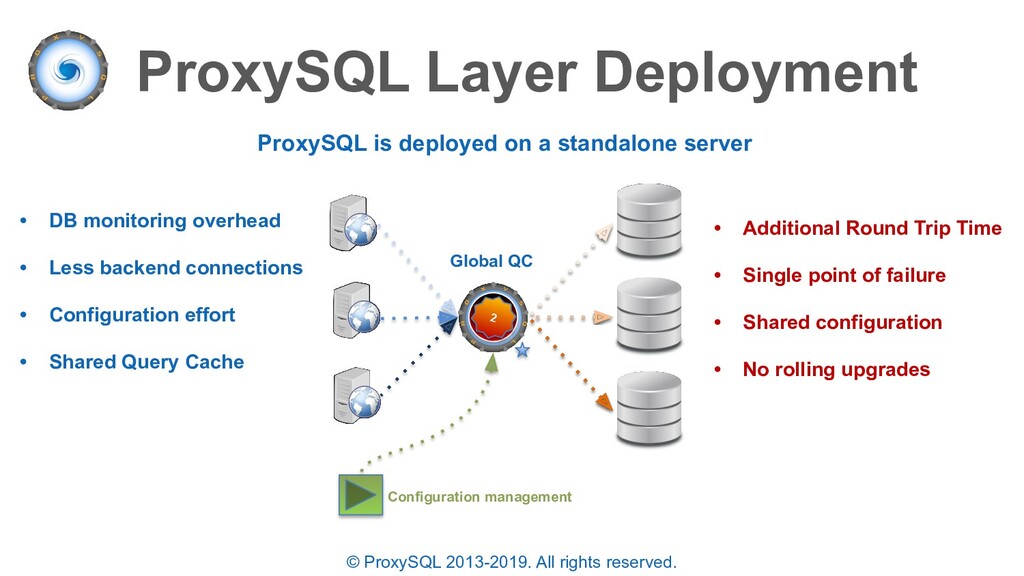
is deployed on a standalone server • DB monitoring overhead • Less backend connections • Configuration effort • Shared Query Cache Configuration management Global QC
is deployed on a standalone server • DB monitoring overhead • Less backend connections • Configuration effort • Shared Query Cache Configuration management Global QC • Additional Round Trip Time • Single point of failure • Shared configuration • No rolling upgrades 2
is the ”first contact” for applications connecting to a database services. • ProxySQL Service is CRITICAL – Deployment decisions affect uptime – Architectural considerations affect scalability – Additional layers introduce possible points of failure
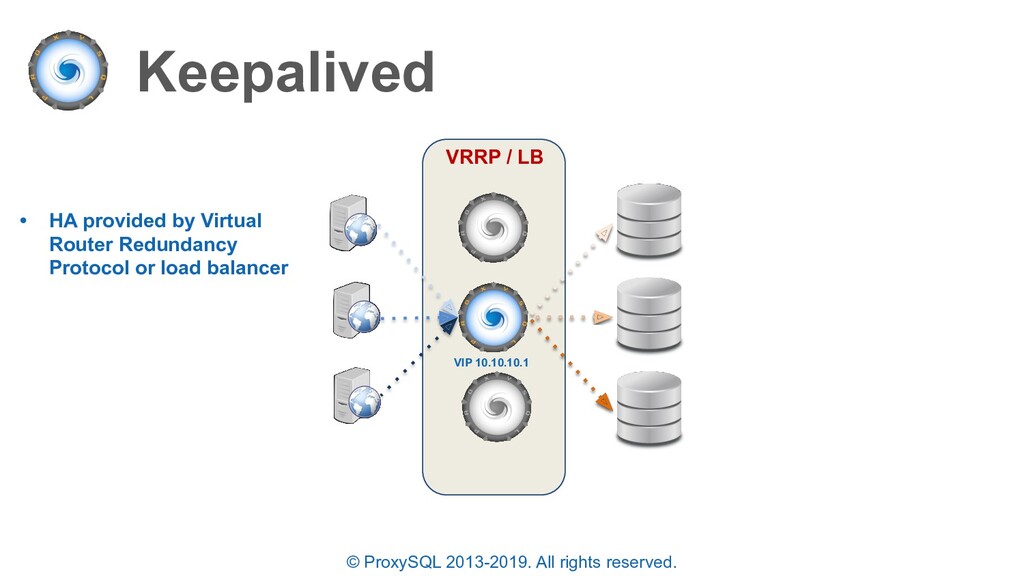
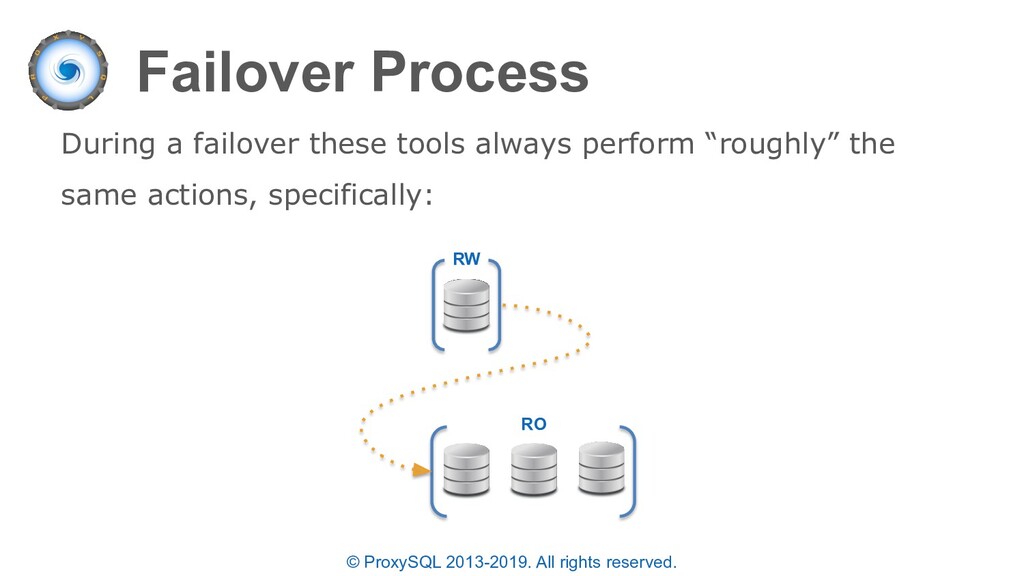
high availability architectures for ProxySQL include: • Keepalived (IP failover / TCP load balancer) • DNS / Consul DNS (other service discovery tools) • ProxySQL Cascading
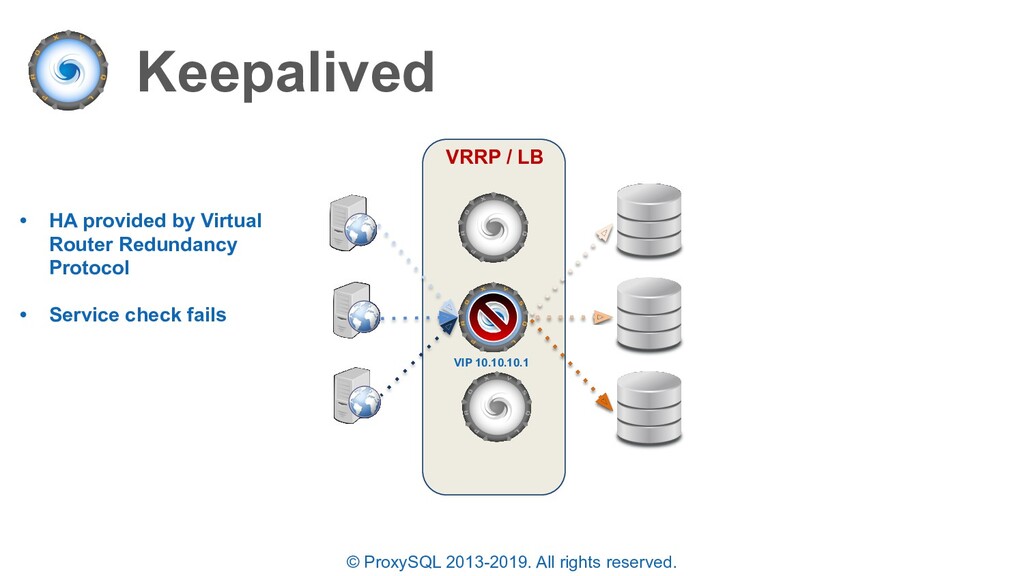
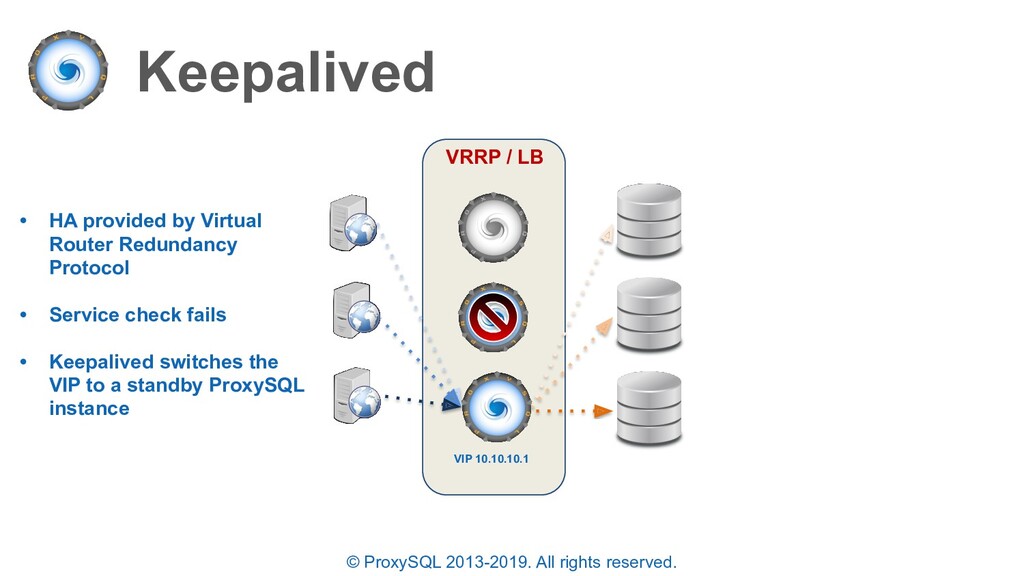
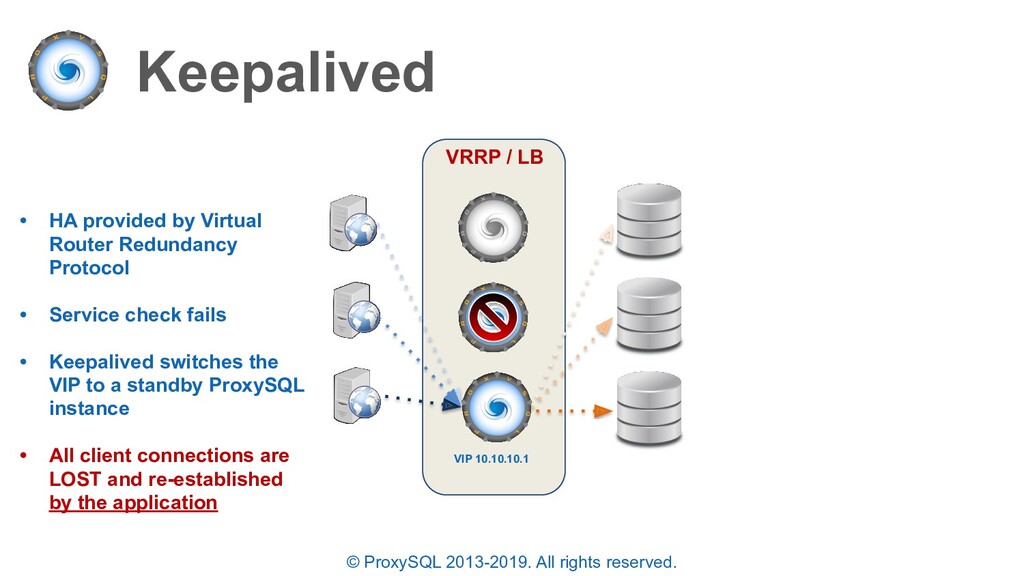
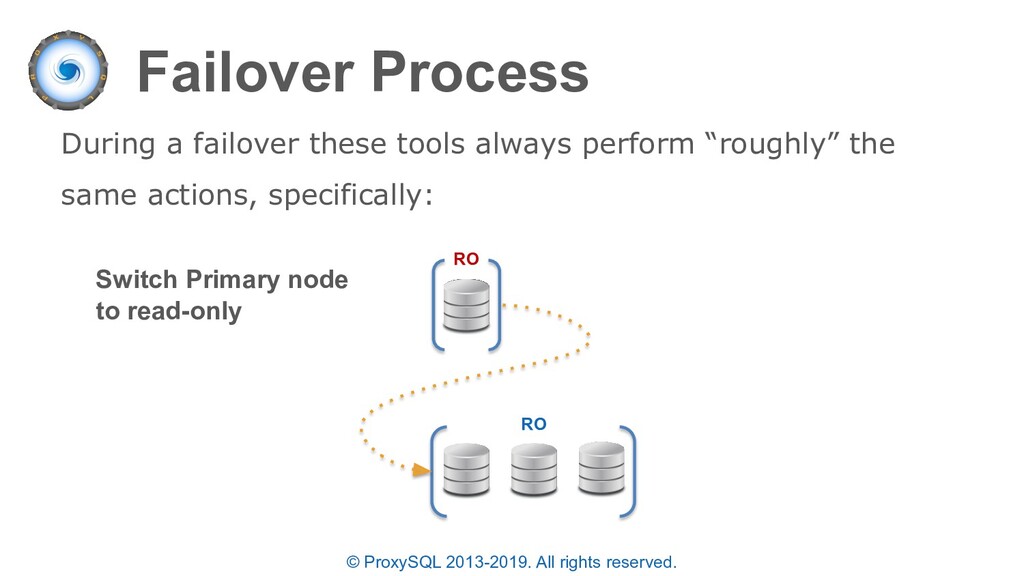
HA provided by Virtual Router Redundancy Protocol • Service check fails • Keepalived switches the VIP to a standby ProxySQL instance • All client connections are LOST and re-established by the application VRRP / LB
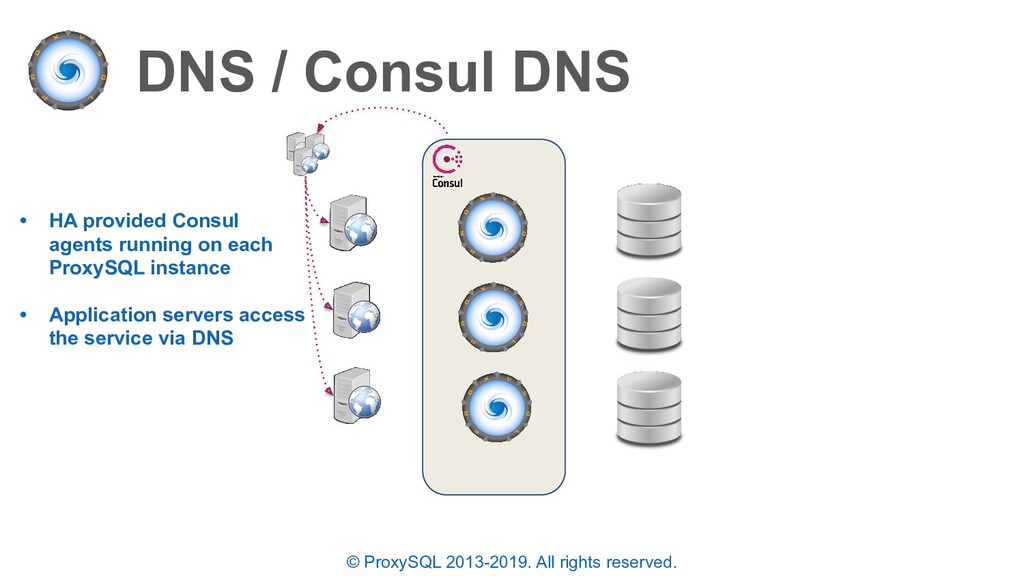
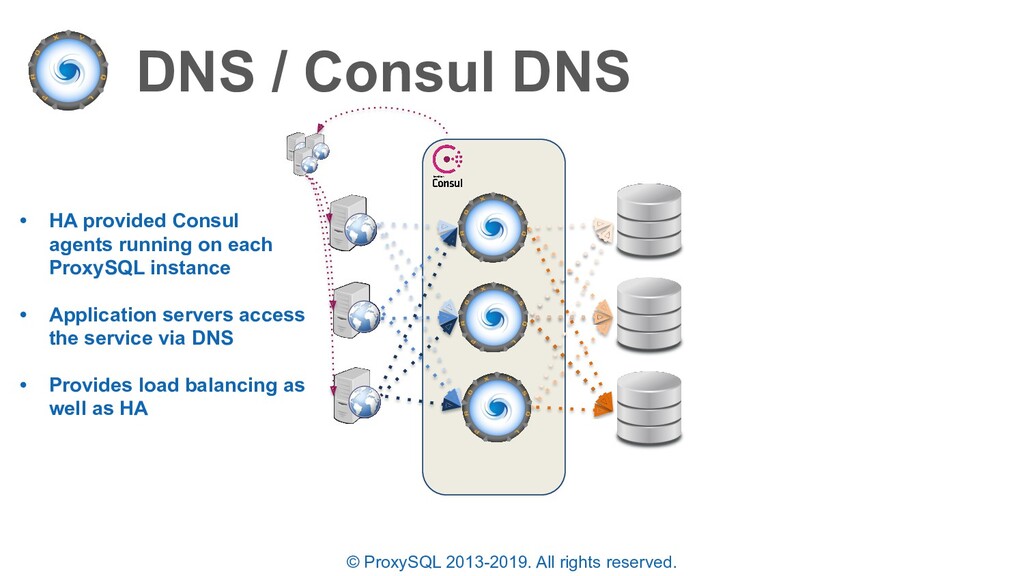
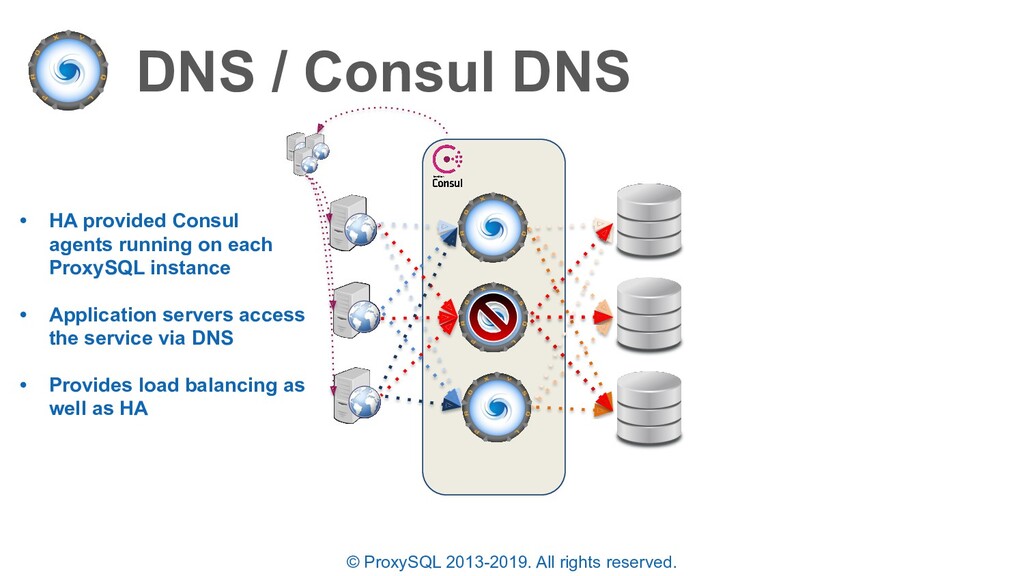
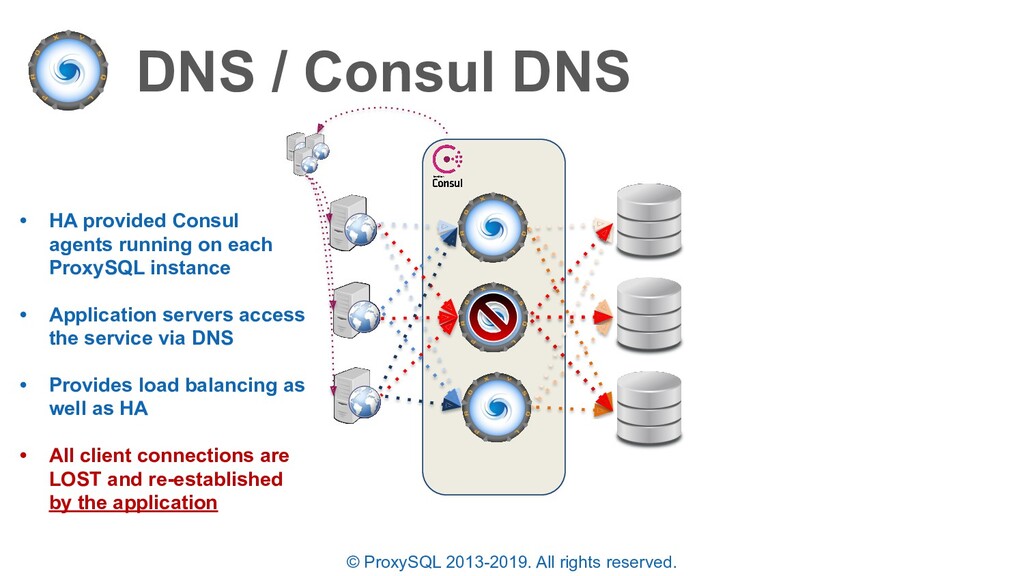
• HA provided Consul agents running on each ProxySQL instance • Application servers access the service via DNS • Provides load balancing as well as HA • All client connections are LOST and re-established by the application
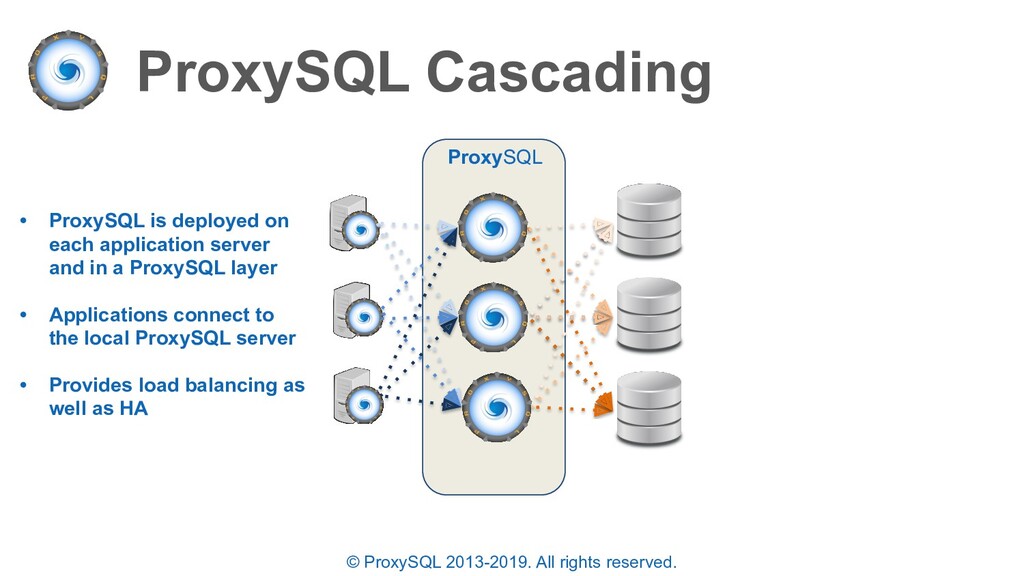
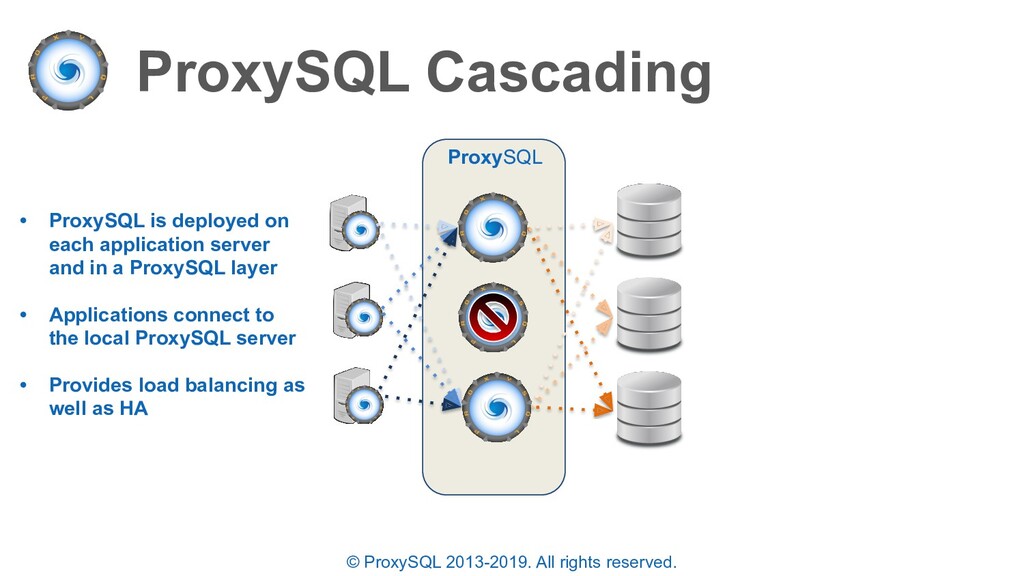
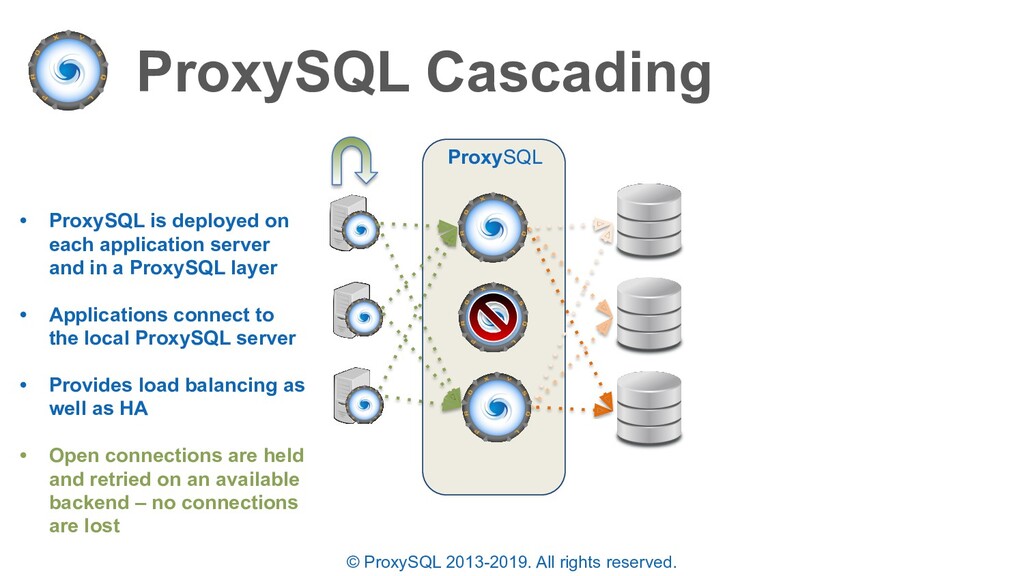
is deployed on each application server and in a ProxySQL layer • Applications connect to the local ProxySQL server • Provides load balancing as well as HA ProxySQL
is deployed on each application server and in a ProxySQL layer • Applications connect to the local ProxySQL server • Provides load balancing as well as HA ProxySQL
is deployed on each application server and in a ProxySQL layer • Applications connect to the local ProxySQL server • Provides load balancing as well as HA • Open connections are held and retried on an available backend – no connections are lost ProxySQL
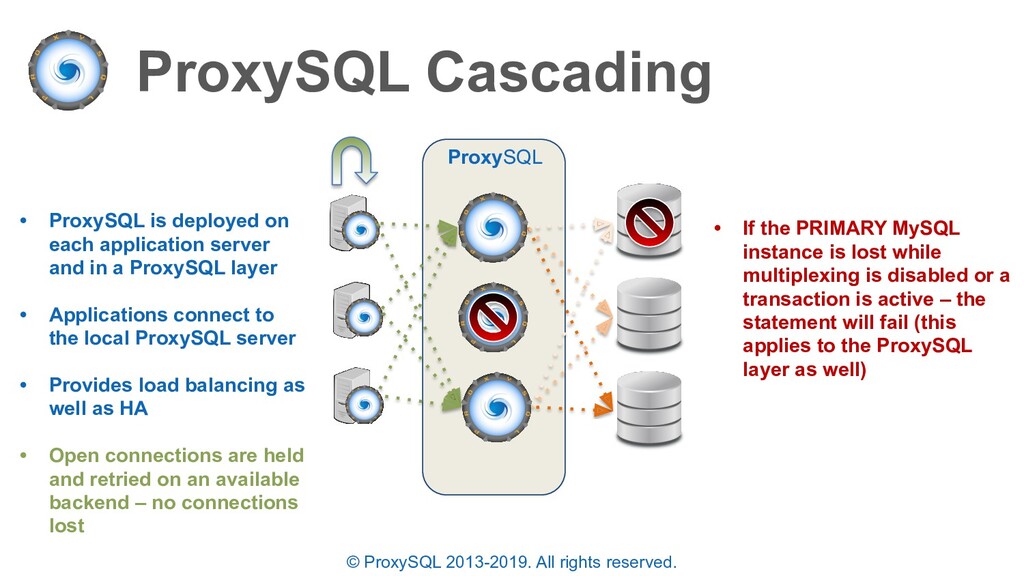
is deployed on each application server and in a ProxySQL layer • Applications connect to the local ProxySQL server • Provides load balancing as well as HA • Open connections are held and retried on an available backend – no connections lost • If the PRIMARY MySQL instance is lost while multiplexing is disabled or a transaction is active – the statement will fail (this applies to the ProxySQL layer as well) ProxySQL
be used to provide HA to itself as it communicates using the MySQL Protocol: • Application layer aware • Provides connection retry • Allows for scale up / scale down without connection loss (during planned maintenance) • Transactions can be lost during edge case unplanned failover
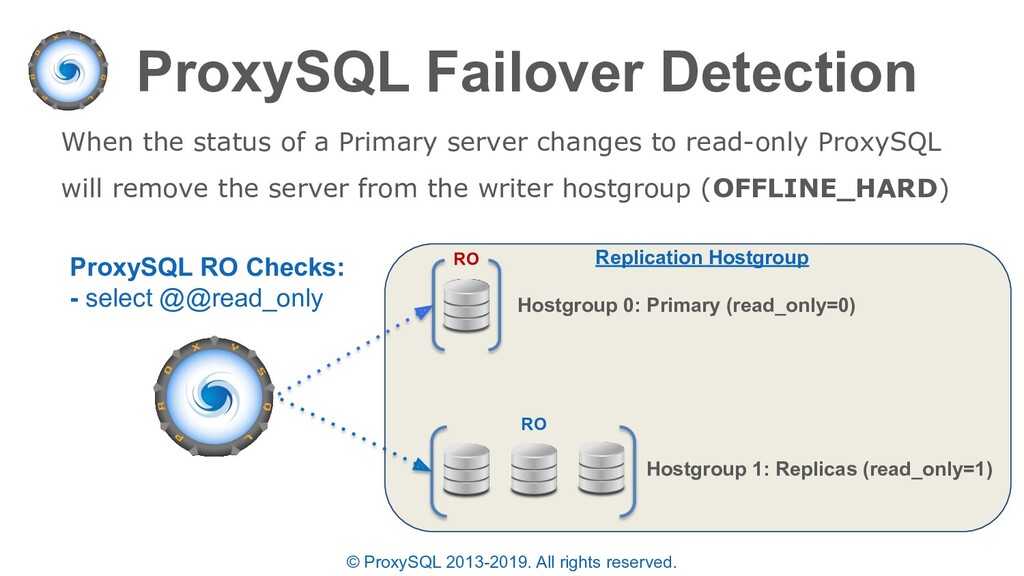
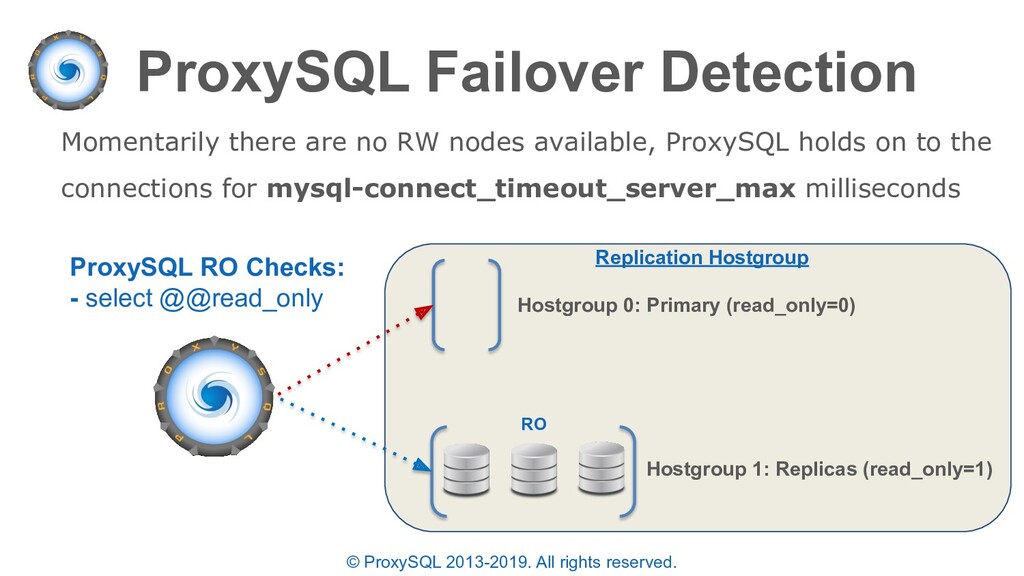
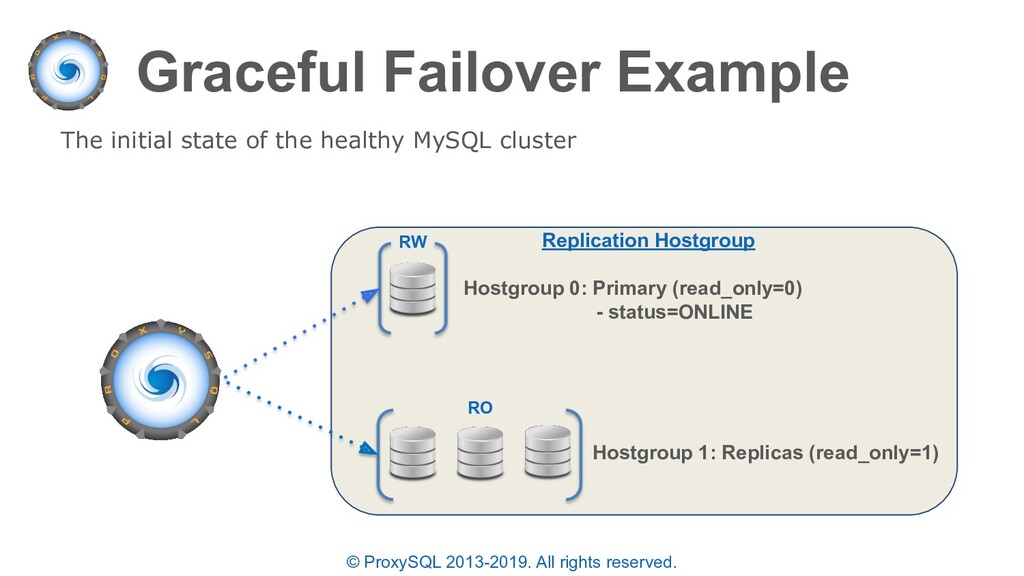
monitor module will determine the status of a backend server in the “runtime_mysql_servers” table (these states can also be set manually in “mysql_servers”): • ONLINE - backend server is fully operational (manually set / automatically set by monitor) • SHUNNED - backend sever is temporarily taken out of use because of either too many connection errors in a time that was too short, or replication lag exceeded the allowed threshold (automatically set by monitor)
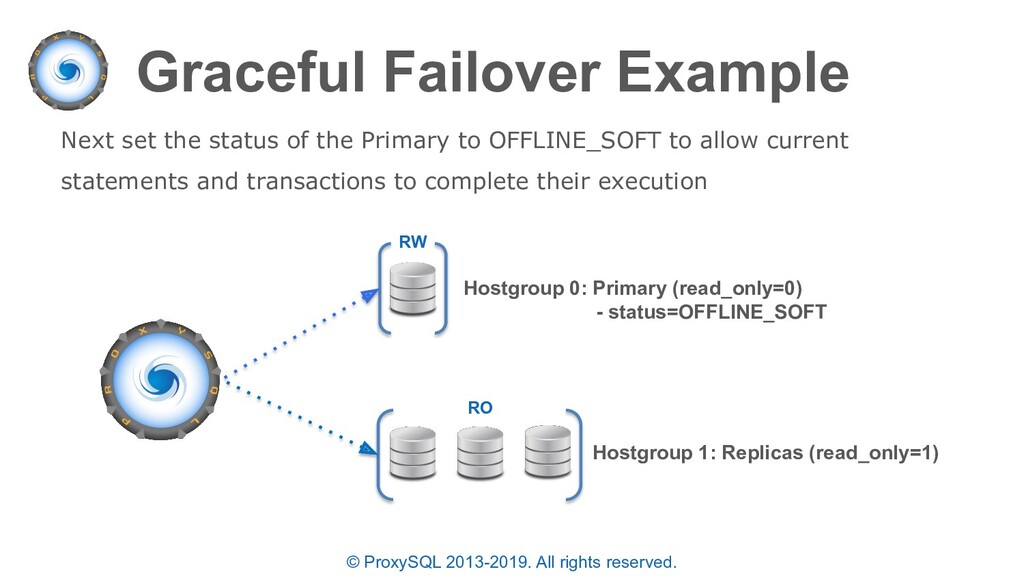
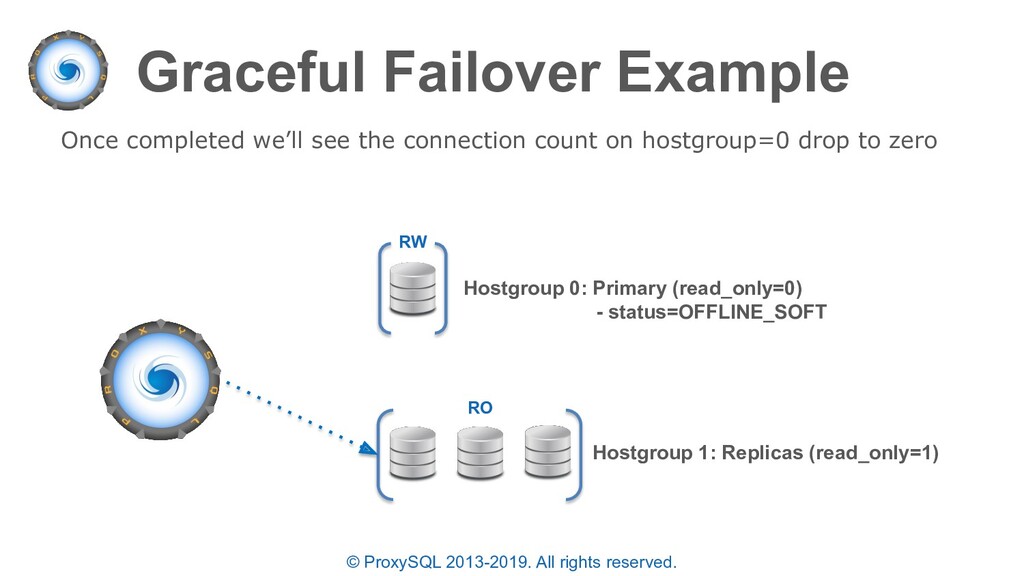
OFFLINE_SOFT - when a server is put into OFFLINE_SOFT mode, new incoming connections aren't accepted anymore, while the existing connections are kept until they became inactive. In other words, connections are kept in use until the current transaction is completed. This allows to gracefully detach a backend (manually set). • OFFLINE_HARD - when a server is put into OFFLINE_HARD mode, the existing connections are dropped and no new incoming connections are accepted. This is equivalent to deleting the server from a hostgroup (indefinitely or for maintenance) and is done by ProxySQL on failover (manually / automatically set by monitor)
was initially built to support regular “async” / “semi-sync” replication topologies (traditional primary / replica), later support for additional types of replication was introduced: • Support for custom replication topologies was available via external scheduler scripts since ProxySQL version 1.x • ProxySQL 1.3.x introduced support for Oracle Group Replication • Native support for Oracle Group Replication was added in ProxySQL 1.4.x • Native support for Galera Replication was added in ProxySQL 2.x • Native support for Amazon Aurora and RDS was added in ProxySQL 2.x
• Multi-master / Active-Active Clustered MySQL Solution – Single master by default (group_replication_single_primary_mode) • Synchronous Replication (certification based) • Multi-threaded Replication • InnoDB Compliant • Suitable for LAN and low latency networks • State transfer is based on GTID matching
• Multi-master / Active-Active Clustered MySQL Solution • Synchronous Replication (certification based) • Multi-threaded Replication • InnoDB Compliant • Suitable for LAN, WAN and Cloud Solutions • IST (incremental) & SST (full) for state transfer • Auto reconnect mechanism for rejected nodes
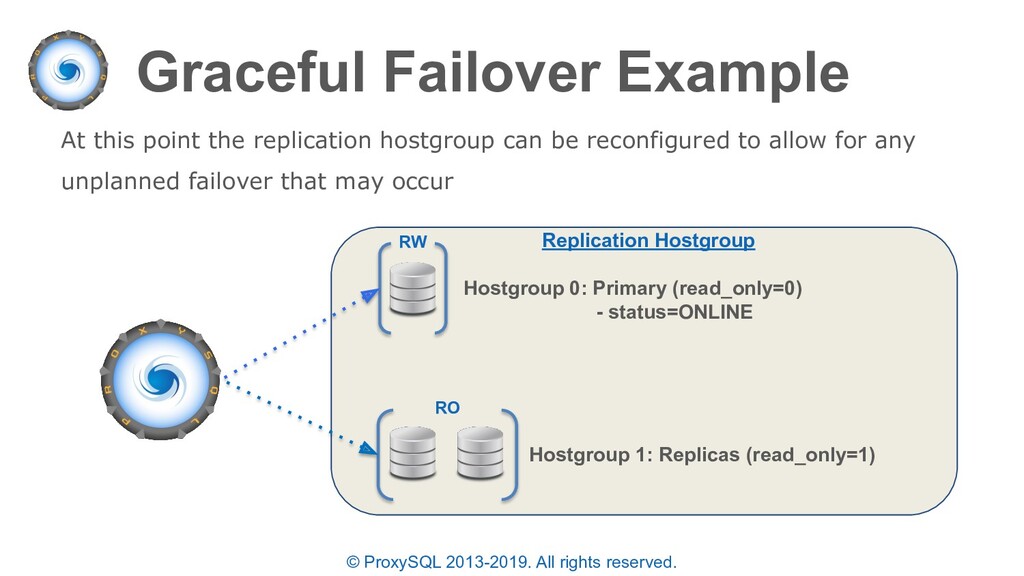
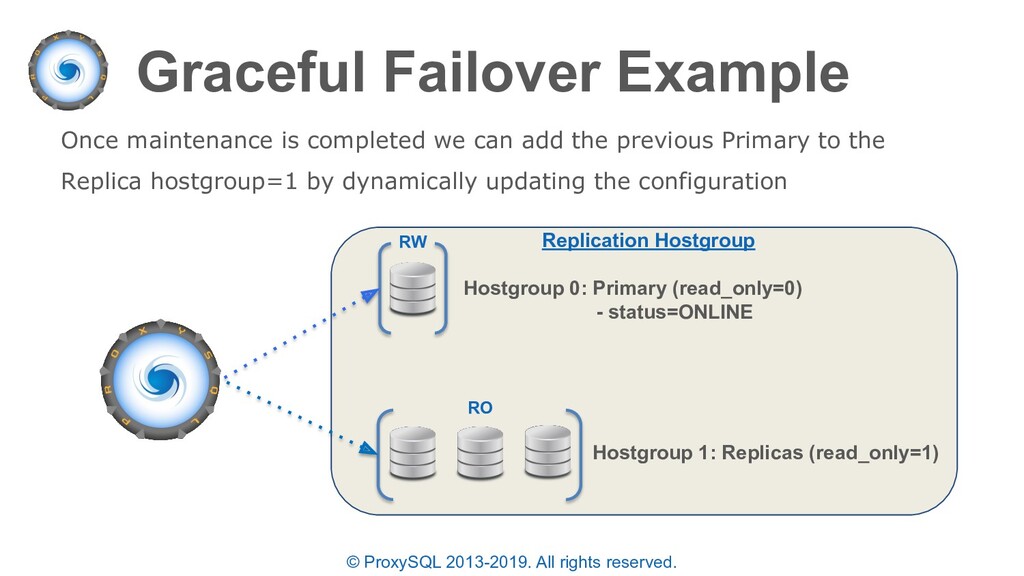
In ProxySQL 2.0 the concept of “mysql_replication_hostgroup” is extended to allow for multiple hostgroups. • In addition to “reader_hostgroup” and “writer_hostgroup” we also have the following additional concepts and hostgroup types: – max_writers – writer_is_also_reader – max_transactions_behind – backup_writer_hostgroup – offline_hostgroup
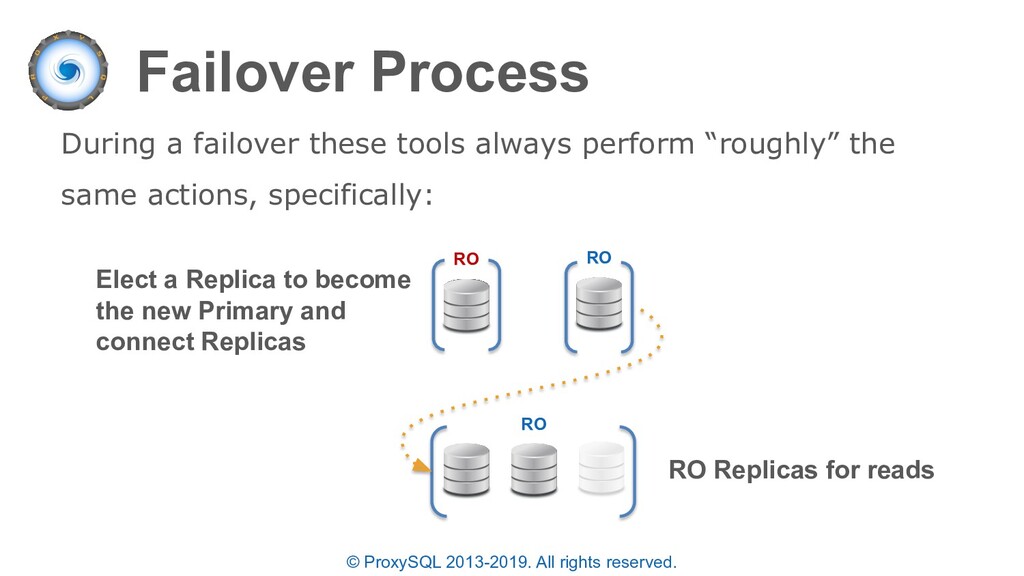
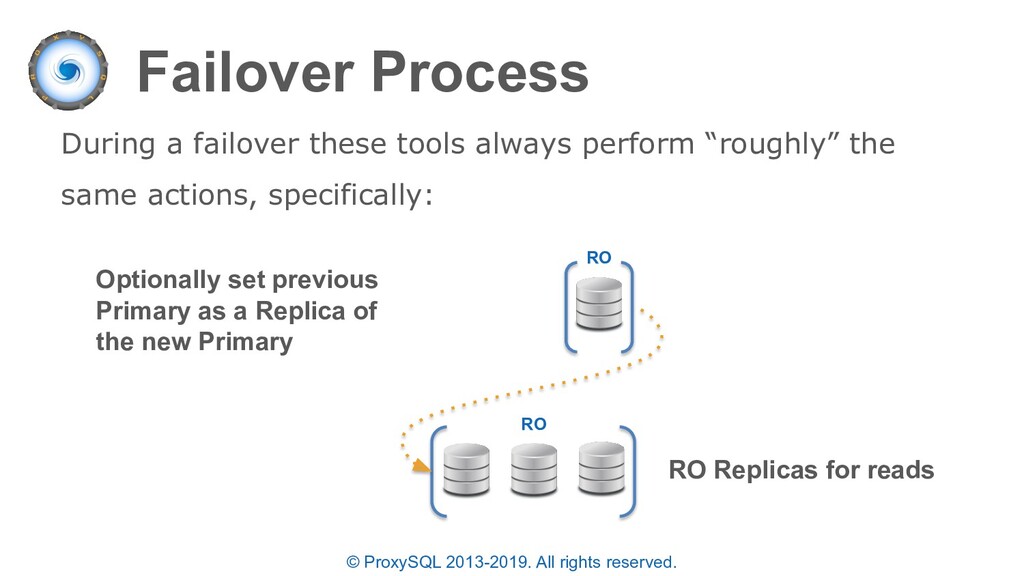
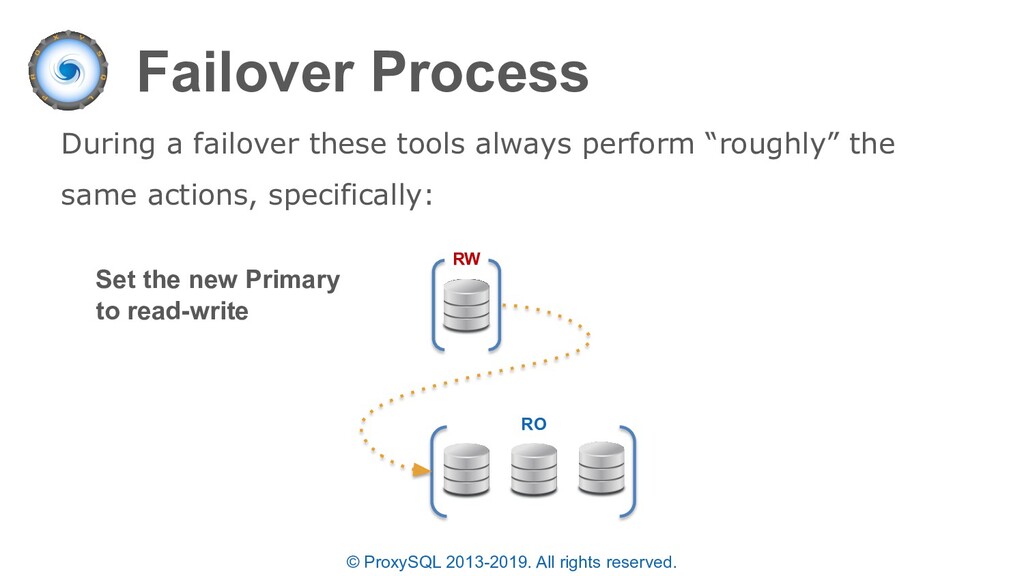
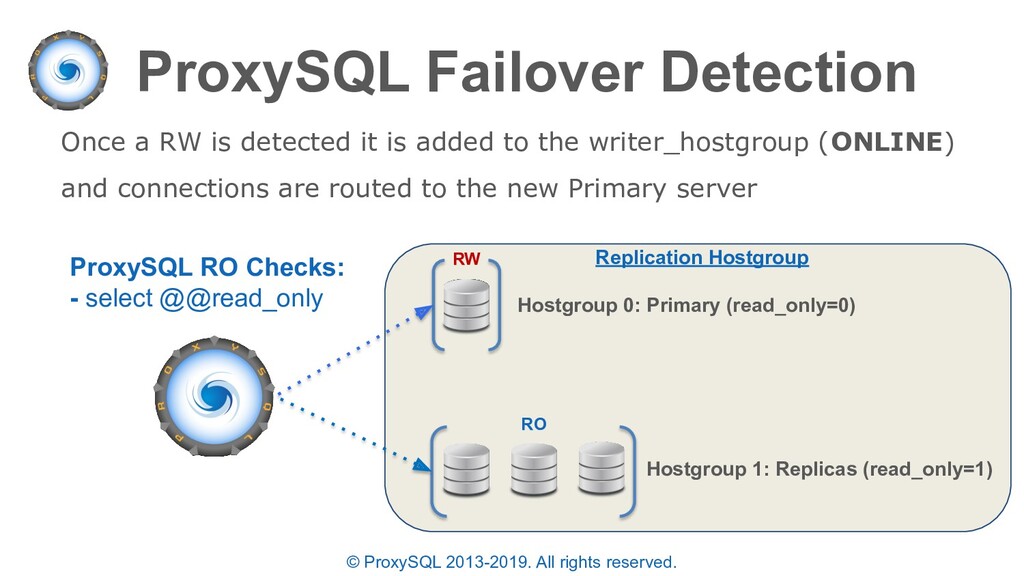
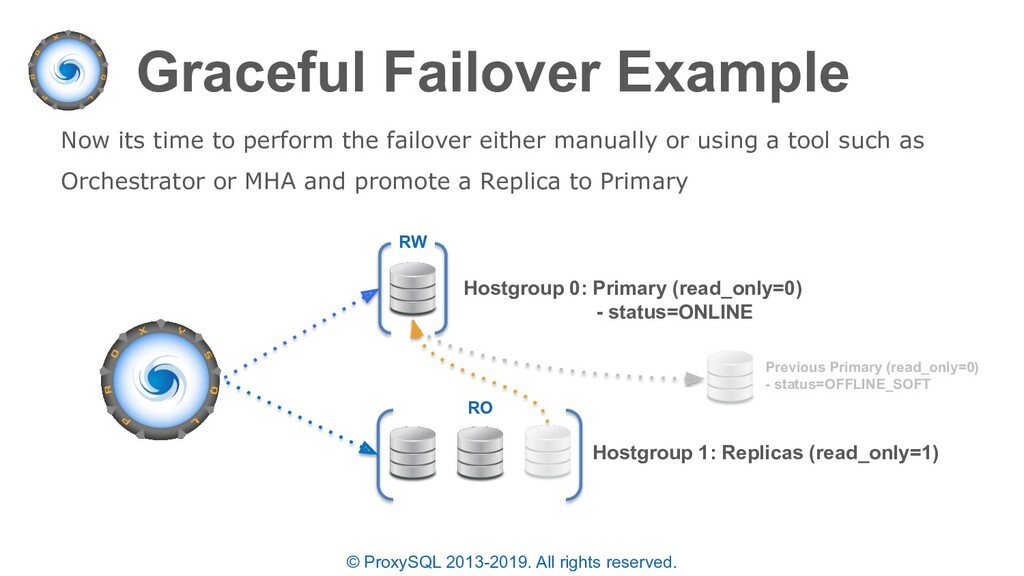
discussed: • ProxySQL will automatically re-route “writer” connections to the new Primary after a failover • The failover time is configurable based on the read only monitoring check • If the PRIMARY MySQL instance is lost while multiplexing is disabled or a transaction is active – the statement will fail since the full transaction should be retried.
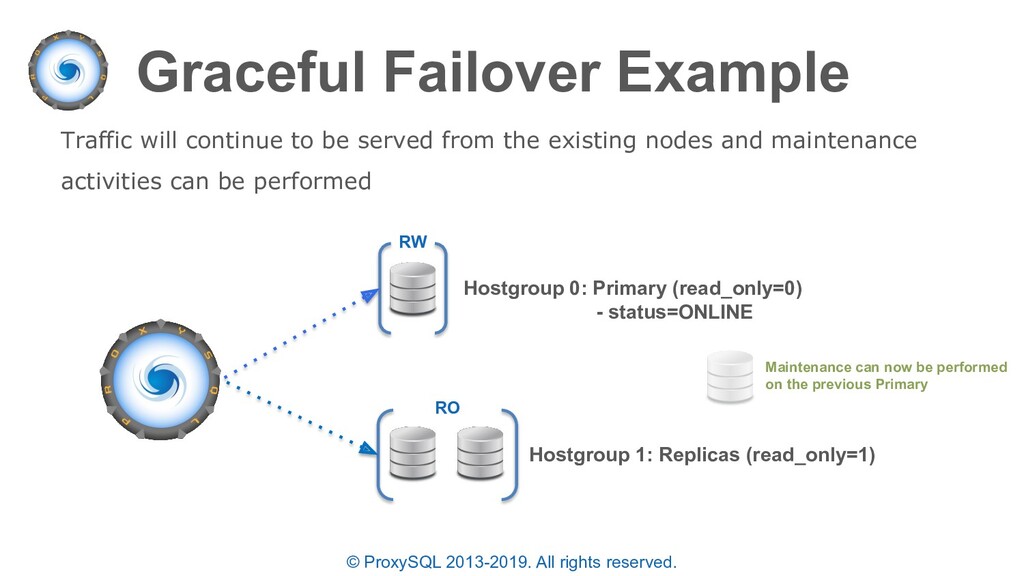
is acceptable in an “emergency situation” failovers can also be required for common maintenance activities including: • Scaling up hardware and resources • Operating system updates • Upgrading MySQL to a newer release • Executing certain blocking ALTERs e.g. converting a primary key from INT to BIGINT
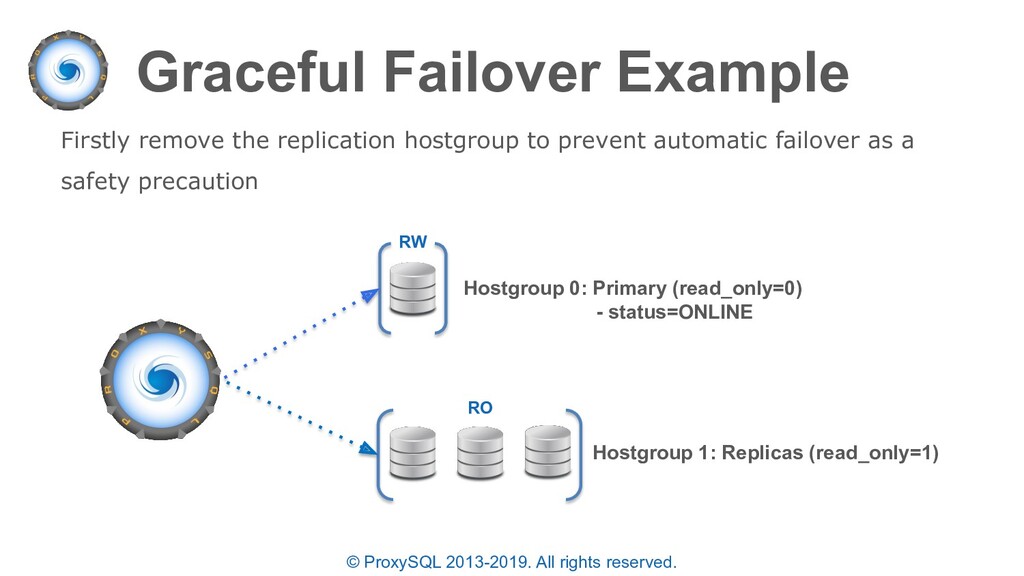
“planned failovers” as well • In the “mysql_servers” table each server can have a status of ONLINE, SHUNNED, OFFLINE_SOFT, OFFLINE_HARD configured • OFFLINE_SOFT is a special status that allows all currently executing connections (statements and transactions) to complete while preventing any new connections to be made • New connections are either sent to another available server in the same destination_hostgroup or held until a server is available
commands to perform the previous example can be executed manually or scripted • Manually executing allows for more control while scripts are more precise and are likely to execute in a smaller time-frame • NOTE: The time between draining connections and promoting a replica must be shorter than “mysql-connect_timeout_server_max” else the new waiting connections will return an error – you can increase this before failover and revert afterwards as needed
that the number of available nodes support the maximum throughput required by applications • Whenever possible use the same sized servers for Primary and Replicas which are candidates for promotion (at least one pair should be equal) • Prepare scripts to execute “planned failover” to ensure a smooth and repeatable process • When integrating with MHA and Orchestrator consider implementing ProxySQL planned failover logic in the available hooks
few failover best practices: • When building failover mechanisms for small environments it is still recommended to use a tool such as MySQL for MHA • For larger environments it is suggested to use Orchestrator, especially for environments when multiple data centers are involved (consider the RAFT implementation) or complex replication hierarchy (long chains of replication)
Carefully consider under what circumstances automatic failover should occur, if failover is too frequent it can lead to unneeded downtime • Manual failover is acceptable if there is a 24/7 on-call team available, in fact even preferred • Properly test failover time for both “local” and “cross-dc” failovers and calculate your ”uptime loss” per failover to create estimates of “number of failovers” that can be supported per year
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}