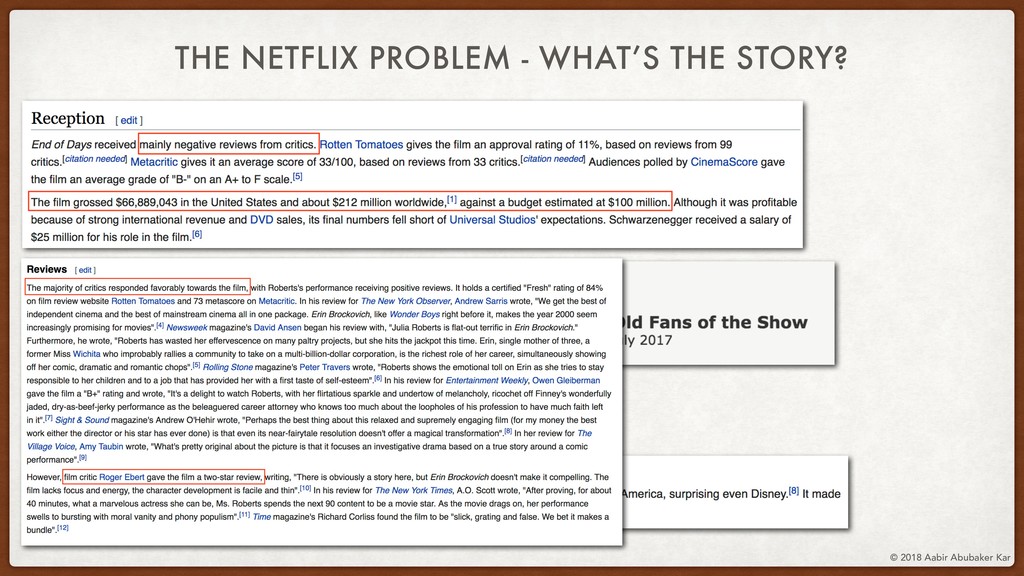
Data is often high-dimensional - millions of pixels, frequencies, categories. A lot of this detail is unnecessary for data analysis - but how much exactly? This talk will discuss the ideas and techniques of dimensionality reduction, provide useful mathematical intuition about how it's done, and show you how Netflix uses it to lead you from binge to binge.
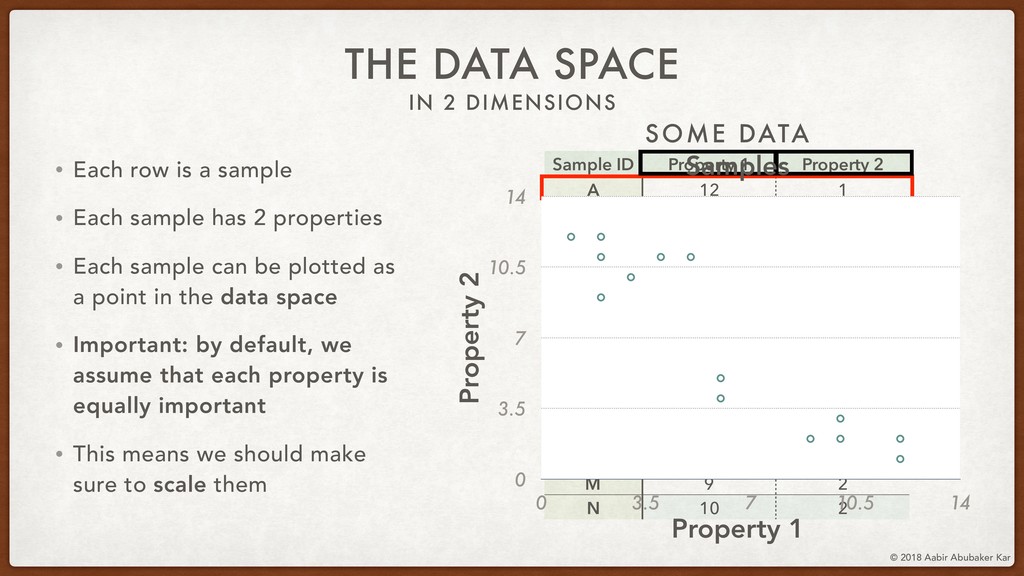
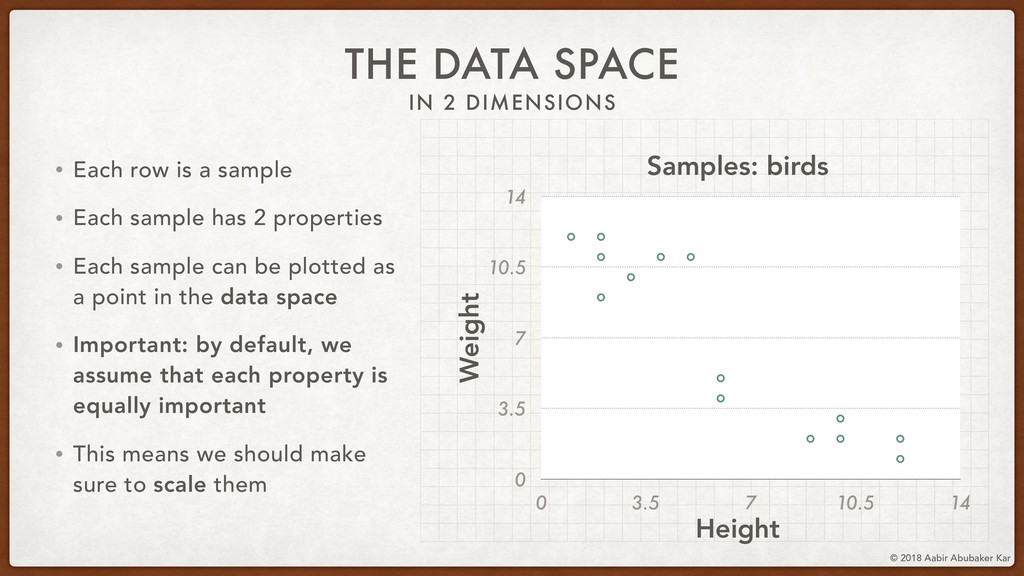
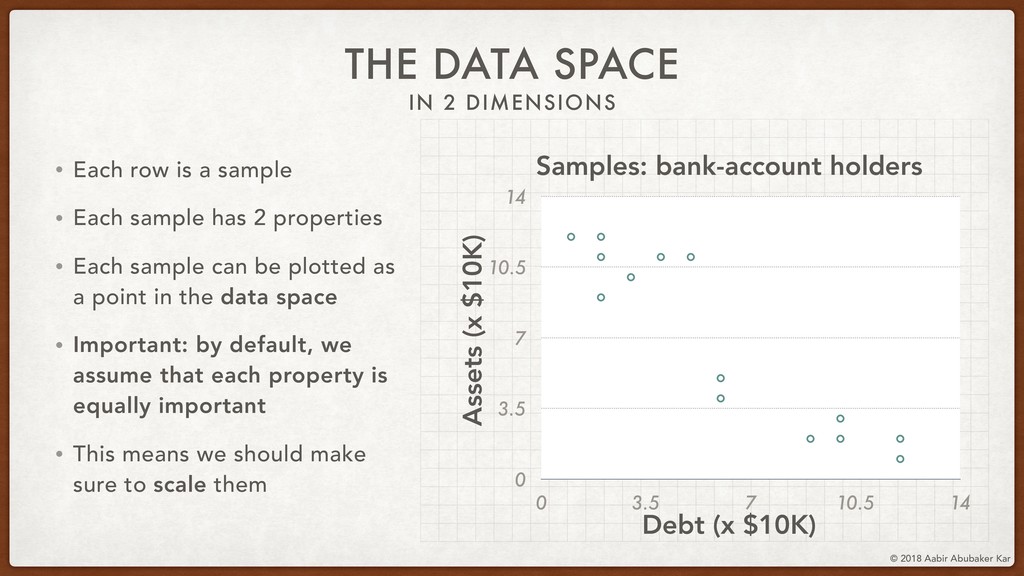
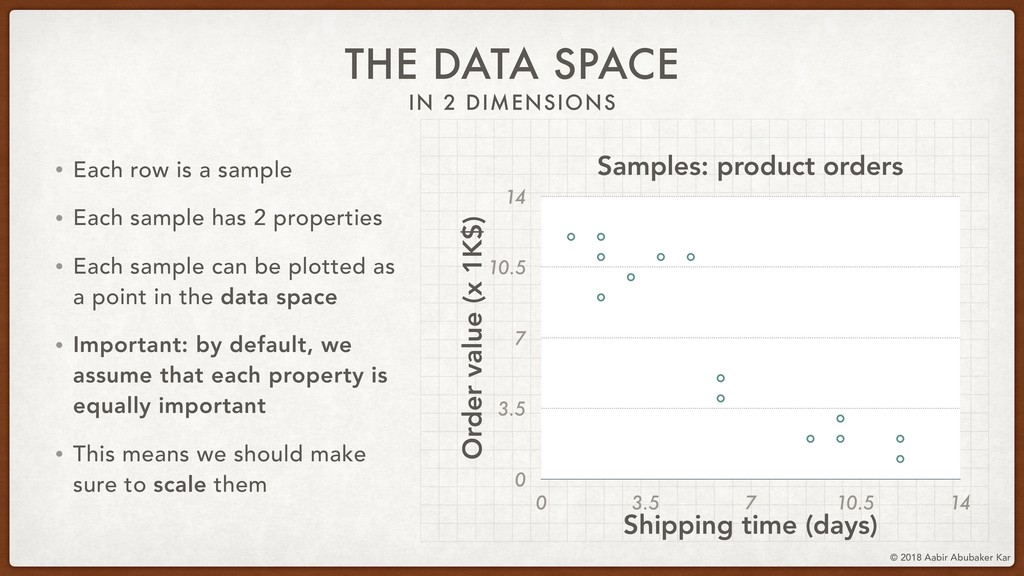
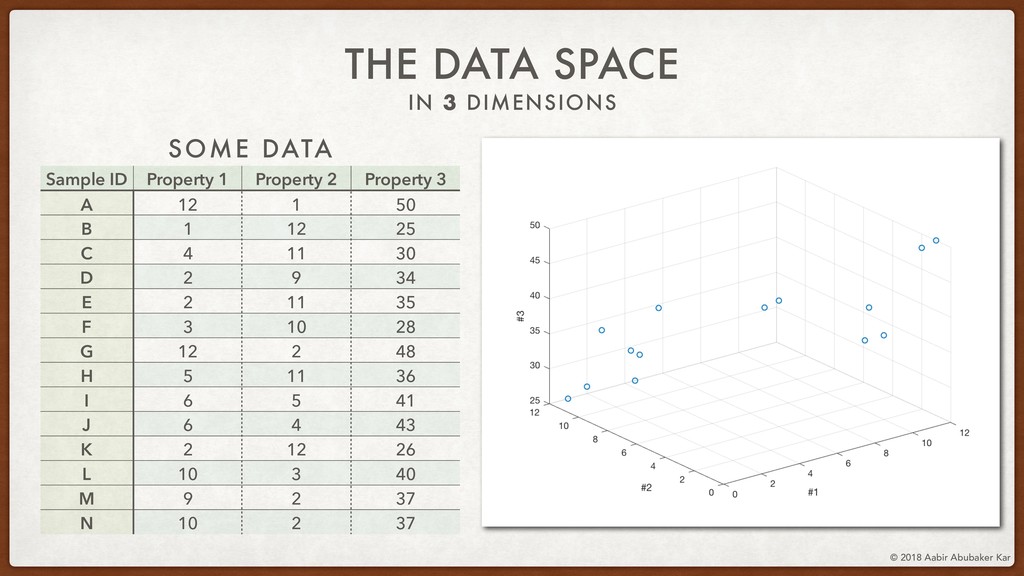
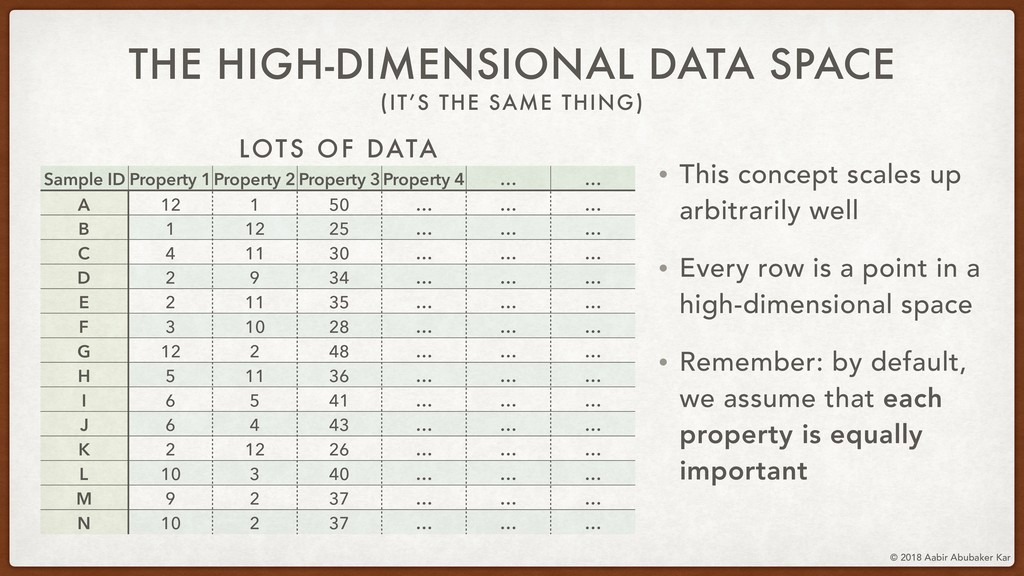
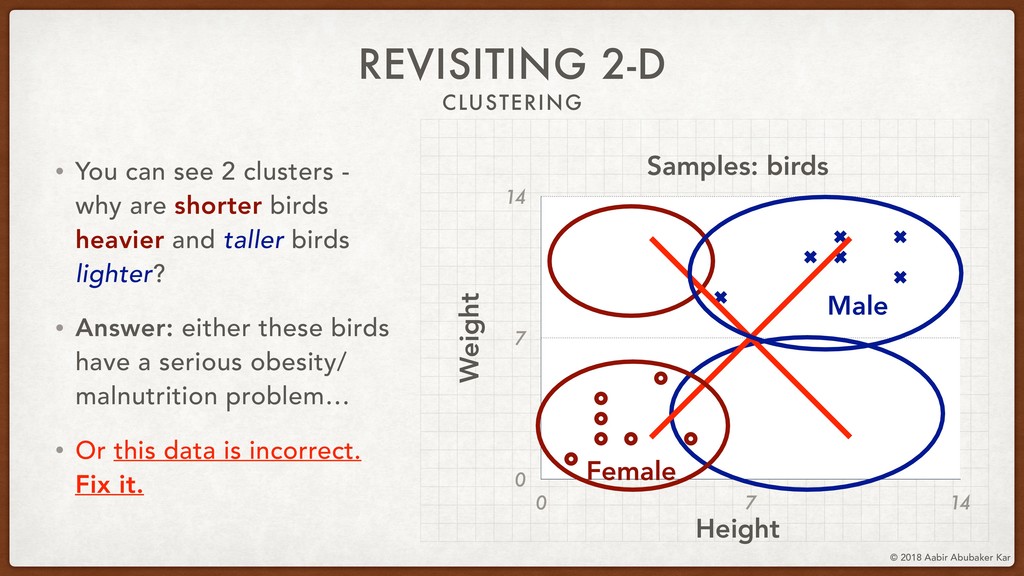
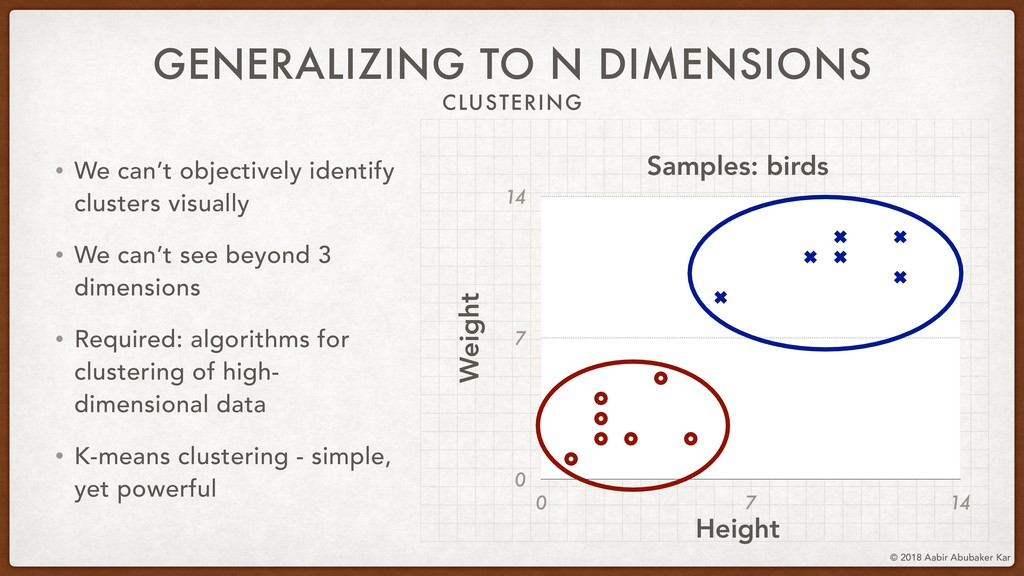
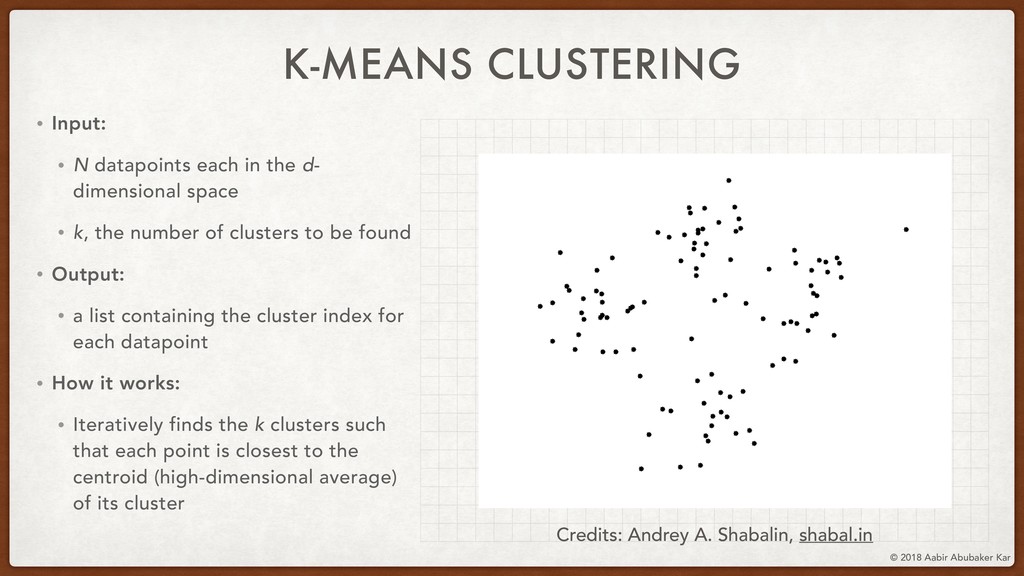
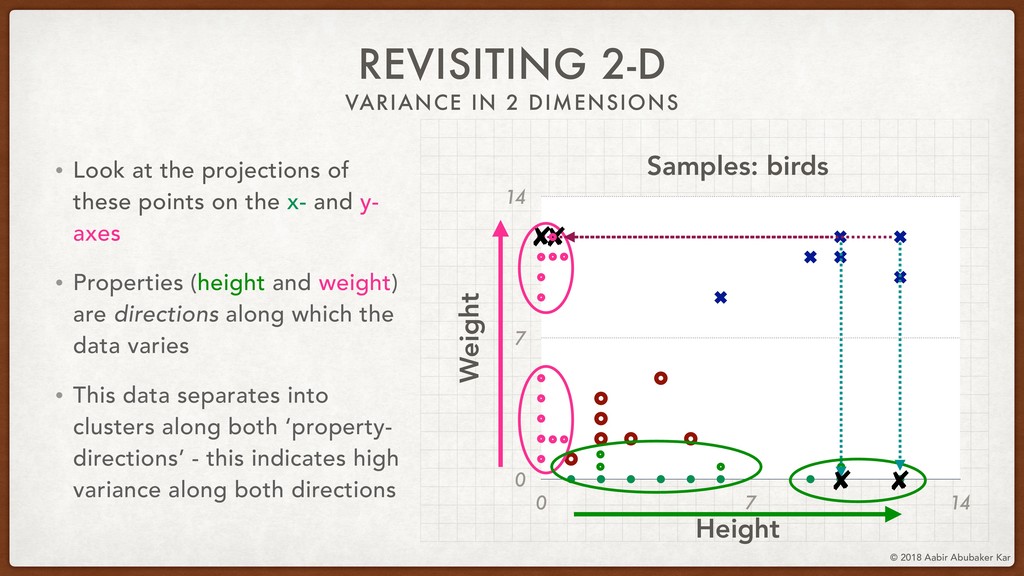
In this session, we'll start by remembering what data really is and what it stands for. Data is a structured set of numbers, and these numbers typically (hopefully!) hold some information. This will lead us naturally to the concept of a high-dimensional dataspace, the mystical realm in which data lives. It turns out that data in this space displays an extremely useful 'selection bias' - a datapoint can be known by the company it keeps. This is one of the basic ideas behind k-means clustering, which we will briefly discuss.
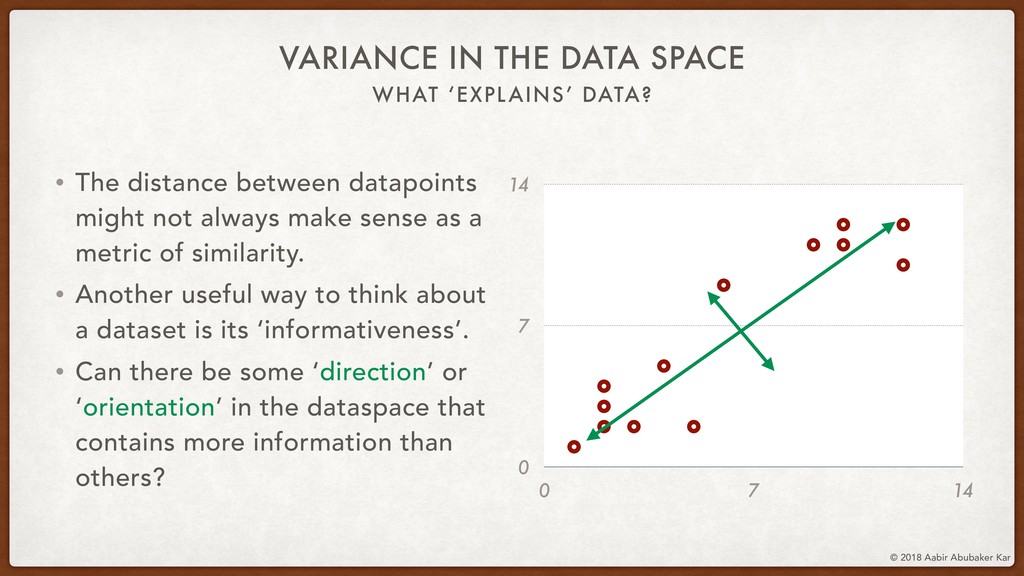
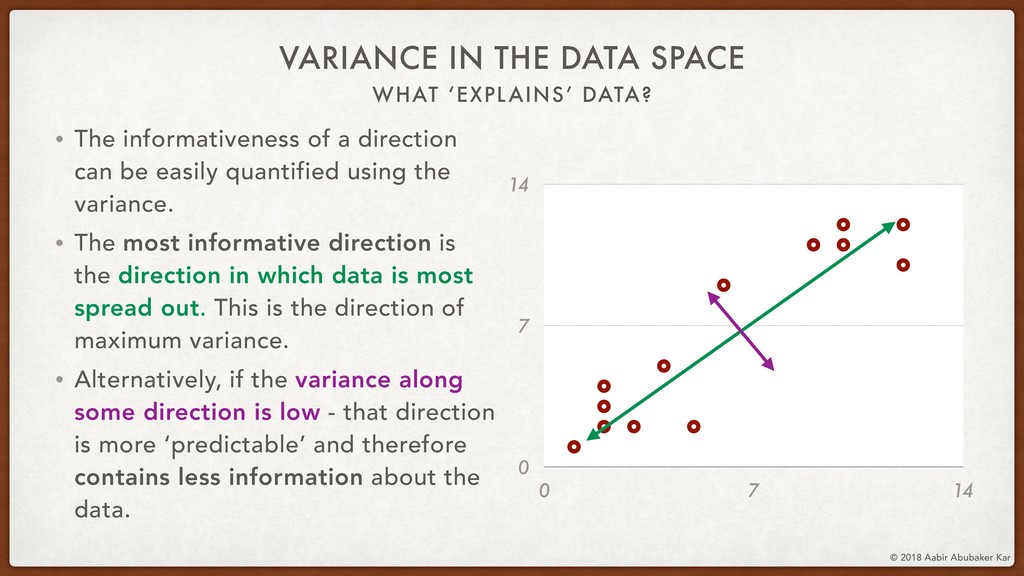
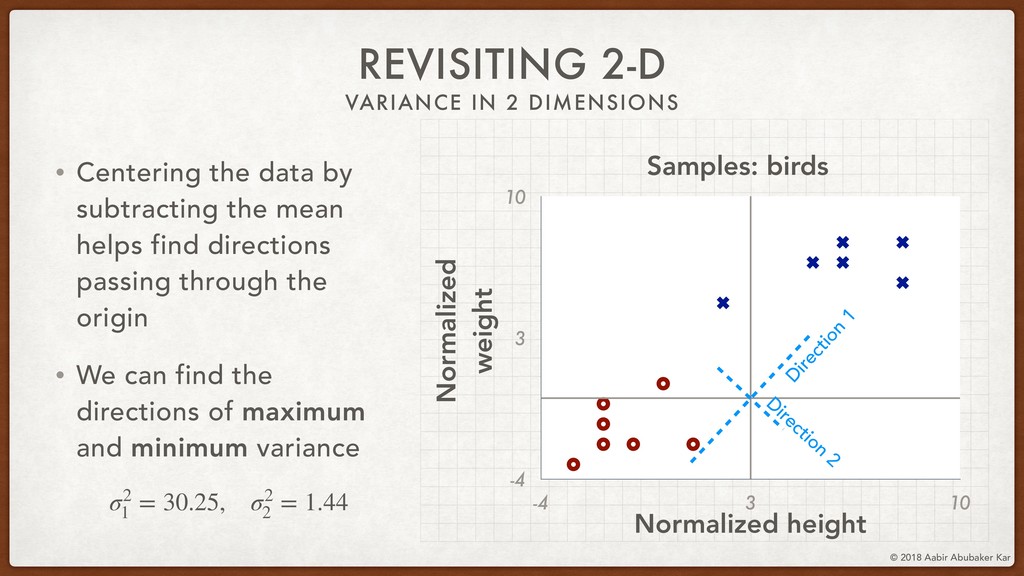
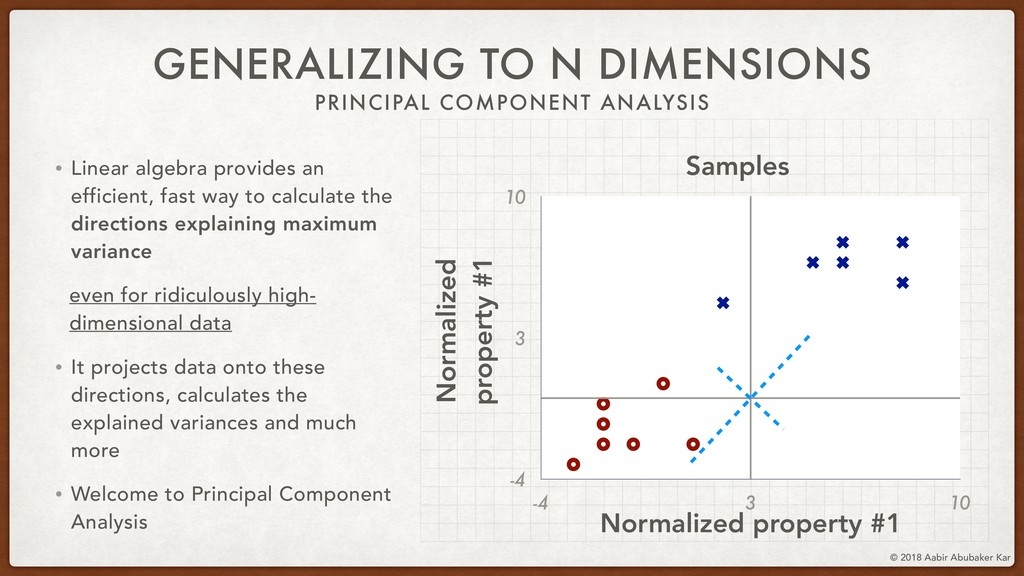
We'll then talk about the informative-ness of certain dimensions of the data space over others. This lays the mathematical foundation for the technique of Principal Component Analysis (PCA), which we will run on the Netflix movie dataset using scikit-learn.
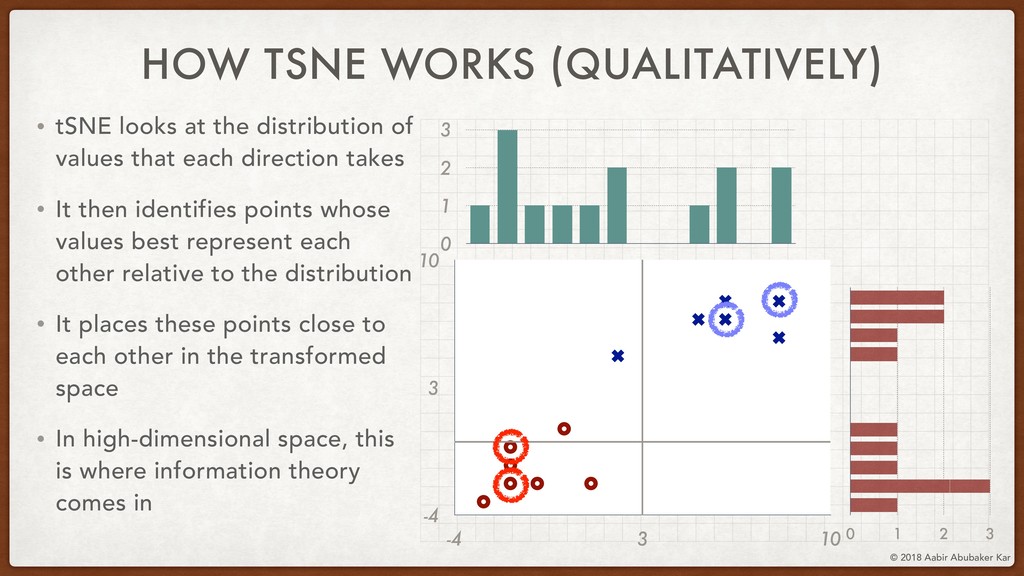
We will also touch upon tSNE, another popular dimensionality-reduction algorithms.
I will be using scikit-learn for processing and matplotlib for visualization. The purpose of this session is to introduce dimensionality-reduction to those who do not know it, and to provide useful guiding intuitions to those who do. We'll also discuss some seminal use-cases, with tips and warnings for your own applications.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}