Collaboration is a major part of doing Data Science. This means Data Scientists are always sharing their work with their colleagues whether to continue in the Data Science process or for review. One problem that is mostly faced in this process is the "It works on my machine" problem.
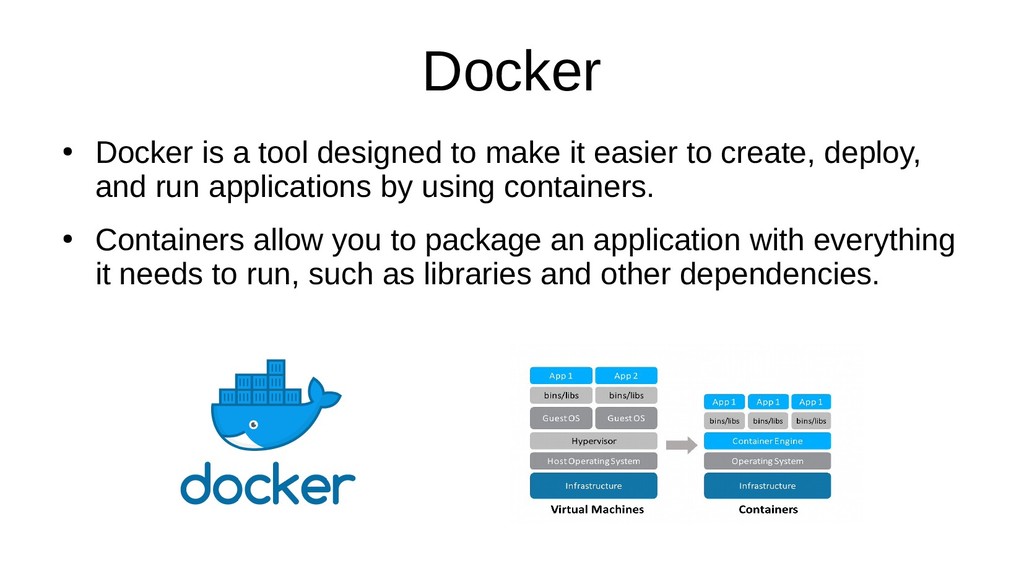
Docker is a tool that is used to package and run applications with all their dependencies in an isolated environment.
In this talk, I'll use Python to analyse some data in jupyter notebooks and show how Docker can be used to ensure reproducibility of that analysis in a different environment.
This talk will cover:
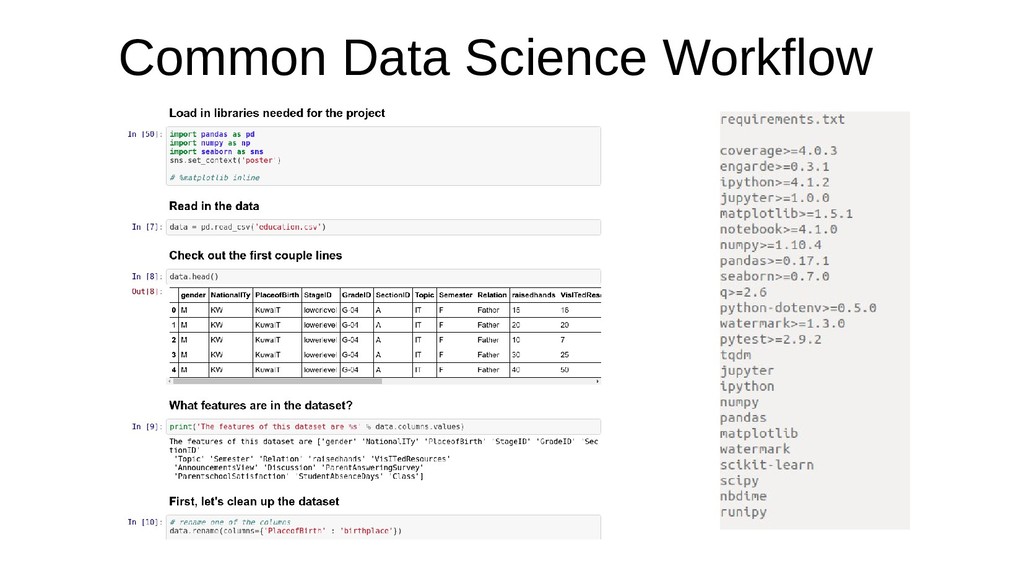
The basics of the data science workflow
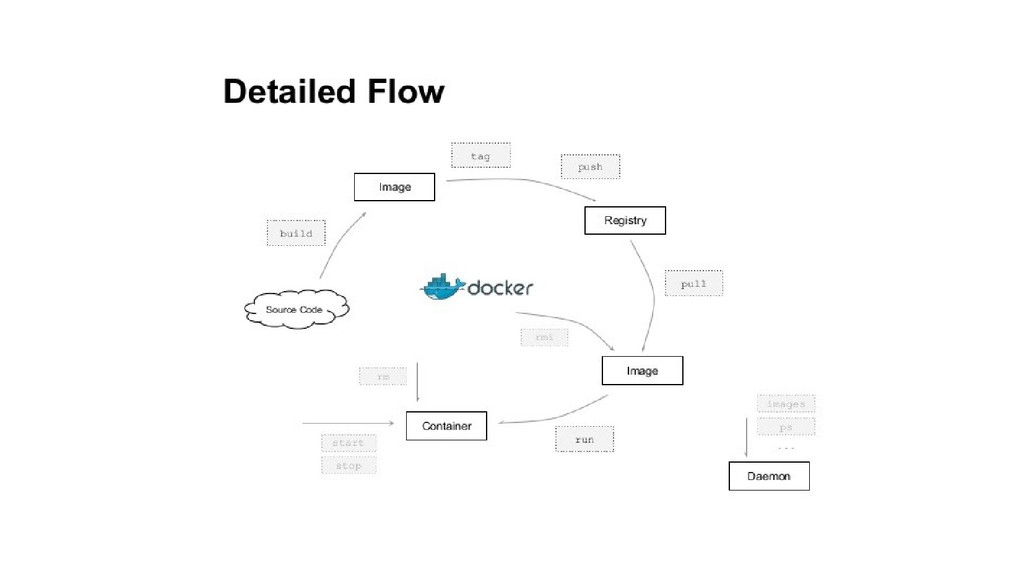
The basics of Docker
A demonstration of sharing and reproducing data analysis work in a jupyter notebook.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}