are not booked in English • Why MT? ◦ 1M+ property, and growing ◦ Very frequent property description updates ◦ New user generated content every second (cs email, review, etc.) • Presentation focus is Property Descriptions Translations
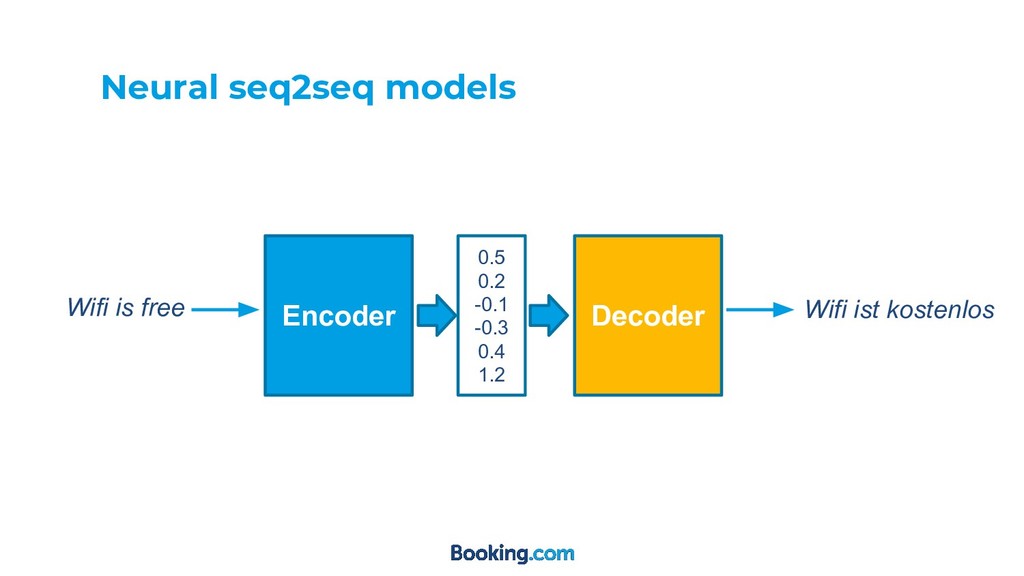
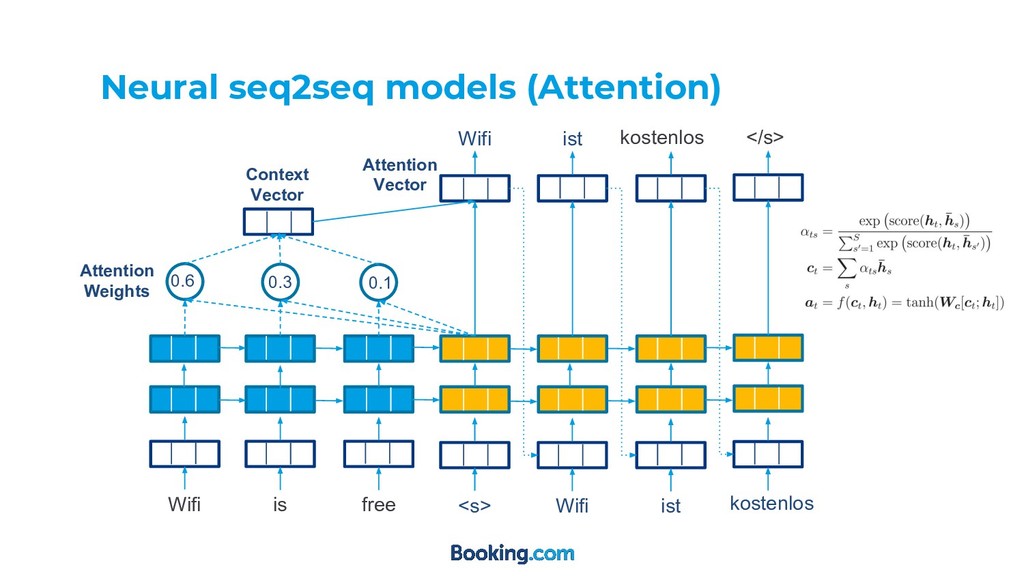
◦ More serious when you have long sequences ◦ Models still struggle to remember early tokens • How to approach this? ◦ Attention mechanisms Neural seq2seq models
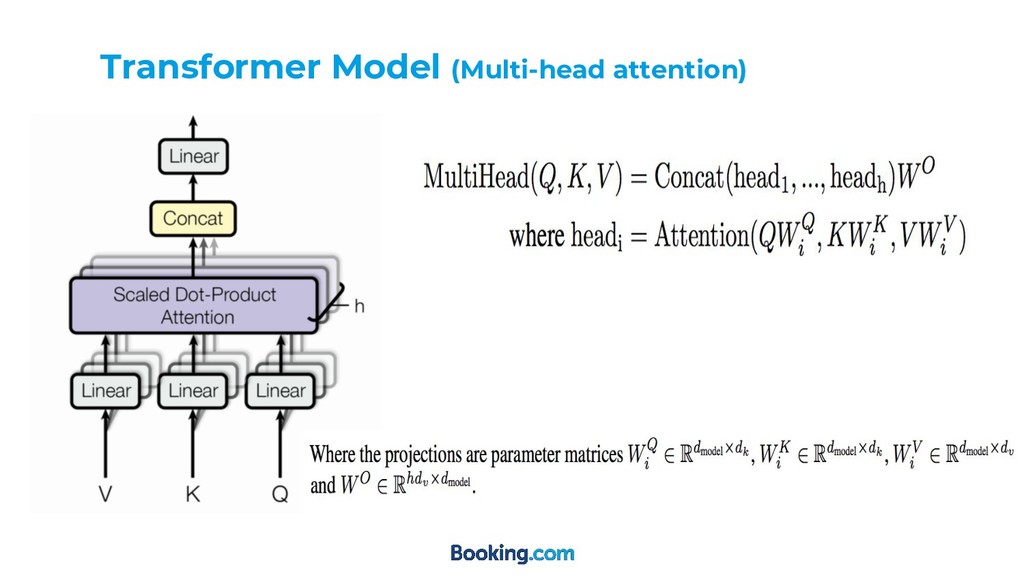
value is calculated according to the compatibility between the query q and it’s key k Context vector c of a query q is then calculated as a weighted average of all values given the attention weights
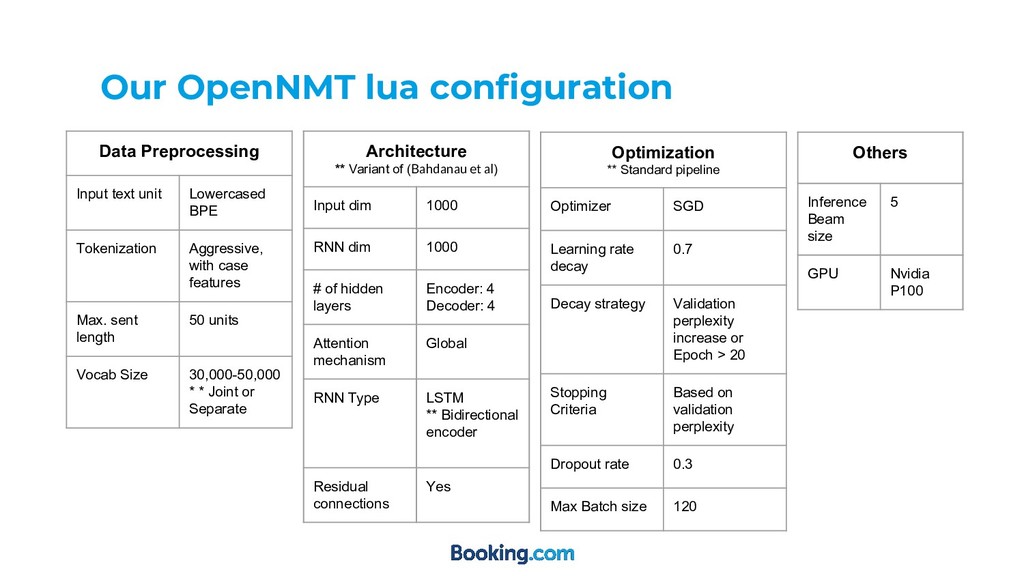
al) Input dim 1000 RNN dim 1000 # of hidden layers Encoder: 4 Decoder: 4 Attention mechanism Global RNN Type LSTM ** Bidirectional encoder Residual connections Yes Data Preprocessing Input text unit Lowercased BPE Tokenization Aggressive, with case features Max. sent length 50 units Vocab Size 30,000-50,000 * * Joint or Separate Optimization ** Standard pipeline Optimizer SGD Learning rate decay 0.7 Decay strategy Validation perplexity increase or Epoch > 20 Stopping Criteria Based on validation perplexity Dropout rate 0.3 Max Batch size 120 Others Inference Beam size 5 GPU Nvidia P100
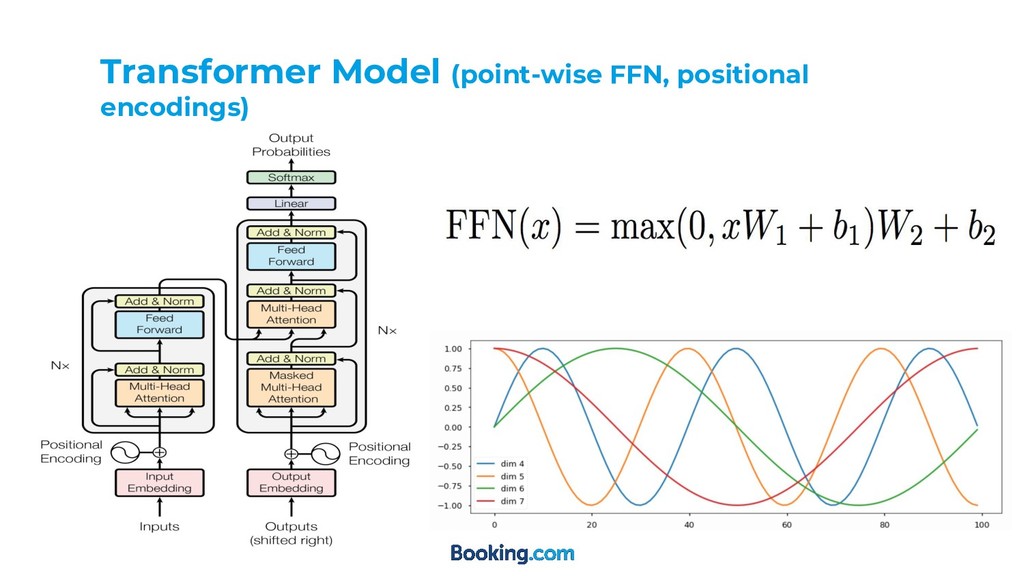
Big Transformer (6 encoder and 6 decoder attention blocks) • Embedding size = 1024 • Mostly with Nvidia P100 GPU • Some hyper-params were tuned based on the validation loss
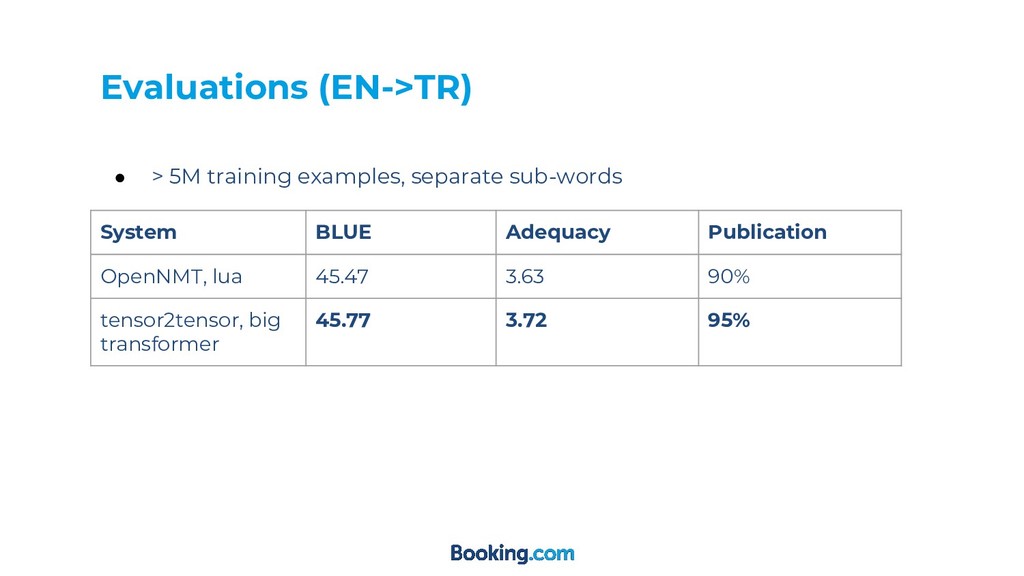
Human Evaluation ◦ Adequacy (1-4) ◦ Fluency (1-4) ◦ Publication score: ▪ The translation does is publishable if it does not mislead the user or stop her/him from booking.
offers free WiFi and air-conditioned rooms with an LCD TV and private bathroom.” ▪ In some languages (fr, ru, ar, etc.), “It” could be masculine, feminine or neutral ◦ Wrong sentence segmentation (error propagation from another component)
◦ Faster to converge ◦ TPU integration ◦ Options for training using multiple clusters ◦ Modular implementation ◦ Translation using multiple GPUs ◦ Native integration with tensorboard ◦ OpenNMT lua is going to be on maintenance mode (more focus on pytorch and tensorflow implementations)
Learning to Align and Translate, ICLR 2015. [2] Vaswani et al. Attention is all you need, 31st Conference on Neural Information Processing Systems (NIPS 2017) [3] Sutskever et al. Sequence to Sequence Learning with Neural Networks Conference on Neural Information Processing Systems (NIPS 2014) [3] Tensor2tensor https://github.com/tensorflow/tensor2tensor [4] OpenNMT http://opennmt.net/OpenNMT/ [5] The Annotated Transformer http://nlp.seas.harvard.edu/2018/04/03/attention.html
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Neural seq2seq models [3]](https://files.speakerdeck.com/presentations/dcc09dc9ec7c4b4881309ed3530697bf/slide_4.jpg){kind=link}
{kind=link}
![Attention [1] Given q (query) and <k,v> pair, the attention](https://files.speakerdeck.com/presentations/dcc09dc9ec7c4b4881309ed3530697bf/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
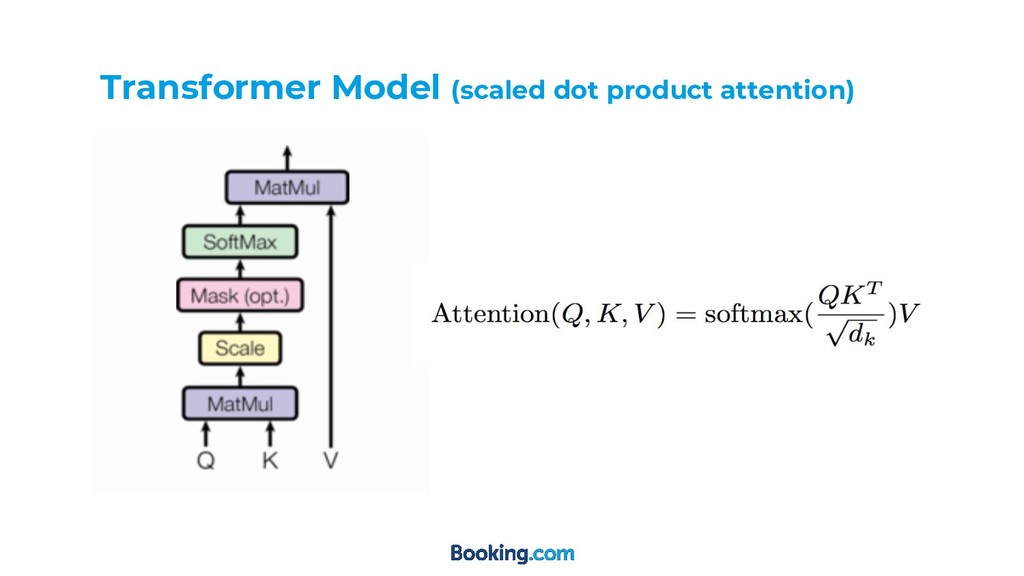
![Transformer Model [2]](https://files.speakerdeck.com/presentations/dcc09dc9ec7c4b4881309ed3530697bf/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![References [1] Bahdanau et al. Neural Machine Translation by Jointly](https://files.speakerdeck.com/presentations/dcc09dc9ec7c4b4881309ed3530697bf/slide_22.jpg){kind=link}
{kind=link}