data sets about companies To join multiple data sets together, we need a common key: company name However one company may be called by different name: : McDonalds Corporation, McDonalds, McDonald’s Corp, etc… Therefore we need to match approximately similar names of companies together
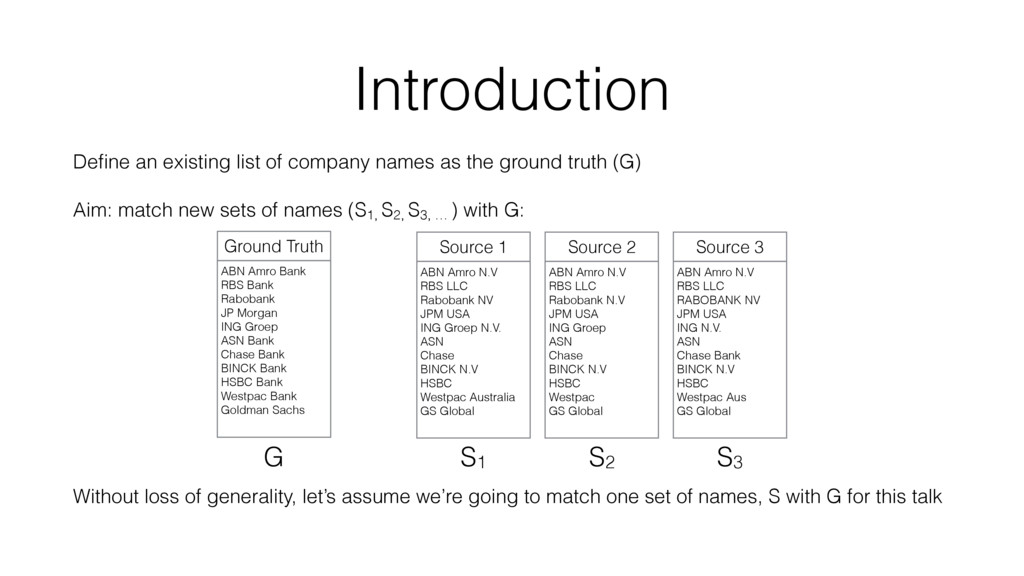
ground truth (G) Aim: match new sets of names (S1, S2, S3, … ) with G: Without loss of generality, let’s assume we’re going to match one set of names, S with G for this talk ABN Amro Bank RBS Bank Rabobank JP Morgan ING Groep ASN Bank Chase Bank BINCK Bank HSBC Bank Westpac Bank Goldman Sachs ABN Amro N.V RBS LLC Rabobank NV JPM USA ING Groep N.V. ASN Chase BINCK N.V HSBC Westpac Australia GS Global Source 1 Ground Truth ABN Amro N.V RBS LLC Rabobank N.V JPM USA ING Groep ASN Chase BINCK N.V HSBC Westpac GS Global Source 2 ABN Amro N.V RBS LLC RABOBANK NV JPM USA ING N.V. ASN Chase Bank BINCK N.V HSBC Westpac Aus GS Global Source 3 G S1 S2 S3
names • S ranges in length between 3000 and 5 mln names To make matters worse: • On average, a name is 31 characters long, containing ~4 words • The world isn’t UTF8 compliant, we have over 160 characters • Although there are limited duplicates in G, some companies have similar names and have hierarchical structures which must be observed
The closer the names are to each other, the more similar they are Calculate closeness for each word and choose the closest Ensemble with different functions to get better results
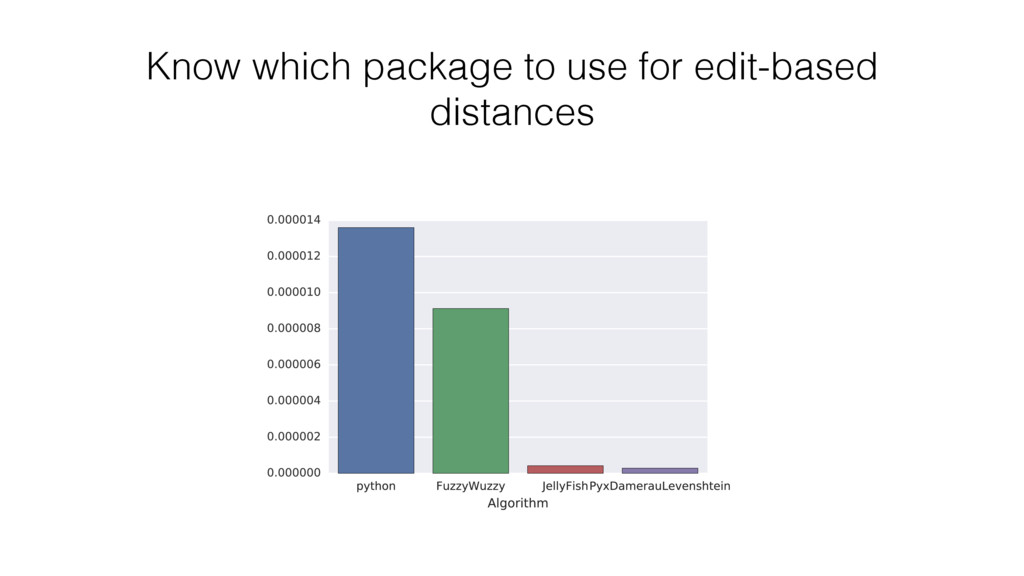
example is the Levenshtein distance. Levenshtein distance calculates the minimum number of character edits (replacing, adding or subtracting) it takes to make two strings equal. Example: levenshtein(“ABN Amro Bank”, “RBS Bank”) • ABN Amro Bank —> RBN Amro Bank (replace A with R) • RBN Amro Bank —> RBN Bank (remove Amro) • RBN Bank —> RBS Bank (replace N with S) Therefore Levenshtein(“ABN Amro Bank”, “RBS Bank”) = 1 + 4 + 1
N.V, … , “GS Global”} ABN Amro Bank RBS Bank Rabobank JP Morgan ING Groep ASN Bank Chase Bank BINCK Bank HSBC Bank Westpac Bank Goldman Sachs ABN Amro N.V RBS LLC Rabobank NV JPM USA ING Groep N.V. ASN Chase BINCK N.V HSBC Westpac Australia GS Global S G
… , “GS Global”} ABN Amro Bank RBS Bank Rabobank JP Morgan ING Groep ASN Bank Chase Bank BINCK Bank HSBC Bank Westpac Bank Goldman Sachs ABN Amro N.V RBS LLC Rabobank NV JPM USA ING Groep N.V. ASN Chase BINCK N.V HSBC Westpac Australia GS Global S G
… , “GS Global”} ABN Amro Bank RBS Bank Rabobank JP Morgan ING Groep ASN Bank Chase Bank BINCK Bank HSBC Bank Westpac Bank Goldman Sachs ABN Amro N.V RBS LLC Rabobank NV JPM USA ING Groep N.V. ASN Chase BINCK N.V HSBC Westpac Australia GS Global S G
5 million names in S • This is 60,000,000,000,000 similarity calculations • Levenshtein algorithm has time complexity of O(mn), where m, n are length of strings. • If we could calculate 10 similarity calculations a second…We would be here for ~ 190,000 years • Parallel: 10,000 cores … 19 years
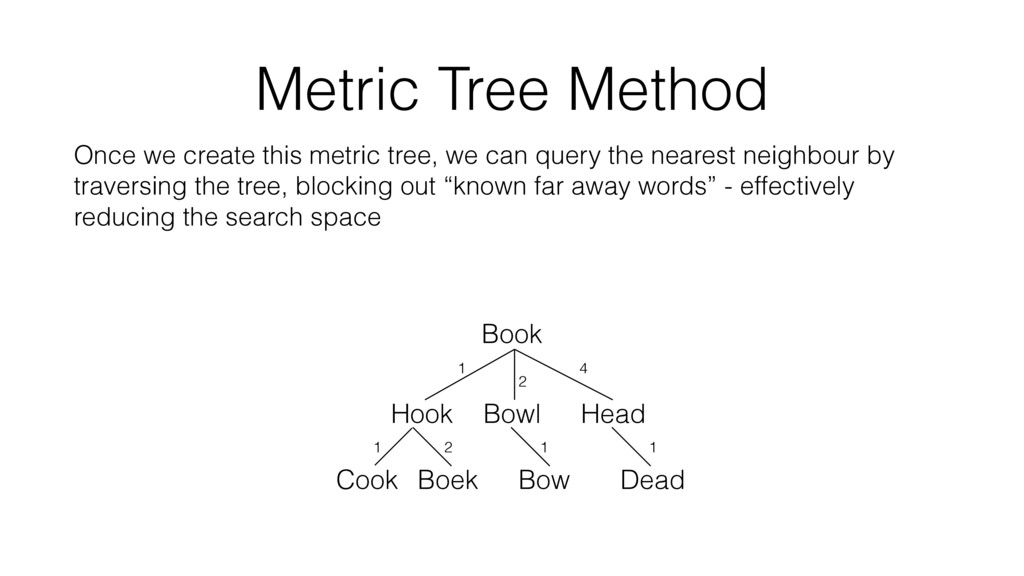
in some topological space We don’t necessarily need to know absolute location of a word in a space, just the relative distance between points Therefore we still use a distance function (as per brute force), but define it so it satisfies some mathematical properties: 1. d(x,y) = 0 —> x = y 2. d(x,y) = d(y,x) 3. d(x,z) <= d(x,y) + d(y,z) This is known as a is a metric, we can save ourself time by organising the words into a tree structure that preserves metric-distances between words
can query the nearest neighbour by traversing the tree, blocking out “known far away words” - effectively reducing the search space Book Bowl Hook Head Cook Boek Bow Dead 1 2 4 1 2 1 1
~2.7 mln different words - O(n log(n)) Typically, all words with distance of 1 determined in ~1 sec Build + query time still years worth of calculation • Added problem of making a tree in parallel • Lots of space required • Worst case performance is actually bad
types of tokens available: words, grams Do this for all names in both G and S (this creates two matrices [names x tokens]) Example: Indicator function word tokeniser: ABN RBS BANK Rabobank NV ABN Amro Bank 1 0 1 0 0 RBS Bank 0 1 1 0 0 Rabobank NV 0 0 0 1 1
of names in G • matrix of names in S • Dot product of and yields • Row i, column j of corresponds to inner product of the tokens of the i-th word in G and the j-th word in S = .
of look somewhat familiar to us: • elements are the cosine similarity of the individual name-token vectors multiplied by the L2 norm • If we normalise the token-vector on creation we end up calculating the cosine-similarity measure!
• But inner-products are cheap to calculate • Tokenised matrices can be computed offline cheaply • Tokenised methods allow for vectorisation and allow for increased memory and CPU efficiency • We can even compute this on a GPU cluster
before (3/4)… Standard token_pattern (‘(?u)\b\w\w+\b’) ignores single letters Use token_pattern (‘(?u)\b\w+\b’) for ‘full’ tokenization (token_pattern = u’(?u)\\S', ngram_range=(3, 3)) gives 3-gram matching ‘Taxibedrijf M. van Seben’ —> [‘Taxibedrijf’, ‘van’, ‘ Seben’ ]
before (4/4) Standard ‘transform’ function of Sklearn TFIDFVectorizer ignores unseen tokens —> either transform using customized function, or tokenise on combination of G and S match(‘JonasTheMan Nederland’) —> 100% match ‘Nederland Nederland’ ?
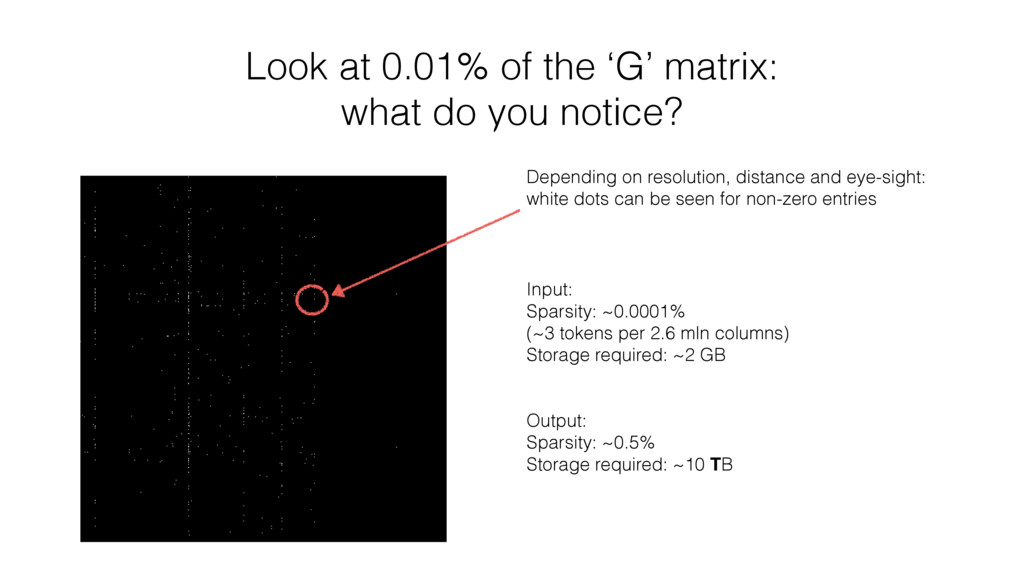
notice? Input: Sparsity: ~0.0001% (~3 tokens per 2.6 mln columns) Storage required: ~2 GB Output: Sparsity: ~0.5% Storage required: ~10 TB Depending on resolution, distance and eye-sight: white dots can be seen for non-zero entries
C++ knowledge Current custom kernel works with Sparse Matrix x Dense Vector (slice = 1) Didn’t distribute the data across the GPU up-front Using single GPU at the moment …so, in short, further optimizations are possible! Using 1 GPU, slice of 1 and Sparse x Dense multiplication: ~50 matches per second
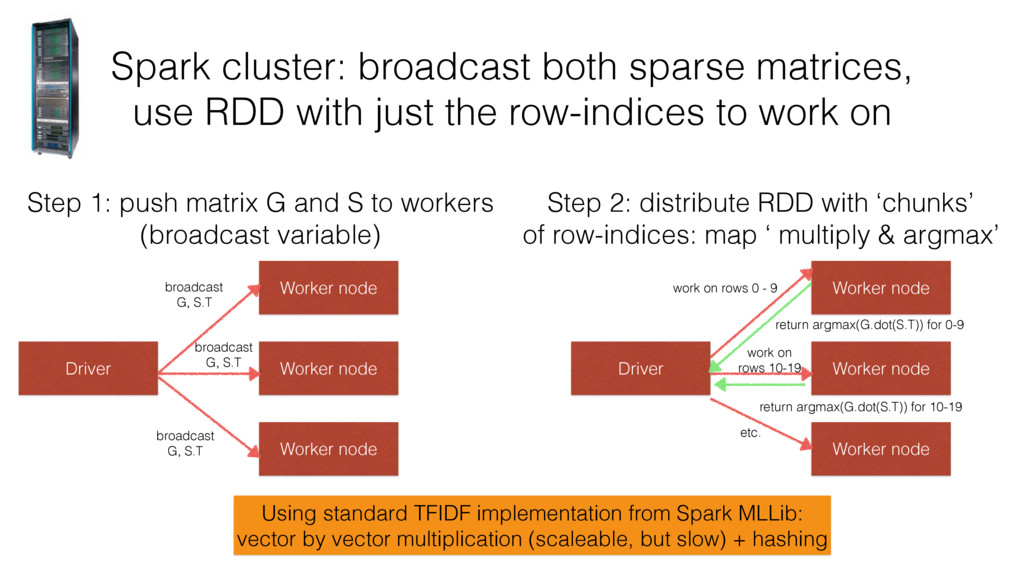
the row-indices to work on Driver Step 1: push matrix G and S to workers (broadcast variable) Worker node Worker node Worker node Step 2: distribute RDD with ‘chunks’ of row-indices: map ‘ multiply & argmax’ broadcast G, S.T broadcast G, S.T broadcast G, S.T Driver Worker node Worker node Worker node work on rows 0 - 9 return argmax(G.dot(S.T)) for 0-9 work on rows 10-19 return argmax(G.dot(S.T)) for 10-19 etc. Using standard TFIDF implementation from Spark MLLib: vector by vector multiplication (scaleable, but slow) + hashing
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}