from start-to-finish § Preprocessing: Pandas § Analysis: scikit-learn § Analysis: nltk § Data pipeline: MRjob § Visualization: matplotlib ¡ What next? ABOUT THIS TALK
processing, network analysis, visualization, scalability ¡ Community support ¡ “Easy” language to learn ¡ Both a scripting and production-ready language WHY PYTHON?
§ Not “big data” but larger data ¡ Solution: MapReduce! § Processing large datasets with a parallel, distributed algorithm § Map step § Reduce step PROCESSING LARGE DATA
break line into words, return word and count within line ¡ Reduce step § Once for each unique key: iterates through values associated with that key § Ex. Word counts: returns word and sum of all counts PROCESSING LARGE DATA
Hadoop ¡ Lots of thorough documentation ¡ A few things to know § Keep everything in one class § MRJob program in a separate file § Output to new file if doing something like word counts MRJOB
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
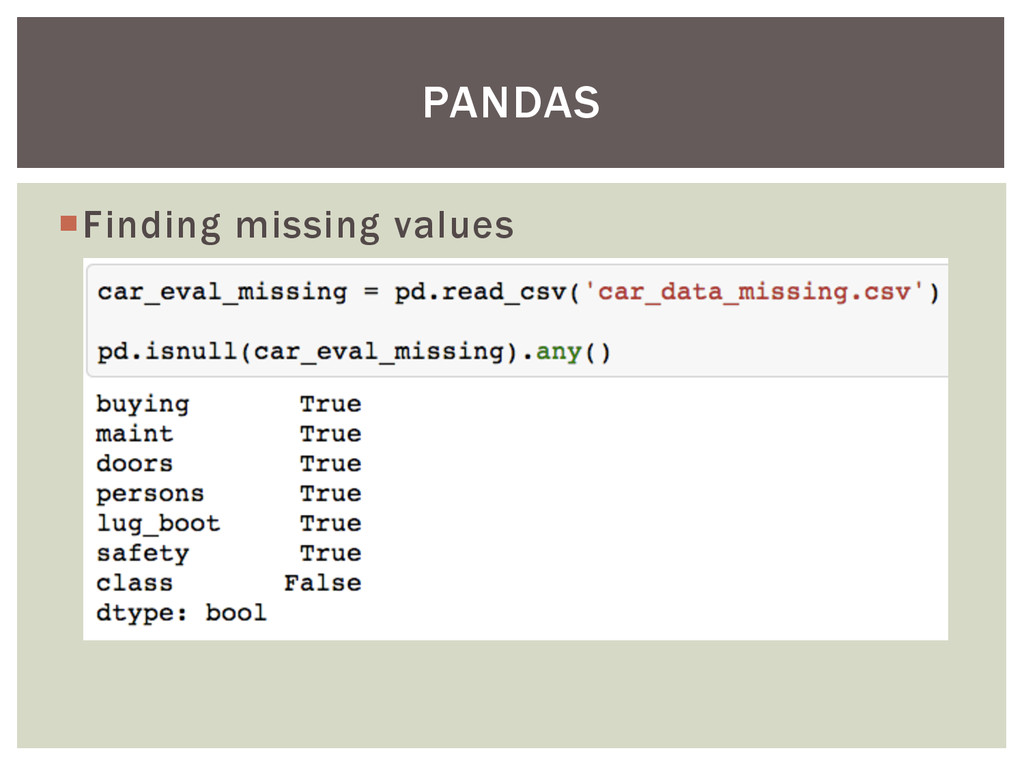{kind=link}
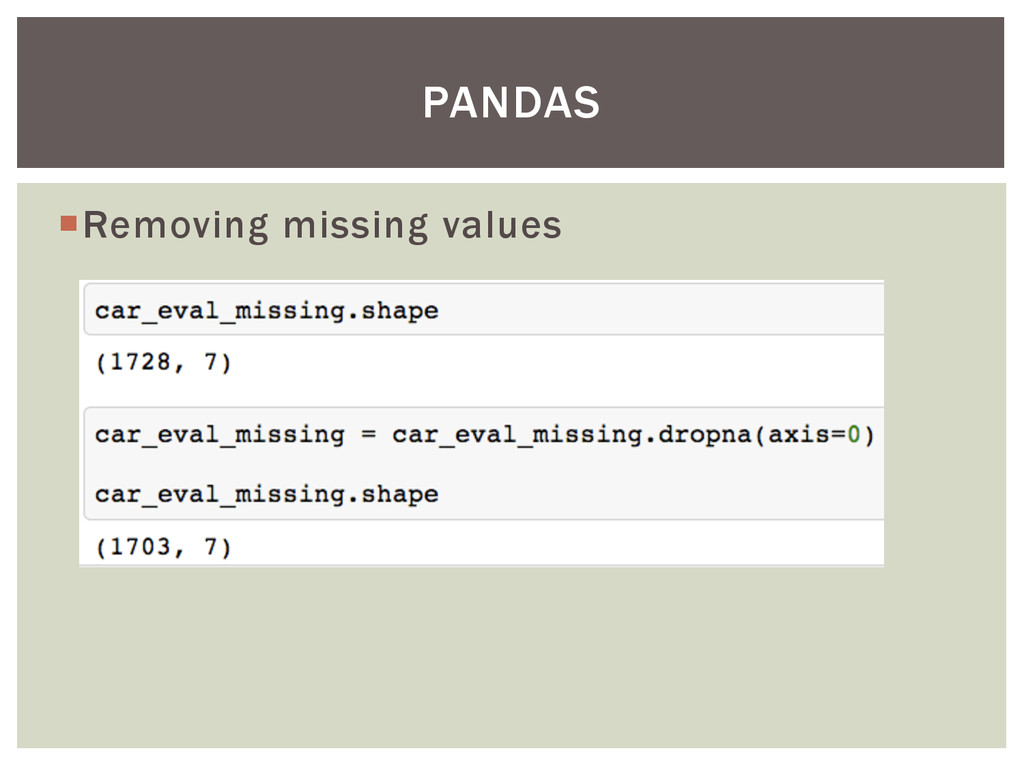{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
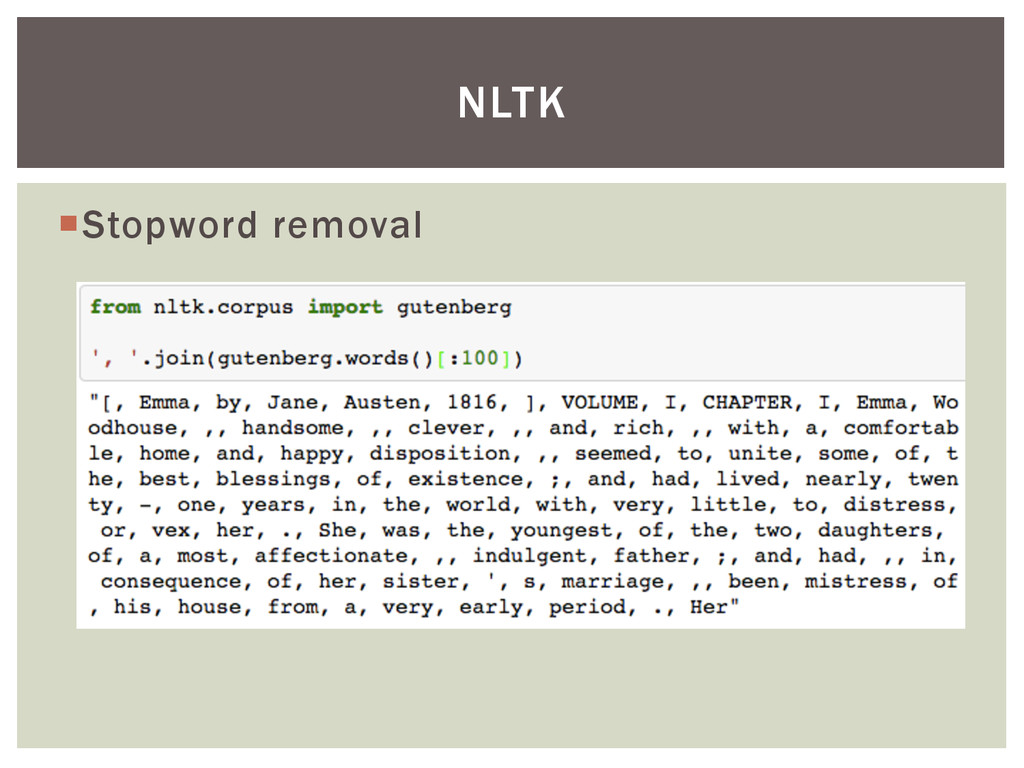{kind=link}
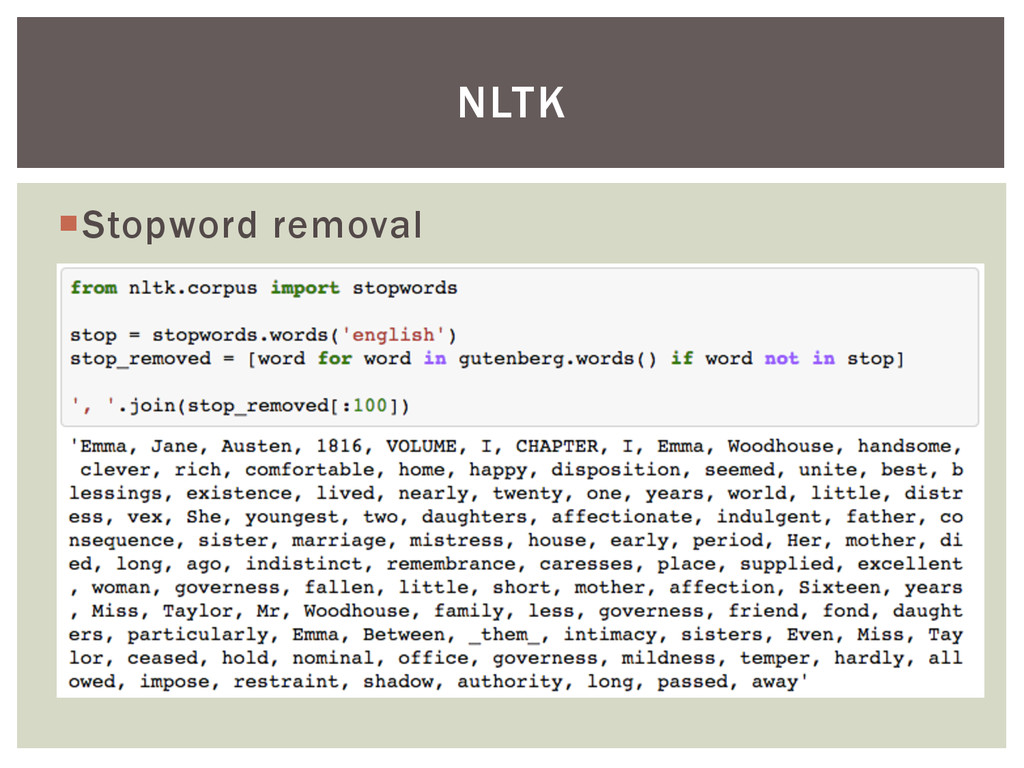{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}