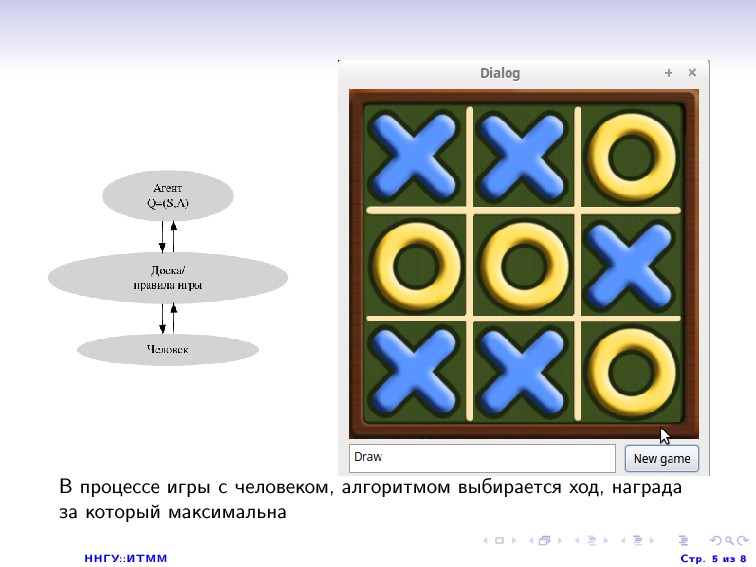
Q[s, a] = RND // 0..1 ob: Observe (Наблюдение): s’ = s // Запомнить предыдущие состояния a’ = a // Запомнить предыдущие действия s = FROM_SENSOR // Получить текущие состояния с сенсора r = FROM_SENSOR // Получить вознаграждение за предыдущее действие Update (Обновление ценности): Q[s’,a’] = Q[s’,a’] + LF * (r + DF * MAX(Q,s) — Q[s’,a’]) // LF — это фактор обучения. Чем он выше, // тем сильнее агент доверяет новой информации. // DF — это фактор дисконтирования. Чем он меньше, // тем меньше агент задумывается о выгоде от будущих своих действий. Decision (Выбор действия): a = ARGMAX(Q, s) TO_ACTIVATOR = a GO TO ob function MAX(Q,s) max = minValue for each a of ACTIONS(s) do if Q[s, a] > max then max = Q[s, a] return max function ARGMAX(Q,s) amax = First of ACTION(s) for each a of ACTION(s) do if Q[s, a] > Q[s, amax] then amax = a return amax ННГУ::ИТММ Стр. 3 из 8
{kind=link}
{kind=link}
{kind=link}
![= [(,)] = [1 , 2 , . . .](https://files.speakerdeck.com/presentations/df8b1edd2ac04e0cba086c2ee0608ee1/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}