Pangeo: A Community Driven Platform for Big Scientific Data Analytics on HPC and Cloud
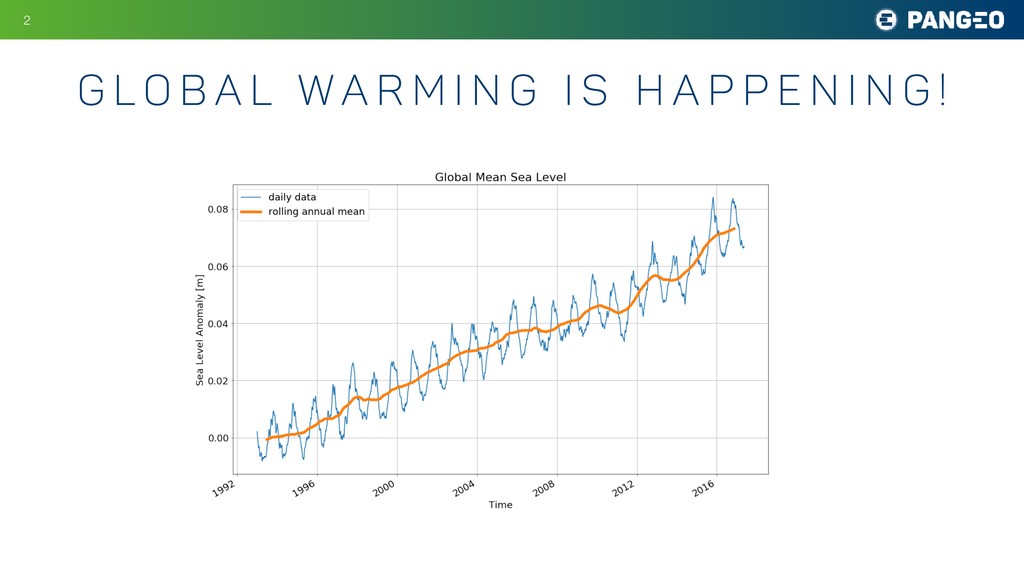
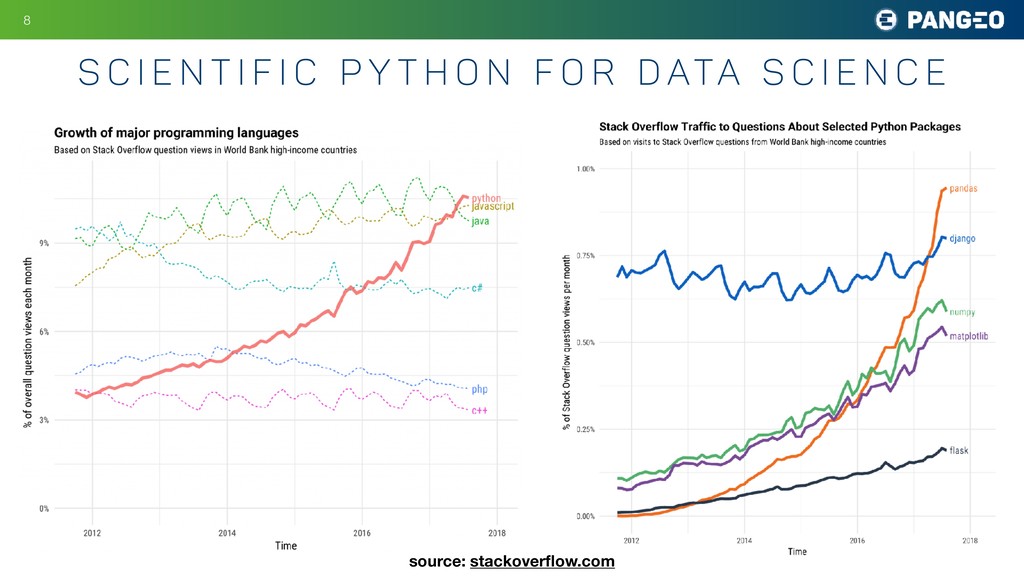
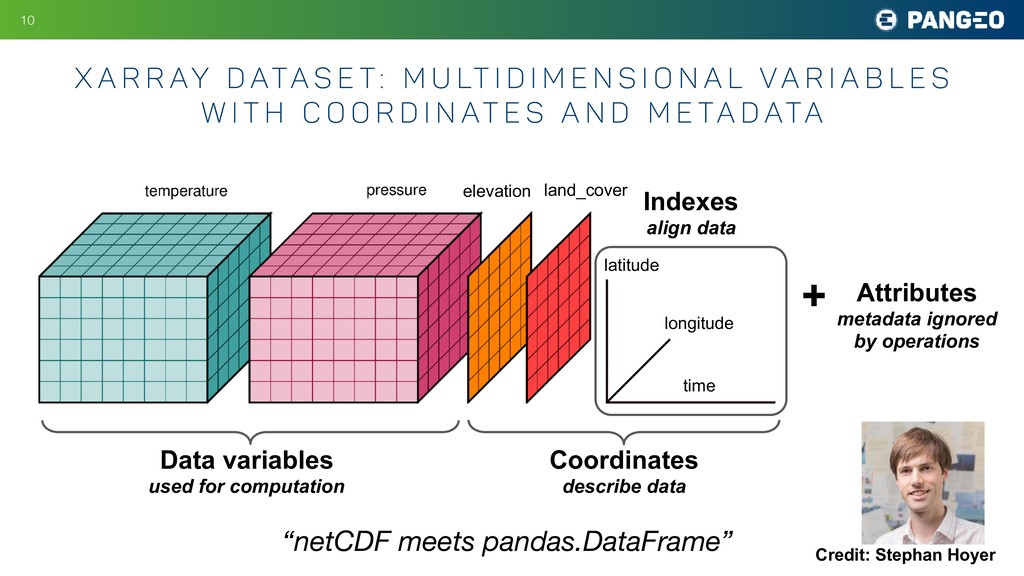
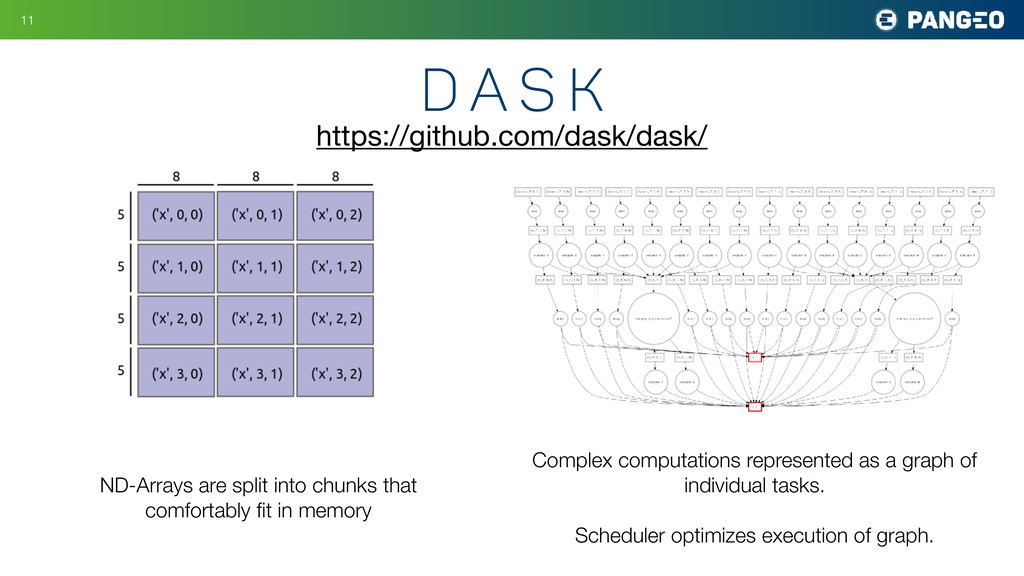
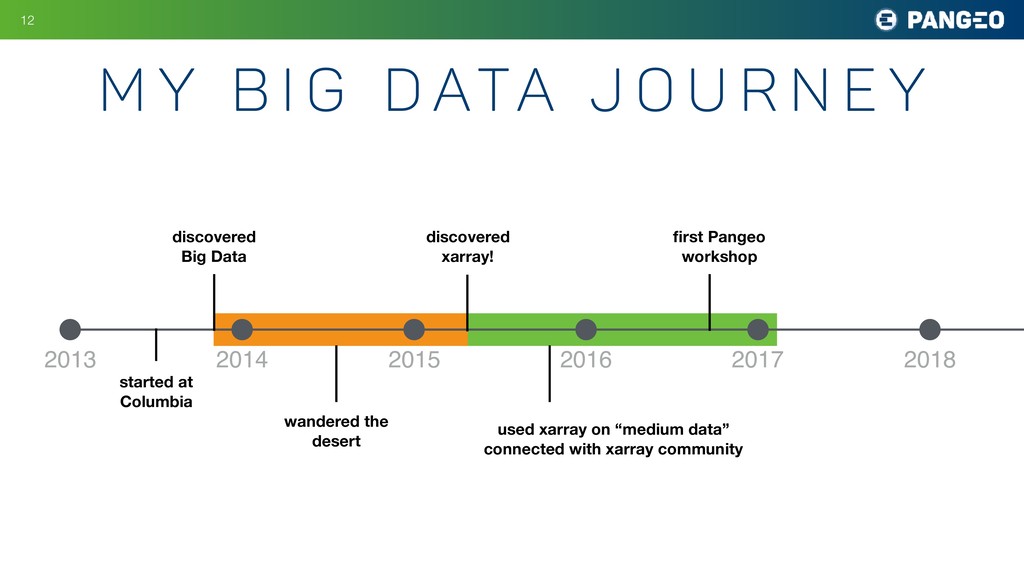
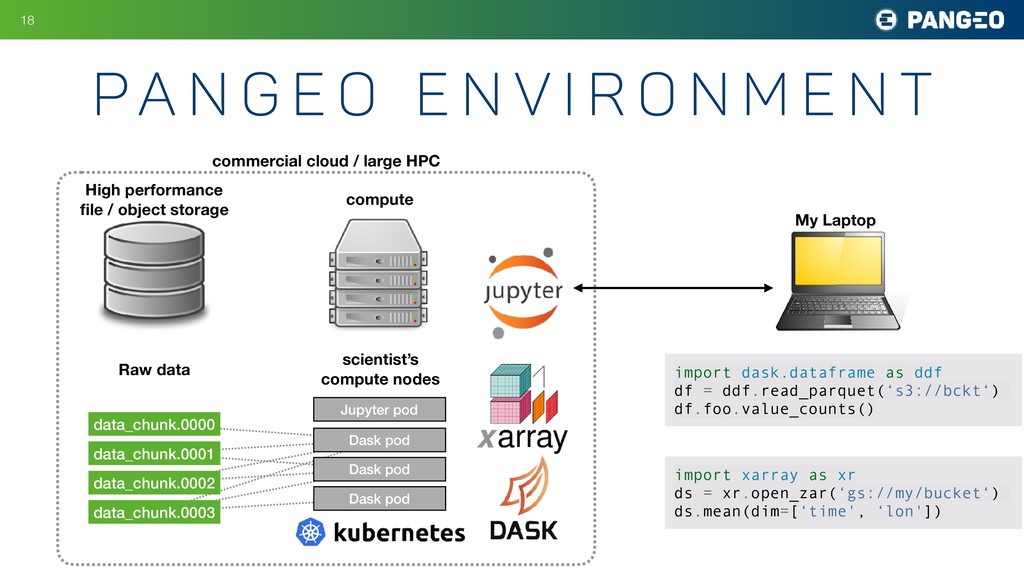
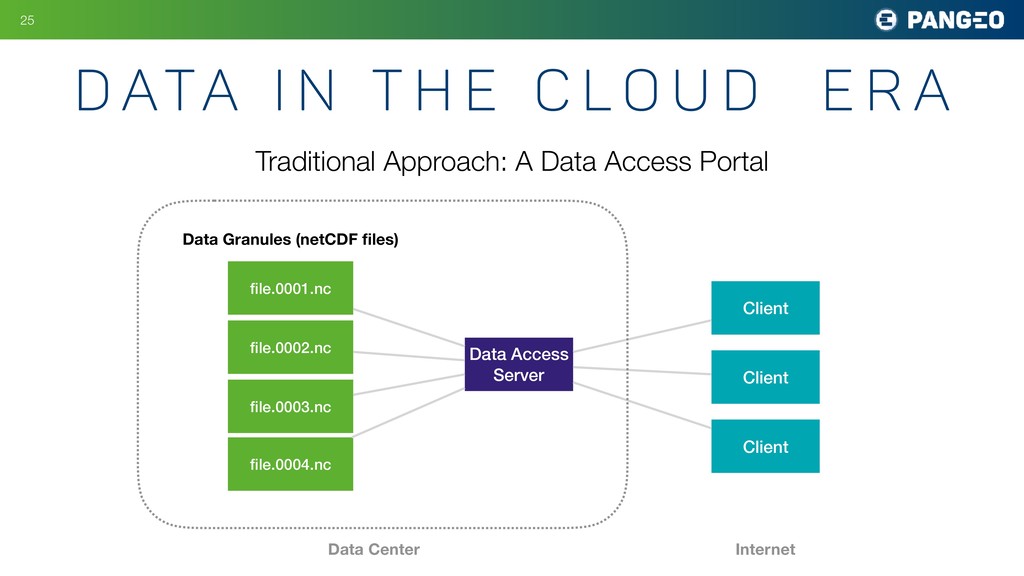
Many fields of science today involve large groups of scientists all studying a similar set of large, shared datasets. Astronomy is a prime example, as are atmospheric science, oceanography, neuroscience, and genomics. As these shared datasets grow into the petabyte range, traditional analysis tools are struggling to keep up, holding back the progress of research. A central goal of the Pangeo project is to meet this challenge by developing data and software infrastructure to enable interactive-speed analysis of the largest geoscience datasets. This is accomplished through the integration of existing open source scientific Python technologies within an HPC or cloud environment. The software packages include xarray, a Python package for working with labeled, multidimensional array data; Dask, a parallel computing library for Python that helps xarray represent huge datasets and distribute computations across clusters; JupyterHub and JupyterLab, computing environments that enable users to interact with cloud-based resources; and Kubernetes, a versatile, cloud-agnostic scheduler for running interactive and batch workloads. My talk will explain how these tools are being deployed used today in climate and oceanography and speculate about how they might be useful for other fields
http://blogs.cornell.edu/cloudforum/home/agenda/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}