Pretendo neste LT abordar um pouco do funcionamento do Framework Scrapy (http://scrapy.org/) e como começar a usá-lo. Esta LT é voltada a iniciantes. LT de 25 min a 30 min.
- Existem muitas bibliotecas em Python que podemos buscar - Existem muitas bibliotecas em Python que podemos buscar informações de páginas web informações de páginas web - Cuidado! Nem todas são perfeitas para o que você precisa - Cuidado! Nem todas são perfeitas para o que você precisa fazer! fazer! - Evitar ao máximo usar REGEX para buscar informações em - Evitar ao máximo usar REGEX para buscar informações em páginas web páginas web - Ter a consciência que as páginas web mudam constantemente - Ter a consciência que as páginas web mudam constantemente
(Query Language) para selecionar nós de um documento XML. Ademais, XPath pode ser usada para computar valores (por exemplo, strings, números ou valores booleanos) do conteúdo de um documento XML. XPath foi definido pelo World Wide Web Consortium (W3C).” Fonte Wikipédia, a enciclopédia livre. XPath XPath
elements in a tree, and as such form one of several technologies that can be used to select nodes in an XML document. Selectors have been optimized for use with HTML and XML, and are designed to be usable in performance-critical code.” From W3C
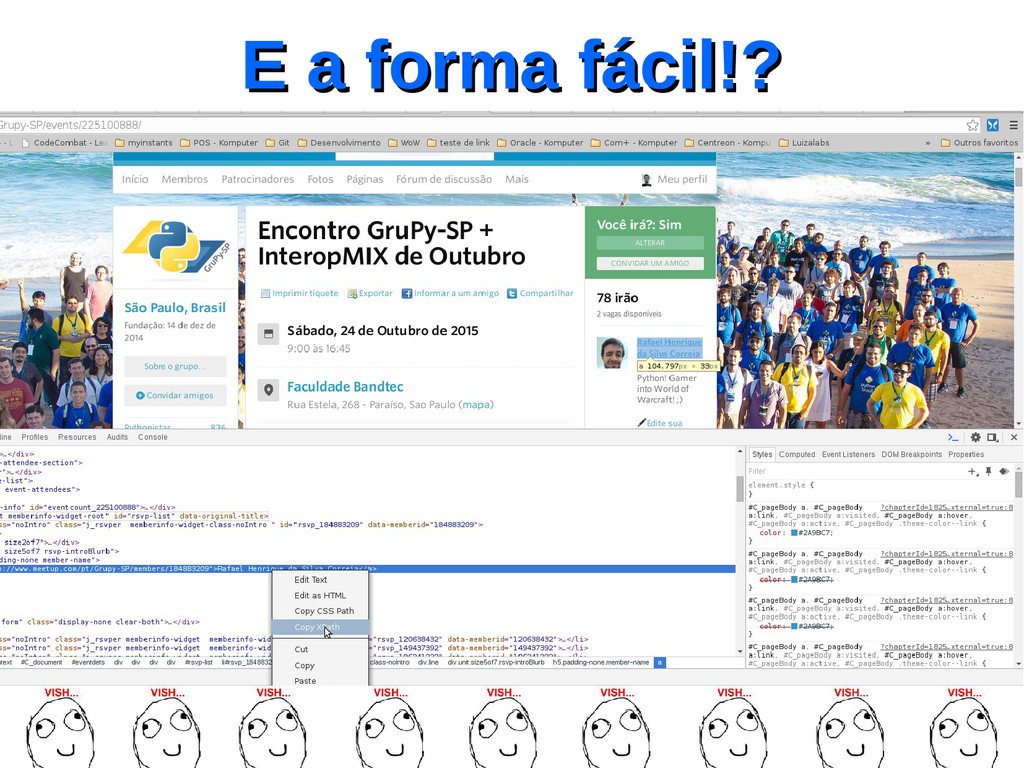
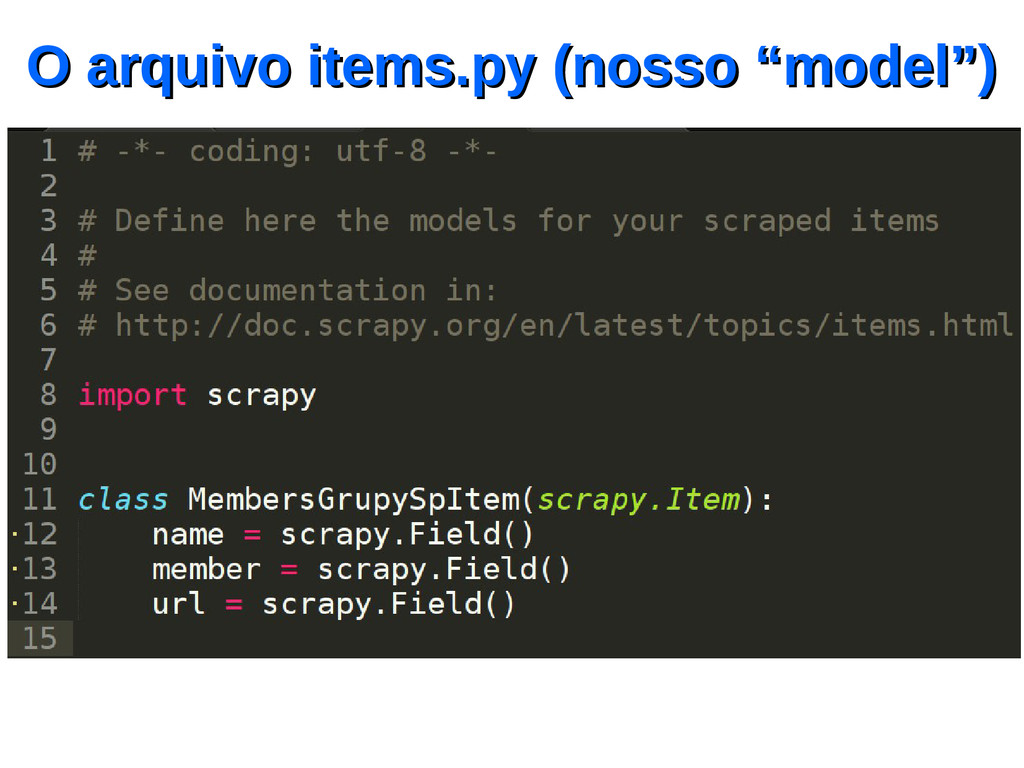
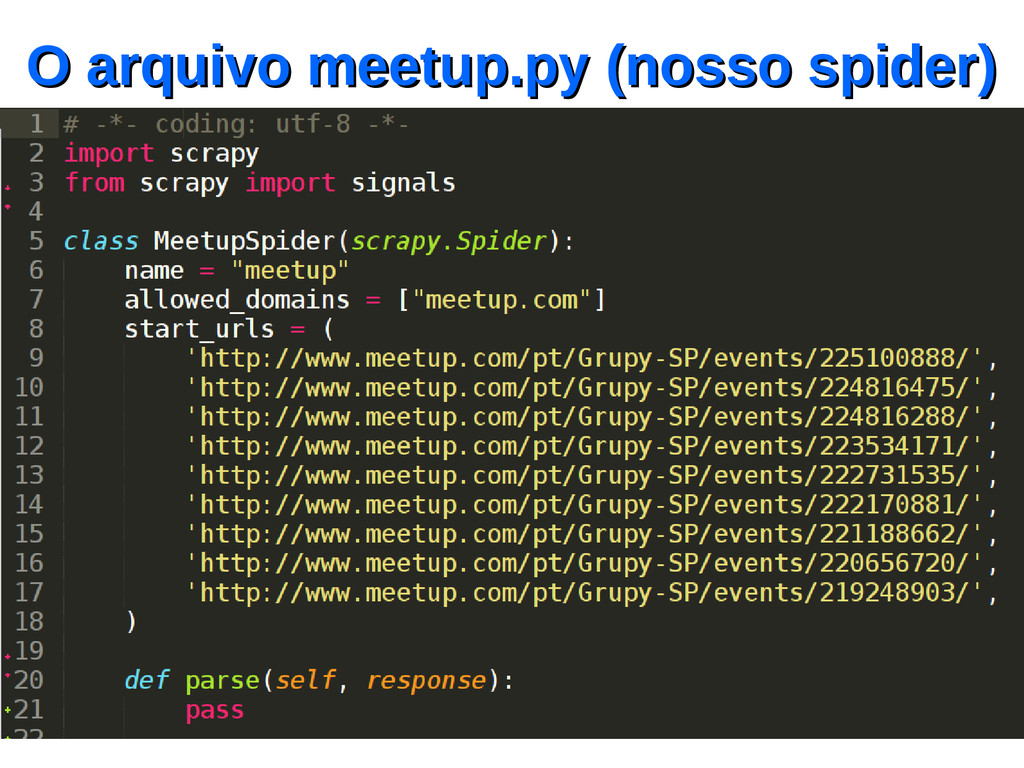
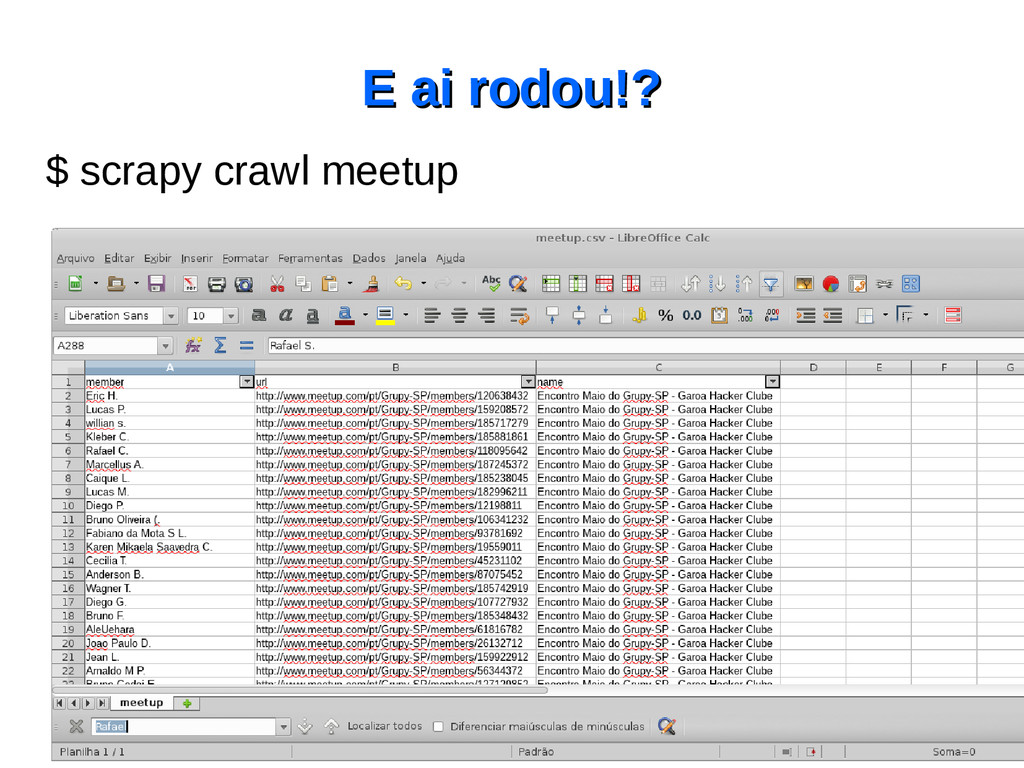
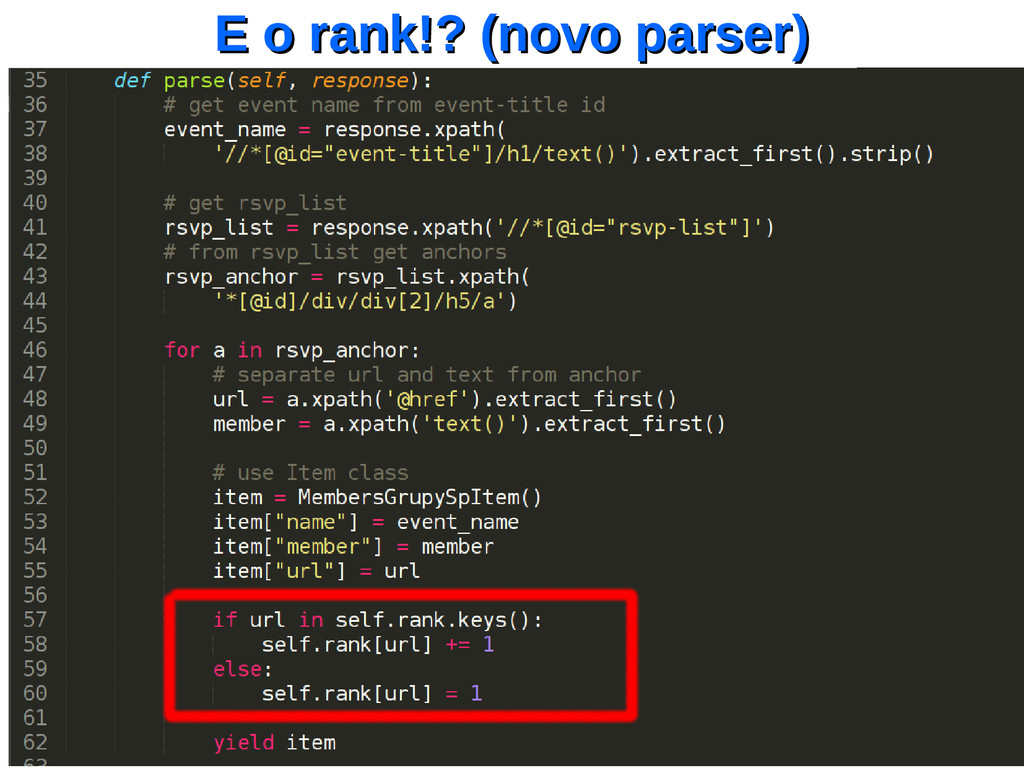
um projeto…. Então vamos lá! Vou criar um projeto para descobrir qual é o cara que mais marcou presença no GruPy-SP (que marcou como RSVP) utilizando TODOS os eventos que foram criados no Meetup.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}