Cyber-attacks against cloud-native infrastructure are increasing in frequency and sophistication. The complexity of modern cloud-native systems and the speed at which technology is developing have outpaced cloud security solutions. On the flip side, cyber-criminals are taking advantage of these developments to launch successful cloud attacks. This session delves into the paradigm of Zero Trust Chaos Experiments, exploring how intentional disruptions and simulated cyber threats can uncover vulnerabilities and enhance cyber resilience. Through practical insights, we will illustrate the transformative impact of Zero Trust Chaos Experiments on organizations' ability to detect and mitigate cyber incidents. By the end of the session, participants will be equipped with actionable strategies and a better understanding of how Zero Trust Chaos Experiments can elevate cyber resilience in cloud-native environments
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
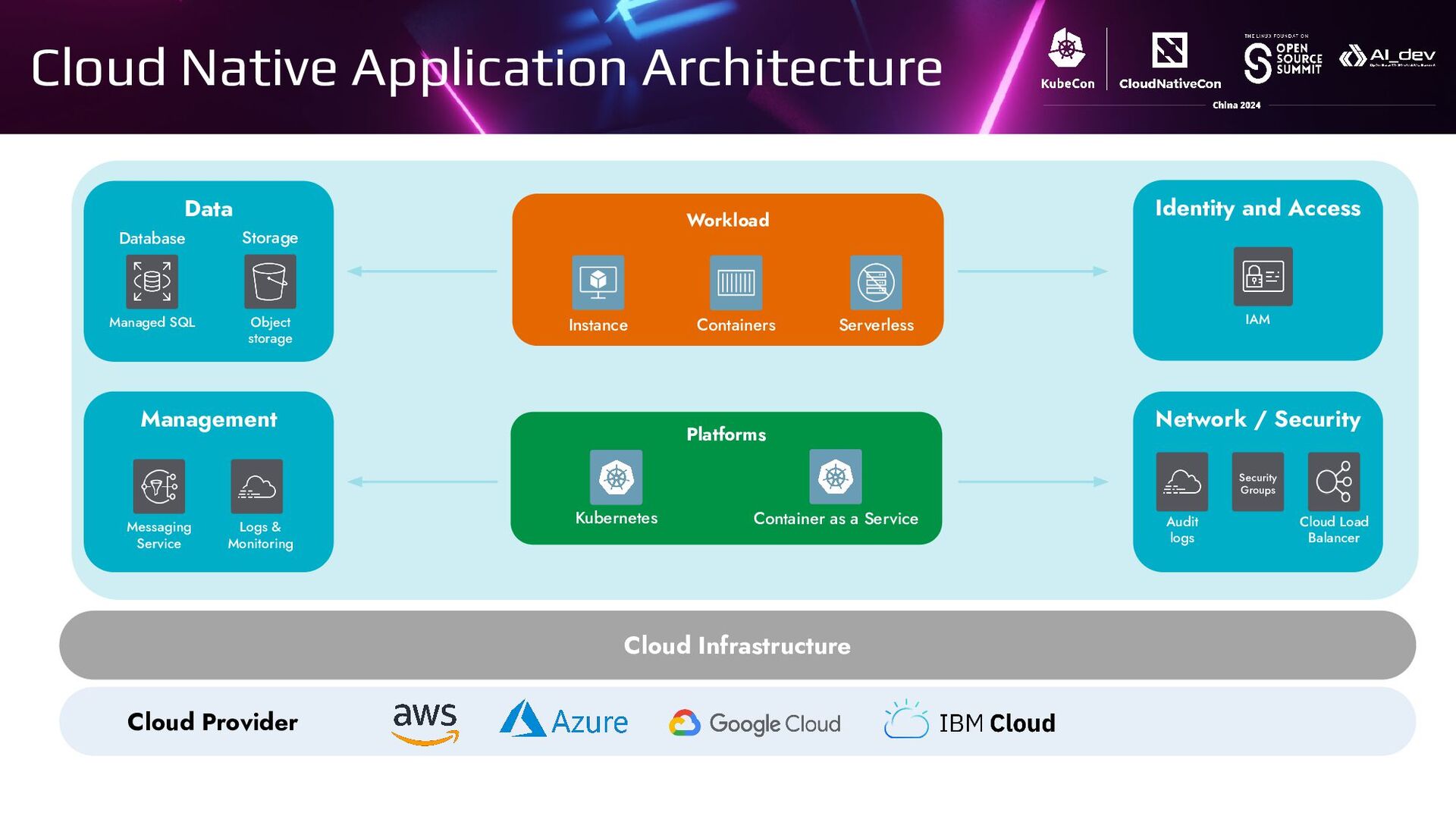{kind=link}
{kind=link}
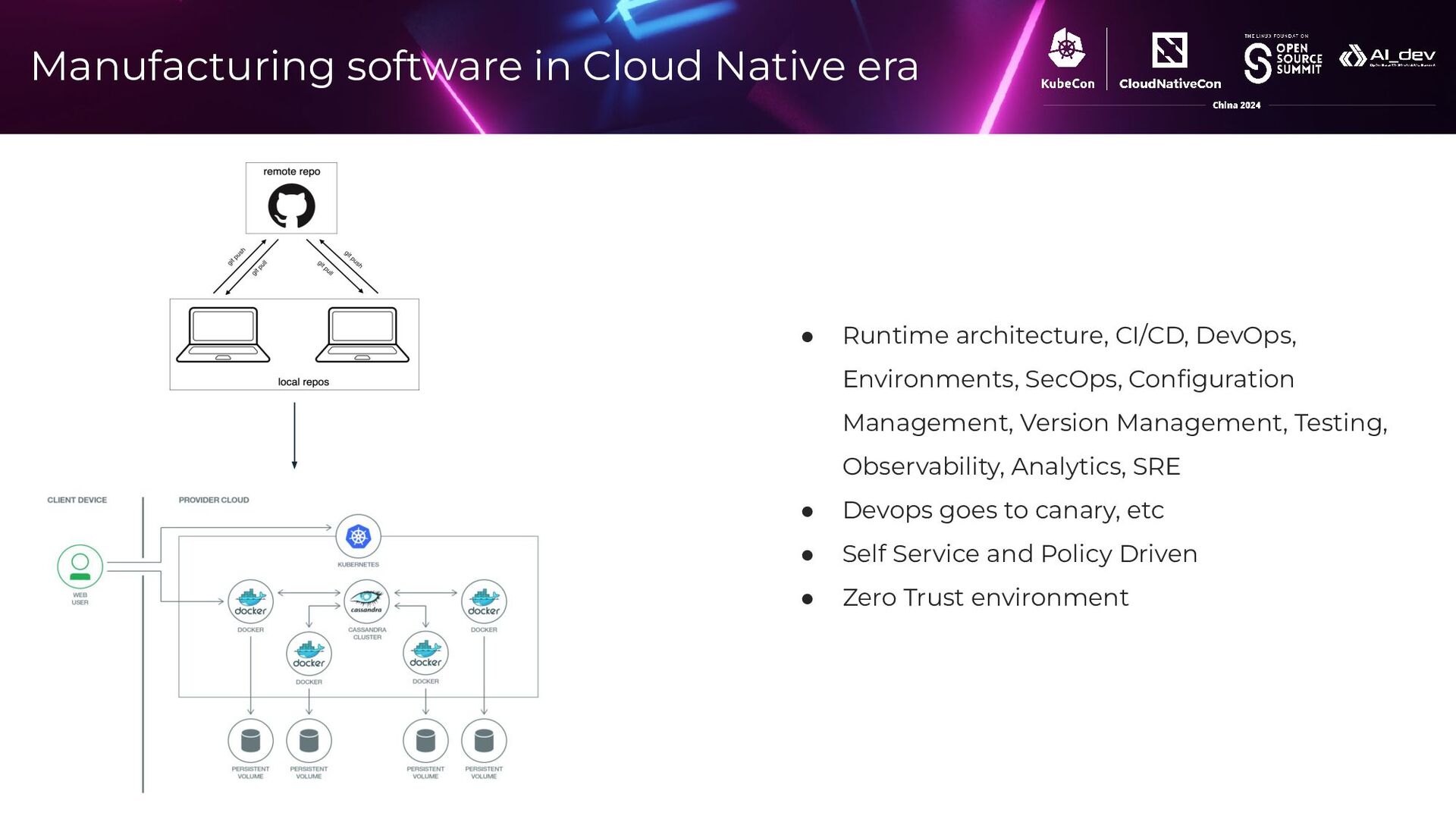{kind=link}
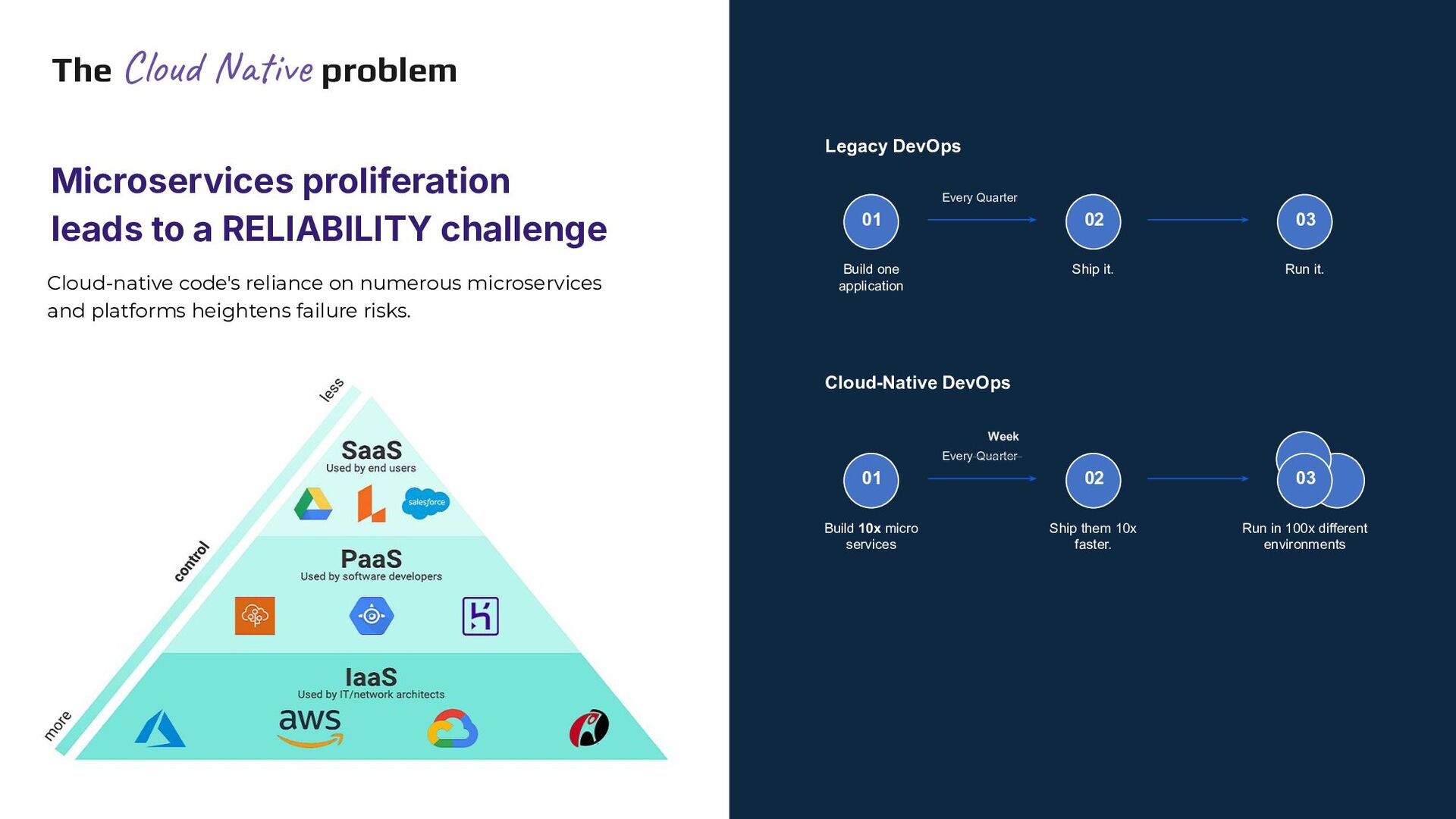{kind=link}
{kind=link}
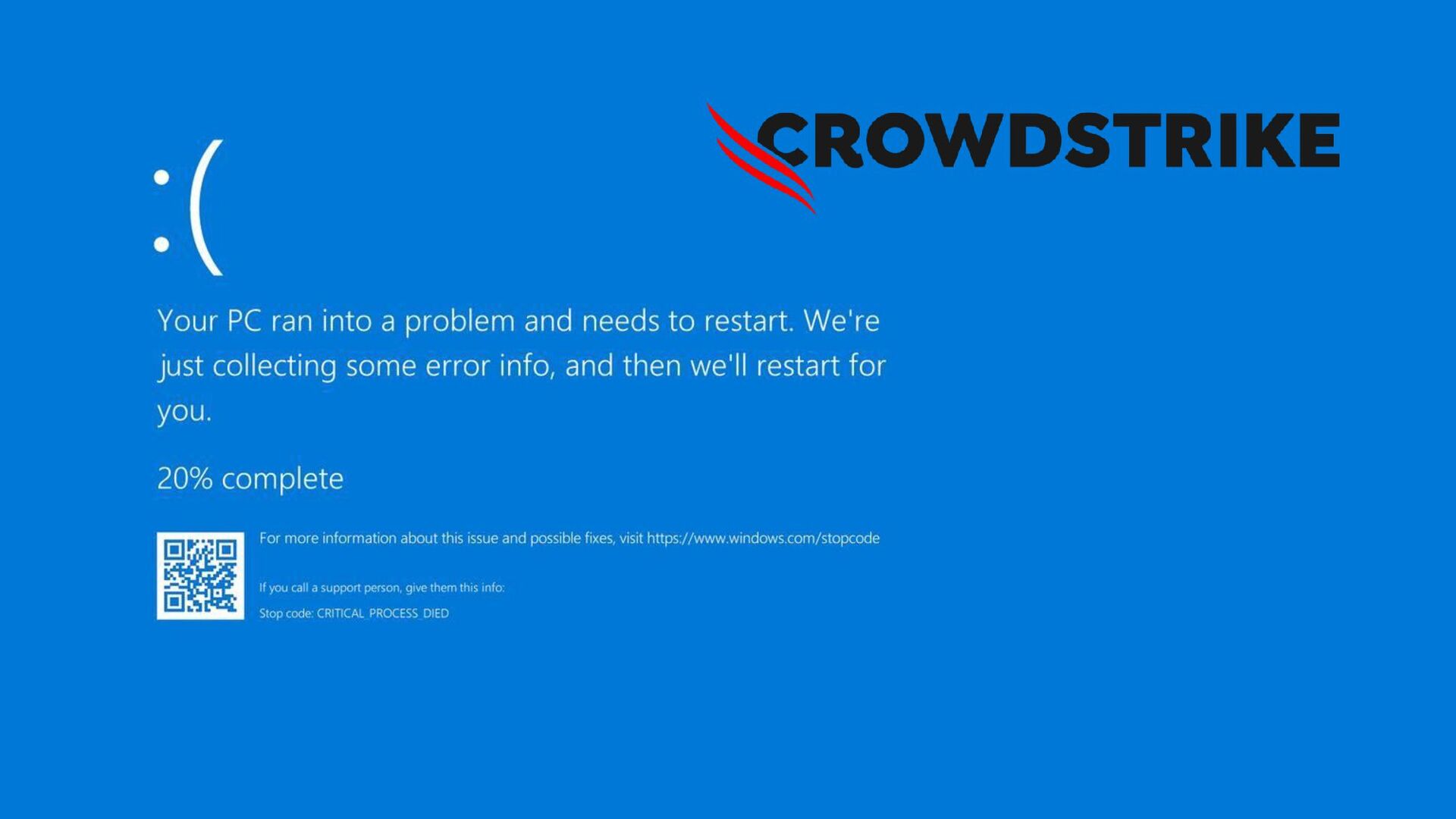{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
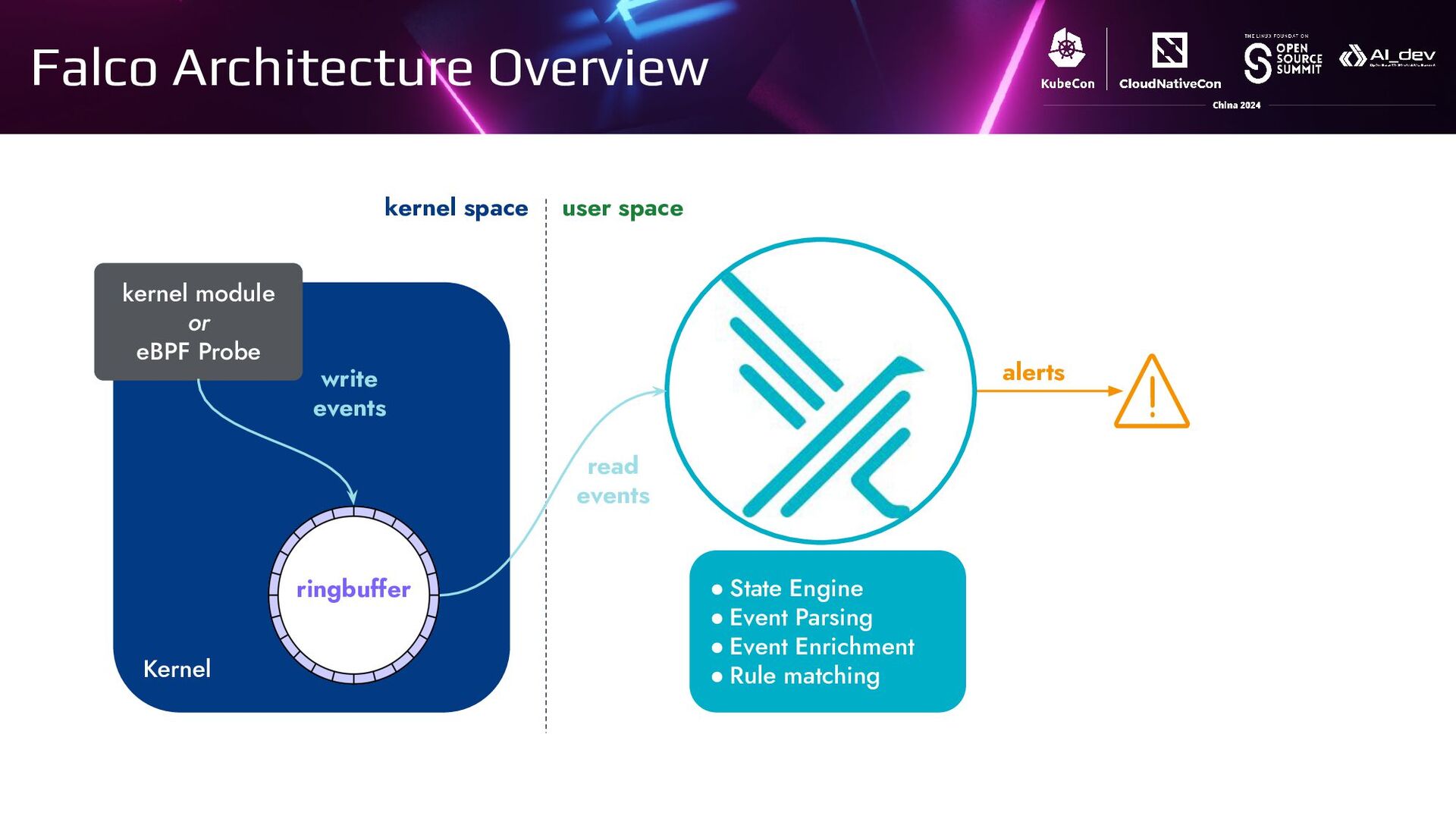{kind=link}
{kind=link}
{kind=link}
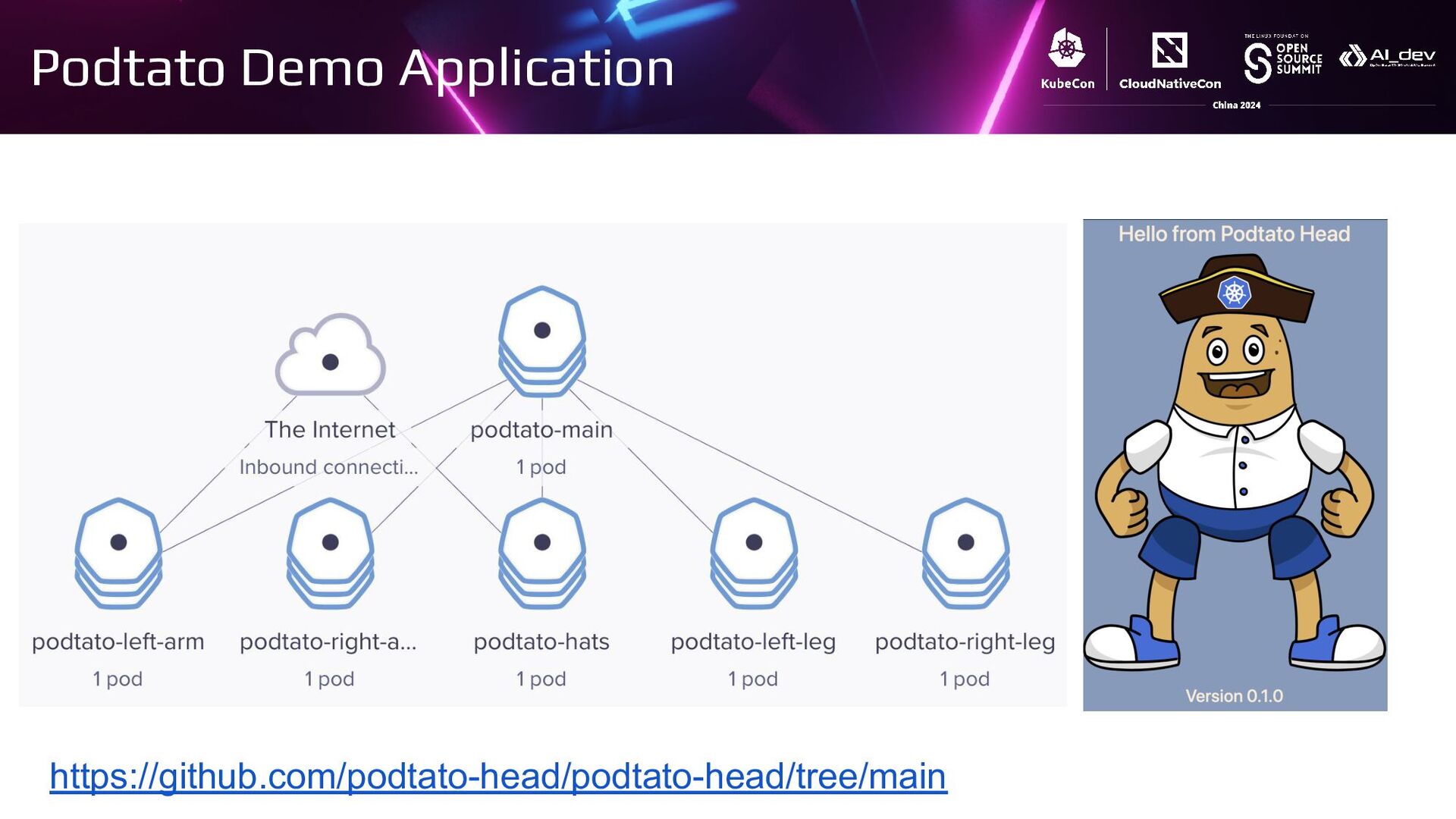{kind=link}
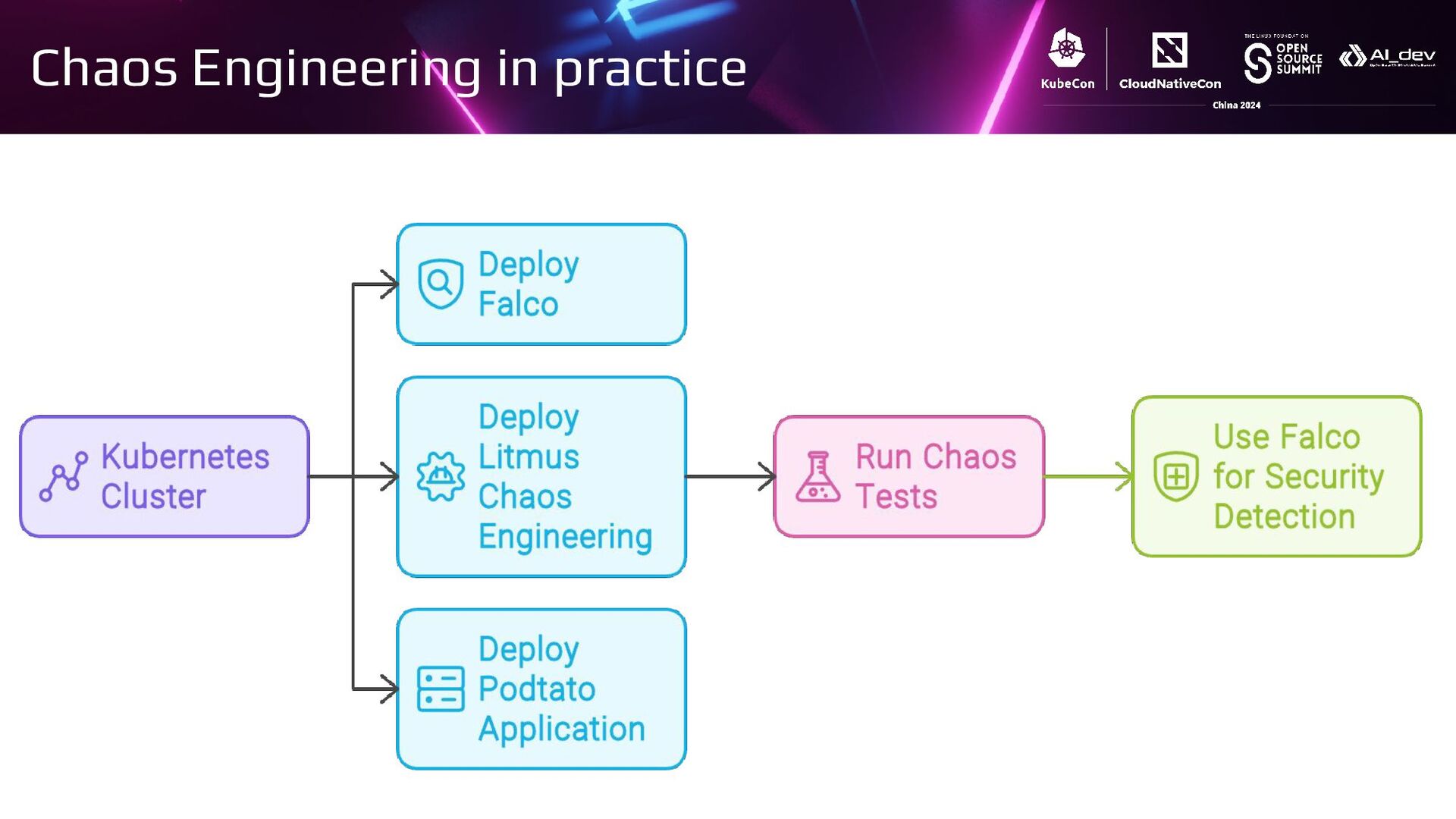{kind=link}
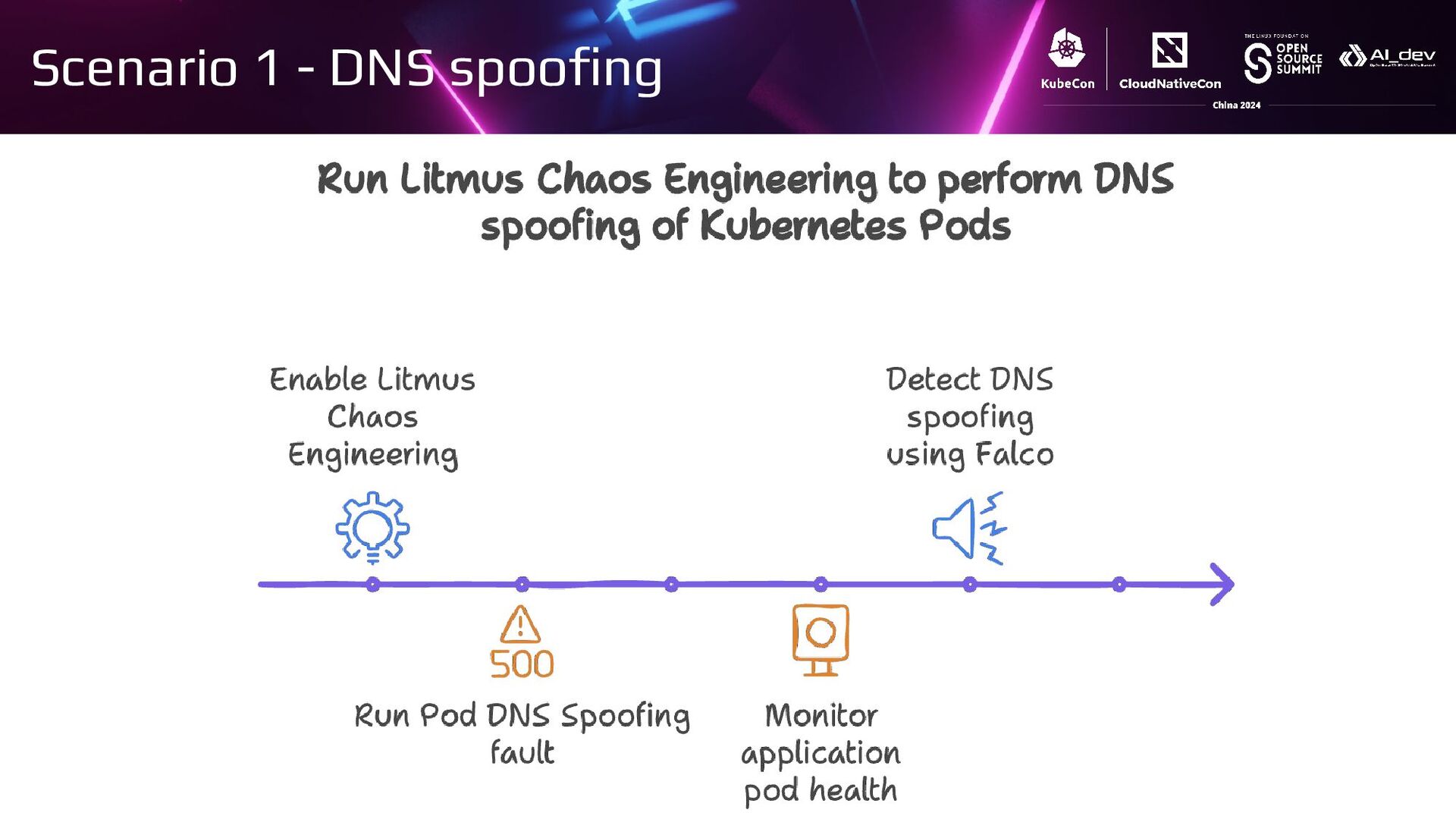{kind=link}
{kind=link}
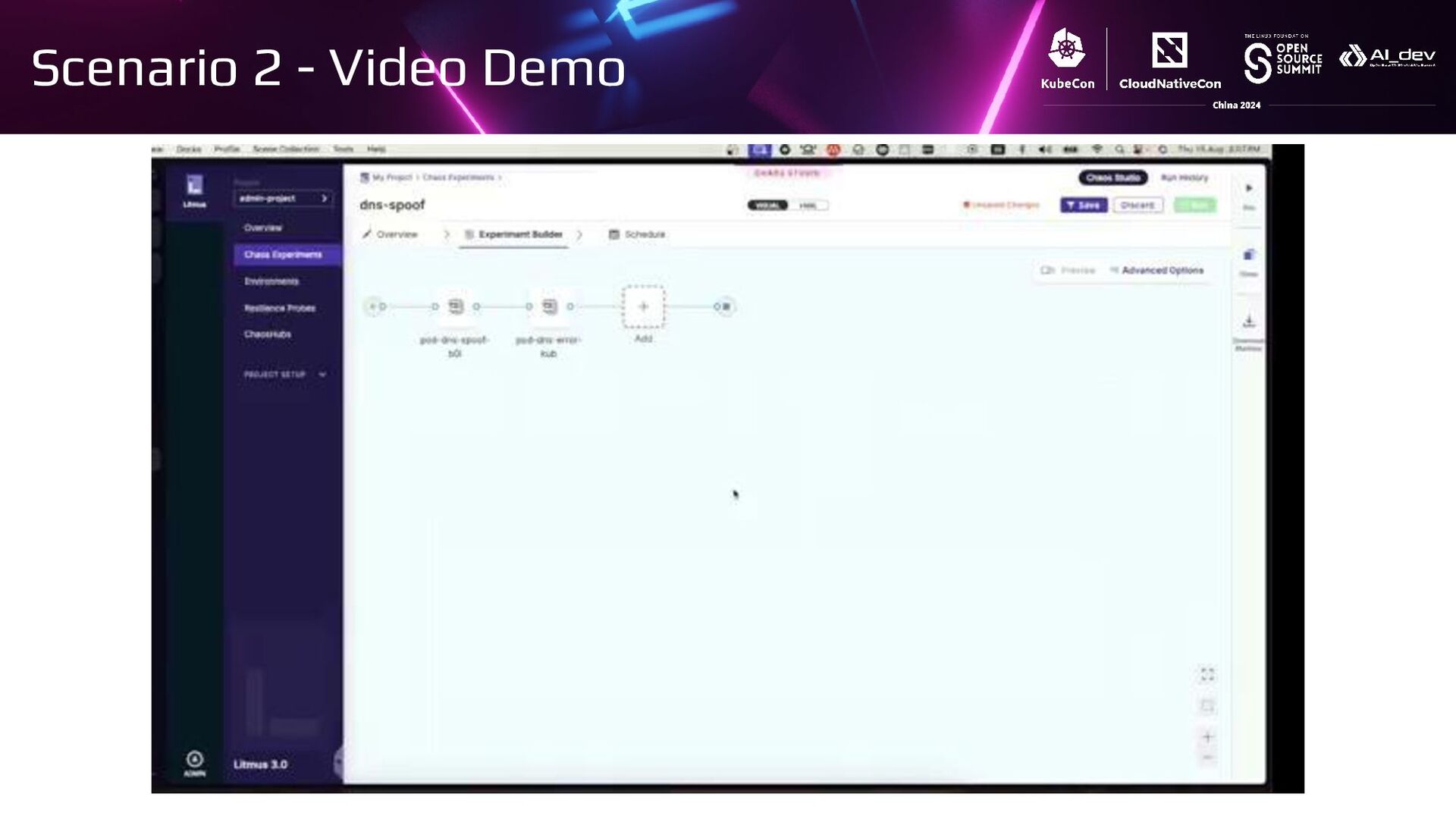{kind=link}
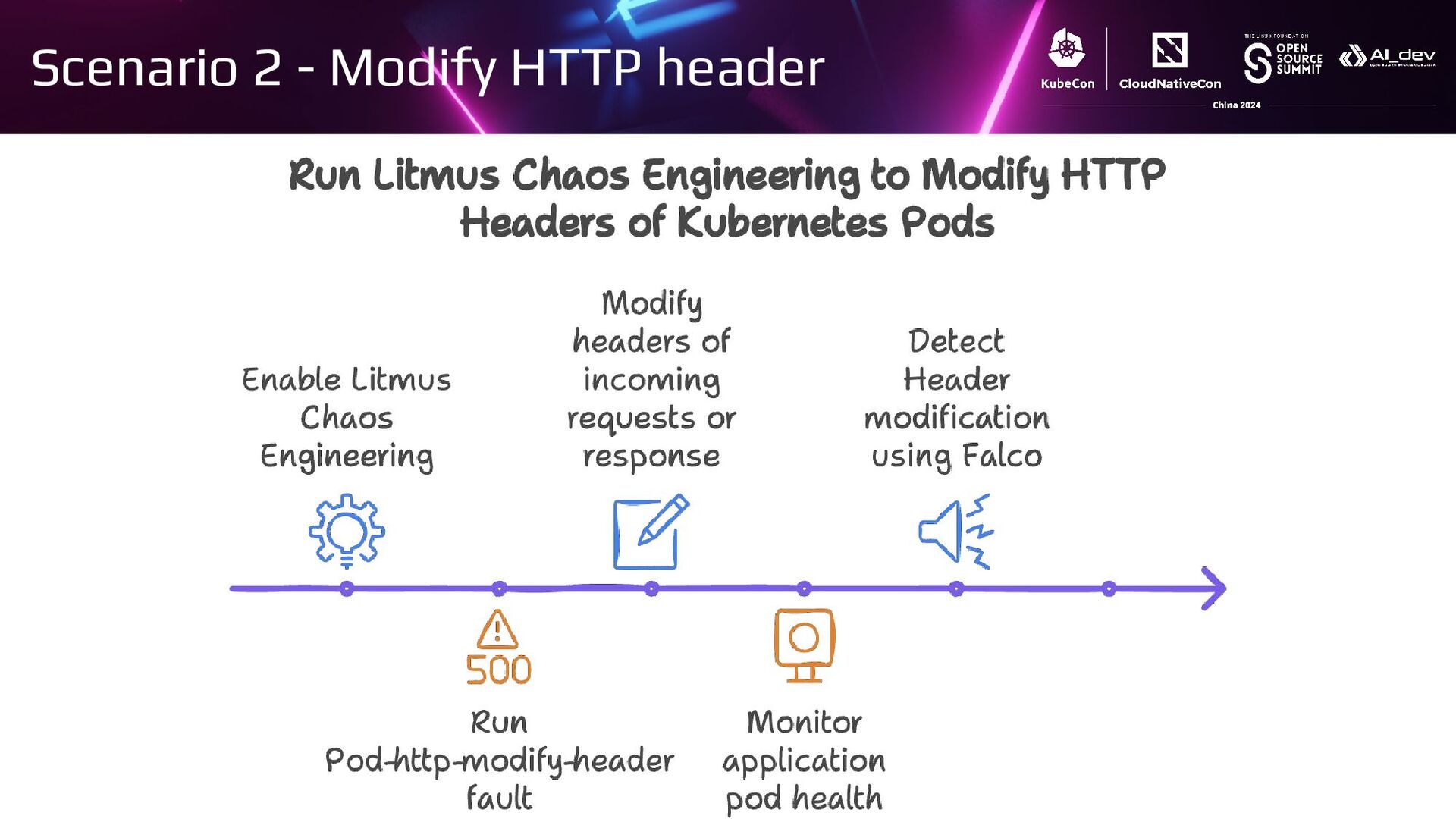{kind=link}
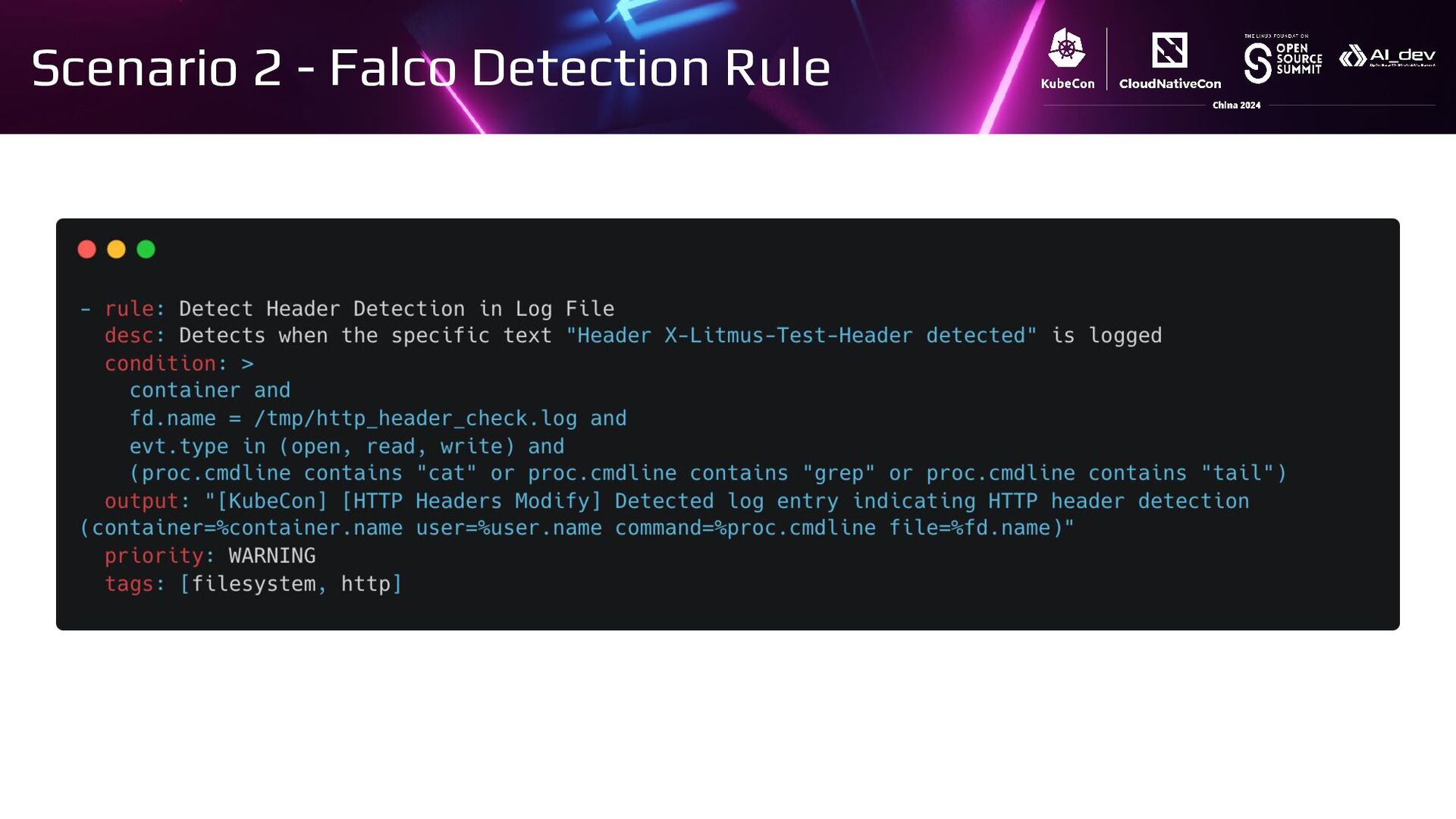{kind=link}
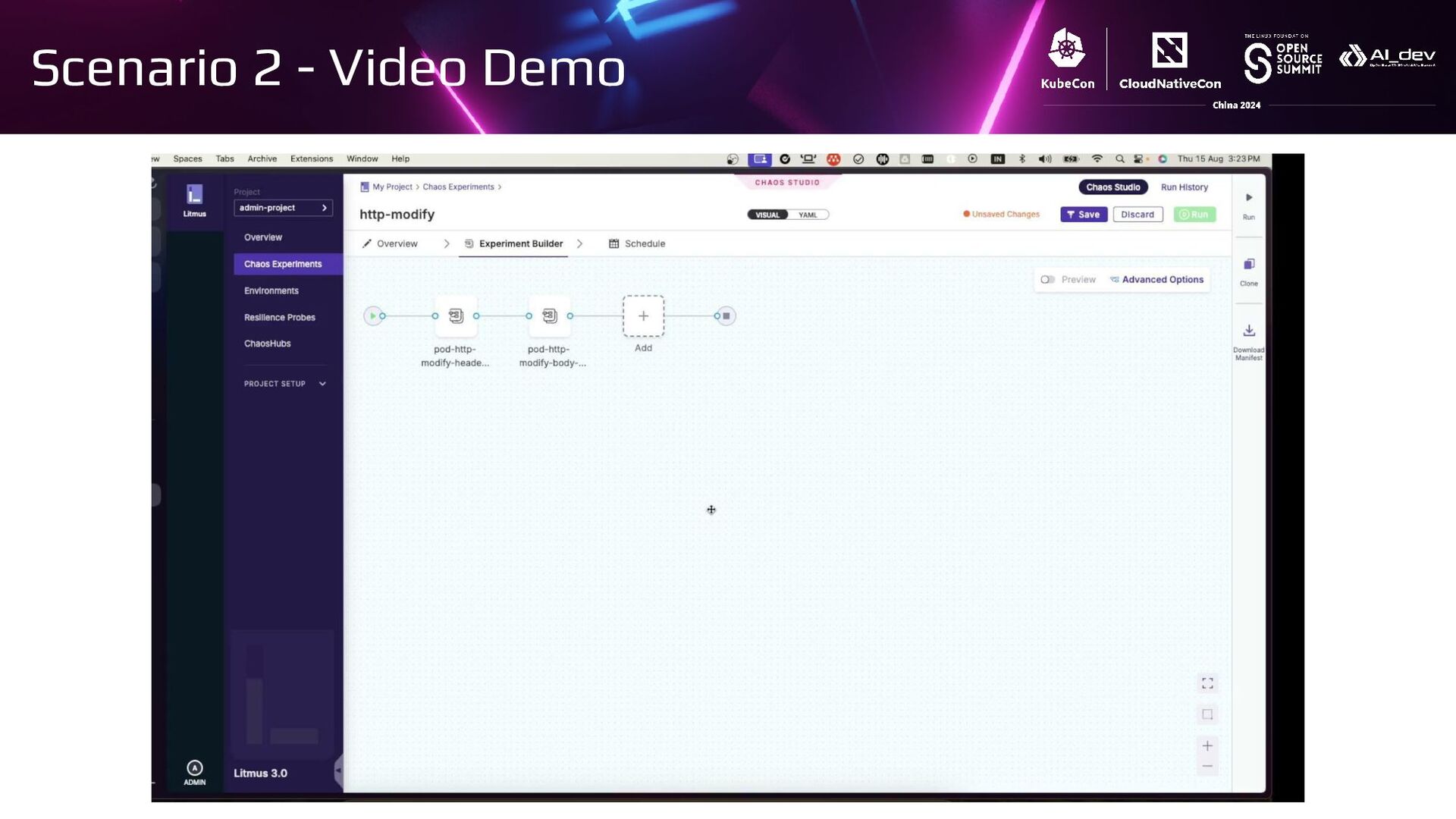{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}