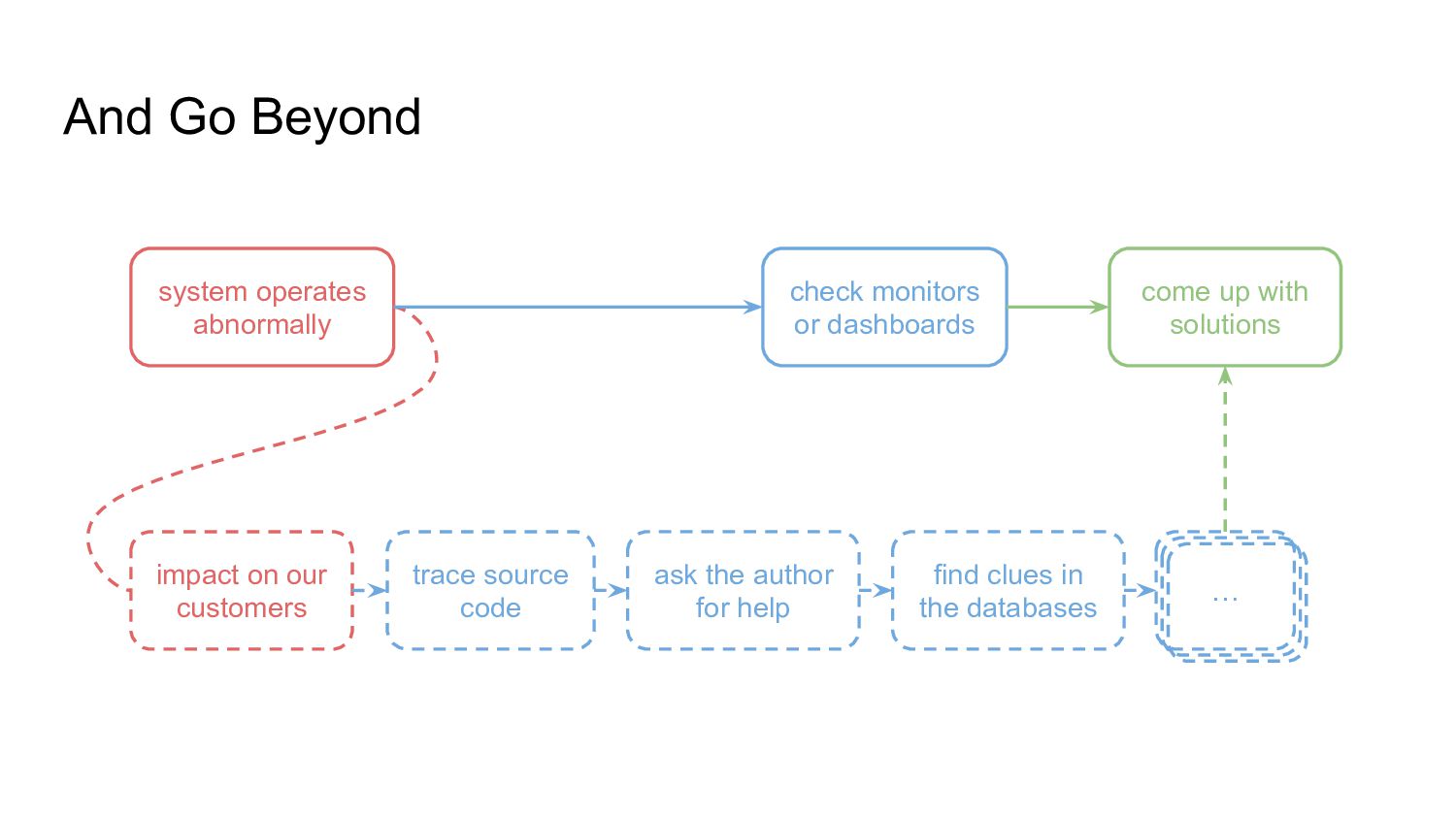
up as - Handle incoming operations - Given a series of operations - Track system status - Check attribute on specific checkpoints - Understand the system and act accordingly - Fix bugs, ready to release if it works well, …
up as - Handle incoming operations - Which is heavier and more uncertain - Track system status - With more organized and intuitive presentation - Understand the system and act accordingly - Identify performance bottlenecks, investigate doubtful requests, …
data point, often associated with alert trigger rules - System Level - CPU, RAM, disk, disk I/O, … - Programming Language Runtime - GC time average, #goroutines, … - Application Level - QPS/RPS, 5xx rate, response time, #connection, …
data point, often associated with event trigger rules - External Services - AWS Service liveness, Payment API latency, … - Business Logic Level - Video playback success rate (used by @Netflix) - Story post success rate (maybe for social networking services) - Advertisement push success rate (maybe for martech services)
- Does the app process killed by os due to out of memory? - Does the journey type campaigns work well currently? - What information should be logged? - Which processing stage will go wrong while a campaign is oversized? - Does a particular campaign to go wrong due to AWS SQS send message error? - What tasks should be traced? - Which database query is the critical performance bottleneck? - Does each dynamic content variable passed to the corresponding parser correctly?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
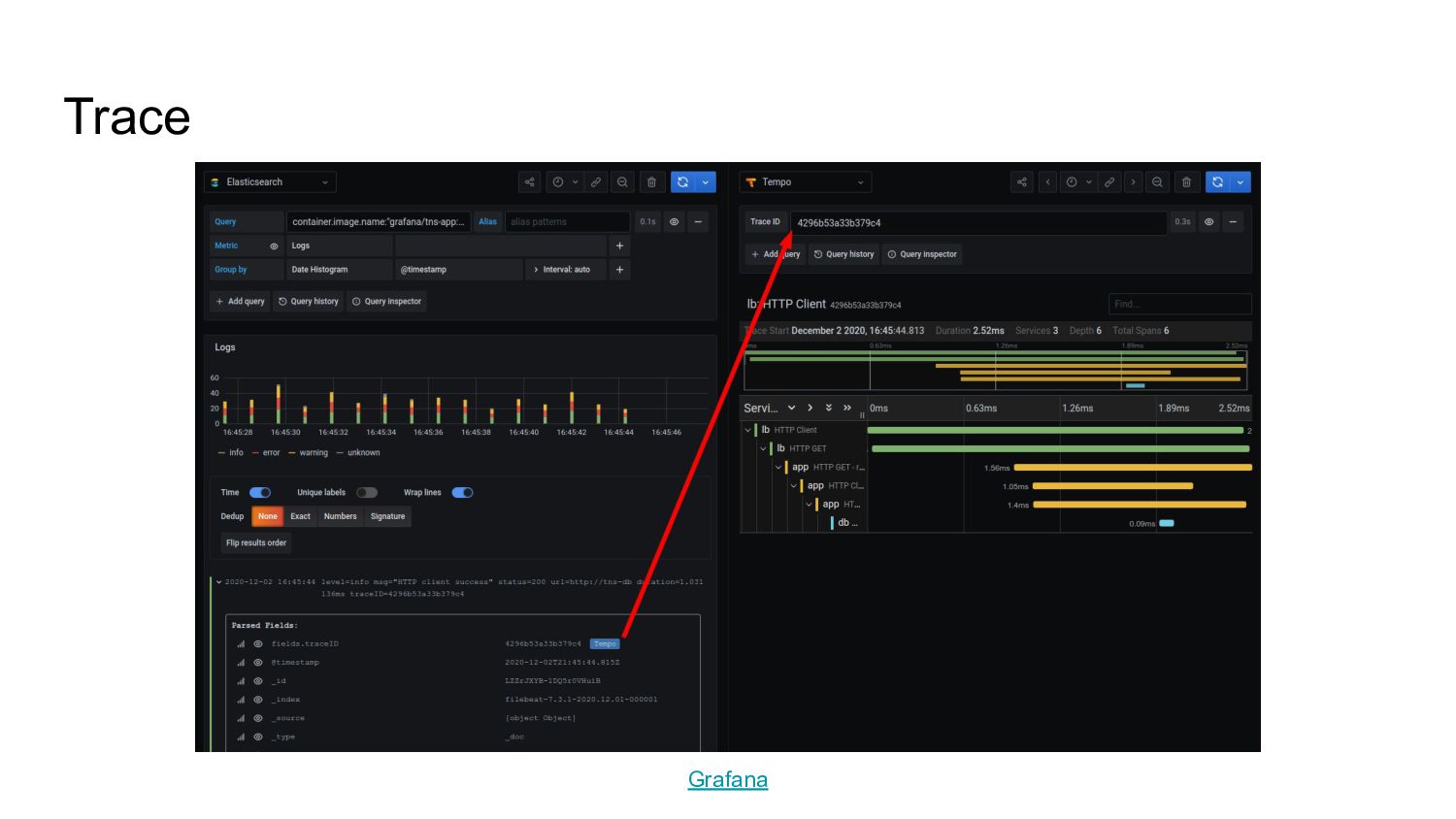{kind=link}
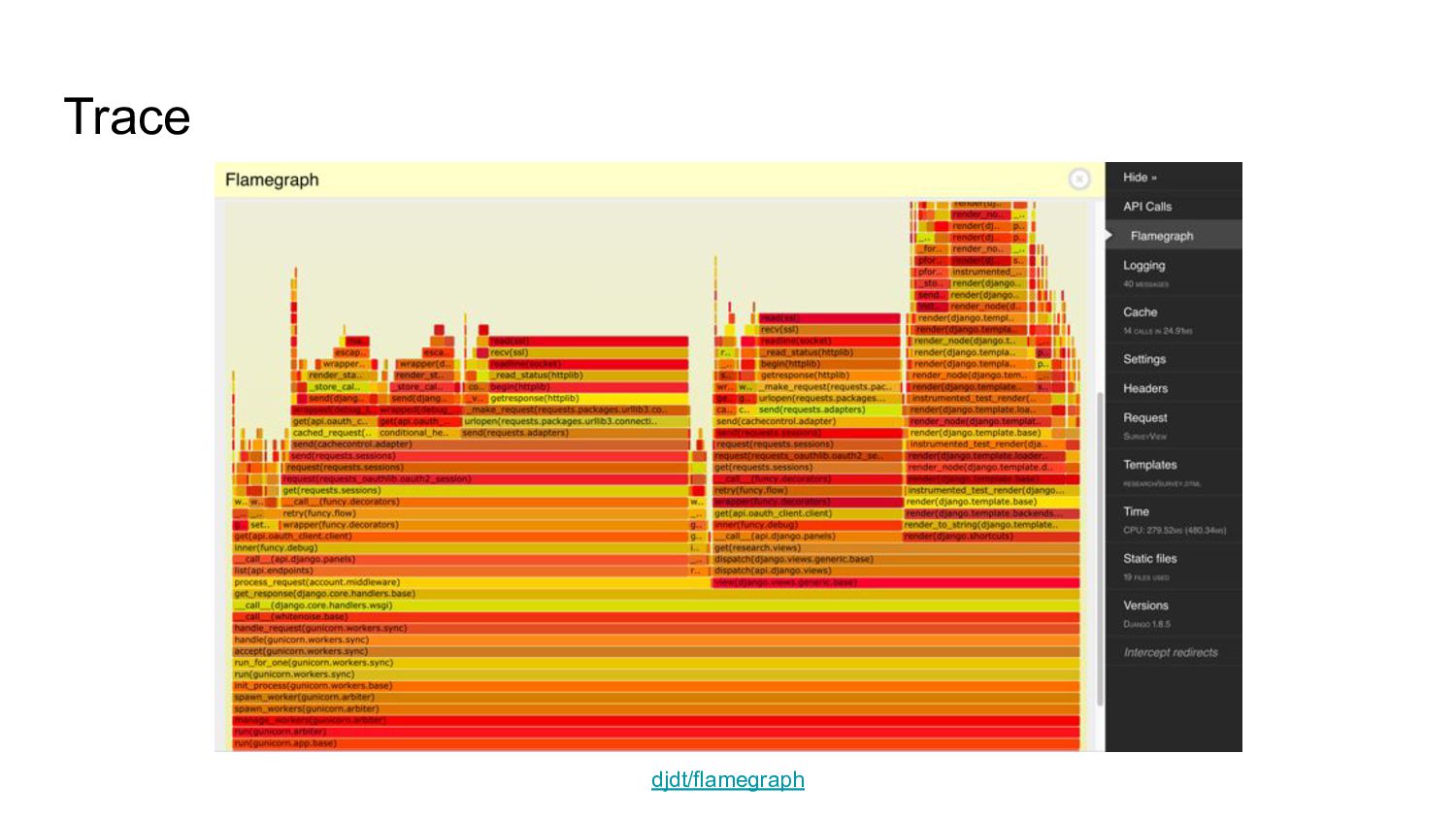{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
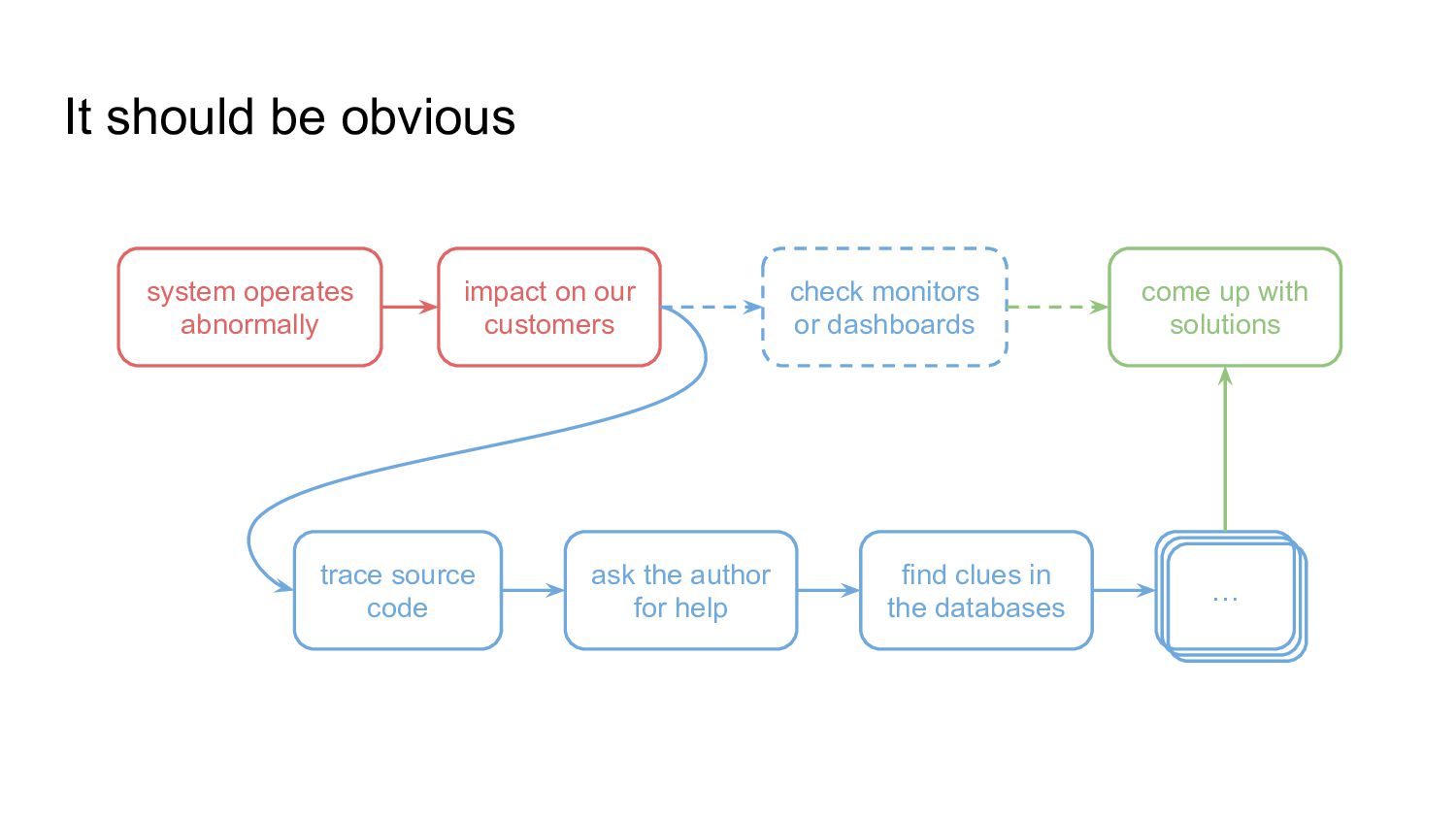{kind=link}
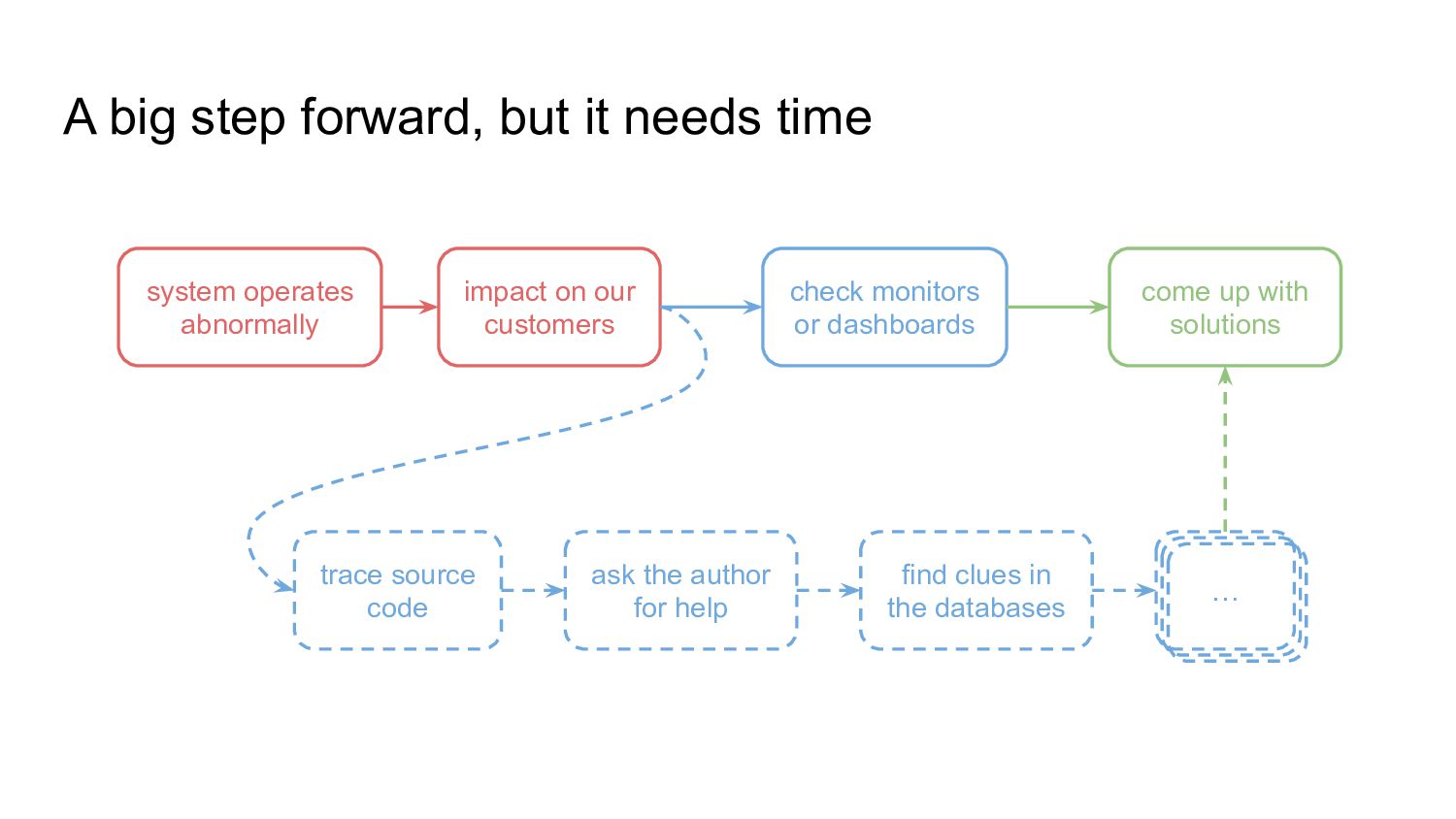{kind=link}
{kind=link}