Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Handling a High Performance PostgreSQL Database
Search
Rain
May 25, 2021
Technology
31
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Handling a High Performance PostgreSQL Database
Rain
May 25, 2021
More Decks by Rain
See All by Rain
System Observability: We can improve only what we can observe
rainrainwu
0
70
Mock out dependencies while testing in Python
rainrainwu
0
200
Scheduling Async Tasks with Python Celery
rainrainwu
0
73
Other Decks in Technology
See All in Technology
あなたの知らないPDFのアクセシビリティ
lycorptech_jp
PRO
0
230
【2026年版】 ベクトル検索とEmbedding最前線
mocobeta
23
7k
Oracle AI Database@AWS:サービス概要のご紹介
oracle4engineer
PRO
4
3k
LayerX コーポレートエンジニアリング室におけるサプライチェーンセキュリティへの取り組み / Supply Chain Security at LayerX Corporate Engineering
yuyatakeyama
3
780
データレイクの「見えない問題」を可視化する
sansantech
PRO
1
170
気軽に使える"情報のハブ"としてのNotion活用 〜フロー情報の集積点 と、 Claude Code × Notion AI〜
syucream
1
170
2026年6月23日 Syncable Tech + Start Python Club にて
hamukazu
0
140
ロボティクスの技術 / Robotics Technology
ks91
PRO
0
120
“詰む”前に仕組みを作れ 〜技術の波に溺れないためのキャッチアップ術〜
takasyou
7
3.2k
【セミナー資料】Claude Code をセキュアに使うための考え方と設定の勘どころ / Claude Code Webinar 20260616
masahirokawahara
2
440
起点・思考・出力で分解する 〜PM業務の自動化設計〜
kazu_kichi_67
0
270
自宅LLMの話
jacopen
1
700
Featured
See All Featured
Evolving SEO for Evolving Search Engines
ryanjones
0
220
The World Runs on Bad Software
bkeepers
PRO
72
12k
Lightning talk: Run Django tests with GitHub Actions
sabderemane
0
200
Why Our Code Smells
bkeepers
PRO
340
58k
The AI Search Optimization Roadmap by Aleyda Solis
aleyda
1
5.9k
Conquering PDFs: document understanding beyond plain text
inesmontani
PRO
4
2.8k
Exploring the relationship between traditional SERPs and Gen AI search
raygrieselhuber
PRO
2
4k
Large-scale JavaScript Application Architecture
addyosmani
515
110k
B2B Lead Gen: Tactics, Traps & Triumph
marketingsoph
0
160
HTML-Aware ERB: The Path to Reactive Rendering @ RubyCon 2026, Rimini, Italy
marcoroth
1
210
svc-hook: hooking system calls on ARM64 by binary rewriting
retrage
2
300
Designing Experiences People Love
moore
143
24k
Transcript
Handling a High Performance PostgreSQL Database
Hello! I am Rain! ex- A. SWE @iCHEF ex- SWE
@NetDB 2 GitHub: RainrainWu LinkedIn: Rain Wu
Outline ⬡ 資料庫基本概念 ⬡ 如何構思解決方案 ⬡ 具體方案與適合情境 3
1. 資料庫基本概念 在進入主題前,先來聊些必備知識
“ 資料庫是一種讓我們能穩定儲 存大量資料的軟體,以實現資料 與邏輯的解耦。 5
“ 其中又可依據是否對存入的資 料有嚴謹的 Schema 要求分為 RDBMS 和 NoSQL 資料庫,這 次所討論的
PostgreSQL 就是 一種 RDBMS。 6
資料庫有哪些操作 ⬡ CRUD ∙ Create ∙ Read ∙ Update ∙
Delete 7
為什麼 資料庫 會變慢 8
有很多原因 ⬡ 讀取很多資料 ⬡ 搜尋特定資料效率低落 ⬡ 為確保一致性所以有交易隔離機制 ⬡ ... 9
資料庫在道德上必須滿足 ACID ⬡ Atomic ⬡ Consistency ⬡ Isolation ⬡ Durability
10
2. 如何構思解決方案
搜集關鍵 資訊 針對可能的方法搜集資料,逐個 驗證是否適用於當前情境 12
可能有用的資訊 ⬡ 資料表的統計資訊 ⬡ Query plan ⬡ Transaction 統計資訊 ⬡
Monitor 13
可以思考的問題 ⬡ 同樣目標可不可以換一種做法 ⬡ 同樣事情可不可以只做一次 ⬡ 為了高效能有哪些東西可以降低優先級 ⬡ 這資料庫的底層實現是否適合當前情境 14
決策流程飛輪 15 驗證方法適用性 依據資訊提出 候選方案 依據異常行為 搜集資訊
3. 具體方案與適合情境
Tune your SQL command ⬡ 找出耗時不合理的指令 ⬡ 看看 query plan
做了哪些事 17
Cache ⬡ 同樣的資料不用每次都搜尋 ⬡ 存在快取中能減少資料庫的工作量 18
Denormalize ⬡ 基於正規化的原則資料庫不該有冗余 的欄位 ⬡ 但有些常用數值每次計算很耗資源, 同時變動較快也不適用 Cache ⬡ 比如
FB 貼文按讚數、TG 未讀訊息數 19
Scale-up ⬡ CPU, RAM 吃滿了? ⬡ 那就加更多資源或換成更高級別的 代管服務吧 20
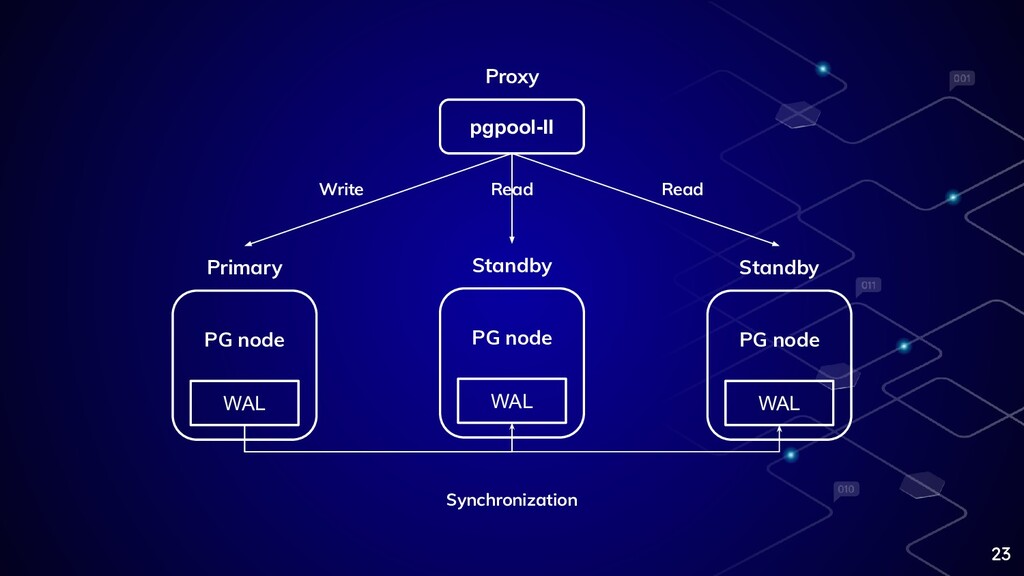
Scale-out (Clustering) ⬡ 多幾台機器分攤工作量 ⬡ 相關概念包含讀寫分離、HA ⬡ 不過為了強一致性通常只有一個負 責接收寫入的節點 ⬡
較適用於 Read >> Write 情境 21
Write-ahead Log (WAL) PostgreSQL 的可靠性機制,在 執行 transaction 前須先像日誌 一樣寫入 Log
內永久儲存 22
23 Primary WAL PG node Standby WAL PG node Standby
WAL PG node pgpool-II Write Read Read Proxy Synchronization
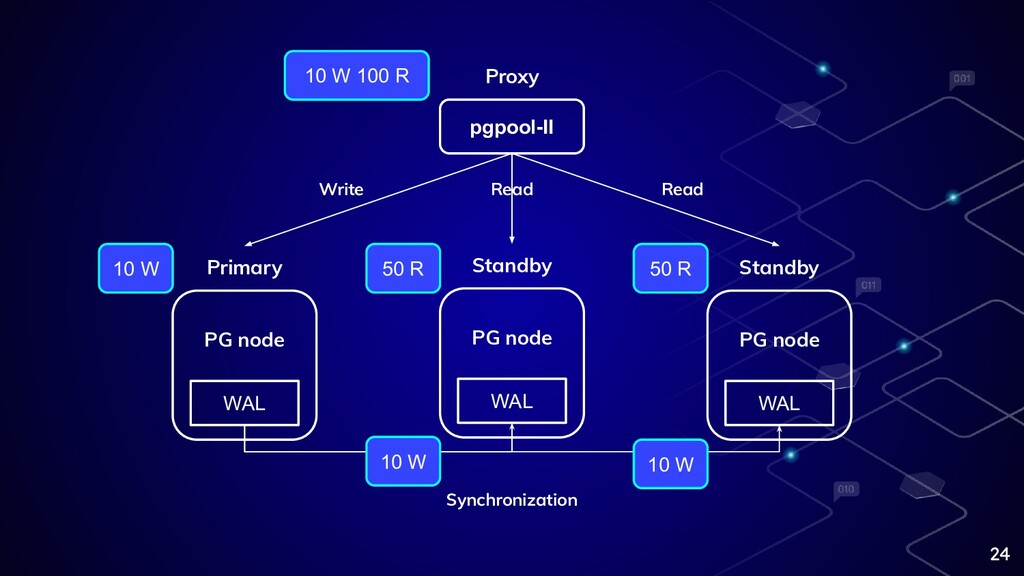
24 Primary WAL PG node Standby WAL PG node Standby
WAL PG node pgpool-II Write Read Read Proxy Synchronization 10 W 100 R 10 W 50 R 50 R 10 W 10 W
讀寫分離 主要是分攤讀的工作量,正好目 前多數服務都是 Read >> Write,但仍須考量資料同步的延 遲 25
Indexes ⬡ 透過維護額外的資料結構讓查找效 率更高 ⬡ 但變相的會犧牲寫入效率 ⬡ 比如二分搜索樹、倒排索引 26
PG 常用 Index GIN 倒排索引,儲存關鍵字與所在文 本之間的映射關係,適合做關鍵 字搜尋 27
28 National Successful University Doc 1 National Failed University Doc
2
Forward Index ⬡ Doc1 : National, Successful, University ⬡ Doc2
: National, Failed, University 29
Inverted Index ⬡ National : Doc1, Doc2 ⬡ Successful :
Doc1 ⬡ University : Doc1, Doc2 ⬡ Failed : Doc2 30
PG 常用 Index BRIN 統計資訊邊界分群,比如時間範 圍、地理位置的 Bounding Box, 適用於銷售日誌或區域查詢 31
Lower Isolation Level ⬡ 根據對交易隔離的要求,資料庫有 多個不同的隔離等級 ⬡ 隔離越是嚴謹效能損失就越大,可 以思考所需要的等級 32
Isolation 層級 ⬡ Read Uncommitted ⬡ Read Committed ⬡ Repeatable
Read ⬡ Serilizable 33
34
Isolation 的主流實作策略 ⬡ Shared-exclusive Lock (SX Lock) ∙ MySQL, MS
SQL ⬡ Multiversion Concurrency Control (MVCC) ∙ PostgreSQL, Oracle 35
SX Lock ⬡ 每筆資料可發行多把 S Lock 和一把 X Lock ⬡
發行 S Lock 時不可有發行中的 X Lock,而發 行 X Lock 時不可有發行中的 S/X Lock ⬡ 只有 Read-Read 不會互相 block,Read-Write 和 Write-Write 都會 36
MVCC ⬡ 每筆紀錄更新或刪除時不直接改動當前資料, 而是新增一個新的版本或刪除標記 ⬡ 每次執行交易時,依據時間點控制該筆交易對 其他紀錄可見的版本 ⬡ 只有 Write-Write
會因為版本先後順序性而 被 block,而 Read-Write 不會 37
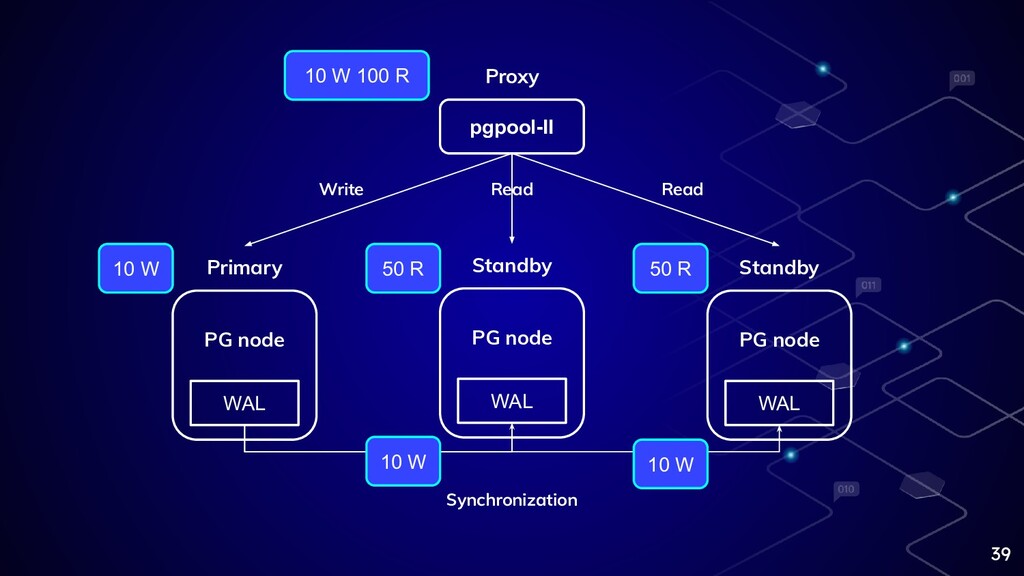
常聽到有人批評 PostgreSQL 做 Clustering 成效不如 MySQL ? ⬡ 讀寫分離解決了 MySQL
中 SX Lock 機制的 Read-Write block 問題,而 PostgreSQL 中 MVCC 機制沒這問題 ⬡ 他的 Read 流量沒有大到需要讀寫分離 ⬡ 他配置有問題 38
39 Primary WAL PG node Standby WAL PG node Standby
WAL PG node pgpool-II Write Read Read Proxy Synchronization 10 W 100 R 10 W 50 R 50 R 10 W 10 W
OLTP v.s. OLAP ⬡ 兩者之間有個很關鍵的行為差異,就 是 range scan ⬡ 計算
real time 指標、產報表都需要 ⬡ 資料庫儲存資料的結構影響很大 40
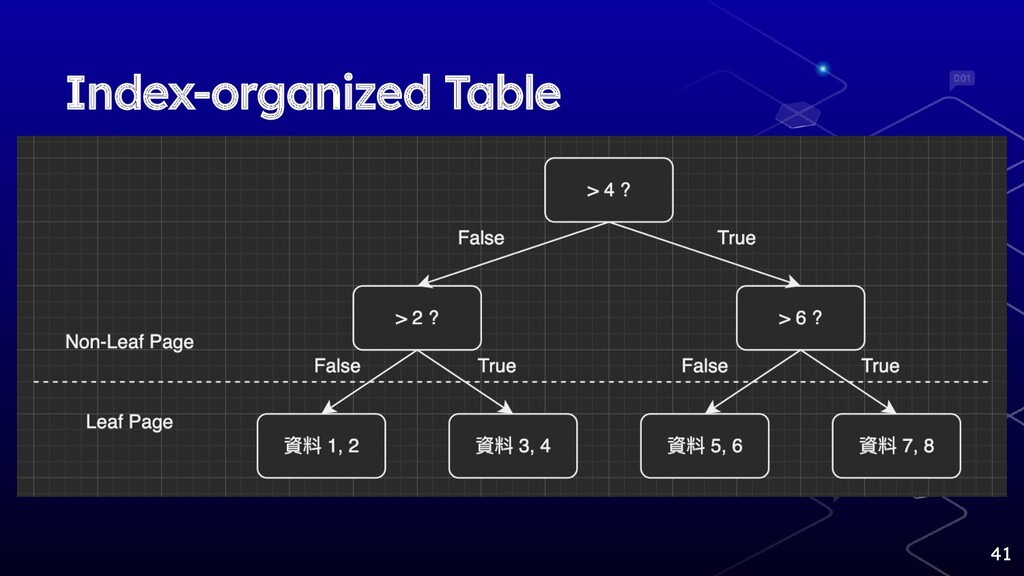
Index-organized Table 41
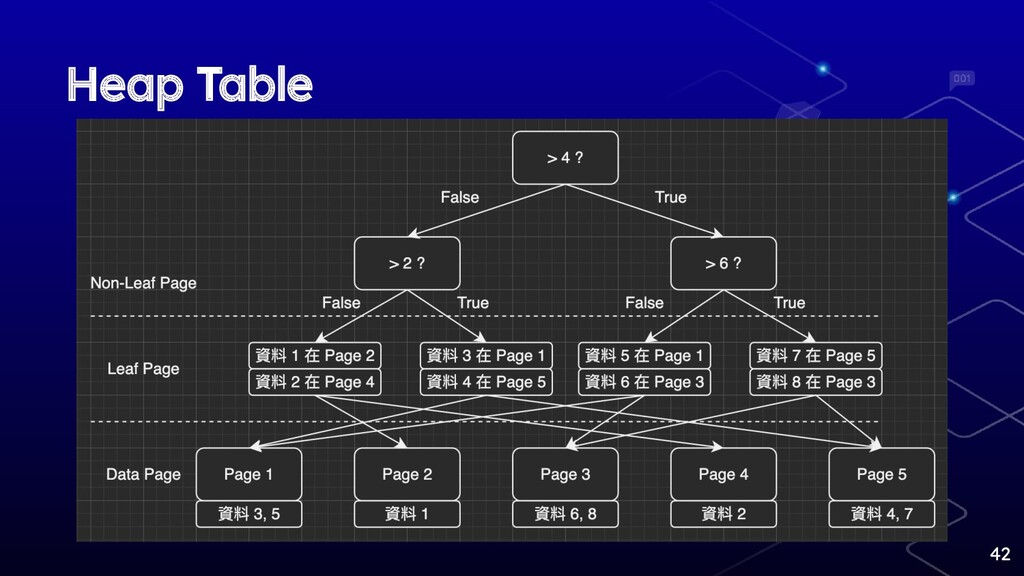
Heap Table 42
有沒有 Range Scan 差很多 ⬡ Heap Table 基本上要 Serial scan
⬡ 當你使用一個 OLTP server 做分析或報表,覺 得他做得很慢時,你可能需要另個 OLAP server 而不是開腦洞優化 OLTP server 43
The End
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}