Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Airワーク採用管理での改善活動とDevOpsへの歩み / DevOpsDays_nishimura
Search
Recruit
PRO
April 22, 2022
Technology
500
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Airワーク採用管理での改善活動とDevOpsへの歩み / DevOpsDays_nishimura
2022/04/21_DevOpsDays Tokyo 2022での、西村の講演資料になります
Recruit
PRO
April 22, 2022
More Decks by Recruit
See All by Recruit
双方向推薦システムにおける長期的マッチング最大化に向けた代理目的関数の設計と実証
recruitengineers
PRO
0
87
就職⽀援サービスにおけるキャリアアドバイザーのシフトスケジューリング
recruitengineers
PRO
1
170
Model Routerを使った逐次LLM選択による毀損低減効果の検証
recruitengineers
PRO
1
56
ストリーム処理基盤のFlink移行検証と適材適所の実践
recruitengineers
PRO
2
99
AI 時代の Platform Engineering
recruitengineers
PRO
2
440
巨大プラットフォームを進化させる「第3のROI」
recruitengineers
PRO
2
3.6k
データ戦略を加速させる プラットフォーム エンジニアリングと進化的アーキテクチャ
recruitengineers
PRO
2
110
まなび領域における生成AI活用事例
recruitengineers
PRO
2
320
AI時代にエンジニアはどう成長すれば良いのか?
recruitengineers
PRO
1
570
Other Decks in Technology
See All in Technology
AI Agent SaaS を支える自社仮想化基盤への挑戦と実運用 / ai-agent-saas-virtualization
flatt_security
2
2.2k
ポストモーテム! DDoSからサイトは守れた。 でもビジネスは守れなかった。
bengo4com
0
980
勉強会企画をアプリで構造化してみた 〜そこで見えた、AIとの付き合い方〜 / I've structured a study group plan using an app.
pauli
0
320
4人目のSREはAgent
tanimuyk
0
400
AIDLC_ヤフーショッピングの取り組み
lycorptech_jp
PRO
0
550
Claude Codeとハーネスについて考えてみる
oikon48
18
8.7k
インフラ寄りSREでも 開発に踏み出せる〜境界を越えてユーザー体験に向き合いたい〜
sansantech
PRO
0
1.7k
プライバシー保護の理論と実践
lycorptech_jp
PRO
1
240
スタートアップにおけるアジャイルの実践について #shibuyagile
murabayashi
3
2.1k
Amazon EVS で VCF 9.0 / 9.1 のサポート開始まとめ
mtoyoda
0
270
product engineering with qa
nealle
0
150
Baseline対応のDOMの型定義を作った
uhyo
3
710
Featured
See All Featured
Effective software design: The role of men in debugging patriarchy in IT @ Voxxed Days AMS
baasie
0
440
Crafting Experiences
bethany
1
210
New Earth Scene 8
popppiees
3
2.4k
Visualizing Your Data: Incorporating Mongo into Loggly Infrastructure
mongodb
49
10k
<Decoding/> the Language of Devs - We Love SEO 2024
nikkihalliwell
1
270
GraphQLの誤解/rethinking-graphql
sonatard
75
12k
Bash Introduction
62gerente
615
220k
Joys of Absence: A Defence of Solitary Play
codingconduct
1
410
The Web Performance Landscape in 2024 [PerfNow 2024]
tammyeverts
12
1.2k
[RailsConf 2023 Opening Keynote] The Magic of Rails
eileencodes
31
10k
Self-Hosted WebAssembly Runtime for Runtime-Neutral Checkpoint/Restore in Edge–Cloud Continuum
chikuwait
0
640
Product Roadmaps are Hard
iamctodd
55
12k
Transcript
Airワーク採用管理での 改善活動とDevOpsへの歩み 2022年4月21日 株式会社リクルート 西村祐樹
自己紹介 西村祐樹 所属 株式会社リクルート 部署 プロダクト統括本部 プロダクト開発統括室 プロダクトディベロップメント室 HR領域プロダクトディベロップメントユニット HR領域エンジニアリング部 HRアーキテクトグループ
ちょうど3ヶ月前にも弊社の改善事例について お話させていただきました https://speakerdeck.com/recruitengineers/tech-meetup2-nishimura アーキテクトが考えるシステム改善を 継続するための心得
・システムの安定稼働、開発を維持するために構造的な問題を解決して 価値を発揮する ・技術の精通だけでなく、現場の課題認識と解決能力も求められる (いわゆるシステム設計だけにとどまらない) ・主に古くからある大規模システムを担当している (古くからある大規模システム ≒ ビジネス規模の大きいシステム) 我々の組織の役割 私の主な担当システム
『Airワーク採用管理』について 2018年にリリースされたサービス 採用HP, 求人掲載, 採用管理などを手 軽にできる採用活動を支援するための サービスになります 本日はこの『Airワーク採用管理』 (以降『Airワーク』で統一します) のシステム改善に関わる中で見えて
きたDevOpsについての考え方につ いて紹介していきます
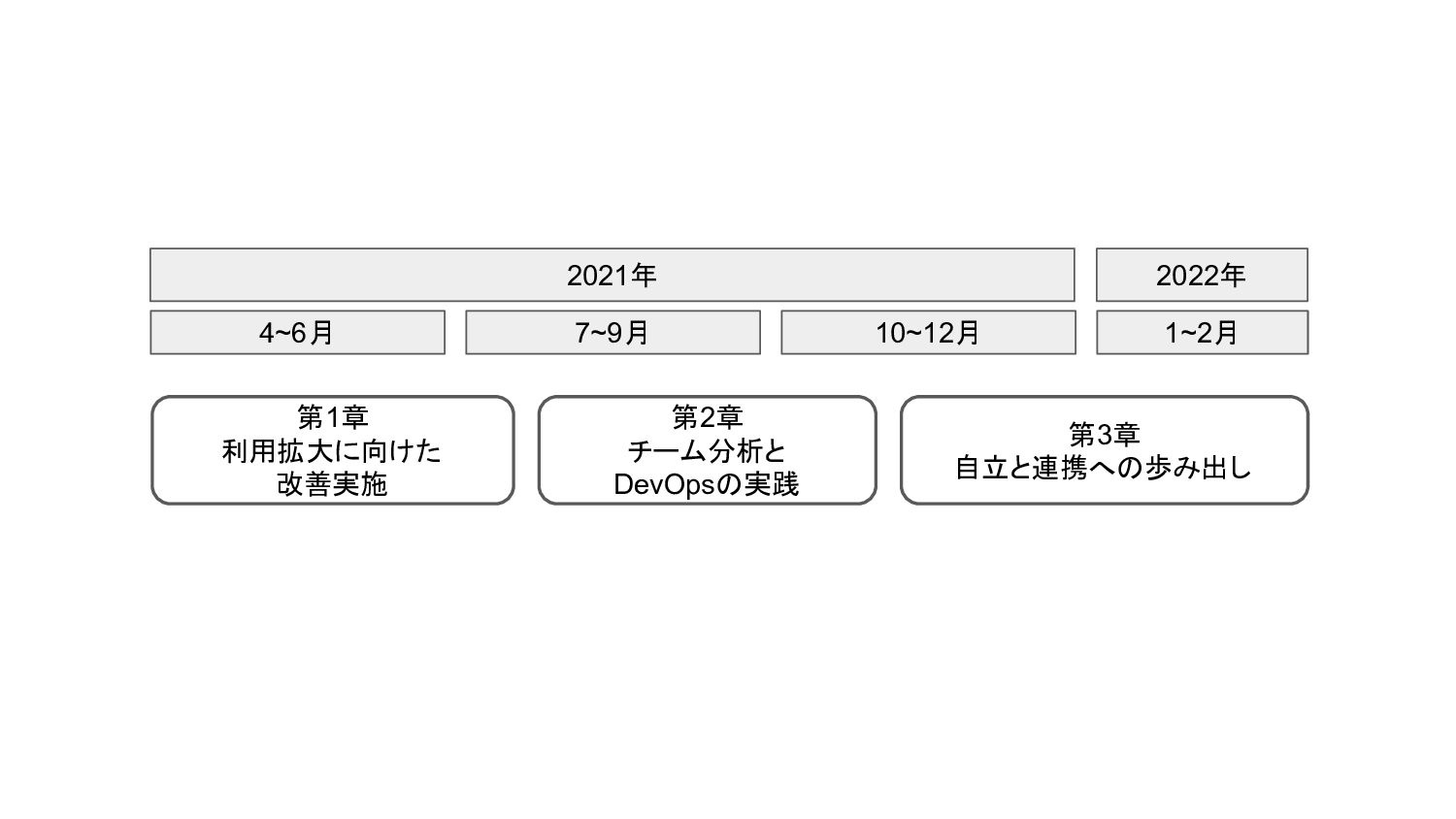
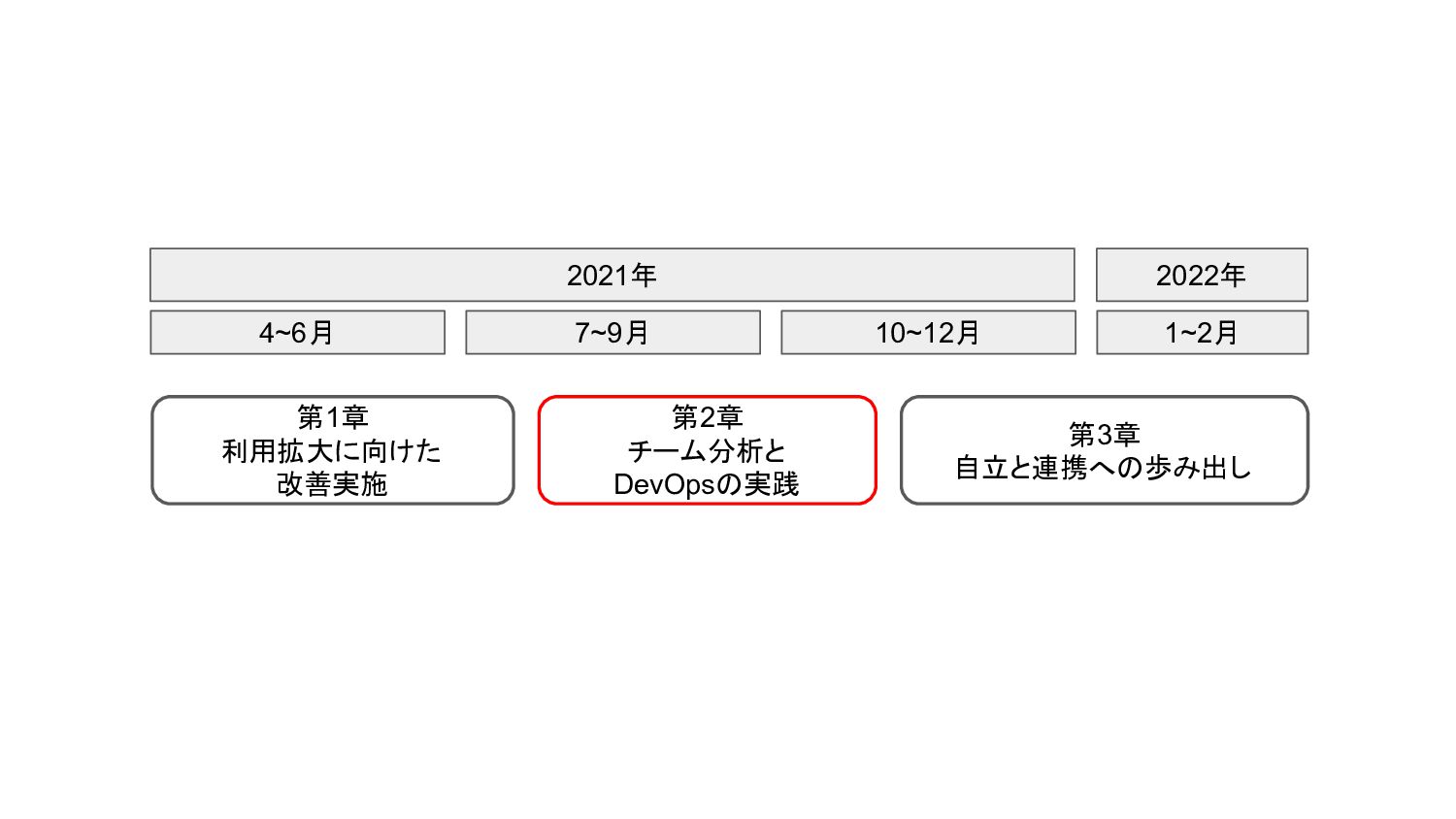
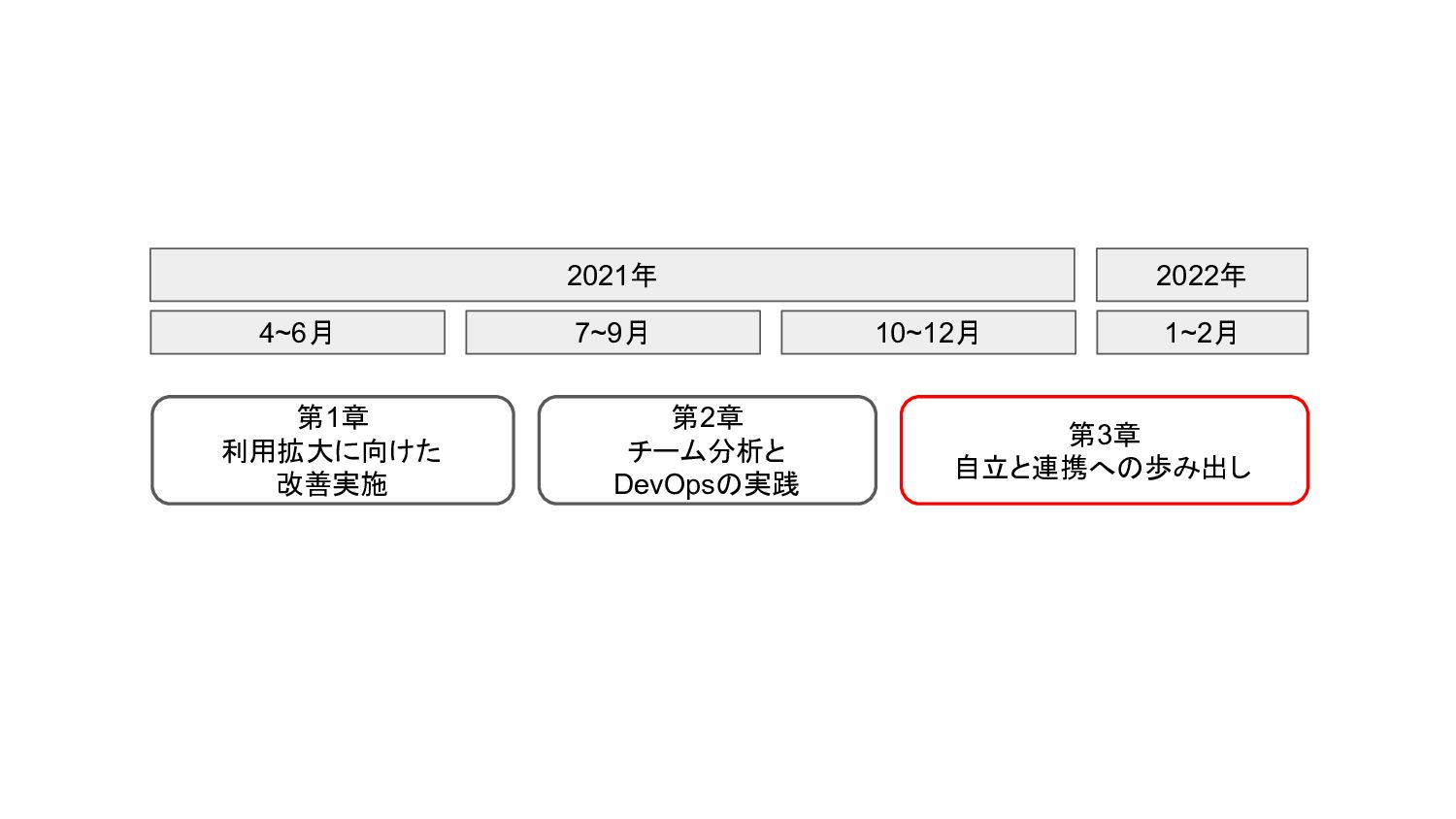
4~6月 7~9月 10~12月 1~2月 第1章 利用拡大に向けた 改善実施 第2章 チーム分析と DevOpsの実践
第3章 自立と連携への歩み出し 2021年 2022年
第1章 利用拡大に向けた改善実施
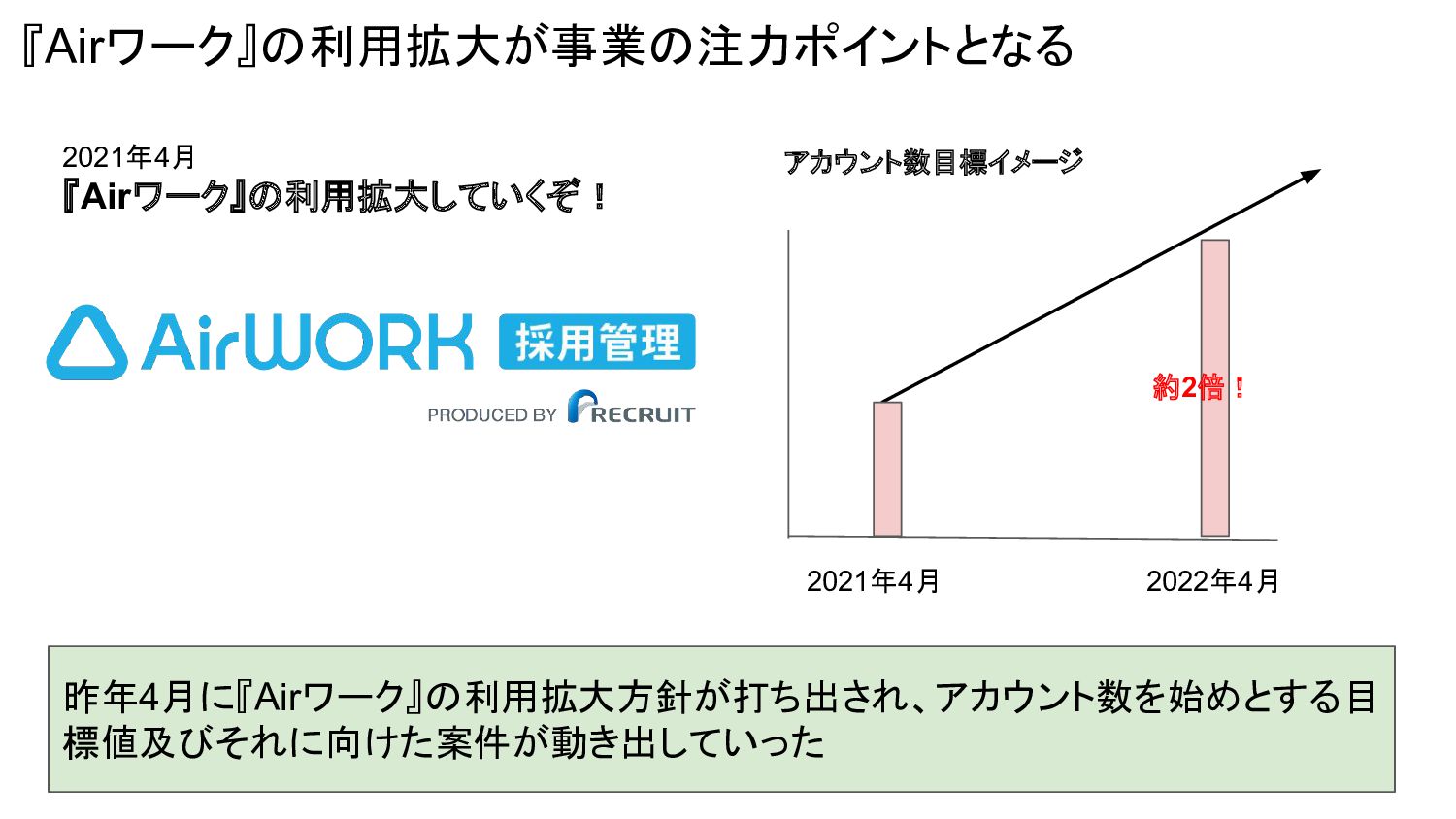
『Airワーク』の利用拡大が事業の注力ポイントとなる 2021年4月 2022年4月 約2倍! アカウント数目標イメージ 昨年4月に『Airワーク』の利用拡大方針が打ち出され、アカウント数を始めとする目 標値及びそれに向けた案件が動き出していった 2021年4月 『Airワーク』の利用拡大していくぞ!
事業方針に伴い我々も『Airワーク』に関わる こっちも見ながら これまでサービス規模的に深く携わっていなかったが 事業方針転換に伴い注力対象とすることに こちらにも注力 我々の動きの変化 New! アーキテクトT
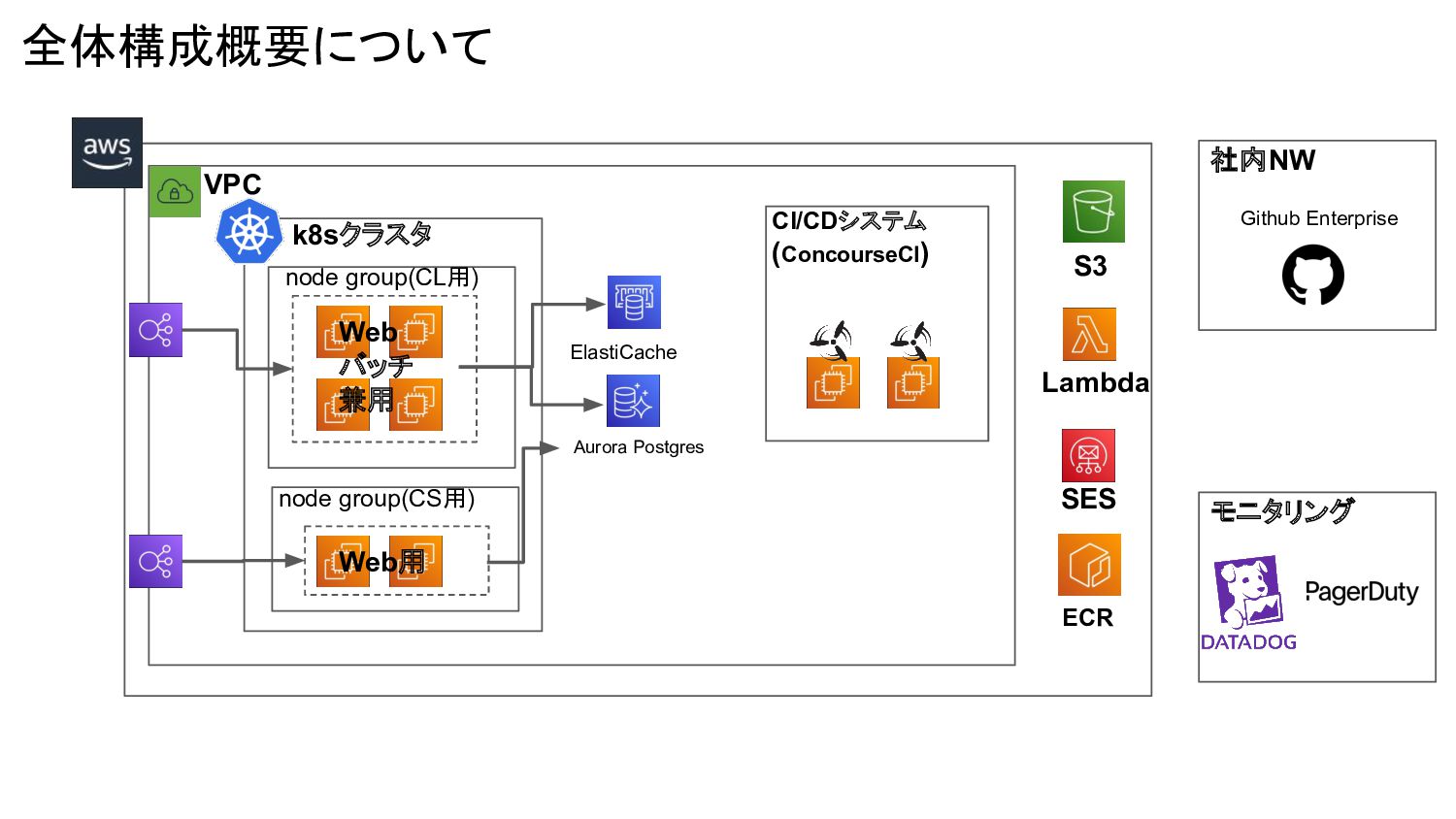
全体構成概要について node group(CL用) node group(CS用) VPC k8sクラスタ Web バッチ 兼用
Web用 CI/CDシステム (ConcourseCI) ECR Github Enterprise 社内NW SES Lambda Aurora Postgres ElastiCache モニタリング S3
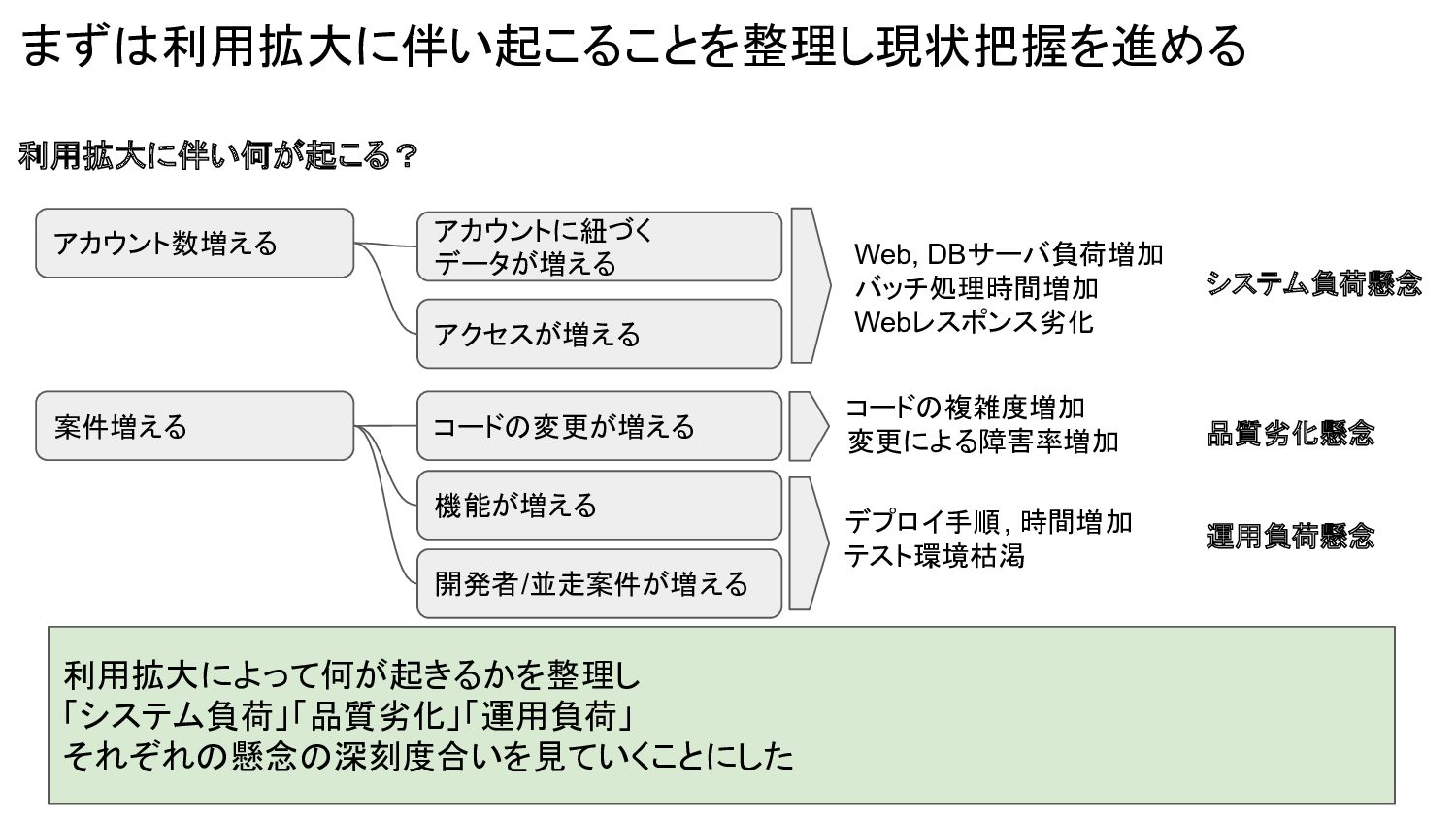
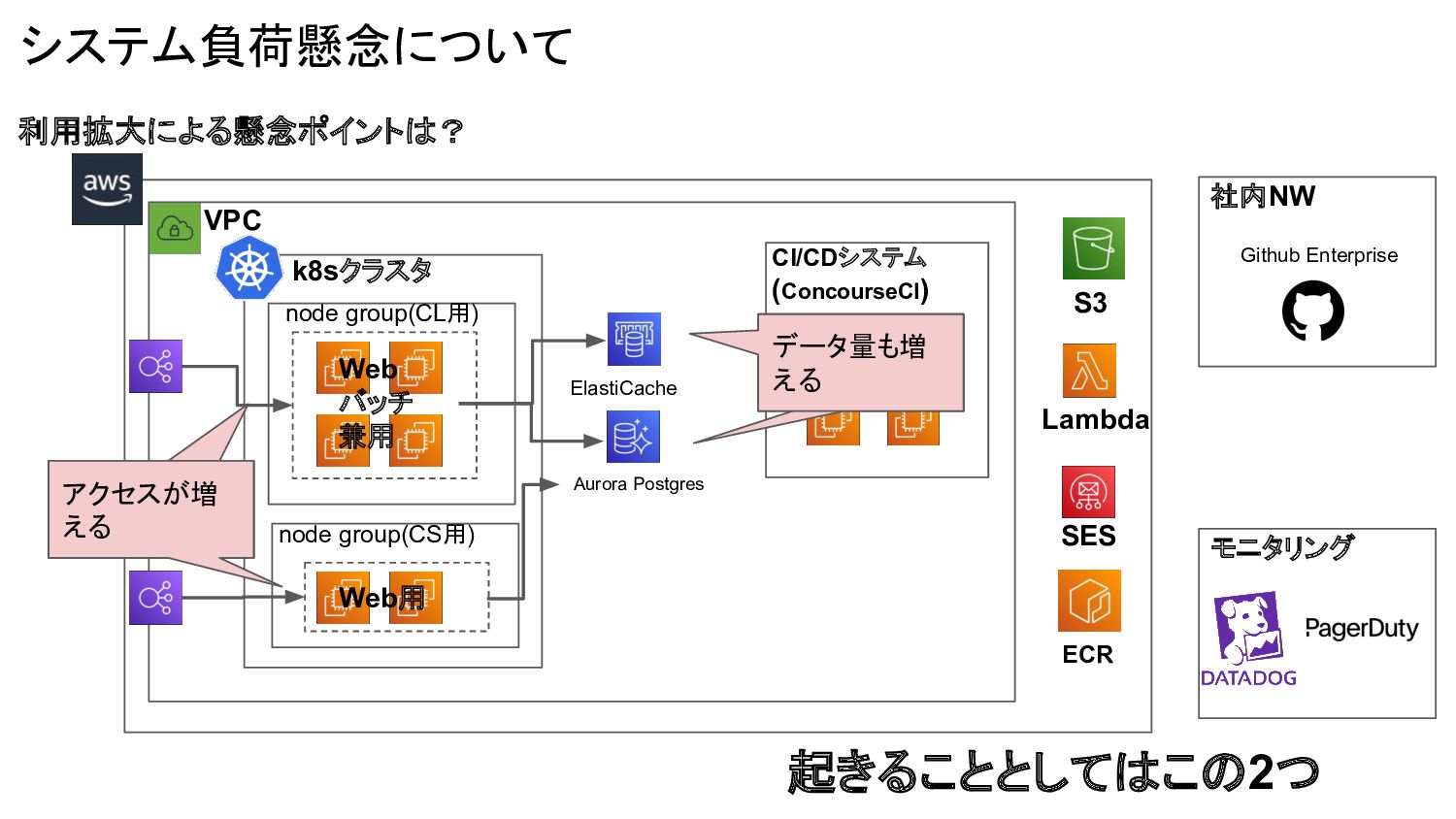
まずは利用拡大に伴い起こることを整理し現状把握を進める 利用拡大によって何が起きるかを整理し 「システム負荷」「品質劣化」「運用負荷」 それぞれの懸念の深刻度合いを見ていくことにした 利用拡大に伴い何が起こる? アカウント数増える 案件増える アカウントに紐づく データが増える アクセスが増える
コードの変更が増える 機能が増える Web, DBサーバ負荷増加 バッチ処理時間増加 Webレスポンス劣化 コードの複雑度増加 変更による障害率増加 品質劣化懸念 システム負荷懸念 デプロイ手順, 時間増加 テスト環境枯渇 開発者/並走案件が増える 運用負荷懸念
node group(CL用) node group(CS用) VPC k8sクラスタ Web バッチ 兼用 Web用
CI/CDシステム (ConcourseCI) ECR Github Enterprise 社内NW SES Lambda Aurora Postgres ElastiCache モニタリング S3 システム負荷懸念について 利用拡大による懸念ポイントは? 起きることとしてはこの2つ アクセスが増 える ここが増える データ量も増 える
node group(CL用) node group(CS用) VPC k8sクラスタ Web バッチ 兼用 Web用
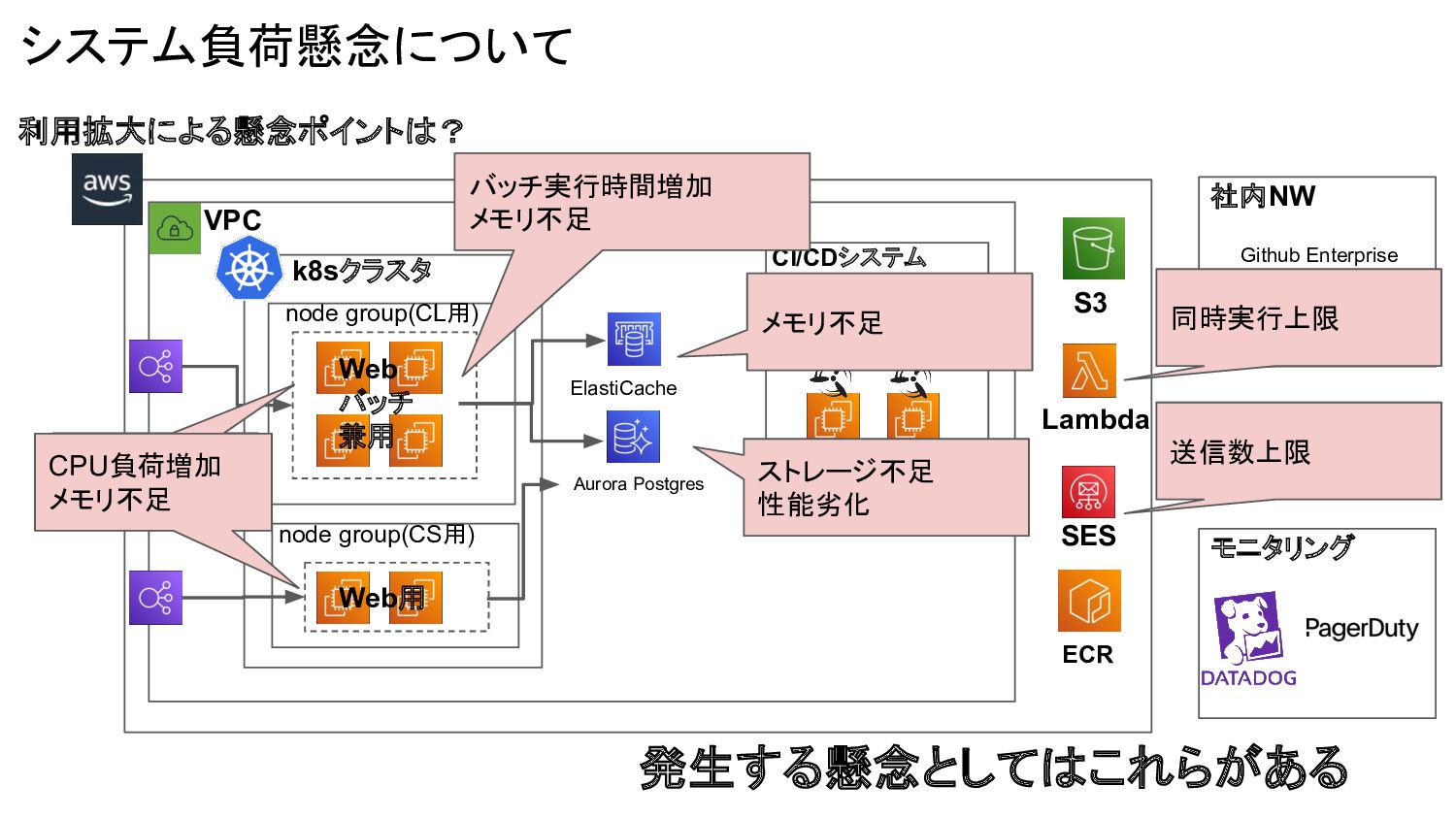
CI/CDシステム (ConcourseCI) ECR Github Enterprise 社内NW SES Lambda Aurora Postgres ElastiCache モニタリング S3 システム負荷懸念について 利用拡大による懸念ポイントは? 発生する懸念としてはこれらがある ストレージ不足 性能劣化 CPU負荷増加 メモリ不足 バッチ実行時間増加 メモリ不足 メモリ不足 送信数上限 同時実行上限
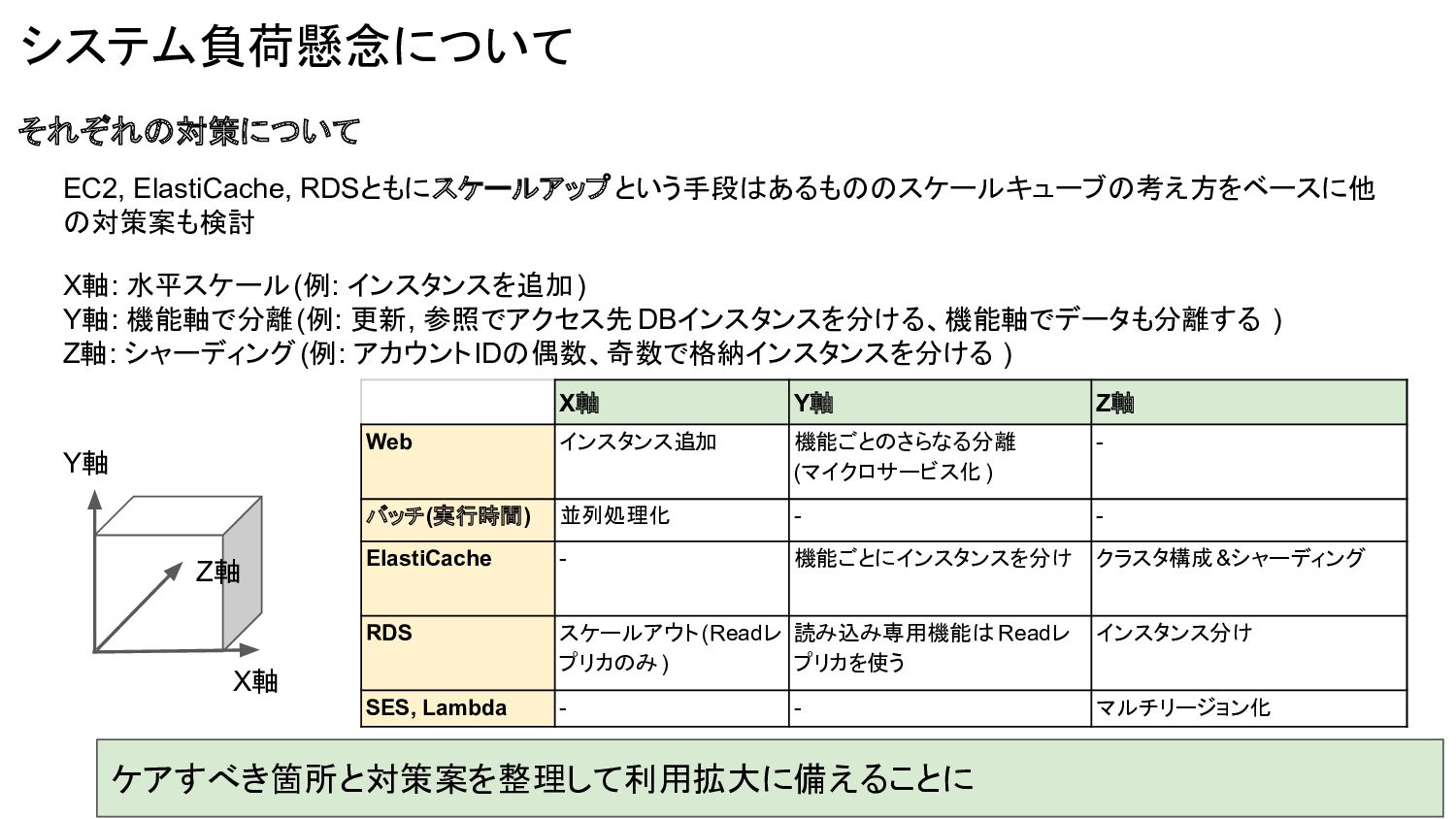
システム負荷懸念について それぞれの対策について EC2, ElastiCache, RDSともにスケールアップという手段はあるもののスケールキューブの考え方をベースに他 の対策案も検討 X軸: 水平スケール(例: インスタンスを追加) Y軸:
機能軸で分離(例: 更新, 参照でアクセス先DBインスタンスを分ける、機能軸でデータも分離する ) Z軸: シャーディング(例: アカウントIDの偶数、奇数で格納インスタンスを分ける ) X軸 Y軸 Z軸 X軸 Y軸 Z軸 Web インスタンス追加 機能ごとのさらなる分離 (マイクロサービス化 ) - バッチ(実行時間) 並列処理化 - - ElastiCache - 機能ごとにインスタンスを分け クラスタ構成&シャーディング RDS スケールアウト(Readレ プリカのみ) 読み込み専用機能は Readレ プリカを使う インスタンス分け SES, Lambda - - マルチリージョン化 ケアすべき箇所と対策案を整理して利用拡大に備えることに
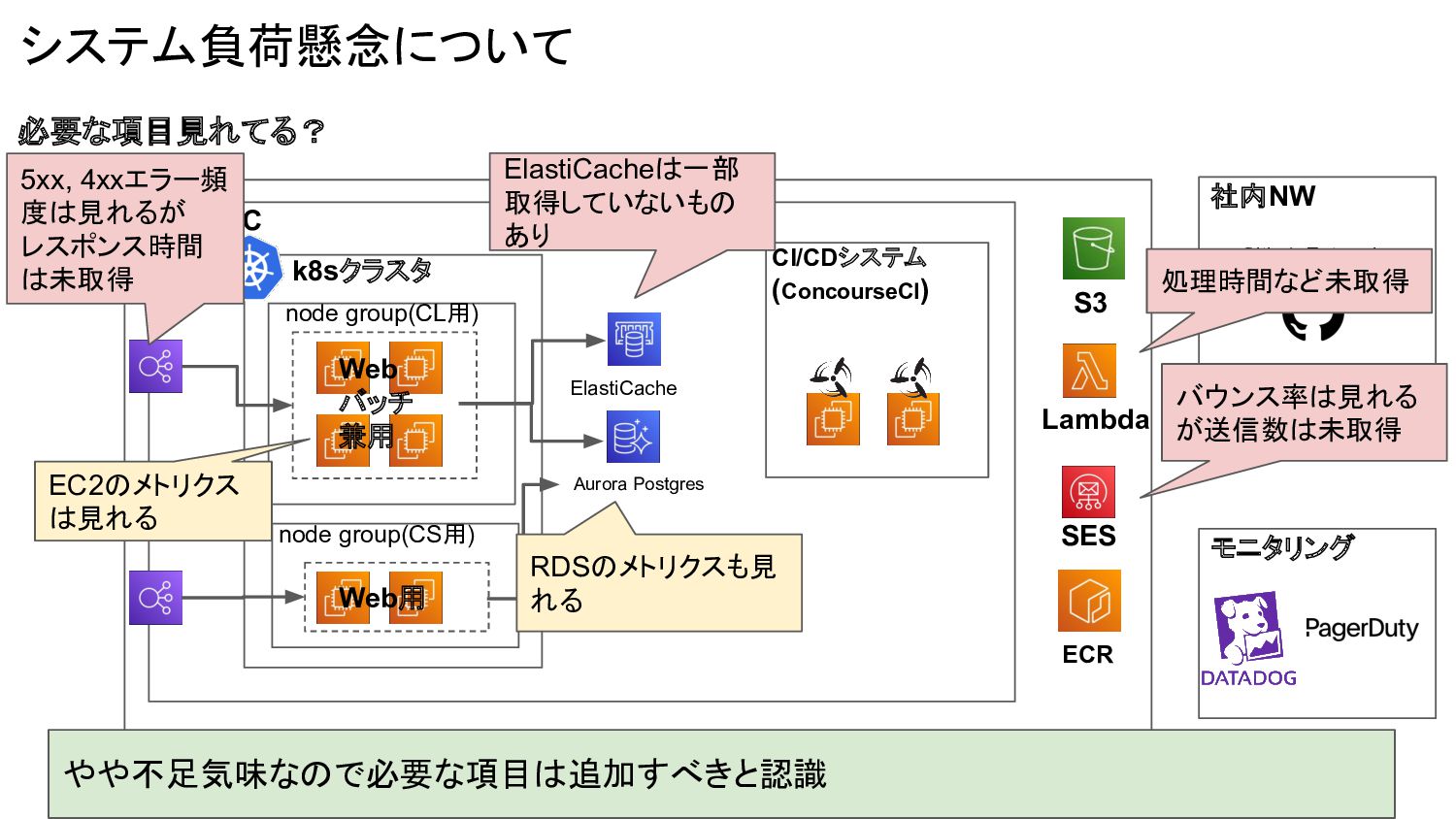
システム負荷懸念について ちゃんと現状把握できる? Datadogである程度は見れる
node group(CL用) node group(CS用) VPC k8sクラスタ Web バッチ 兼用 Web用
CI/CDシステム (ConcourseCI) ECR Github Enterprise 社内NW SES Lambda Aurora Postgres ElastiCache モニタリング S3 システム負荷懸念について 必要な項目見れてる? RDSのメトリクスも見 れる EC2のメトリクス は見れる ElastiCacheは一部 取得していないもの あり 5xx, 4xxエラー頻 度は見れるが レスポンス時間 は未取得 バウンス率は見れる が送信数は未取得 処理時間など未取得 やや不足気味なので必要な項目は追加すべきと認識
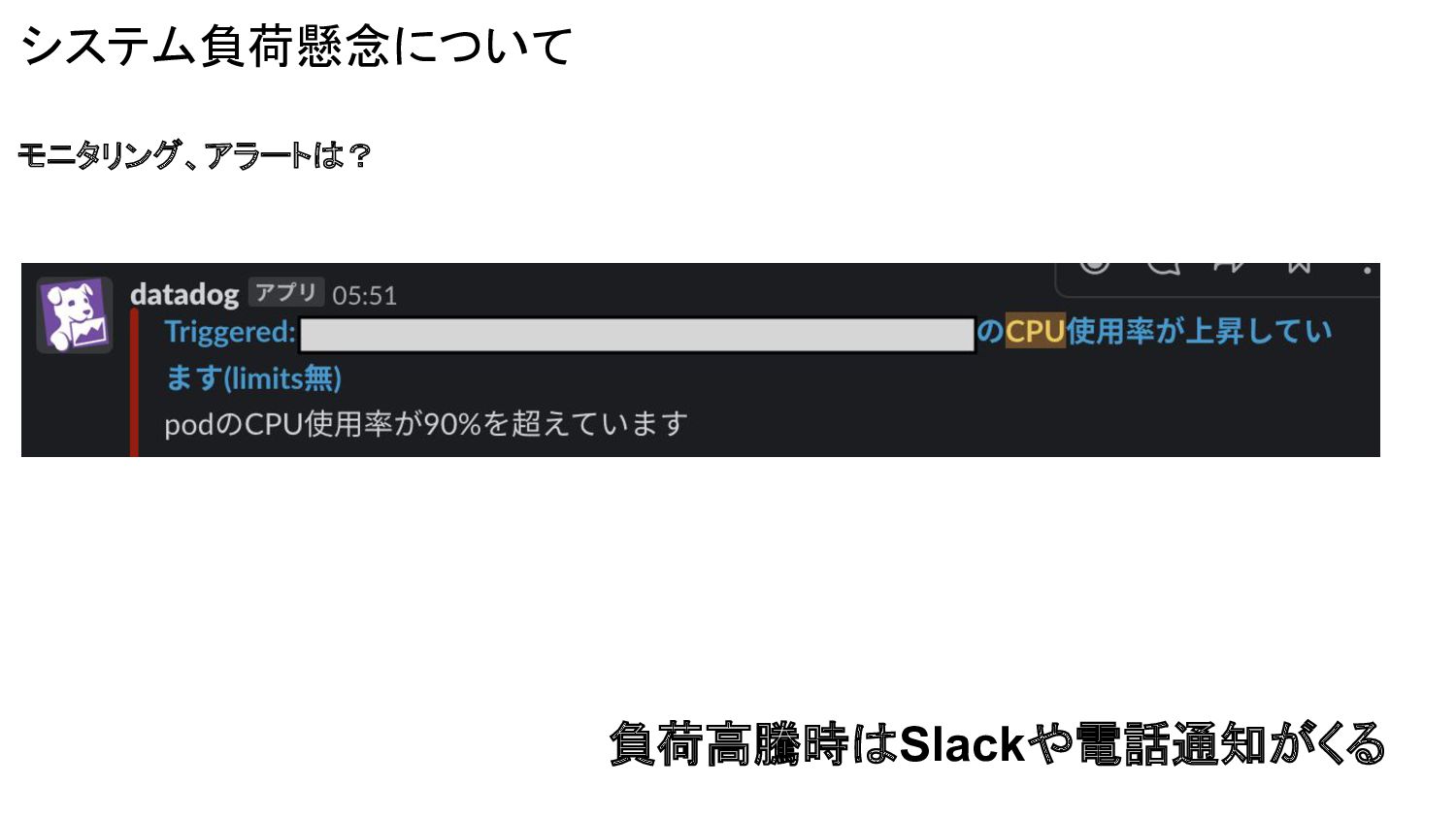
システム負荷懸念について モニタリング、アラートは? 負荷高騰時はSlackや電話通知がくる
システム負荷懸念について アラート検知時の対応は? 影響ないほうって必要? 落ち着いたので静観します サービス影響ない場合 サービス影響出た場合 集まって対応だ! 既知の問題なので静観します
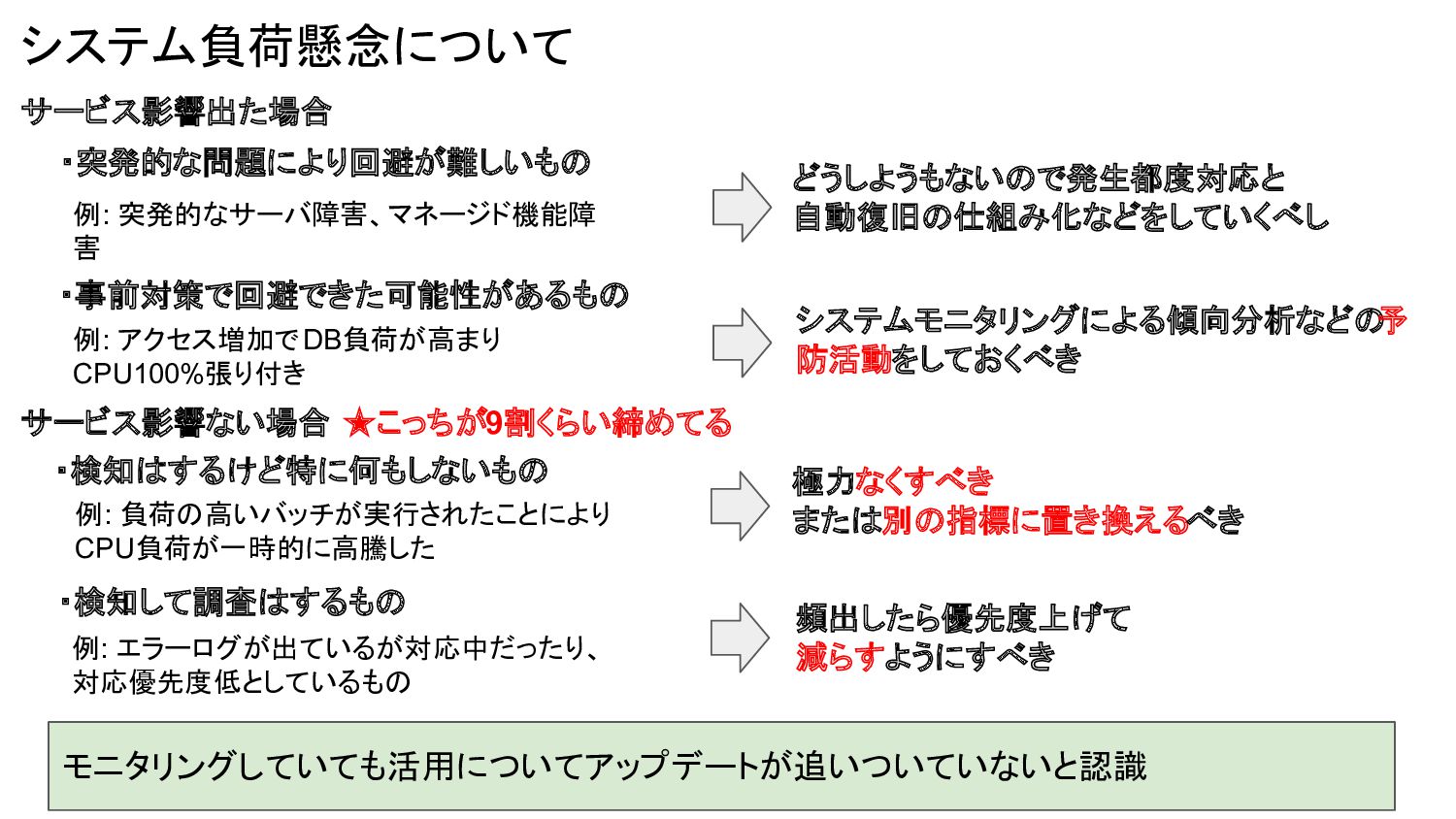
システム負荷懸念について ・検知はするけど特に何もしないもの 例: 負荷の高いバッチが実行されたことにより CPU負荷が一時的に高騰した ・検知して調査はするもの サービス影響ない場合 ★こっちが9割くらい締めてる 例: エラーログが出ているが対応中だったり、
対応優先度低としているもの 極力なくすべき または別の指標に置き換えるべき 頻出したら優先度上げて 減らすようにすべき サービス影響出た場合 ・突発的な問題により回避が難しいもの ・事前対策で回避できた可能性があるもの どうしようもないので発生都度対応と 自動復旧の仕組み化などをしていくべし システムモニタリングによる傾向分析などの 予 防活動をしておくべき 例: 突発的なサーバ障害、マネージド機能障 害 例: アクセス増加でDB負荷が高まり CPU100%張り付き モニタリングしていても活用についてアップデートが追いついていないと認識
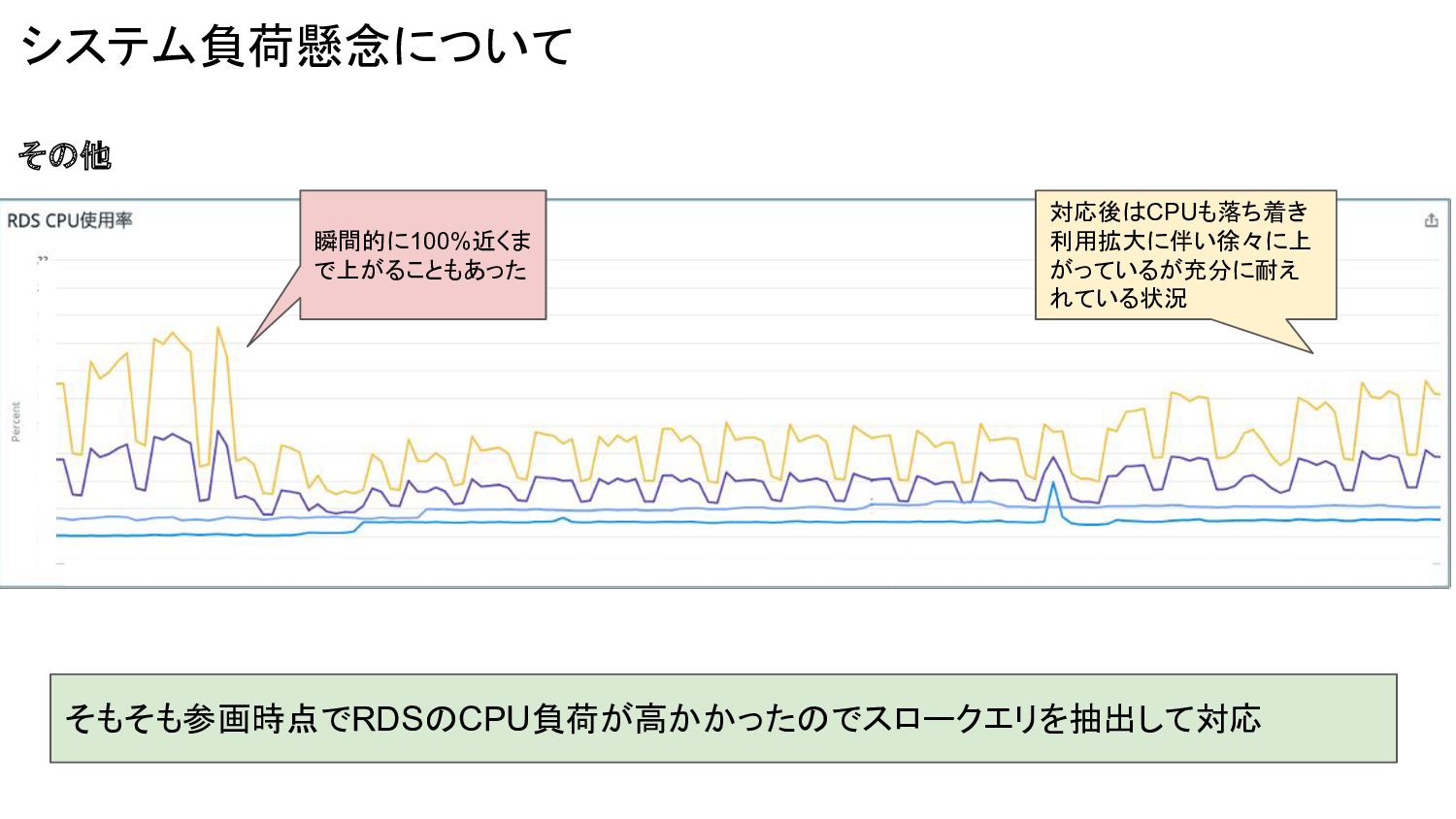
システム負荷懸念について その他 そもそも参画時点でRDSのCPU負荷が高かかったのでスロークエリを抽出して対応 瞬間的に100%近くま で上がることもあった 対応後はCPUも落ち着き 利用拡大に伴い徐々に上 がっているが充分に耐え れている状況
システム負荷懸念について 結論、システム負荷懸念に対しては以下の 2軸でいくことに 1. 利用拡大に向けた対策案の整理 (短期) ・スケールアップ、スケールアウトの実現性は? ・発動させる条件は? 2. 運用含めたモニタリング強化(長期)
・不足している情報は追加する ・モニタリングの活用(運用)についても整理する
品質劣化懸念について 障害傾向(変更失敗率が増加傾向になってないか? ) 既存ソースコード分析(客観的に見通しのよい状態か? ) 計画外作業(手戻りが多くなってないか?) 手戻りを中心に各工程の実体を確認しようとしたが 未計測だったので保留 特定の主要機能についてやや失敗率が高め (週1回リリースで2~3ヶ月に1回頻度
≒ 約10~20%) フロントエンド ↔ BFF ↔ APIという構造でフロントエンドと BFF周りのコードが複雑になっていた 障害分析, 計画外作業に加えてコード自体も一通り確認
結論、品質劣化懸念については最低限のケアで凌ぐことに 1. 既存アーキテクチャの見直し発生など高難度な案件がきた際にはレビューで対応 2. 変更失敗率が高くなってきたら別途見直す 品質劣化懸念について
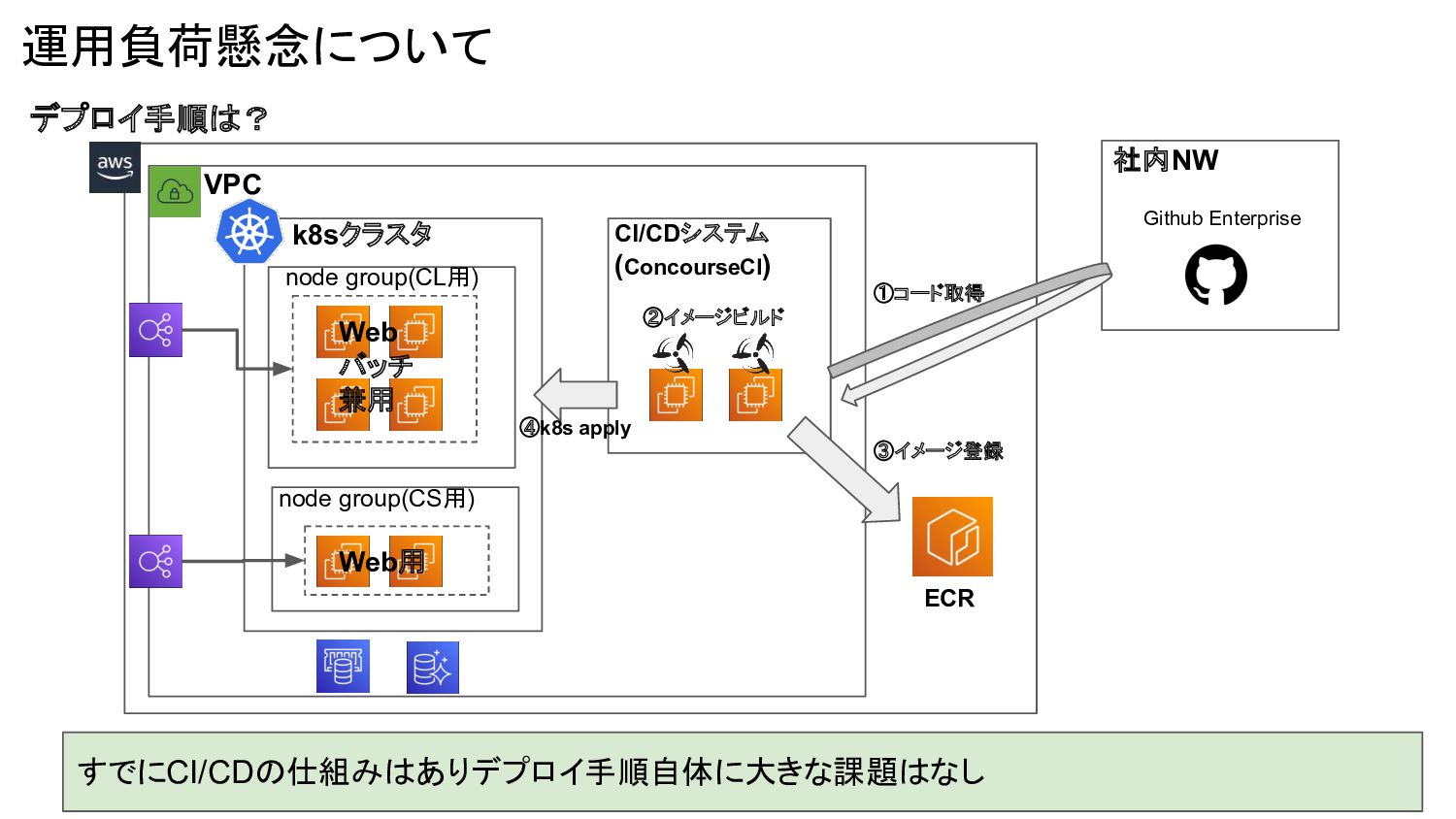
デプロイ手順は? 運用負荷懸念について node group(CL用) node group(CS用) VPC k8sクラスタ Web バッチ
兼用 Web用 CI/CDシステム (ConcourseCI) ECR Github Enterprise 社内NW ①コード取得 ②イメージビルド ③イメージ登録 ④k8s apply すでにCI/CDの仕組みはありデプロイ手順自体に大きな課題はなし
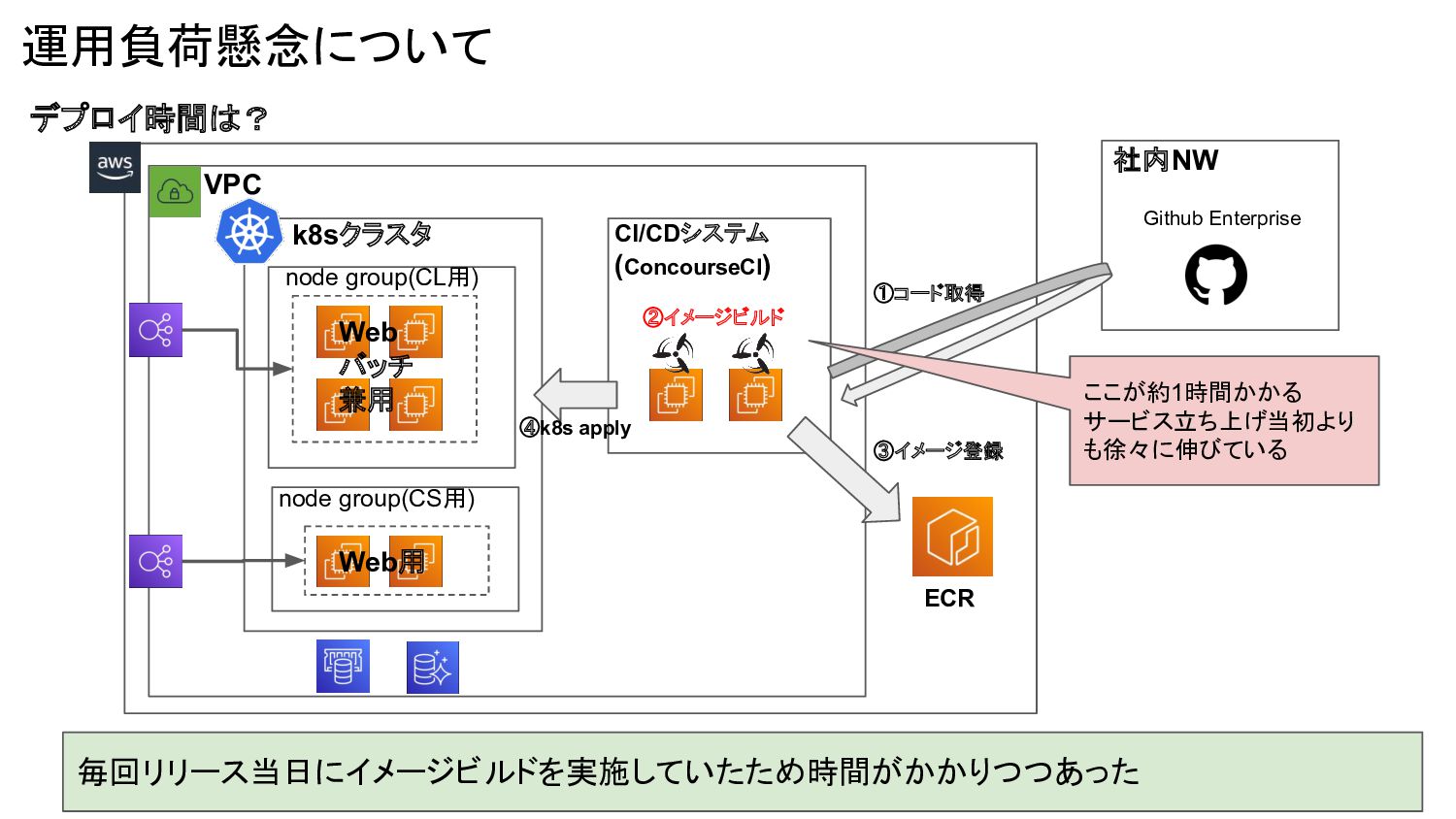
デプロイ時間は? 運用負荷懸念について node group(CL用) node group(CS用) VPC k8sクラスタ Web バッチ
兼用 Web用 CI/CDシステム (ConcourseCI) ECR Github Enterprise 社内NW ①コード取得 ②イメージビルド ③イメージ登録 ④k8s apply ここが約1時間かかる サービス立ち上げ当初より も徐々に伸びている 毎回リリース当日にイメージビルドを実施していたため時間がかかりつつあった
デプロイ時間は? 運用負荷懸念について スキーマ変更を伴うリリースではメンテナンスリリースを実施しており、深夜作業も発生 今後の機能追加に伴い時間が伸びる懸念があったため事前ビルド方式が必要と判断 メンテナンスモー ド切り替え ビルド& イメージ登録 デプロイ 内部動作
確認 DBマイグ レーション メンテナンスモー ド切り替え 03:00 05:00 ここだけで1時間 メンテナンスモー ド切り替え デプロイ 内部動作 確認 DBマイグ レーション メンテナンスモー ド切り替え 03:00 04:00 こうできるはず ※ビルド&イメージ登録は前日に済ませる
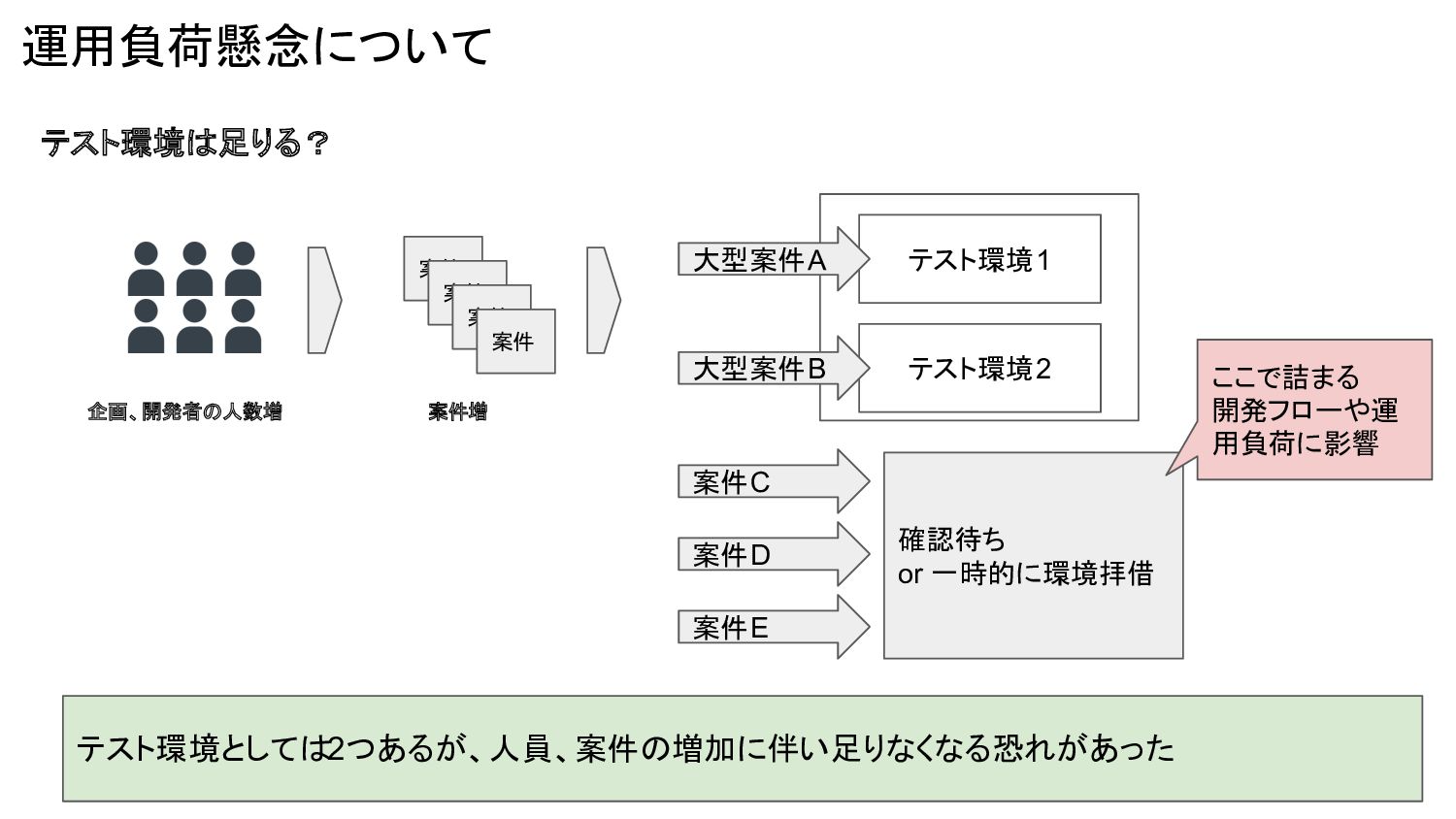
運用負荷懸念について テスト環境は足りる? 案件 案件 案件 案件 テスト環境1 テスト環境2 大型案件A 大型案件B
案件C 案件D 案件E 確認待ち or 一時的に環境拝借 テスト環境としては2つあるが、人員、案件の増加に伴い足りなくなる恐れがあった 企画、開発者の人数増 案件増 ここで詰まる 開発フローや運 用負荷に影響
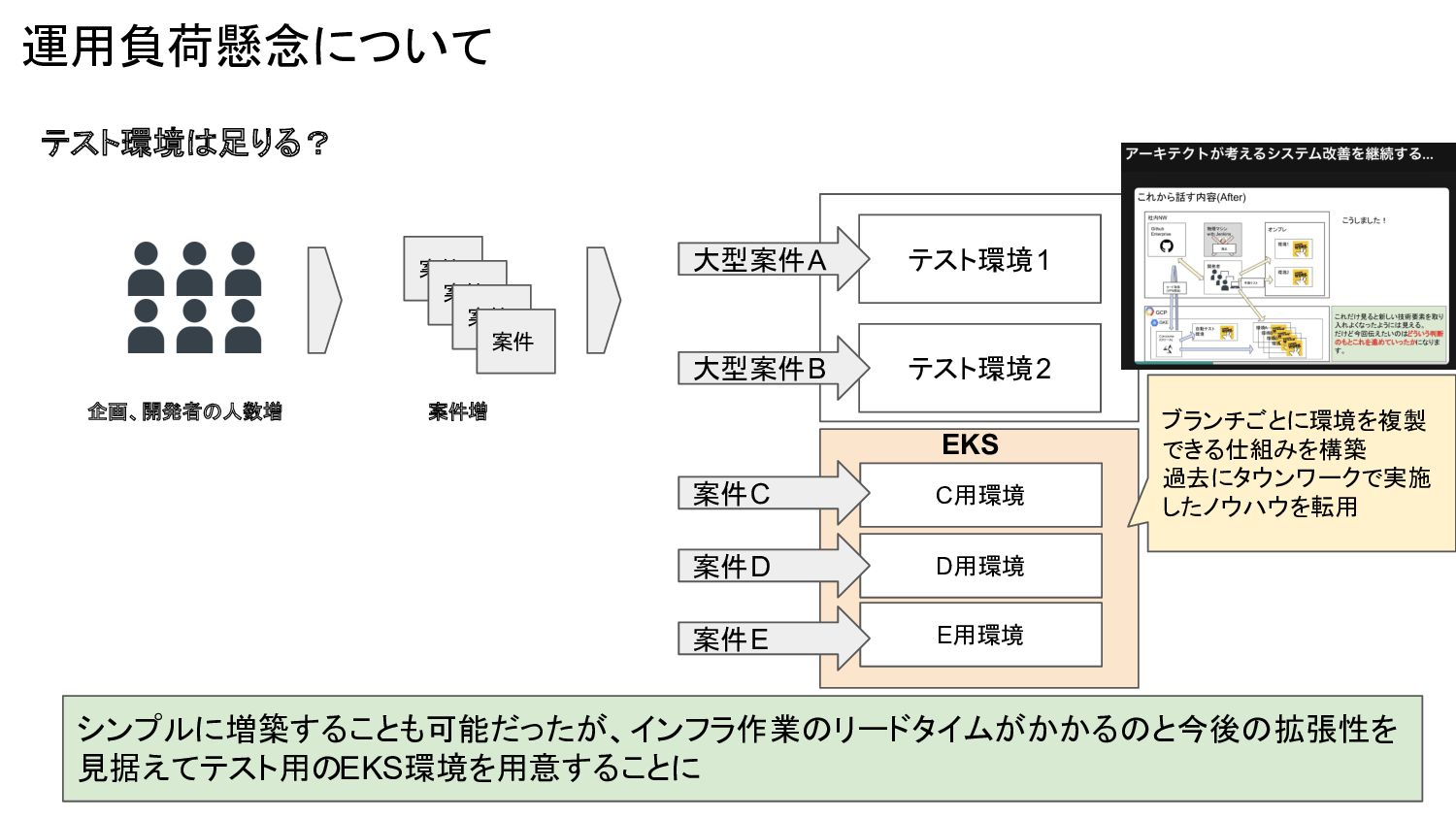
運用負荷懸念について テスト環境は足りる? 案件 案件 案件 案件 テスト環境1 テスト環境2 大型案件A 大型案件B
シンプルに増築することも可能だったが、インフラ作業のリードタイムがかかるのと今後の拡張性を 見据えてテスト用のEKS環境を用意することに 企画、開発者の人数増 案件増 EKS C用環境 D用環境 E用環境 案件C 案件D 案件E ブランチごとに環境を複製 できる仕組みを構築 過去にタウンワークで実施 したノウハウを転用
結論、運用負荷懸念については直近効果ありそうな以下の 2点を実施することに 1. デプロイ手順の改良によりリリース時間短縮 2. テスト環境拡張による開発フロー、運用負荷の改善 運用負荷懸念について
開発T 対応優先度を決めて各チームと連携 アーキ側で各対応についてのハンドリングをして徐々に進めていくスタイルを実施 アーキテ クトT インフラT 1.システム負荷 モニタリング項目追加 スケール対策検討 アラート見直し
2.運用負荷 デプロイ改善 テスト環境拡張 3.品質劣化 設計/コードレビュー ..その他発生ベースで適宜 優先度判断 具体案検討 タスク化 適宜対応依頼
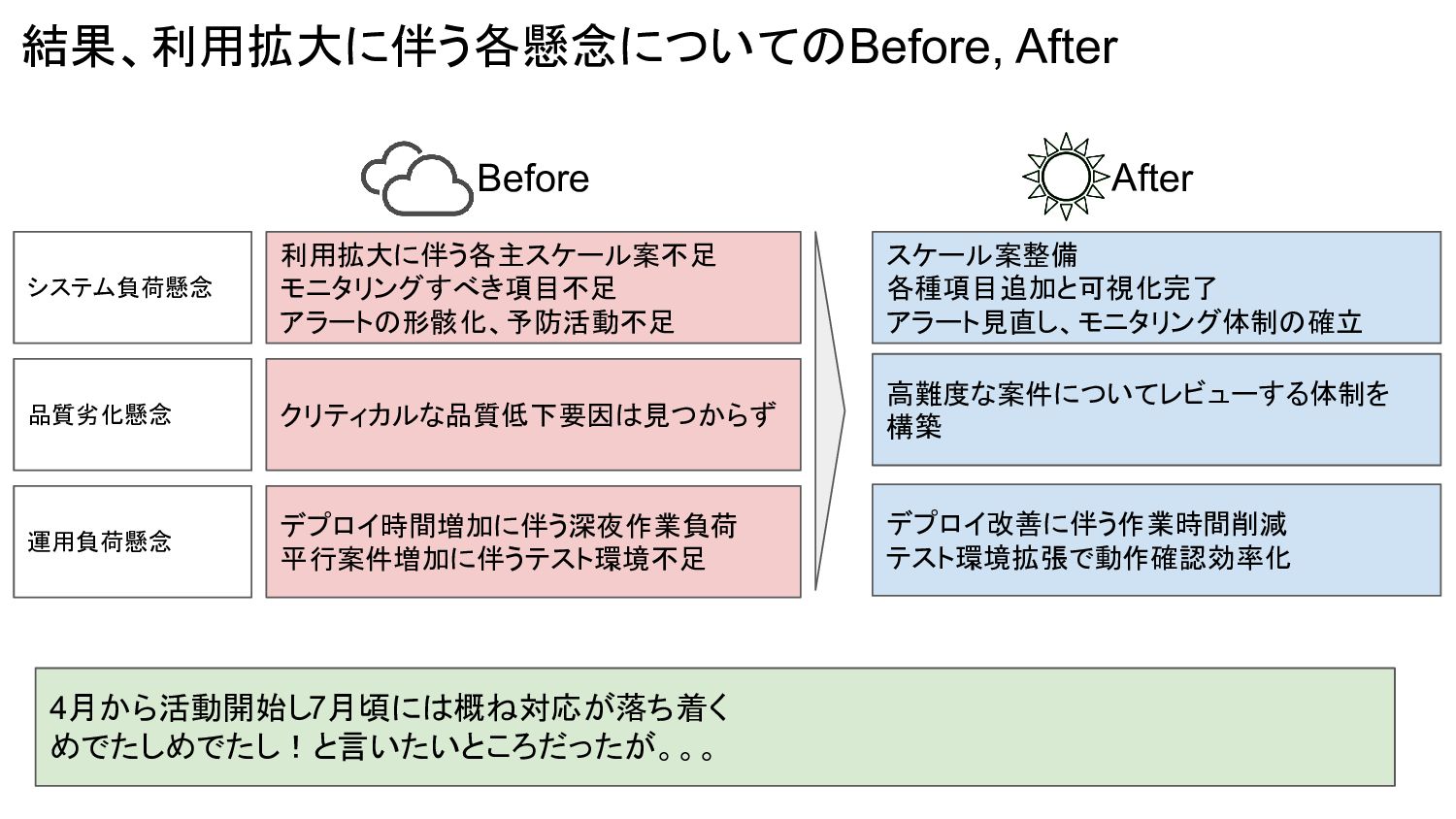
結果、利用拡大に伴う各懸念についてのBefore, After 4月から活動開始し7月頃には概ね対応が落ち着く めでたしめでたし!と言いたいところだったが。。。 システム負荷懸念 品質劣化懸念 運用負荷懸念 利用拡大に伴う各主スケール案不足 モニタリングすべき項目不足 アラートの形骸化、予防活動不足
スケール案整備 各種項目追加と可視化完了 アラート見直し、モニタリング体制の確立 クリティカルな品質低下要因は見つからず 高難度な案件についてレビューする体制を 構築 デプロイ時間増加に伴う深夜作業負荷 平行案件増加に伴うテスト環境不足 デプロイ改善に伴う作業時間削減 テスト環境拡張で動作確認効率化 Before After
参画前後の認識差異 システム面での改善はしたものの、現場の課題認識や対応不足が浮き彫りになった。 我々ががっつりサポートしなくても大丈夫な状態にできないのか? そもそもなぜこのような状態になっているのか? を考えてみることにした。 参画する前はこう考えてた 開発T: 現状こういう状態で、利用拡大に伴ってやばくなりそうな箇所はここです → 現場に課題認識があり技術難度の高いところを中心にフォロー
実際はこうだった 開発T: 利用拡大に伴いどうなるかわからない、、 サーバリソースのどこに響くのかとかよくわからない、、 → 現場での現状整理ができておらずここから実施が必要 → 直近の対策はできたとして、、今後大丈夫か?
第2章 チーム分析とDevOpsの実践
4~6月 7~9月 10~12月 1~2月 第1章 利用拡大に向けた 改善実施 第2章 チーム分析と DevOpsの実践
第3章 自立と連携への歩み出し 2021年 2022年
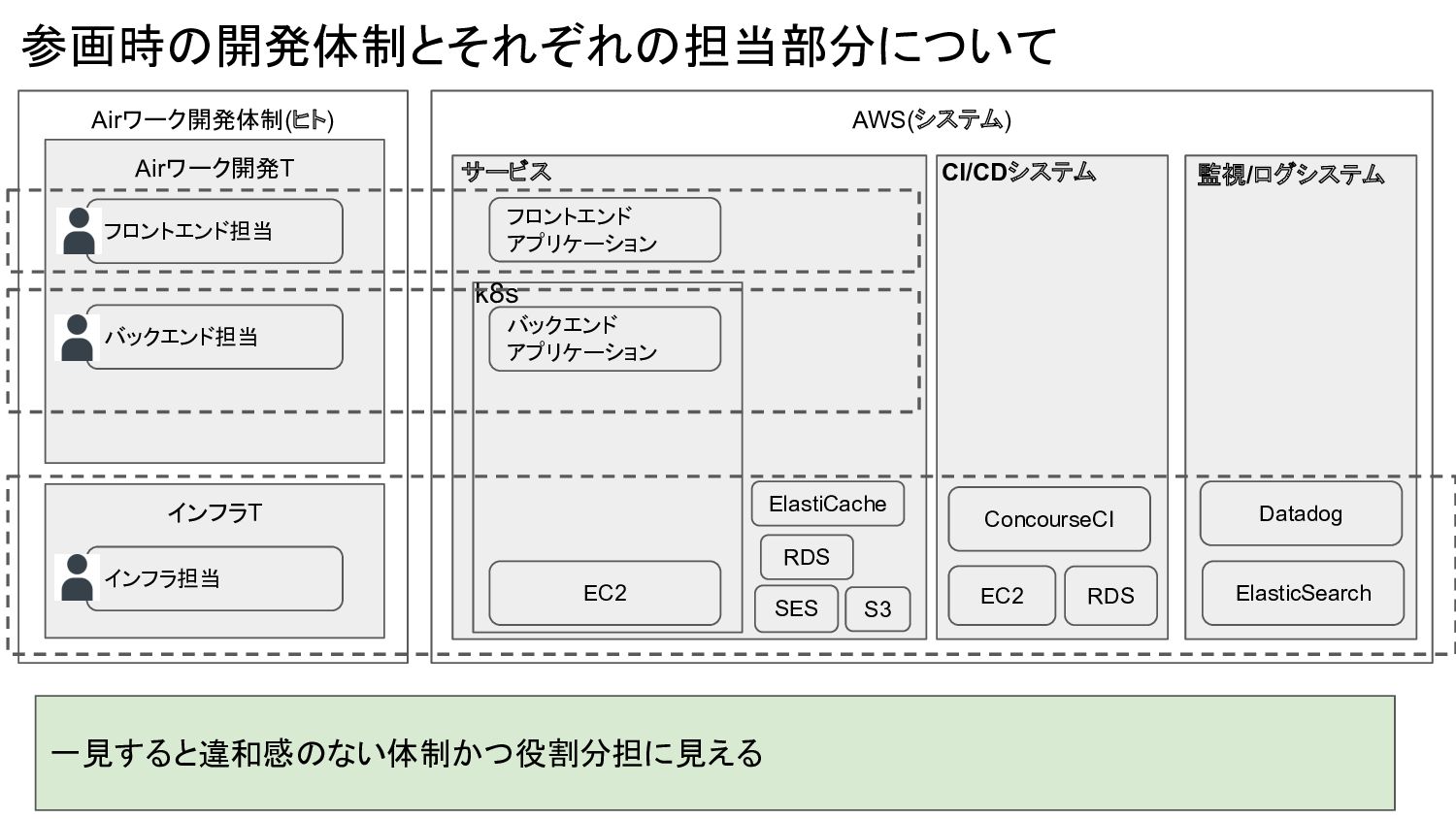
Airワーク開発体制(ヒト) AWS(システム) 参画時の開発体制とそれぞれの担当部分について 一見すると違和感のない体制かつ役割分担に見える Airワーク開発T バックエンド担当 フロントエンド担当 インフラT インフラ担当 EC2
バックエンド アプリケーション フロントエンド アプリケーション k8s S3 SES RDS ElastiCache サービス CI/CDシステム EC2 ConcourseCI RDS 監視/ログシステム Datadog ElasticSearch
Airワーク開発体制(ヒト) AWS(システム) 参画時の開発体制とそれぞれの担当部分について Airワーク開発T バックエンド担当 フロントエンド担当 インフラT インフラ担当 EC2 バックエンド
アプリケーション フロントエンド アプリケーション k8s S3 SES RDS ElastiCache サービス CI/CDシステム EC2 ConcourseCI RDS 監視/ログシステム Datadog ElasticSearch 実はサービス全体の運用の専任者はいない 問題発生ベースで全力対応はするが、予防や改善活動などまで手が回らない状態 インフラT ≠ 運用T リリース作業などの定常作業 は開発Tが担当
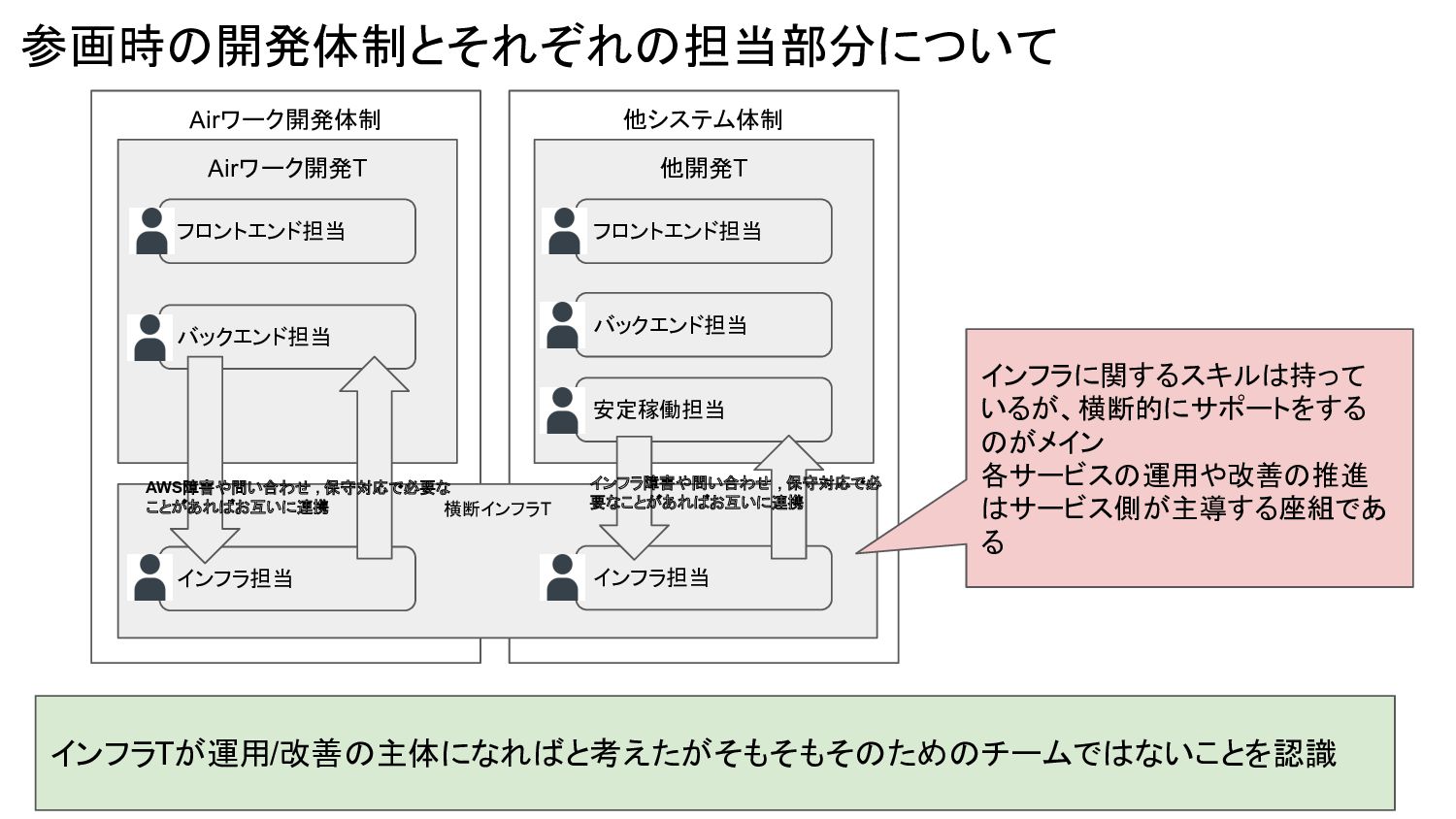
他システム体制 Airワーク開発体制 参画時の開発体制とそれぞれの担当部分について インフラTが運用/改善の主体になればと考えたがそもそもそのためのチームではないことを認識 Airワーク開発T バックエンド担当 フロントエンド担当 横断インフラT インフラ担当 他開発T
バックエンド担当 フロントエンド担当 安定稼働担当 インフラ担当 インフラ障害や問い合わせ , 保守対応で必 要なことがあればお互いに連携 AWS障害や問い合わせ , 保守対応で必要な ことがあればお互いに連携 インフラに関するスキルは持って いるが、横断的にサポートをする のがメイン 各サービスの運用や改善の推進 はサービス側が主導する座組であ る
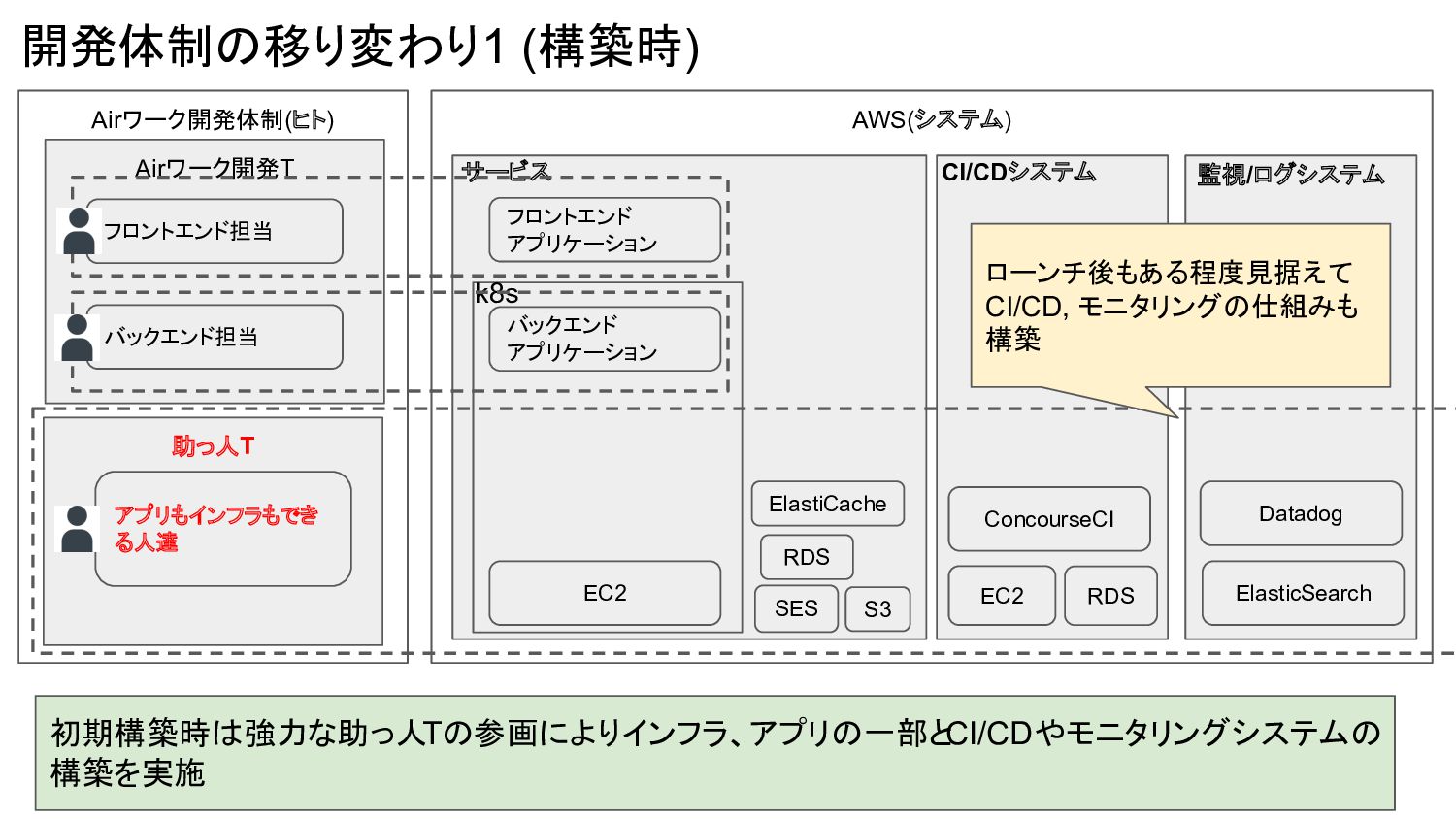
Airワーク開発体制(ヒト) AWS(システム) 開発体制の移り変わり1 (構築時) 初期構築時は強力な助っ人Tの参画によりインフラ、アプリの一部と CI/CDやモニタリングシステムの 構築を実施 Airワーク開発T バックエンド担当 フロントエンド担当
EC2 バックエンド アプリケーション フロントエンド アプリケーション k8s S3 SES RDS ElastiCache サービス CI/CDシステム EC2 ConcourseCI RDS 監視/ログシステム Datadog ElasticSearch 助っ人T アプリもインフラもでき る人達 ローンチ後もある程度見据えて CI/CD, モニタリングの仕組みも 構築
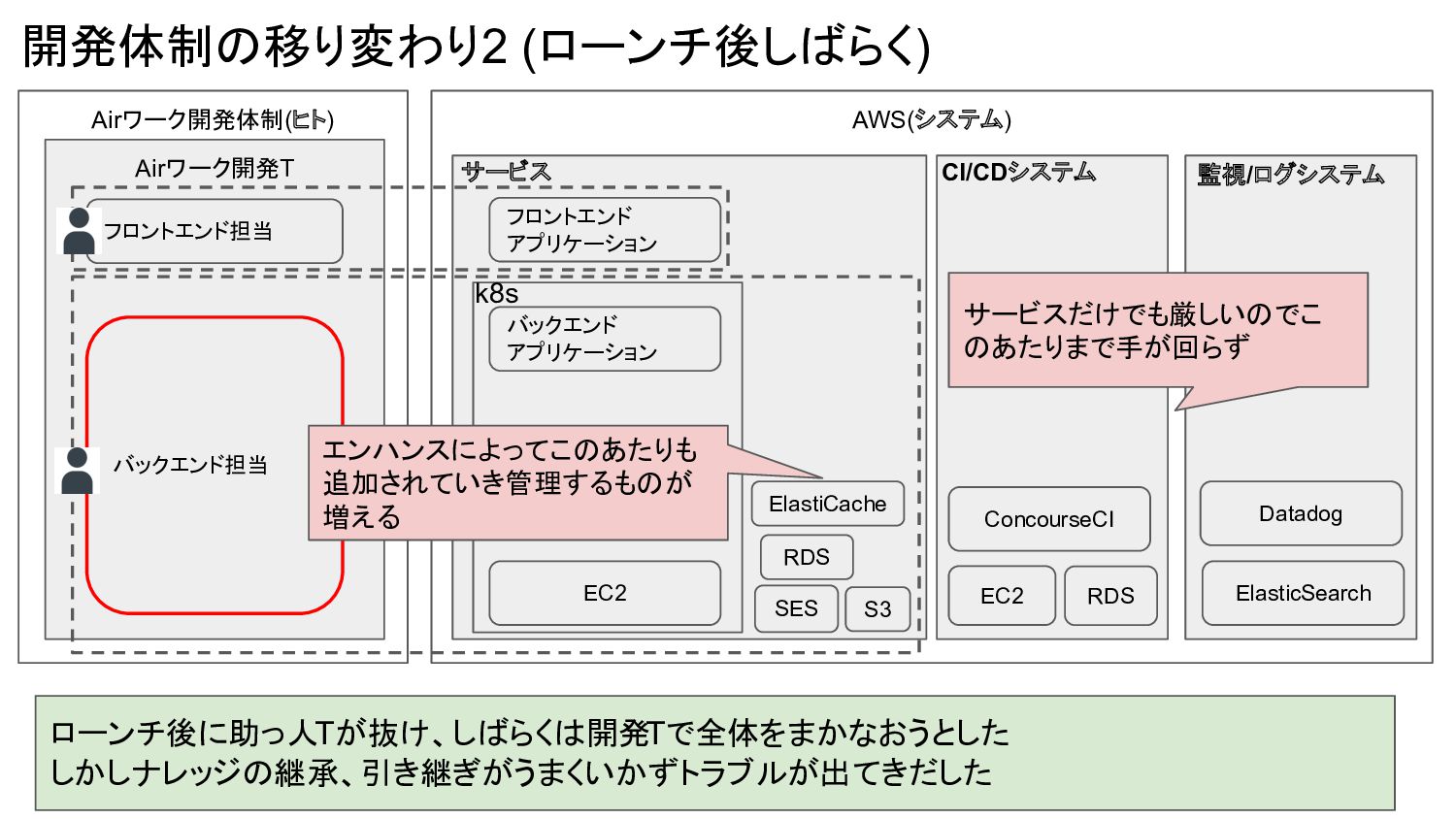
Airワーク開発体制(ヒト) AWS(システム) 開発体制の移り変わり2 (ローンチ後しばらく) ローンチ後に助っ人Tが抜け、しばらくは開発Tで全体をまかなおうとした しかしナレッジの継承、引き継ぎがうまくいかずトラブルが出てきだした Airワーク開発T バックエンド担当 フロントエンド担当 EC2
バックエンド アプリケーション フロントエンド アプリケーション k8s S3 SES RDS ElastiCache サービス CI/CDシステム EC2 ConcourseCI RDS 監視/ログシステム Datadog ElasticSearch サービスだけでも厳しいのでこ のあたりまで手が回らず エンハンスによってこのあたりも 追加されていき管理するものが 増える
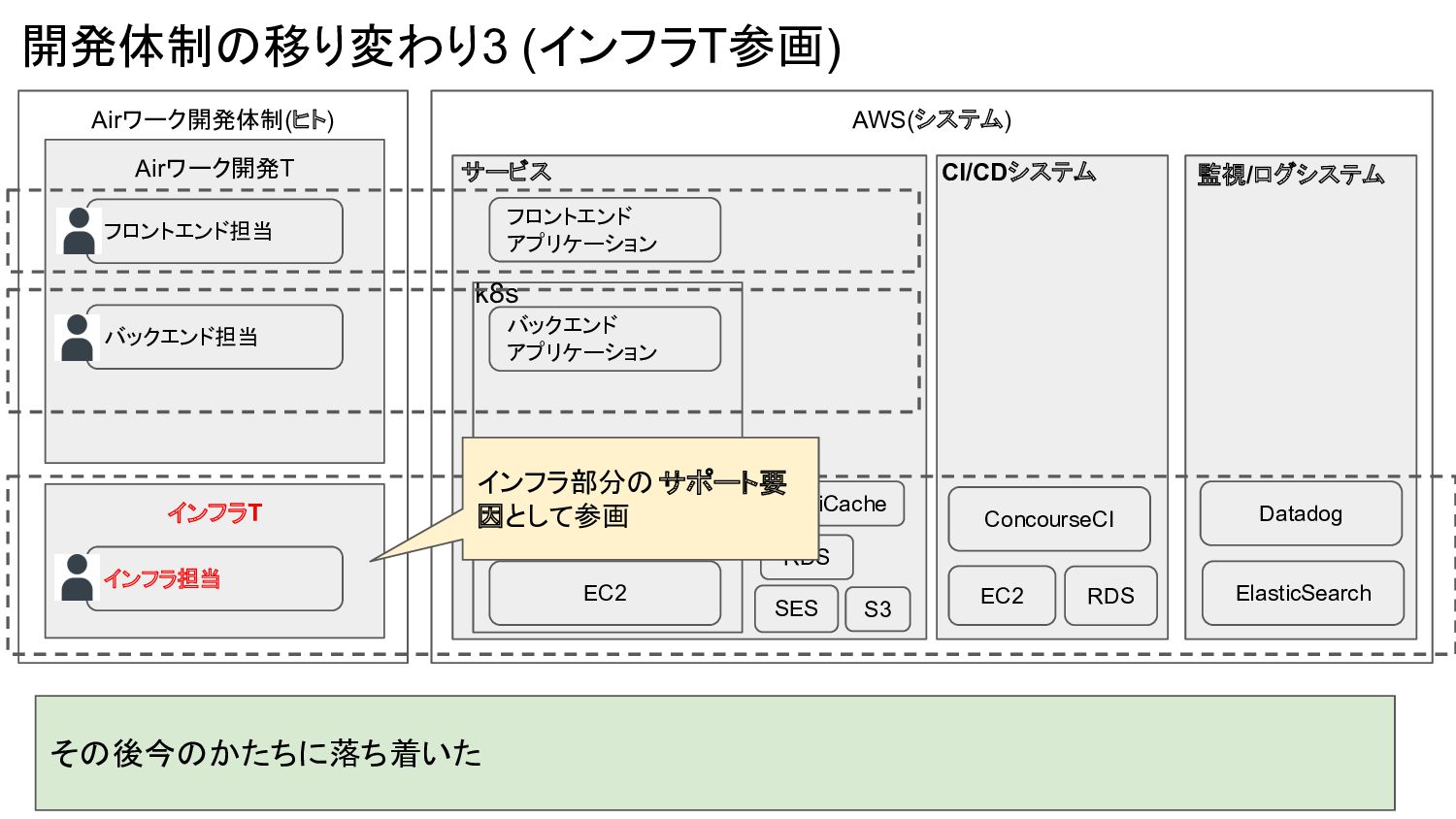
Airワーク開発体制(ヒト) AWS(システム) 開発体制の移り変わり3 (インフラT参画) その後今のかたちに落ち着いた Airワーク開発T バックエンド担当 フロントエンド担当 インフラT インフラ担当
EC2 バックエンド アプリケーション フロントエンド アプリケーション k8s S3 SES RDS ElastiCache サービス CI/CDシステム EC2 ConcourseCI RDS 監視/ログシステム Datadog ElasticSearch インフラ部分のサポート要 因として参画
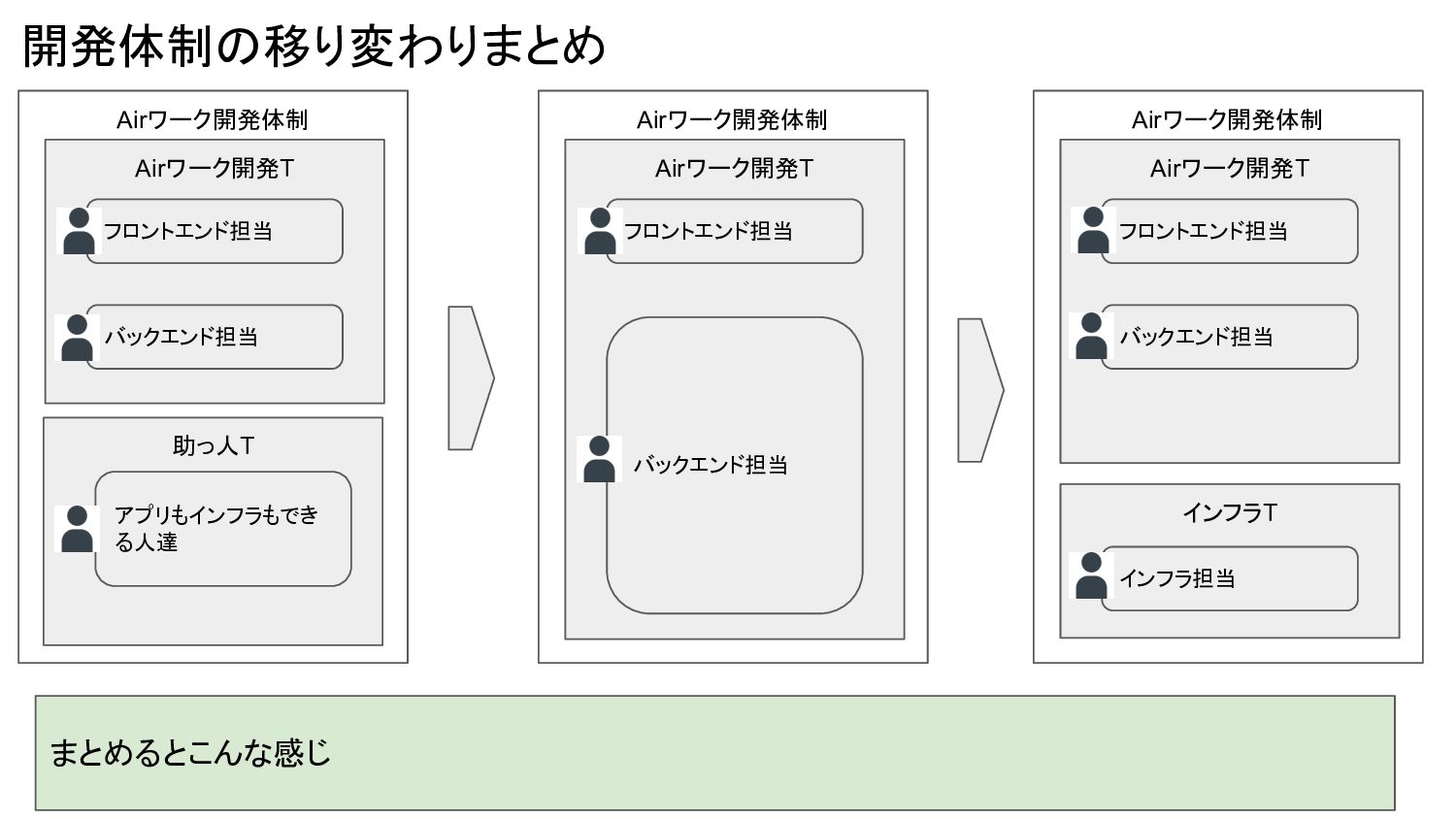
Airワーク開発体制 開発体制の移り変わりまとめ まとめるとこんな感じ Airワーク開発T バックエンド担当 フロントエンド担当 助っ人T アプリもインフラもでき る人達 Airワーク開発体制
Airワーク開発T バックエンド担当 フロントエンド担当 Airワーク開発体制 Airワーク開発T バックエンド担当 フロントエンド担当 インフラT インフラ担当
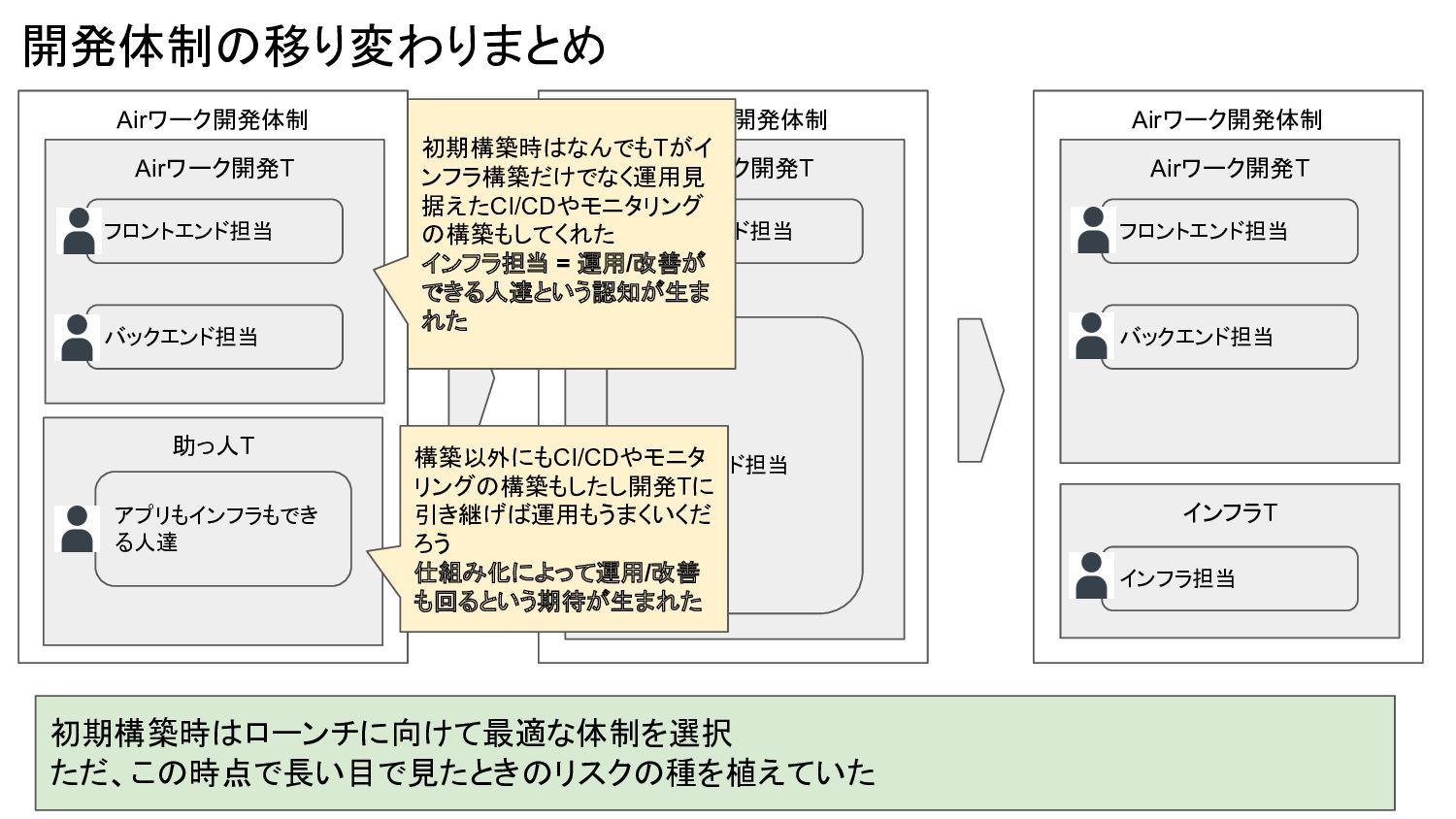
Airワーク開発体制 開発体制の移り変わりまとめ Airワーク開発T バックエンド担当 フロントエンド担当 助っ人T アプリもインフラもでき る人達 Airワーク開発体制 Airワーク開発T
バックエンド担当 フロントエンド担当 Airワーク開発体制 Airワーク開発T バックエンド担当 フロントエンド担当 インフラT インフラ担当 初期構築時はなんでもTがイ ンフラ構築だけでなく運用見 据えたCI/CDやモニタリング の構築もしてくれた インフラ担当 = 運用/改善が できる人達という認知が生ま れた 構築以外にもCI/CDやモニタ リングの構築もしたし開発Tに 引き継げば運用もうまくいくだ ろう 仕組み化によって運用/改善 も回るという期待が生まれた 初期構築時はローンチに向けて最適な体制を選択 ただ、この時点で長い目で見たときのリスクの種を植えていた
Airワーク開発体制 開発体制の移り変わりまとめ Airワーク開発T バックエンド担当 フロントエンド担当 助っ人T アプリもインフラもでき る人達 Airワーク開発体制 Airワーク開発T
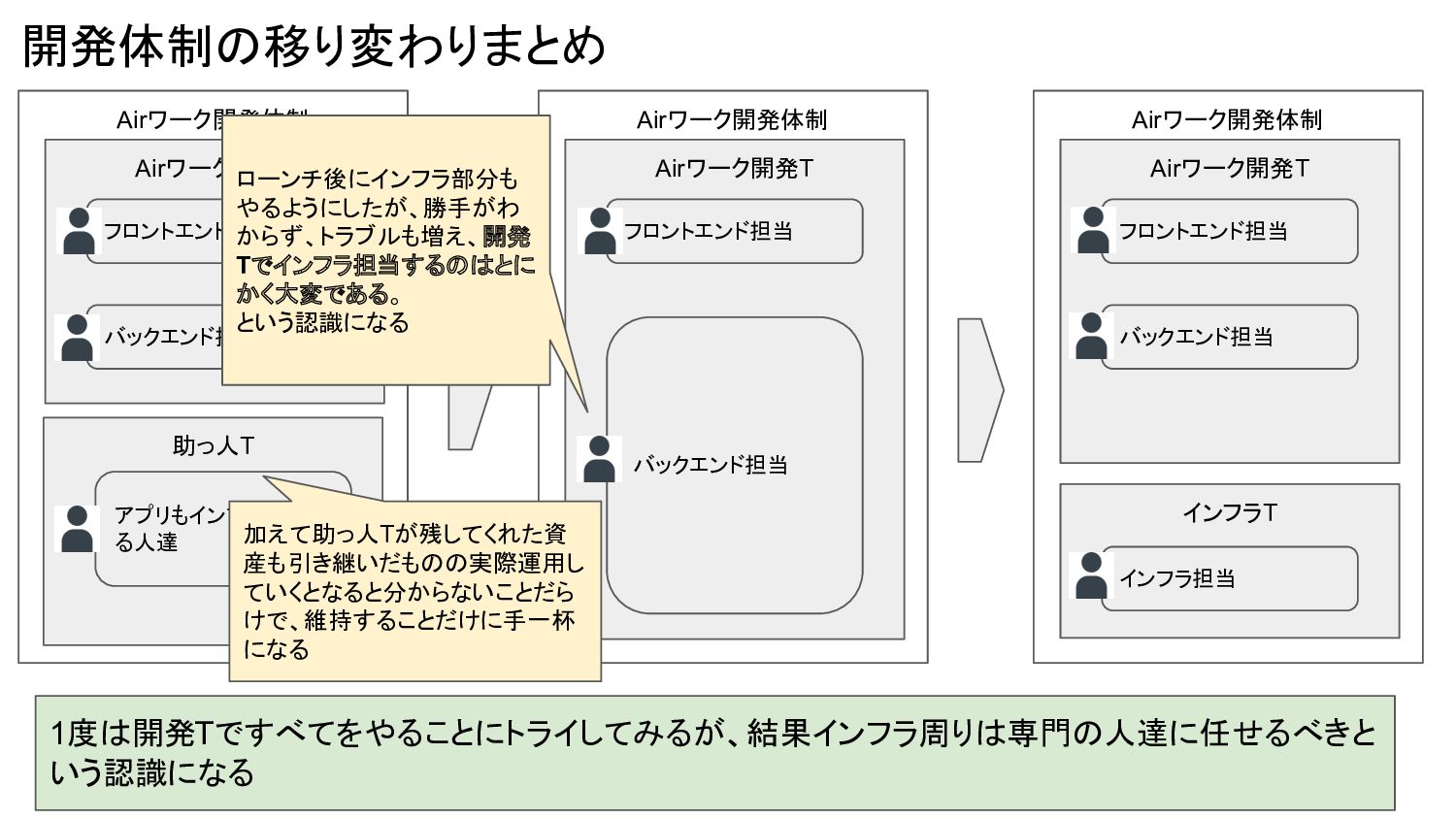
バックエンド担当 フロントエンド担当 Airワーク開発体制 Airワーク開発T バックエンド担当 フロントエンド担当 インフラT インフラ担当 ローンチ後にインフラ部分も やるようにしたが、勝手がわ からず、トラブルも増え、開発 Tでインフラ担当するのはとに かく大変である。 という認識になる 1度は開発Tですべてをやることにトライしてみるが、結果インフラ周りは専門の人達に任せるべきと いう認識になる 加えて助っ人Tが残してくれた資 産も引き継いだものの実際運用し ていくとなると分からないことだら けで、維持することだけに手一杯 になる
Airワーク開発体制 開発体制の移り変わりまとめ Airワーク開発T バックエンド担当 フロントエンド担当 助っ人T アプリもインフラもでき る人達 Airワーク開発体制 Airワーク開発T
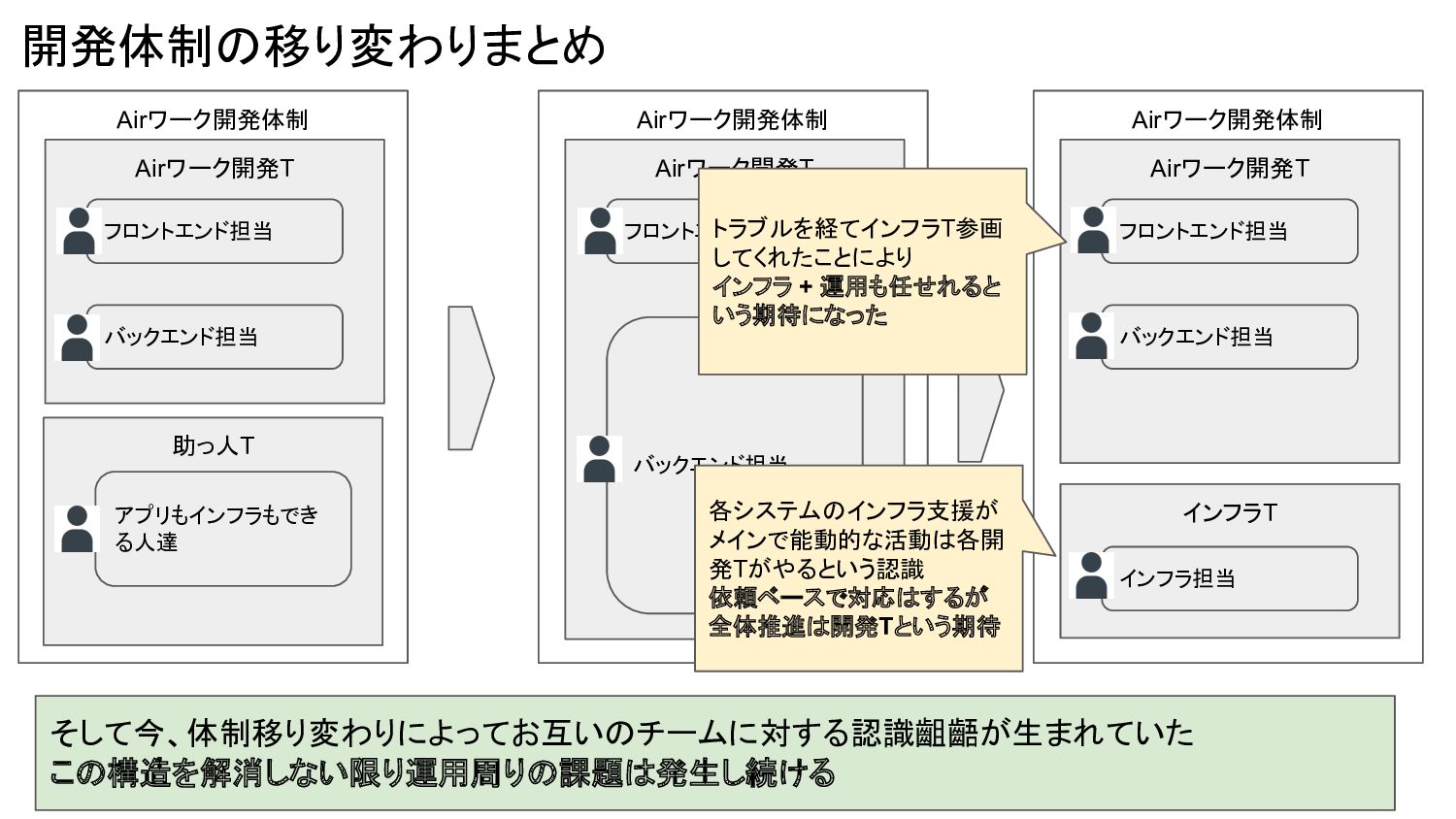
バックエンド担当 フロントエンド担当 Airワーク開発体制 Airワーク開発T バックエンド担当 フロントエンド担当 インフラT インフラ担当 そして今、体制移り変わりによってお互いのチームに対する認識齟齬が生まれていた この構造を解消しない限り運用周りの課題は発生し続ける トラブルを経てインフラT参画 してくれたことにより インフラ + 運用も任せれると いう期待になった 各システムのインフラ支援が メインで能動的な活動は各開 発Tがやるという認識 依頼ベースで対応はするが 全体推進は開発Tという期待
Airワーク開発体制(ヒト) AWS(システム) 実際の不安要素 Airワーク開発T バックエンド担当 フロントエンド担当 インフラT インフラ担当 EC2 バックエンド
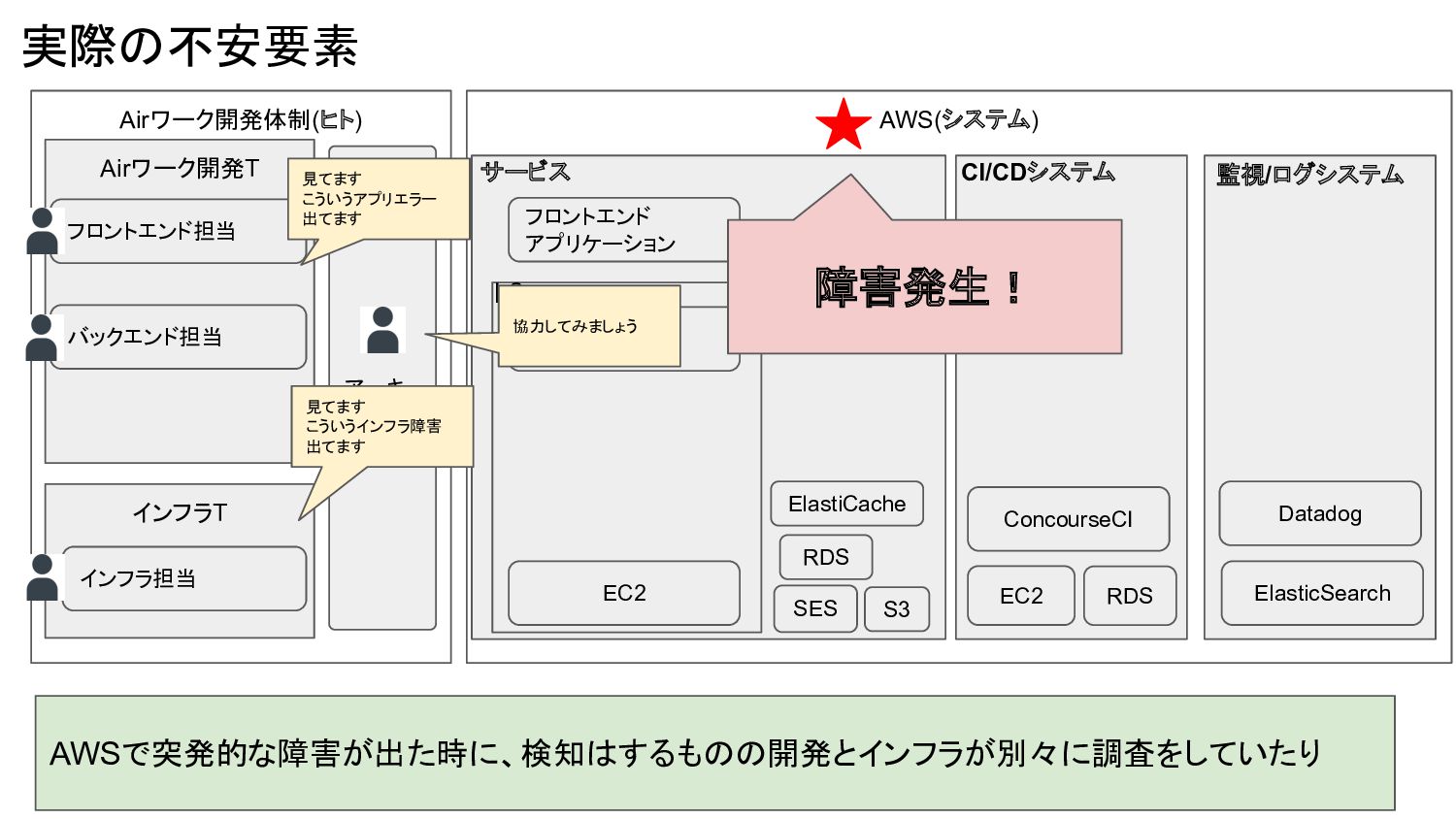
アプリケーション フロントエンド アプリケーション k8s S3 SES RDS ElastiCache サービス CI/CDシステム EC2 ConcourseCI RDS 監視/ログシステム Datadog ElasticSearch アーキ AWSで突発的な障害が出た時に、検知はするものの開発とインフラが別々に調査をしていたり 見てます こういうアプリエラー 出てます 見てます こういうインフラ障害 出てます 障害発生! 協力してみましょう
Airワーク開発体制(ヒト) AWS(システム) 実際の不安要素 Airワーク開発T バックエンド担当 フロントエンド担当 インフラT インフラ担当 EC2 バックエンド
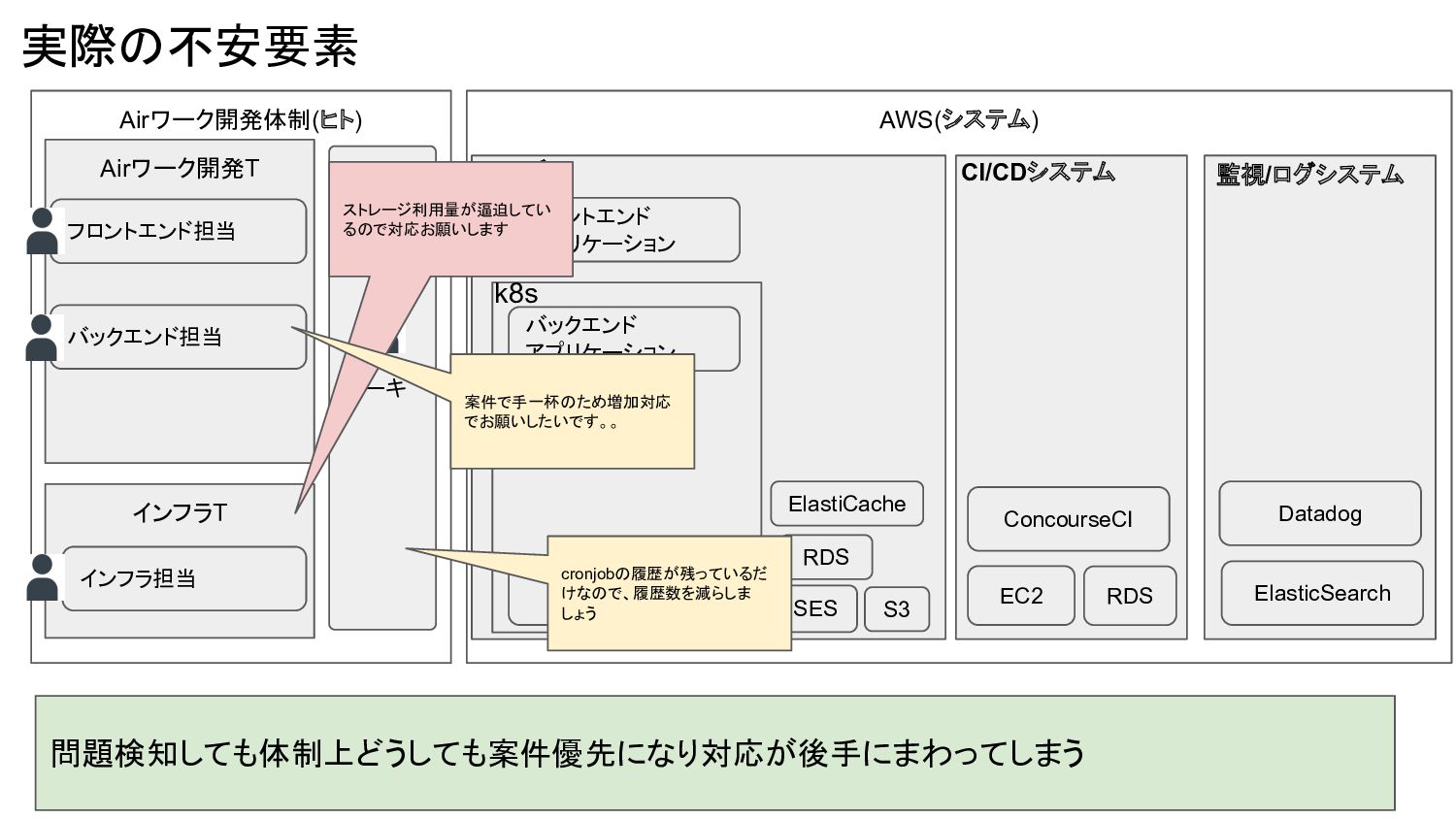
アプリケーション フロントエンド アプリケーション k8s S3 SES RDS ElastiCache サービス CI/CDシステム EC2 ConcourseCI RDS 監視/ログシステム Datadog ElasticSearch アーキ 問題検知しても体制上どうしても案件優先になり対応が後手にまわってしまう ストレージ利用量が逼迫してい るので対応お願いします 案件で手一杯のため増加対応 でお願いしたいです。。 cronjobの履歴が残っているだ けなので、履歴数を減らしま しょう
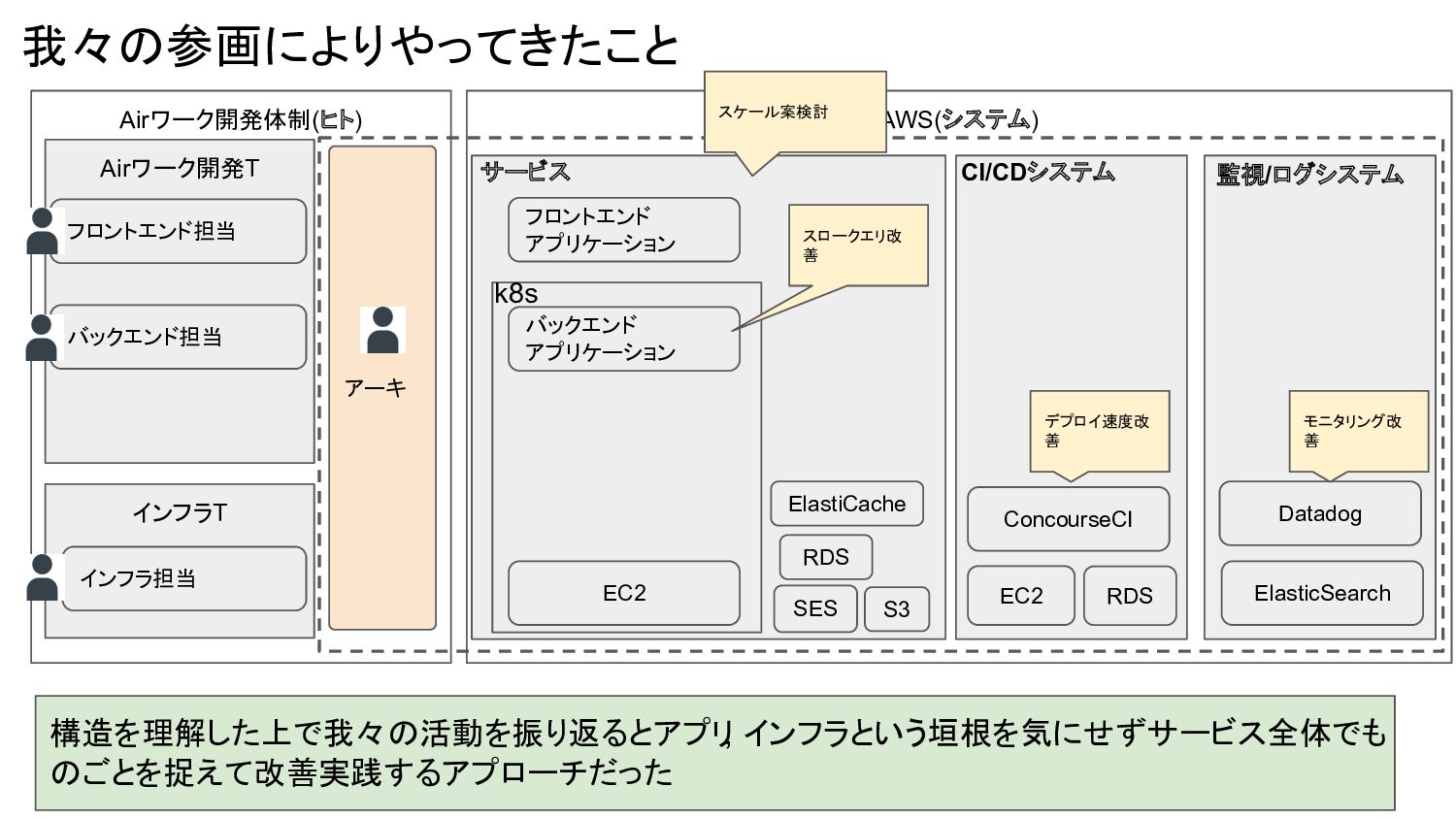
Airワーク開発体制(ヒト) AWS(システム) 我々の参画によりやってきたこと Airワーク開発T バックエンド担当 フロントエンド担当 インフラT インフラ担当 EC2 バックエンド
アプリケーション フロントエンド アプリケーション k8s S3 SES RDS ElastiCache サービス CI/CDシステム EC2 ConcourseCI RDS 監視/ログシステム Datadog ElasticSearch アーキ 構造を理解した上で我々の活動を振り返るとアプリ , インフラという垣根を気にせずサービス全体でも のごとを捉えて改善実践するアプローチだった デプロイ速度改 善 モニタリング改 善 スロークエリ改 善 スケール案検討
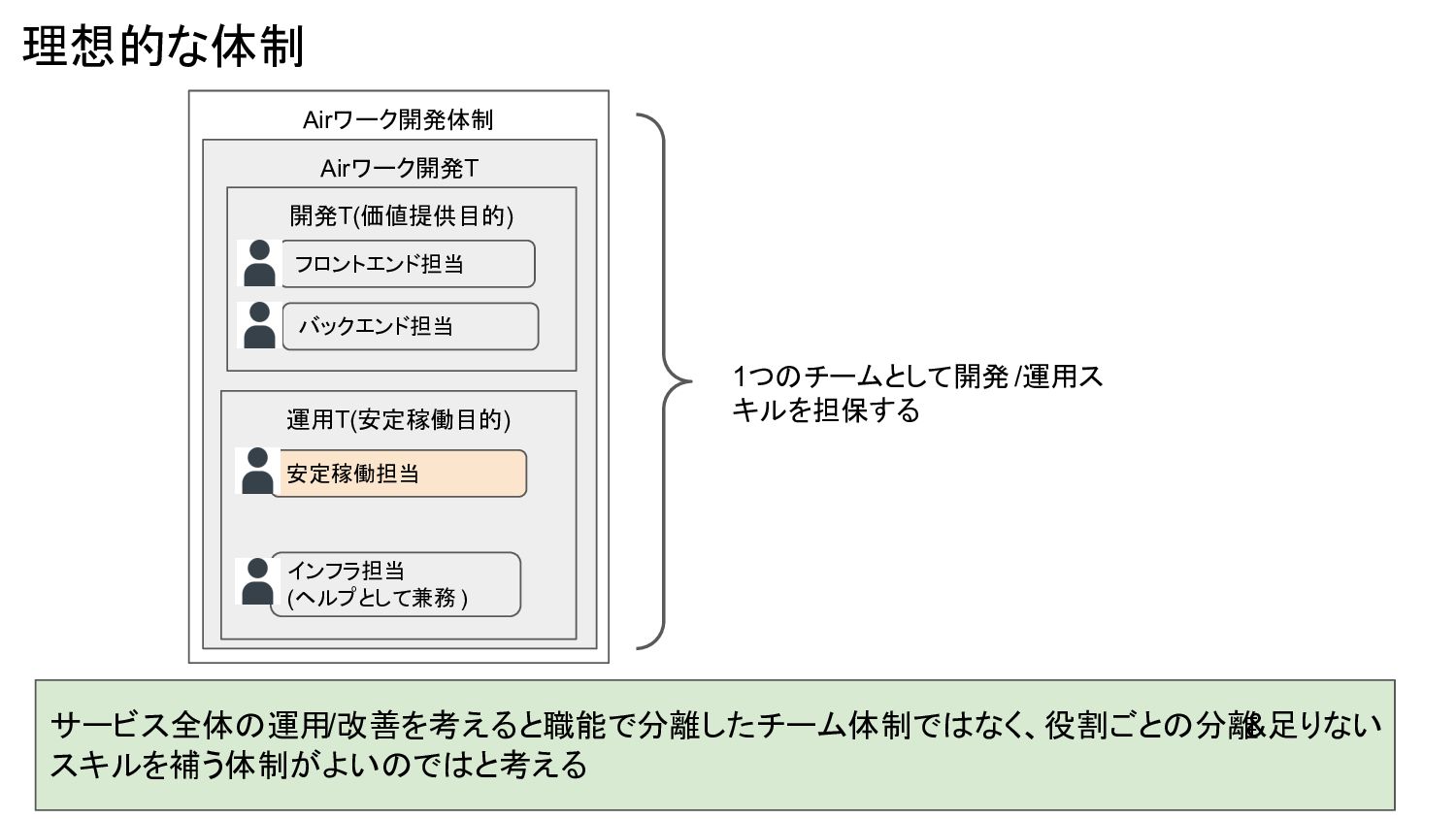
Airワーク開発体制 理想的な体制 Airワーク開発T サービス全体の運用/改善を考えると職能で分離したチーム体制ではなく、役割ごとの分離 &足りない スキルを補う体制がよいのではと考える 開発T(価値提供目的) 運用T(安定稼働目的) バックエンド担当 フロントエンド担当
安定稼働担当 インフラ担当 (ヘルプとして兼務 ) 1つのチームとして開発 /運用ス キルを担保する
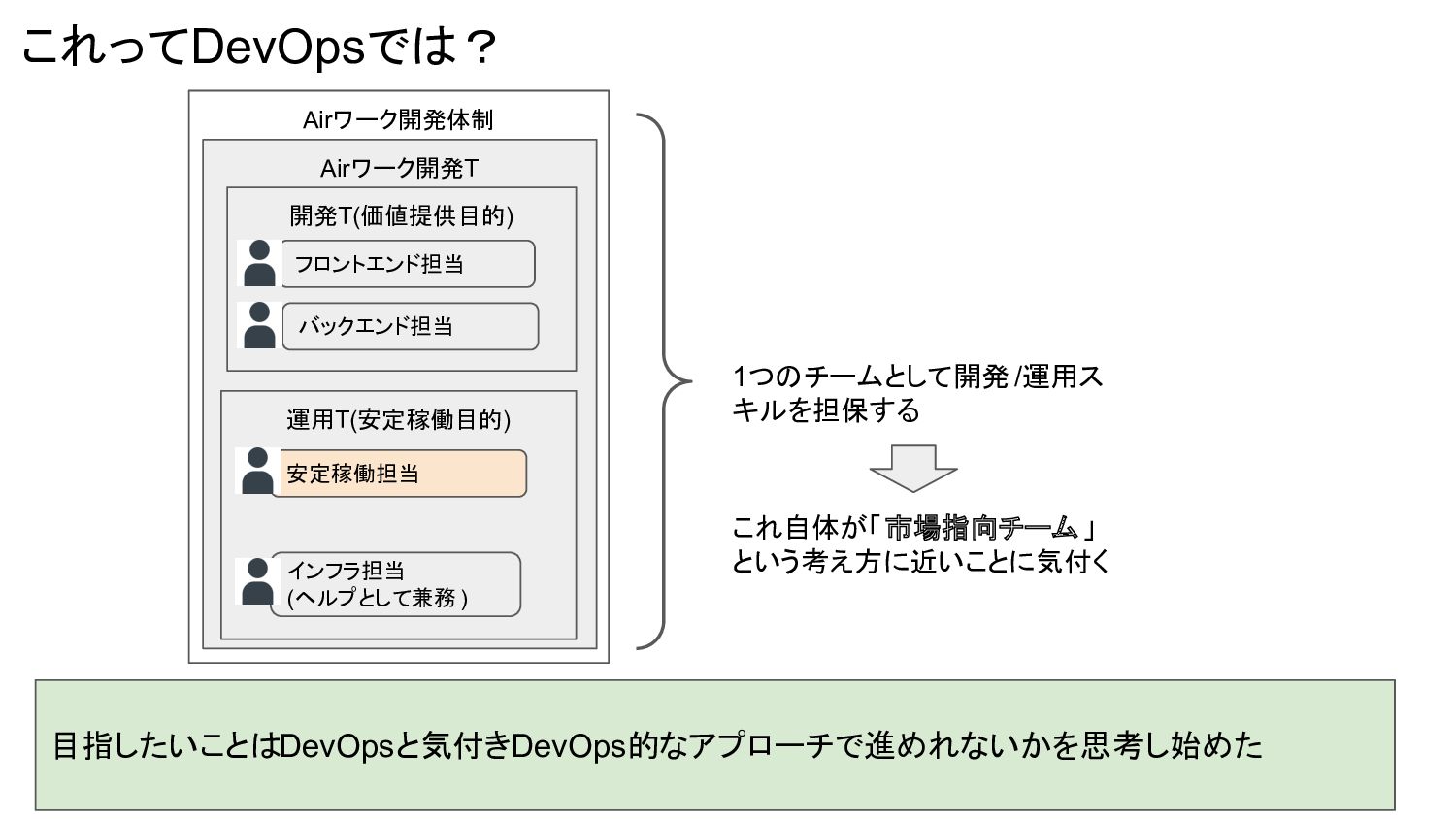
Airワーク開発体制 これってDevOpsでは? Airワーク開発T 目指したいことはDevOpsと気付きDevOps的なアプローチで進めれないかを思考し始めた 開発T(価値提供目的) 運用T(安定稼働目的) バックエンド担当 フロントエンド担当 安定稼働担当 インフラ担当
(ヘルプとして兼務 ) 1つのチームとして開発 /運用ス キルを担保する これ自体が「市場指向チーム」 という考え方に近いことに気付く
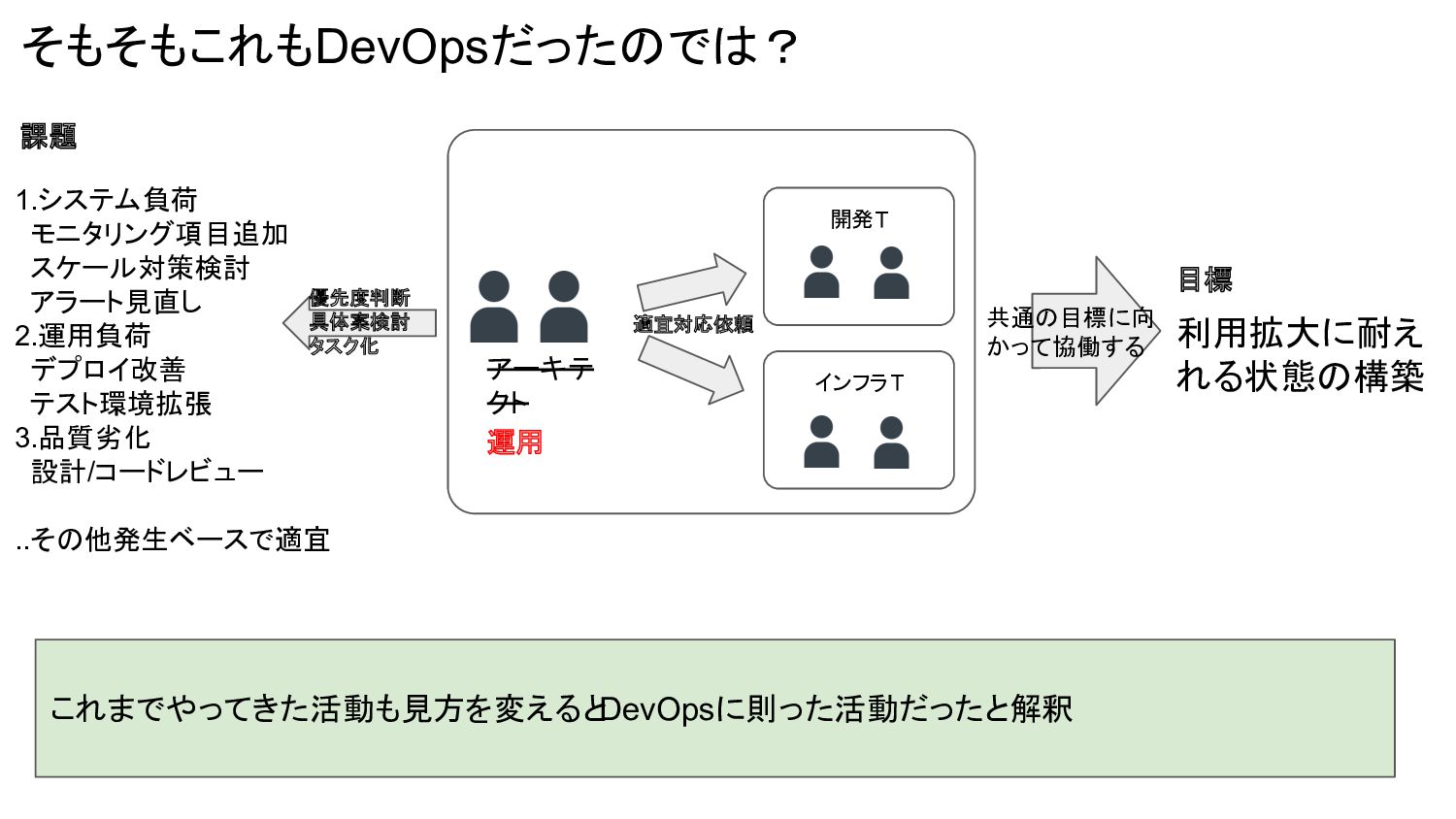
開発T そもそもこれもDevOpsだったのでは? これまでやってきた活動も見方を変えると DevOpsに則った活動だったと解釈 アーキテ クト インフラT 1.システム負荷 モニタリング項目追加 スケール対策検討
アラート見直し 2.運用負荷 デプロイ改善 テスト環境拡張 3.品質劣化 設計/コードレビュー ..その他発生ベースで適宜 優先度判断 具体案検討 タスク化 適宜対応依頼 運用 課題 目標 利用拡大に耐え れる状態の構築 共通の目標に向 かって協働する
DevOpsの原則である3つの道を考える バリューストリームの理解も気になったが今の状態では なぜ改善するかを理解すること そのうえで改善を根付かせること の2点が重要と判断 1. フローの原則 CI/CDといった仕組みはすでにある 週1回リリースサイクルだがこれが遅いという話は出ていない 2.
フィードバックの原則 自動テストの仕組みはすでにある モニタリングにやや不備があったが改善済み 3. 継続的な学習と実験の原則 圧倒的にここが不足している 開発作業がメインだったため日常業務の改善をしたり、今の状態や目指すべきものといった 考え方がそもそもない
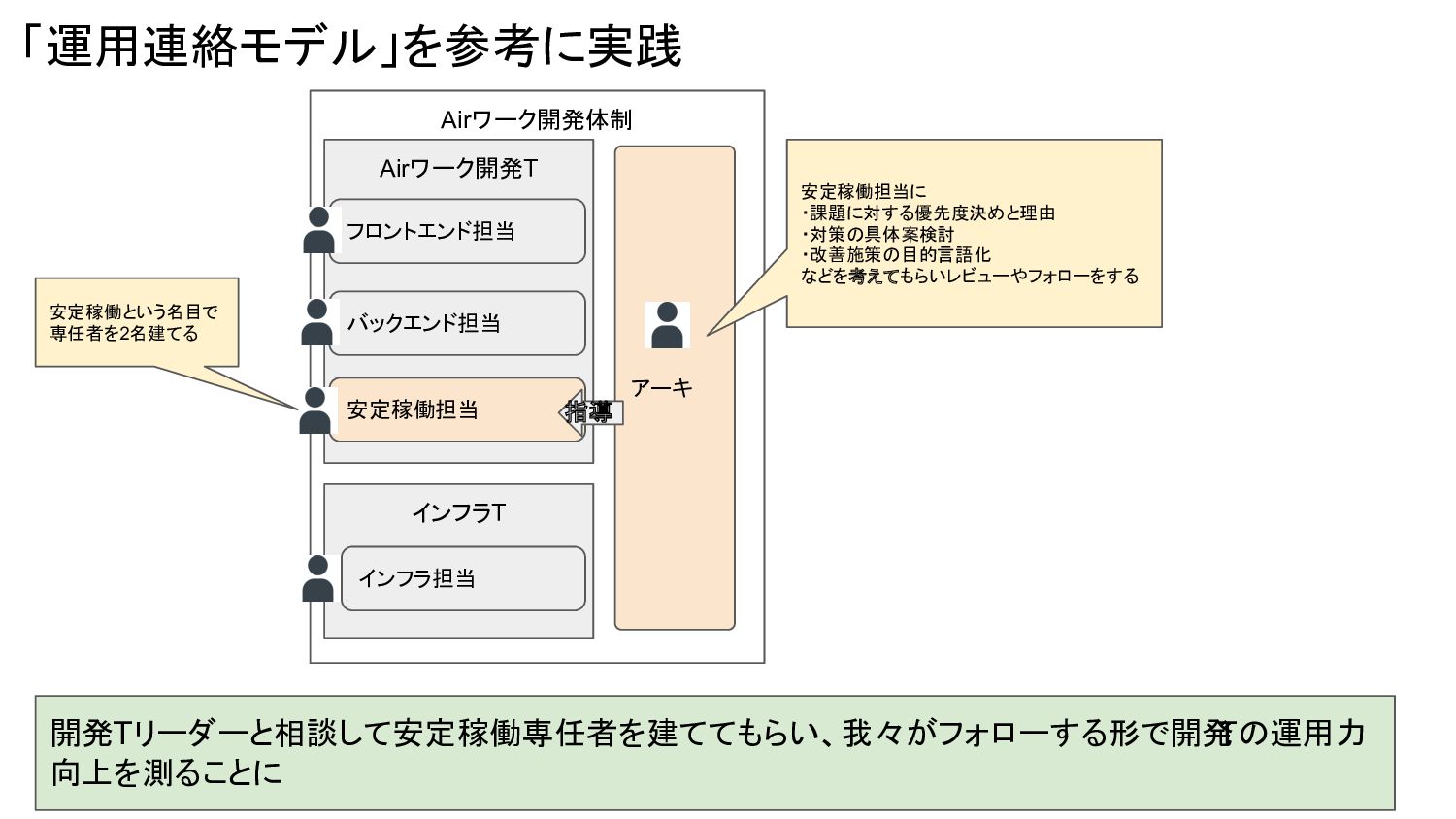
Airワーク開発体制 「運用連絡モデル」を参考に実践 Airワーク開発T バックエンド担当 フロントエンド担当 インフラT インフラ担当 アーキ 開発Tリーダーと相談して安定稼働専任者を建ててもらい、我々がフォローする形で開発 Tの運用力
向上を測ることに 安定稼働担当 指導 安定稼働担当に ・課題に対する優先度決めと理由 ・対策の具体案検討 ・改善施策の目的言語化 などを考えてもらいレビューやフォローをする 安定稼働という名目で 専任者を2名建てる
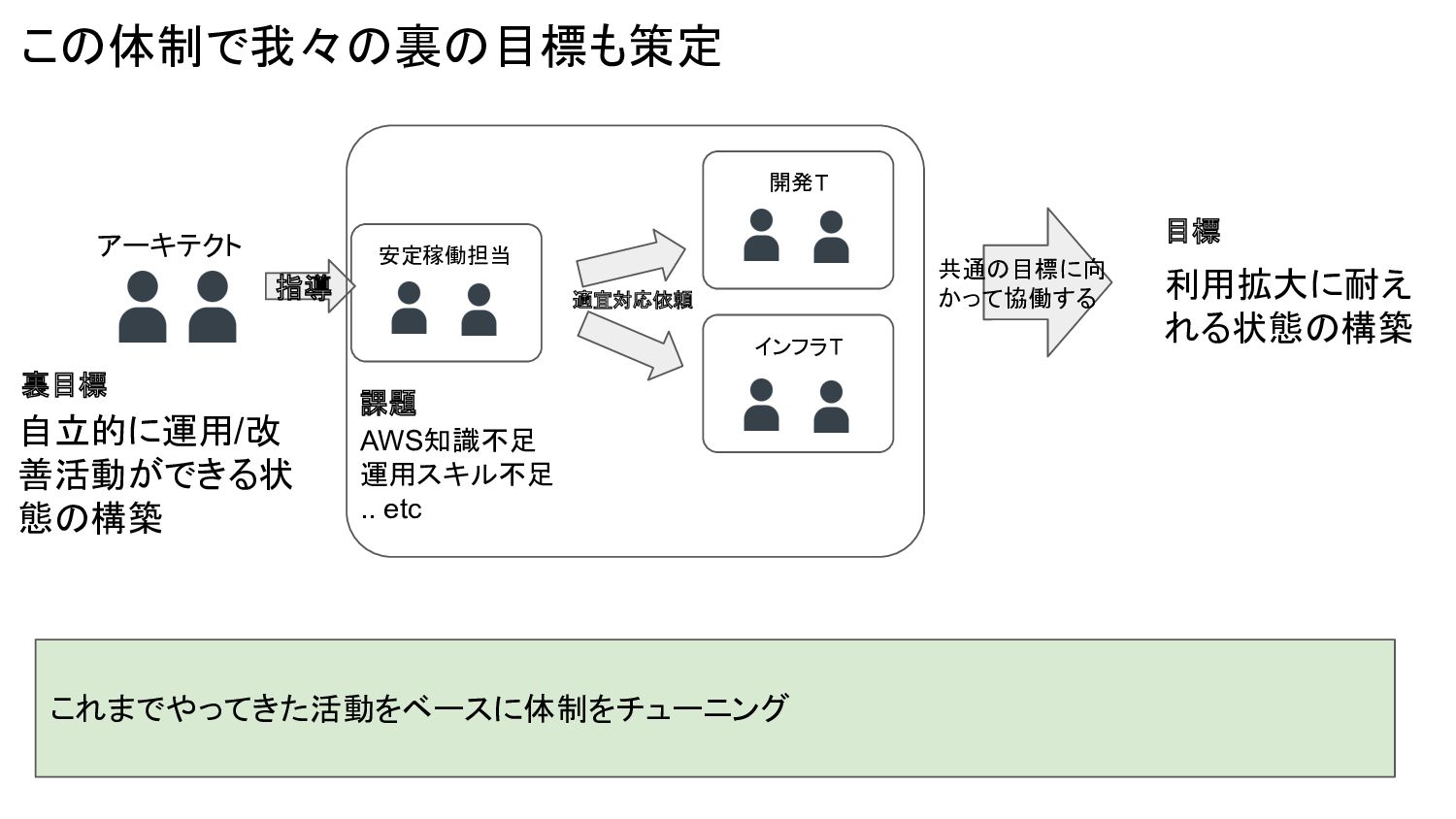
開発T この体制で我々の裏の目標も策定 これまでやってきた活動をベースに体制をチューニング アーキテクト インフラT AWS知識不足 運用スキル不足 .. etc 適宜対応依頼
目標 利用拡大に耐え れる状態の構築 共通の目標に向 かって協働する 裏目標 自立的に運用/改 善活動ができる状 態の構築 安定稼働担当 指導 課題
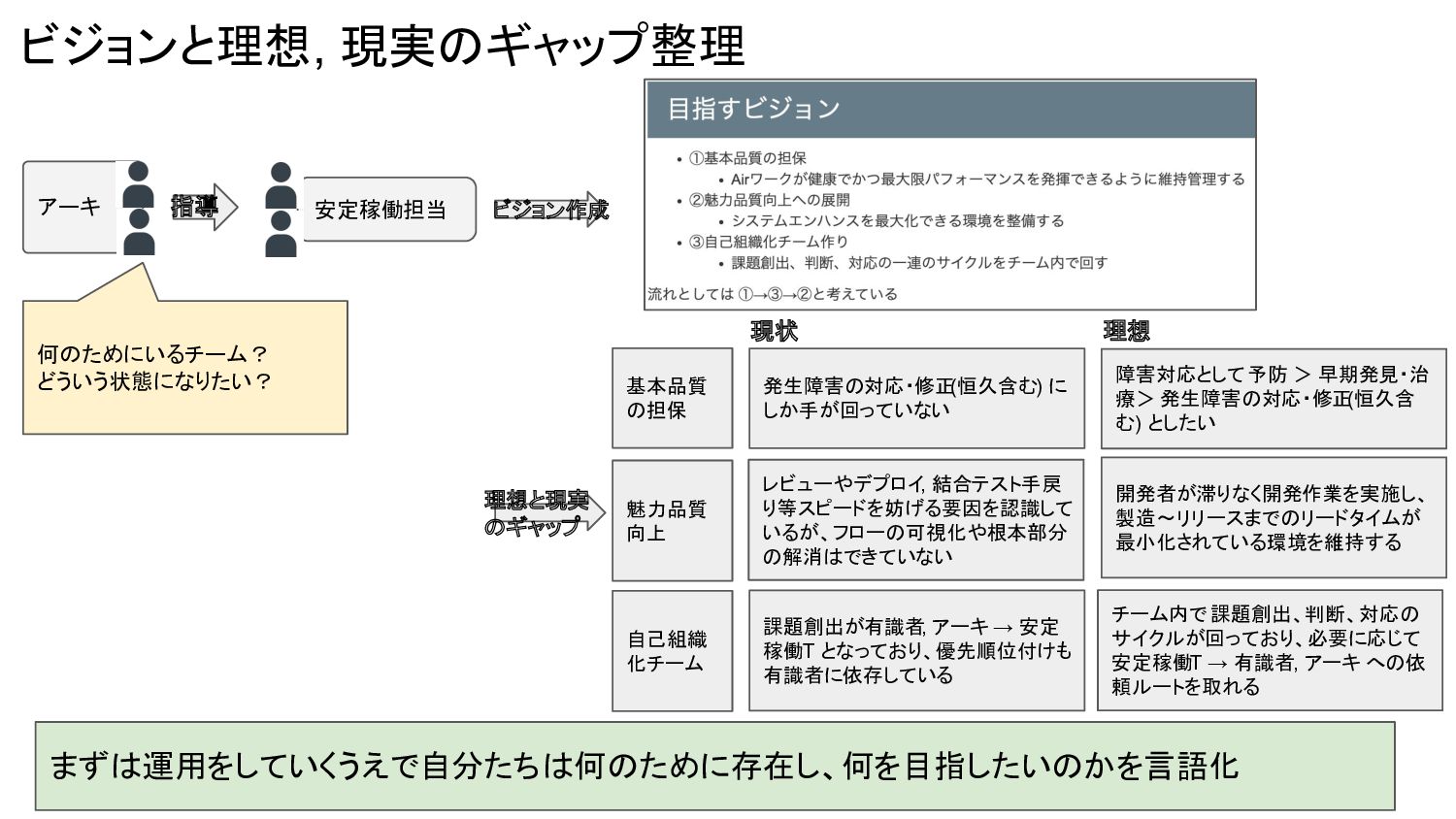
ビジョンと理想, 現実のギャップ整理 アーキ まずは運用をしていくうえで自分たちは何のために存在し、何を目指したいのかを言語化 安定稼働担当 指導 ビジョン作成 何のためにいるチーム? どういう状態になりたい? 理想と現実
のギャップ 発生障害の対応・修正 (恒久含む) に しか手が回っていない 障害対応として 予防 > 早期発見・治 療> 発生障害の対応・修正 (恒久含 む) としたい 現状 理想 レビューやデプロイ, 結合テスト手戻 り等スピードを妨げる要因を認識して いるが、フローの可視化や根本部分 の解消はできていない 課題創出が有識者, アーキ → 安定 稼働T となっており、優先順位付けも 有識者に依存している チーム内で 課題創出、判断、対応の サイクルが回っており、必要に応じて 安定稼働T → 有識者, アーキ への依 頼ルートを取れる 開発者が滞りなく開発作業を実施し、 製造〜リリースまでのリードタイムが 最小化されている環境を維持する 基本品質 の担保 魅力品質 向上 自己組織 化チーム
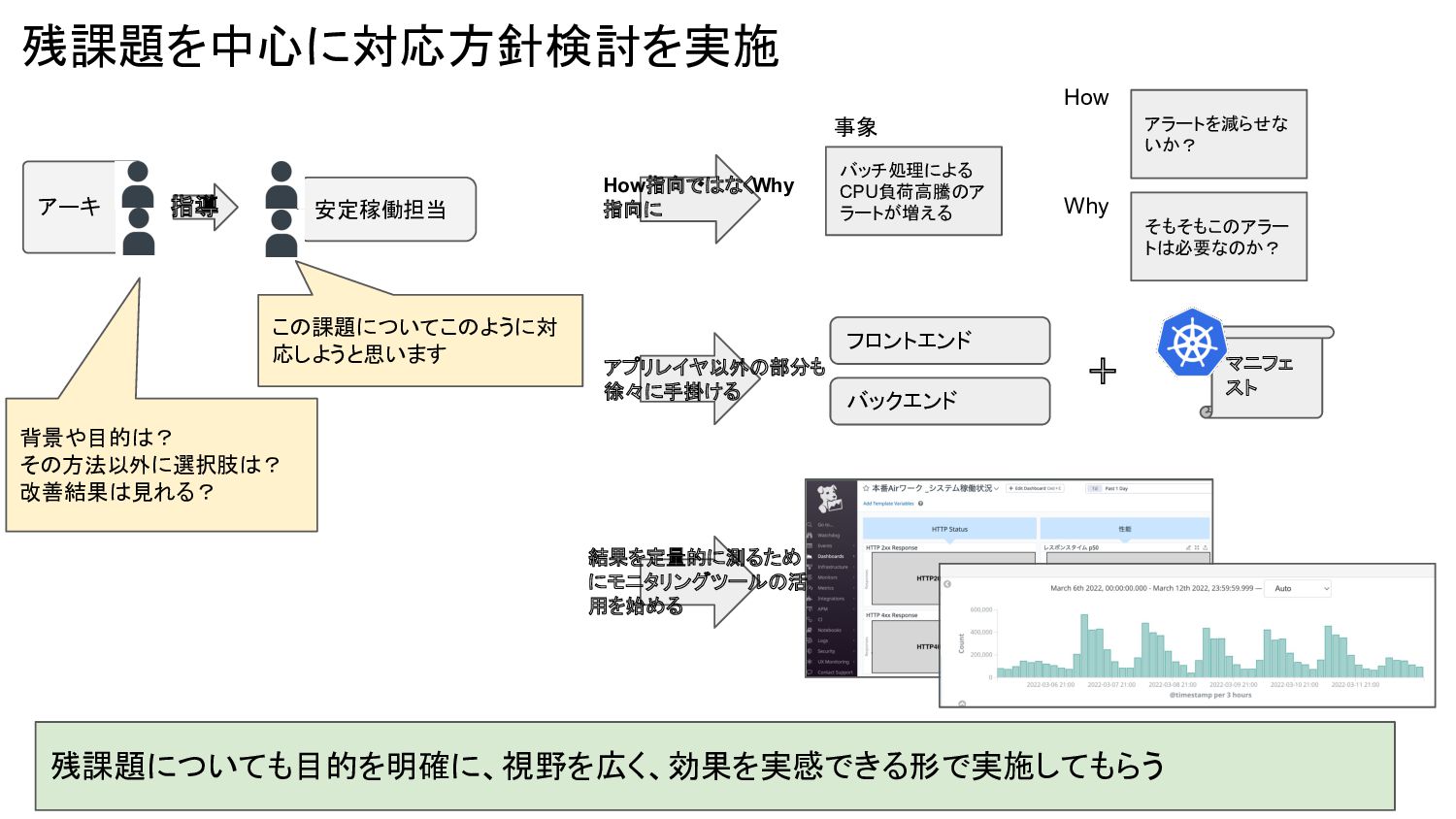
残課題を中心に対応方針検討を実施 残課題についても目的を明確に、視野を広く、効果を実感できる形で実施してもらう マニフェ スト フロントエンド バックエンド + アプリレイヤ以外の部分も 徐々に手掛ける 結果を定量的に測るため
にモニタリングツールの活 用を始める How指向ではなくWhy 指向に バッチ処理による CPU負荷高騰のア ラートが増える アラートを減らせな いか? そもそもこのアラー トは必要なのか? 事象 How Why アーキ 安定稼働担当 指導 この課題についてこのように対 応しようと思います 背景や目的は? その方法以外に選択肢は? 改善結果は見れる?
徐々に起き始める変化 安定稼働のために徐々に主体的な動きが出てくるようになる アーキ 安定稼働担当 このアラート最近頻発してるの で調査と対策優先させたいで す いいね! 調査するにはこういうところ見 るといいよ
この障害については振り返り 必要だと思うので実施します ポストモーテムとか参考にし て、仕組みで対策できないかな ど考えてみてください
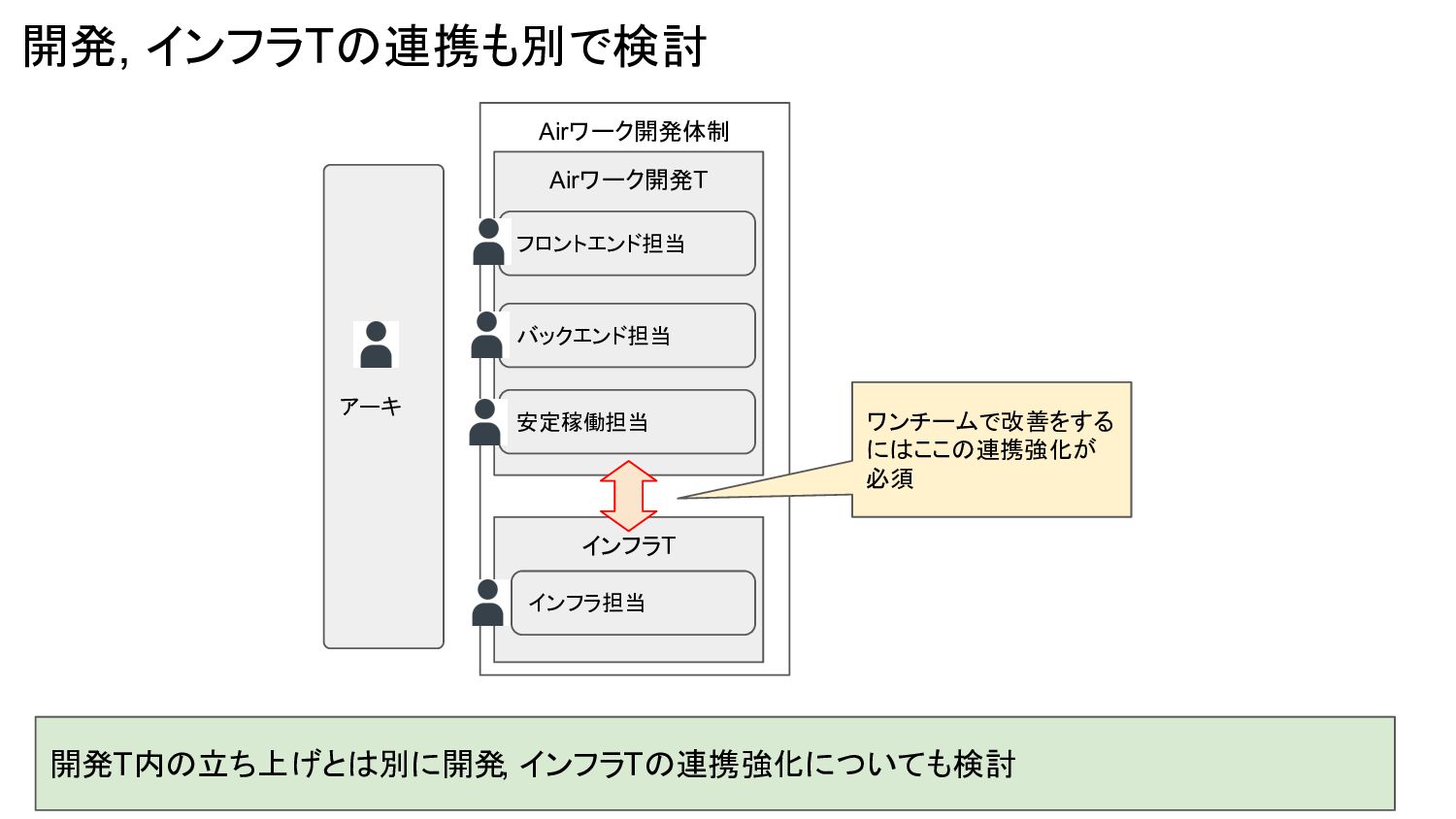
開発, インフラTの連携も別で検討 開発T内の立ち上げとは別に開発, インフラTの連携強化についても検討 Airワーク開発体制 Airワーク開発T バックエンド担当 フロントエンド担当 インフラT インフラ担当
アーキ 安定稼働担当 ワンチームで改善をする にはここの連携強化が 必須
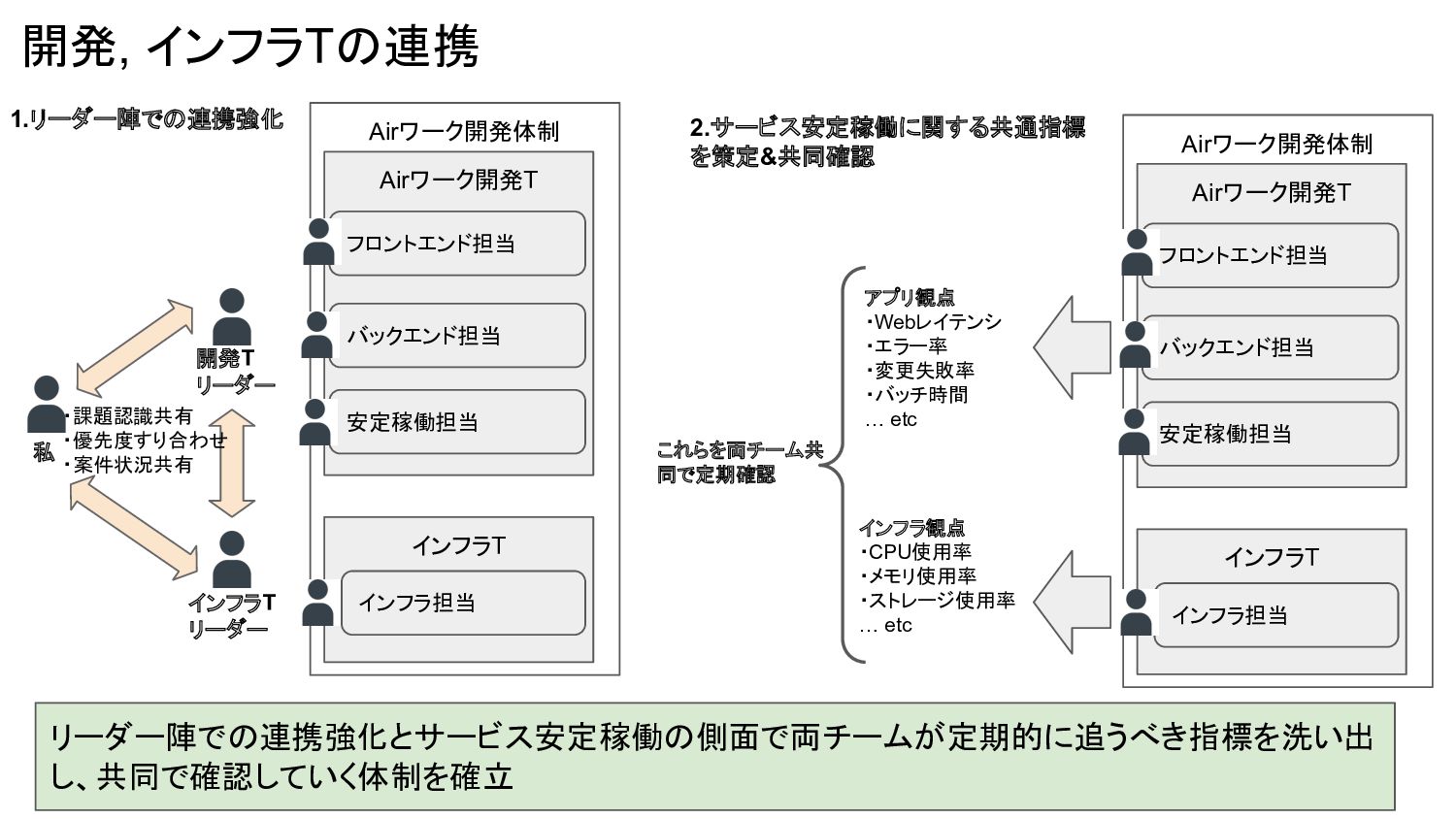
開発, インフラTの連携 リーダー陣での連携強化とサービス安定稼働の側面で両チームが定期的に追うべき指標を洗い出 し、共同で確認していく体制を確立 Airワーク開発体制 Airワーク開発T バックエンド担当 フロントエンド担当 インフラT インフラ担当
安定稼働担当 開発T リーダー インフラT リーダー 私 ・課題認識共有 ・優先度すり合わせ ・案件状況共有 Airワーク開発体制 Airワーク開発T バックエンド担当 フロントエンド担当 インフラT インフラ担当 安定稼働担当 インフラ観点 ・CPU使用率 ・メモリ使用率 ・ストレージ使用率 … etc アプリ観点 ・Webレイテンシ ・エラー率 ・変更失敗率 ・バッチ時間 … etc 1.リーダー陣での連携強化 2.サービス安定稼働に関する共通指標 を策定&共同確認 これらを両チーム共 同で定期確認
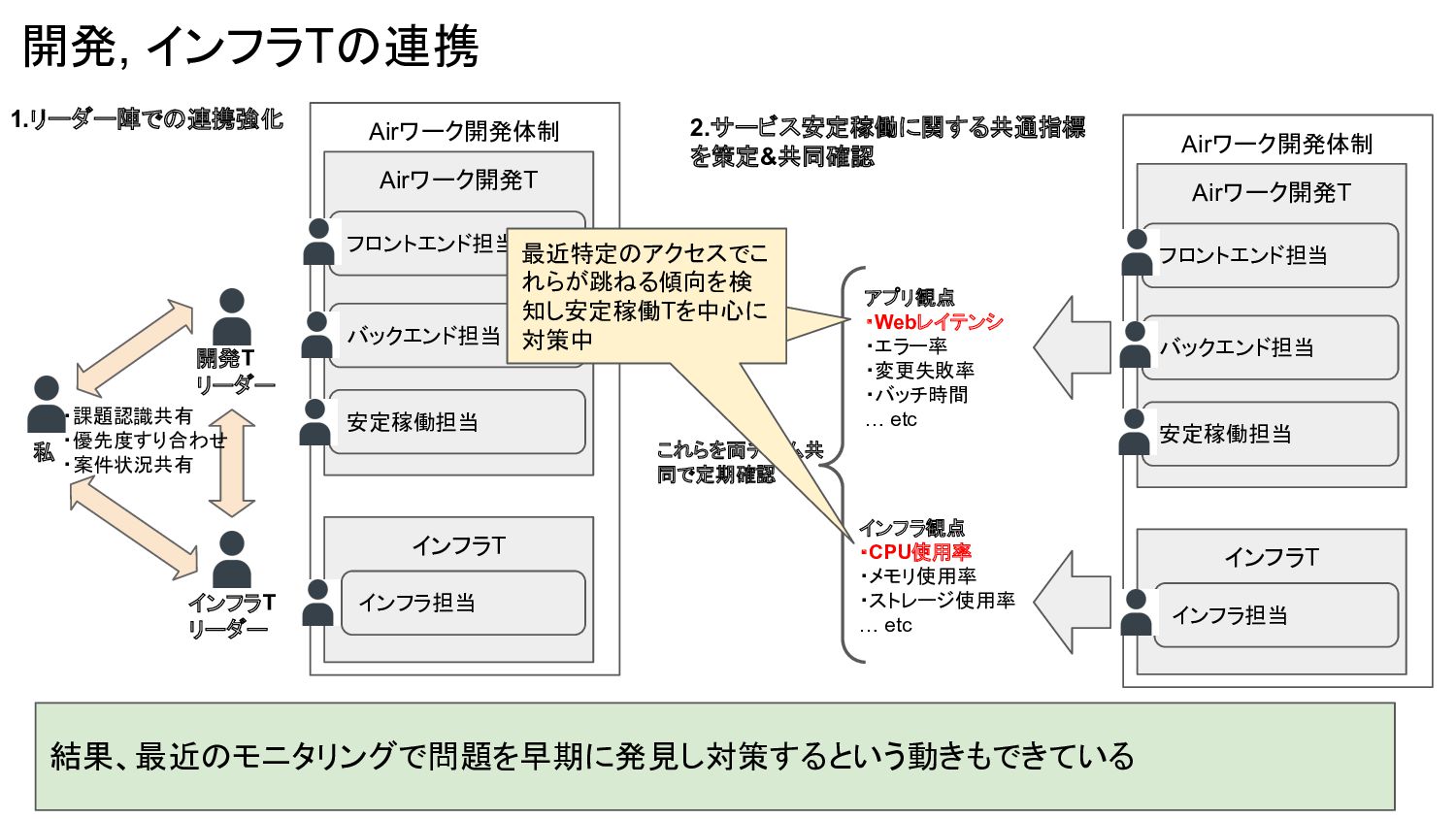
開発, インフラTの連携 結果、最近のモニタリングで問題を早期に発見し対策するという動きもできている Airワーク開発体制 Airワーク開発T バックエンド担当 フロントエンド担当 インフラT インフラ担当 安定稼働担当
開発T リーダー インフラT リーダー 私 ・課題認識共有 ・優先度すり合わせ ・案件状況共有 Airワーク開発体制 Airワーク開発T バックエンド担当 フロントエンド担当 インフラT インフラ担当 安定稼働担当 インフラ観点 ・CPU使用率 ・メモリ使用率 ・ストレージ使用率 … etc アプリ観点 ・Webレイテンシ ・エラー率 ・変更失敗率 ・バッチ時間 … etc 1.リーダー陣での連携強化 2.サービス安定稼働に関する共通指標 を策定&共同確認 これらを両チーム共 同で定期確認 最近これらが跳ねる傾 向を検知し安定稼働Tを 中心に対策中 最近特定のアクセスでこ れらが跳ねる傾向を検 知し安定稼働Tを中心に 対策中
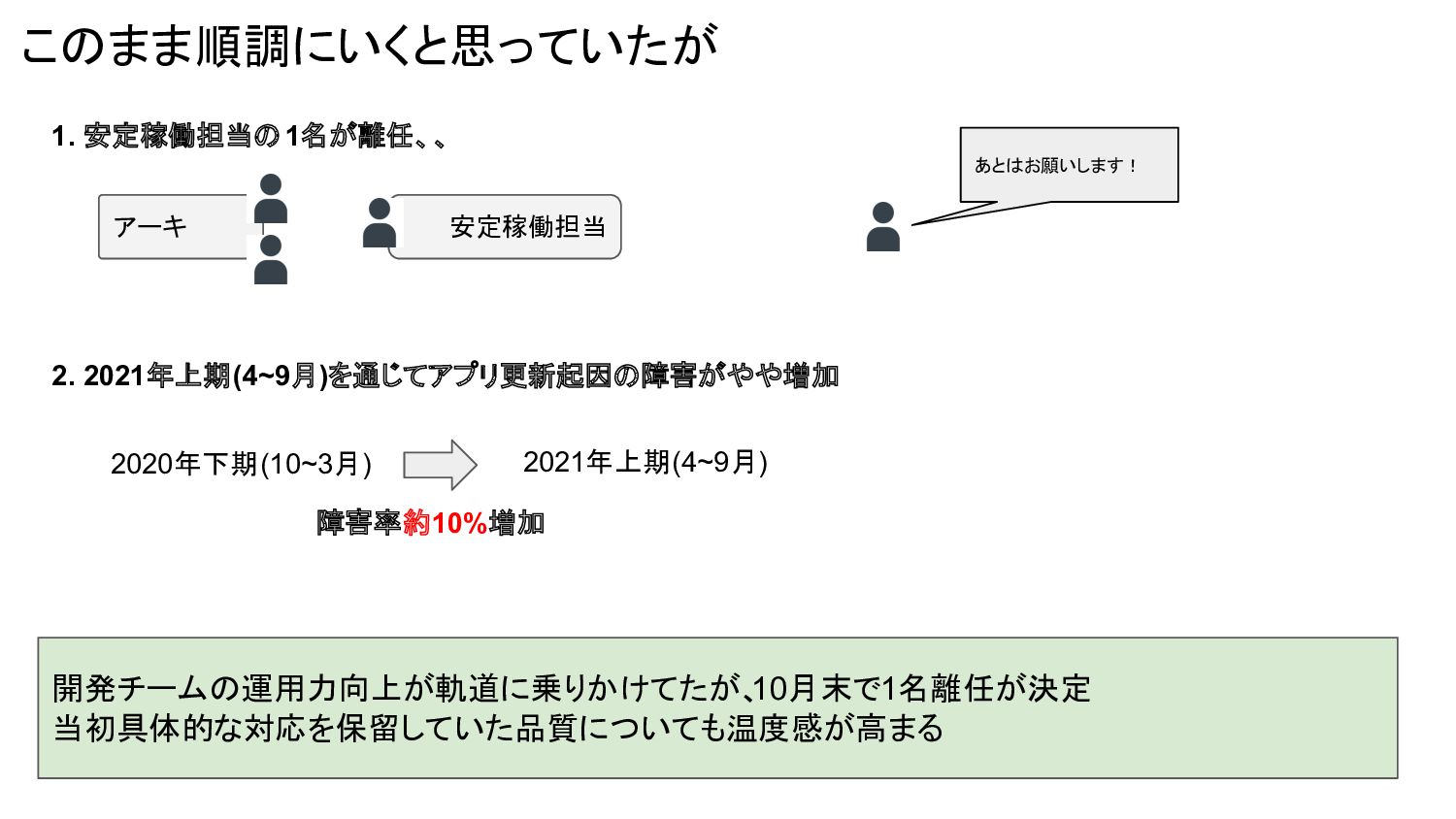
このまま順調にいくと思っていたが 開発チームの運用力向上が軌道に乗りかけてたが、 10月末で1名離任が決定 当初具体的な対応を保留していた品質についても温度感が高まる 安定稼働担当 1. 安定稼働担当の1名が離任、、 あとはお願いします! アーキ 2.
2021年上期(4~9月)を通じてアプリ更新起因の障害がやや増加 2020年下期(10~3月) 2021年上期(4~9月) 障害率約10%増加
第3章 自立と連携への歩み出し
4~6月 7~9月 10~12月 1~2月 第1章 利用拡大に向けた 改善実施 第2章 チーム分析と DevOpsの実践
第3章 自立と連携への歩み出し 2021年 2022年
離任影響を分析 もともと2名とも運用/改善活動以外に案件系タスクもしていた 1名体制になるとほぼ間違いなく回らなくなることが予想された 離任による影響を分析 安定稼働のリーダー格 (離任されたのはこちら ) ・優先度決め、タスク差配 /実行などの実施 ・運用業務の他にバックエンドチームの取りまとめも兼任
安定稼働のメンバー ・運用/改善業務の実稼働をメイン ・その他フロントエンドチームの取りまとめや案件の要件定義なども兼任 Aさん Bさん
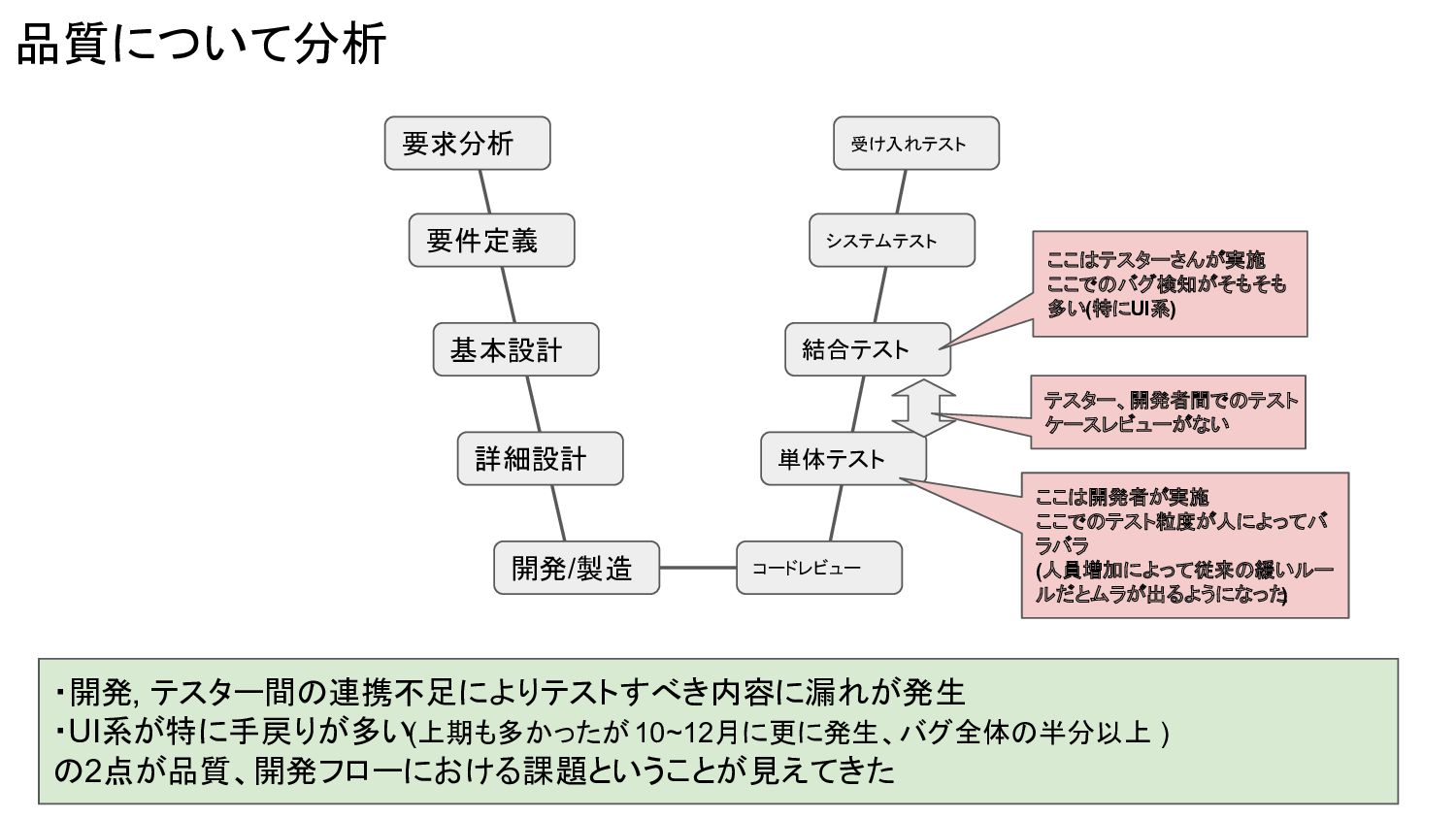
品質について分析 要求分析 要件定義 基本設計 詳細設計 開発/製造 コードレビュー 単体テスト 結合テスト システムテスト
受け入れテスト ここはテスターさんが実施 ここでのバグ検知がそもそも 多い(特にUI系) ここは開発者が実施 ここでのテスト粒度が人によってバ ラバラ (人員増加によって従来の緩いルー ルだとムラが出るようになった ) ・開発, テスター間の連携不足によりテストすべき内容に漏れが発生 ・UI系が特に手戻りが多い(上期も多かったが10~12月に更に発生、バグ全体の半分以上 ) の2点が品質、開発フローにおける課題ということが見えてきた テスター、開発者間でのテスト ケースレビューがない
先にネタバレ 実は第3章は我々が手厚くフォローしたのではなく 現場で自立的に進めたものがメインになります (適宜アドバイスはしたが取捨選択は委ねた)
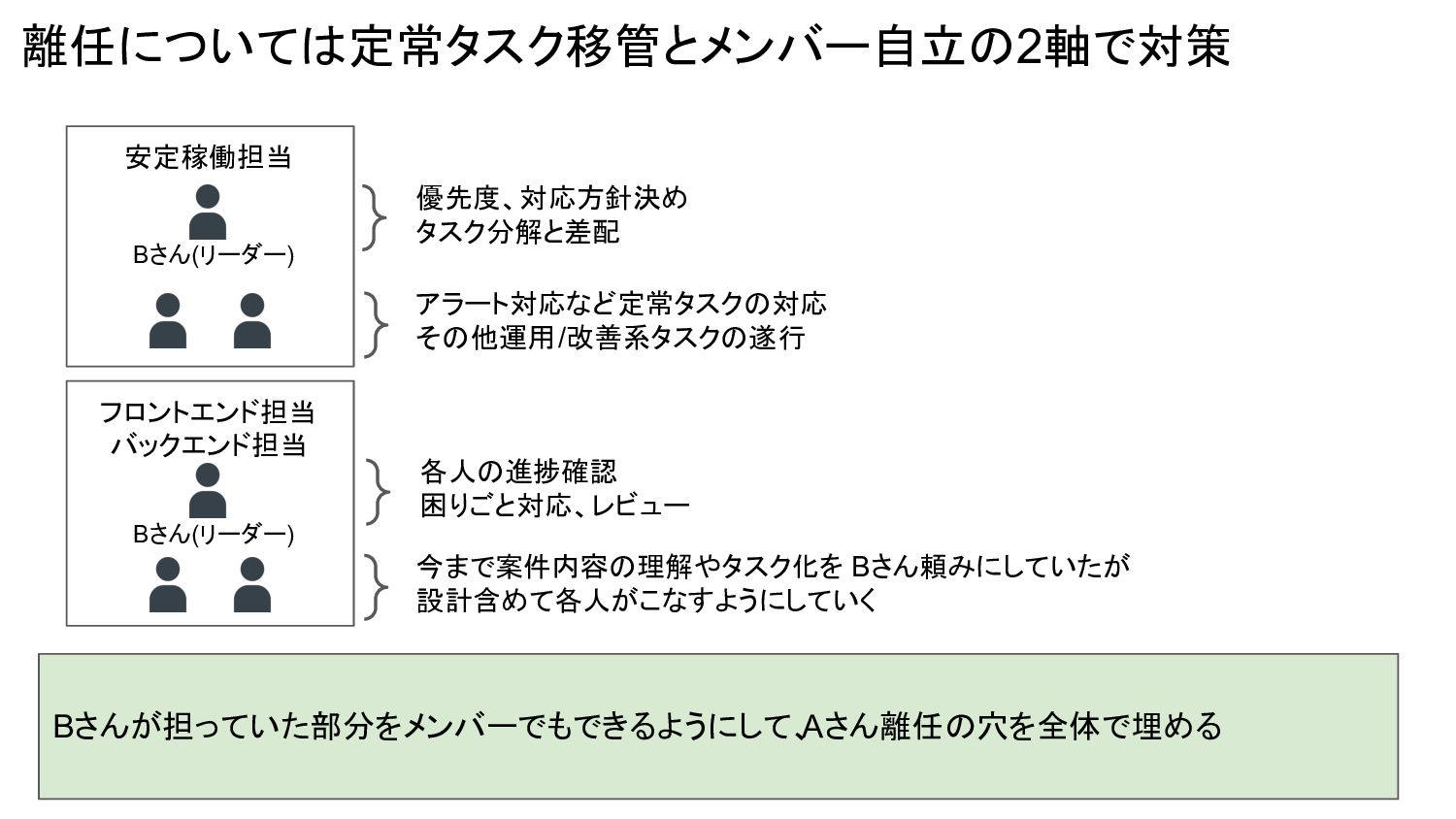
安定稼働担当 離任については定常タスク移管とメンバー自立の2軸で対策 Bさんが担っていた部分をメンバーでもできるようにして、 Aさん離任の穴を全体で埋める 優先度、対応方針決め タスク分解と差配 Bさん(リーダー) アラート対応など定常タスクの対応 その他運用/改善系タスクの遂行 フロントエンド担当
バックエンド担当 Bさん(リーダー) 今まで案件内容の理解やタスク化を Bさん頼みにしていたが 設計含めて各人がこなすようにしていく 各人の進捗確認 困りごと対応、レビュー
品質(テスト漏れ)については単体テスト方針とテスターとの連携で対策 これまで各担当者に任せきりになっていたテスト全般についてルールを整備 プロセスを重くして品質を上げるではなくチーム間の連携により全体で品質を守るアプローチを取っ た 単体テスト方針 改修に併せてテストコードでどこまで担保するのか? - 条件網羅、カバレッジ、境界値などの考え方整理 テストコードで担保しない部分についてどこまで手動テストで担保するのか? -
UIテスト、ブラウザ網羅など テスター連携 役割分担 - バッチや内部処理などテストが難しい場所は開発で担保 - 回帰テストや案件ごとの細かな UIテストはテスターで担保 案件内容の共有 - 案件意図に合わせたテストができるようにテスターも案件理解に加わるなど
品質(UIバグ多い)についてはデザイナーとの連携で対策 ここでもチーム間の連携強化により最適な方法を模索することにした デザイン不備がとにかく多かった 深ぼったところ、デザイナーが Figmaで記したデザインをそのまま個別に CSSで表現していた → 「実はこことここは同じデザイン」といったデザイナーの意図をコードに反映させておらず 修正漏れが多発していた デザイナーとの連携を強化
デザイナーとUIコンポーネントの定義やデザイン思想の認識合わせを実施 デザインの意図を徐々にコードに反映させていくことに
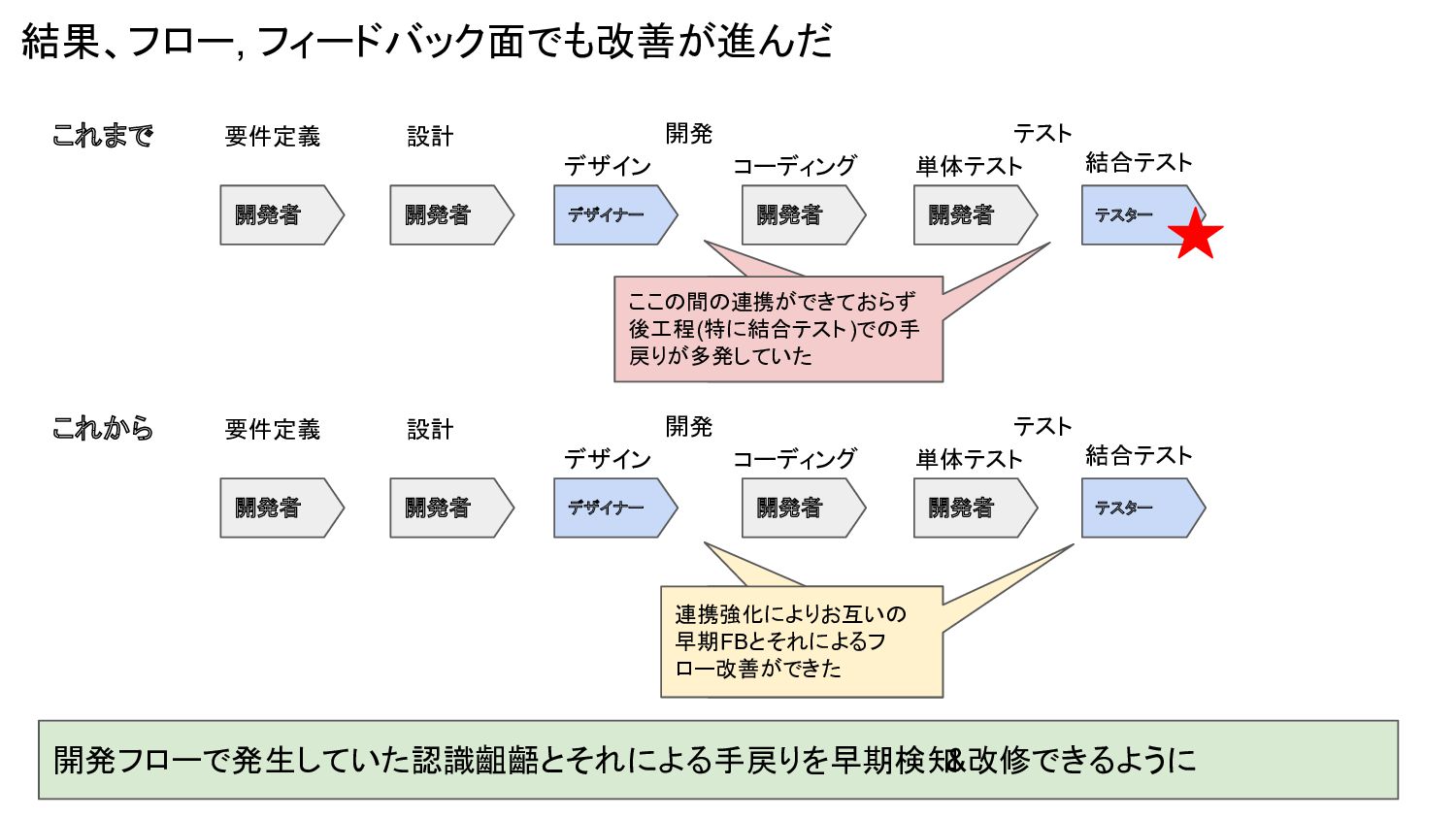
結果、フロー, フィードバック面でも改善が進んだ 開発フローで発生していた認識齟齬とそれによる手戻りを早期検知 &改修できるように これまで 要件定義 設計 デザイン コーディング 単体テスト
開発者 デザイナー テスター 結合テスト 開発 テスト 開発者 開発者 開発者 ここの間の連携がで きておらず後工程で の手戻りが多発して いた ここの間の連携ができておらず 後工程(特に結合テスト)での手 戻りが多発していた これから 要件定義 設計 デザイン コーディング 単体テスト 開発者 デザイナー テスター 結合テスト 開発 テスト 開発者 開発者 開発者 ここの間の連携がで きておらず後工程で の手戻りが多発して いた 連携強化によりお互いの 早期FBとそれによるフ ロー改善ができた
定量的に見た結果 定量的にも改善傾向が明確に出た 結合テストのUIバグ件数 約1/5 アプリ更新起因の障害 約1/3 Before(10~12月) After(1~3月)
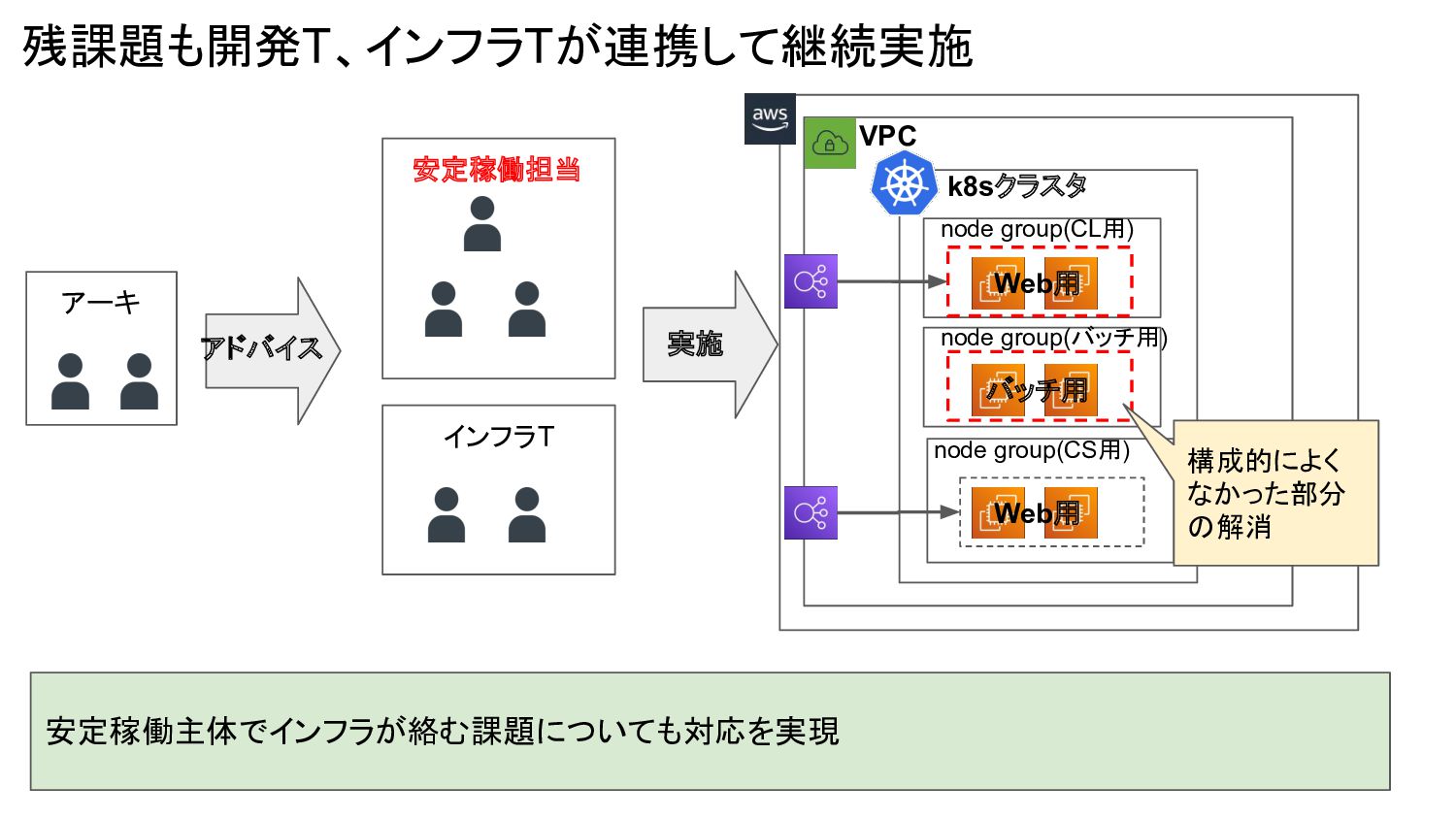
残課題も開発T、インフラTが連携して継続実施 安定稼働主体でインフラが絡む課題についても対応を実現 安定稼働担当 インフラT node group(CL用) node group(CS用) VPC k8sクラスタ
Web用 Web用 バッチ用 構成的によく なかった部分 の解消 アーキ 実施 アドバイス node group(バッチ用)
関わり方は参画前の認識になってきた 参画する前はこう考えてた 開発T: 現状こういう状態で、利用拡大に伴ってやばくなりそうな箇所はここです → 現場に課題認識があり技術難度の高いところを中心にフォロー 参画直後はこうだった 開発T: 利用拡大に伴いどうなるかわからない、、 サーバリソースのどこに響くのかとかよくわからない、、
→ 現場での現状整理ができておらずここから実施が必要 → 直近の対策はできたとして、、今後大丈夫か? 最近はこうなりつつある 開発T: この課題対応にはこうするとよいと考えていますが、見解やアドバイスほしいです → 課題認識と対応検討を主体的に進め、技術難度の高いところをフォロー
よく聞く理想のDevOpsにはまだまだ遠いが 1日100回デプロイといった世界には遠いが、組織としてもシステムとしても徐々に良い方向には向 かっている まだまだ課題も多いが、だからこそ学習し続けることに価値があると考える 1. フローの原則 開発フロー上の無駄を一部排除 週1回リリースサイクルのままだがチーム連携という動きは生まれつつある 2. フィードバックの原則
システム的なフィードバックはそのまま チーム間のフィードバックという好循環ができつつある 3. 継続的な学習と実験の原則 まだ時折HOW思考に陥ったり、目指すべき状態を見失うこともあるが、運用力は強化されつつある
我々がやってきたことまとめ 1. 事業要望に応えるためにシステム改善に注力した (エンジニアリング的アプローチ) → 改善によるシステム安定化 2. 改善継続には現場の自立が必要と認識してスキル , 考え方の注入をした(ヒト的アプローチ)
→ 超人がいないと成り立たないではなく自己組織化を目指す 3. 1つのチームとして連携できるように共通の指標を立てた (ヒト的アプローチ) → システム安定稼働をチームで守るという意識付け ヒトとエンジニアリングの両軸でアプローチすることでDevOps的な文化を生みだせる! 大事なのはチームとしてどうしていきたいか?を考え、実践していくことです。
「どうしていきたいか?」 → 「あなたはどうしたい?」 一緒に自己組織化したチームで働きませんか? 弊社では「あなたどうしたい?」という問をもとに 自立して働く方を募集中です!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}