centralized state. The mutex protects all goroutine-related operations (creation, completion, rescheduling, etc). 2. Goroutine (G) hand-o (G.nextg). Worker threads (M's) frequently hand-o runnable goroutines between each other, this may lead to increased latencies and additional overheads. Every M must be able to execute any runnable G, in particular the M that just created the G. 3. Per-M memory cache (M.mcache). Memory cache and other caches (stack alloc) are associated with all M's, while they need to be associated only with M's running Go code (an M blocked inside of syscall does not need mcache). A ratio between M's running Go code and all M's can be as high as 1:100. This leads to excessive resource consumption (each MCache can suck up up to 2M) and poor data locality. 4. Aggressive thread blocking/unblocking. In presence of syscalls worker threads are frequently blocked and unblocked. This adds a lot of overhead.
code, however it can be blocked or in a syscall w/o an associated P. Gs are in P's local queue or global queue G keeps current task status, provides stack
r c / r u n t i m e / p r o c . g o f u n c s c h e d i n i t ( ) { . . . p r o c s : = i n t ( n c p u ) i f n : = a t o i ( g o g e t e n v ( " G O M A X P R O C S " ) ) ; n > 0 { i f n > _ M a x G o m a x p r o c s { n = _ M a x G o m a x p r o c s } p r o c s = n } i f p r o c r e s i z e ( i n t 3 2 ( p r o c s ) ) ! = n i l { t h r o w ( " u n k n o w n r u n n a b l e g o r o u t i n e d u r i n g b o o t s t r a p " ) } . . .
c G O M A X P R O C S ( n i n t ) i n t { i f n > _ M a x G o m a x p r o c s { n = _ M a x G o m a x p r o c s } l o c k ( & s c h e d . l o c k ) r e t : = i n t ( g o m a x p r o c s ) u n l o c k ( & s c h e d . l o c k ) i f n < = 0 | | n = = r e t { r e t u r n r e t } s t o p T h e W o r l d ( " G O M A X P R O C S " ) / / n e w p r o c s w i l l b e p r o c e s s e d b y s t a r t T h e W o r l d n e w p r o c s = i n t 3 2 ( n ) s t a r t T h e W o r l d ( ) r e t u r n r e t }
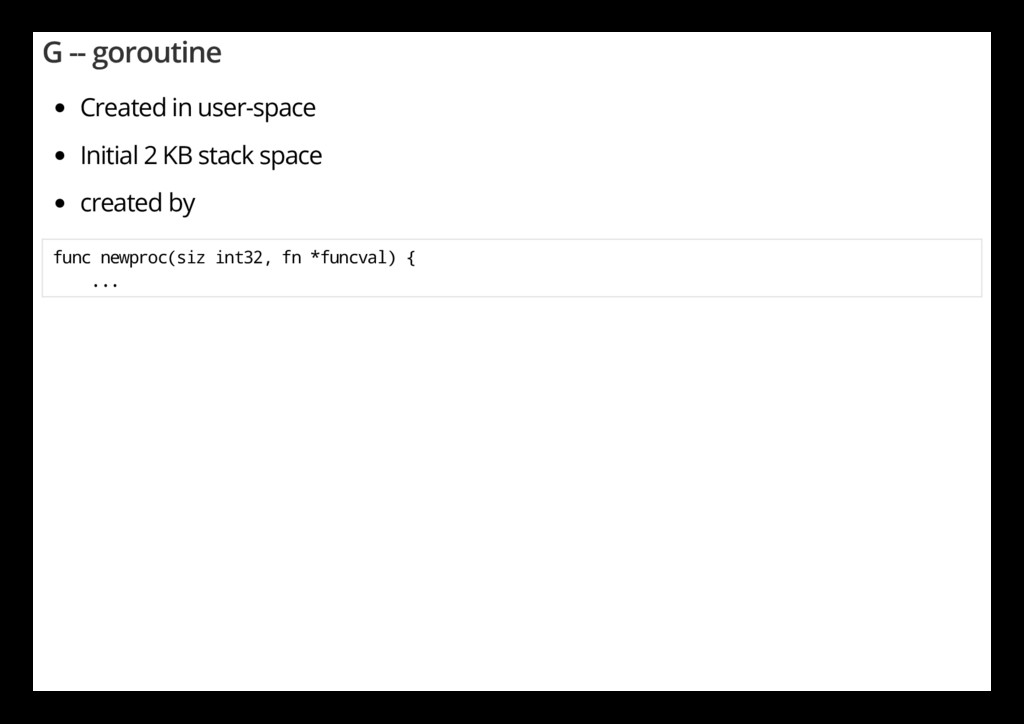
easily f u n c n e w p r o c 1 ( f n * f u n c v a l , a r g p * u i n t 8 , n a r g i n t 3 2 , n r e t i n t 3 2 , c a l l e r p c u i n t p t r ) * g { _ g _ : = g e t g ( ) / / G E T c u r r e n t G . . . _ p _ : = _ g _ . m . p . p t r ( ) / / G E T i d l e G f r o m c u r r e n t P ' s q u e u e n e w g : = g f g e t ( _ p _ ) i f n e w g = = n i l { n e w g = m a l g ( _ S t a c k M i n ) c a s g s t a t u s ( n e w g , _ G i d l e , _ G d e a d ) a l l g a d d ( n e w g ) / / p u b l i s h e s w i t h a g - > s t a t u s o f G d e a d s o G C s c a n n e r d o e s n ' t l o o k a t u n i n i t i a l i z } Goroutines will be reused
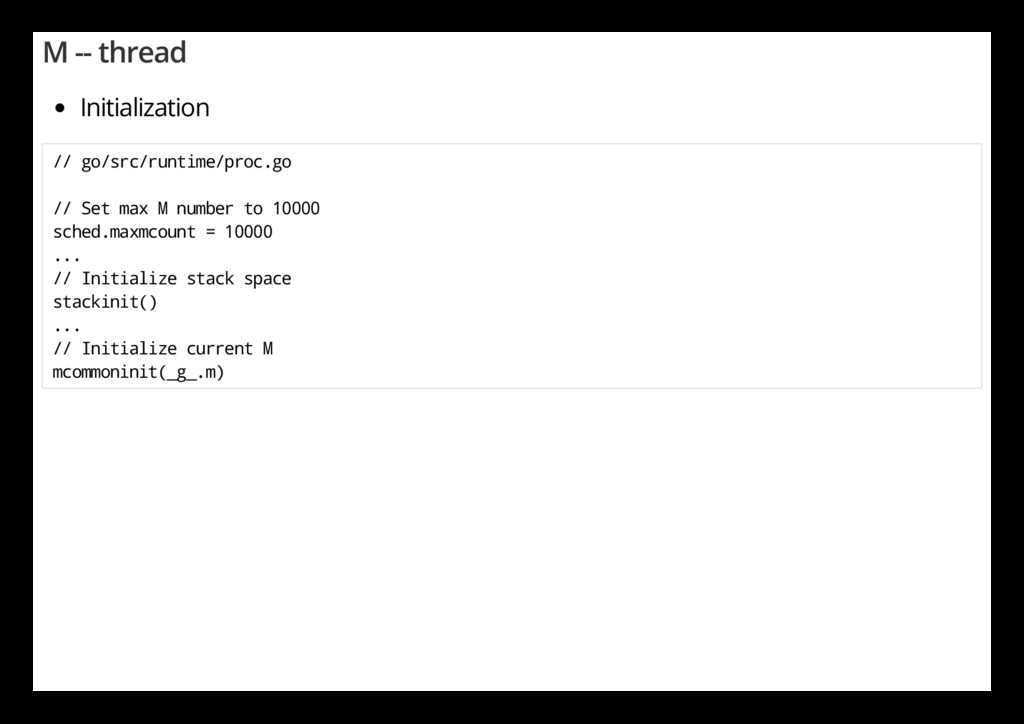
r c / r u n t i m e / p r o c . g o / / S e t m a x M n u m b e r t o 1 0 0 0 0 s c h e d . m a x m c o u n t = 1 0 0 0 0 . . . / / I n i t i a l i z e s t a c k s p a c e s t a c k i n i t ( ) . . . / / I n i t i a l i z e c u r r e n t M m c o m m o n i n i t ( _ g _ . m )
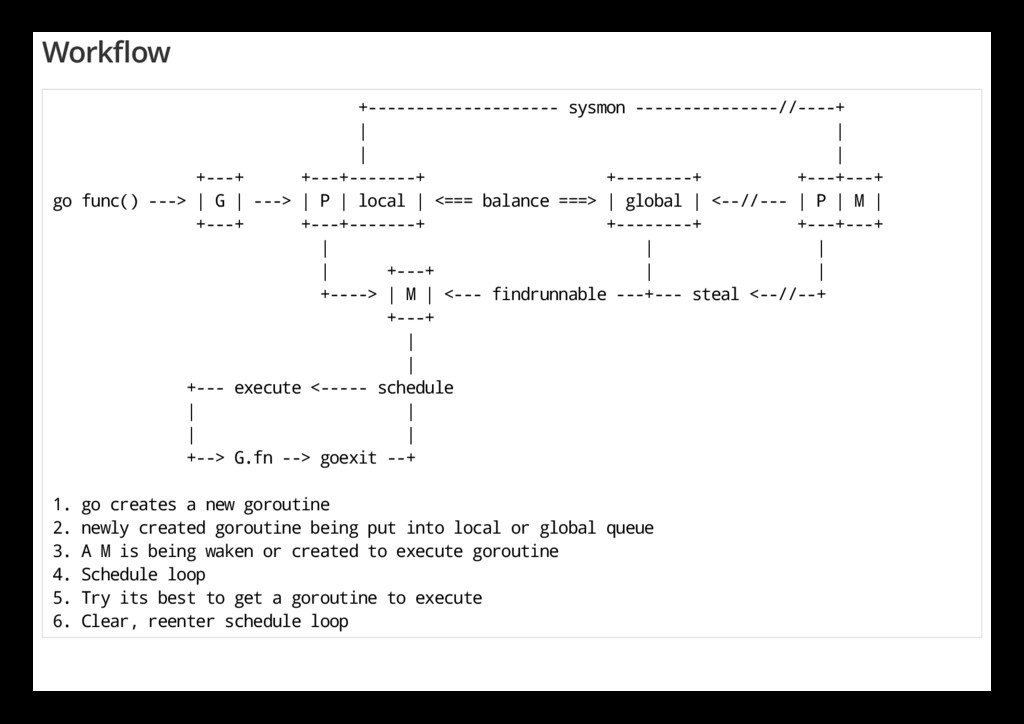
- - - - - - - - - - - - - s y s m o n - - - - - - - - - - - - - - - / / - - - - + | | | | + - - - + + - - - + - - - - - - - + + - - - - - - - - + + - - - + - - - + g o f u n c ( ) - - - > | G | - - - > | P | l o c a l | < = = = b a l a n c e = = = > | g l o b a l | < - - / / - - - | P | M | + - - - + + - - - + - - - - - - - + + - - - - - - - - + + - - - + - - - + | | | | + - - - + | | + - - - - > | M | < - - - f i n d r u n n a b l e - - - + - - - s t e a l < - - / / - - + + - - - + | | + - - - e x e c u t e < - - - - - s c h e d u l e | | | | + - - > G . f n - - > g o e x i t - - + 1 . g o c r e a t e s a n e w g o r o u t i n e 2 . n e w l y c r e a t e d g o r o u t i n e b e i n g p u t i n t o l o c a l o r g l o b a l q u e u e 3 . A M i s b e i n g w a k e n o r c r e a t e d t o e x e c u t e g o r o u t i n e 4 . S c h e d u l e l o o p 5 . T r y i t s b e s t t o g e t a g o r o u t i n e t o e x e c u t e 6 . C l e a r , r e e n t e r s c h e d u l e l o o p
work stealing than sharing When all processors have work to do, no threads are migrated by a work-stealing scheduler Threads are always migrated by a work-sharing scheudler
At the beginning of each step, each processor either is idle or has a thread to work on 2. Those processors that are idle begin the step by attempting to remove any ready thread from the pool. - 2.1 If there are su ciently many ready threads in the pool to satisfy all of the idle processors, then every idle processor gets a ready thread to work on - 2.2 Otherwise, some processors remain idle. 3. Then each processor that has a thread to work on executes the next instruction from that thread until the thread either spawns, stalls or dies.
Algorithm is distributed across the processors. 1. Each processor maintains a ready deque data structure of threads. 2. A processor obtains work by removing the thread at the bottom of its ready deque. 3. The Work-Stealing Algorithm begines work stealing when ready deques empty. - 3.1 The processor becomes a thief and attempts to steal work from a victim processor chosen uniformly at random. - 3.2 The thief queries the ready deque of the victim, and if it is nonempty, the thief removes and begins work on the top thread. - 3.3 If the victim's ready deque is empty, however, the thief tries again, picking another victim at random.
P to execute Go code, however it can be blocked or in a syscall w/o an associated P. Gs are in P's local queue or global queue G keeps current task status, provides stack Implements both Busy-Leaves & Randomized Work-Stealing
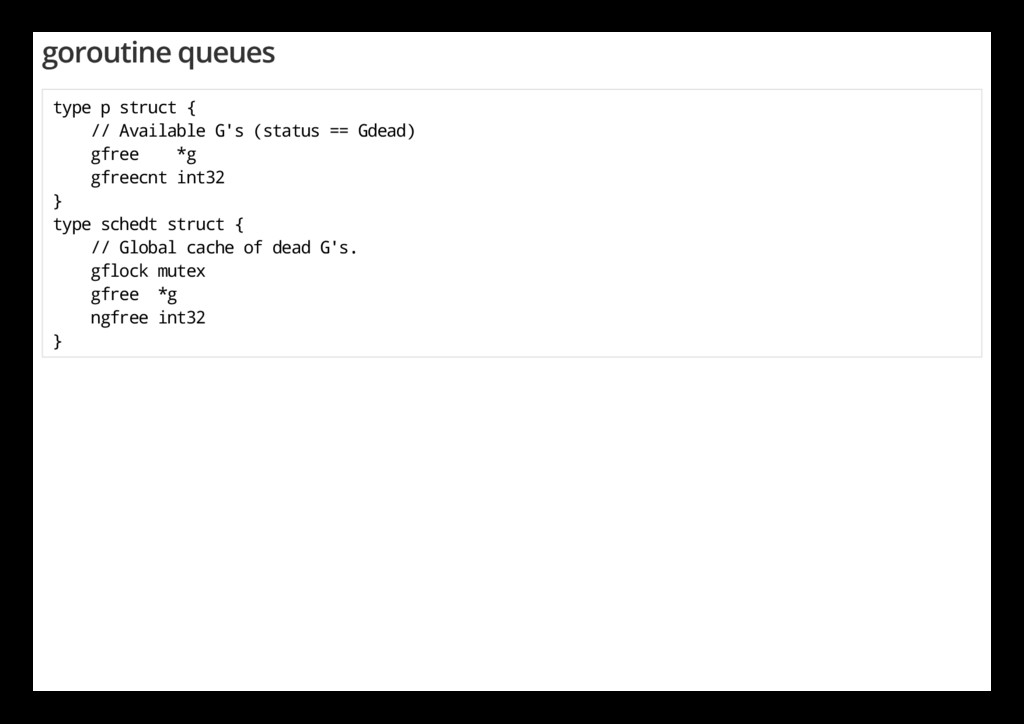
u c t { / / A v a i l a b l e G ' s ( s t a t u s = = G d e a d ) g f r e e * g g f r e e c n t i n t 3 2 } t y p e s c h e d t s t r u c t { / / G l o b a l c a c h e o f d e a d G ' s . g f l o c k m u t e x g f r e e * g n g f r e e i n t 3 2 }
f r o m g f r e e l i s t . / / I f l o c a l l i s t i s e m p t y , g r a b a b a t c h f r o m g l o b a l l i s t . f u n c g f g e t ( _ p _ * p ) * g { r e t r y : g p : = _ p _ . g f r e e i f g p = = n i l & & s c h e d . g f r e e ! = n i l { l o c k ( & s c h e d . g f l o c k ) f o r _ p _ . g f r e e c n t < 3 2 & & s c h e d . g f r e e ! = n i l { _ p _ . g f r e e c n t + + g p = s c h e d . g f r e e s c h e d . g f r e e = g p . s c h e d l i n k . p t r ( ) s c h e d . n g f r e e - - g p . s c h e d l i n k . s e t ( _ p _ . g f r e e ) _ p _ . g f r e e = g p } u n l o c k ( & s c h e d . g f l o c k ) g o t o r e t r y }
d s a r u n n a b l e g o r o u t i n e t o e x e c u t e . / / T r i e s t o s t e a l f r o m o t h e r P ' s , g e t g f r o m g l o b a l q u e u e , p o l l n e t w o r k . f u n c f i n d r u n n a b l e ( ) ( g p * g , i n h e r i t T i m e b o o l ) { . . . / / r a n d o m s t e a l f r o m o t h e r P ' s f o r i : = 0 ; i < i n t ( 4 * g o m a x p r o c s ) ; i + + { i f s c h e d . g c w a i t i n g ! = 0 { g o t o t o p } _ p _ : = a l l p [ f a s t r a n d 1 ( ) % u i n t 3 2 ( g o m a x p r o c s ) ] v a r g p * g i f _ p _ = = _ g _ . m . p . p t r ( ) { g p , _ = r u n q g e t ( _ p _ ) } e l s e { s t e a l R u n N e x t G : = i > 2 * i n t ( g o m a x p r o c s ) / / f i r s t l o o k f o r r e a d y q u e u e s w i t h m o r e t h a n 1 g g p = r u n q s t e a l ( _ g _ . m . p . p t r ( ) , _ p _ , s t e a l R u n N e x t G ) } i f g p ! = n i l { r e t u r n g p , f a l s e } } . . .
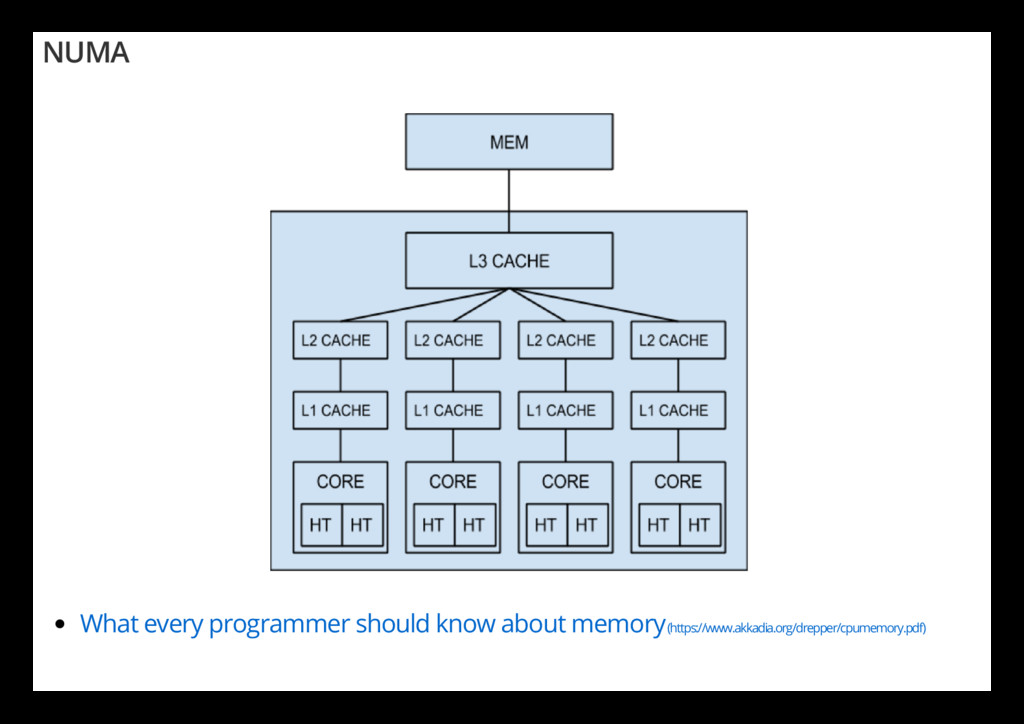
Design Doc (https://docs.google.com/document/d/1ETuA2IOmnaQ4j81AtTGT40Y4_Jr6_IDASEKg0t0dBR8/edit) Scheduling Multithreaded Computations by Work Stealing (http://supertech.csail.mit.edu/papers/steal.pdf) What every programmer should know about memory (https://www.akkadia.org/drepper/cpumemory.pdf)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}