Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Happywhale - Whale and Dolphin Identification 2...
Search
Rist Inc.
March 27, 2025
Technology
290
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Happywhale - Whale and Dolphin Identification 2nd place solution
Rist Inc.
March 27, 2025
More Decks by Rist Inc.
See All by Rist Inc.
CMI - Detect Behavior with Sensor Data
rist
0
170
大規模言語モデル (LLM) 入門
rist
2
710
Drawing with LLMs
rist
0
620
Eedi - Mining Misconceptions in Mathematics 4th place solution
rist
1
430
モンテカルロ木探索のパフォーマンスを予測する Kaggleコンペ解説 〜生成AIによる未知のゲーム生成〜
rist
4
2k
HMSコンペ解説
rist
0
320
Other Decks in Technology
See All in Technology
ヘルスケア領域における AI 活用と その安全性担保のための取り組み (Leveraging AI in Healthcare and Our Efforts to Ensure Its Safety) - Google I/O Extended Tokyo 2026, July 11, 2026
zettaittenani
0
250
型は壁、Rustでもバグを直すな、表現できなくせよ
nwiizo
13
1.9k
Amazon EVS で VCF 9.0 / 9.1 のサポート開始まとめ
mtoyoda
0
290
ruby.wasmとPicoRuby.wasmに対応した仮想DOMライブラリを作ってる話 #kaigieffect_kaigi
sue445
PRO
0
120
証券システムを10年Scalaで作り続けるということ - 関数型まつり2026
krrrr38
3
820
AI駆動開発におけるQAエンジニアの役割事例 〜AI駆動開発の現場から〜
kobayashiyorimitsu
0
460
Control Planeで育てるBtoB SaaSの認証基盤 - SRE NEXT 2026
pokohide
1
2.1k
プロダクトだけじゃない、社内プロセスにおける自動化・省力化ノススメ
kakehashi
PRO
1
3.4k
依頼文化をやめる日 EM視点で語るPlatform EngineeringとInclusive SRE / Discussing Platform Engineering and Inclusive SRE from an EM's Perspective
shin1988
4
5k
なぜ人は自分のプロジェクトを 「なんちゃってアジャイル」と 自嘲するのか
kozotaira
0
280
CSに"SLO"は要らない、経営層に"99.9%"は伝わらない - SREを全社に"翻訳"する3原則
cscengineer
PRO
1
4.3k
AIに「使われる」時代のSaaS戦略 〜既存WebAPIのMCPサーバー化における開発ノウハウ〜
ekispert_api
0
310
Featured
See All Featured
The Art of Programming - Codeland 2020
erikaheidi
57
14k
Why You Should Never Use an ORM
jnunemaker
PRO
61
9.9k
[Rails World 2023 - Day 1 Closing Keynote] - The Magic of Rails
eileencodes
38
2.9k
More Than Pixels: Becoming A User Experience Designer
marktimemedia
3
460
Measuring Dark Social's Impact On Conversion and Attribution
stephenakadiri
2
230
The Myth of the Modular Monolith - Day 2 Keynote - Rails World 2024
eileencodes
28
3.6k
Java REST API Framework Comparison - PWX 2021
mraible
34
9.4k
ReactJS: Keep Simple. Everything can be a component!
pedronauck
666
130k
Leo the Paperboy
mayatellez
8
1.9k
Navigating Algorithm Shifts & AI Overviews - #SMXNext
aleyda
1
1.3k
Darren the Foodie - Storyboard
khoart
PRO
3
3.4k
Game over? The fight for quality and originality in the time of robots
wayneb77
1
220
Transcript
Happywhale - Whale and Dolphin Identification 2nd place solution 株式会社Rist
©Rist Inc. 02 1. Competition概要 2. 2nd place solution 3.
上位解法の紹介 目次
©Rist Inc. 03 Competition概要
©Rist Inc. 04 • 開催情報: ◦ 期間: 2022/2 ~ 2022/4
◦ 主催: Happywhale ◦ 結果: 2位 / 1589チーム • 課題: ◦ クジラとイルカの個体識別 ◦ 海洋保全への活用が目的 • 評価指標: ◦ MAP@5 • Data: ◦ 画像枚数:train=51033 / test=27956 ◦ testには、trainに存在しない個体 “new_individual”があり、 これも予測する必要がある ◦ 2019年にも同様のコンペが開催されていた Happywhale - Whale and Dolphin Identification
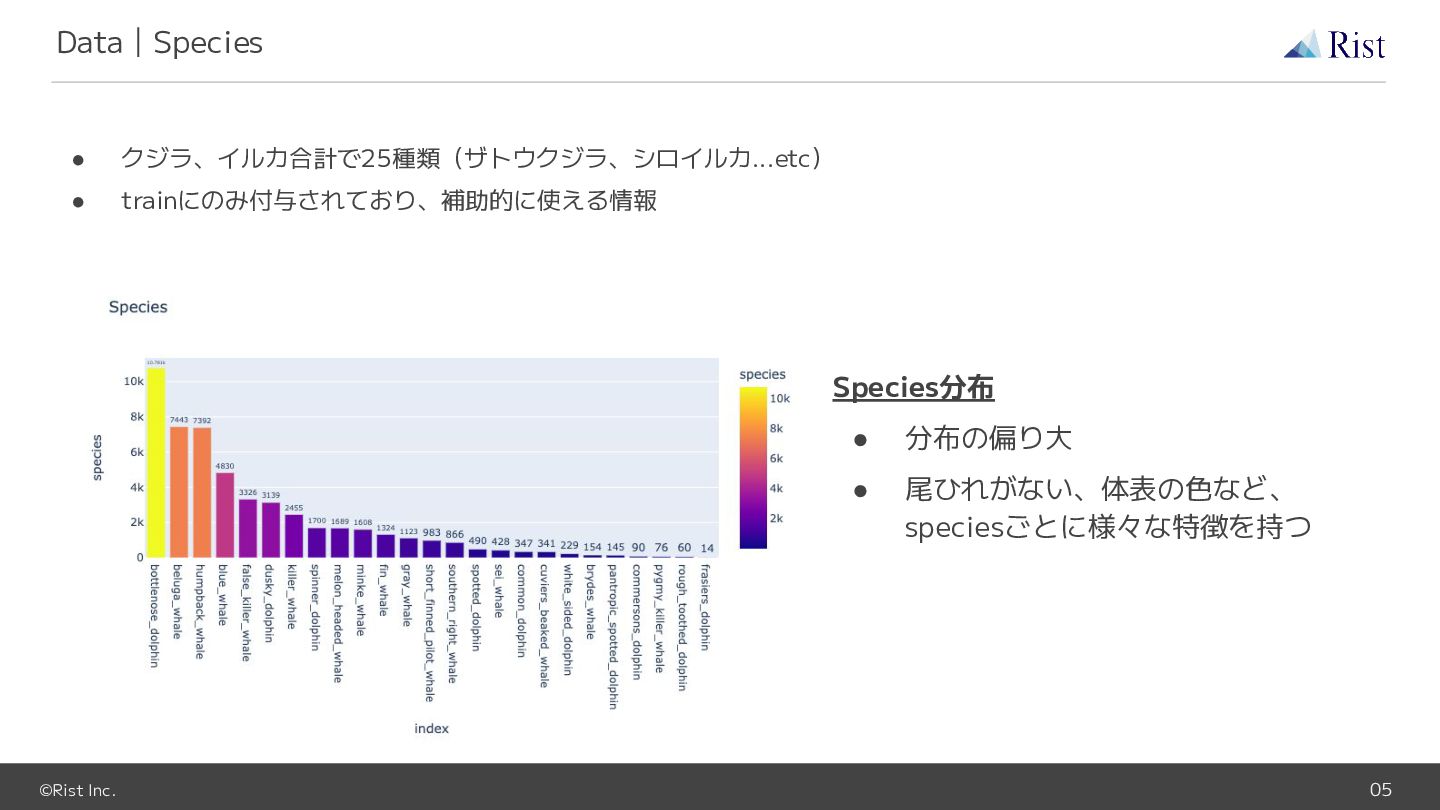
©Rist Inc. 05 • クジラ、イルカ合計で25種類(ザトウクジラ、シロイルカ...etc) • trainにのみ付与されており、補助的に使える情報 Data|Species Species分布 •
分布の偏り大 • 尾ひれがない、体表の色など、 speciesごとに様々な特徴を持つ
©Rist Inc. 06 • 個体識別id • 15587の既知のid + new_individual の、合計15588クラス
• ただし、9258個のidがtrainに1枚ずつしかなかったり、逆に一部のidは400枚以上あったりと、不均衡なデータ Data|Individual_id (target)
©Rist Inc. 07 • testデータの各画像に対して、最大5つまでの individual_id を予測 → MAPで評価 •
trainに存在しないと思われる個体には、 “new_individual” の予測を挿入する Submission形式 name predictions (確信度:降順) image_0 id_1, id_2, id_0, id_4, id_3 image_1 new_individual, id_0, id_3, id_1, id_4 image_2 id_1, id_2, id_0, new_individual, id_3 … …
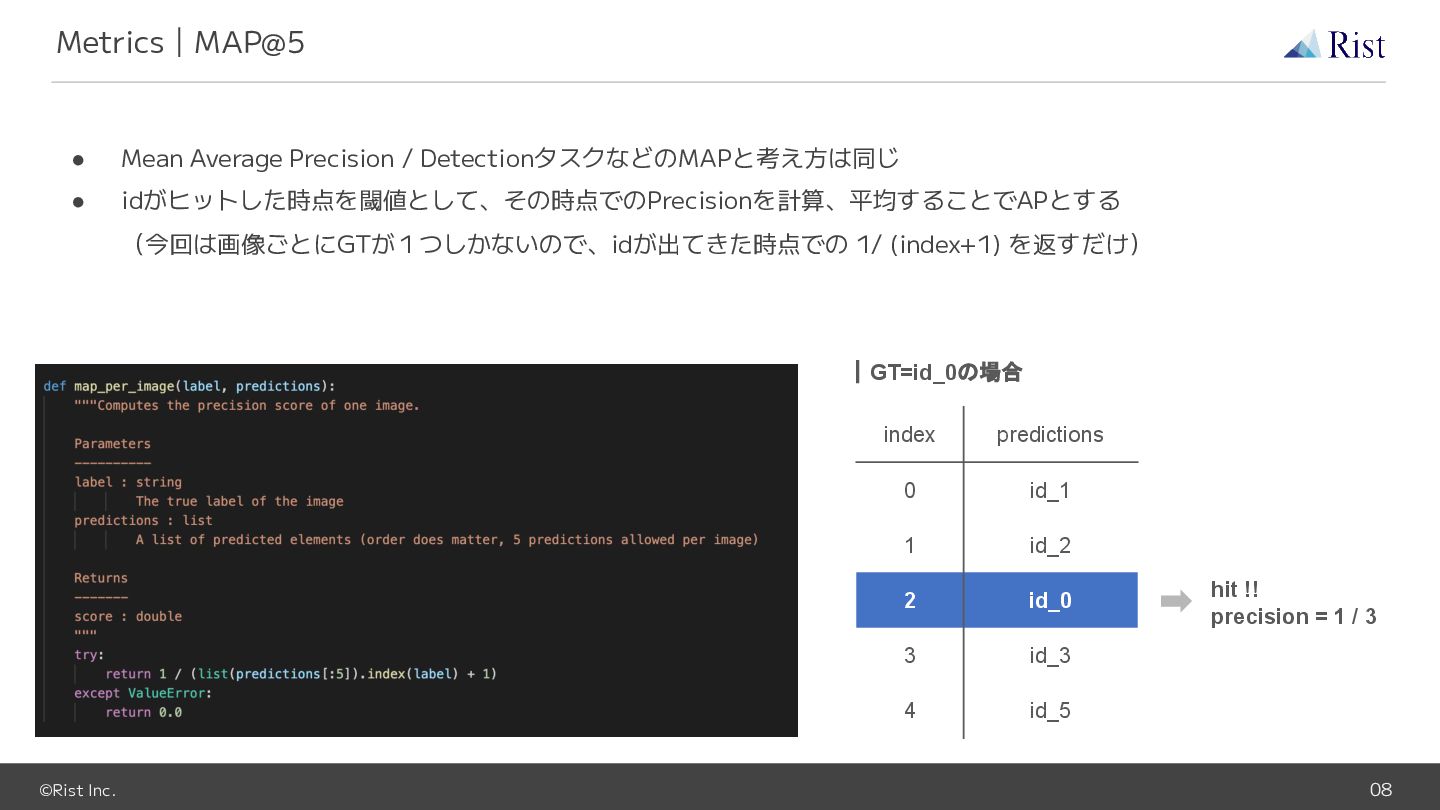
©Rist Inc. 08 • Mean Average Precision / DetectionタスクなどのMAPと考え方は同じ •
idがヒットした時点を閾値として、その時点でのPrecisionを計算、平均することでAPとする (今回は画像ごとにGTが1つしかないので、idが出てきた時点での 1/ (index+1) を返すだけ) Metrics|MAP@5 index predictions 0 id_1 1 id_2 2 id_0 3 id_3 4 id_5 |GT=id_0の場合 hit !! precision = 1 / 3
©Rist Inc. 09 • 前回のコンペとの比較は下記 • top solutionの範囲では、前回コンペデータを使ったチームはなかった 前回のコンペデータ使えないの? 項目
クジラコンペ2019 クジラコンペ2022 対象 ザトウクジラ クジラ/イルカ 25種 撮影部位 尾ひれ 尾ひれ / 背びれ / 全身..etc 撮影環境 well aligned 低品質なものもある
©Rist Inc. 010 前回のコンペデータ使えないの? クジラコンペ2019 クジラコンペ2022
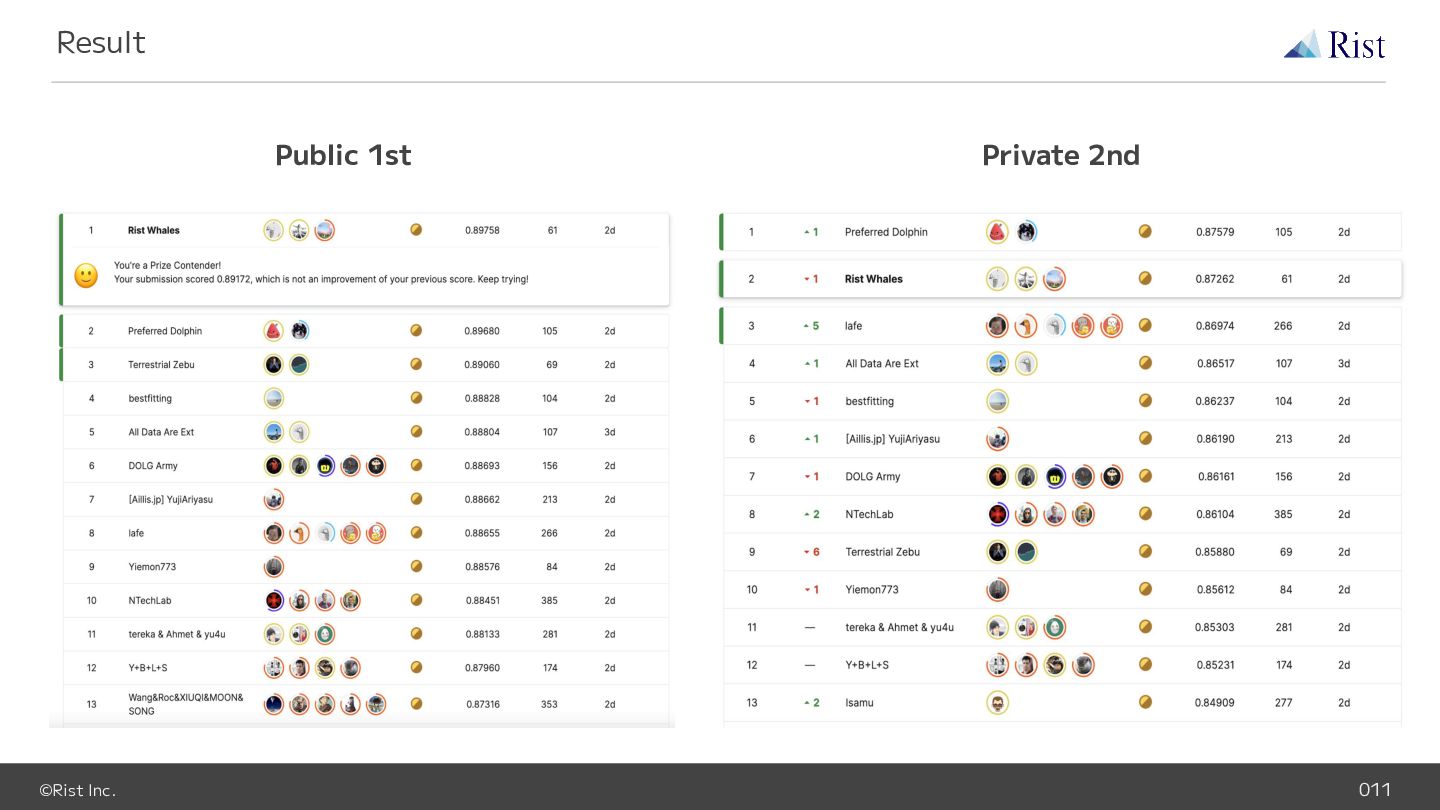
©Rist Inc. 011 Result Public 1st Private 2nd
©Rist Inc. 012 1. まず初めに、物体検出モデルでクジラ/イルカだけを切り抜くdetectorを作成 a. すでに公開されているdetector, cropped datasetを使うチームが多かった b.
弊チームでも、コンペ最終日まで fullbody dataset (公開dataset) を使っていた c. LB topの人たちは独自にannotationした画像でdetectorを作り直したりしていた 2. cropped imageを使って、metric learning (Arcfaceなど) で学習 3. 上記で学習したモデルを使い train, testのembeddingを取得 4. Cosine similarityなどで検索 → Top5 idを作成 5. post processで “new_individual” を挿入 Basic Approach
©Rist Inc. 013 Public datasets backfin dataset fullbody dataset detic
dataset remove background
©Rist Inc. 014 2nd place solution
©Rist Inc. 015 • efficientnet_l2 + pseudo labeling 5round +α
• 最終日に YOLOX detectorを学習、上記のモデルをfine-tuning • 最終subはバリエーションを持たせた4つのefficientnet_l2のensemble 2nd place solution|Overview
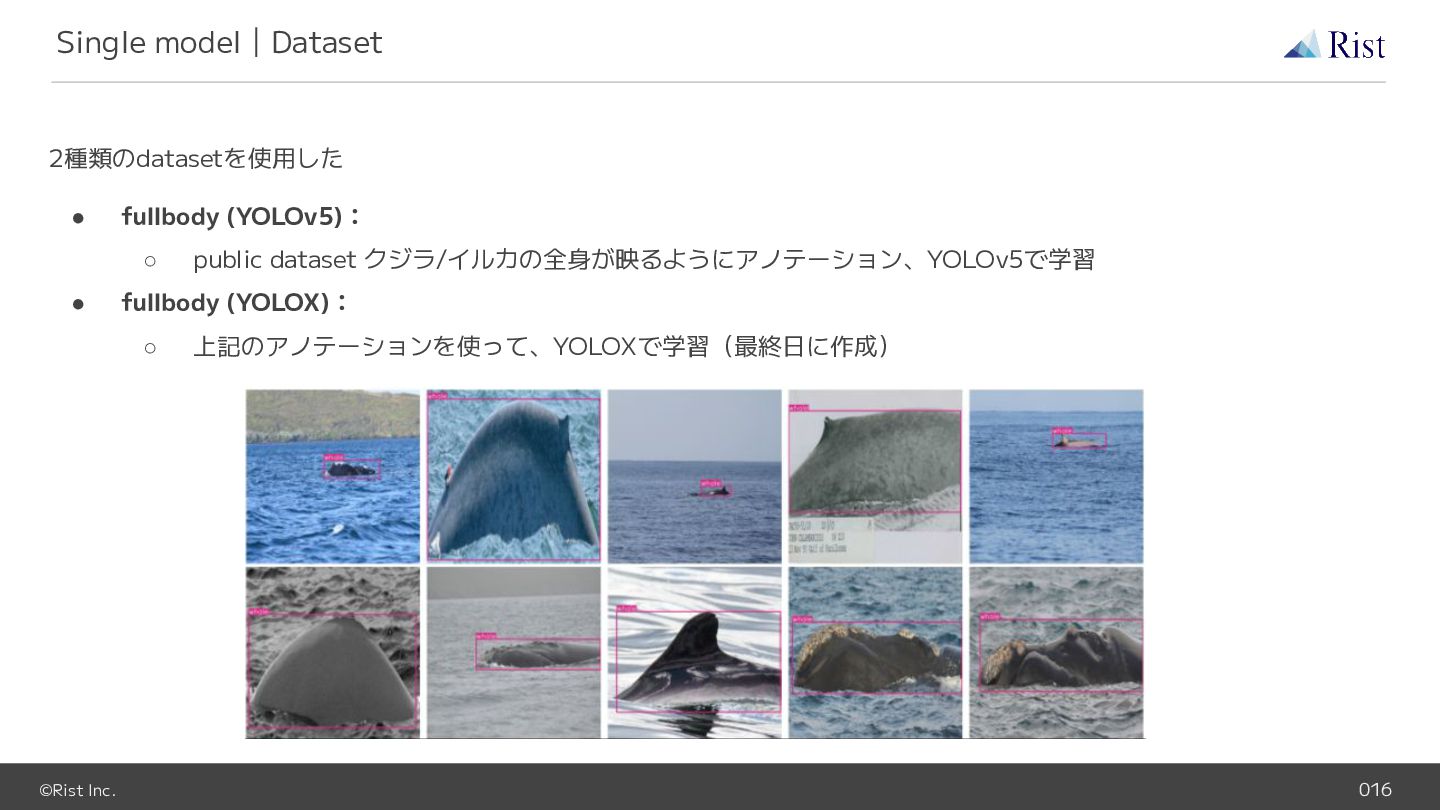
©Rist Inc. 016 2種類のdatasetを使用した • fullbody (YOLOv5): ◦ public dataset
クジラ/イルカの全身が映るようにアノテーション、YOLOv5で学習 • fullbody (YOLOX): ◦ 上記のアノテーションを使って、YOLOXで学習(最終日に作成) Single model|Dataset
©Rist Inc. 017 YOLOシリーズ(v1 〜 v5, X)は、single stageの物体検出モデル(およびライブラリ)であり、高速な学習、推論 を特徴とする(なお、YOLOv5については論文が存在しない(Githubのみ)ため、本ページではYOLOXについての み特徴を記載します)
YOLOX YOLOv1を除くYOLOシリーズでは、RCNN系モデルと同じくアンカーベースの手法となっていたが、YOLOXではこ れをアンカーフリーに戻し、Decoupled Head, Multi positive, SimOTAなどさまざまな学習時の工夫を導入している • Decoupled Head:classificationとregressionを別々のブランチで学習する • Multi positive:前景、背景のデータ不均衡対策。GTの近傍3x3のアンカーもPositiveとして評価 • SimOTA:Loss計算時のGT_bboxとpred_bboxの割り当てを、最適輸送問題として解く手法(OTA)を高速化 YOLO (v5, X)
©Rist Inc. 018 • Keypoint:Large model (efficientnet_l2), Strong augmentation (RandAugment)
• mixed precision, gradient checkpointingを使うと single RTX3090でもimg_size=768で batch_size=16が可能 • Pytorch buildの違いで学習速度に影響が出ていた。NVIDIAからリリースされているものが一番 高速だった Single model|Architecture Training Configs - backbone = tf_efficientnet_l2_ns - img_size = 768 - loss = Arcface with adaptive margin - augmentation = Horizontal flip, RandAugment - optimizer = SGD - scheduler = Cosine Decay with warmup - batch_size = 16 per GPU - n_epoch = 20 Pytorch build (docker image) cudnn benchmark training throughput (imgs/sec) pytorch/pytorch:1.11.0-cuda11. 3-cudnn8-devel False 2.5 pytorch/pytorch:1.11.0-cuda11. 3-cudnn8-devel True 3.4 nvcr.io/nvidia/pytorch:22.02-py3 False 4.0 nvcr.io/nvidia/pytorch:22.02-py3 True 4.1
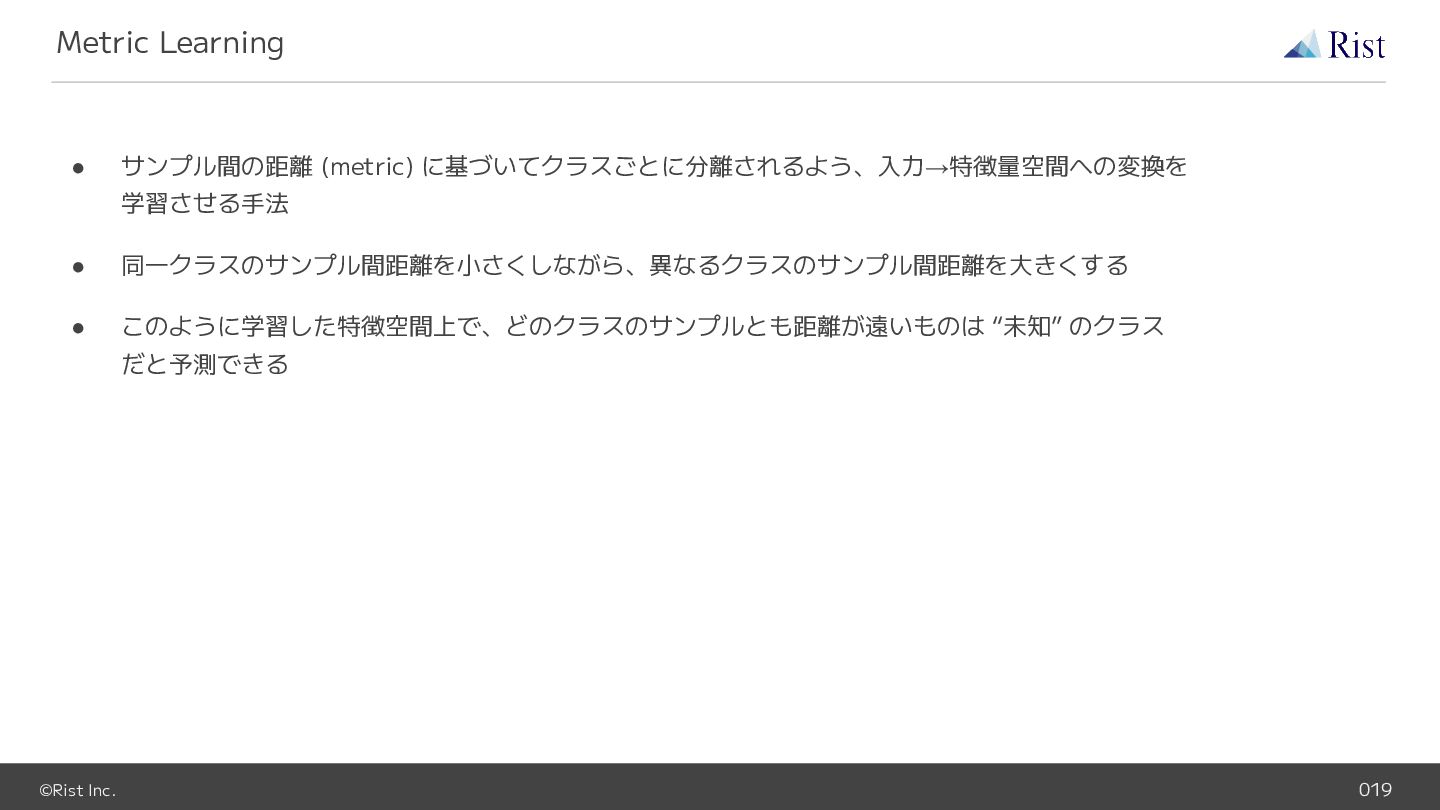
©Rist Inc. 019 • サンプル間の距離 (metric) に基づいてクラスごとに分離されるよう、入力→特徴量空間への変換を 学習させる手法 • 同一クラスのサンプル間距離を小さくしながら、異なるクラスのサンプル間距離を大きくする
• このように学習した特徴空間上で、どのクラスのサンプルとも距離が遠いものは “未知” のクラス だと予測できる Metric Learning
©Rist Inc. 020 Arcface • 通常のクラス分類の手法に、異なるクラス間の距離を遠ざけるペナルティ項としてmarginを導入 Adaptive margin • 通常のArcfaceは、すべてのクラスに対して同じmarginを設定する
• しかし、今回のコンペのようにclass imbalanceな問題では、上記のmarginをクラスごとに調整した 方が良いことがある = Adaptive margin • 今回は、画像枚数が少ないクラスほど大きなmarginを使用するように調整 Arcface with Adaptive margin
©Rist Inc. 021 • NAS (Neural Architecture Search) により取得したベースモデル (Efficientnet
B0) を、ある一定 のScaling raw に従い Up scaling したモデル群 • Efficientnet L2はその中でも一番大規模なモデル Efficientnet 単一のパラメータ φ に従い、モデルをup scaling
©Rist Inc. 022 • 様々なaugmentからランダムにN個サンプリングし、それぞれを強度Mでsequentialに適用する • 本コンペでは上記のN, Mは、 mmclassification における
ImageNet学習時のパラメータを使用 (N=2, M=9) • サンプリングするaugmentation ◦ identity / autoContrast / equalize / rotate / solarize / color / posterize / contrast / brightness / sharpness / shear-x / shear-y / translate-x / translate-y RandAugment
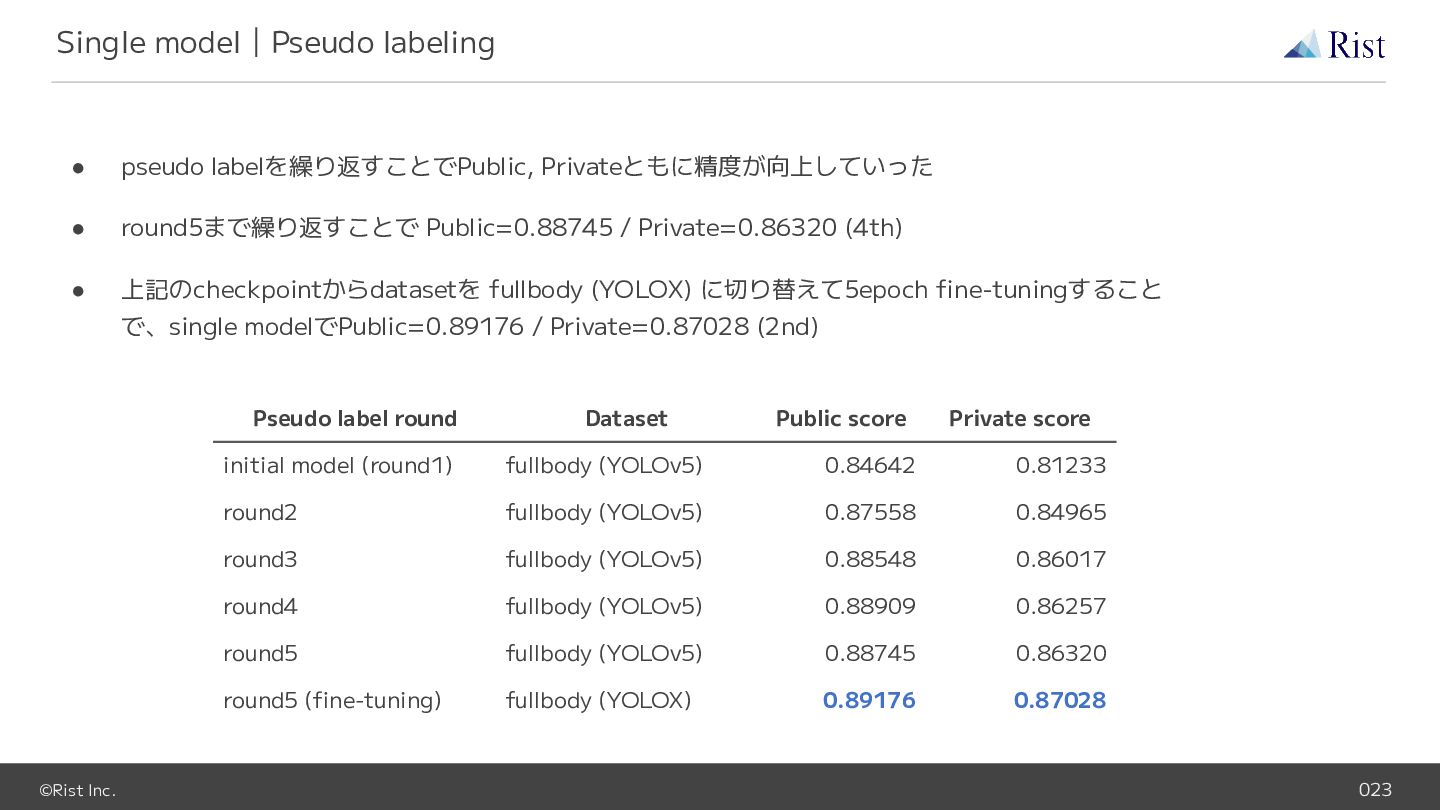
©Rist Inc. 023 • pseudo labelを繰り返すことでPublic, Privateともに精度が向上していった • round5まで繰り返すことで Public=0.88745
/ Private=0.86320 (4th) • 上記のcheckpointからdatasetを fullbody (YOLOX) に切り替えて5epoch fine-tuningすること で、single modelでPublic=0.89176 / Private=0.87028 (2nd) Single model|Pseudo labeling Pseudo label round Dataset Public score Private score initial model (round1) fullbody (YOLOv5) 0.84642 0.81233 round2 fullbody (YOLOv5) 0.87558 0.84965 round3 fullbody (YOLOv5) 0.88548 0.86017 round4 fullbody (YOLOv5) 0.88909 0.86257 round5 fullbody (YOLOv5) 0.88745 0.86320 round5 (fine-tuning) fullbody (YOLOX) 0.89176 0.87028
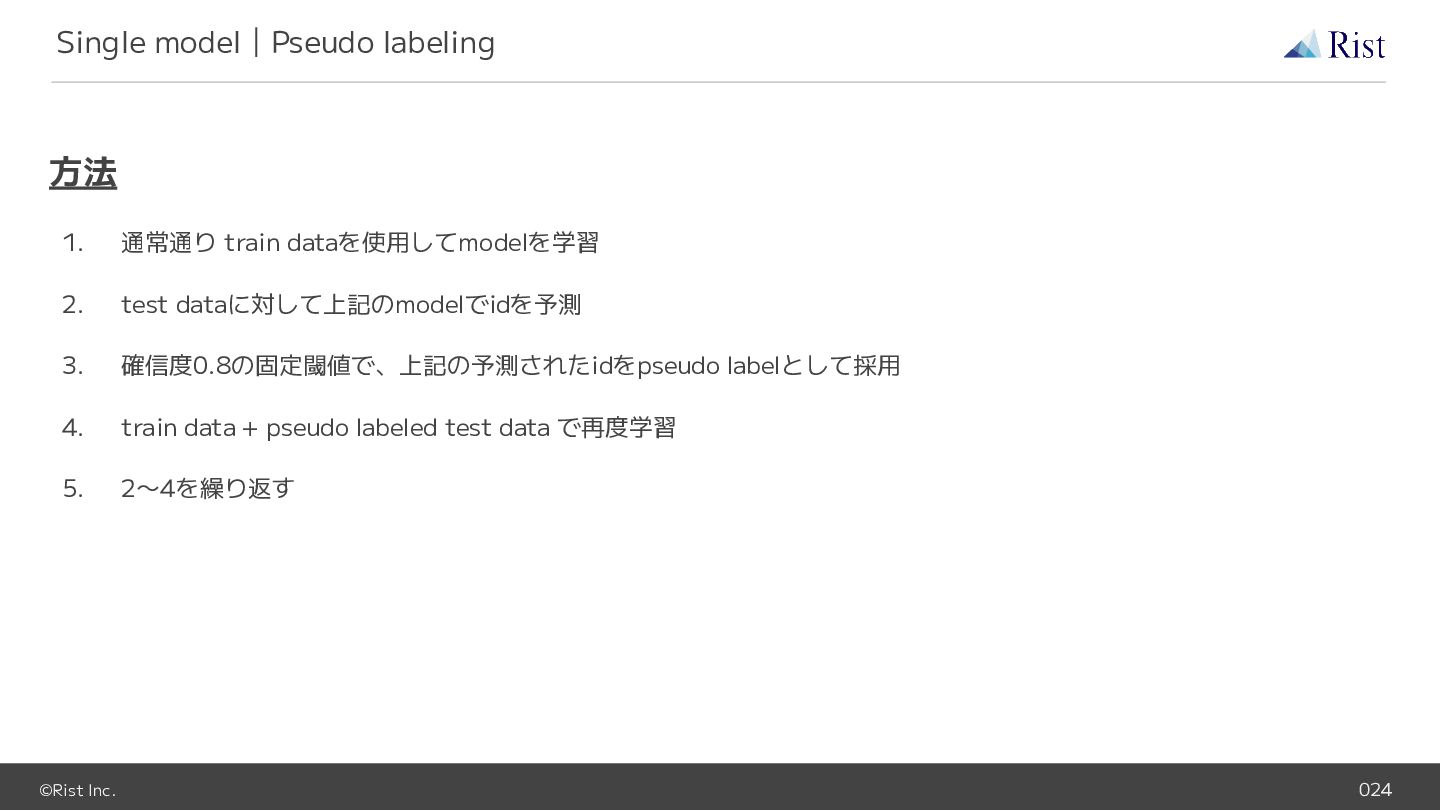
©Rist Inc. 024 方法 1. 通常通り train dataを使用してmodelを学習 2. test
dataに対して上記のmodelでidを予測 3. 確信度0.8の固定閾値で、上記の予測されたidをpseudo labelとして採用 4. train data + pseudo labeled test data で再度学習 5. 2〜4を繰り返す Single model|Pseudo labeling
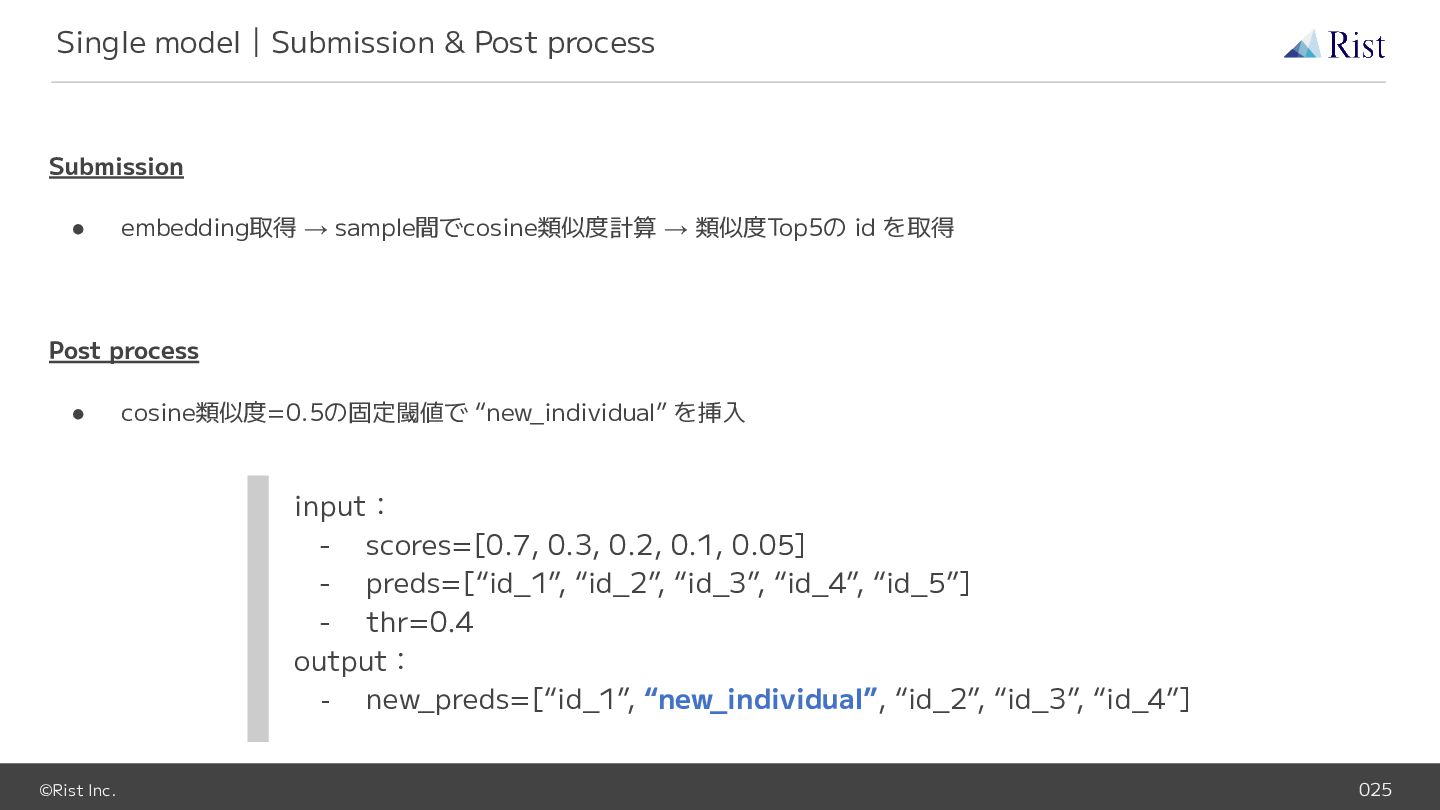
©Rist Inc. 025 Submission • embedding取得 → sample間でcosine類似度計算 → 類似度Top5の
id を取得 Post process • cosine類似度=0.5の固定閾値で “new_individual” を挿入 Single model|Submission & Post process input: - scores=[0.7, 0.3, 0.2, 0.1, 0.05] - preds=[“id_1”, “id_2”, “id_3”, “id_4”, “id_5”] - thr=0.4 output: - new_preds=[“id_1”, “new_individual”, “id_2”, “id_3”, “id_4”]
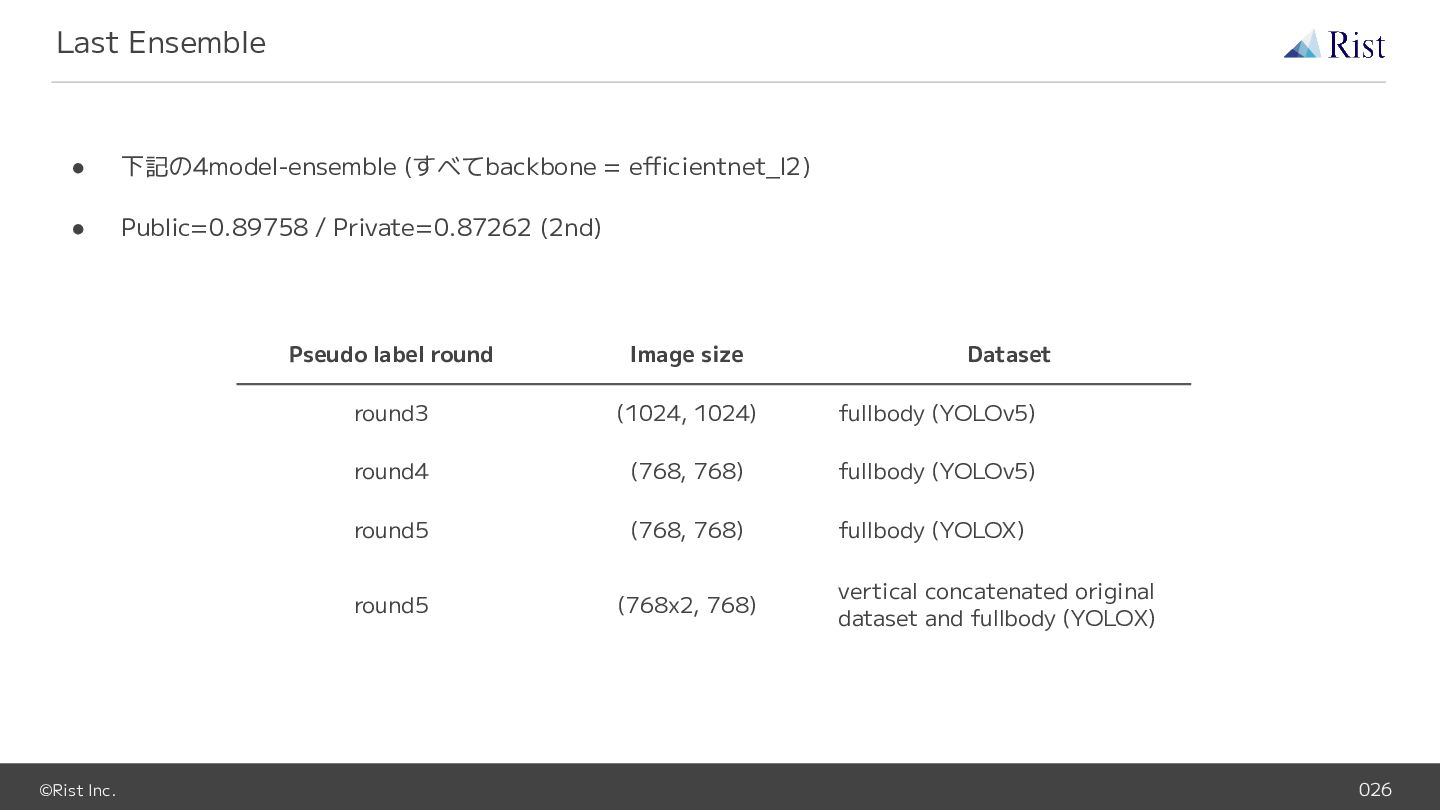
©Rist Inc. 026 • 下記の4model-ensemble (すべてbackbone = efficientnet_l2) • Public=0.89758
/ Private=0.87262 (2nd) Last Ensemble Pseudo label round Image size Dataset round3 (1024, 1024) fullbody (YOLOv5) round4 (768, 768) fullbody (YOLOv5) round5 (768, 768) fullbody (YOLOX) round5 (768x2, 768) vertical concatenated original dataset and fullbody (YOLOX)
©Rist Inc. 027 上位解法の紹介
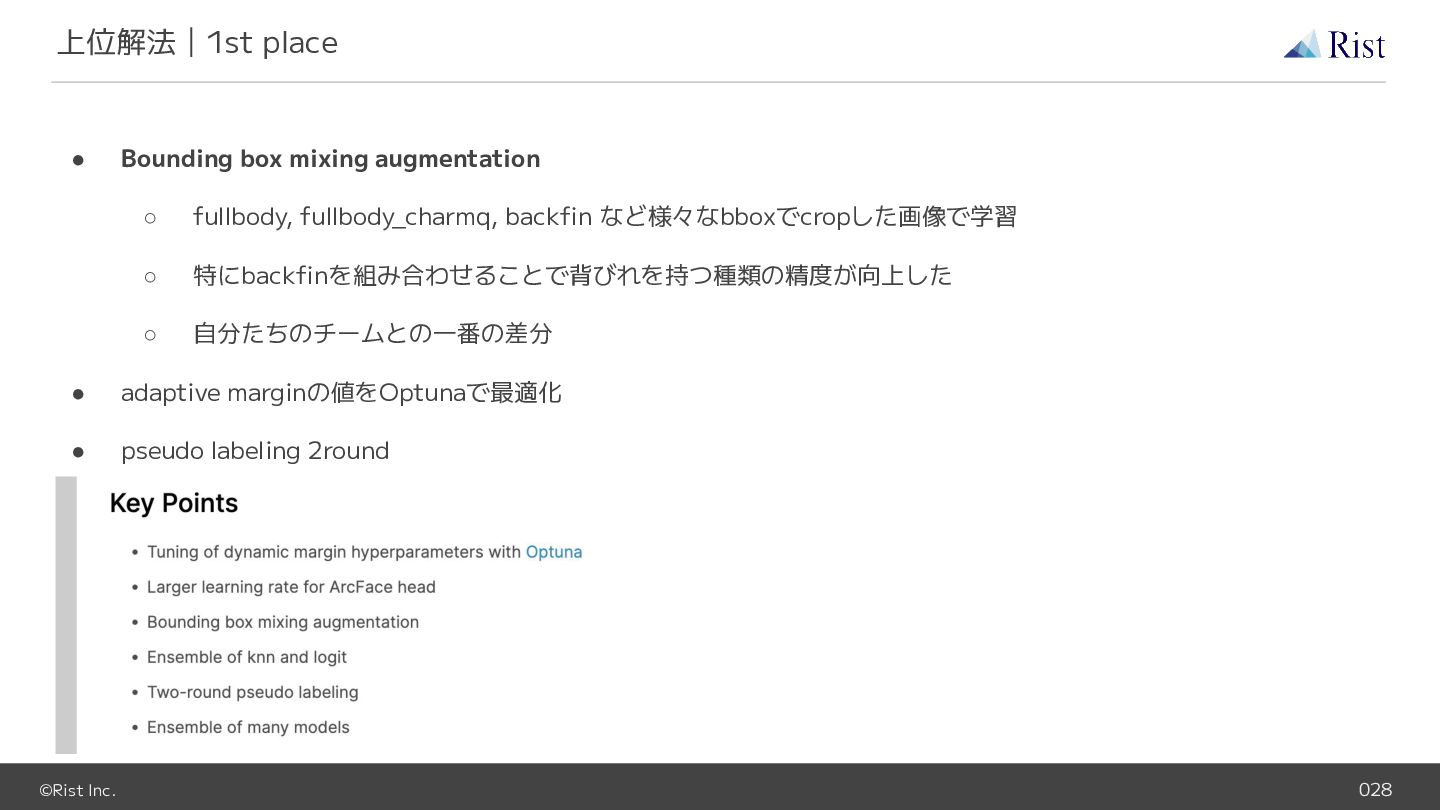
©Rist Inc. 028 • Bounding box mixing augmentation ◦ fullbody,
fullbody_charmq, backfin など様々なbboxでcropした画像で学習 ◦ 特にbackfinを組み合わせることで背びれを持つ種類の精度が向上した ◦ 自分たちのチームとの一番の差分 • adaptive marginの値をOptunaで最適化 • pseudo labeling 2round 上位解法|1st place
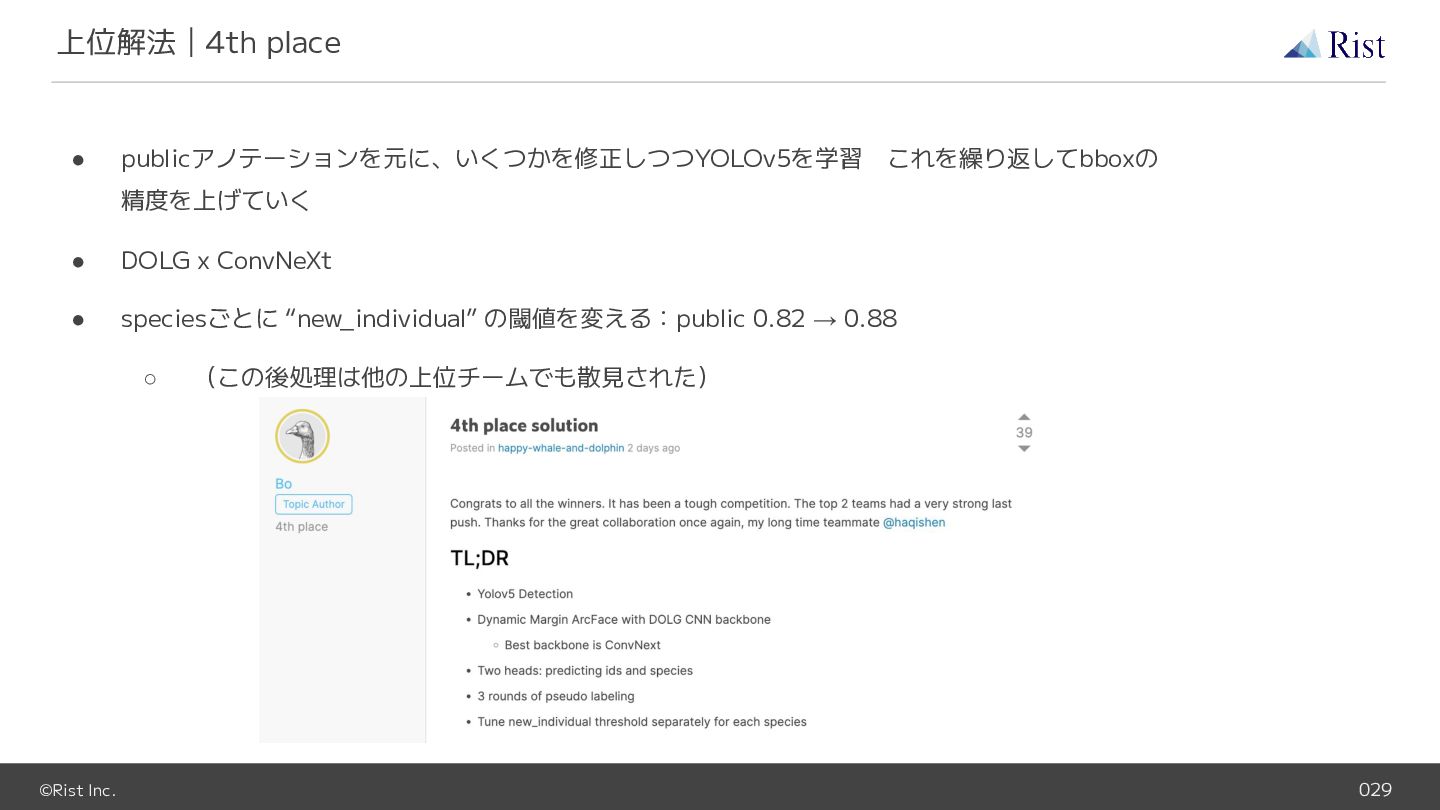
©Rist Inc. 029 • publicアノテーションを元に、いくつかを修正しつつYOLOv5を学習 これを繰り返してbboxの 精度を上げていく • DOLG x ConvNeXt
• speciesごとに “new_individual” の閾値を変える:public 0.82 → 0.88 ◦ (この後処理は他の上位チームでも散見された) 上位解法|4th place
©Rist Inc. 030 Appendix 2nd place solution + bbox mixing
augmentation
©Rist Inc. 031 弊チームのsolutionに対して、1stが使用していた bbox mixing augmentationの要素を取り入れ、 どの程度精度が改善するか検証 方法 •
モデルの学習時に、入力画像のcropを下記のように確率的に切り替える ◦ fullbody crop: p=0.75, backfin crop: p=0.25 ◦ その他の設定は2nd place solutionの通り • inference時はfullbody cropを使用(これまでと変わらず) • 上記設定で pseudo labeling を round-5 まで繰り返す 2nd place solution + bbox mixing augmentation
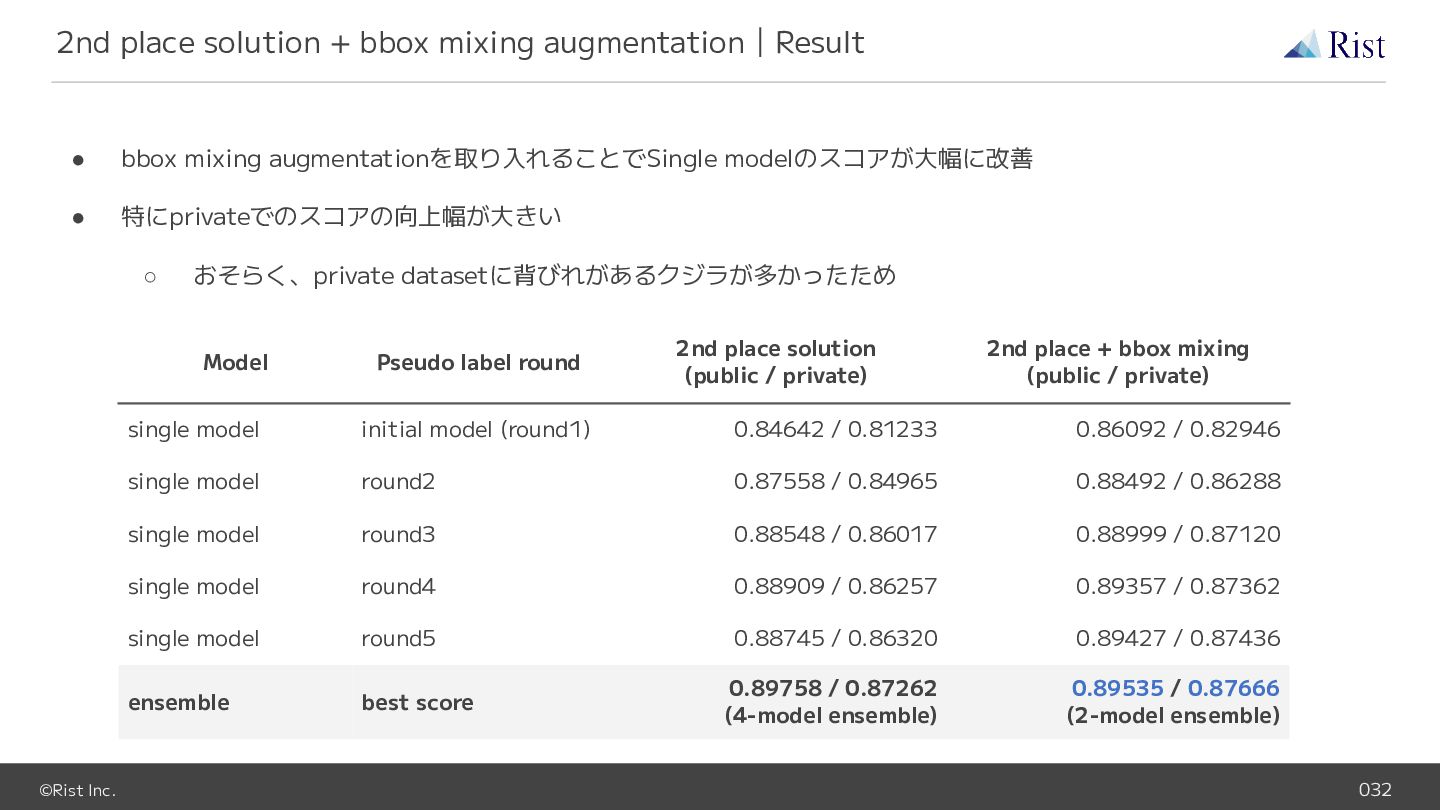
©Rist Inc. 032 • bbox mixing augmentationを取り入れることでSingle modelのスコアが大幅に改善 • 特にprivateでのスコアの向上幅が大きい
◦ おそらく、private datasetに背びれがあるクジラが多かったため 2nd place solution + bbox mixing augmentation|Result Model Pseudo label round 2nd place solution (public / private) 2nd place + bbox mixing (public / private) single model initial model (round1) 0.84642 / 0.81233 0.86092 / 0.82946 single model round2 0.87558 / 0.84965 0.88492 / 0.86288 single model round3 0.88548 / 0.86017 0.88999 / 0.87120 single model round4 0.88909 / 0.86257 0.89357 / 0.87362 single model round5 0.88745 / 0.86320 0.89427 / 0.87436 ensemble best score 0.89758 / 0.87262 (4-model ensemble) 0.89535 / 0.87666 (2-model ensemble)
©Rist Inc. 033 以上
©Rist Inc. 034 以下、回答用スライド
©Rist Inc. 035 • 3weeks ago:チームで参加開始, base model探索 (dataset, architecture..)
◦ 256x256などの画像サイズで検証サイクルをできるだけ多く回す • 2weeks ago:pseudo labeling / post-process / ensemble 方法検討 ◦ 周辺テクニックを試す。pseudo labelingの有効性をここで確認 • 1weeks ago:final model作成 ◦ これまでの結果とリソースなどを元にfinal modelの方向性を固め、学習をひたすら回す コンペ期間中の取り組み
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}