Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
HMSコンペ解説
Search
Rist Inc.
March 27, 2025
Technology
320
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
HMSコンペ解説
Rist Inc.
March 27, 2025
More Decks by Rist Inc.
See All by Rist Inc.
CMI - Detect Behavior with Sensor Data
rist
0
170
大規模言語モデル (LLM) 入門
rist
2
710
Drawing with LLMs
rist
0
620
Eedi - Mining Misconceptions in Mathematics 4th place solution
rist
1
430
モンテカルロ木探索のパフォーマンスを予測する Kaggleコンペ解説 〜生成AIによる未知のゲーム生成〜
rist
4
2k
Happywhale - Whale and Dolphin Identification 2nd place solution
rist
0
290
Other Decks in Technology
See All in Technology
あなたの『Site』はどこですか? — xREという考え方
miyamu
0
1.2k
ループエンジニアリングでE2Eテストを実践
noriyukitakei
0
330
[2026-07-15] AI Ready なはずだったアーキテクチャと、見えてきた課題・次に目指す状態
wxyzzz
4
1.9k
Zoom2Youtube.Claude
kawaguti
PRO
3
490
はじめてのWDM
miyukichi_ospf
1
140
Mastraエージェント、どのクラウドにデプロイする?
minorun365
PRO
2
180
AI Agent SaaS を支える自社仮想化基盤への挑戦と実運用 / ai-agent-saas-virtualization
flatt_security
2
3.6k
知らん間に、回ってる
ming_ayami
0
380
DMM.com 購入改善推進チーム におけるCodeRabbitを用いた レビューフロー改善の一例
ysknsid25
2
580
しくみを学んで使いこなそう GitHub Copilot app
torumakabe
1
170
product engineering with qa
nealle
0
160
LLMやAIエージェントをソフトウェアに組み込むプラクティス
shibuiwilliam
1
260
Featured
See All Featured
10 Git Anti Patterns You Should be Aware of
lemiorhan
PRO
659
62k
Lightning Talk: Beautiful Slides for Beginners
inesmontani
PRO
2
600
Winning Ecommerce Organic Search in an AI Era - #searchnstuff2025
aleyda
1
2.1k
Testing 201, or: Great Expectations
jmmastey
46
8.2k
The SEO Collaboration Effect
kristinabergwall1
1
500
Jamie Indigo - Trashchat’s Guide to Black Boxes: Technical SEO Tactics for LLMs
techseoconnect
PRO
0
270
Leveraging LLMs for student feedback in introductory data science courses - posit::conf(2025)
minecr
1
310
CoffeeScript is Beautiful & I Never Want to Write Plain JavaScript Again
sstephenson
162
16k
What does AI have to do with Human Rights?
axbom
PRO
1
2.2k
Designing Dashboards & Data Visualisations in Web Apps
destraynor
231
55k
Leo the Paperboy
mayatellez
8
1.9k
Imperfection Machines: The Place of Print at Facebook
scottboms
270
14k
Transcript
HMSコンペ解説 株式会社Rist
©Rist Inc. 02 1. Competition概要 2. 弊チームの解法紹介 目次
©Rist Inc. 03 Competition概要
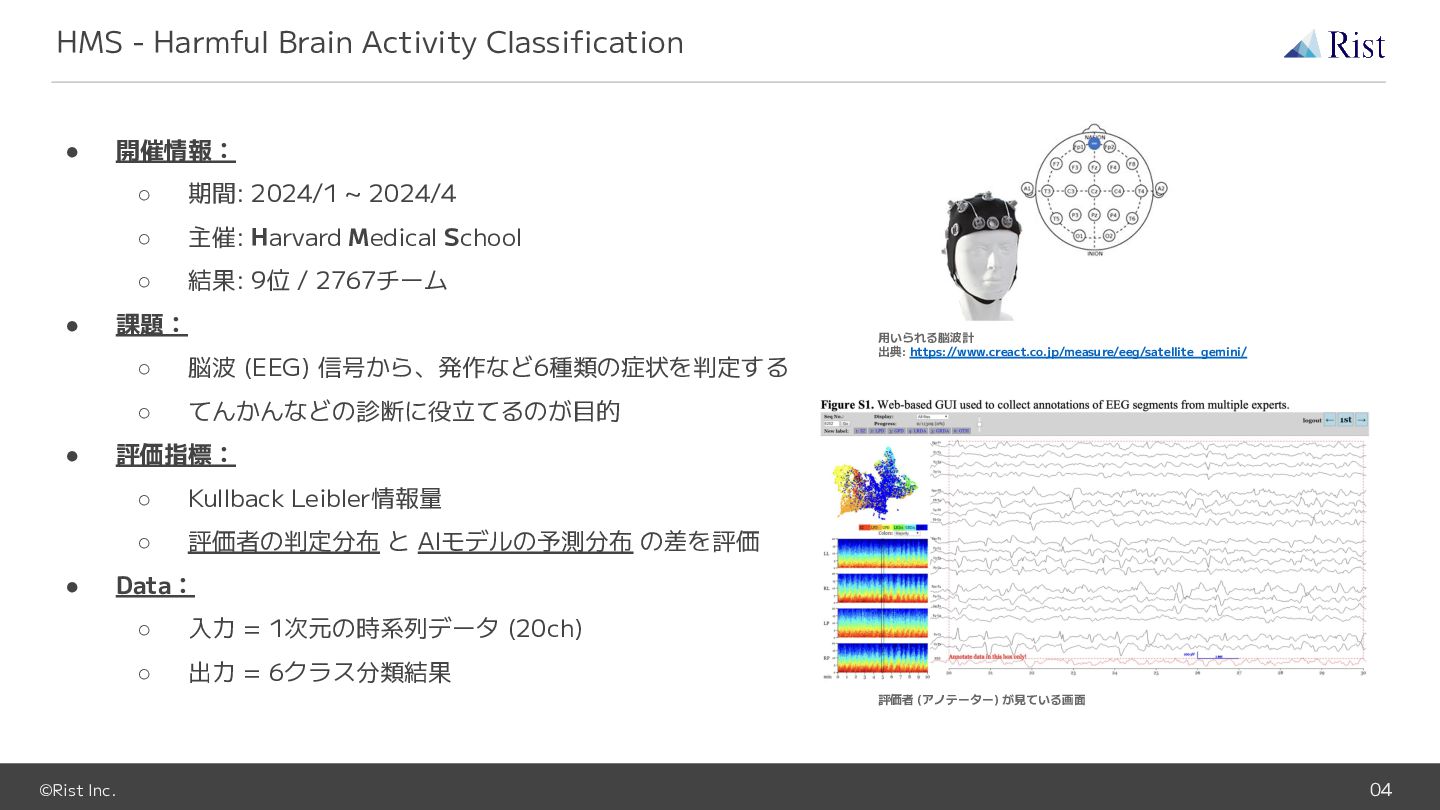
©Rist Inc. 04 • 開催情報: ◦ 期間: 2024/1 ~ 2024/4
◦ 主催: Harvard Medical School ◦ 結果: 9位 / 2767チーム • 課題: ◦ 脳波 (EEG) 信号から、発作など6種類の症状を判定する ◦ てんかんなどの診断に役立てるのが目的 • 評価指標: ◦ Kullback Leibler情報量 ◦ 評価者の判定分布 と AIモデルの予測分布 の差を評価 • Data: ◦ 入力 = 1次元の時系列データ (20ch) ◦ 出力 = 6クラス分類結果 HMS - Harmful Brain Activity Classification 用いられる脳波計 出典: https://www.creact.co.jp/measure/eeg/satellite_gemini/ 評価者 (アノテーター) が見ている画面
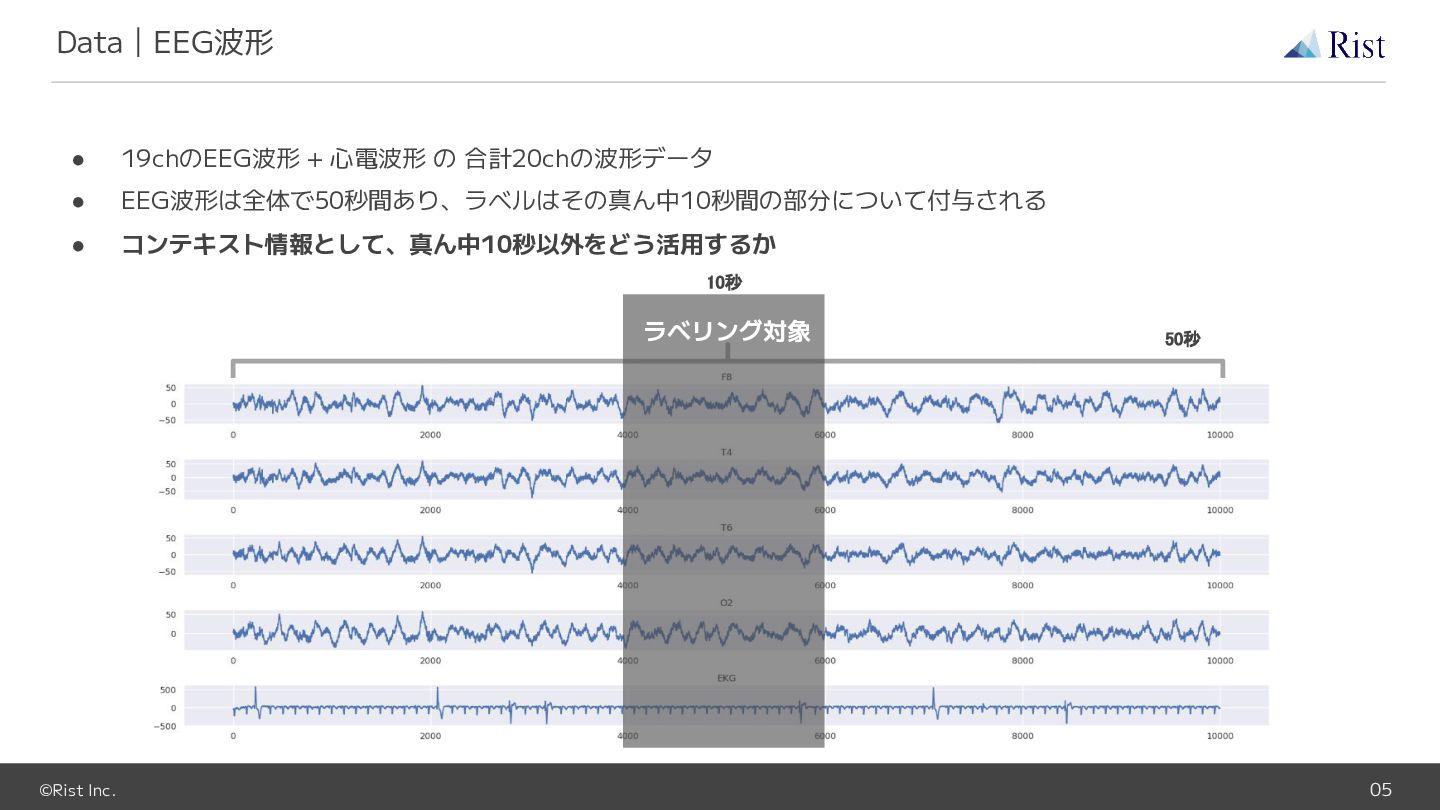
©Rist Inc. 05 • 19chのEEG波形 + 心電波形 の 合計20chの波形データ •
EEG波形は全体で50秒間あり、ラベルはその真ん中10秒間の部分について付与される • コンテキスト情報として、真ん中10秒以外をどう活用するか Data|EEG波形 50秒 ラベリング対象 10秒
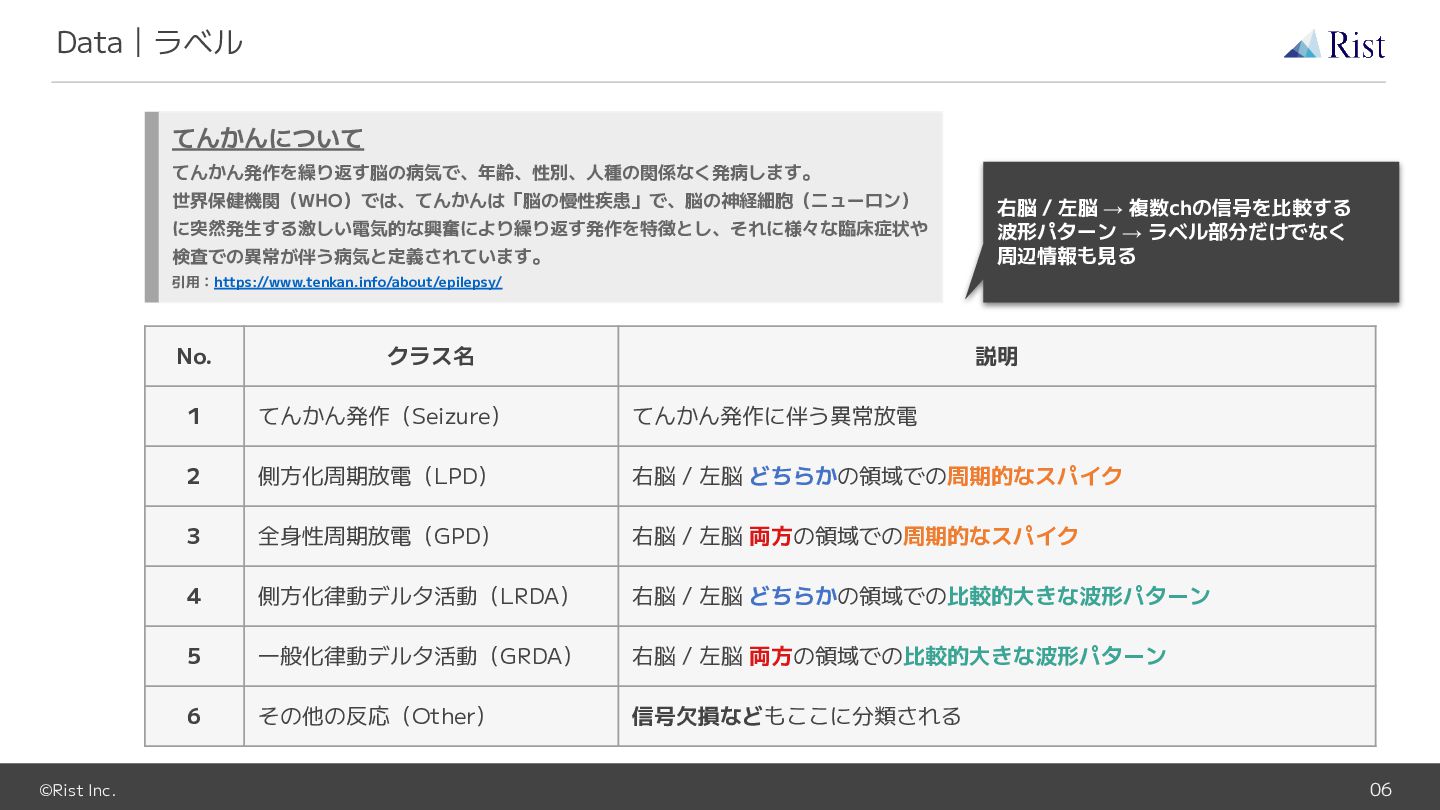
©Rist Inc. 06 Data|ラベル No. クラス名 説明 1 てんかん発作(Seizure) てんかん発作に伴う異常放電
2 側方化周期放電(LPD) 右脳 / 左脳 どちらかの領域での周期的なスパイク 3 全身性周期放電(GPD) 右脳 / 左脳 両方の領域での周期的なスパイク 4 側方化律動デルタ活動(LRDA) 右脳 / 左脳 どちらかの領域での比較的大きな波形パターン 5 一般化律動デルタ活動(GRDA) 右脳 / 左脳 両方の領域での比較的大きな波形パターン 6 その他の反応(Other) 信号欠損などもここに分類される てんかんについて てんかん発作を繰り返す脳の病気で、年齢、性別、人種の関係なく発病します。 世界保健機関(WHO)では、てんかんは「脳の慢性疾患」で、脳の神経細胞(ニューロン) に突然発生する激しい電気的な興奮により繰り返す発作を特徴とし、それに様々な臨床症状や 検査での異常が伴う病気と定義されています。 引用:https://www.tenkan.info/about/epilepsy/ 右脳 / 左脳 → 複数chの信号を比較する 波形パターン → ラベル部分 けでなく 周辺情報も見る
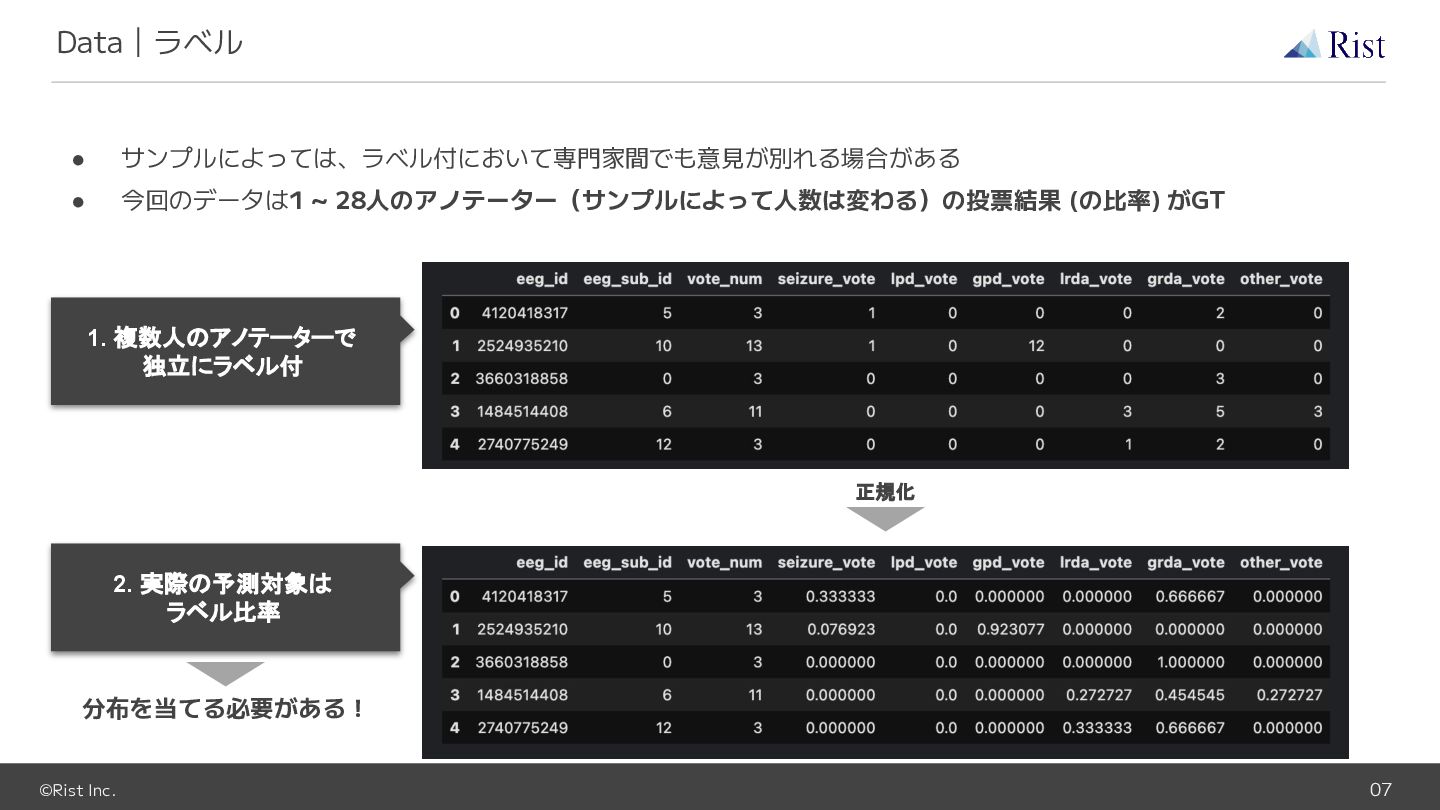
©Rist Inc. 07 Data|ラベル • サンプルによっては、ラベル付において専門家間でも意見が別れる場合がある • 今回のデータは1 ~ 28人のアノテーター(サンプルによって人数は変わる)の投票結果
(の比率) がGT 正規化 1. 複数人のアノテーターで 独立にラベル付 2. 実際の予測対象は ラベル比率 分布を当てる必要がある!
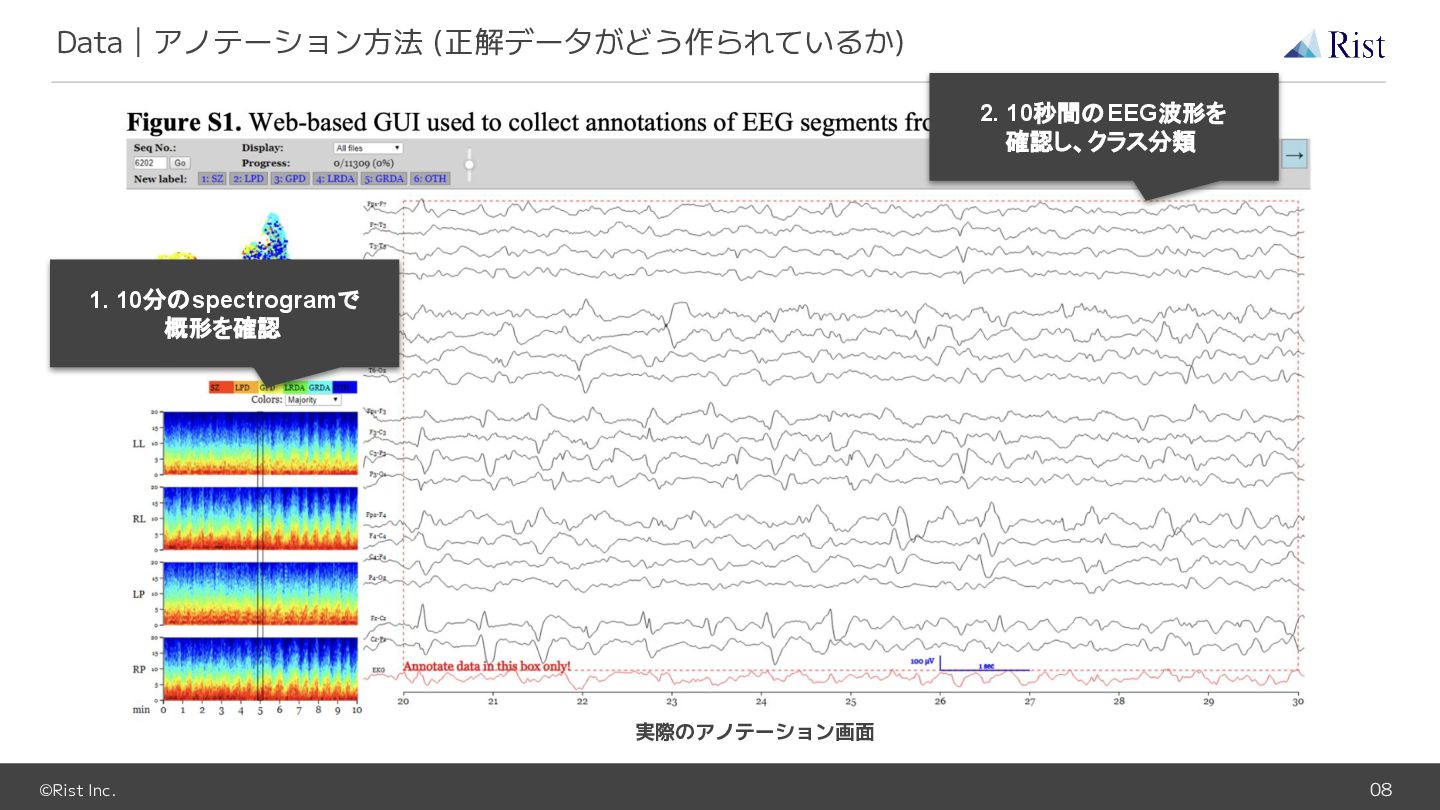
©Rist Inc. 08 Data|アノテーション方法 (正解データがどう作られているか) 1. 10分のspectrogramで 概形を確認 2. 10秒間のEEG波形を
確認し、クラス分類 実際のアノテーション画面
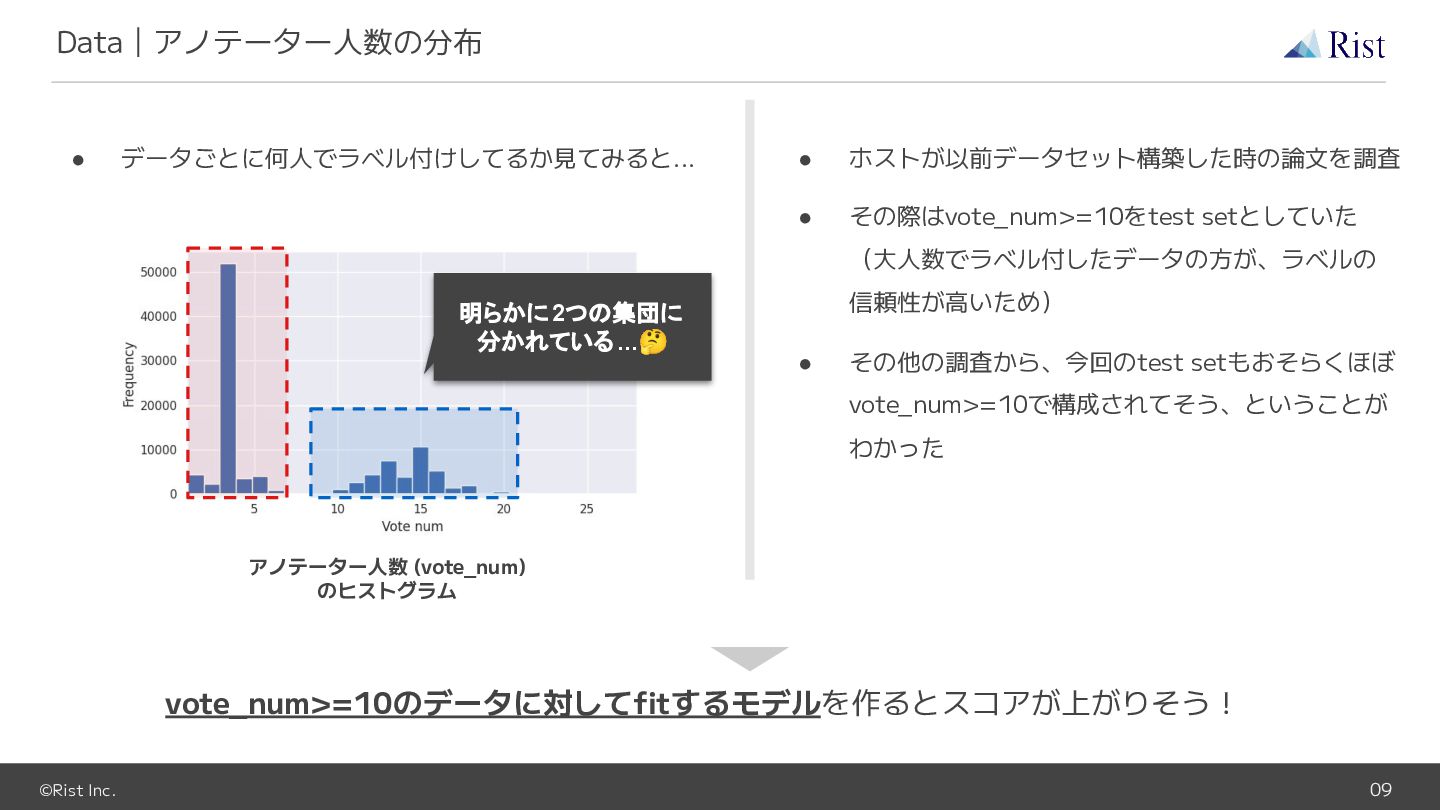
©Rist Inc. 09 Data|アノテーター人数の分布 • データごとに何人でラベル付けしてるか見てみると... アノテーター人数 (vote_num) のヒストグラム 明らかに2つの集団に
分かれている ...🤔 • ホストが以前データセット構築した時の論文を調査 • その際はvote_num>=10をtest setとしていた (大人数でラベル付したデータの方が、ラベルの 信頼性が高いため) • その他の調査から、今回のtest setもおそらくほぼ vote_num>=10で構成されてそう、ということが わかった vote_num>=10のデータに対してfitするモデルを作るとスコアが上がりそう!
©Rist Inc. 010 Data|ここまでのまとめ • ラベルがつけられる領域(10s) と周辺領域 (50s) • 複数chでのスパイクの同期
/ 非同期が大事 • アノテーションでは、最初に10分間の荒いスペクトログラムで概形を確認して、その後見たい領域 (10s) に フォーカスしてラベルをつけている • どうやらアノテーション数に偏りがあり、特に大人数でつけられているデータに対する予測精度が大事らしい ◦ (それでなくとも、少人数でつけたサンプルはラベルノイズが多いはず) データの傾向が掴めるとモデルの方向性がわかる
©Rist Inc. 011 弊チームの解法紹介
©Rist Inc. 012 全体 • 入力データ ◦ 10sだけでなく50sまで含めてモデルに入力 (コンテキスト情報の利用) ◦
アノテーションに倣って、10分間の荒いスペクトログラムも入力に加える • モデルの学習戦略 ◦ vote_num>=10に対してfittingしたい ▪ vote_num>=10のデータで学習 ▪ そうすると捨てるデータが増えてしまいもったいない... • ノイズの多い vote_num<10のデータは事前学習につかう • チームでの取り組み方 ◦ 各自でパイプラインを組み、お互い良かった(効いた)点を取り込みながらモデルを育てていく ◦ 最終的には3人分のモデルを合わせて大規模なensemble (モデルの予測値を混ぜる)
©Rist Inc. 013 詳細|前処理 • フィルタリング処理に気をつかう: ◦ 60Hzノッチフィルタ(電気ノイズの除去)、0.4Hzハイパスフィルタ(低周波ノイズ除去) ◦ chごとにrobust
scaler ▪ この辺りのフィルタリングを失敗すると、一気にモデルの学習が進まなくなる ▪ 波形処理の経験豊富なメンバ (nikaido) の知見によるところが大きい • ch同士で差分をとる: ◦ 実際にアノテーターが見ている波形は下記のDouble bananaだが、他にも様々な差分の取り方を採用 し、それぞれでモデルを作る (多様性確保の目的) ◦ 右脳 / 左脳の同期 / 非同期の一部はここでケアできる
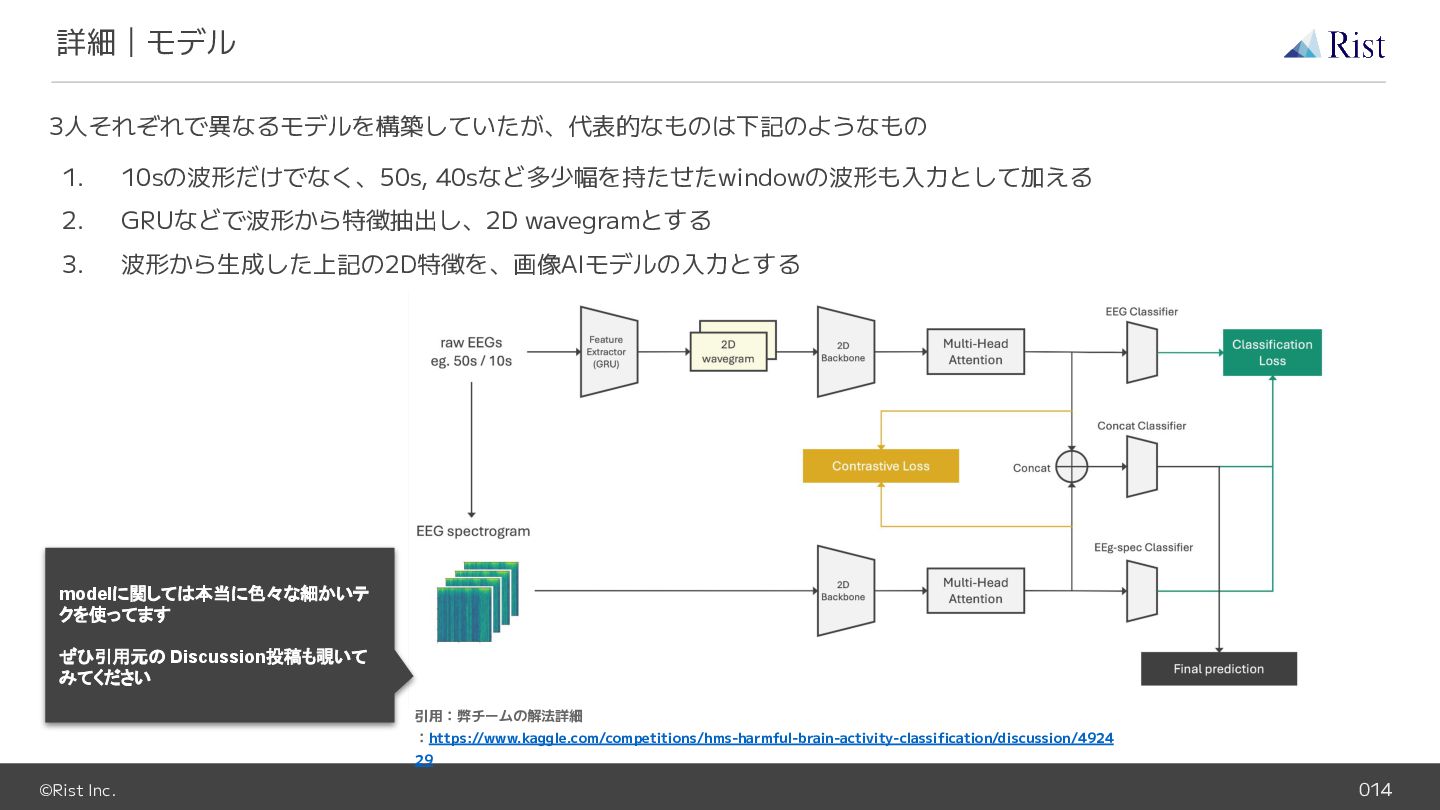
©Rist Inc. 014 詳細|モデル 3人それぞれで異なるモデルを構築していたが、代表的なものは下記のようなもの 1. 10sの波形だけでなく、50s, 40sなど多少幅を持たせたwindowの波形も入力として加える 2. GRUなどで波形から特徴抽出し、2D
wavegramとする 3. 波形から生成した上記の2D特徴を、画像AIモデルの入力とする 引用:弊チームの解法詳細 :https://www.kaggle.com/competitions/hms-harmful-brain-activity-classification/discussion/4924 29 modelに関しては本当に色々な細かいテ クを使ってます ぜひ引用元の Discussion投稿も覗いて みてください
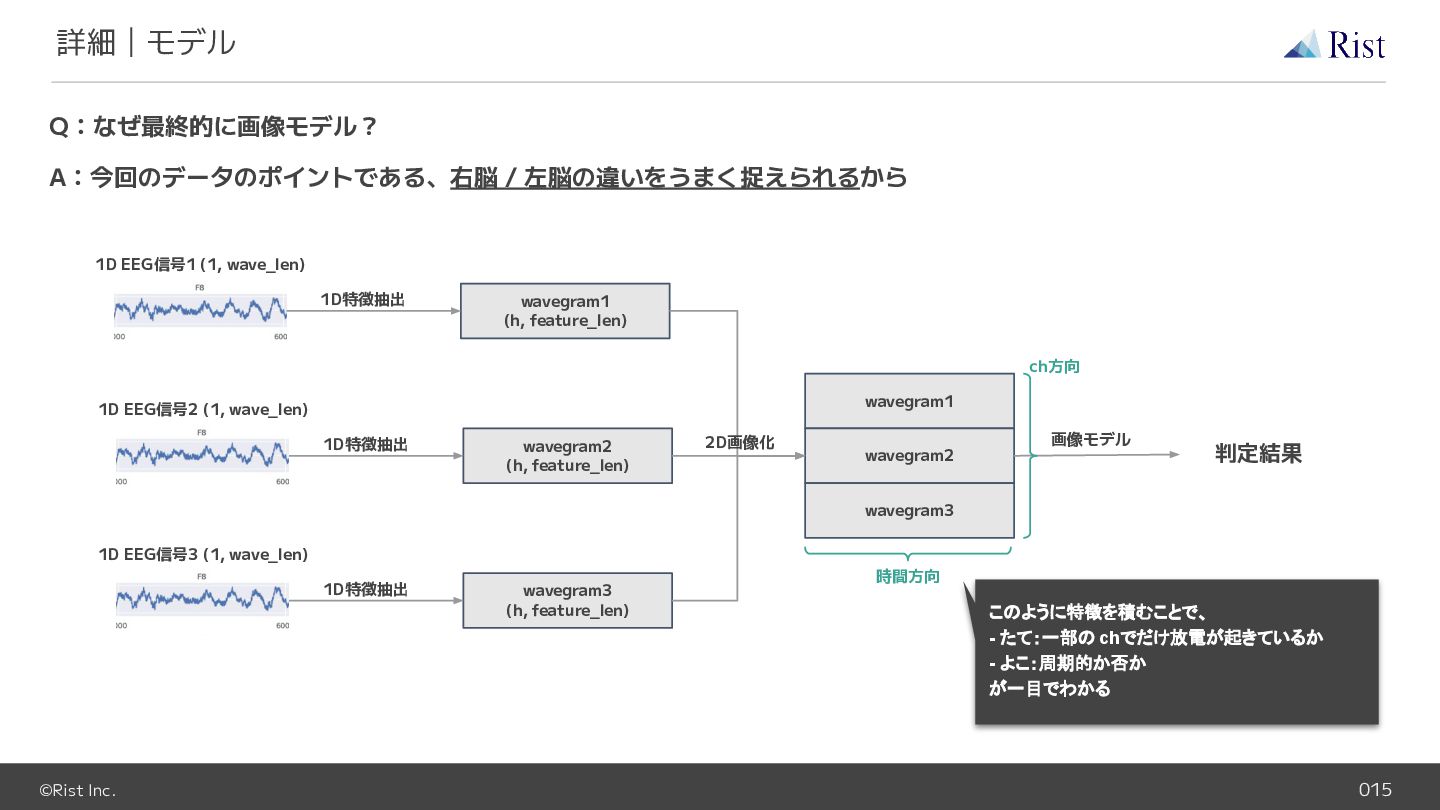
©Rist Inc. 015 詳細|モデル Q:なぜ最終的に画像モデル? A:今回のデータのポイントである、右脳 / 左脳の違いをうまく捉えられるから wavegram1 (h,
feature_len) 1D EEG信号1 (1, wave_len) 1D特徴抽出 wavegram2 (h, feature_len) 1D EEG信号2 (1, wave_len) 1D特徴抽出 wavegram3 (h, feature_len) 1D EEG信号3 (1, wave_len) 1D特徴抽出 wavegram1 wavegram2 wavegram3 2D画像化 画像モデル 判定結果 時間方向 ch方向 このように特徴を積むことで、 - たて:一部の chでだけ放電が起きているか - よこ:周期的か否か が一目でわかる
©Rist Inc. 016 コンペを振り返って なぜ金圏に入れたか • おそらく一番大きいのは、test setが大人数サンプルで構成されていると気づけた点 • あとは、下記が特に貢献度が高い
◦ 前処理 (ここが適切でないと、そもそも学習ができない) ◦ モデル構成 (右脳 / 左脳の違いを効率よく学習する) なぜ賞金圏 (3位以内)に入れなかったか • モデルの多様性不足 ◦ 終盤で手札が尽きてしまった。普段から手札を増やす努力をすべき ◦ 上位解法を見てみると、自分たちの知らない活性化関数やデータ変換の方法などが散見された • モデルのブレンドの仕方 ◦ 仮説を立てたら、ある程度のリスクを取る覚悟で積極的な方法も採用するべきだった ◦ 上位チームでは、vote_num>=10にさらにfitさせるために積極的なmodel stackingなどを利用していた
©Rist Inc. 017 以上
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}