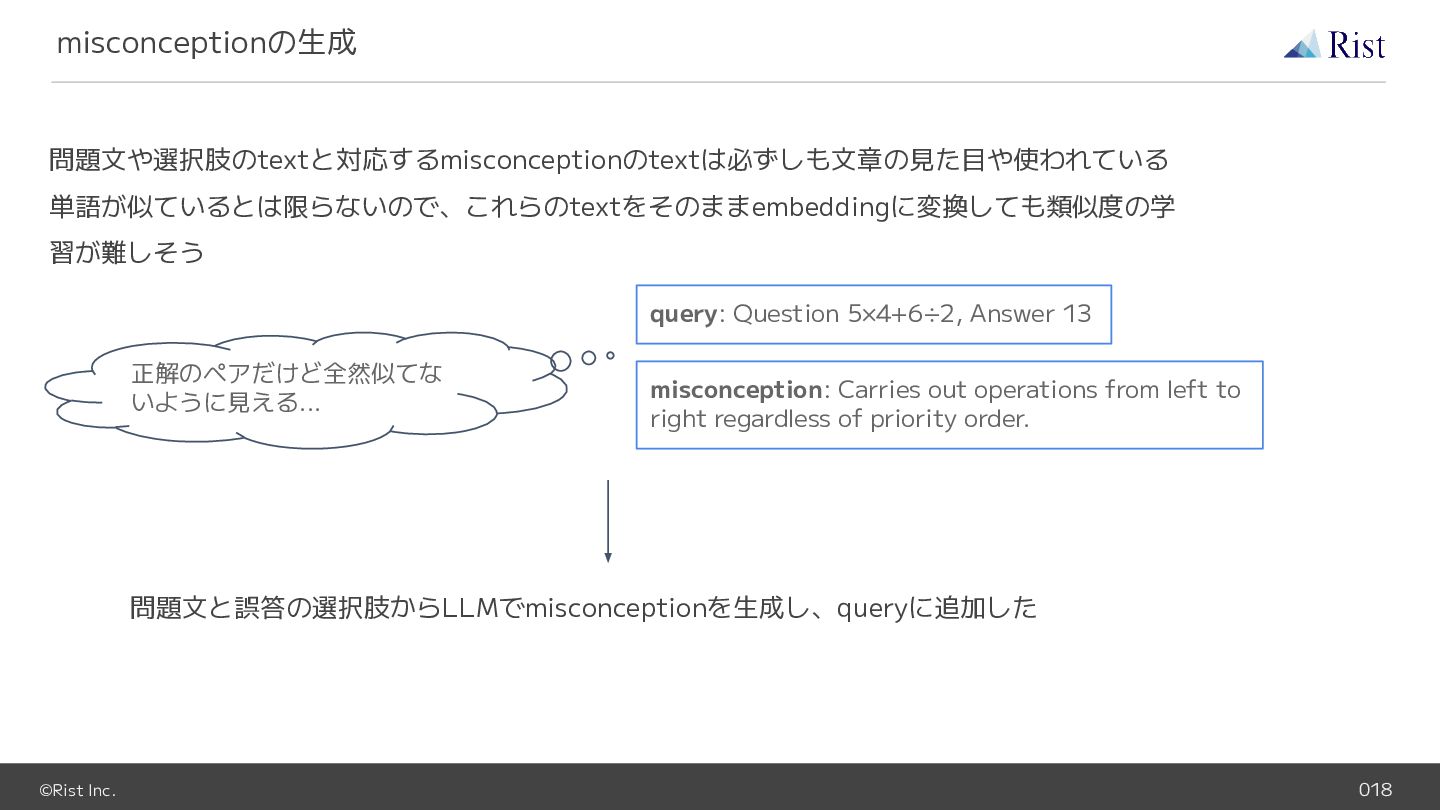
Answer 13 misconception: Carries out operations from left to right regardless of priority order. 正解のペアだけど全然似てな いように見える... 問題文と誤答の選択肢からLLMでmisconceptionを生成し、queryに追加した
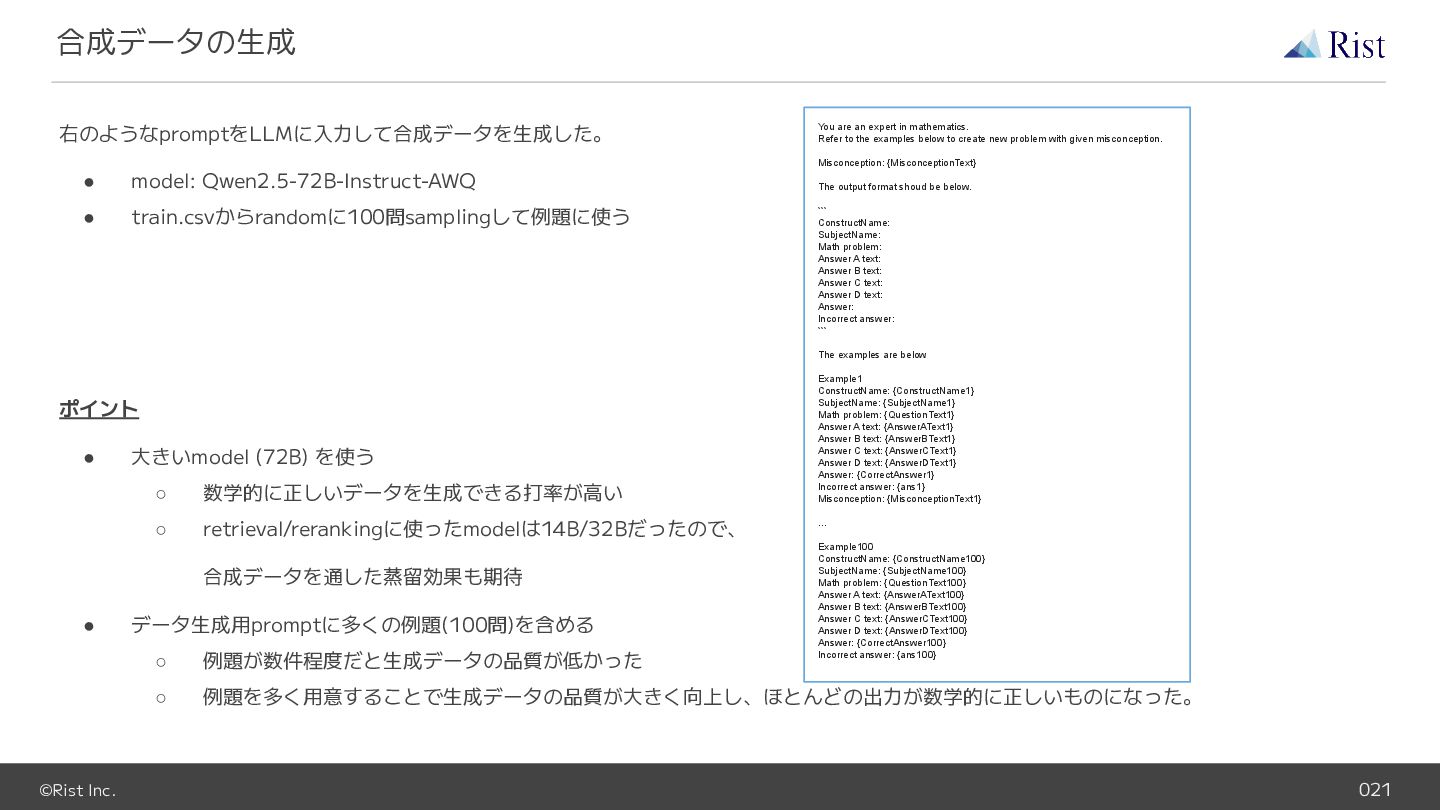
• 大きいmodel (72B) を使う ◦ 数学的に正しいデータを生成できる打率が高い ◦ retrieval/rerankingに使ったmodelは14B/32Bだったので、 合成データを通した蒸留効果も期待 • データ生成用promptに多くの例題(100問)を含める ◦ 例題が数件程度だと生成データの品質が低かった ◦ 例題を多く用意することで生成データの品質が大きく向上し、ほとんどの出力が数学的に正しいものになった。 合成データの生成 You are an expert in mathematics. Refer to the examples below to create new problem with given misconception. Misconception: {MisconceptionText} The output format shoud be below. ``` ConstructName: SubjectName: Math problem: Answer A text: Answer B text: Answer C text: Answer D text: Answer: Incorrect answer: ``` The examples are below Example1 ConstructName: {ConstructName1} SubjectName: {SubjectName1} Math problem: {QuestionText1} Answer A text: {AnswerAText1} Answer B text: {AnswerBText1} Answer C text: {AnswerCText1} Answer D text: {AnswerDText1} Answer: {CorrectAnswer1} Incorrect answer: {ans1} Misconception: {MisconceptionText1} … Example100 ConstructName: {ConstructName100} SubjectName: {SubjectName100} Math problem: {QuestionText100} Answer A text: {AnswerAText100} Answer B text: {AnswerBText100} Answer C text: {AnswerCText100} Answer D text: {AnswerDText100} Answer: {CorrectAnswer100} Incorrect answer: {ans100}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
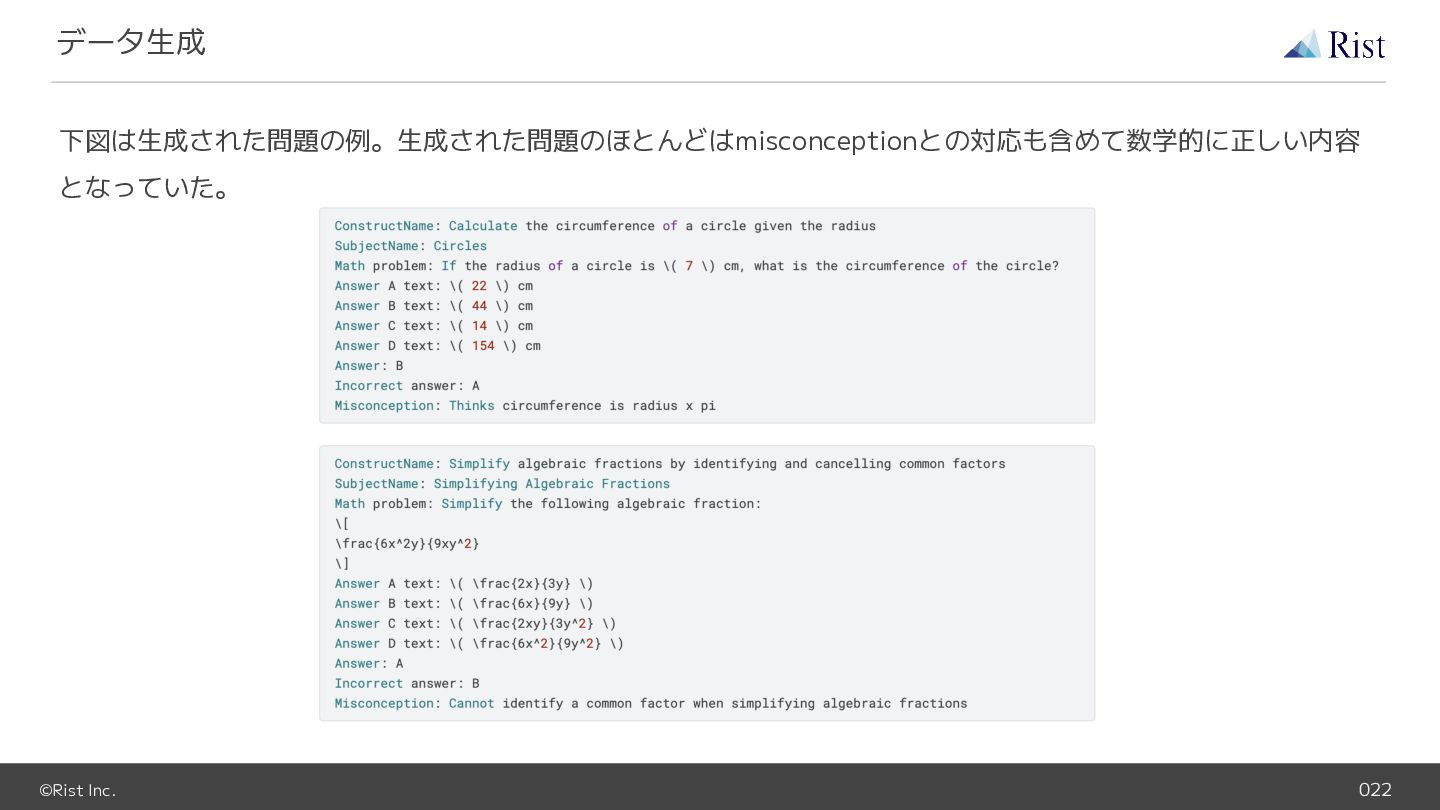{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}