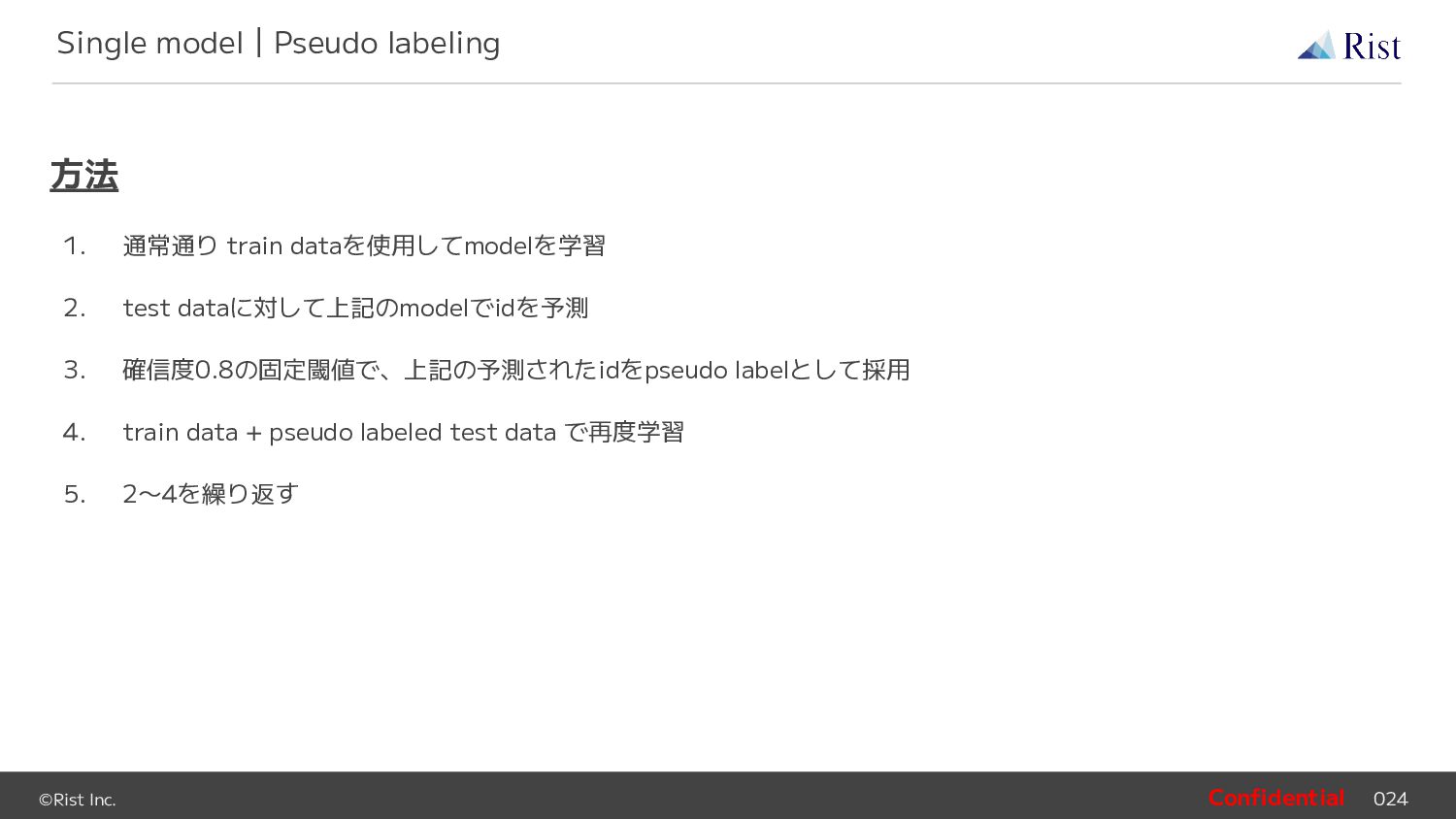
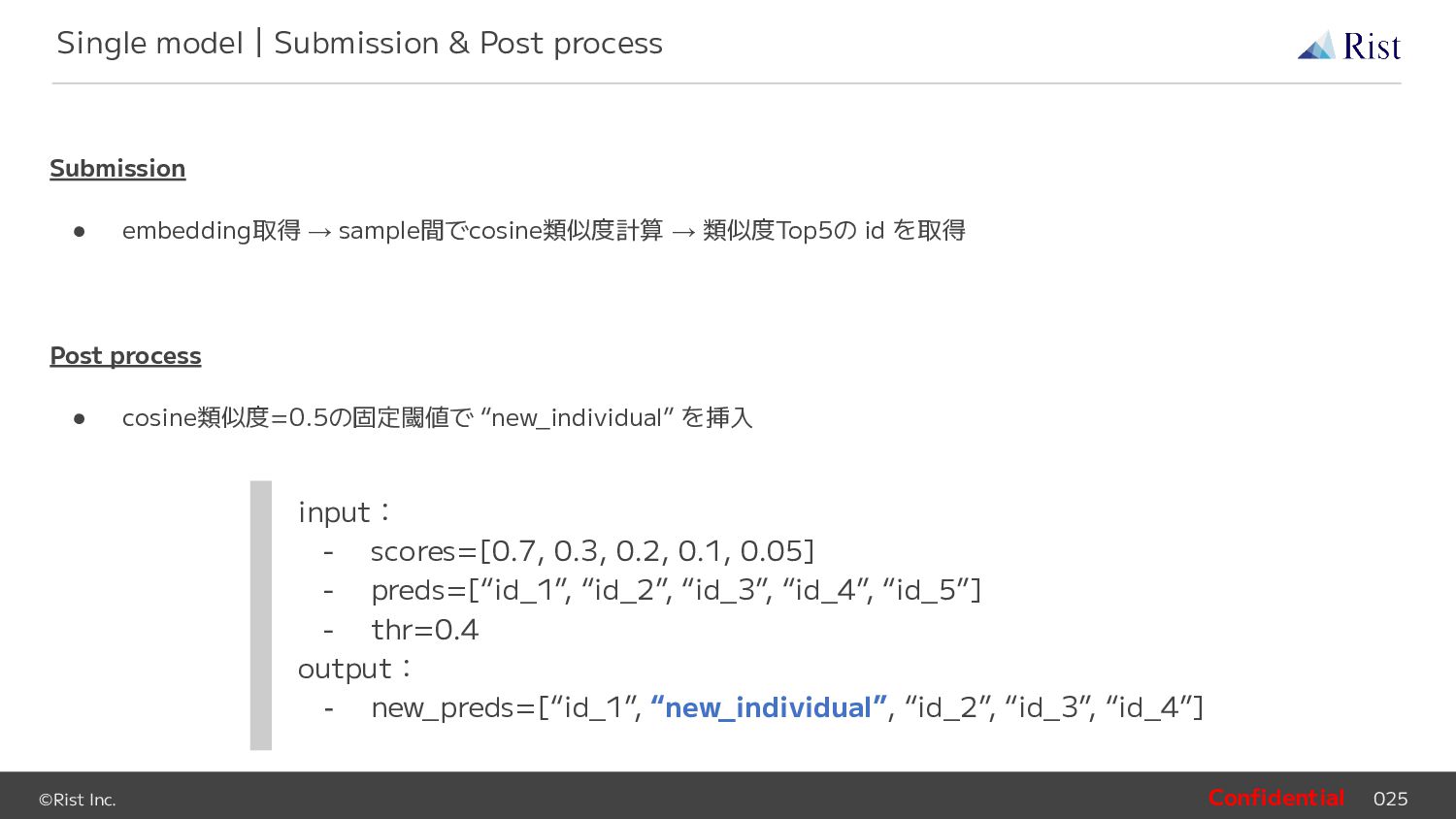
id を取得 Post process • cosine類似度=0.5の固定閾値で “new_individual” を挿入 Single model|Submission & Post process input: - scores=[0.7, 0.3, 0.2, 0.1, 0.05] - preds=[“id_1”, “id_2”, “id_3”, “id_4”, “id_5”] - thr=0.4 output: - new_preds=[“id_1”, “new_individual”, “id_2”, “id_3”, “id_4”]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
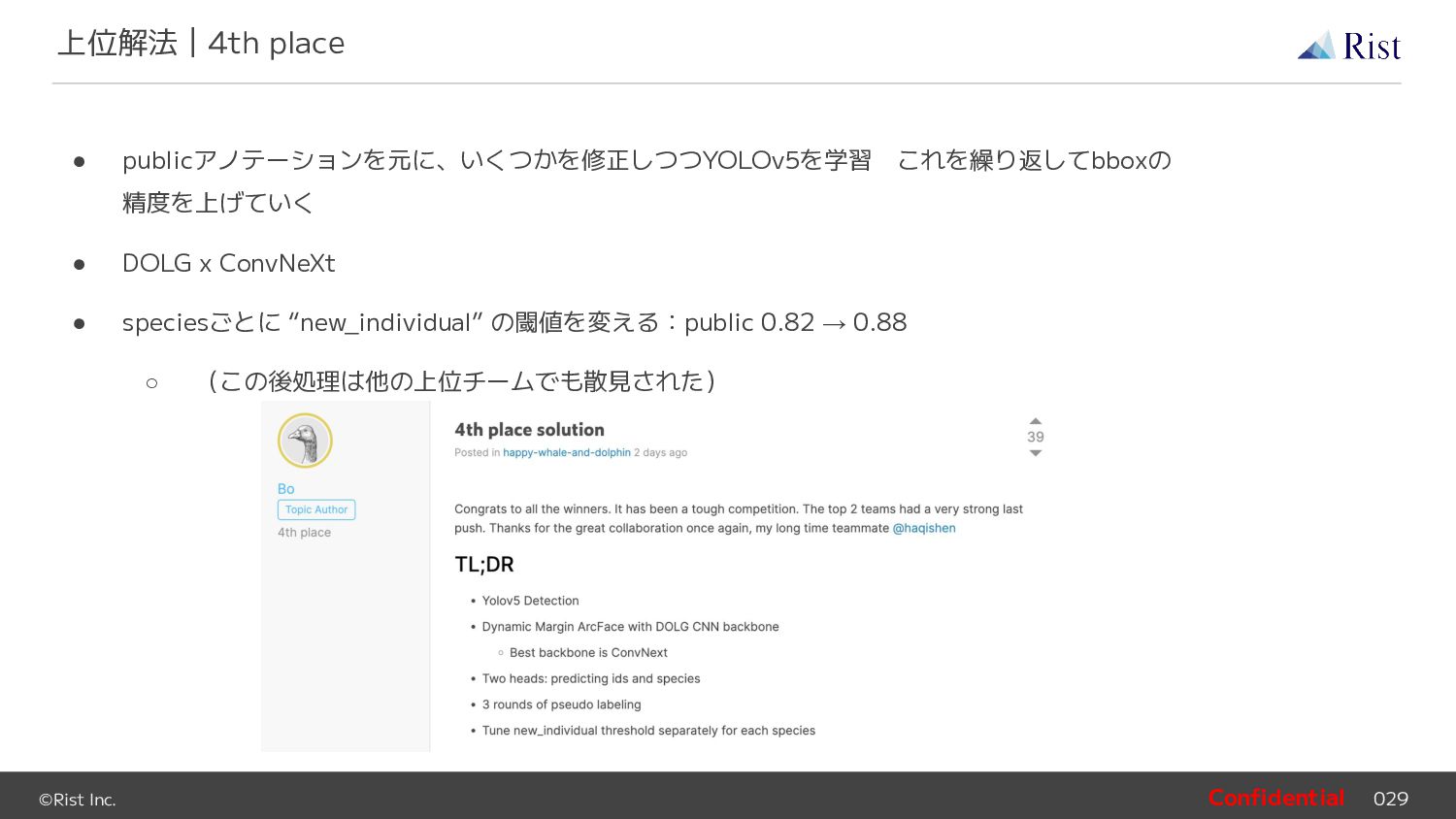{kind=link}
{kind=link}
{kind=link}
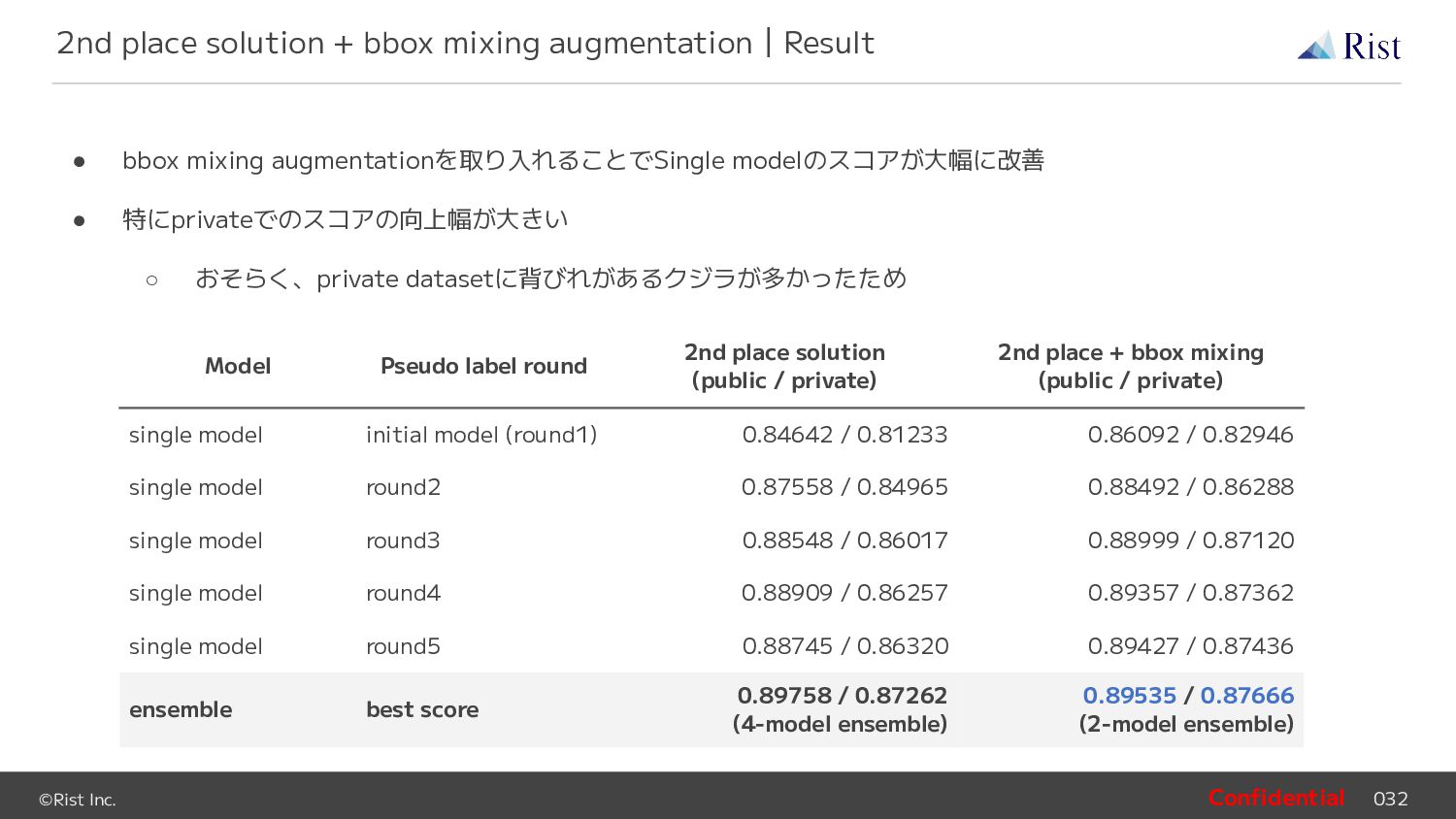{kind=link}
{kind=link}
{kind=link}
{kind=link}