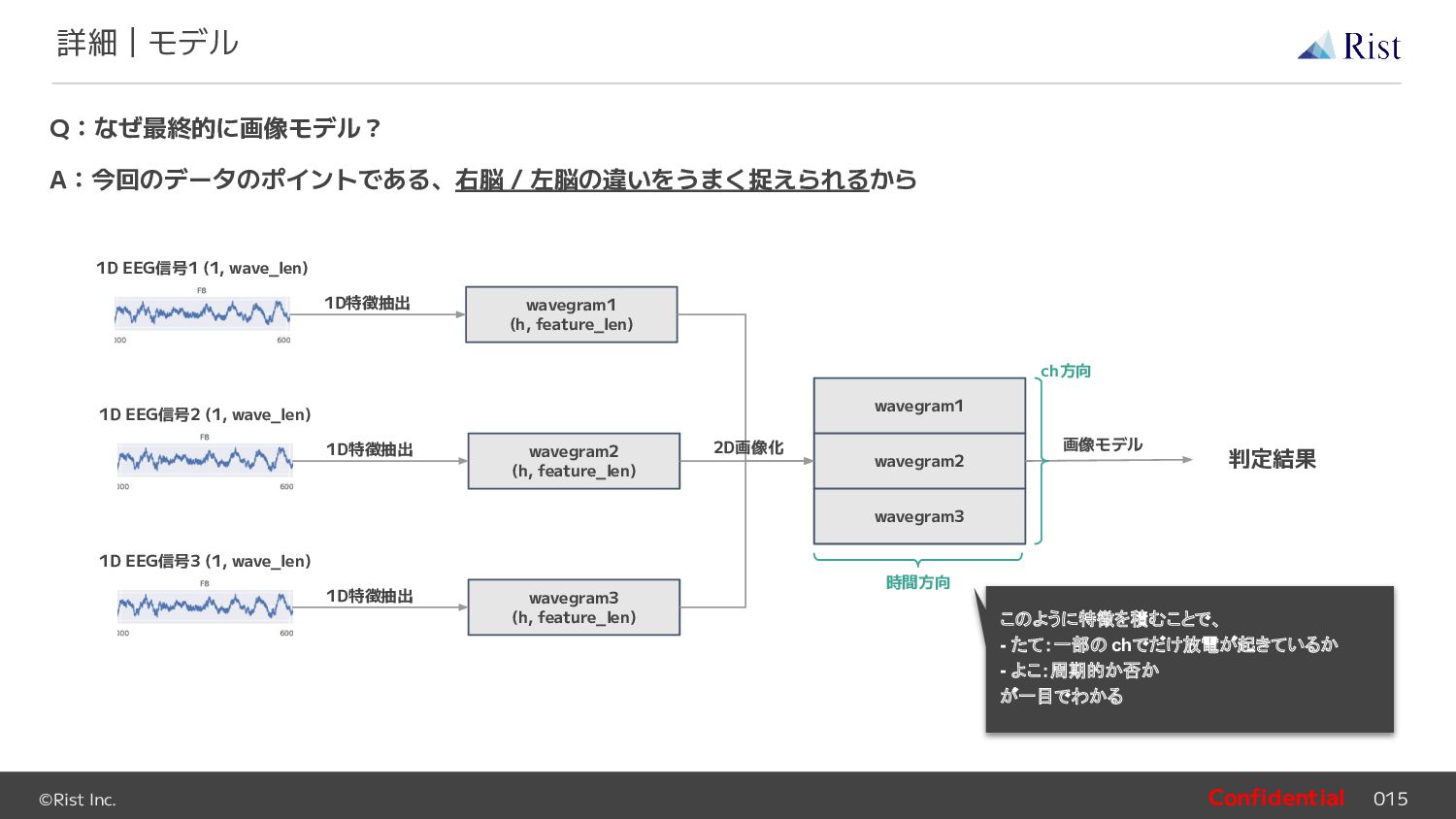
feature_len) 1D EEG信号1 (1, wave_len) 1D特徴抽出 wavegram2 (h, feature_len) 1D EEG信号2 (1, wave_len) 1D特徴抽出 wavegram3 (h, feature_len) 1D EEG信号3 (1, wave_len) 1D特徴抽出 wavegram1 wavegram2 wavegram3 2D画像化 画像モデル 判定結果 時間方向 ch方向 このように特徴を積むことで、 - たて:一部の chでだけ放電が起きているか - よこ:周期的か否か が一目でわかる
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
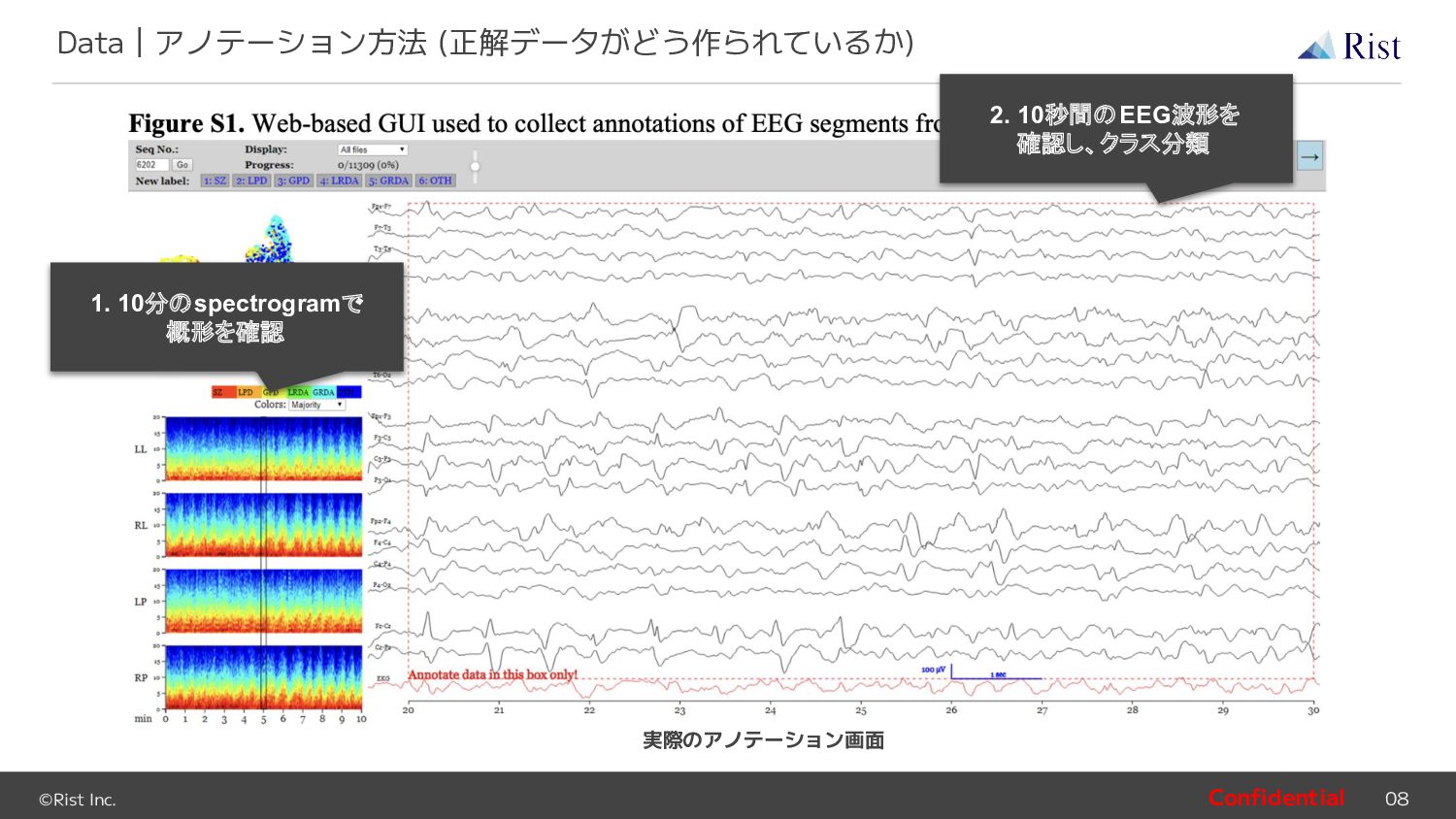{kind=link}
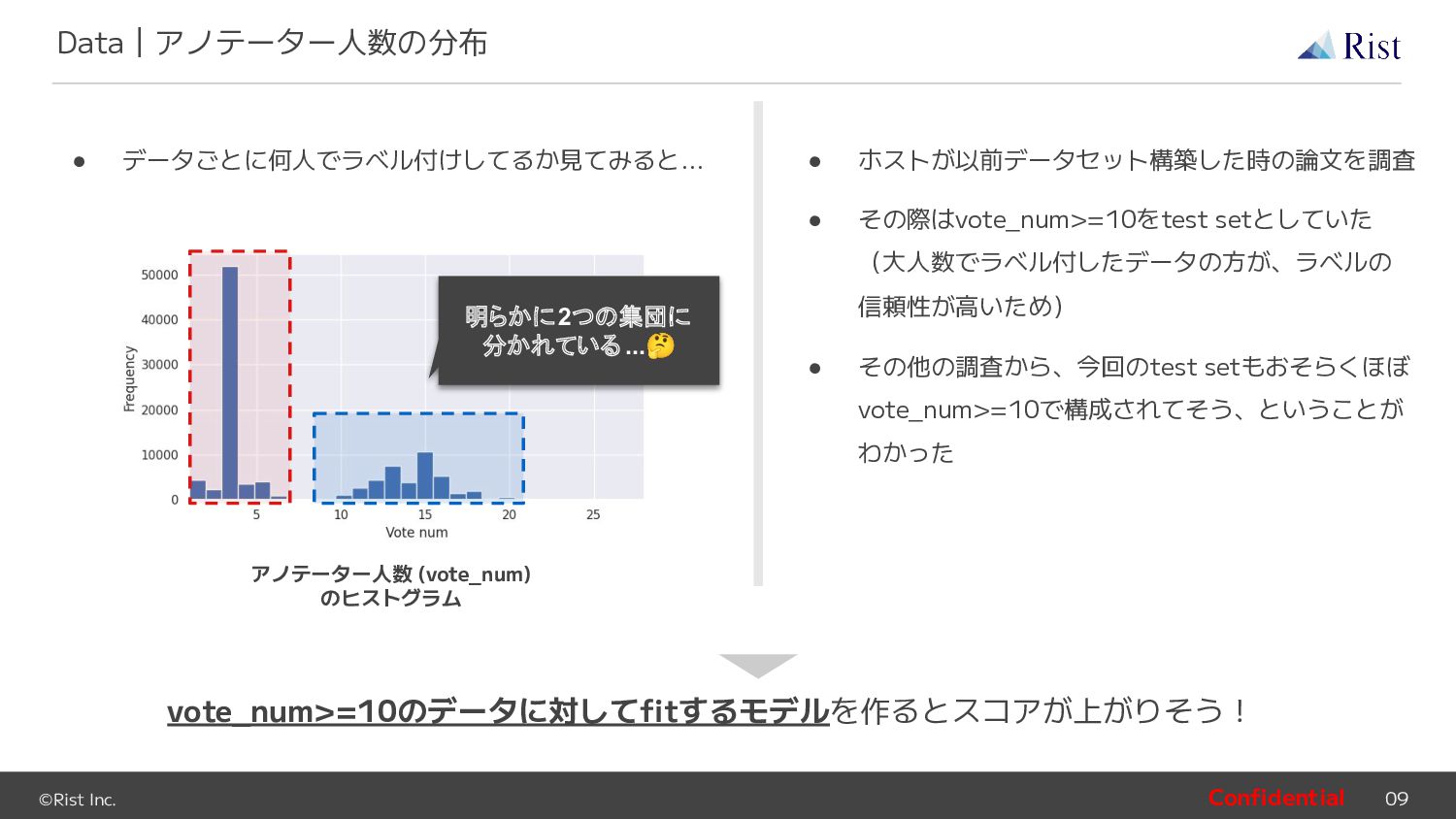{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
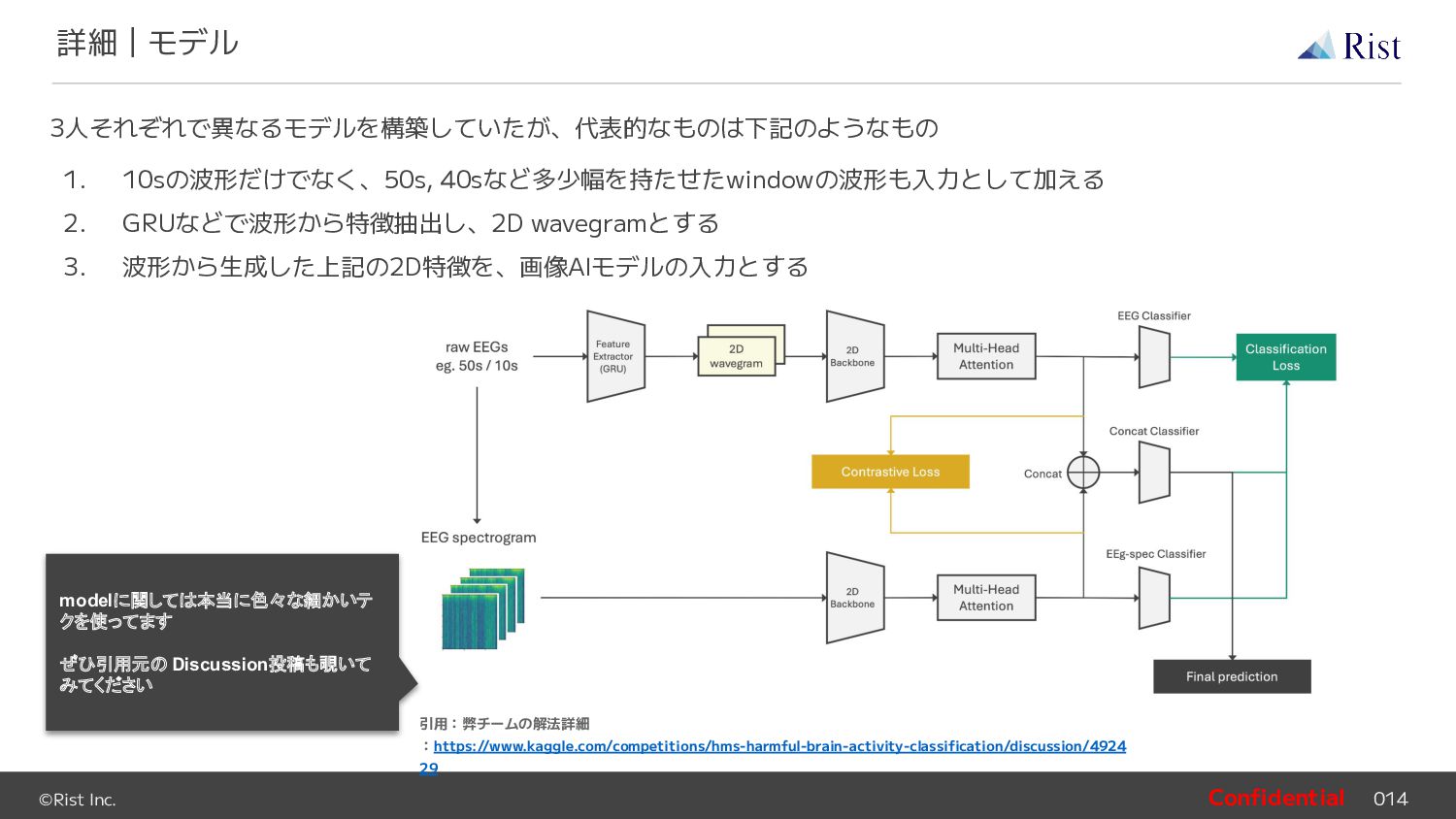{kind=link}
{kind=link}
{kind=link}
{kind=link}