Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
そのAIレビュー、レビューしてますか? / Are you reviewing those A...
Search
r-kagaya
January 21, 2026
Programming
5.5k
6
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
そのAIレビュー、レビューしてますか? / Are you reviewing those AI reviews?
CodeRabbit User Group Tokyo #0 〜立ち上げキックオフ〜の登壇資料です。
https://crug.connpass.com/event/378621/
r-kagaya
January 21, 2026
More Decks by r-kagaya
See All by r-kagaya
エンジニアにデザインハーネスを 〜デザインプロセスを規定するためのハーネス〜 / Design harness from an engineer's perspective
rkaga
2
1.7k
「AIで開発し、AIを届ける」をEvalでつなぐ 〜AIネイティブに始めるプロダクト開発の実践〜 / Connecting "Develop with AI, deliver AI" with Eval
rkaga
4
5.8k
ハーネスエンジニアリングにどう向き合うか 〜ルールファイルを超えて開発プロセスを設計する〜 / How to approach harness engineering
rkaga
29
28k
AIエージェント、”どう作るか”で差は出るか? / AI Agents: Does the "How" Make a Difference?
rkaga
4
2.4k
Context is King? 〜Verifiability時代とコンテキスト設計 / Beyond "Context is King"
rkaga
10
3.5k
AIエンジニアリングのご紹介 / Introduction to AI Engineering
rkaga
7
4.9k
MCPでVibe Working。そして、結局はContext Eng(略)/ Working with Vibe on MCP And Context Eng
rkaga
6
3.4k
一人でAIプロダクトを作るための工夫 〜技術選定・開発プロセス編〜 / I want AI to work harder
rkaga
14
3.7k
テストから始めるAgentic Coding 〜Claude Codeと共に行うTDD〜 / Agentic Coding starts with testing
rkaga
19
9.3k
Other Decks in Programming
See All in Programming
『コードを書く以外の』エンジニアリング〜課金基盤移行プロジェクト推進のためのTips4選
yuriko1211
0
540
任せる範囲はこう広がった / How the Scope of AI Delegation Has Expanded
nrslib
1
280
PHP に部分適用が来るぞ!……ところで何それ?おいしいの? #phpcon / phpcon-2026
shogogg
0
350
共通化で考えるべきは、実装より公開する型だった
codeegg
0
280
광주소프트웨어마이스터고등학교 DevFest 특강 - 바이브 코딩 시대에서 주니어 개발자로 살아남는 방법
utilforever
1
150
変わらないものが、変わるものを決める — 意図駆動開発 × イベントソーシング × イミュータブル | What Doesn't Change Decides What Can — IDD × Event Sourcing × Immutability
tomohisa
0
260
AIが無かった頃の素敵な出会いの話
codmoninc
1
220
ITヒヤリハットを整理してみた ~ライフサイクルと原因から考える再発防止策~
koukimiura
1
110
Generative UI & AI-Assistants for Your Angular Solutions
manfredsteyer
PRO
0
120
Android CLI
fornewid
0
170
ソフトウェア設計に溶けるインフラ ― AWS CDK のインフラ認識論
konokenj
2
640
琵琶湖の水は止められてもNet--HTTPのリトライは止められない / You might be able to stop the water flow of Lake Biwa but you can't stop Net::HTTP retries
luccafort
PRO
0
440
Featured
See All Featured
Music & Morning Musume
bryan
47
7.3k
A Soul's Torment
seathinner
6
3.1k
A Guide to Academic Writing Using Generative AI - A Workshop
ks91
PRO
1
360
What Being in a Rock Band Can Teach Us About Real World SEO
427marketing
0
1.1k
More Than Pixels: Becoming A User Experience Designer
marktimemedia
3
470
The SEO Collaboration Effect
kristinabergwall1
1
510
Mozcon NYC 2025: Stop Losing SEO Traffic
samtorres
1
420
Why You Should Never Use an ORM
jnunemaker
PRO
61
9.9k
Designing for Timeless Needs
cassininazir
1
400
Unlocking the hidden potential of vector embeddings in international SEO
frankvandijk
0
880
Building Better People: How to give real-time feedback that sticks.
wjessup
370
20k
How to make the Groovebox
asonas
2
2.3k
Transcript
2026年1月21日 Asterminds株式会社 r.kagaya CodeRabbit User Group Tokyo #0 〜立ち上げキックオフ〜 そのAIレビュー、レビューしてますか?
〜AI as a Judgeから考えるAIコードレビューの育成〜
2022年に株式会社ログラスに入社 経営管理SaaSの開発、開発生産性向上に取り組んだのち、 生成AI/LLMチームを立ち上げ、新規AIプロダクトの立ち 上げに従事、その後、25年8月に独立・現職 翻訳を担当したAIエンジニアリングが オライリージャパンより出版 Asterminds(アスターマインズ)株式会社 共同創業者・CTO r.kagaya(@ry0_kaga) 自己紹介
そのAIコードレビュー、レビューしてますか?
フィードバックして、育てられていますか?
AIコードレビューは 「人間の代わりに、コードを“判断”させている」
AIコードレビューは 「人間の代わりに、コードを“判断”させている」 LLM as a Judgeの知見が使えるのでは?
LLM as a Judgeの事例・プラクティス から考えるAIコードレビューの育て方 今日の内容
CodeRabbitの機能解説は少なめです...🙇
簡単にLLM as a Judge とは
全ての土台となる評価 信頼できる評価軸があるからこその体系的な改善 「この修正で本当にシステムは良くなったか?」に自信を持って答えるためには? Vibe Check(雰囲気での確認)には限界がある なぜ難しいのか? オープンエンドな出力は正解が一つに収斂しないため AIエンジニアリングの世界においては、オープンエンドな出力の利用が 増える。 なぜ重要なのか?
評価パイプライン・基準がなければ、開発は単なる「手探りの試行錯誤」 に陥る可能性
評価の主体(誰が、または何が評価を行うか)の分類 最近は、「AIに評価させる」ことがアプローチの一つとして浸透してきている では、どうやって評価するのか? AIコードレビュー、ほぼこれ?
LLM as a Judgeとは AIモデル(生成応答)を評価するために、別のAIモデル(評価者)を利用する by オライリーAIエンジニアリング 速度とコスト効率 参照データ不要 高い相関性
人間の評価者(アノ テーター)と比較し て、はるかに高速か つ安価に評価を行う ことができる 正解データ(参照応 答)が存在しない本番 環境のデータに対し ても、プロンプトに基 づいて品質や安全性 を評価できる 人間の評価者と強い 相関(85%の一致率 など)を示すことが研 究で報告されており、 信頼性がある程度確 認されている 柔軟性 プロンプトを変更す るだけで、ハルシネー ションの検出、トーン の確認、役割(ロール プレイ)の維持など、 あらゆる基準に基づ いた評価が可能
LLM as a Judgeの特性・課題 評価基準は標準化されておらず、使用するツールやプロンプトによっ て定義やスコアリングが異なり、比較が困難 非一貫性 (Inconsistency) 確率的に動作するため、同じ入力に対しても実行するたびに異なるス コアを出力する可能性があり、評価の再現性が損なわれることがある
独自のバイアス コードレビューと文章の校正等の異なる点は、実行して検証できること (機能正確性) AIコードレビューを育てる上でも強力なフィードバック 基準の曖昧さ AI as a Judgeには特有の性質に起因する課題や特徴が存在
LLM as a Judgeの課題: バイアス これらのバイアスは、コードレビューでも起きうる問題か? 自己バイアス 位置バイアス 冗長性バイアス 自分が生成したものを高く
評価する モデルは、自分自身(または 同じシリーズのモデル)が生 成した応答を高く評価する傾 向 選択肢の順序を変えるだけ で評価が変わる 2つの応答を比較する際、内 容に関わらず「最初に提示さ れた応答」を好む傾向 長い回答を「良い」と判断し がち 内容の質に関わらず、より長 い回答を好む傾向
LLM as a Judgeの事例・プラクティス から考えるAIコードレビューの育て方
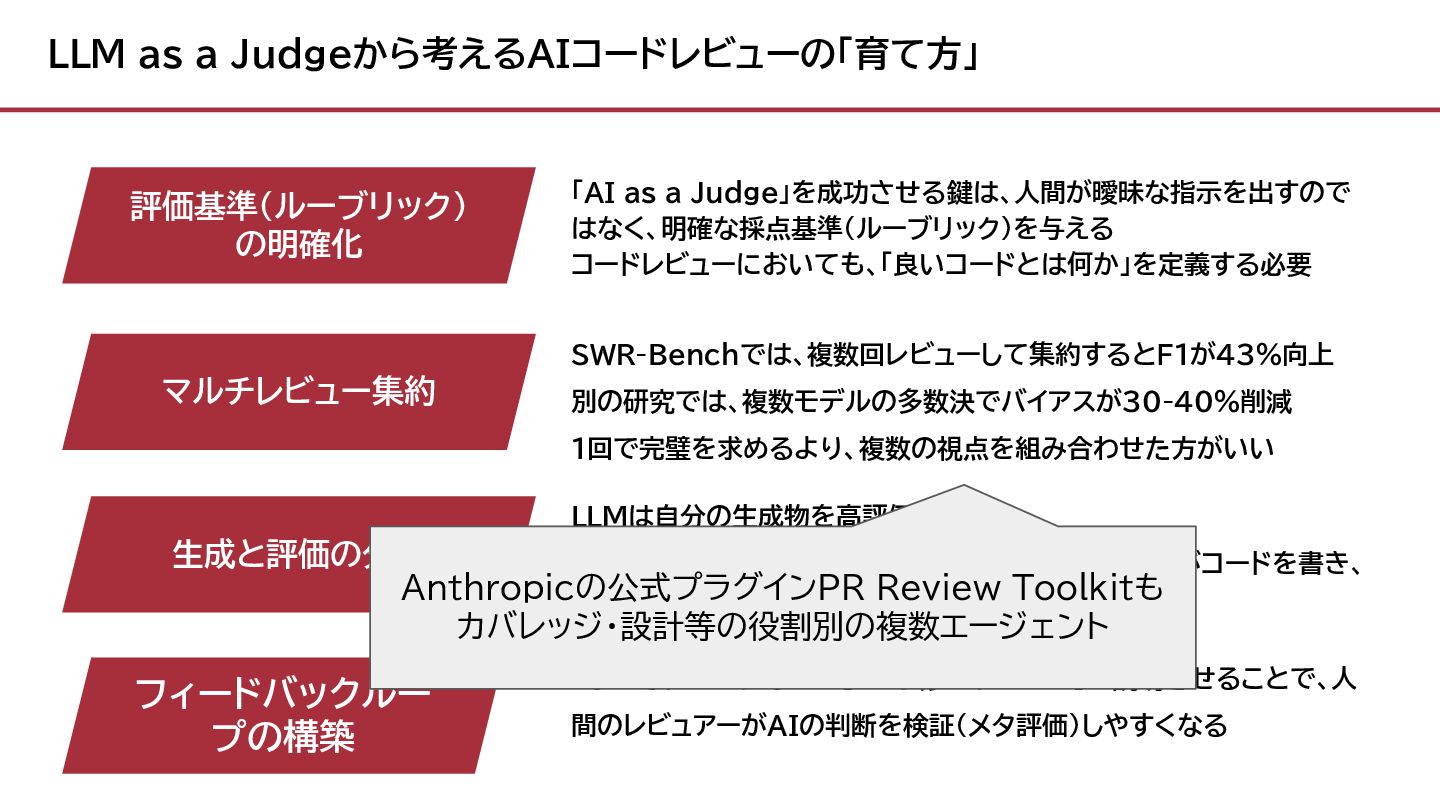
LLM as a Judgeから考えるAIコードレビューの「育て方」 LLMは自分の生成物を高評価しがち Anthropic公式ベストプラクティス 「1つのClaudeがコードを書き、 別のClaudeがレビューする」 フィードバックルー プの構築
「なぜそれがバグなのか」「どう修正すべきか」を説明させることで、人 間のレビュアーがAIの判断を検証(メタ評価)しやすくなる 評価基準(ルーブリック) の明確化 「AI as a Judge」を成功させる鍵は、人間が曖昧な指示を出すので はなく、明確な採点基準(ルーブリック)を与える コードレビューにおいても、「良いコードとは何か」を定義する必要 マルチレビュー集約 SWR-Benchでは、複数回レビューして集約するとF1が43%向上 別の研究では、複数モデルの多数決でバイアスが30-40%削減 1回で完璧を求めるより、複数の視点を組み合わせた方がいい 生成と評価の分離
評価基準の明文化 「何を見ればいいか」、「何を評価するか」を具体的に明示 • 基準の曖昧さはAI as a Judgeの精度低下の主因の一つ • 質問固有の基準 >
汎用基準 5段階は判定が難しいので、 2値 or 3段階の方が楽という話も別途
CodeRabbitなら? path_instructionsで評価基準を指示 ディレクトリごとに「何を見てほしいか」「どう判断すべきか」を記述 https://docs.coderabbit.ai/reference/configuration#param-path-instructions
LLM as a Judgeから考えるAIコードレビューの「育て方」 LLMは自分の生成物を高評価しがち Anthropic公式ベストプラクティス 「1つのClaudeがコードを書き、 別のClaudeがレビューする」 フィードバックルー プの構築
「なぜそれがバグなのか」「どう修正すべきか」を説明させることで、人 間のレビュアーがAIの判断を検証(メタ評価)しやすくなる 評価基準(ルーブリック) の明確化 「AI as a Judge」を成功させる鍵は、人間が曖昧な指示を出すので はなく、明確な採点基準(ルーブリック)を与える コードレビューにおいても、「良いコードとは何か」を定義する必要 マルチレビュー集約 SWR-Benchでは、複数回レビューして集約するとF1が43%向上 別の研究では、複数モデルの多数決でバイアスが30-40%削減 1回で完璧を求めるより、複数の視点を組み合わせた方がいい 生成と評価の分離 Anthropicの公式プラグインPR Review Toolkitも カバレッジ・設計等の役割別の複数エージェント
コードレビューはマルチエージェント向きのタスクか? シングル or マルチエージェントの整理の一つが、読み込み/書き込みのどちらの 側面が強いか? コンテキストの一貫性の要求が比較的低い、読み込み中心の並列探索がマルチ エージェントに向いてると考察
説明可能性:スコアだけでなく、理由を語る AIコードレビューを育てるための判断基準として理由を語らせる • 「このレビューコメントは本当に正しいですか?」と自問自答させ、間違いが あれば修正させる • レビュー結果に対して「なぜその指摘をしたのか」を振り返らせ、論理的な不 整合がないかを確認する (CodeRabbitで上手く実現する方法があれば教えて貰えたら嬉しい...!)
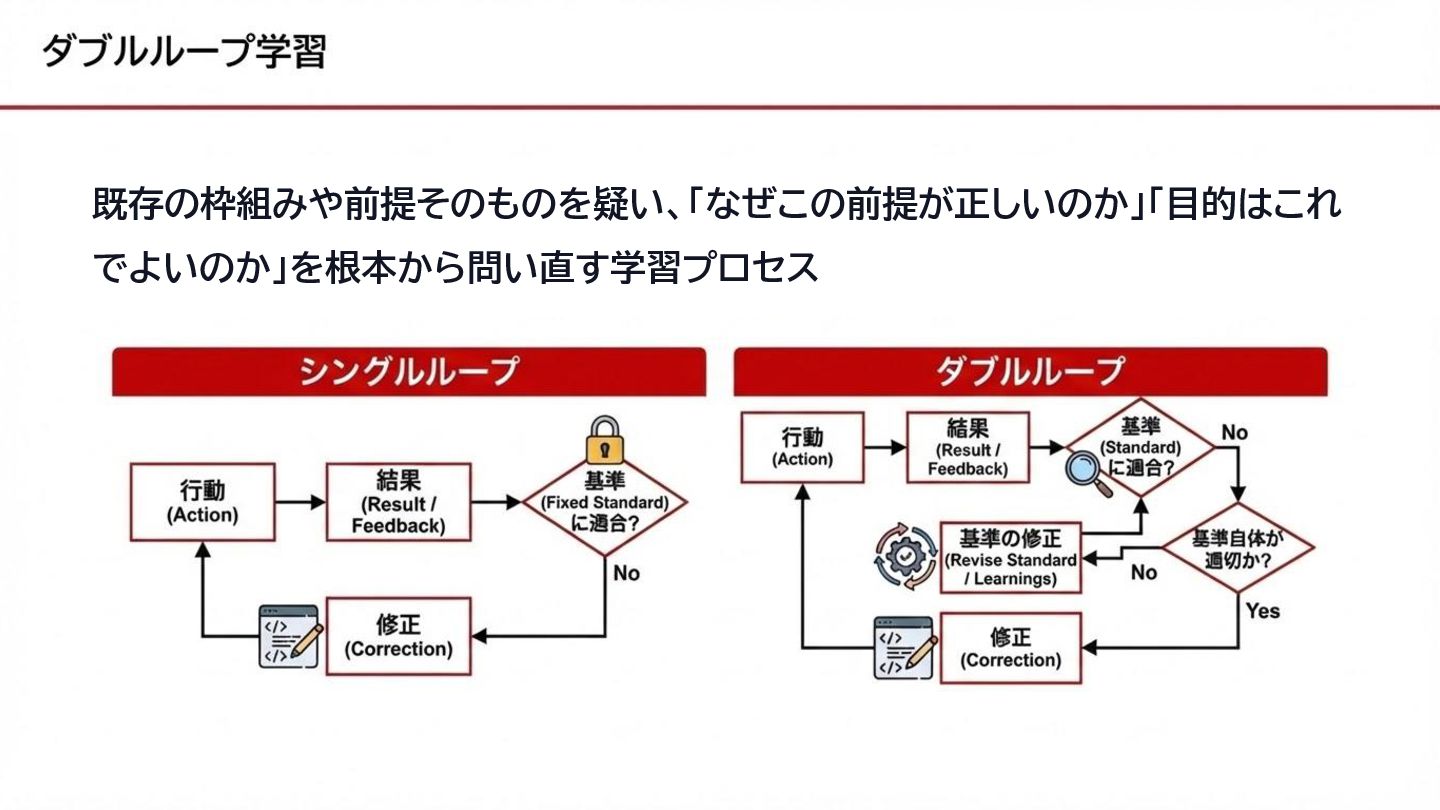
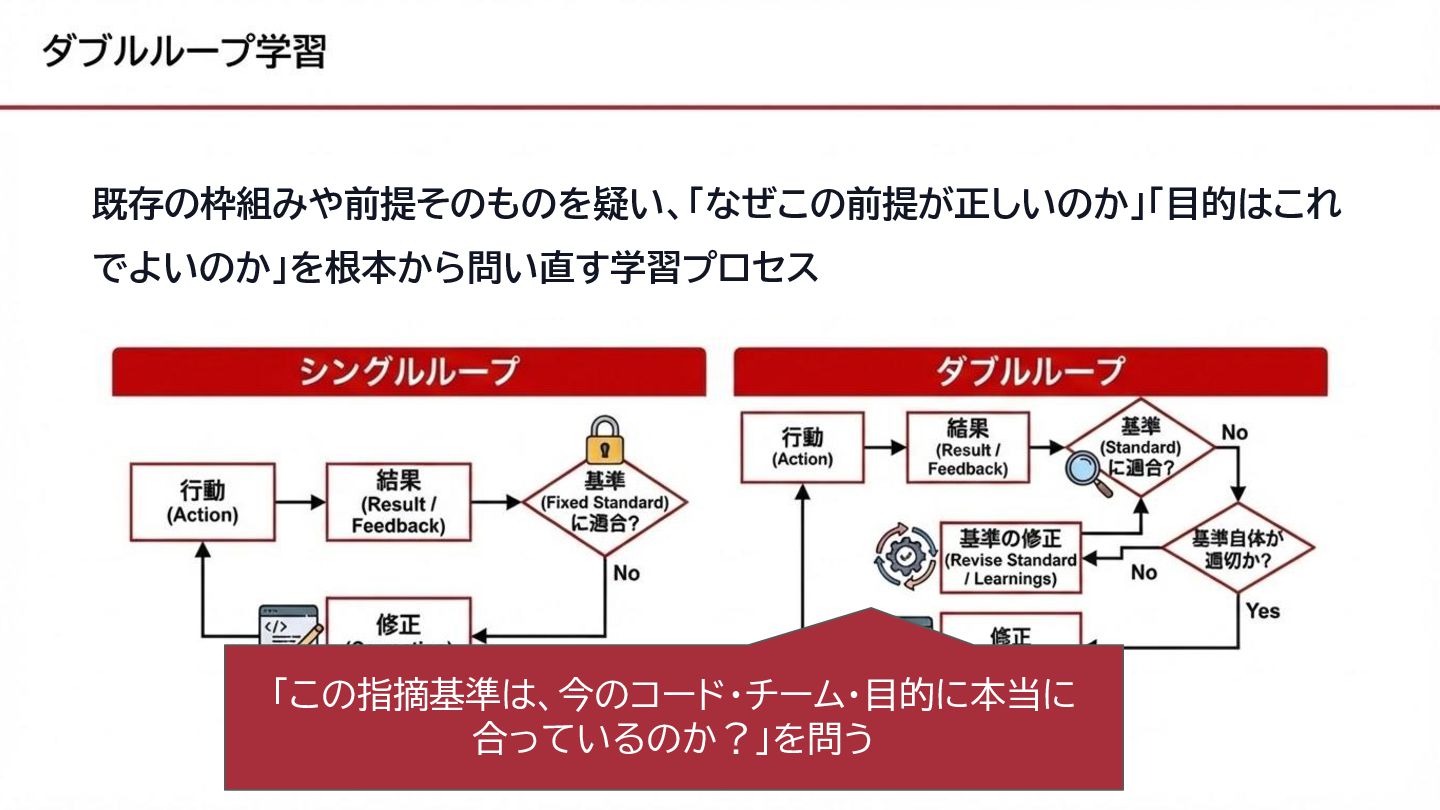
既存の枠組みや前提そのものを疑い、「なぜこの前提が正しいのか」「目的はこれ でよいのか」を根本から問い直す学習プロセス
既存の枠組みや前提そのものを疑い、「なぜこの前提が正しいのか」「目的はこれ でよいのか」を根本から問い直す学習プロセス 「この指摘基準は、今のコード・チーム・目的に本当に 合っているのか?」を問う
さらに育てる: Learnings機能 チーム固有の基準そのものが更新されていくLearnings > CodeRabbitはあなたとの対話から得られた知見を活用・蓄積し、時間の経 過とともに学習を強化します。 https://docs.coderabbit.ai/guides/learnings
理由を説明させたり、良い・悪いレビューを問いながら レビュー基準そのものをダブルループ学習で育てていく そのための機能もCodeRabbitにある
From Code to Courtroom: LLMs as the New Software Judges
ソフトウェア工学におけるLLM-as-a-Judgeの包括的調査 コード品質、セキュリティ、ドキュメント等の評価にLLMを活用する研究を体系化 https://arxiv.org/abs/2503.02246
まとめ
まとめ • AIコードレビューは評価基準とフィードバックで育てるもの • LLM as a Judgeの事例やプラクティスは、AIコードレビューのレビューや 育成を考える上で、参考になる点はある ◦
今回取り上げられなかった内容やTips、学びを得られそうな事例/研究 は沢山ある • コーディングエージェントの圧倒的な手数による可能性を感じる時代、コー ディング以外のプロセスのスクラップ&ビルドは求められる ◦ コードレビューはその代表例に感じる
そのAIコードレビュー、レビューしてますか? フィードバックして、育てられていますか?
終わり
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}