Spark+AI Summit Europe 2019 presentation
Video at https://databricks.com/session_eu19/apache-spark-at-scale-in-the-cloud
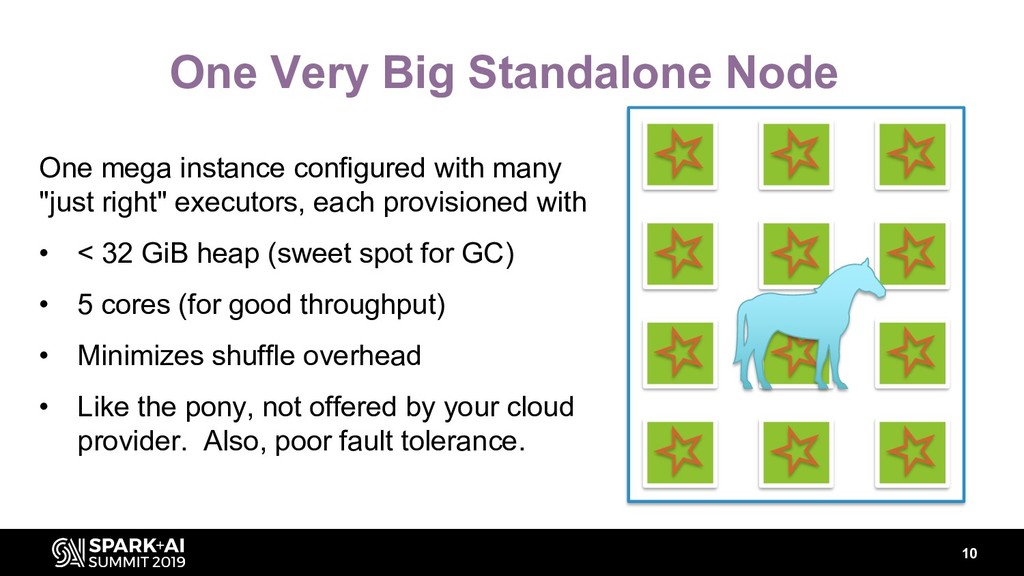
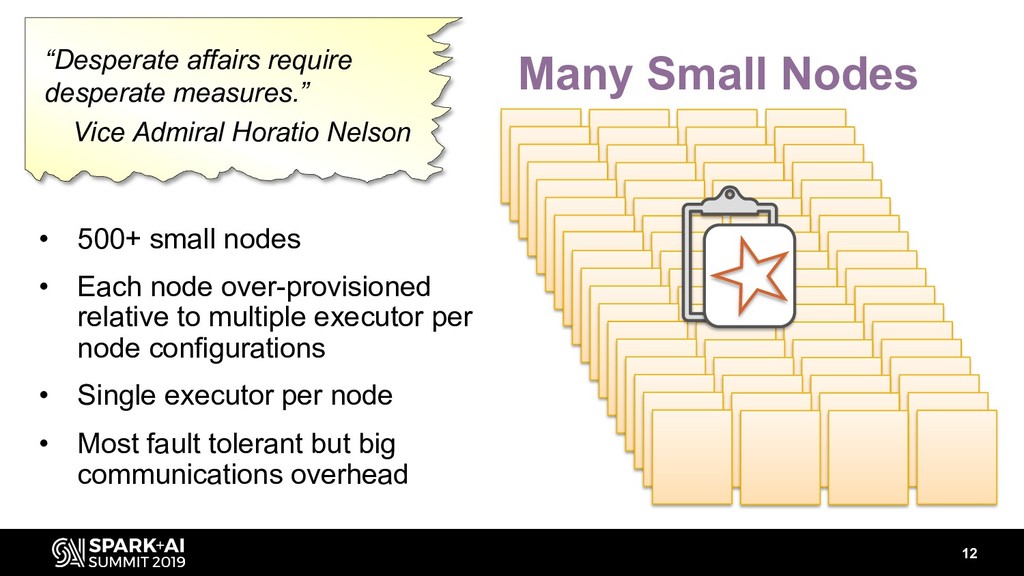
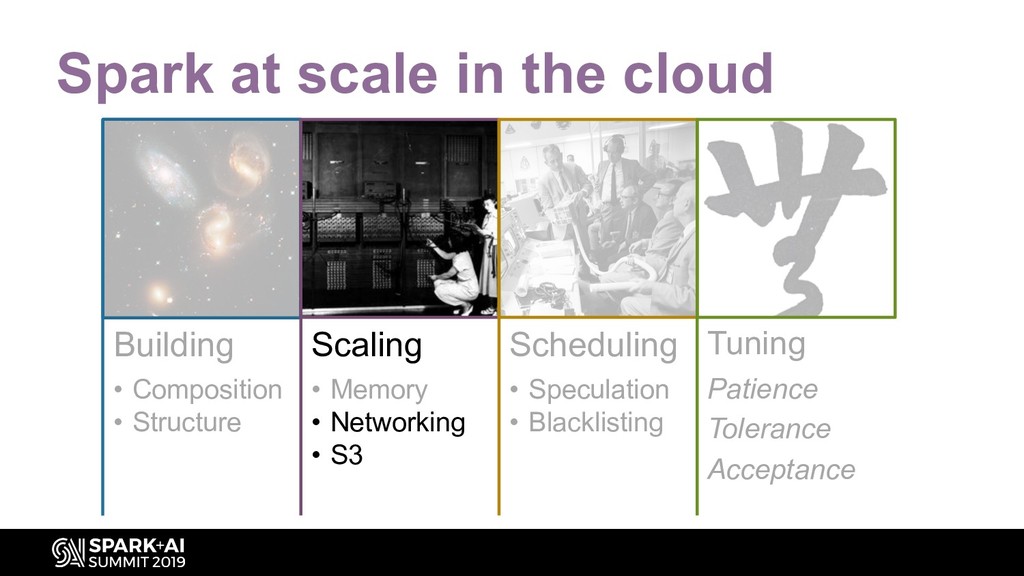
Using Apache Spark to analyze large datasets in the cloud presents a range of challenges. Different stages of your pipeline may be constrained by CPU, memory, disk and/or network IO. But what if all those stages have to run on the same cluster? In the cloud, you have limited control over the hardware your cluster runs on.
You may have even less control over the size and format of your raw input files. Performance tuning is an iterative and experimental process. It’s frustrating with very large datasets: what worked great with 30 billion rows may not work at all with 400 billion rows. But with strategic optimizations and compromises, 50+ TiB datasets can be no big deal.
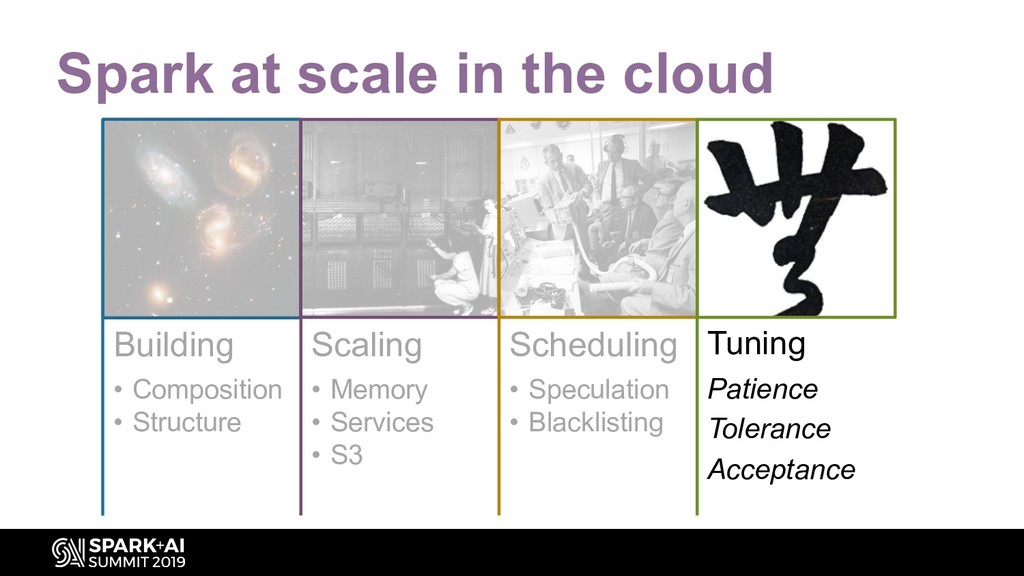
By using Spark UI and simple metrics, explore how to diagnose and remedy issues on jobs:
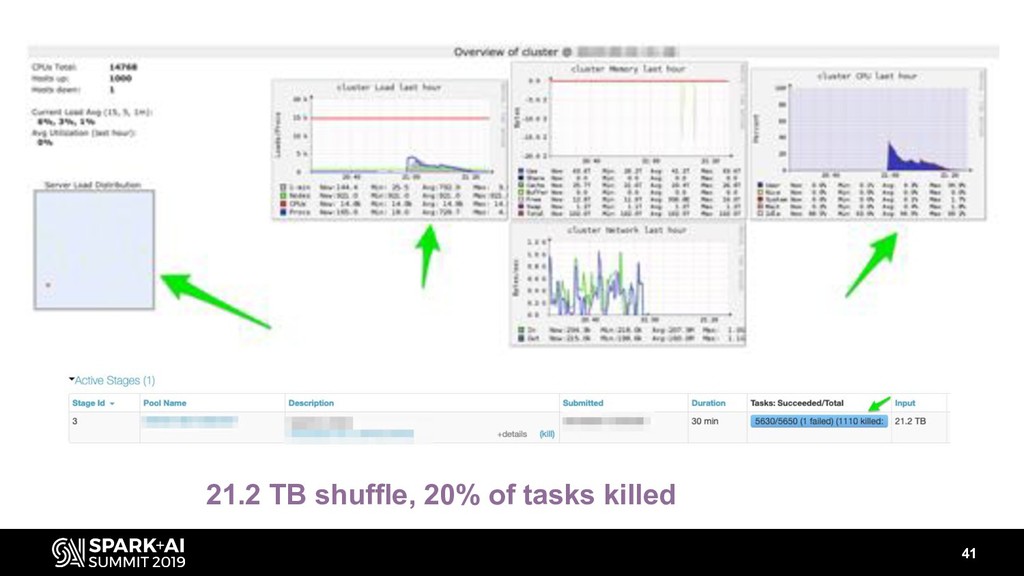
- Sizing the cluster based on your dataset (shuffle partitions)
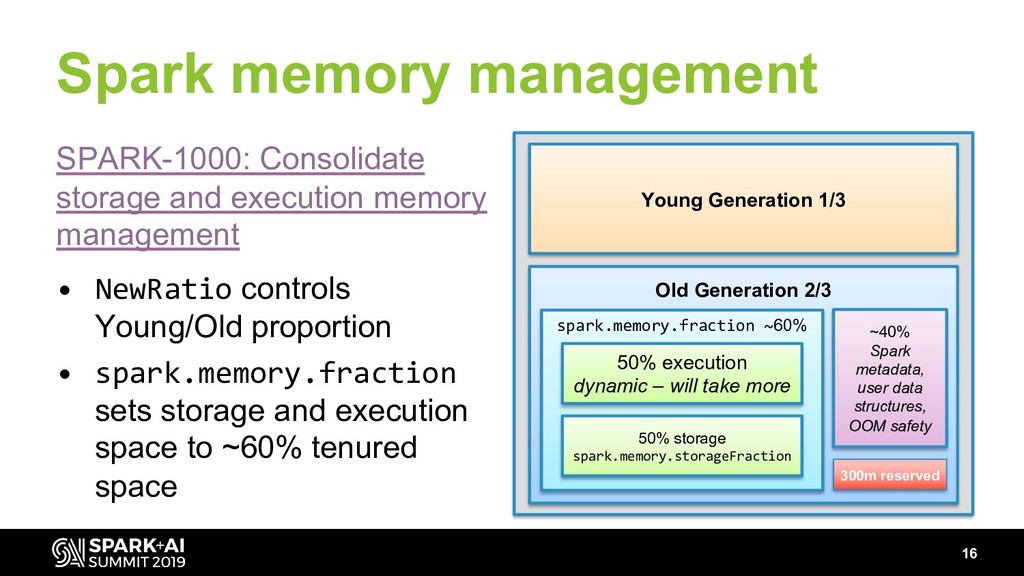
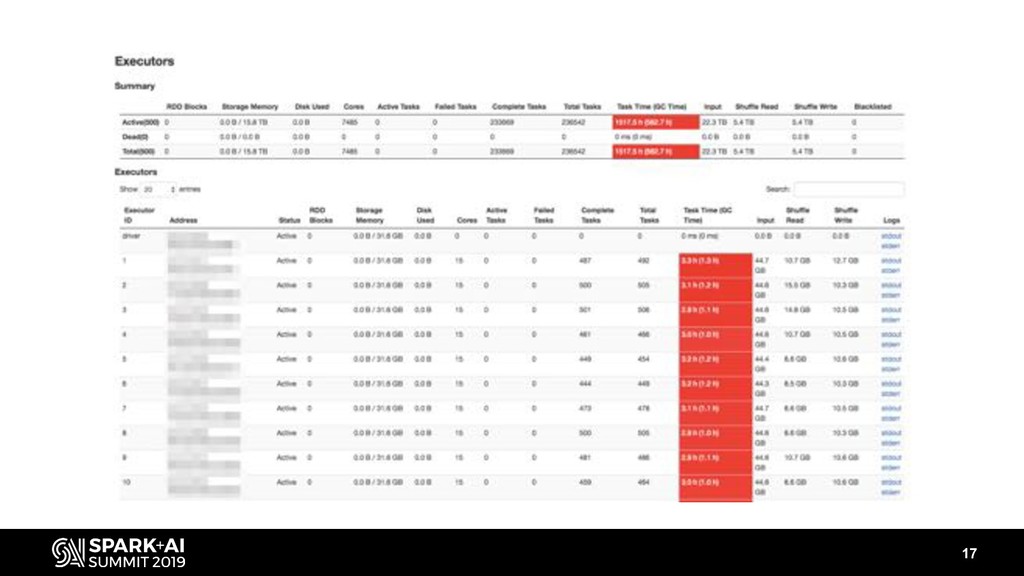
- Managing memory (sorting GC – when to go parallel, when to go G1, when offheap can help you)
- Shuffle (give a little to get a lot – configs for better out of box shuffle) – Spill (partitioning for the win)
- Scheduling (FAIR vs FIFO, is there a difference for your pipeline?)
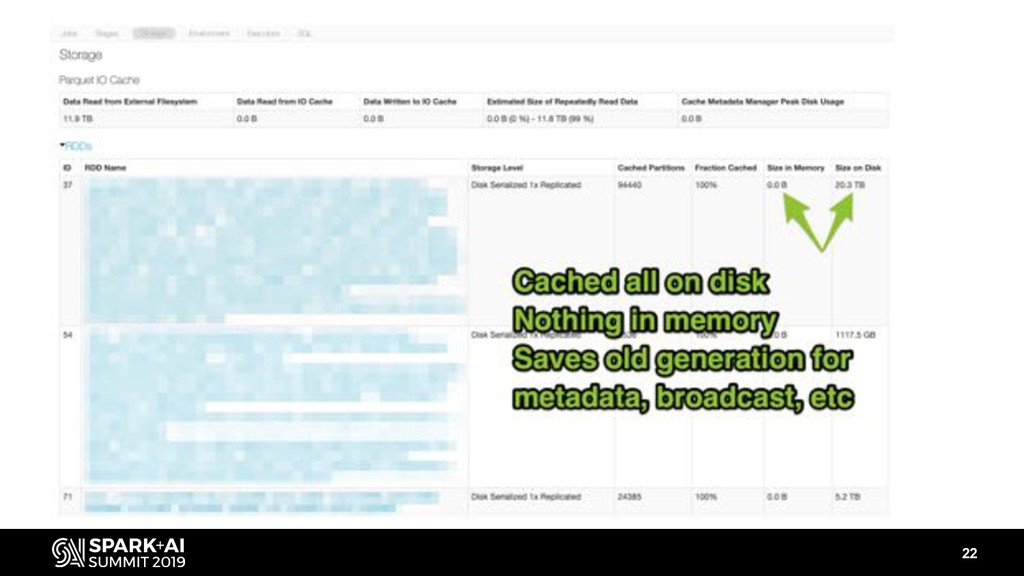
- Caching and persistence (it’s the cost of doing business, so what are your options?)
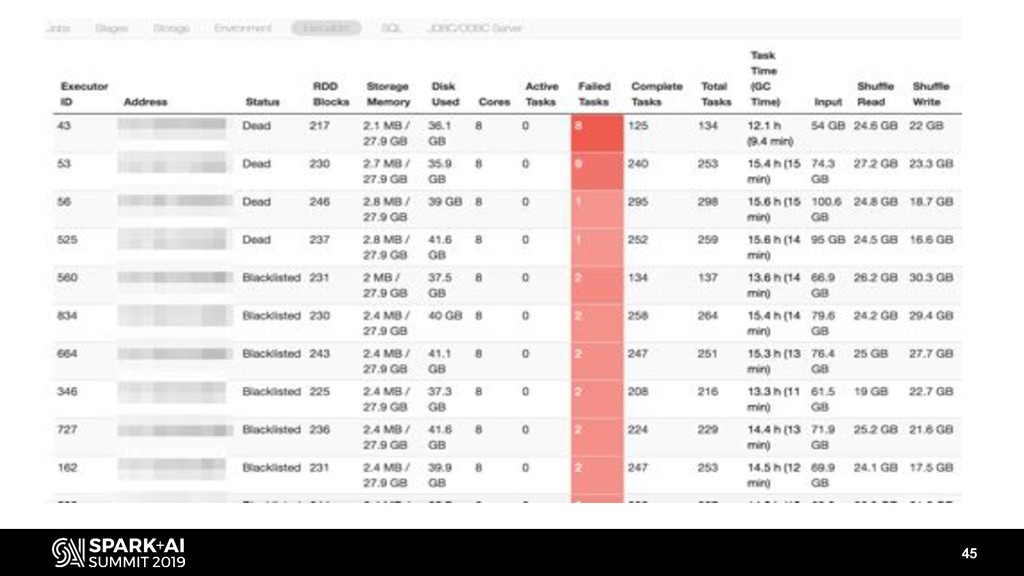
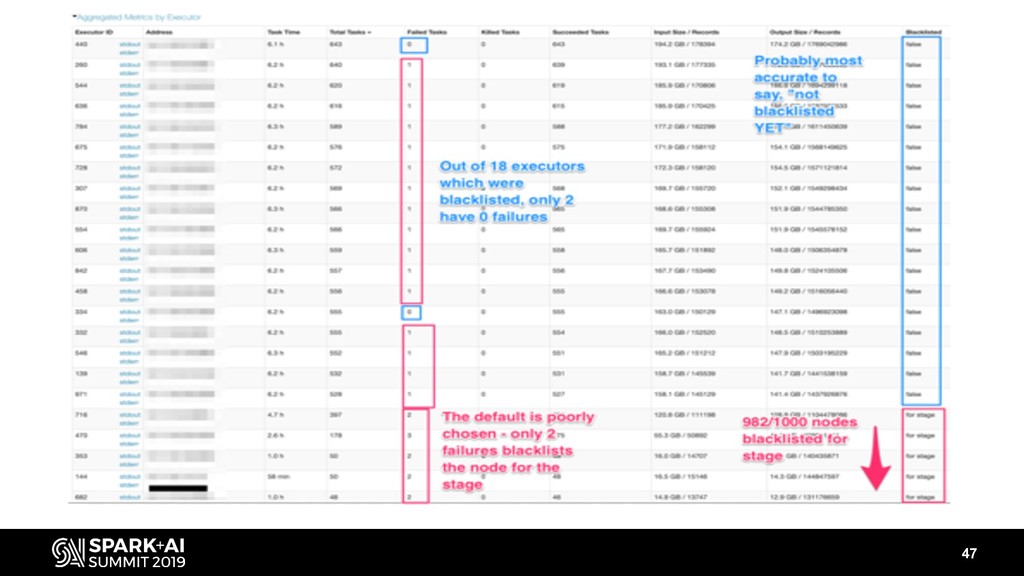
- Fault tolerance (blacklisting, speculation, task reaping)
- Making the best of a bad deal (skew joins, windowing, UDFs, very large query plans)
- Writing to S3 (dealing with write partitions, HDFS and s3DistCp vs writing directly to S3)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}