概要: ChatGPTを使って論文が読めるのかどうか,簡単な実験で検証しました
リンク
- エンタメとAIのための3Dパラレルワールド構築(GPU UNITE 2025 特別講演) https://speakerdeck.com/pfn/20251015-gpu-unite-2025-pfn-3d-parallel-world
- 深層学習と3Dキャプチャ・3Dモデル生成(土木学会応用力学委員会 応用数理・AIセミナー) https://speakerdeck.com/pfn/20250109_jsce_pfn
- 三次元再構成(東京大学大学院 情報理工学系研究科『知能情報論』) https://speakerdeck.com/pfn/20240613-utokyo-intelligent-informatics
- 落合陽一先生の論文まとめフォーマット https://lafrenze.hatenablog.com/entry/2015/08/04/120205
- Lyra: Generative 3D Scene Reconstruction via Video Diffusion Model Self-Distillation https://speakerdeck.com/spatial_ai_network/lyra-generative-3d-scene-reconstructionvia-video-diffusion-model-self-distillation
- HyRF: Hybrid Radiance Fields for Memory-efficient and High-quality Novel View Synthesis https://speakerdeck.com/spatial_ai_network/hyrf-hybrid-radiance-fields-for-novel-view-synthesis
- Kato+ 2018 https://nmr.hiroharu-kato.com/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![10 試してみた 例題: “Neural 3D Mesh Renderer” [Kato+ 2018] ✔](https://files.speakerdeck.com/presentations/3a722bf4db1e47c7a6f00311ba082e75/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
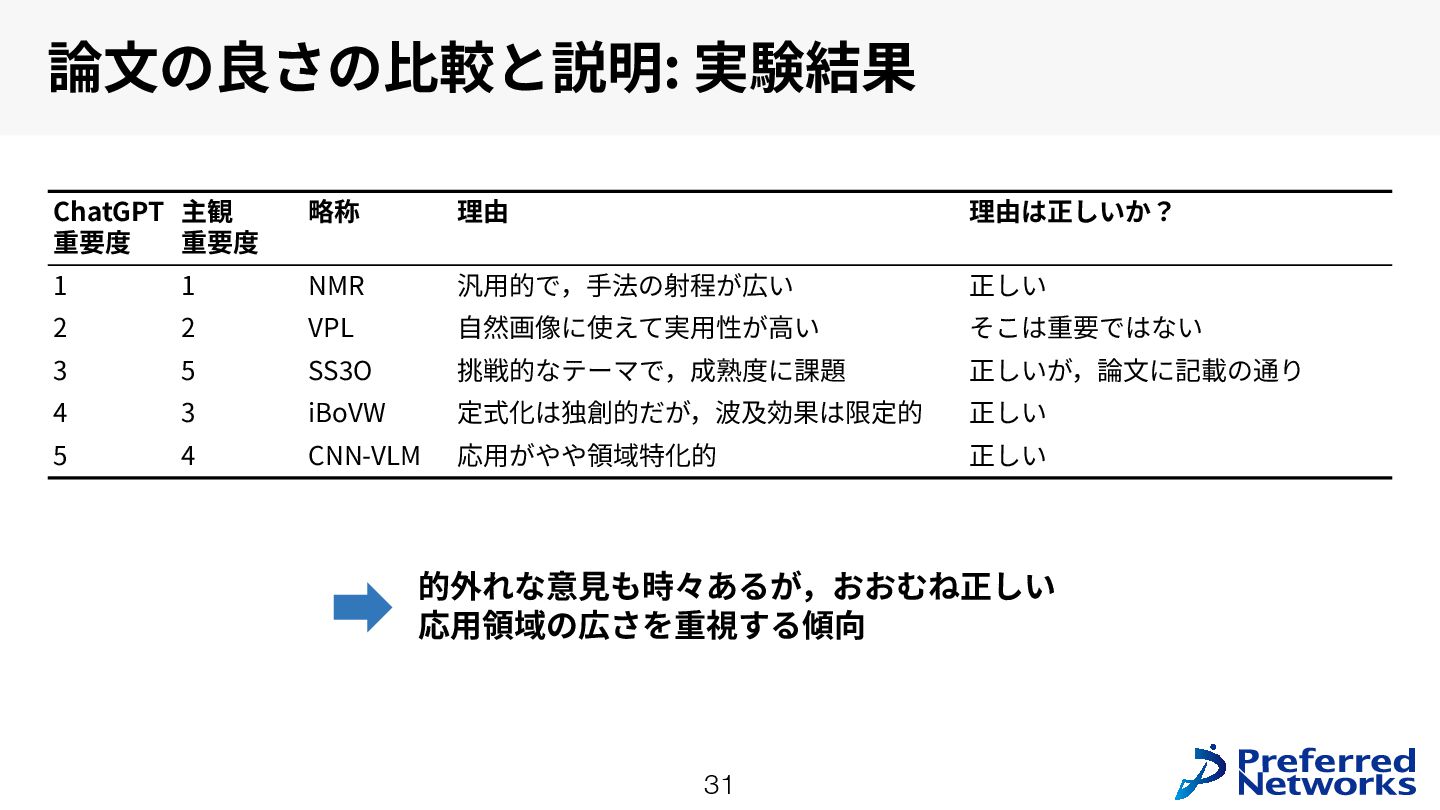{kind=link}
![32 重要な研究‧論⽂の予想: 検証⽅法 “この論⽂に続く研究の⽅向性として、重要(影響⼒が⾼い)と考えられるものを いくつか述べてください。Web検索は⾏わないでください。” 対象論⽂は NMR [Kato+ 2018] とし,回答はたとえば以下を想定](https://files.speakerdeck.com/presentations/3a722bf4db1e47c7a6f00311ba082e75/slide_31.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}