Version with slides only: https://speakerdeck.com/rofreg/the-doctor-is-in-using-checkups-to-find-bugs-in-production
Presented at RailsConf 2018
A good test suite can help you catch errors in development, but how do you know if your code starts misbehaving in production?
In this talk, we’ll learn about checkups: a powerful and flexible way to ensure that your code continues to work as intended after you deploy. Through real-world examples, we’ll see how adding a simple suite of checkups to your app can help you detect unforeseen issues, including tricky problems like race conditions and data corruption. We’ll even look at how checkups can mitigate much larger disasters in real-time. Come give your app’s health a boost!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
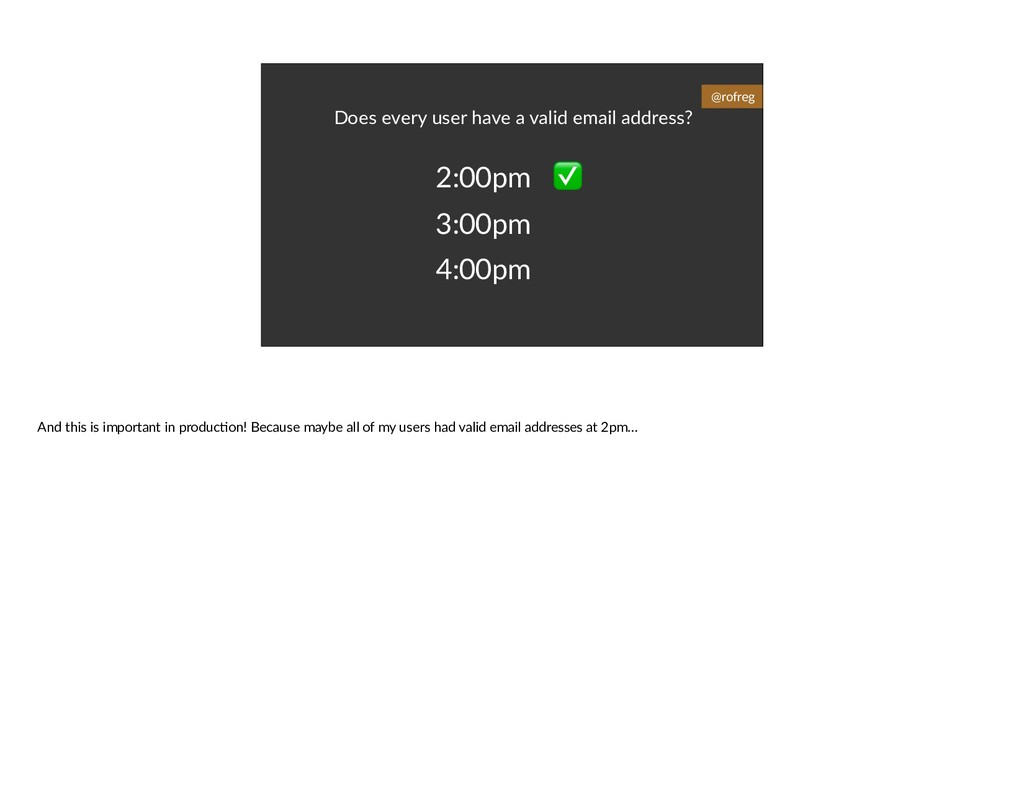{kind=link}
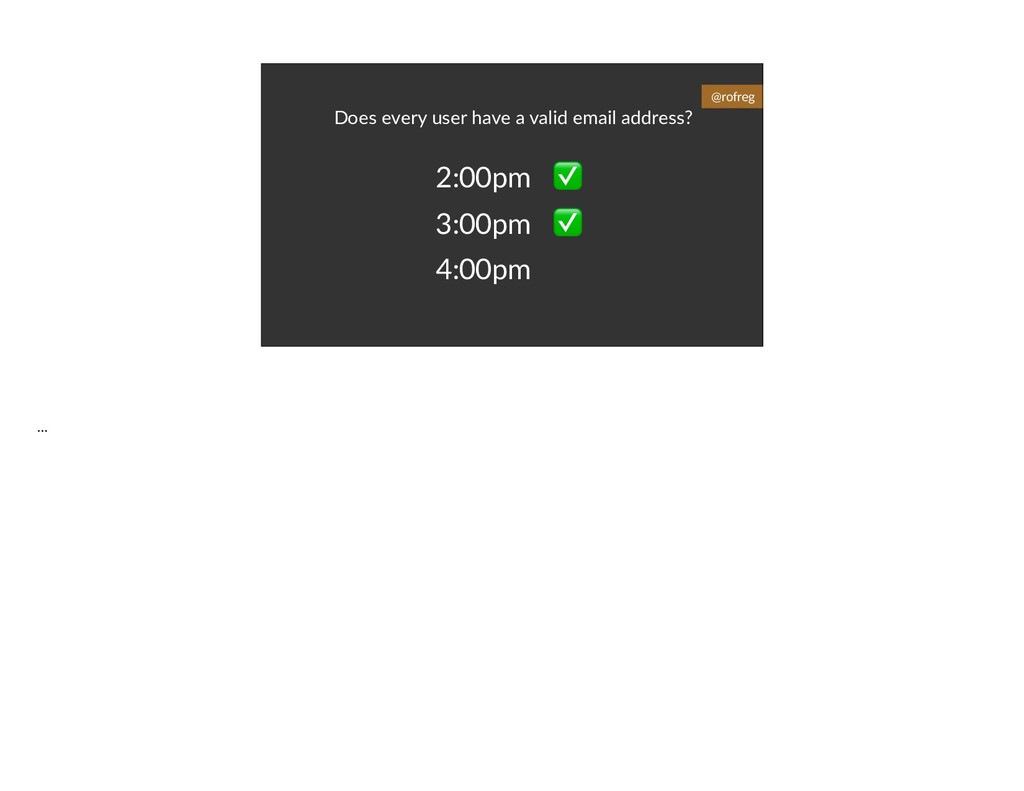{kind=link}
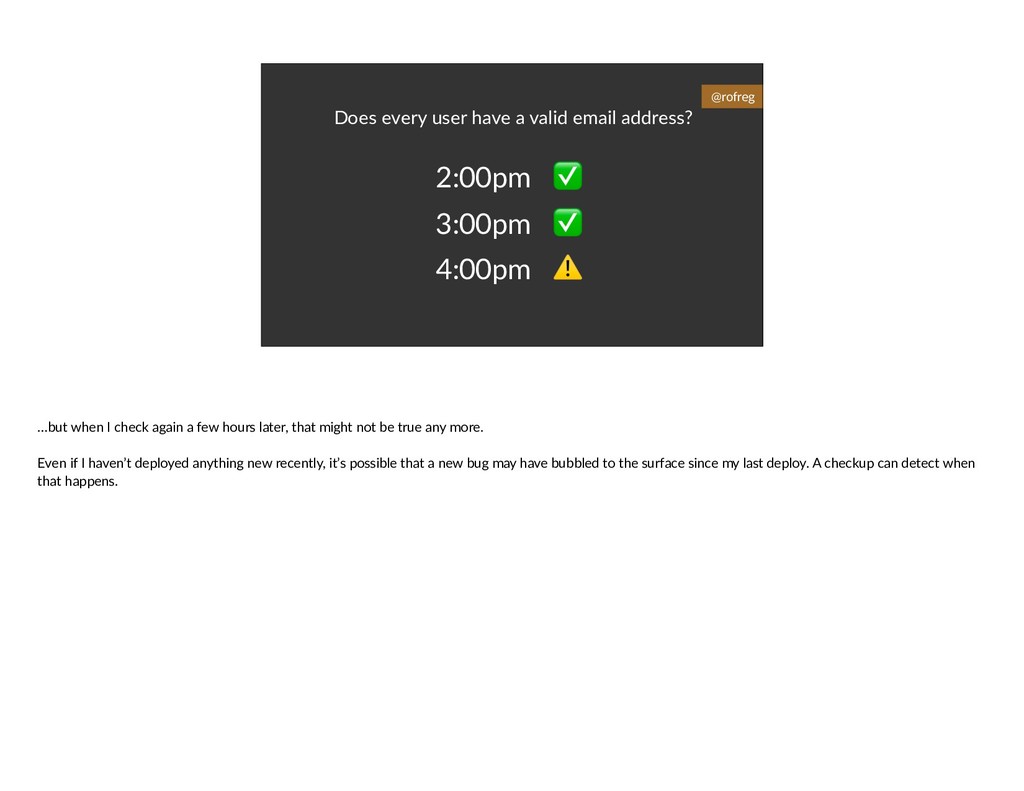{kind=link}
{kind=link}
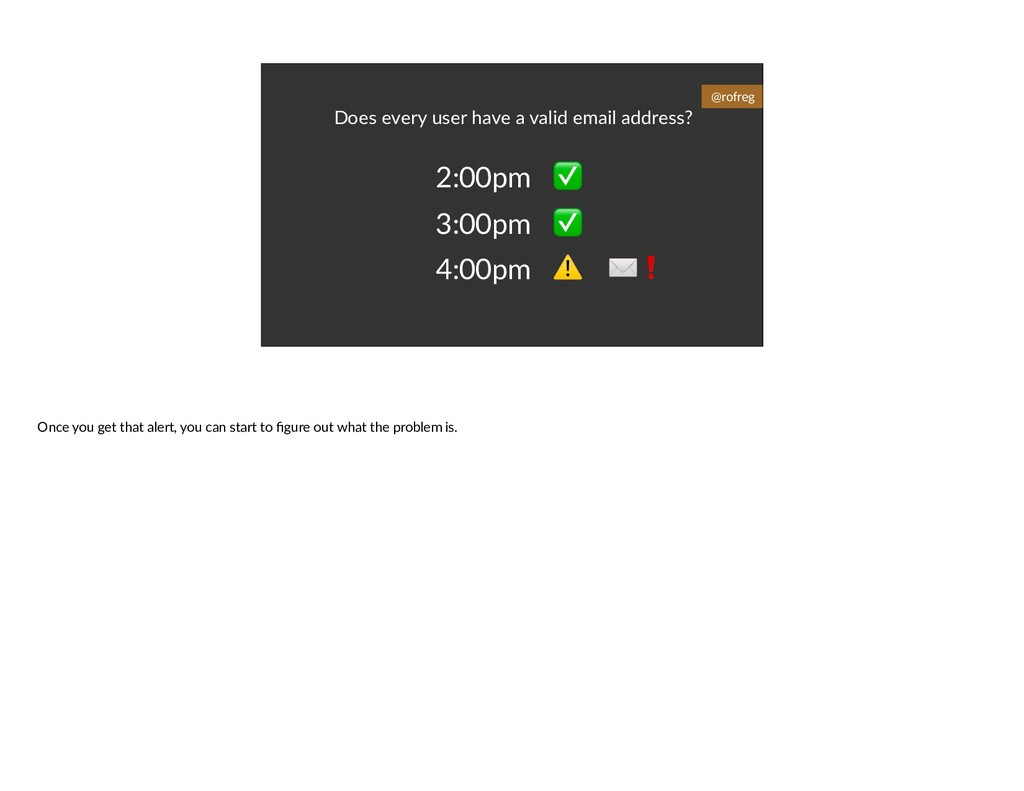{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
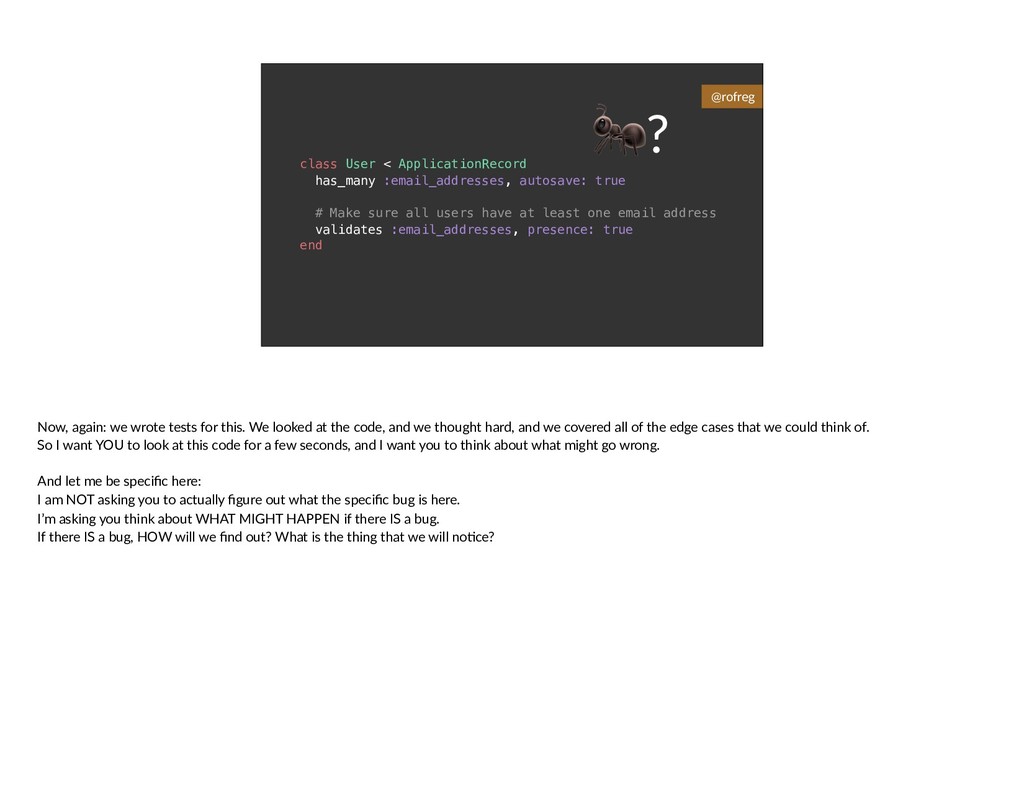{kind=link}
{kind=link}
{kind=link}
{kind=link}
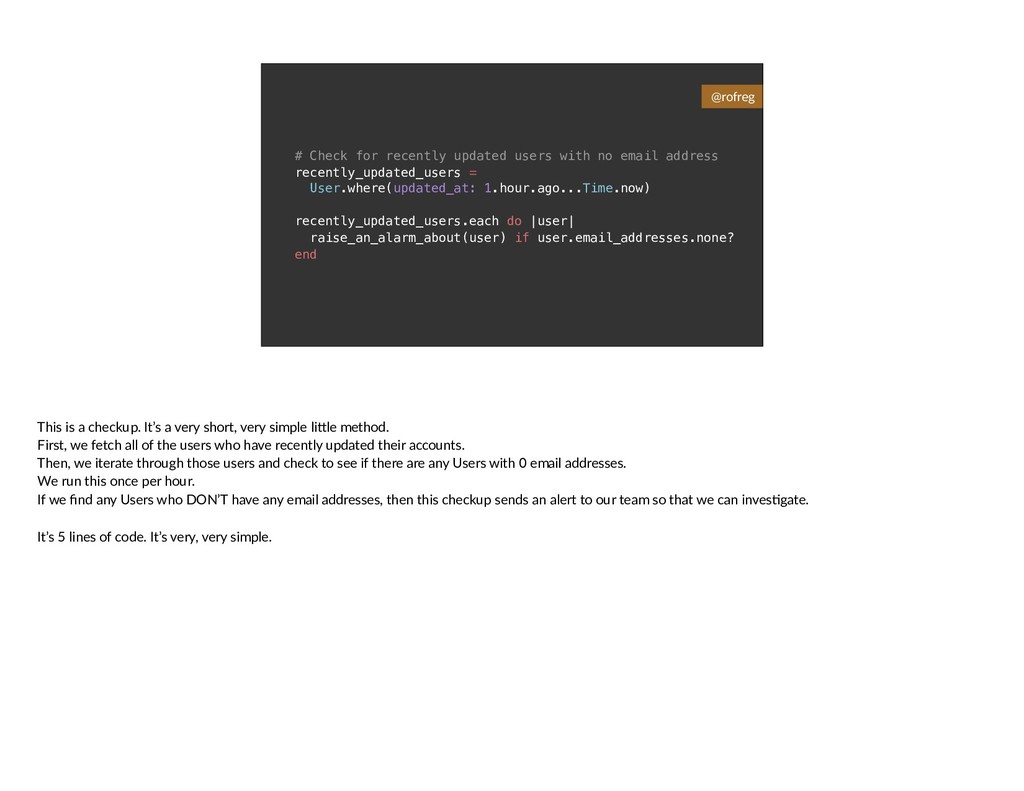{kind=link}
{kind=link}
{kind=link}
{kind=link}
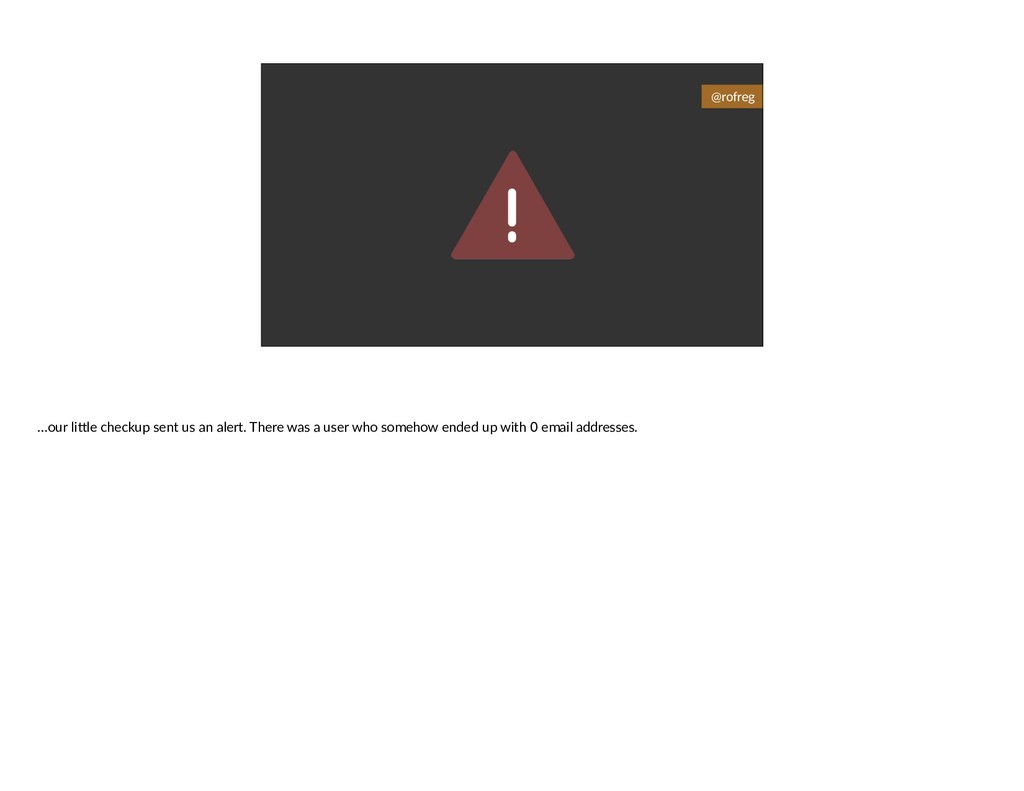{kind=link}
{kind=link}
{kind=link}
![[email protected] [email protected] REQUEST #2 [email protected] [email protected] REQUEST #1 @rofreg See,](https://files.speakerdeck.com/presentations/4f17cbcffc954c778e9b46c7536a5491/slide_64.jpg){kind=link}
![[email protected] [email protected] REQUEST #2 [email protected] [email protected] REQUEST #1 @rofreg …and](https://files.speakerdeck.com/presentations/4f17cbcffc954c778e9b46c7536a5491/slide_65.jpg){kind=link}
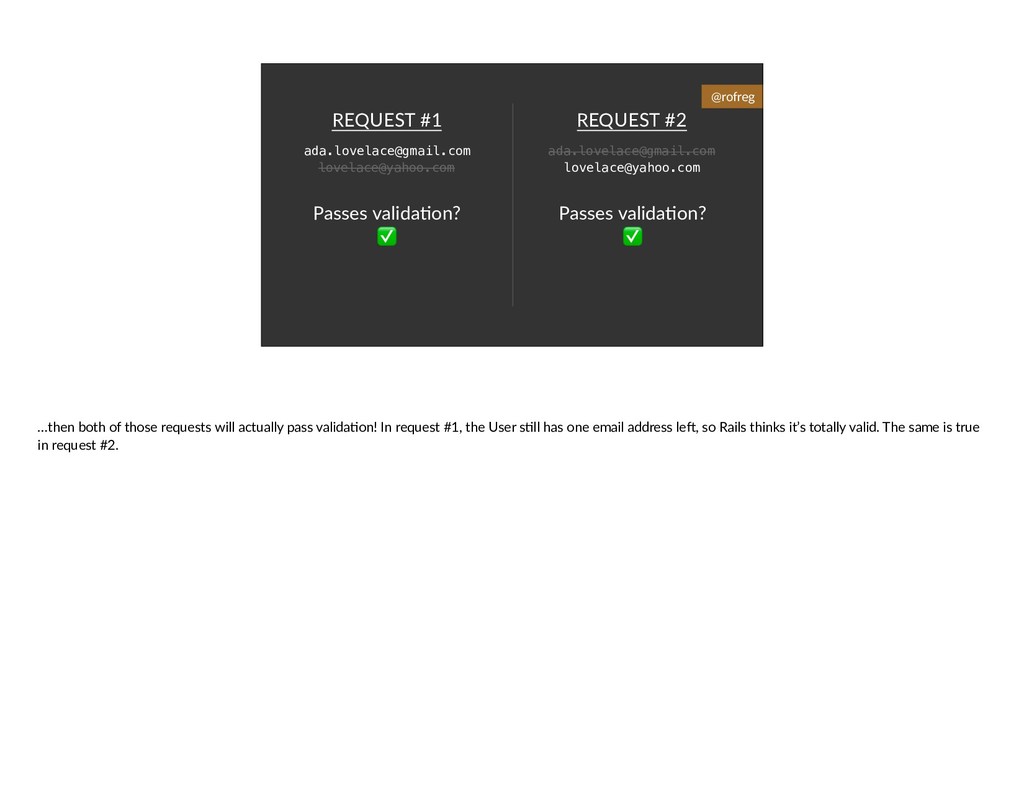{kind=link}
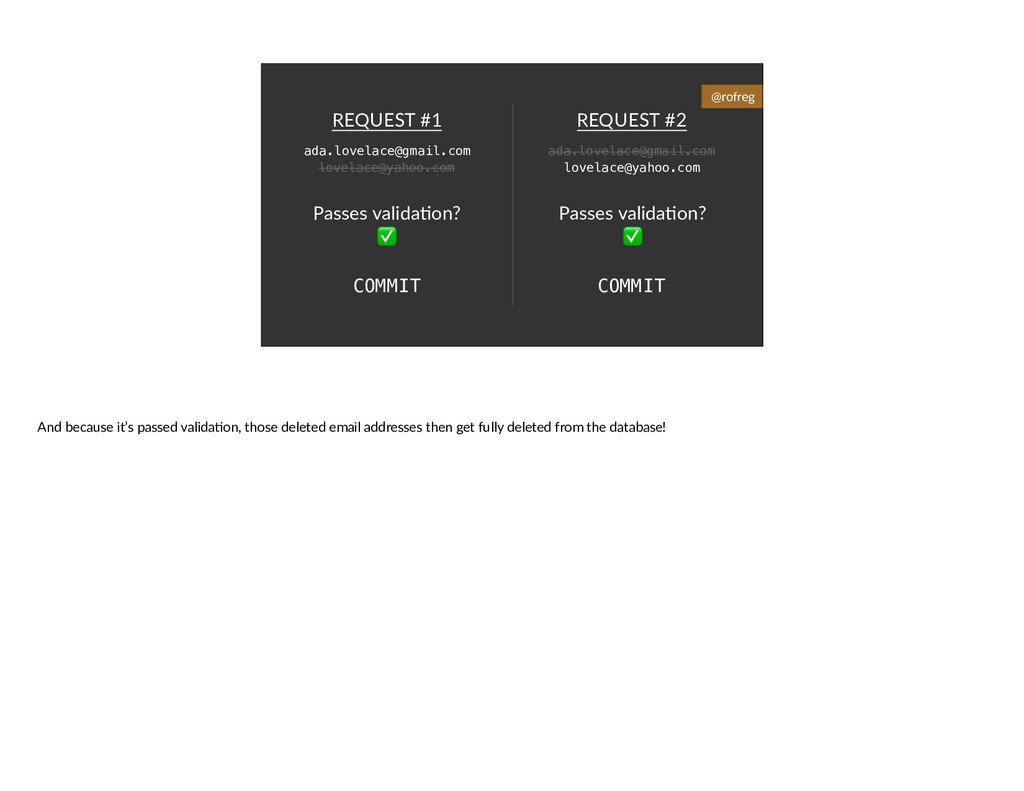{kind=link}
![FINAL RESULT [email protected] [email protected] @rofreg And you end up with](https://files.speakerdeck.com/presentations/4f17cbcffc954c778e9b46c7536a5491/slide_68.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
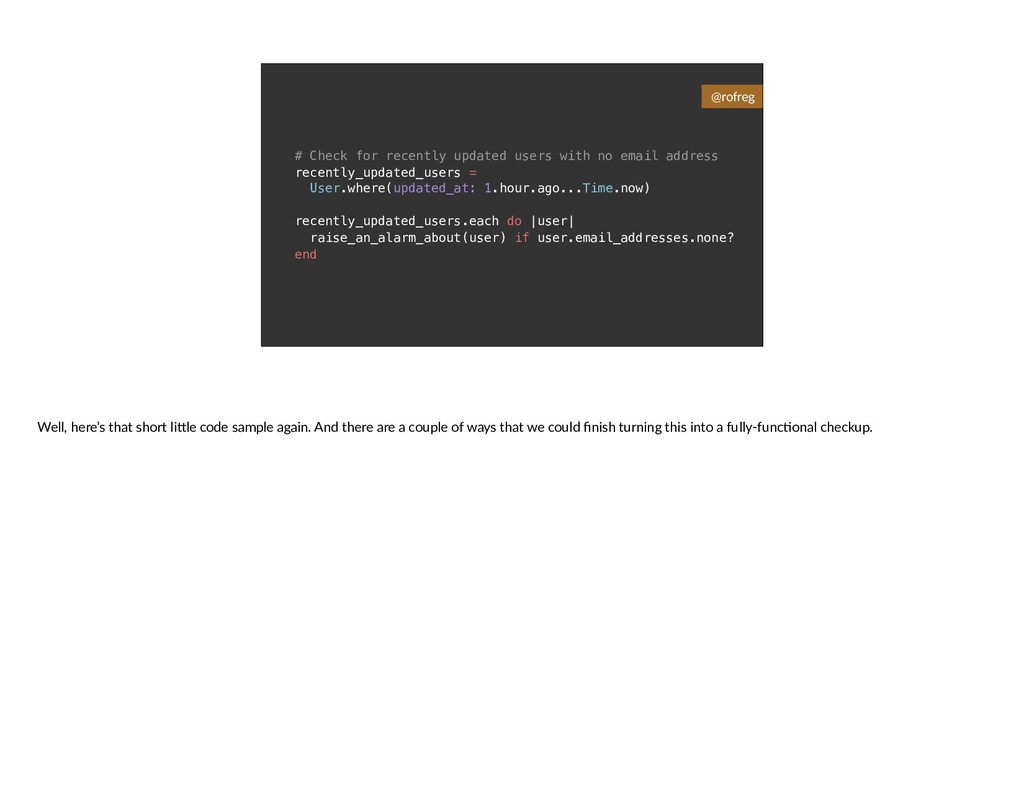{kind=link}
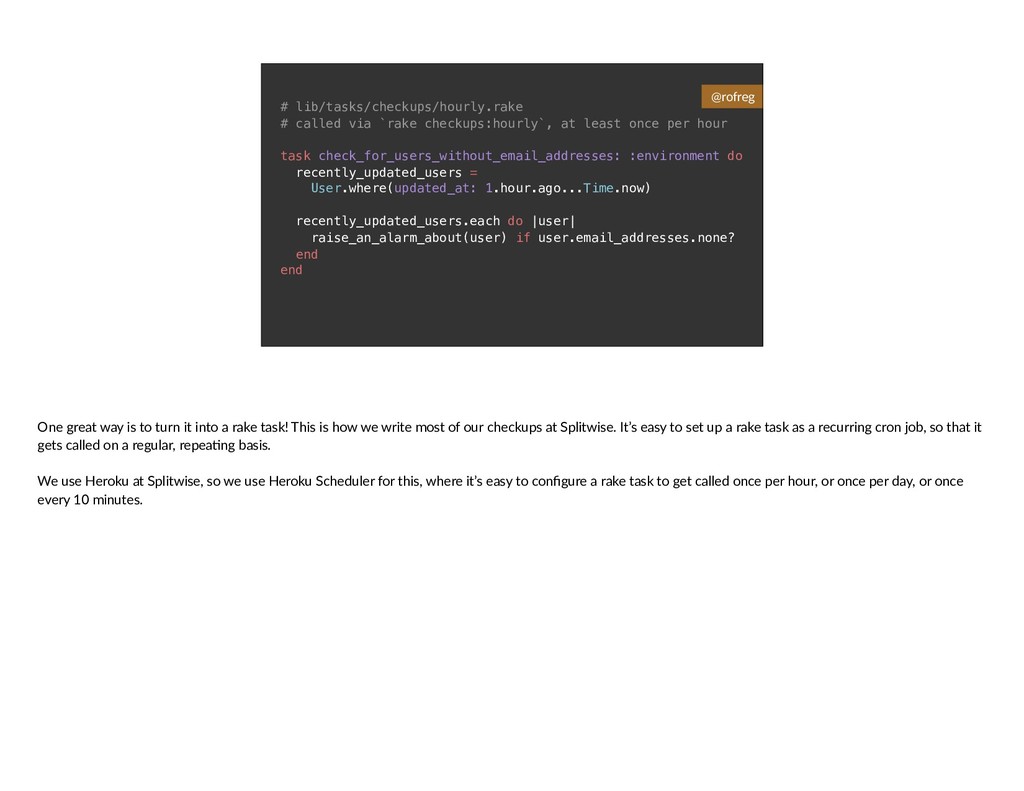{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![FINAL RESULT [email protected] [email protected] @rofreg Here’s a real example. Let’s](https://files.speakerdeck.com/presentations/4f17cbcffc954c778e9b46c7536a5491/slide_81.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}