Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
『本文が全部消えました』を撲滅 〜18年続くサービスに変更履歴機能を実装〜
Search
Yudai Tanaka
October 07, 2025
Programming
18
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
『本文が全部消えました』を撲滅 〜18年続くサービスに変更履歴機能を実装〜
Yudai Tanaka
October 07, 2025
Other Decks in Programming
See All in Programming
Android CLI
fornewid
0
120
はてなアカウント基盤 State of the Union
cockscomb
1
1.3k
Claude Opus 4.6以後の受託開発エンジニアの変化(Claude Code開発ノウハウ大公開スペシャルbyクラスメソッド)
iidatakuma
1
840
2年かけて Deno に DOMMatrix を実装した話 / How I implemented DOMMatrix in Deno over two years
petamoriken
0
110
Prismを使った型安全な暗号化_関数型まつり2026
_fhhmm
0
150
Haskell/Servantを通してWebミドルウェアを捉え直す
pizzacat83
1
610
使用 Meilisearch 建立新聞搜尋工具
johnroyer
0
170
琵琶湖の水は止められてもNet--HTTPのリトライは止められない / You might be able to stop the water flow of Lake Biwa but you can't stop Net::HTTP retries
luccafort
PRO
0
430
変わらないものが、変わるものを決める — 意図駆動開発 × イベントソーシング × イミュータブル | What Doesn't Change Decides What Can — IDD × Event Sourcing × Immutability
tomohisa
0
150
AI がコードを書く時代における新卒エンジニアの仕事風景 (2026) / New Graduate Engineers in the Era of AI Coding (2026)
sushichan044
0
230
Terraform標準の組織で AWS CDKをどう使うか
mu7889yoon
1
350
AI時代、エンジニアはどう育つのか -未経験エンジニアの成長を間近で見て考えたこと-
thasu0123
0
140
Featured
See All Featured
Bootstrapping a Software Product
garrettdimon
PRO
307
120k
Into the Great Unknown - MozCon
thekraken
41
2.6k
BBQ
matthewcrist
89
10k
Code Reviewing Like a Champion
maltzj
528
40k
The State of eCommerce SEO: How to Win in Today's Products SERPs - #SEOweek
aleyda
2
11k
How Software Deployment tools have changed in the past 20 years
geshan
0
34k
Highjacked: Video Game Concept Design
rkendrick25
PRO
1
410
Joys of Absence: A Defence of Solitary Play
codingconduct
1
420
Fashionably flexible responsive web design (full day workshop)
malarkey
408
67k
Mind Mapping
helmedeiros
PRO
1
290
brightonSEO & MeasureFest 2025 - Christian Goodrich - Winning strategies for Black Friday CRO & PPC
cargoodrich
3
750
GraphQLの誤解/rethinking-graphql
sonatard
75
12k
Transcript
『本文が全部消えました』を撲滅 〜18年続くサービスに変更履歴機能を実装〜 Tech Talks ! @Studio #1 田中湧大 - @Romira915
田中湧大 自己紹介 株式会社PR TIMES 事業ユニット 第一開発部 ソフトウェアエンジニア (24卒入社) @Romira915 @Romira915
主にバックエンド 仕事ではPHP, 趣味でRustを書く
None
PR TIMES / エディター PR TIMESは18年続く歴史あるサービス 2023年12月にエディターをリニューアルしUI/UXが大きく変わる そのエディターに変更履歴機能を実装
なぜ変更履歴が必要だったか
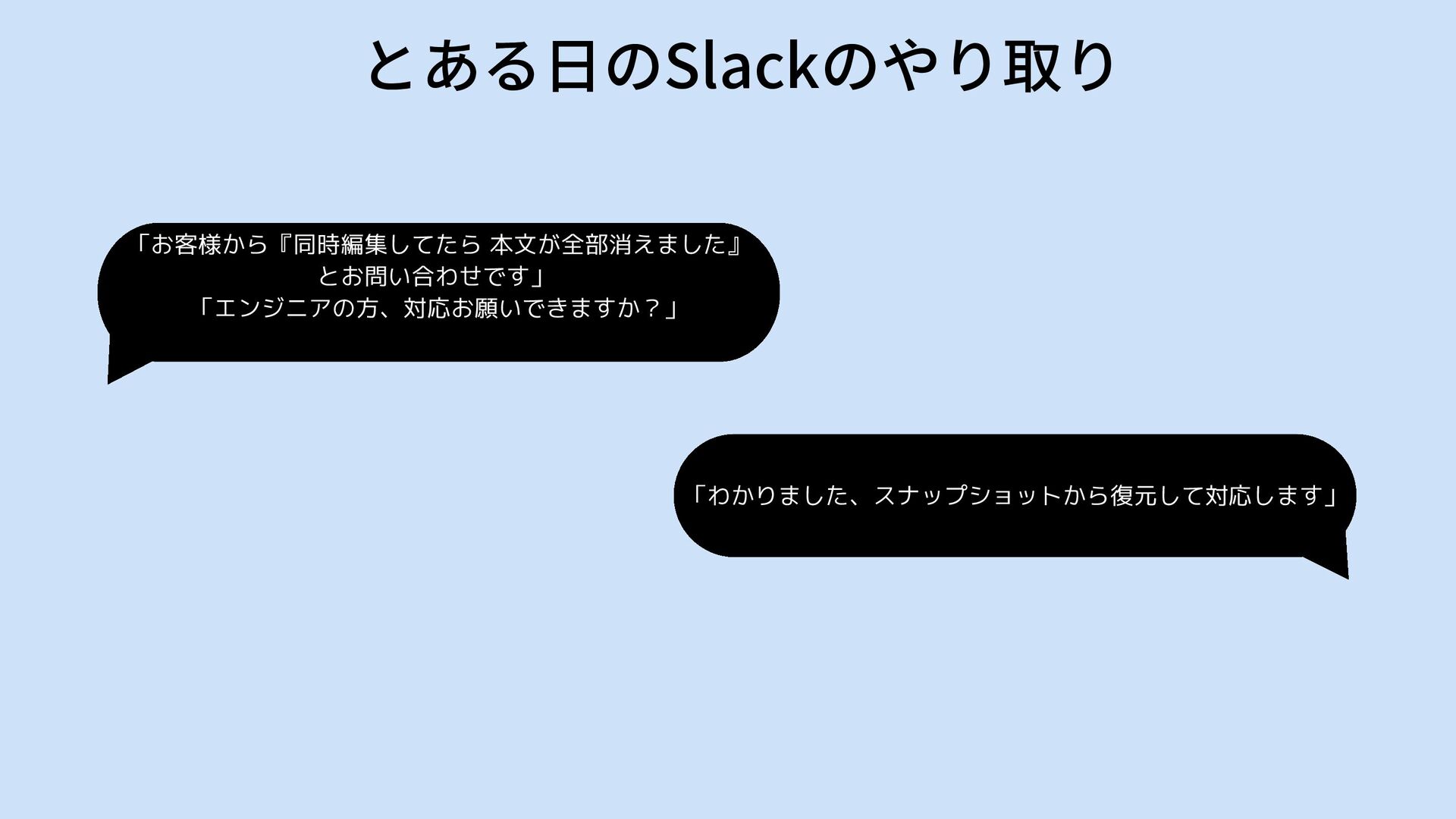
「お客様から『同時編集してたら 本文が全部消えました』 とお問い合わせです」 「エンジニアの方、対応お願いできますか?」 「わかりました、スナップショットから復元して対応します」 とある日のSlackのやり取り
というやり取りが数件発生
問い合わせのたびにエンジニアの工数がかかっていた・・ お客様からいつ頃、どのリリースが消えたか 正常に保存されていたタイミングはいつか ヒアリングから該当時刻を特定してAWS RDSの機能「Point-in-time recovery」 を使ってスナップショットから復元 当然本番DBを全て丸ごと復元するので時間がかかる 復元したDBから本文を取ってきて本番へ復元 https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/USER_PIT.html
お客様は待たされ、 エンジニアの時間も奪われる・・・
そこで変更履歴機能を実装して お客様自身で復元できるように
何を?どのタイミングで?いつまで?
何を保存するか? タイトル・サブタイトル・本文 画像(最大30枚 × 10MB) PDFなどのドキュメントファイル(最大4つ × 5MB) メタデータ(ビジネスカテゴリ、キーワード、位置情報、配信先) プレスリリースを構成する要素
何を保存するか? プレスリリースを構成する要素 今回は「本文が消えた」という課題を解決するために 本文に関わる要素のみを履歴保存の対象にする タイトル・サブタイトル・本文 画像(最大30枚 × 10MB) PDFなどのドキュメントファイル(最大4つ ×
5MB) メタデータ(ビジネスカテゴリ、キーワード、位置情報、配信先)
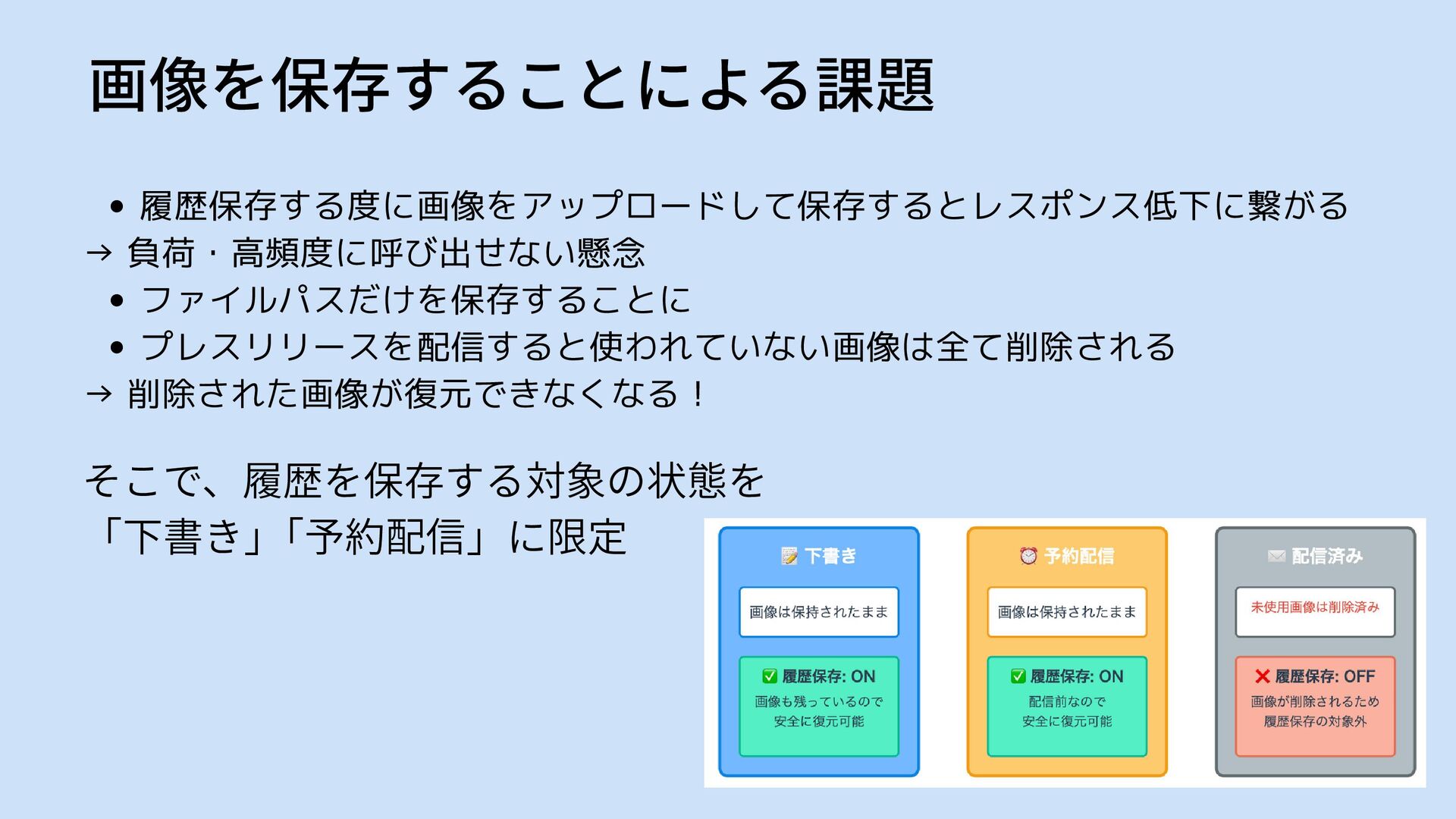
画像を保存することによる課題 履歴保存する度に画像をアップロードして保存するとレスポンス低下に繋がる → 負荷・高頻度に呼び出せない懸念 ファイルパスだけを保存することに 画像(最大30枚 × 10MB) PDFなどのドキュメントファイル(最大4つ ×
5MB)
履歴保存する度に画像をアップロードして保存するとレスポンス低下に繋がる → 負荷・高頻度に呼び出せない懸念 ファイルパスだけを保存することに プレスリリースを配信すると使われていない画像は全て削除される → 削除された画像が復元できなくなる! 画像を保存することによる課題 そこで、履歴を保存する対象の状態を 「下書き」
「予約配信」に限定
どのタイミングで保存するか? 自動保存API呼び出し間隔 現在:3秒ごと 変更履歴:2分に1回 過去1ヶ月の自動保存の頻度を分析して この頻度で問題ないかを調査
どのタイミングで保存するか? 1ヶ月あたりの保存回数: 約820,000(開発開始当時) 1記事あたりの保存回数:ほとんどのプレスリリースが20回以下 月約2万件のINSERT
どのタイミングで保存するか? 2分に1回 復元する前 保存ボタンを手動で押したとき 最終的に以下のタイミングで履歴を保存することに ただし、前バージョンと差分がない場合は保存しない
テーブル設計の工夫
正規化されていないテーブル プレスリリースを管理する1つのテーブルに 全ての情報が集約 画像だけで60カラム SQLの見通しが悪く、拡張性が乏しい releasesテーブル 10回以上スクロールしないと 全体が読めない!
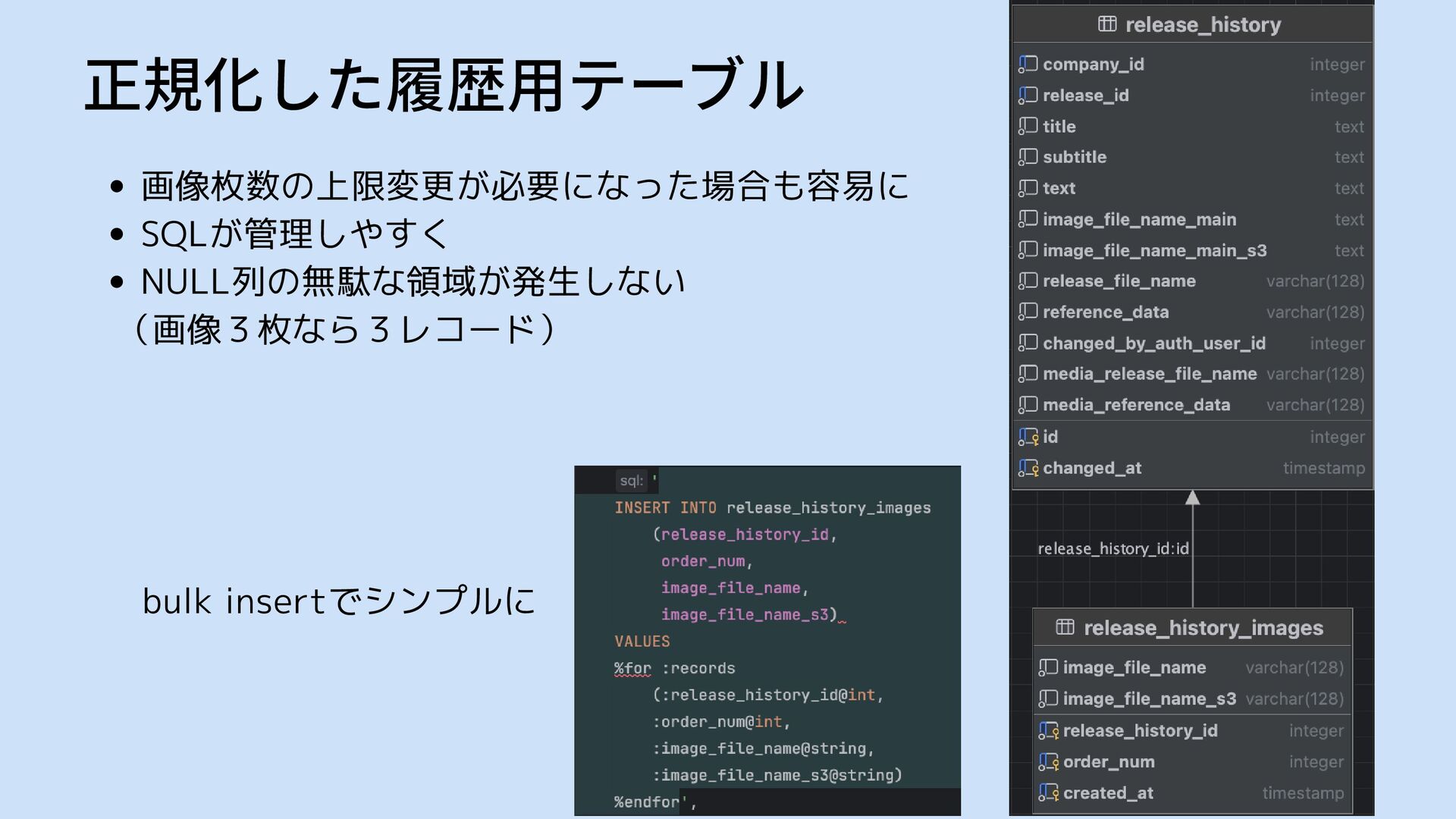
正規化した履歴用テーブル 画像枚数の上限変更が必要になった場合も容易に SQLが管理しやすく NULL列の無駄な領域が発生しない (画像3枚なら3レコード) bulk insertでシンプルに
【余談】パーティションを切ったテーブルに 外部キーを設定しようが断念した話
仕様として直近30日以内のデータのみを表示する 古いデータは定期的に削除する パーティションテーブルを採用し、月単位でテーブルを分割 バッチ処理でテーブルを定期的にDROP パーティションテーブルを活用
release_history_imagesに外部キーを張る 外部キー自体は作成できる
release_history_imagesに外部キーを張る 月次のパーティションテーブルを作り、保存期間がすぎ たら削除することを考える 外部キー制約によりDROPできない 外部キーは貼らない方針で行う
履歴から復元するフローをどうするか?
復元フローの選択 方法1 → 復元処理APIを実装(バックエンドで復元を行う) 方法2 → 復元処理はフロントエンド(State更新) 保存は既存の保存用APIを叩く
方法1復元処理APIを実装 PROS CONS APIが独立しているため、復元機能に関するAPI監視や、利用 数の追跡が容易 APIをCallするだけなのでフロントエンドが簡素になる APIを実装する必要があるため方法2と比べて工数が上がる 「保存」という同じ処理が複数存在することになる
方法2復元処理はフロントエンド(State更新) 保存は既存の保存用APIを利用 PROS CONS 保存APIを再利用できるため工数削減 保存フローを統一できるためバグが発生しにくい 文字数制限を超えた履歴も柔軟に復元可能(Stateのみ更新、保存はユー ザー判断) 復元機能を利用したログ情報を保存するAPIを実装する必要がある
フロントエンドのState更新 → APIリクエスト の流れになり複雑度が 上がる
方法2復元処理はフロントエンド(State更新) 保存は既存の保存用APIを利用 保存APIを再利用できるため工数削減 保存フローを統一できるためバグが発生しにくい 文字数制限を超えた履歴も柔軟に復元可能(Stateのみ更新、保存はユー ザー判断) 復元機能を利用したログ情報を保存するAPIを実装する必要がある フロントエンドのState更新 →
APIリクエスト の流れになり複雑度が 上がる 両者を比較した結果、方法2を採用し実装 CONS PROS
まとめ 実装後の効果 リリース後本文消失のお問い合わせは1件のみ DBから復元するエンジニアの対応時間もほぼ0に やったこと 既存APIを活用しながら変更履歴機能を実現 レガシーなテーブルはそのまま、履歴テーブルで正規化を実現 仕様をシンプルに絞り込み、3ヶ月で完遂
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}