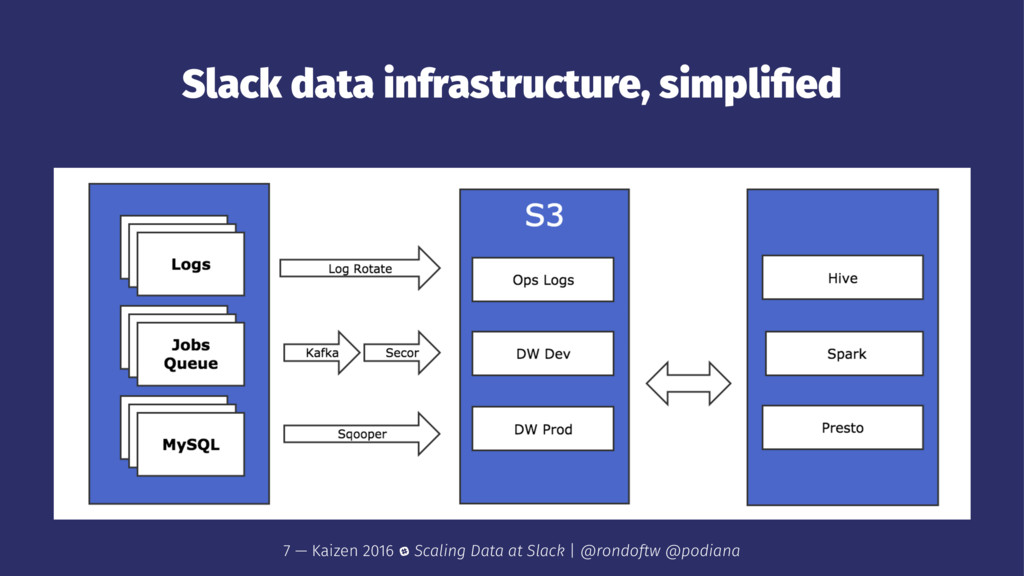
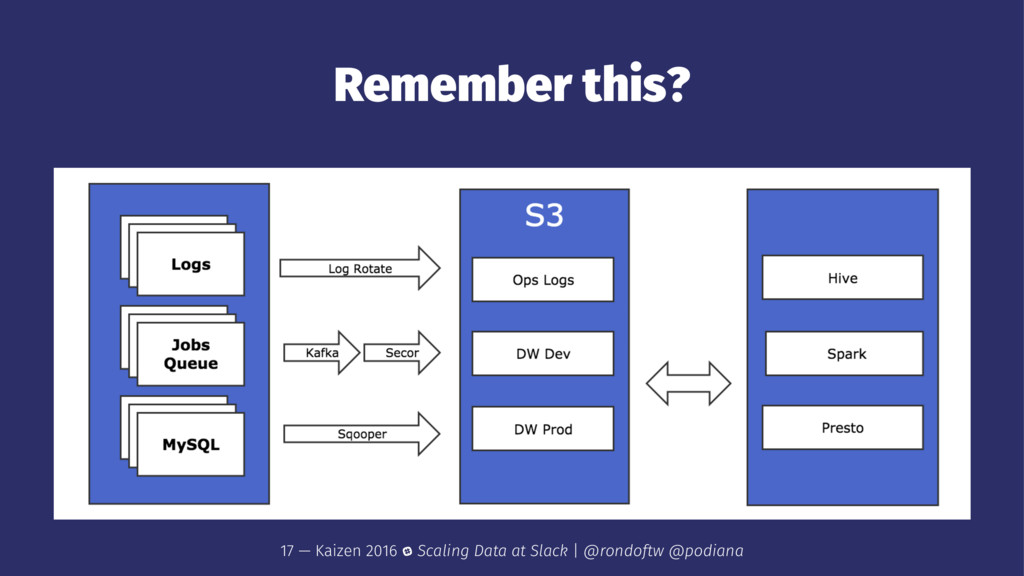
→ fast/adhoc queries to explore data and get fast answers for a short time range → majority of use is via UI interface vs command line → visualization tools via Mode for making charts and dashboards 8 — Kaizen 2016 Scaling Data at Slack | @rondoftw @podiana
jobs → suited for ETL pipeline as it can handle larger joins → queries for longer time ranges or bigger datasets because there are no memory constraints → fault-tolerance to stage failures 9 — Kaizen 2016 Scaling Data at Slack | @rondoftw @podiana
different Hive tables for analysts → easier to express some logic in code (! Scala!) and use libraries instead of SQL-like language → multiple knobs to turn to make the jobs more efficient and faster than Hive queries → testable 10 — Kaizen 2016 Scaling Data at Slack | @rondoftw @podiana
set up with Presto/Hive/Spark → clusters are ephemeral, we only use it for computation and run our jobs there 11 — Kaizen 2016 Scaling Data at Slack | @rondoftw @podiana
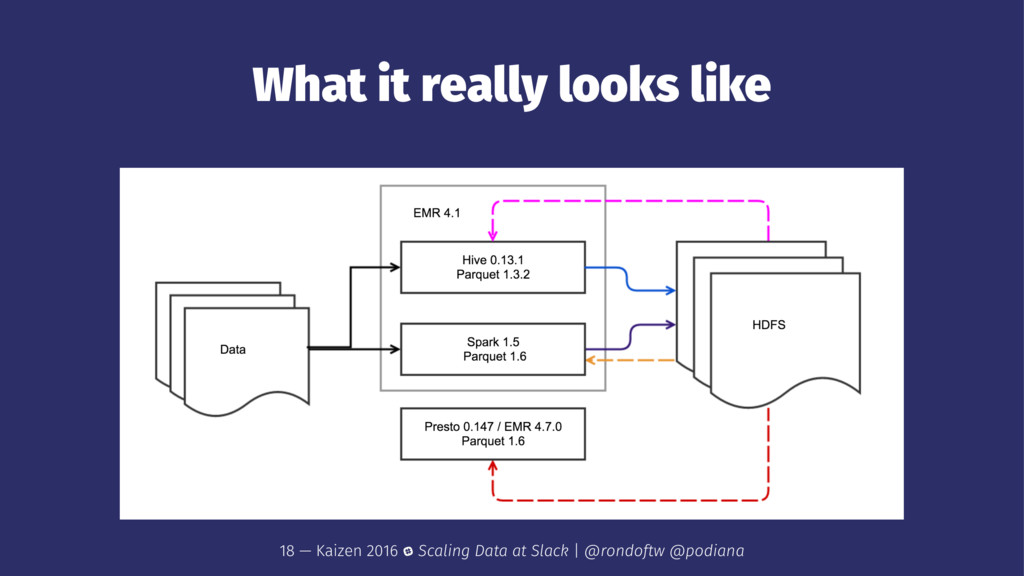
→ Data is structured and typed → Easy to test and launch in production when ready → Flexibility to choose best processing engine for the job 15 — Kaizen 2016 Scaling Data at Slack | @rondoftw @podiana
read back → You can write data another tool can't read → You can write data that is read the wrong way ! → Have to flatten structured data to keep evolving it → Need to maintain and support interop of all engines 16 — Kaizen 2016 Scaling Data at Slack | @rondoftw @podiana
→ Presto/Spark/Hive versions use conflicting dependencies (parquet) → You're stuck with those versions (no latest features, bug fixes) ! → Missing many useful UDFs from newer versions → Upgrading is not as easy as it seems 19 — Kaizen 2016 Scaling Data at Slack | @rondoftw @podiana
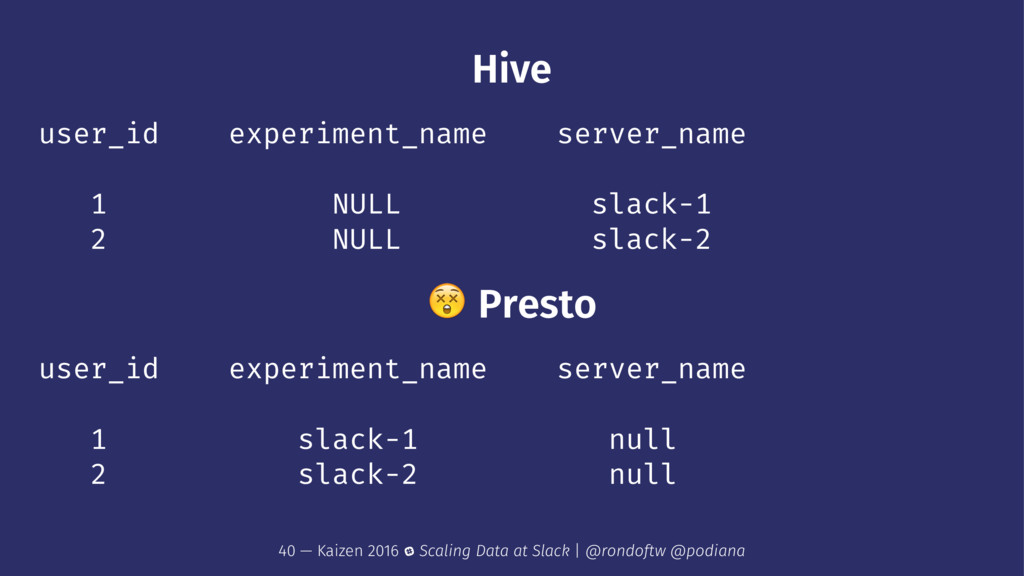
uri: string>, user struct<id: bigint>) PARTITIONED BY ( date string ) LOCATION 's3://datawarehouse/prod/slog' 22 — Kaizen 2016 Scaling Data at Slack | @rondoftw @podiana
data ! Altering the table just updates Hive's metadata without updating parquet's schema and the already written partitions metadata. ! We used the lastest HiveParquetSerDe 26 — Kaizen 2016 Scaling Data at Slack | @rondoftw @podiana
HiveParquetSerDe ! ERROR: There is a mismatch between the table and partition schemas. The column 'http' in table 'prod.slog' is declared as type 'struct<method:string,uri:string,user_agent:string>', but partition declared column 'http' as type 'struct<method:string,uri:string>'. ! We created a flattened version of our logs 27 — Kaizen 2016 Scaling Data at Slack | @rondoftw @podiana
3: User user } struct Http { 1: string method 2: string uri 3: string user_agent } struct User { 1: i64 id } 28 — Kaizen 2016 Scaling Data at Slack | @rondoftw @podiana
Hive ! java.io.IOException: java.lang.NullPointerException at org.apache.hadoop.hive.ql.exec.FetchOperator.getNextRow(FetchOperator.java:663) ... Caused by: java.lang.NullPointerException at parquet.format.converter.ParquetMetadataConverter.fromParquetStatistics(ParquetMetadataConverter.java:247) at parquet.format.converter.ParquetMetadataConverter.fromParquetMetadata(ParquetMetadataConverter.java:368) at parquet.format.converter.ParquetMetadataConverter.readParquetMetadata(ParquetMetadataConverter.java:346) at parquet.hadoop.ParquetFileReader.readFooter(ParquetFileReader.java:296) at parquet.hadoop.ParquetFileReader.readFooter(ParquetFileReader.java:254) at org.apache.hadoop.hive.ql.io.parquet.read.ParquetRecordReaderWrapper.getSplit(ParquetRecordReaderWrapper.java:200) at org.apache.hadoop.hive.ql.io.parquet.read.ParquetRecordReaderWrapper.<init>(ParquetRecordReaderWrapper.java:79) at org.apache.hadoop.hive.ql.io.parquet.read.ParquetRecordReaderWrapper.<init>(ParquetRecordReaderWrapper.java:66) at org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat.getRecordReader(MapredParquetInputFormat.java:72) at org.apache.hadoop.hive.ql.exec.FetchOperator.getRecordReader(FetchOperator.java:498) at org.apache.hadoop.hive.ql.exec.FetchOperator.getNextRow(FetchOperator.java:588) ... 15 more 34 — Kaizen 2016 Scaling Data at Slack | @rondoftw @podiana
case DoubleType => 0.asInstanceOf[Double] case IntegerType => 0 case LongType => 0L case StringType => "" case ArrayType(_, _) => List.empty case MapType(_, _) => Map.empty case t => throw new IllegalArgumentException(s"Unknown type to get default value: $t") } 35 — Kaizen 2016 Scaling Data at Slack | @rondoftw @podiana
{ --> case BooleanType => null case DoubleType => 0.asInstanceOf[Double] case IntegerType => 0 case LongType => 0L case StringType => "" case ArrayType(_, _) => List.empty case MapType(_, _) => Map.empty case t => throw new IllegalArgumentException(s"Unknown type to get default value: $t") } 36 — Kaizen 2016 Scaling Data at Slack | @rondoftw @podiana
are illegal, the field should be ommited completely instead java.lang.RuntimeException: Parquet record is malformed: empty fields are illegal, the field should be ommited completely instead at org.apache.hadoop.hive.ql.io.parquet.write.DataWritableWriter.write(DataWritableWriter.java:64) at org.apache.hadoop.hive.ql.io.parquet.write.DataWritableWriteSupport.write(DataWritableWriteSupport.java:59) at org.apache.hadoop.hive.ql.io.parquet.write.DataWritableWriteSupport.write(DataWritableWriteSupport.java:31) at parquet.hadoop.InternalParquetRecordWriter.write(InternalParquetRecordWriter.java:121) at parquet.hadoop.ParquetRecordWriter.write(ParquetRecordWriter.java:123) ... at com.facebook.presto.execution.SqlTaskExecution$DriverSplitRunner.processFor(SqlTaskExecution.java:622) at com.facebook.presto.execution.TaskExecutor$PrioritizedSplitRunner.process(TaskExecutor.java:529) at com.facebook.presto.execution.TaskExecutor$Runner.run(TaskExecutor.java:665) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) at java.lang.Thread.run(Thread.java:745) Caused by: parquet.io.ParquetEncodingException: empty fields are illegal, the field should be ommited completely instead at parquet.io.MessageColumnIO$MessageColumnIORecordConsumer.endField(MessageColumnIO.java:244) at org.apache.hadoop.hive.ql.io.parquet.write.DataWritableWriter.writeMap(DataWritableWriter.java:241) at org.apache.hadoop.hive.ql.io.parquet.write.DataWritableWriter.writeValue(DataWritableWriter.java:116) at org.apache.hadoop.hive.ql.io.parquet.write.DataWritableWriter.writeGroupFields(DataWritableWriter.java:89) at org.apache.hadoop.hive.ql.io.parquet.write.DataWritableWriter.write(DataWritableWriter.java:60) ... 23 more 38 — Kaizen 2016 Scaling Data at Slack | @rondoftw @podiana
properly handled for Parquet tables def getDefaultValue(dataType: DataType): Any = dataType match { case BooleanType => null case DoubleType => 0.asInstanceOf[Double] case IntegerType => 0 case LongType => 0L case StringType => "" --> case ArrayType(elemDataType, _) => List(getDefaultValue(elemDataType)) --> case MapType(keyDataType, valueDataType, _) => Map(getDefaultValue(keyDataType) -> getDefaultValue(valueDataType)) case t => throw new IllegalArgumentException(s"Unknown type to get default value: $t") } 39 — Kaizen 2016 Scaling Data at Slack | @rondoftw @podiana
are accessed by their ordinal position in the Hive table definition. → hive.parquet.use-column-names=true → explicitly write column values so that column shift cannot happen 42 — Kaizen 2016 Scaling Data at Slack | @rondoftw @podiana
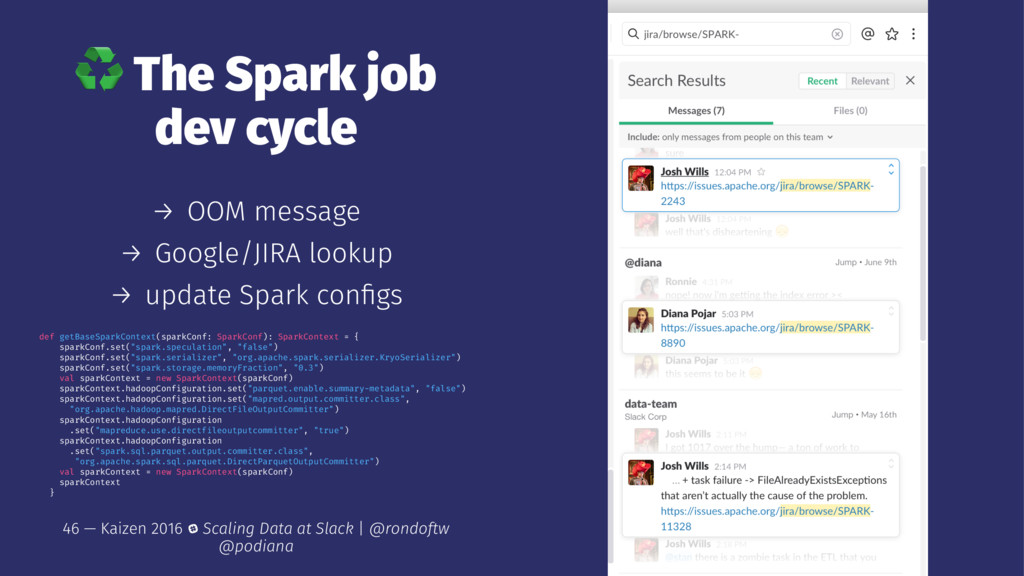
error message when direct parquet output committer is used and there is a file already exists error. 45 — Kaizen 2016 Scaling Data at Slack | @rondoftw @podiana
never worry about it again public class SlackSparkParquetOutputFormat(val path: String) extends ParquetOutputFormat[Row] { ... } 53 — Kaizen 2016 Scaling Data at Slack | @rondoftw @podiana
are more complicated than they appear → Backwards compatibility isn't always → Consequences from your previous decisions combine in strange ways 55 — Kaizen 2016 Scaling Data at Slack | @rondoftw @podiana
than writing the code ! If you're not running on premise, look into constraints and interop first ☔ Build for the greatest common factor of features or risk surprises 57 — Kaizen 2016 Scaling Data at Slack | @rondoftw @podiana
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Presto [HIVE-11625] - Map instances with null keys are not](https://files.speakerdeck.com/presentations/524234e3fe8841a4a683c803ccacf58f/slide_38.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![Leveraging Scala: Option[T] > null Writing custom rich classes to](https://files.speakerdeck.com/presentations/524234e3fe8841a4a683c803ccacf58f/slide_42.jpg){kind=link}
{kind=link}
![! java.io.IOException: File already exists... [SPARK-11328] - Provide more informative](https://files.speakerdeck.com/presentations/524234e3fe8841a4a683c803ccacf58f/slide_44.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}