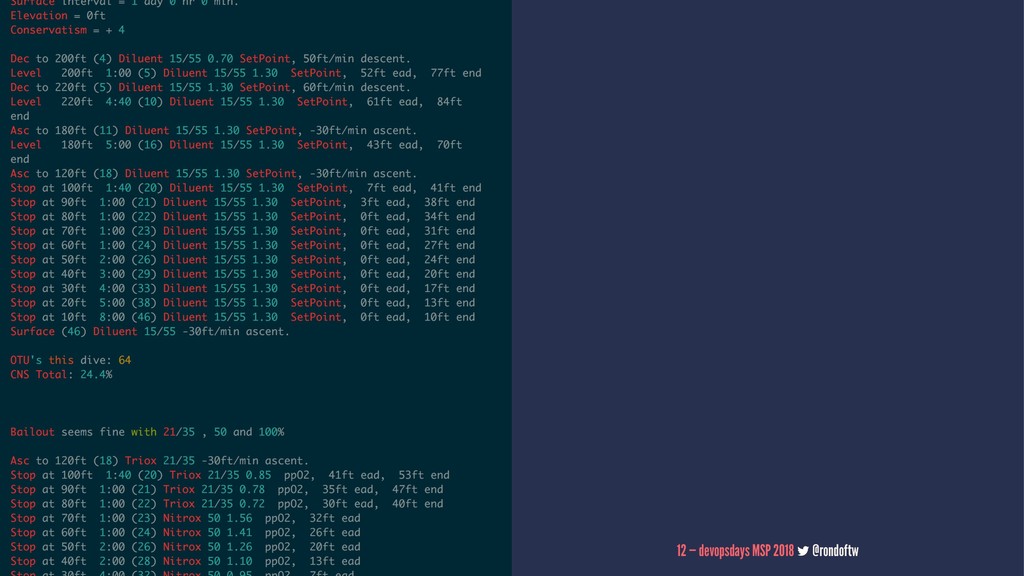
4. carbon dioxide buildup 5. oxygen sensor failure 6. deep tissue isobaric counterdiffusion (ICD) 7. high pressure nervous syndrome (HPNS) 8. exhausting your carbon dioxide scrubber 9. carbon dioxide channeling from a poorly packed scrubber 10. carbon buildup causing an spark leading to an oxygen fire. underwater. 11. flooding of breathing loop or circuitry 12. water mixing with the scrubbing agent to produce a toxic caustic soda that will give you chemical burns on your mouth, airway, and lungs 13. plain old decompression sickness 10 — devopsdays MSP 2018 @rondoftw
DEALING WITH COMPLEX SYSTEMS INSTEAD * These guidelines have only been shown to work for life or death situations under the ocean. They have not been proven to work for tech. 19 — devopsdays MSP 2018 @rondoftw
a rebreather malfunction ▸ which you would have caught it if you were testing your equipment on a regular basis ▸ your backup tank had a leak and is running low and that wasn't caught either ▸ and your buddy is too far away and isn't checking in with you ▸ and your dive light that you use to communicate at a distance is out of power ▸ and in the excitement you kick up silt and the visibility drops ▸ and in your panic your air consumption goes up and then you breathe through the last of the air in your tank ▸ so you swim for the surface even though you have a decompression obligation 23 — devopsdays MSP 2018 @rondoftw
the system fails. They happen because all the safety procedures that are supposed to stop the failure from cascading didn't work. 25 — devopsdays MSP 2018 @rondoftw
it was safe ADAPTATION experience is no longer a suitable gauge of risk SOCIAL PRESSURE this is just how we do things 28 — devopsdays MSP 2018 @rondoftw
on likelihood of occurrence. ▸ Make assessments based on magnitude of regret. If you are only evaluating risk based on the chance of it happening, you must be prepared to experience the corresponding level of regret if it does. 32 — devopsdays MSP 2018 @rondoftw
you cannot survive without. ▸ Have a redundant pathway to success: a procedure for graceful degradation for systems that are important but not critical. ▸ Have a process for changing over from primary to redundant systems. 36 — devopsdays MSP 2018 @rondoftw
leads ▸ Experienced person advises, only intervening when necessary ▸ Team is invested in personal success to ensure mission success 40 — devopsdays MSP 2018 @rondoftw
the best ways to equalize a gap in experience ▸ Opportunity to revise and improve problematic systems ▸ Help build good judgment 41 — devopsdays MSP 2018 @rondoftw
▸ Identify potential avenues of of failure and make plans for them ▸ Include both likely failures and high regret failures 45 — devopsdays MSP 2018 @rondoftw
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}