:drop, :drop_while, :each_cons, :each_entry, :each_slice, :each_with_index, :each_with_object, :entries, :find, :find_all, :find_index, :first, :flat_map, :grep, :group_by, :include?, :inject, :lazy, :map, :max, :max_by, :member?, :min, :min_by, :minmax, :minmax_by, :none?, :one?, :partition, :reduce, :reject, :reverse_each, :select, :slice_after, :slice_before, :slice_when, :sort, :sort_by, :take, :take_while, :to_a, :to_h, :zip] p Enumerable.instance_methods.sort Speaking of Enumerable methods, we’ve got a lot to choose from. There are over 50 instance methods provided by Enumerable, some of which you know well, and I’ll bet, some less familiar. It could benefit you to explore aspects you haven’t used much yet.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![10 [1, 2, 3].each { |i| puts i } When](https://files.speakerdeck.com/presentations/df623bc08aa642328c303a619c92fab0/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
![13 [Enumerable, Kernel] [Enumerable, Kernel] [Enumerable, Kernel] [Enumerable, Kernel] [Enumerable]](https://files.speakerdeck.com/presentations/df623bc08aa642328c303a619c92fab0/slide_12.jpg){kind=link}
![14 p [1, 2, 3].map { |n| n * n](https://files.speakerdeck.com/presentations/df623bc08aa642328c303a619c92fab0/slide_13.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![words = ["it's", "close", "to", "midnight", ...] histogram = {}](https://files.speakerdeck.com/presentations/df623bc08aa642328c303a619c92fab0/slide_21.jpg){kind=link}
![words = ["it's", "close", "to", "midnight", ...] histogram = words.reduce(Hash.new(0))](https://files.speakerdeck.com/presentations/df623bc08aa642328c303a619c92fab0/slide_22.jpg){kind=link}
{kind=link}
{kind=link}
![words = ["it's", "close", "to", "midnight", ...] histogram = words.reduce(Hash.new(0))](https://files.speakerdeck.com/presentations/df623bc08aa642328c303a619c92fab0/slide_25.jpg){kind=link}
![words = ["it's", "close", "to", "midnight", ...] histogram = words.each_with_object(Hash.new(0))](https://files.speakerdeck.com/presentations/df623bc08aa642328c303a619c92fab0/slide_26.jpg){kind=link}
![words = ["it's", "close", "to", "midnight", ...] histogram = Hash[*words.group_by](https://files.speakerdeck.com/presentations/df623bc08aa642328c303a619c92fab0/slide_27.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
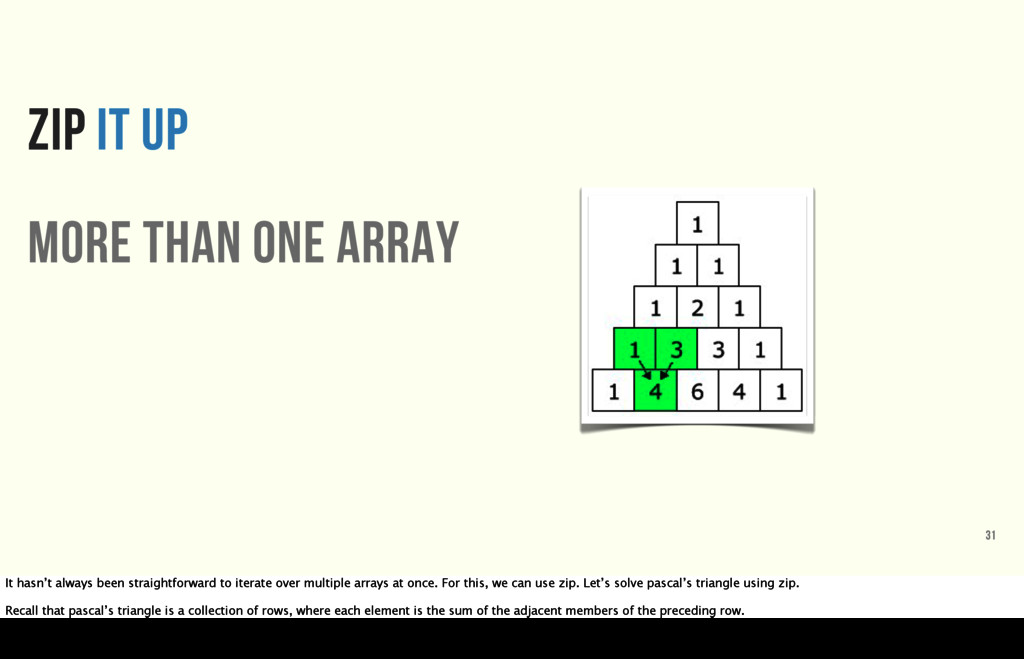
![def pascal_row(row = [1]) end row = [1] p row](https://files.speakerdeck.com/presentations/df623bc08aa642328c303a619c92fab0/slide_31.jpg){kind=link}
![Given [1, 1], return [1, 2, 1] 33 1, 1](https://files.speakerdeck.com/presentations/df623bc08aa642328c303a619c92fab0/slide_32.jpg){kind=link}
![def pascal_row(row = [1]) ([0] + row).zip(row + [0]).map {](https://files.speakerdeck.com/presentations/df623bc08aa642328c303a619c92fab0/slide_33.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![p [1, 2, 3].each p [1, 2, 3].map 48 #<Enumerator:](https://files.speakerdeck.com/presentations/df623bc08aa642328c303a619c92fab0/slide_47.jpg){kind=link}
{kind=link}
![letters = %w[a b c d e] pairs = letters.map.with_index](https://files.speakerdeck.com/presentations/df623bc08aa642328c303a619c92fab0/slide_49.jpg){kind=link}
![letters = %w[a b c d e] group_1 = letters.reverse_each.group_by.each_with_index](https://files.speakerdeck.com/presentations/df623bc08aa642328c303a619c92fab0/slide_50.jpg){kind=link}
{kind=link}
![p ['aliceblue', 'ghostwhite'].cycle.take(5) 53 ["aliceblue", "ghostwhite", "aliceblue", "ghostwhite", "aliceblue"] Cycle](https://files.speakerdeck.com/presentations/df623bc08aa642328c303a619c92fab0/slide_52.jpg){kind=link}
![Project = Struct.new(:name) projects = [Project.new("TODO"), Project.new("Work"), Project.new("Home")] colors =](https://files.speakerdeck.com/presentations/df623bc08aa642328c303a619c92fab0/slide_53.jpg){kind=link}
![enumerator = [1, 2].each p enumerator.next p enumerator.next begin p](https://files.speakerdeck.com/presentations/df623bc08aa642328c303a619c92fab0/slide_54.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![class PascalsTriangle def rows(first = [1]) Enumerator.new do |y| current](https://files.speakerdeck.com/presentations/df623bc08aa642328c303a619c92fab0/slide_64.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
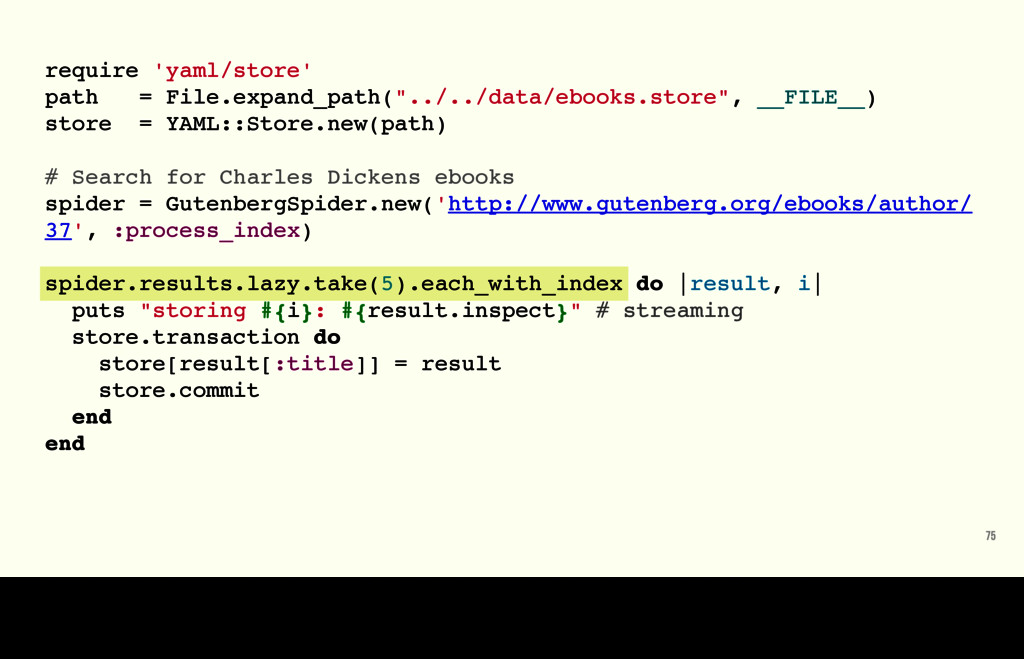{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![82 rossta/loves-enumerable @rossta ['thanks'] You can find all the code](https://files.speakerdeck.com/presentations/df623bc08aa642328c303a619c92fab0/slide_81.jpg){kind=link}